Gambaran umum Streaming Terstruktur Spark Apache
Streaming Terstruktur Apache Spark memungkinkan Anda untuk menerapkan aplikasi yang dapat diskalakan, dengan throughput tinggi, dan tahan terhadap kesalahan untuk memproses aliran data. Streaming Terstruktur dibangun di atas mesin Spark SQL, dan konstruksinya meningkat dari Spark SQL Data Frames dan Himpunan data, sehingga Anda dapat menulis kueri streaming dengan cara yang sama untuk menulis kueri batch.
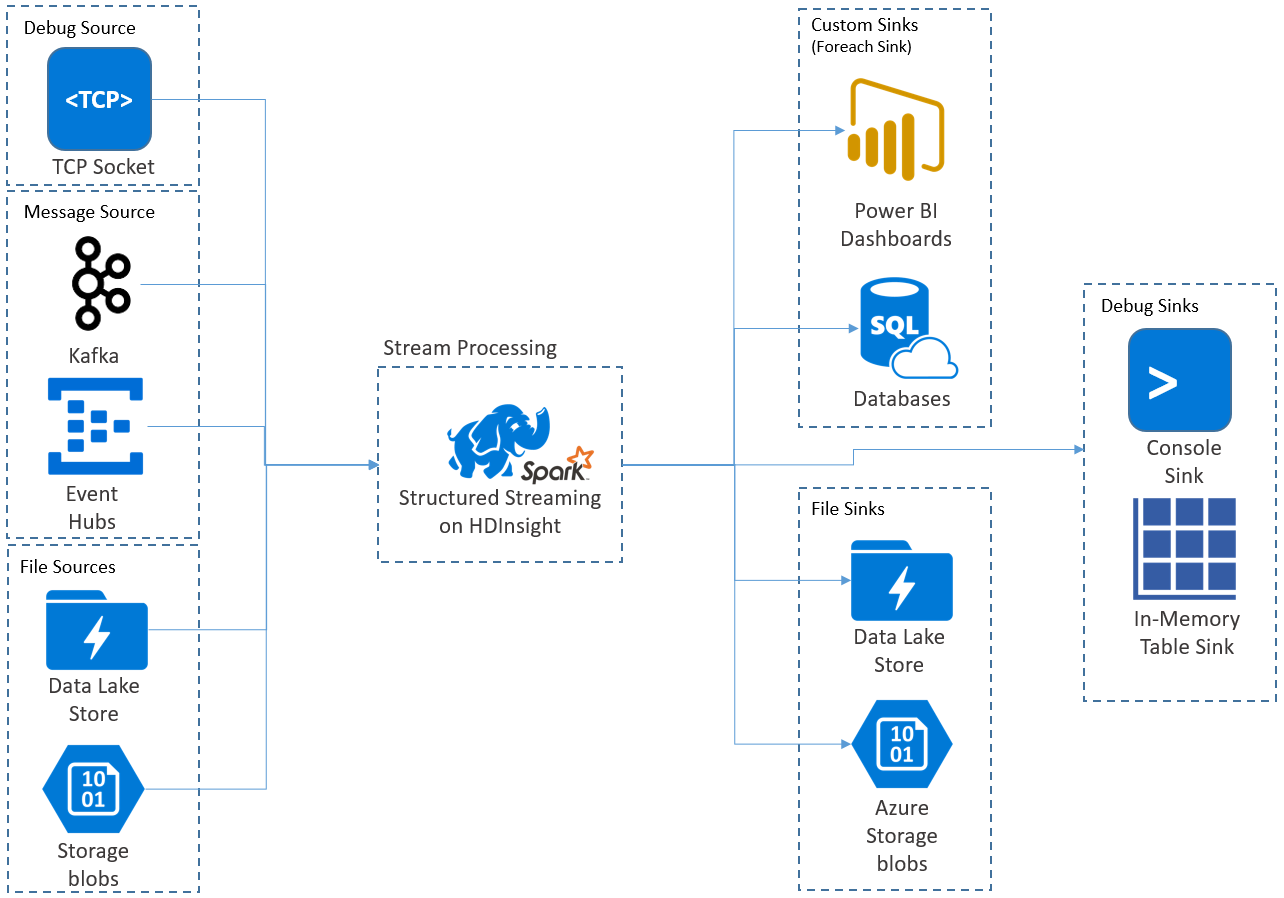
Aplikasi Streaming Terstruktur berjalan pada kluster HDInsight Spark, dan terhubung ke data streaming dari Apache Kafka, soket TCP (untuk tujuan penelusuran kesalahan), Microsoft Azure Storage, atau Azure Data Lake Storage. Dua opsi terakhir, yang bergantung pada layanan penyimpanan eksternal, memungkinkan Anda untuk melihat file baru yang ditambahkan ke penyimpanan dan memproses kontennya seolah-olah mereka di-streaming.
