Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Pelajari cara menggunakan Apache Pig dengan Microsoft Azure HDInsight.
Apache Pig adalah platform untuk membuat program untuk Apache Hadoop dengan menggunakan bahasa prosedural yang dikenal sebagai Pig Latin. Pig adalah alternatif untuk Java untuk membuat solusi MapReduce , dan disertakan dengan Azure HDInsight. Gunakan tabel berikut untuk menemukan berbagai cara agar Pig dapat digunakan dengan Microsoft Azure HDInsight:
Mengapa menggunakan Apache Pig
Salah satu tantangan pemrosesan data dengan menggunakan MapReduce di Hadoop adalah menerapkan logika pemrosesan Anda hanya dengan menggunakan peta dan fungsi pengurangan. Untuk pemrosesan yang kompleks, Anda sering harus memecah pemrosesan ke beberapa operasi MapReduce yang dirantai bersama untuk mencapai hasil yang diinginkan.
Pig memungkinkan Anda untuk mendefinisikan pemrosesan sebagai serangkaian transformasi yang aliran datanya untuk menghasilkan output yang diinginkan.
Bahasa Pig Latin memungkinkan Anda untuk menggambarkan aliran data dari input mentah, melalui satu atau lebih transformasi, untuk menghasilkan output yang diinginkan. Program Pig Latin mengikuti pola umum ini:
Muat: Baca data yang akan dimanipulasi dari sistem file.
Transformasi: Manipulasikan data.
Buang atau simpan: Keluarkan data ke layar atau simpan untuk diproses.
Fungsi yang ditentukan pengguna
Pig Latin juga mendukung fungsi yang ditentukan pengguna (UDF), yang memungkinkan Anda untuk memanggil komponen eksternal yang menerapkan logika yang sulit dimodelkan dalam Pig Latin.
Untuk informasi selengkapnya tentang Pig Latin, lihat Referensi Manual Pig Latin 1 dan Referensi Manual Pig Latin 2.
Contoh data
Microsoft Azure HDInsight menyediakan berbagai contoh himpunan data, yang disimpan di direktori /example/data dan /HdiSamples. Direktori ini berada di penyimpanan default untuk kluster Anda. Contoh Pig dalam dokumen ini menggunakan file Log4j dari /example/data/sample.log.
Setiap log di dalam file terdiri dari baris bidang yang berisi [LOG LEVEL] bidang untuk memperlihatkan jenis dan tingkat keparahan, misalnya:
2012-02-03 20:26:41 SampleClass3 [ERROR] verbose detail for id 1527353937
Dalam contoh sebelumnya, tingkat log adalah ERROR.
Catatan
Anda juga dapat membuat file log4j dengan menggunakan alat pengelogan Log4j Apache lalu unggah mengunggah file tersebut ke blob Anda. Lihat Unggah Data ke Microsoft Azure HDInsight untuk petunjuk. Untuk informasi selengkapnya tentang bagaimana blob di penyimpanan Azure digunakan dengan Microsoft Azure HDInsight, lihat Gunakan Azure Blob Storage dengan Microsoft Azure HDInsight.
Contoh pekerjaan
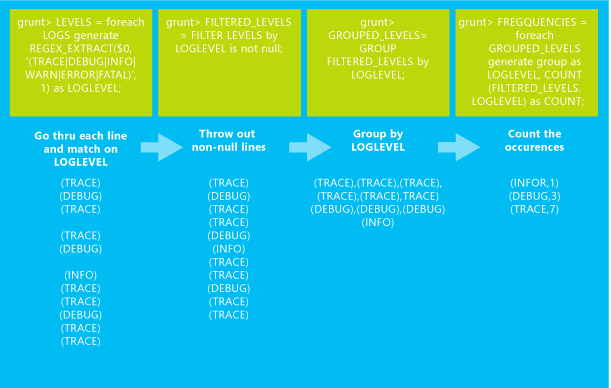
Pekerjaan Pig Latin berikut memuat sample.log file dari penyimpanan default untuk kluster Microsoft Azure HDInsight Anda. Kemudian melakukan serangkaian transformasi yang menghasilkan hitungan berapa kali setiap tingkat log terjadi dalam data input. Hasilnya ditulis ke STDOUT.
LOGS = LOAD 'wasb:///example/data/sample.log';
LEVELS = foreach LOGS generate REGEX_EXTRACT($0, '(TRACE|DEBUG|INFO|WARN|ERROR|FATAL)', 1) as LOGLEVEL;
FILTEREDLEVELS = FILTER LEVELS by LOGLEVEL is not null;
GROUPEDLEVELS = GROUP FILTEREDLEVELS by LOGLEVEL;
FREQUENCIES = foreach GROUPEDLEVELS generate group as LOGLEVEL, COUNT(FILTEREDLEVELS.LOGLEVEL) as COUNT;
RESULT = order FREQUENCIES by COUNT desc;
DUMP RESULT;
Gambar berikut menunjukkan ringkasan apa yang dilakukan setiap transformasi terhadap data.
Jalankan pekerjaan Pig Latin
HDInsight dapat menjalankan pekerjaan Pig Latin dengan menggunakan berbagai metode. Gunakan tabel berikut untuk memutuskan metode yang tepat untuk Anda, kemudian ikuti tautan untuk mendapatkan panduannya.
Pig dan SSIS
Anda dapat menggunakan SQL Server Integration Services (SSIS) untuk menjalankan pekerjaan Pig. Paket Fitur Azure untuk SSIS menyediakan komponen berikut yang bekerja dengan pekerjaan Pig di Microsoft Azure HDInsight.
Pelajari selengkapnya tentang Paket Fitur Azure untuk SSIS di sini.
Langkah berikutnya
Sekarang setelah Anda mempelajari apa itu Apache Hive dan cara menggunakannya dengan Hadoop di Microsoft Azure HDInsight, gunakan tautan berikut untuk menjelajahi cara lain untuk bekerja dengan Azure HDInsight.