Ikhtisar Azure Storage di HDInsight
Azure Storage adalah solusi penyimpanan serbaguna yang kuat yang terintegrasi dengan mulus dengan HDInsight. HDInsight dapat menggunakan kontainer blob di Azure Storage sebagai sistem file default untuk klaster. Melalui antarmuka HDFS, set lengkap dari komponen dalam HDInsight dapat beroperasi langsung pada data terstruktur atau tidak terstruktur yang disimpan sebagai blob.
Kami menyarankan penggunaan kontainer penyimpanan terpisah untuk penyimpanan klaster default dan data bisnis Anda. Pemisahan ini bertujuan untuk mengisolasi log HDInsight dan file sementara dari data bisnis Anda sendiri. Kami juga menyarankan penghapusan kontainer blob default, yang berisi log aplikasi dan sistem, setelah setiap penggunaan untuk mengurangi biaya penyimpanan. Pastikan untuk mengambil log sebelum menghapus kontainer.
Jika Anda memilih untuk mengamankan akun penyimpanan Anda dengan pembatasan Firewall dan jaringan virtual pada Jaringan tertentu, pastikan untuk mengaktifkan pengecualian Izinkan layanan Microsoft tepercaya... sehingga HDInsight dapat mengakses akun penyimpanan Anda.
Arsitektur penyimpanan HDInsight
Diagram berikut ini menyediakan tampilan abstrak dari arsitektur HDInsight Azure Storage:
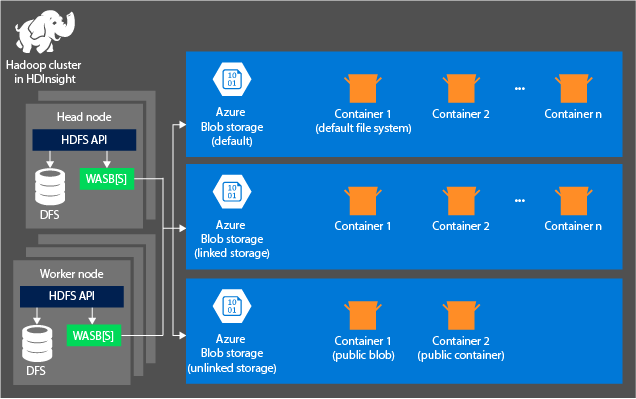
HDInsight menyediakan akses ke sistem file terdistribusi yang secara lokal melekat pada node komputasi. Sistem file ini dapat diakses dengan menggunakan URI yang sepenuhnya memenuhi syarat, contohnya:
hdfs://<namenodehost>/<path>
Melalui HDInsight, Anda juga dapat mengakses data di Azure Storage. Sintaksisnya adalah sebagai berikut:
wasb://<containername>@<accountname>.blob.core.windows.net/<path>
Untuk akun yang memiliki namespace hierarkis (Azure Data Lake Storage Gen2), sintaksnya adalah sebagai berikut:
abfs://<containername>@<accountname>.dfs.core.windows.net/<file.path>/
Pertimbangkan prinsip-prinsip berikut saat menggunakan akun Azure Storage dengan klaster HDInsight:
Kontainer di akun penyimpanan yang terhubung ke klaster: Karena nama akun dan kunci dikaitkan dengan klaster selama pembuatan, Anda memiliki akses penuh ke blob dalam kontainer tersebut.
Kontainer publik atau blob publik di akun penyimpanan yang tidak terhubung ke klaster: Anda memiliki izin baca-saja pada blob dalam kontainer.
Catatan
Kontainer publik memungkinkan Anda untuk mendapatkan daftar dari semua blob yang tersedia dalam kontainer tersebut dan mendapatkan metadata kontainer. Blob publik memungkinkan Anda untuk mengakses blob hanya jika Anda tahu URL dengan persis. Untuk informasi selengkapnya, lihat Mengelola akses baca anonim ke kontainer dan blob.
Kontainer privat di akun penyimpanan yang tidak terhubung ke klaster: Anda tidak dapat mengakses blob dalam kontainer kecuali Anda menentukan akun penyimpanan saat Anda mengirimkan pekerjaan WebHCat.
Akun penyimpanan yang ditentukan dalam proses pembuatan dan kuncinya disimpan di %HADOOP_HOME%/conf/core-site.xml pada node klaster. Secara default, HDInsight menggunakan akun penyimpanan yang ditentukan dalam file core-site.xml. Anda dapat mengubah pengaturan ini dengan menggunakan Apache Ambari. Untuk informasi selengkapnya tentang pengaturan akun penyimpanan yang dapat diubah atau ditempatkan di file core-site.xml, lihat artikel berikut:
- Dukungan Azure Hadoop: Azure Blob Storage
- Dukungan Azure Hadoop: ABFS — Azure Data Lake Storage Gen2
Beberapa pekerjaan WebHCat, termasuk Apache Hive. Dan MapReduce, streaming Apache Hadoop, dan Apache Pig, menegaskan deskripsi akun penyimpanan dan metadata. (Aspek ini saat ini bersifat true untuk Pig dengan akun penyimpanan tetapi tidak untuk metadata.) Untuk informasi selengkapnya, lihat Menggunakan klaster HDInsight dengan akun penyimpanan alternatif dan metastores.
Blob dapat digunakan untuk data terstruktur dan tidak terstruktur. Kontainer blob menyimpan data sebagai pasangan kunci/nilai dan tidak memiliki hierarki direktori. Namun nama kunci dapat menyertakan karakter garis miring (/) untuk membuatnya tampak seolah-olah file disimpan dalam struktur direktori. Misalnya, kunci blob bisa berupa input/log1.txt. Sebenarnya direktori input tidak ada, tetapi karena karakter garis miring dalam nama kunci, kunci terlihat seperti jalur file.
Manfaat Azure Storage
Klaster komputasi dan sumber daya penyimpanan yang tidak dikolokasi memiliki biaya kinerja tersirat. Biaya ini dimitigasi dengan cara membuat klaster komputasi dekat dengan sumber daya akun penyimpanan di dalam region Azure. Di region ini, node komputasi dapat mengakses data secara efisien melalui jaringan berkecepatan tinggi di dalam Azure Storage.
Dengan menyimpan data di Azure Storage dan bukan HDFS, Anda mendapatkan beberapa manfaat:
Penggunaan ulang dan berbagi data: Data dalam HDFS terletak di dalam klaster komputasi. Hanya aplikasi yang memiliki akses ke klaster komputasi yang dapat menggunakan data dengan menggunakan API HDFS. Sebaliknya, data di Azure Storage, dapat diakses melalui API HDFS atau API REST penyimpanan Blob. Karena pengaturan ini, set aplikasi (termasuk klaster HDInsight lainnya) dan alat yang lebih besar dapat digunakan untuk menghasilkan dan mengonsumsi data.
Pengarsipan data: Saat data disimpan di Azure Storage, klaster HDInsight yang digunakan untuk komputasi dapat dihapus dengan aman tanpa kehilangan data pengguna.
Biaya penyimpanan data: Penyimpanan data di DFS dalam jangka panjang lebih mahal daripada penyimpanan data di Azure Storage. Karena biaya klaster komputasi lebih tinggi dari biaya Azure Storage. Selain itu, karena data tidak harus dimuat ulang untuk setiap pembuatan klaster komputasi, Anda juga menghemat biaya pemuatan data.
Skala elastis: Meskipun HDFS memberi Anda sistem file yang luar biasa, skala ditentukan oleh jumlah node yang Anda buat untuk klaster Anda. Pengubahan skala bisa lebih rumit daripada kemampuan penyekalaan elastis yang Anda dapatkan secara otomatis di Azure Storage.
Replikasi geografis: Azure Storage Anda dapat direplikasi secara geografis. Meskipun replikasi geografis memberikan pemulihan geografis dan redundansi data kepada Anda, kegagalan pada lokasi yang direplikasi geografis sangat berdampak pada kinerja Anda, dan dapat menimbulkan biaya tambahan. Jadi pilih replikasi geografis dengan hati-hati dan hanya jika nilai data membenarkan biaya tambahan.
Pekerjaan dan paket MapReduce tertentu mungkin membuat hasil menengah yang tidak ingin Anda simpan di Azure Storage. Dalam hal ini, Anda dapat memilih untuk menyimpan data dalam HDFS lokal. HDInsight menggunakan DFS untuk beberapa hasil menengah tersebut di pekerjaan Apache Hive dan proses lainnya.
Catatan
Sebagian besar perintah HDFS (contohnya, ls, copyFromLocal, dan mkdir) berfungsi sesuai ekspektasi di Azure Storage. Hanya perintah yang khusus untuk implementasi HDFS asli (yang disebut sebagai DFS), seperti fschk dan dfsadmin, menunjukkan perilaku yang berbeda dalam Azure Storage.