Structured Streaming membuat kueri yang berjalan lama saat Anda menerapkan operasi ke data input, seperti pemilihan, proyeksi, agregasi, jendela, dan bergabung dengan DataFrame streaming dengan DataFrame referensi. Selanjutnya, Anda menghasilkan hasil ke penyimpanan file (Microsoft Azure Storage Blobs atau Azure Data Lake Storage) atau ke datastore mana pun dengan menggunakan kode kustom (seperti Database SQL atau Power BI). Streaming Terstruktur juga menyediakan output ke konsol untuk penelusuran kesalahan secara lokal, dan ke tabel dalam memori sehingga Anda dapat melihat data yang dihasilkan untuk penelusuran kesalahan di Microsoft Azure HDInsight.
Catatan
Streaming Terstruktur Spark menggantikan Streaming Spark (DStreams). Ke depannya, Streaming Terstruktur akan terus menerima peningkatan dan pemeliharaan, sementara DStreams hanya akan berada dalam mode pemeliharaan. Streaming Terstruktur tidak memiliki fitur sebanyak DStreams untuk sumber dan sink yang didukungnya di luar kotak, jadi evaluasi kebutuhan Anda untuk memilih opsi pemrosesan aliran Spark yang sesuai.
Microsoft Stream sebagai tabel
Streaming Terstruktur Spark mewakili aliran data sebagai tabel yang tidak terbatas kedalamannya, yaitu tabel terus bertambah saat data baru datang. Tabel input ini terus diproses oleh kueri yang berjalan lama, dan hasilnya dikirim ke tabel output:

Pada Streaming Terstruktur, data tiba di sistem dan segera diserap ke dalam tabel input. Anda menulis kueri (menggunakan API DataFrame dan Himpunan data) yang melakukan operasi terhadap tabel input ini. Output kueri menghasilkan tabel lain, yaitu tabel hasil. Tabel hasil berisi hasil kueri Anda, dari mana Anda menggambar data untuk penyimpanan data eksternal, database relasional seperti itu. Pewaktuan saat data diproses dari tabel input dikontrol oleh interval pemicu. Secara default, interval pemicu adalah nol, jadi Streaming Terstruktur mencoba memproses data segera setelah tiba. Dalam praktiknya, Hal ini berarti bahwa segera setelah Streaming Terstruktur selesai memproses jalannya kueri sebelumnya, akan memulai pemrosesan lain yang dijalankan terhadap data yang baru diterima. Anda dapat mengonfigurasi pemicu untuk berjalan pada interval, sehingga data streaming diproses dalam batch berbasis waktu.
Data dalam tabel hasil mungkin hanya berisi data yang baru sejak terakhir kali kueri diproses (mode penambahan), atau tabel dapat direfresh setiap kali ada data baru sehingga tabel menyertakan semua data output sejak kueri streaming dimulai (mode lengkap).
Mode penambahan
Dalam mode penambahan, hanya baris yang ditambahkan ke tabel hasil karena kueri terakhir yang dijalankan ada dalam tabel hasil dan ditulis ke penyimpanan eksternal. Misalnya, kueri paling sederhana hanya menyalin semua data dari tabel input ke tabel hasil yang tidak diubah. Setiap kali interval pemicu berlalu, data baru diproses dan baris yang menunjukkan bahwa data baru muncul dalam tabel hasil.
Pertimbangkan skenario ketika Anda memproses telemetri dari sensor suhu, seperti termostat. Asumsikan pemicu pertama diproses satu peristiwa pada saat 00.01 untuk perangkat 1 dengan pembacaan suhu 95 derajat. Di pemicu pertama kueri, hanya baris dengan waktu 00.01 yang muncul dalam tabel hasil. Pada waktu 00.02 ketika peristiwa lain terjadi, satu-satunya baris baru adalah baris dengan waktu 00.02 dan tabel hasil hanya akan berisi satu baris.
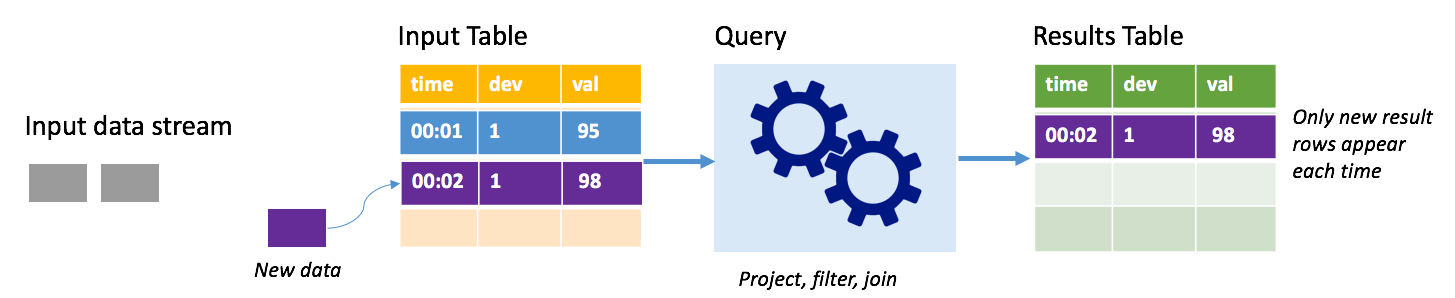
Saat menggunakan mode tambahkan, kueri Anda akan menerapkan proyeksi (memilih kolom yang menjadi perhatiannya), pemfilteran (hanya memilih baris yang cocok dengan kondisi tertentu) atau bergabung (menambah data dengan data dari tabel pencarian statis). Mode penambahan memberikan kemudahan untuk mendorong hanya poin data baru yang relevan ke penyimpanan eksternal.
Mode lengkap
Pertimbangkan skenario yang sama, kali ini menggunakan mode lengkap. Dalam mode lengkap, seluruh tabel output direfresh pada setiap pemicu sehingga tabel menyertakan data tidak hanya dari jalankan pemicu terbaru, tetapi dari semua jalankan. Anda dapat menggunakan mode lengkap untuk menyalin data yang tidak dialirkan dari tabel input ke tabel hasil. Pada setiap eksekusi yang dipicu, baris hasil baru muncul bersama dengan semua baris sebelumnya. Tabel hasil output akan menyimpan semua data yang dikumpulkan sejak kueri dimulai, dan Anda akan kehabisan memori pada akhirnya. Mode lengkap dimaksudkan untuk digunakan dengan kueri agregat yang meringkas data masuk dalam beberapa cara, jadi pada setiap pemicu tabel hasil diperbarui dengan ringkasan baru.
Asumsikan sejauh ini ada data senilai lima detik yang sudah diproses, dan saatnya untuk memproses data untuk detik keenam. Tabel input memiliki peristiwa untuk waktu 00.01 dan waktu 00.03. Tujuan dari contoh kueri ini adalah untuk memberikan suhu rata-rata perangkat setiap lima detik. Implementasi kueri ini menerapkan agregat yang mengambil semua nilai yang termasuk dalam setiap jeda 5 detik, rata-rata suhu, dan menghasilkan baris untuk suhu rata-rata selama interval tersebut. Pada akhir jendela 5 detik pertama, ada dua tuple: (00.01, 1, 95) dan (00.03, 1, 98). Jadi untuk jeda 00:00-00:05, agregasi menghasilkan tupel dengan suhu rata-rata 96,5 derajat. Pada jeda 5 detik berikutnya, hanya ada satu poin data pada waktu 00:06, sehingga suhu rata-rata yang dihasilkan adalah 98 derajat. Pada waktu 00:10, menggunakan mode lengkap, tabel hasil memiliki baris untuk kedua jendela 00:00-00:05 dan 00:05-00:10 karena kueri mengeluarkan semua baris agregat, bukan hanya yang baru. Oleh karena itu, tabel hasil terus tumbuh saat jendela baru ditambahkan.
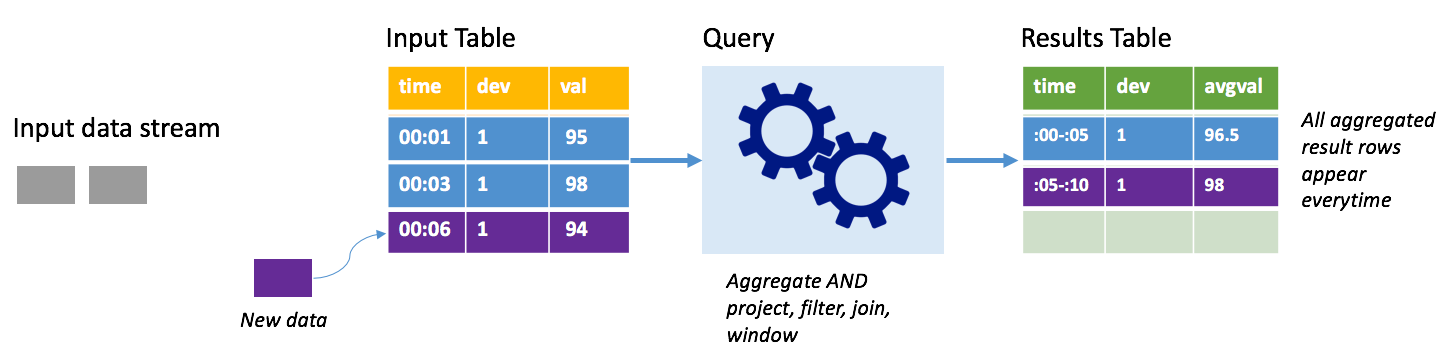
Tidak semua kueri yang menggunakan mode lengkap akan menyebabkan penambahan tabel tanpa batas. Pertimbangkan dalam contoh sebelumnya bahwa daripada rata-rata suhu menurut jendela waktu, hal tersebut rata-rata sebagai gantinya oleh ID perangkat. Tabel hasil berisi jumlah baris tetap (satu per perangkat) dengan suhu rata-rata untuk perangkat di semua poin data yang diterima dari perangkat tersebut. Saat suhu baru diterima, tabel hasil diperbarui sehingga rata-rata dalam tabel selalu terkini.
Komponen aplikasi Streaming Terstruktur Spark
Contoh kueri sederhana dapat meringkas pembacaan suhu dengan jendela selama satu jam. Dalam hal ini, data disimpan dalam file JSON di Azure Storage (terlampir sebagai penyimpanan default untuk kluster HDInsight):
{"time":1469501107,"temp":"95"}
{"time":1469501147,"temp":"95"}
{"time":1469501202,"temp":"95"}
{"time":1469501219,"temp":"95"}
{"time":1469501225,"temp":"95"}
File JSON ini disimpan dalam subfolder temps di bawah kontainer kluster Microsoft Azure HDInsight.
Tentukan sumber input
Pertama-tama, konfigurasikan DataFrame yang menjelaskan sumber data dan pengaturan apa pun yang diperlukan oleh sumber tersebut. Contoh ini diambil dari file JavaScript Object Notation di Microsoft Azure Storage dan menerapkan skema kepada mereka pada waktu baca.
import org.apache.spark.sql.types._
import org.apache.spark.sql.functions._
//Cluster-local path to the folder containing the JSON files
val inputPath = "/temps/"
//Define the schema of the JSON files as having the "time" of type TimeStamp and the "temp" field of type String
val jsonSchema = new StructType().add("time", TimestampType).add("temp", StringType)
//Create a Streaming DataFrame by calling readStream and configuring it with the schema and path
val streamingInputDF = spark.readStream.schema(jsonSchema).json(inputPath)
Menerapkan kueri
Selanjutnya, terapkan kueri yang berisi operasi yang diinginkan terhadap DataFrame Streaming. Dalam hal ini, agregasi mengelompokkan semua baris ke dalam jendela 1 jam, lalu menghitung suhu minimum, rata-rata, dan maksimum di jendela 1 jam itu.
val streamingAggDF = streamingInputDF.groupBy(window($"time", "1 hour")).agg(min($"temp"), avg($"temp"), max($"temp"))
Menentukan sink output
Berikutnya, tentukan tujuan untuk baris yang ditambahkan ke tabel hasil dalam setiap interval pemicu. Contoh ini hanya menghasilkan semua baris ke tabel temps dalam memori yang nantinya dapat Anda kueri dengan SparkSQL. Mode output lengkap memastikan bahwa semua baris untuk semua jeda adalah output setiap saat.
val streamingOutDF = streamingAggDF.writeStream.format("memory").queryName("temps").outputMode("complete")
Memulai kueri
Mulai aplikasi streaming dan jalankan sampai sinyal penghentian diterima.
val query = streamingOutDF.start()
Lihat hasilnya
Saat kueri sedang berjalan, dalam SparkSession yang sama, Anda bisa menjalankan kueri SparkSQL terhadap temps tabel tempat hasil kueri disimpan.
select * from temps
Kueri ini menghasilkan hasil yang mirip dengan yang berikut ini:
| window | min(temp) | avg(temp) | max(temp) |
|---|---|---|---|
| {u'start': u'2016-07-26T02:00:00.000Z', u'end'... | 95 | 95.231579 | 99 |
| {u'start': u'2016-07-26T03:00:00.000Z', u'end'... | 95 | 96.023048 | 99 |
| {u'start': u'2016-07-26T04:00:00.000Z', u'end'... | 95 | 96.797133 | 99 |
| {u'start': u'2016-07-26T05:00:00.000Z', u'end'... | 95 | 96.984639 | 99 |
| {u'start': u'2016-07-26T06:00:00.000Z', u'end'... | 95 | 97.014749 | 99 |
| {u'start': u'2016-07-26T07:00:00.000Z', u'end'... | 95 | 96.980971 | 99 |
| {u'start': u'2016-07-26T08:00:00.000Z', u'end'... | 95 | 96.965997 | 99 |
Untuk detail tentang Stream terstruktur Spark API, bersama dengan sumber data input, operasi, dan output yang didukungnya, lihat Panduan Pemrograman Streaming Terstruktur Apache Spark.
Titik pemeriksaan dan log tulis-depan
Untuk memberikan ketangguhan dan toleransi kesalahan, Streaming Terstruktur Spark mengandalkan titik pemeriksaan untuk memastikan bahwa pemrosesan streaming dapat berlanjut tanpa gangguan, bahkan saat menghadapi kegagalan simpul. Di Microsoft Azure HDInsight, Spark membuat pos pemeriksaan ke penyimpanan yang tahan lama, baik Microsoft Azure Storage atau Azure Data Lake Storage. Titik pemeriksaan ini menyimpan informasi kemajuan tentang kueri streaming. Selain itu, Streaming Terstruktur menggunakan write-ahead log (WAL). WAL menangkap data yang terserap, yang telah diterima tetapi belum diproses oleh kueri. Jika kegagalan terjadi dan pemrosesan dimulai ulang dari WAL, setiap peristiwa yang diterima dari sumber tidak hilang.
Menyebarkan aplikasi Spark Streaming
Biasanya Anda membuat aplikasi Streaming Spark secara lokal ke dalam file JAR, kemudian menyebarkannya ke Spark di HDInsight dengan menyalin file JAR ke penyimpanan default yang melekat pada kluster HDInsight Anda. Anda dapat memulai aplikasi dengan REST API Apache Livy yang tersedia dari kluster Anda menggunakan operasi POST. Isi POST mencakup dokumen JavaScript Object Notation yang menyediakan jalur ke JAR Anda, nama kelas yang metode utamanya mendefinisikan dan menjalankan aplikasi streaming, dan secara opsional persyaratan sumber daya pekerjaan (seperti jumlah pelaksana, memori dan inti), dan pengaturan konfigurasi apa pun yang diperlukan kode aplikasi Anda.
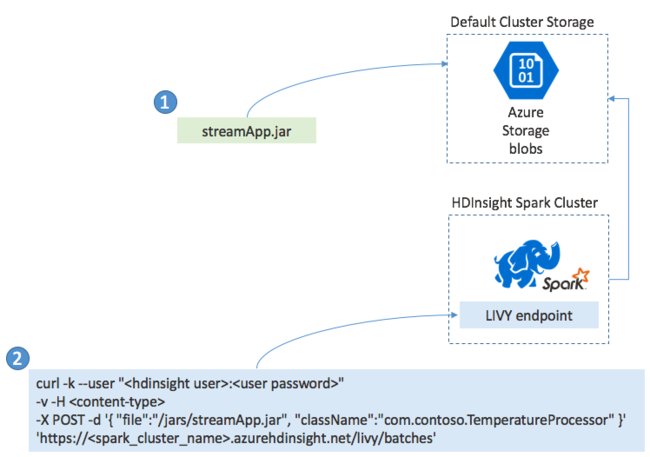
Status semua aplikasi juga dapat diperiksa dengan permintaan GET terhadap titik akhir LIVY. Akhirnya, Anda dapat mengakhiri aplikasi yang sedang berjalan dengan mengeluarkan permintaan HAPUS terhadap titik akhir LIVY. Untuk perincian tentang API LIVY, lihat Pekerjaan jarak jauh dengan Apache LIVY
Langkah berikutnya
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk