Menggunakan Apache Spark MLlib untuk membangun aplikasi pembelajaran mesin dan menganalisis himpunan data
Pelajari cara menggunakan Apache Spark MLlib untuk membuat aplikasi pembelajaran mesin. Aplikasi melakukan analisis prediktif pada himpunan data terbuka. Dari pustaka pembelajaran mesin bawaan Apache Spark, contoh ini menggunakan klasifikasi melalui regresi logistik.
MLlib adalah pustaka Spark inti yang menyediakan banyak utilitas yang berguna untuk tugas pembelajaran mesin, seperti:
- Klasifikasi
- Regresi
- Pengklusteran
- Pemodelan
- Penguraian nilai tunggal (SVD) dan analisis komponen utama (PCA)
- Pengujian hipotesis dan penghitungan statistik sampel
Memahami klasifikasi dan regresi logistik
Klasifikasi, tugas pembelajaran mesin yang populer, adalah proses pengurutan data input ke dalam kategori. Hal ini adalah pekerjaan algoritma klasifikasi untuk mencari tahu cara menetapkan "label" untuk memasukkan data yang Anda berikan. Misalnya, Anda dapat memikirkan algoritma pembelajaran mesin yang menerima informasi stok sebagai input. Kemudian, membagi saham menjadi dua kategori: saham yang harus Anda jual dan saham yang harus Anda simpan.
Regresi logistik adalah algoritma yang Anda gunakan untuk klasifikasi. API regresi logistik Spark berguna untuk klasifikasi biner, atau mengklasifikasikan data input ke dalam salah satu dari dua grup. Untuk informasi selengkapnya tentang regresi logistik, lihat Wikipedia.
Singkatnya, proses regresi logistik menghasilkan fungsi logistik. Menggunakan fungsi untuk memprediksi peluang bahwa vektor input termasuk dalam satu grup atau yang lain.
Contoh analisis prediktif data inspeksi makanan
Dalam contoh ini, Anda menggunakan Spark untuk melakukan beberapa analisis prediktif pada data inspeksi makanan (Food_Inspections1.csv). Data diperoleh melalui portal data Kota Chicago. Himpunan data ini berisi informasi tentang inspeksi perusahaan makanan yang dilakukan di Chicago. Termasuk informasi tentang setiap pendirian, pelanggaran yang ditemukan (jika ada), dan hasil pemeriksaan. File data CSV sudah tersedia di akun penyimpanan yang terkait dengan kluster di /HdiSamples/HdiSamples/FoodInspectionData/Food_Inspections1.csv.
Dalam langkah-langkah berikut, Anda mengembangkan model untuk melihat apa yang diperlukan untuk lulus atau gagal pemeriksaan makanan.
Membuat aplikasi pembelajaran mesin Apache Spark MLlib
Buat Jupyter Notebook menggunakan kernel PySpark. Untuk instruksinya, lihat Membuat file Jupyter Notebook.
Mengimpor jenis yang diperlukan untuk aplikasi ini. Menyalin dan Menempelkan kode berikut dalam sel kosong, dan kemudian tekan SHIFT + ENTER.
from pyspark.ml import Pipeline from pyspark.ml.classification import LogisticRegression from pyspark.ml.feature import HashingTF, Tokenizer from pyspark.sql import Row from pyspark.sql.functions import UserDefinedFunction from pyspark.sql.types import *Karena kernel PySpark, Anda tidak perlu membuat konteks apa pun secara eksplisit. Konteks Spark dan Apache Hive secara otomatis dibuat saat Anda menjalankan sel kode pertama.
Menyusun dataframe input
Menggunakan konteks Spark untuk menarik data CSV mentah ke dalam memori sebagai teks yang tidak terstruktur. Kemudian, gunakan pustaka CSV Python untuk mengurai setiap baris data.
