Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Artikel ini berfokus pada metode pembelajaran mendalam untuk prakiraan rangkaian waktu di AutoML. Instruksi dan contoh untuk model prakiraan pelatihan di AutoML dapat ditemukan di artikel prakiraan AutoML untuk rangkaian waktu kami.
Pembelajaran mendalam memiliki banyak kasus penggunaan di bidang mulai dari pemodelan bahasa hingga pelipatan protein, di antara banyak lainnya. Prakiraan rangkaian waktu juga mendapat manfaat dari kemajuan terbaru dalam teknologi pembelajaran mendalam. Misalnya, model deep neural network (DNN) memiliki fitur yang menonjol di model berkinerja tinggi dari perulangan keempat dan kelima dari perulangan prakiraan Makridakis profil tinggi.
Dalam artikel ini, kami menjelaskan struktur dan pengoperasian model TCNForecaster di AutoML untuk membantu Anda menerapkan model paling baik ke skenario Anda.
Pengantar TCNForecaster
TCNForecaster adalah jaringan konvolusional temporal, atau TCN, yang memiliki arsitektur DNN yang dirancang untuk data rangkaian waktu. Model ini menggunakan data historis untuk kuantitas target, bersama dengan fitur terkait, untuk membuat prakiraan probabilistik target hingga cakrawala prakiraan tertentu. Gambar berikut menunjukkan komponen utama arsitektur TCNForecaster:
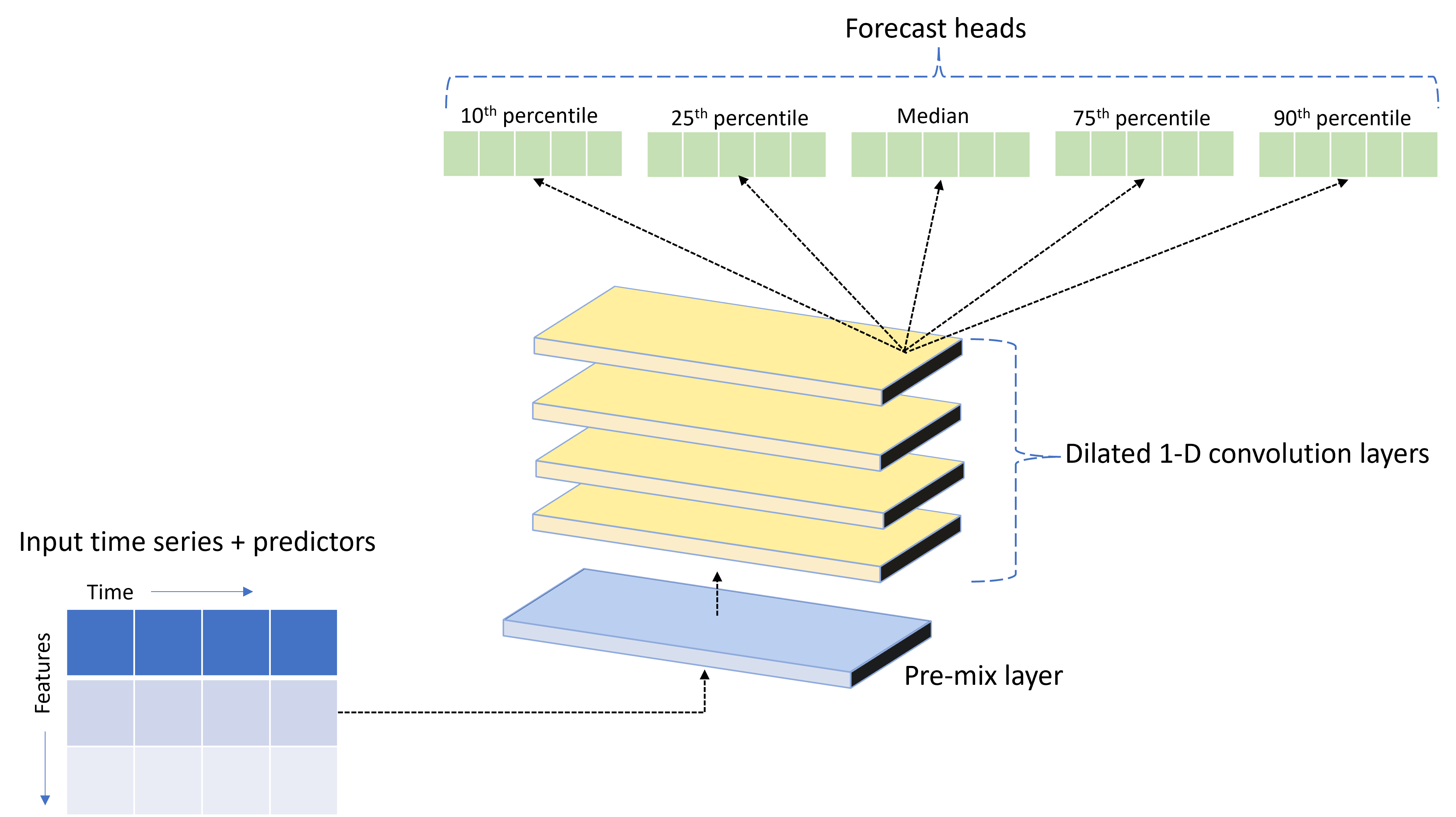
TCNForecaster memiliki komponen utama berikut:
