Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Dalam tutorial ini, Anda belajar cara membuat dataframe dari file csv, dan cara menjalankan kueri Spark SQL interaktif terhadap kluster Apache Spark di Azure HDInsight. Di Spark, dataframe adalah kumpulan data terdistribusi yang disusun ke dalam kolom bernama. Dataframe secara konseptual setara dengan tabel dalam database relasional atau bingkai data di R/Python.
Dalam tutorial ini, Anda akan mempelajari cara:
- Membuat dataframe dari file csv
- Menjalankan kueri pada dataframe
Prasyarat
Klaster Apache Spark pada HDInsight. Lihat Buat kluster Apache Spark.
Membuat Jupyter Notebook
Jupyter Notebook merupakan lingkungan buku catatan interaktif yang mendukung berbagai bahasa pemrogram. Buku catatan tersebut memungkinkan Anda untuk berinteraksi dengan data, menggabungkan kode dengan teks markdown, dan melakukan visualisasi sederhana.
Edit URL
https://SPARKCLUSTER.azurehdinsight.net/jupyterdengan menggantiSPARKCLUSTERdengan nama kluster Spark Anda. Kemudian masukkan URL yang diedit di browser web. Jika diminta, masukkan kredensial masuk kluster untuk kluster.Dari halaman web Jupyter, Untuk kluster Spark 2.4, Pilih Baru>PySpark untuk membuat notebook. Untuk rilis Spark 3.1, pilih Baru>PySpark3 untuk membuat notebook karena kernel PySpark tidak lagi tersedia di Spark 3.1.
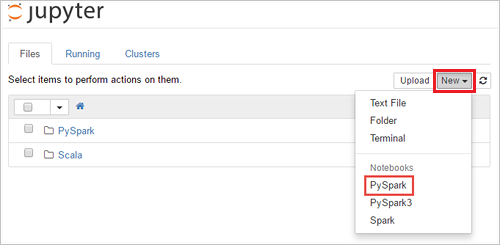
Buku catatan baru dibuat dan dibuka dengan nama Untitled(
Untitled.ipynb).Catatan
Dengan menggunakan kernel PySpark atau PySpark3 untuk membuat notebook, sesi
sparkdibuat secara otomatis untuk Anda saat Anda menjalankan sel kode pertama. Anda tidak perlu membuat sesi secara eksplisit.
Membuat dataframe dari file csv
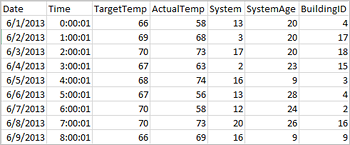
Aplikasi dapat membuat dataframe langsung dari file atau folder di penyimpanan jarak jauh seperti Azure Storage atau Azure Data Lake Storage; dari tabel Apache Hive; atau dari sumber data lain yang didukung oleh Spark, seperti Azure Cosmos DB, Azure SQL DB, DW, dan sebagainya. Cuplikan layar berikut menunjukkan rekam jepret dari file HVAC.csv yang digunakan dalam tutorial ini. File csv dilengkapi dengan semua kluster HDInsight Spark. Data menangkap variasi suhu beberapa bangunan.
Tempelkan kode berikut dalam sel kosong Jupyter Netbook, lalu tekan SHIFT + ENTER untuk menjalankan kode. Kode ini mengimpor tipe yang diperlukan untuk skenario ini:
from pyspark.sql import * from pyspark.sql.types import *Saat Anda menjalankan kueri interaktif di Jupyter, jendela browser web atau keterangan tab memperlihatkan status (Sibuk) bersama dengan judul buku catatan. Anda juga melihat lingkaran padat di sebelah teks PySpark di pojok kanan atas. Setelah pekerjaan selesai, lingkaran akan berubah menjadi lingkaran berongga.
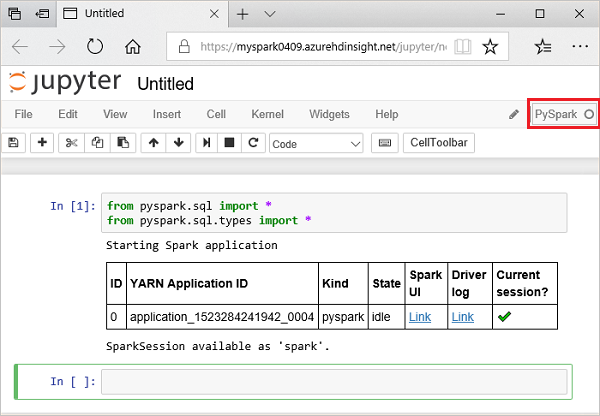
Perhatikan id sesi yang dikembalikan. Dari gambar di atas, id sesi adalah 0. Jika diinginkan, Anda dapat mengambil detail sesi dengan mengakses
https://CLUSTERNAME.azurehdinsight.net/livy/sessions/ID/statements, di mana CLUSTERNAME adalah nama kluster Spark Anda dan ID adalah nomor sesi Anda.Jalankan kode berikut untuk membuat dataframe dan tabel sementara(hvac) dengan menjalankan kode berikut.
# Create a dataframe and table from sample data csvFile = spark.read.csv('/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv', header=True, inferSchema=True) csvFile.write.saveAsTable("hvac")
Menjalankan kueri pada datanami
Setelah tabel dibuat, Anda bisa menjalankan kueri interaktif pada data.
Jalankan kode berikut ini di sel kosong buku catatan:
%%sql SELECT buildingID, (targettemp - actualtemp) AS temp_diff, date FROM hvac WHERE date = \"6/1/13\"Output tabular berikut ditampilkan.
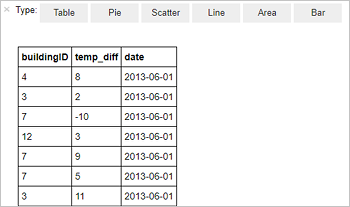
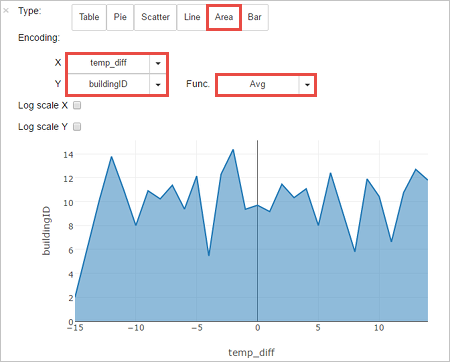
Anda juga dapat melihat hasilnya di visualisasi lain. Untuk melihat grafik area untuk output yang sama, pilih Area lalu atur nilai lain seperti yang diperlihatkan.
Dari bilah menu buku catatan, navigasi ke File>Simpan dan Pos Pemeriksaan.
Jika Anda memulai tutorial berikutnya sekarang, biarkan buku catatan terbuka. Jika tidak, matikan buku catatan untuk merilis sumber daya kluster: dari bilah menu buku catatan, navigasi ke File>Tutup dan Hentikan.
Membersihkan sumber daya
Dengan HDInsight, data dan Notebook Jupyter Anda disimpan di Azure Storage atau Azure Data Lake Storage, sehingga Anda dapat menghapus klaster dengan aman saat tidak digunakan. Anda juga dikenakan biaya untuk kluster HDInsight, bahkan saat tidak digunakan. Karena biaya untuk kluster berkali-kali lebih banyak daripada biaya untuk penyimpanan, masuk akal secara ekonomis untuk menghapus kluster saat tidak digunakan. Jika Anda berencana untuk segera bekerja pada tutorial berikutnya, Anda mungkin ingin mempertahankan kluster.
Buka kluster di portal Microsoft Azure, dan pilih Hapus.
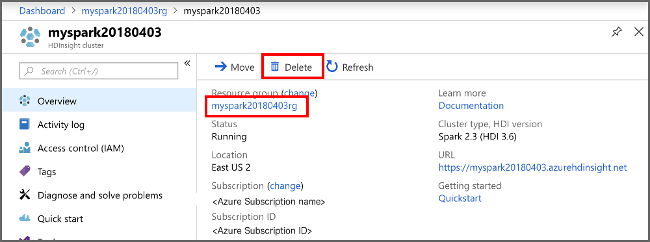
Anda juga dapat memilih nama grup sumber daya untuk membuka halaman grup sumber daya, lalu memilih Hapus grup sumber daya. Dengan menghapus grup sumber daya, Anda menghapus baik kluster HDInsight Spark maupun akun penyimpanan default.
Langkah berikutnya
Dalam tutorial ini, Anda belajar cara membuat dataframe dari file csv, dan cara menjalankan kueri Spark SQL interaktif terhadap kluster Apache Spark di Azure HDInsight. Lanjutkan ke artikel berikutnya untuk melihat bagaimana data yang Anda daftarkan di Apache Spark dapat ditarik ke dalam alat analitik BI seperti Power BI.