Menjalankan baris berikut untuk membuat Himpunan data Terdistribusi Tangguh (RDD) dengan mengimpor dan mengurai data input.
def csvParse(s): import csv from io import StringIO sio = StringIO(s) value = next(csv.reader(sio)) sio.close() return value inspections = sc.textFile('/HdiSamples/HdiSamples/FoodInspectionData/Food_Inspections1.csv')\ .map(csvParse)Menjalankan kode berikut untuk mengambil satu baris dari RDD, sehingga Anda bisa melihat skema data:
inspections.take(1)Outputnya adalah:
[['413707', 'LUNA PARK INC', 'LUNA PARK DAY CARE', '2049789', "Children's Services Facility", 'Risk 1 (High)', '3250 W FOSTER AVE ', 'CHICAGO', 'IL', '60625', '09/21/2010', 'License-Task Force', 'Fail', '24. DISH WASHING FACILITIES: PROPERLY DESIGNED, CONSTRUCTED, MAINTAINED, INSTALLED, LOCATED AND OPERATED - Comments: All dishwashing machines must be of a type that complies with all requirements of the plumbing section of the Municipal Code of Chicago and Rules and Regulation of the Board of Health. OBSEVERD THE 3 COMPARTMENT SINK BACKING UP INTO THE 1ST AND 2ND COMPARTMENT WITH CLEAR WATER AND SLOWLY DRAINING OUT. INST NEED HAVE IT REPAIR. CITATION ISSUED, SERIOUS VIOLATION 7-38-030 H000062369-10 COURT DATE 10-28-10 TIME 1 P.M. ROOM 107 400 W. SURPERIOR. | 36. LIGHTING: REQUIRED MINIMUM FOOT-CANDLES OF LIGHT PROVIDED, FIXTURES SHIELDED - Comments: Shielding to protect against broken glass falling into food shall be provided for all artificial lighting sources in preparation, service, and display facilities. LIGHT SHIELD ARE MISSING UNDER HOOD OF COOKING EQUIPMENT AND NEED TO REPLACE LIGHT UNDER UNIT. 4 LIGHTS ARE OUT IN THE REAR CHILDREN AREA,IN THE KINDERGARDEN CLASS ROOM. 2 LIGHT ARE OUT EAST REAR, LIGHT FRONT WEST ROOM. NEED TO REPLACE ALL LIGHT THAT ARE NOT WORKING. | 35. WALLS, CEILINGS, ATTACHED EQUIPMENT CONSTRUCTED PER CODE: GOOD REPAIR, SURFACES CLEAN AND DUST-LESS CLEANING METHODS - Comments: The walls and ceilings shall be in good repair and easily cleaned. MISSING CEILING TILES WITH STAINS IN WEST,EAST, IN FRONT AREA WEST, AND BY THE 15MOS AREA. NEED TO BE REPLACED. | 32. FOOD AND NON-FOOD CONTACT SURFACES PROPERLY DESIGNED, CONSTRUCTED AND MAINTAINED - Comments: All food and non-food contact equipment and utensils shall be smooth, easily cleanable, and durable, and shall be in good repair. SPLASH GUARDED ARE NEEDED BY THE EXPOSED HAND SINK IN THE KITCHEN AREA | 34. FLOORS: CONSTRUCTED PER CODE, CLEANED, GOOD REPAIR, COVING INSTALLED, DUST-LESS CLEANING METHODS USED - Comments: The floors shall be constructed per code, be smooth and easily cleaned, and be kept clean and in good repair. INST NEED TO ELEVATE ALL FOOD ITEMS 6INCH OFF THE FLOOR 6 INCH AWAY FORM WALL. ', '41.97583445690982', '-87.7107455232781', '(41.97583445690982, -87.7107455232781)']]Output memberi Anda ide tentang skema file input. Hal ini termasuk nama setiap pendirian, dan jenis pendirian. Juga, alamat, data pemeriksaan, dan lokasi, antara lain.
Menjalankan kode berikut untuk membuat dataframe (df) dan tabel sementara (CountResults) dengan beberapa kolom yang berguna untuk analisis prediktif.
sqlContextdigunakan untuk melakukan transformasi pada data terstruktur.schema = StructType([ StructField("id", IntegerType(), False), StructField("name", StringType(), False), StructField("results", StringType(), False), StructField("violations", StringType(), True)]) df = spark.createDataFrame(inspections.map(lambda l: (int(l[0]), l[1], l[12], l[13])) , schema) df.registerTempTable('CountResults')Empat kolom yang menarik dalam dataframe adalah ID, nama, hasil, dan pelanggaran.
Menjalankan kode berikut untuk mendapatkan sampel kecil data:
df.show(5)Outputnya adalah:
+------+--------------------+-------+--------------------+ | id| name|results| violations| +------+--------------------+-------+--------------------+ |413707| LUNA PARK INC| Fail|24. DISH WASHING ...| |391234| CAFE SELMARIE| Fail|2. FACILITIES TO ...| |413751| MANCHU WOK| Pass|33. FOOD AND NON-...| |413708|BENCHMARK HOSPITA...| Pass| | |413722| JJ BURGER| Pass| | +------+--------------------+-------+--------------------+
Memahami data
Mari kita mulai merasakan apa yang berisi himpunan data.
Menjalankan kode berikut untuk memperlihatkan nilai berbeda di kolom hasil:
df.select('results').distinct().show()Outputnya adalah:
+--------------------+ | results| +--------------------+ | Fail| |Business Not Located| | Pass| | Pass w/ Conditions| | Out of Business| +--------------------+Menjalankan kode berikut untuk memvisualisasikan distribusi hasil ini:
%%sql -o countResultsdf SELECT COUNT(results) AS cnt, results FROM CountResults GROUP BY results%%sqlSihir diikuti dengan-o countResultsdfmemastikan bahwa output kueri ditempelkan secara lokal di server Jupyter (biasanya headnode kluster). Outputnya tetap sebagai dataframe Pandas dengan nama yang ditentukan countResultsdf. Untuk informasi selengkapnya tentang%%sqlsihir, dan sihir lain yang tersedia dengan kernel PySpark, lihat Kernel yang tersedia di Jupyter Notebooks dengan kluster Apache Spark Microsoft Azure HDInsight.Outputnya adalah:
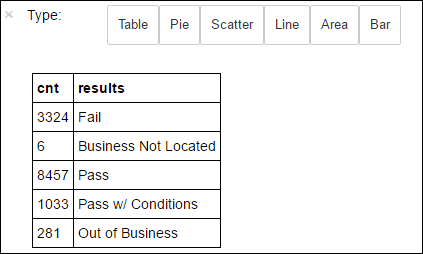
Anda juga dapat menggunakan Matplotlib, pustaka yang digunakan untuk membangun visualisasi data, untuk membuat plot. Karena plot harus dibuat dari dataframe countResultsdf yang bertahan secara lokal, cuplikan kode harus dimulai dengan
%%localsihir. Tindakan ini memastikan bahwa kode dijalankan secara lokal di server Jupyter.%%local %matplotlib inline import matplotlib.pyplot as plt labels = countResultsdf['results'] sizes = countResultsdf['cnt'] colors = ['turquoise', 'seagreen', 'mediumslateblue', 'palegreen', 'coral'] plt.pie(sizes, labels=labels, autopct='%1.1f%%', colors=colors) plt.axis('equal')Untuk memprediksi hasil inspeksi makanan, Anda perlu mengembangkan model berdasarkan pelanggaran. Karena regresi logistik adalah metode klasifikasi biner, ini masuk akal untuk mengelompokkan data hasil ke dalam dua kategori: Gagal dan Lulus:
Lulus
- Lulus
- Lulus dengan catatan
Gagal
- Gagal
Membuang
- Bisnis tidak ditemukan
- Kehabisan Bisnis
Data dengan hasil lain ("Bisnis Tidak Ditemukan" atau "Bisnis Gulung Tikar") tidak berguna, dan mereka tetap membuat persentase kecil dari hasilnya.