- Lapisan pra-campuran yang mencampur rangkaian waktu input dan data fitur ke dalam array saluran sinyal yang diproses tumpukan konvolusional.
- Tumpukan lapisan konvolusi yang melebar yang memproses array saluran secara berurutan; setiap lapisan dalam tumpukan memproses output lapisan sebelumnya untuk menghasilkan array saluran baru. Setiap saluran dalam output ini berisi campuran sinyal yang difilter konvolusi dari saluran input.
- Kumpulan unit kepala prakiraan yang menyatukan sinyal output dari lapisan konvolusi dan menghasilkan perkiraan kuantitas target dari representasi laten ini. Setiap head unit menghasilkan prakiraan hingga cakrawala untuk kuantil distribusi prediksi.
Konvolusi kausal yang melebar
Operasi pusat TCN adalah konvolusi penyebab yang melebar di sepanjang dimensi waktu sinyal input. Secara intuitif, konvolusi menggabungkan nilai dari titik waktu terdekat dalam input. Proporsi dalam campuran adalah kernel, atau bobot, dari konvolusi sementara pemisahan antara titik-titik dalam campuran adalah pelingkupan. Sinyal output dihasilkan dari input dengan geser kernel tepat waktu di sepanjang input dan mengakumulasi campuran pada setiap posisi. Konvolusi kausal adalah salah satu di mana kernel hanya mencampur nilai input di masa lalu relatif terhadap setiap titik output, mencegah output "melihat" ke masa depan.
Menumpuk konvolusi yang melebar memberi TCN kemampuan untuk memodelkan korelasi selama durasi panjang dalam sinyal input dengan bobot kernel yang relatif sedikit. Misalnya, gambar berikut menunjukkan tiga lapisan bertumpuk dengan kernel dua berat di setiap lapisan dan faktor dilasi yang meningkat secara eksponensial:
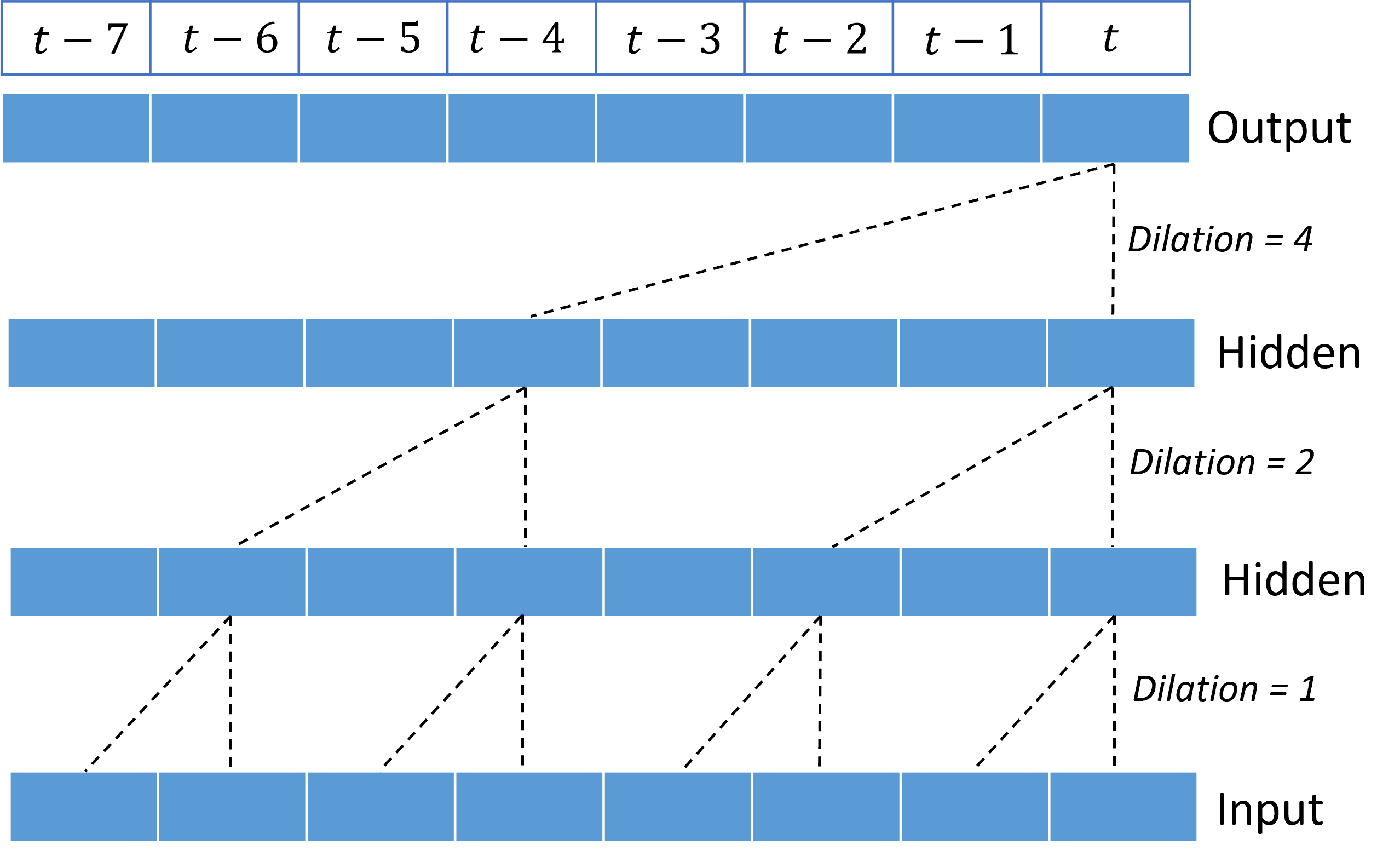
Garis putus-putus menunjukkan jalur melalui jaringan yang berakhir pada output pada satu waktu $t$. Jalur ini mencakup delapan titik terakhir dalam input, menggambarkan bahwa setiap titik output adalah fungsi dari delapan titik yang paling relatif terbaru dalam input. Panjang riwayat, atau "lihat ke belakang", yang digunakan jaringan konvolusional untuk membuat prediksi disebut bidang reseptif dan ditentukan sepenuhnya oleh arsitektur TCN.
Arsitektur TCNForecaster
Inti dari arsitektur TCNForecaster adalah tumpukan lapisan konvolusional antara pra-campuran dan kepala prakiraan. Tumpukan dibagi secara logis menjadi unit berulang yang disebut blok yang, pada gilirannya, terdiri dari sel residu. Sel residu menerapkan konvolusi kausal pada pelokalan yang ditetapkan bersama dengan normalisasi dan aktivasi nonlinear. Yang penting, setiap sel sisa menambahkan outputnya ke inputnya menggunakan apa yang disebut koneksi residu. Koneksi ini telah terbukti menguntungkan pelatihan DNN, mungkin karena memfasilitasi aliran informasi yang lebih efisien melalui jaringan. Gambar berikut menunjukkan arsitektur lapisan konvolusional untuk jaringan contoh dengan dua blok dan tiga sel residu di setiap blok:
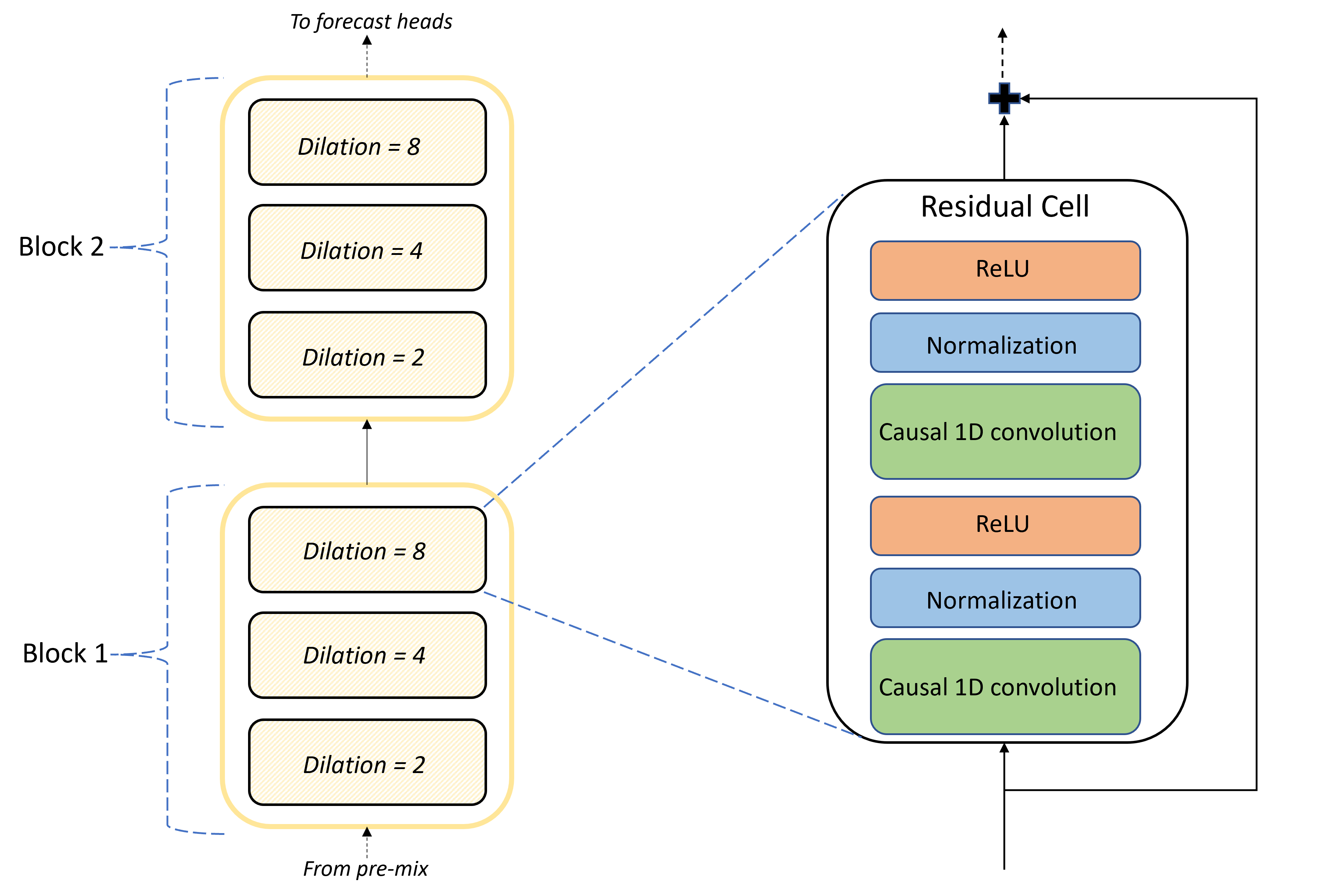
Jumlah blok dan sel, bersama dengan jumlah saluran sinyal di setiap lapisan, mengontrol ukuran jaringan. Parameter arsitektur TCNForecaster dirangkum dalam tabel berikut:
| Pengaturan | Deskripsi |
|---|---|
| $n_{b}$ | Jumlah blok dalam jaringan; juga disebut kedalaman |
| $n_{c}$ | Jumlah sel di setiap blok |
| $n_{\text{ch}}$ | Jumlah saluran dalam lapisan tersembunyi |
Bidang reseptif tergantung pada parameter kedalaman dan diberikan oleh rumus,
$t_{\text{rf}} = 4n_{b}\left(2^{n_{c}} - 1\kanan) + 1,$
Kita dapat memberikan definisi yang lebih tepat tentang arsitektur TCNForecaster dalam hal rumus. Biarkan $X$ menjadi array input di mana setiap baris berisi nilai fitur dari data input. Kita dapat membagi $X$ menjadi array fitur numerik dan kategoris, $X_{\text{num}}$ dan $X_{\text{cat}}$. Kemudian, TCNForecaster diberikan oleh rumus,
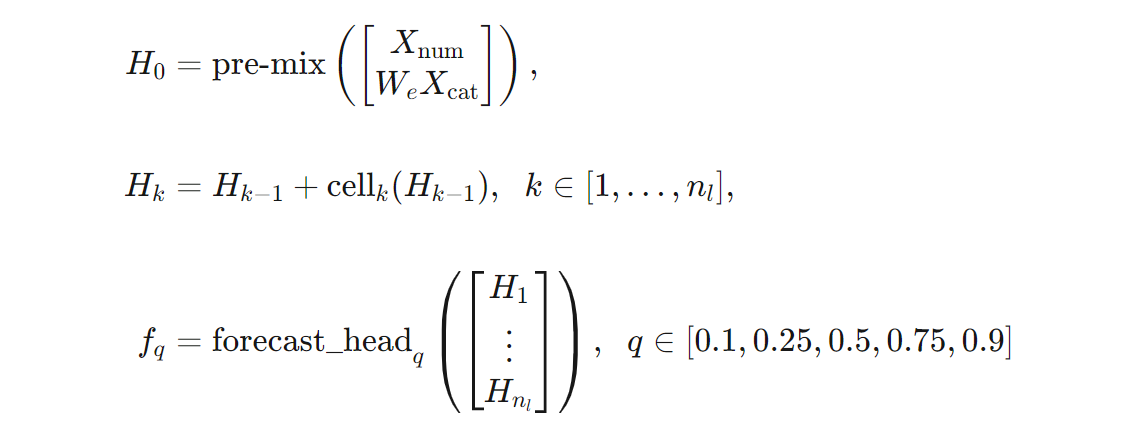
Di mana $W_{e}$ adalah matriks penyematan untuk fitur kategoris, $n_{l} = n_{b}n_{c}$ adalah jumlah total sel residu, $H_{k}$ menunjukkan output lapisan tersembunyi, dan $f_{q}$ adalah output prakiraan untuk kuantil tertentu dari distribusi prediksi. Untuk membantu pemahaman, dimensi variabel ini ada dalam tabel berikut:
| Variabel | Deskripsi | Dimensi |
|---|---|---|
| $X$ | Array input | $n_{\text{input}} \times t_{\text{rf}}$ |
| $H_{i}$ | Output lapisan tersembunyi untuk $i=0,1,\ldots,n_{l}$ | $n_{\text{ch}} \times t_{\text{rf}}$ |
| $f_{q}$ | Output prakiraan untuk kuantil $q$ | $h$ |
Dalam tabel, $n_{\text{input}} = n_{\text{features}} + 1$, jumlah variabel prediktor/fitur ditambah kuantitas target. Kepala prakiraan menghasilkan semua prakiraan hingga cakrawala maksimum, $h$, dalam satu pass, sehingga TCNForecaster adalah prakiraan langsung.
TCNForecaster di AutoML
TCNForecaster adalah model opsional di AutoML. Untuk mempelajari cara menggunakannya, lihat mengaktifkan pembelajaran mendalam.
Di bagian ini, kami menjelaskan bagaimana AutoML membangun model TCNForecaster dengan data Anda, termasuk penjelasan tentang pra-pemrosesan data, pelatihan, dan pencarian model.
Langkah-langkah pra-pemrosesan data
AutoML menjalankan beberapa langkah pra-pemrosesan pada data Anda untuk mempersiapkan pelatihan model. Tabel berikut ini menjelaskan langkah-langkah ini dalam urutan yang dilakukan:
| Langkah | Deskripsi |
|---|---|
| Mengisi data yang hilang | Impute nilai yang hilang dan celah pengamatan dan secara opsional pad atau hilangkan rangkaian waktu pendek |
| Membuat fitur kalender | Menambah data input dengan fitur yang berasal dari kalender seperti hari dalam seminggu dan, secara opsional, hari libur untuk negara/wilayah tertentu. |
| Mengodekan data kategoris | String enkode label dan jenis kategoris lainnya; ini mencakup semua kolom ID rangkaian waktu. |
| Transformasi target | Secara opsional terapkan fungsi logaritma alami ke target tergantung pada hasil pengujian statistik tertentu. |
| Normalisasi kasus | Skor Z menormalkan semua data numerik; normalisasi dilakukan per fitur dan per grup rangkaian waktu, seperti yang didefinisikan oleh kolom ID rangkaian waktu. |
Langkah-langkah ini disertakan dalam alur transformasi AutoML, sehingga secara otomatis diterapkan saat diperlukan pada waktu inferensi. Dalam beberapa kasus, operasi terbalik ke langkah disertakan dalam alur inferensi. Misalnya, jika AutoML menerapkan transformasi $\log$ ke target selama pelatihan, prakiraan mentah dieksponensikan dalam alur inferensi.
Pelatihan
TCNForecaster mengikuti praktik terbaik pelatihan DNN yang umum untuk aplikasi lain dalam gambar dan bahasa. AutoML membagi data pelatihan yang telah diolah sebelumnya menjadi contoh yang diacak dan digabungkan menjadi batch. Jaringan memproses batch secara berurutan, menggunakan propagasi balik dan penurunan gradien stochastic untuk mengoptimalkan bobot jaringan sehubungan dengan fungsi kehilangan. Pelatihan dapat memerlukan banyak pass melalui data pelatihan lengkap; setiap pass disebut epoch.
Tabel berikut mencantumkan dan menjelaskan pengaturan input dan parameter untuk pelatihan TCNForecaster:
| Input pelatihan | Deskripsi | Nilai |
|---|---|---|
| Data validasi | Sebagian data yang disimpan dari pelatihan untuk memandu pengoptimalan jaringan dan mengurangi kecocokan. | Disediakan oleh pengguna atau dibuat secara otomatis dari data pelatihan jika tidak disediakan. |
| Metrik utama | Metrik dihitung dari prakiraan nilai median pada data validasi di akhir setiap epoch pelatihan; digunakan untuk penghentian awal dan pemilihan model. | Dipilih oleh pengguna; kesalahan kuadrat rata-rata akar yang dinormalisasi atau kesalahan absolut rata-rata yang dinormalisasi. |
| Epoch pelatihan | Jumlah maksimum epoch yang akan dijalankan untuk pengoptimalan bobot jaringan. | 100; logika penghentian awal otomatis dapat mengakhiri pelatihan pada jumlah epoch yang lebih kecil. |
| Kesabaran penghentian awal | Jumlah epoch untuk menunggu peningkatan metrik utama sebelum pelatihan dihentikan. | 20 |
| Fungsi kehilangan | Fungsi tujuan untuk pengoptimalan bobot jaringan. | Kerugian kuantil rata-rata lebih dari prakiraan persentil ke-10, 25, 50, 75, dan 90. |
| Ukuran batch | Jumlah contoh dalam batch. Setiap contoh memiliki dimensi $n_{\text{input}} \times t_{\text{rf}}$ untuk input dan $h$ untuk output. | Ditentukan secara otomatis dari jumlah total contoh dalam data pelatihan; nilai maksimum 1024. |
| Menyematkan dimensi | Dimensi spasi penyematan untuk fitur kategoris. | Secara otomatis diatur ke akar keempat dari jumlah nilai berbeda di setiap fitur, dibulatkan ke bilangan bulat terdekat. Ambang diterapkan pada nilai minimum 3 dan nilai maksimum 100. |
| Arsitektur jaringan* | Parameter yang mengontrol ukuran dan bentuk jaringan: kedalaman, jumlah sel, dan jumlah saluran. | Ditentukan oleh pencarian model. |
| Bobot jaringan | Parameter yang mengontrol campuran sinyal, penyematan kategoris, bobot kernel konvolusi, dan pemetaan ke nilai prakiraan. | Diinisialisasi secara acak, lalu dioptimalkan sehubungan dengan fungsi kehilangan. |
| Tingkat pembelajaran* | Mengontrol berapa banyak bobot jaringan yang dapat disesuaikan dalam setiap iterasi penurunan gradien; berkurang secara dinamis mendekati konvergensi. | Ditentukan oleh pencarian model. |
| Rasio dropout* | Mengontrol tingkat regularisasi dropout yang diterapkan ke bobot jaringan. | Ditentukan oleh pencarian model. |
Input yang ditandai dengan tanda bintang (*) ditentukan oleh pencarian hyper-parameter yang dijelaskan di bagian berikutnya.
Pencarian model
AutoML menggunakan metode pencarian model untuk menemukan nilai untuk parameter hiper berikut:
- Kedalaman jaringan, atau jumlah blok konvolusional,
- Jumlah sel per blok,
- Jumlah saluran di setiap lapisan tersembunyi,
- Rasio dropout untuk regularisasi jaringan,
- Tingkat pembelajaran.
Nilai optimal untuk parameter ini dapat bervariasi secara signifikan tergantung pada skenario masalah dan data pelatihan, sehingga AutoML melatih beberapa model yang berbeda dalam ruang nilai hyper-parameter dan memilih yang terbaik sesuai dengan skor metrik utama pada data validasi.
Pencarian model memiliki dua fase:
- AutoML melakukan pencarian lebih dari 12 model "landmark". Model landmark bersifat statis dan dipilih untuk menjangkau ruang hyper-parameter secara wajar.
- AutoML terus mencari melalui ruang hyper-parameter menggunakan pencarian acak.
Pencarian berakhir saat kriteria penghentian terpenuhi. Kriteria penghentian bergantung pada konfigurasi pekerjaan pelatihan prakiraan, tetapi beberapa contoh termasuk batas waktu, batasan jumlah uji coba pencarian yang harus dilakukan, dan logika penghentian awal saat metrik validasi tidak membaik.
Langkah berikutnya
- Pelajari cara menyiapkan AutoML untuk melatih model prakiraan rangkaian waktu.
- Pelajari tentang metodologi prakiraan di AutoML.
- Telusuri tanya jawab umum tentang prakiraan di AutoML.