Menjalankan kode berikut untuk mengonversi dataframe(
df) yang ada menjadi dataframe baru di mana setiap inspeksi direpresentasikan sebagai pasangan pelanggaran label. Dalam hal ini, label0.0mewakili kegagalan, label1.0mewakili keberhasilan, dan label-1.0mewakili beberapa hasil selain dua hasil tersebut.def labelForResults(s): if s == 'Fail': return 0.0 elif s == 'Pass w/ Conditions' or s == 'Pass': return 1.0 else: return -1.0 label = UserDefinedFunction(labelForResults, DoubleType()) labeledData = df.select(label(df.results).alias('label'), df.violations).where('label >= 0')Menjalankan kode berikut untuk memperlihatkan satu baris data berlabel:
labeledData.take(1)Outputnya adalah:
[Row(label=0.0, violations=u"41. PREMISES MAINTAINED FREE OF LITTER, UNNECESSARY ARTICLES, CLEANING EQUIPMENT PROPERLY STORED - Comments: All parts of the food establishment and all parts of the property used in connection with the operation of the establishment shall be kept neat and clean and should not produce any offensive odors. REMOVE MATTRESS FROM SMALL DUMPSTER. | 35. WALLS, CEILINGS, ATTACHED EQUIPMENT CONSTRUCTED PER CODE: GOOD REPAIR, SURFACES CLEAN AND DUST-LESS CLEANING METHODS - Comments: The walls and ceilings shall be in good repair and easily cleaned. REPAIR MISALIGNED DOORS AND DOOR NEAR ELEVATOR. DETAIL CLEAN BLACK MOLD LIKE SUBSTANCE FROM WALLS BY BOTH DISH MACHINES. REPAIR OR REMOVE BASEBOARD UNDER DISH MACHINE (LEFT REAR KITCHEN). SEAL ALL GAPS. REPLACE MILK CRATES USED IN WALK IN COOLERS AND STORAGE AREAS WITH PROPER SHELVING AT LEAST 6' OFF THE FLOOR. | 38. VENTILATION: ROOMS AND EQUIPMENT VENTED AS REQUIRED: PLUMBING: INSTALLED AND MAINTAINED - Comments: The flow of air discharged from kitchen fans shall always be through a duct to a point above the roofline. REPAIR BROKEN VENTILATION IN MEN'S AND WOMEN'S WASHROOMS NEXT TO DINING AREA. | 32. FOOD AND NON-FOOD CONTACT SURFACES PROPERLY DESIGNED, CONSTRUCTED AND MAINTAINED - Comments: All food and non-food contact equipment and utensils shall be smooth, easily cleanable, and durable, and shall be in good repair. REPAIR DAMAGED PLUG ON LEFT SIDE OF 2 COMPARTMENT SINK. REPAIR SELF CLOSER ON BOTTOM LEFT DOOR OF 4 DOOR PREP UNIT NEXT TO OFFICE.")]
Membuat model regresi logistik dari dataframe input
Tugas akhir adalah untuk mengonversi data berlabel. Konversikan data menjadi format yang dianalisis oleh regresi logistik. Input ke algoritma regresi logistik membutuhkan set pasangan vektor fitur label. Di mana "vektor fitur" adalah vektor angka yang mewakili titik input. Jadi, Anda perlu mengonversi kolom "pelanggaran", yang semi terstruktur dan berisi banyak komentar dalam teks bebas. Mengonversi kolom menjadi larik angka riil yang dapat dipahami oleh mesin dengan mudah.
Salah satu pendekatan pembelajaran mesin standar untuk memproses bahasa alami adalah menetapkan setiap kata yang berbeda indeks. Kemudian, berikan vektor ke algoritma pembelajaran mesin. Sedemikian rupa sehingga setiap nilai indeks berisi frekuensi relatif kata tersebut dalam untai(karakter) teks.
MLlib menyediakan cara mudah untuk melakukan operasi ini. Pertama, "tokenize" setiap pelanggaran string untuk mendapatkan kata-kata individual di setiap string. Kemudian, gunakan HashingTF untuk mengonversi setiap himpunan token menjadi vektor fitur yang kemudian dapat diteruskan ke algoritma regresi logistik untuk membangun model. Anda melakukan semua langkah ini secara berurutan menggunakan alur.
tokenizer = Tokenizer(inputCol="violations", outputCol="words")
hashingTF = HashingTF(inputCol=tokenizer.getOutputCol(), outputCol="features")
lr = LogisticRegression(maxIter=10, regParam=0.01)
pipeline = Pipeline(stages=[tokenizer, hashingTF, lr])
model = pipeline.fit(labeledData)
Evaluasi model penggunaan set data lain
Anda dapat menggunakan model yang Anda buat sebelumnya untuk memprediksi hasil inspeksi baru. Prediksi tersebut didasarkan pada pelanggaran yang diamati. Anda melatih model ini pada himpunan data Food_Inspections1.csv. Anda dapat menggunakan himpunan data kedua, Food_Inspections2.csv, untuk mengevaluasi kekuatan model ini pada data baru. Himpunan data kedua ini (Food_Inspections2.csv) berada dalam wadah penyimpanan default yang terkait dengan kluster.
Menjalankan kode berikut untuk membuat dataframe baru, predictionsDf yang berisi prediksi yang dihasilkan oleh model. Cuplikan juga membuat tabel sementara yang disebut Prediksi berdasarkan dataframe.
testData = sc.textFile('wasbs:///HdiSamples/HdiSamples/FoodInspectionData/Food_Inspections2.csv')\ .map(csvParse) \ .map(lambda l: (int(l[0]), l[1], l[12], l[13])) testDf = spark.createDataFrame(testData, schema).where("results = 'Fail' OR results = 'Pass' OR results = 'Pass w/ Conditions'") predictionsDf = model.transform(testDf) predictionsDf.registerTempTable('Predictions') predictionsDf.columnsAnda akan melihat output seperti contoh di bawah ini:
['id', 'name', 'results', 'violations', 'words', 'features', 'rawPrediction', 'probability', 'prediction']Lihatlah salah satu prediksi. Menjalankan cuplikan ini:
predictionsDf.take(1)Terdapat prediksi untuk entri pertama dalam himpunan data uji.
model.transform()Metode ini menerapkan transformasi yang sama ke data baru dengan skema yang sama, dan sampai pada prediksi cara mengklasifikasikan data. Anda dapat melakukan beberapa statistik untuk merasakan bagaimana prediksi itu:numSuccesses = predictionsDf.where("""(prediction = 0 AND results = 'Fail') OR (prediction = 1 AND (results = 'Pass' OR results = 'Pass w/ Conditions'))""").count() numInspections = predictionsDf.count() print ("There were", numInspections, "inspections and there were", numSuccesses, "successful predictions") print ("This is a", str((float(numSuccesses) / float(numInspections)) * 100) + "%", "success rate")Hasilnya akan terlihat seperti teks berikut:
There were 9315 inspections and there were 8087 successful predictions This is a 86.8169618894% success ratePenggunaan regresi logistik dengan Spark memberi Anda model hubungan antara deskripsi pelanggaran dalam bahasa Inggris. Dan apakah bisnis tertentu akan lulus atau gagal inspeksi makanan.
Membuat representasi visual dari prediksi
Anda sekarang dapat membangun visualisasi akhir untuk membantu Anda beralasan tentang hasil uji ini.
Anda mulai dengan mengekstrak prediksi dan hasil yang berbeda dari tabel Prediksi sementara yang dibuat sebelumnya. Kueri berikut memisahkan output sebagai true_positive, false_positive, true_negative, dan false_negative. Dalam kueri di bawah ini, Anda mematikan visualisasi dengan menggunakan
-qdan juga menyimpan output (dengan menggunakan-o) sebagai dataframe yang kemudian dapat digunakan dengan%%localsihir.%%sql -q -o true_positive SELECT count(*) AS cnt FROM Predictions WHERE prediction = 0 AND results = 'Fail'%%sql -q -o false_positive SELECT count(*) AS cnt FROM Predictions WHERE prediction = 0 AND (results = 'Pass' OR results = 'Pass w/ Conditions')%%sql -q -o true_negative SELECT count(*) AS cnt FROM Predictions WHERE prediction = 1 AND results = 'Fail'%%sql -q -o false_negative SELECT count(*) AS cnt FROM Predictions WHERE prediction = 1 AND (results = 'Pass' OR results = 'Pass w/ Conditions')Terakhir, gunakan cuplikan berikut untuk menghasilkan plot menggunakan Matplotlib.
%%local %matplotlib inline import matplotlib.pyplot as plt labels = ['True positive', 'False positive', 'True negative', 'False negative'] sizes = [true_positive['cnt'], false_positive['cnt'], false_negative['cnt'], true_negative['cnt']] colors = ['turquoise', 'seagreen', 'mediumslateblue', 'palegreen', 'coral'] plt.pie(sizes, labels=labels, autopct='%1.1f%%', colors=colors) plt.axis('equal')Anda akan menemukan output berikut:
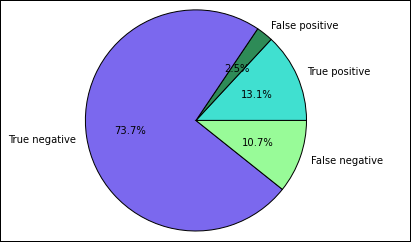
Dalam bagan ini, hasil "positif" mengacu pada inspeksi makanan yang gagal, sementara hasil negatif mengacu pada inspeksi yang dilewatkan.
Mematikan buku catatan
Setelah menjalankan aplikasi, Anda harus mematikan notebook untuk merilis sumber daya. Untuk melakukan rilis ini, dari menu File pada buku catatan, pilih Tutup dan Hentikan. Tindakan ini akan mematikan dan menutup buku catatan.
Langkah berikutnya
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk