Inferensi dan evaluasi model prakiraan
Artikel ini memperkenalkan konsep yang terkait dengan inferensi dan evaluasi model dalam tugas prakiraan. Untuk petunjuk dan contoh model prakiraan pelatihan di AutoML, lihat Menyiapkan AutoML untuk melatih model prakiraan rangkaian waktu dengan SDK dan CLI.
Setelah Anda menggunakan AutoML untuk melatih dan memilih model terbaik, langkah selanjutnya adalah menghasilkan prakiraan. Kemudian, jika memungkinkan, evaluasi akurasi mereka pada set pengujian yang diadakan dari data pelatihan. Untuk melihat cara menyiapkan dan menjalankan evaluasi model prakiraan dalam pembelajaran mesin otomatis, lihat Mengatur pelatihan, inferensi, dan evaluasi.
Skenario inferensi
Dalam pembelajaran mesin, inferensi adalah proses menghasilkan prediksi model untuk data baru yang tidak digunakan dalam pelatihan. Ada beberapa cara untuk menghasilkan prediksi dalam prakiraan karena ketergantungan waktu data. Skenario paling sederhana adalah ketika periode inferensi segera mengikuti periode pelatihan dan Anda menghasilkan prediksi ke cakrawala prakiraan. Diagram berikut mengilustrasikan skenario ini:
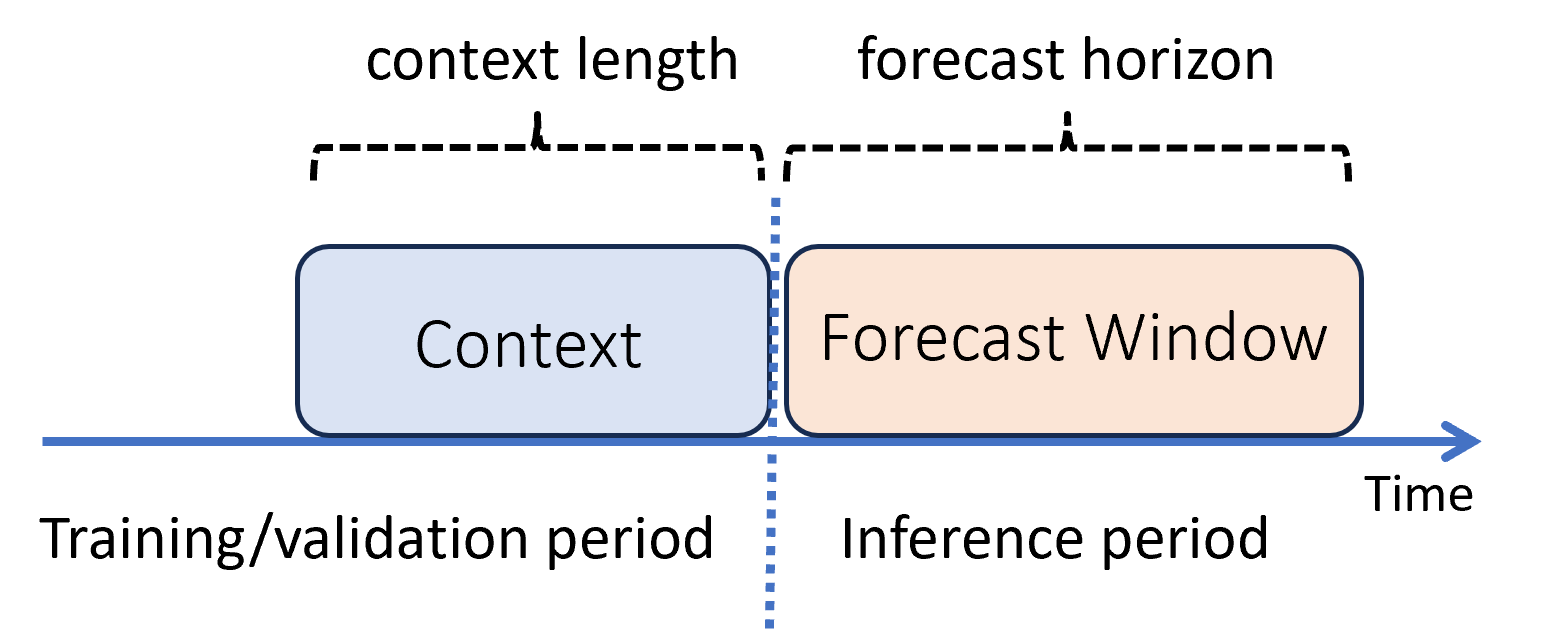
Diagram menunjukkan dua parameter inferensi penting:
- Panjang konteks adalah jumlah riwayat yang diperlukan model untuk membuat prakiraan.
- Cakrawala prakiraan adalah seberapa jauh ke depan pada waktu prakiraan dilatih untuk memprediksi.
Model prakiraan biasanya menggunakan beberapa informasi historis, konteksnya, untuk membuat prediksi sebelumnya hingga cakrawala prakiraan. Ketika konteks adalah bagian dari data pelatihan, AutoML menyimpan apa yang diperlukan untuk membuat prakiraan. Tidak perlu menyediakannya secara eksplisit.
Ada dua skenario inferensi lain yang lebih rumit:
- Menghasilkan prediksi lebih jauh ke masa depan daripada cakrawala prakiraan
- Mendapatkan prediksi ketika ada kesenjangan antara periode pelatihan dan inferensi
Sub bagian berikut meninjau kasus-kasus ini.
Prediksi melewati cakrawala prakiraan: prakiraan rekursif
Ketika Anda memerlukan prakiraan melewati cakrawala, AutoML menerapkan model secara rekursif selama periode inferensi. Prediksi dari model disalurkan kembali sebagai input untuk menghasilkan prediksi untuk jendela prakiraan berikutnya. Diagram berikut menunjukkan contoh sederhana:
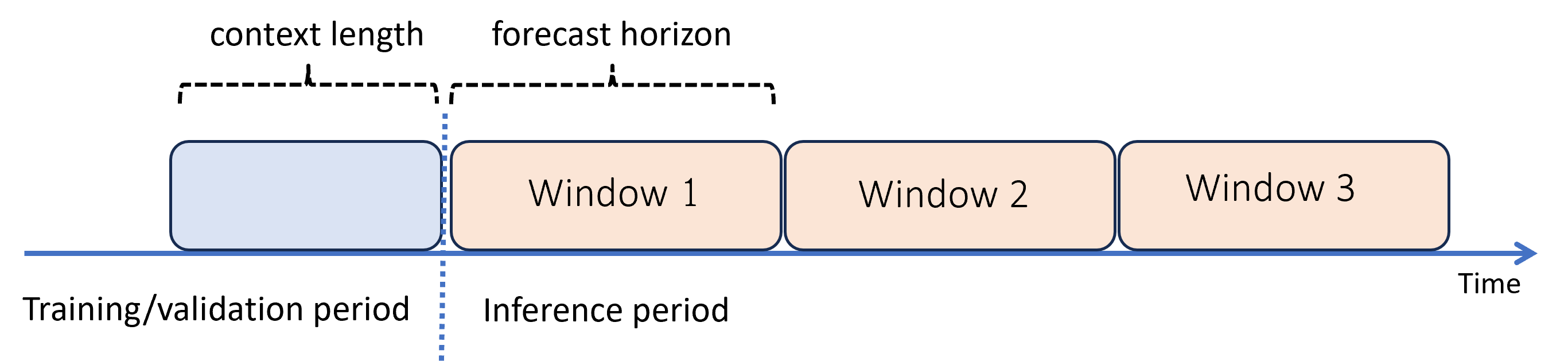
Di sini, pembelajaran mesin menghasilkan prakiraan pada periode tiga kali panjang cakrawala. Ini menggunakan prediksi dari satu jendela sebagai konteks untuk jendela berikutnya.
Peringatan
Kesalahan pemodelan senyawa prakiraan rekursif. Prediksi menjadi kurang akurat semakin jauh dari cakrawala prakiraan asli. Anda mungkin menemukan model yang lebih akurat dengan berlatih kembali dengan cakrawala yang lebih panjang.
Memprediksi dengan kesenjangan antara periode pelatihan dan inferensi
Misalkan setelah Melatih model, Anda ingin menggunakannya untuk membuat prediksi dari pengamatan baru yang belum tersedia selama pelatihan. Dalam hal ini, ada kesenjangan waktu antara periode pelatihan dan inferensi:

AutoML mendukung skenario inferensi ini, tetapi Anda perlu memberikan data konteks dalam periode kesenjangan, seperti yang ditunjukkan dalam diagram. Data prediksi yang diteruskan ke komponen inferensi membutuhkan nilai untuk fitur dan nilai target yang diamati dalam kesenjangan dan nilai atau NaN nilai yang hilang untuk target dalam periode inferensi. Tabel berikut ini memperlihatkan contoh pola ini:
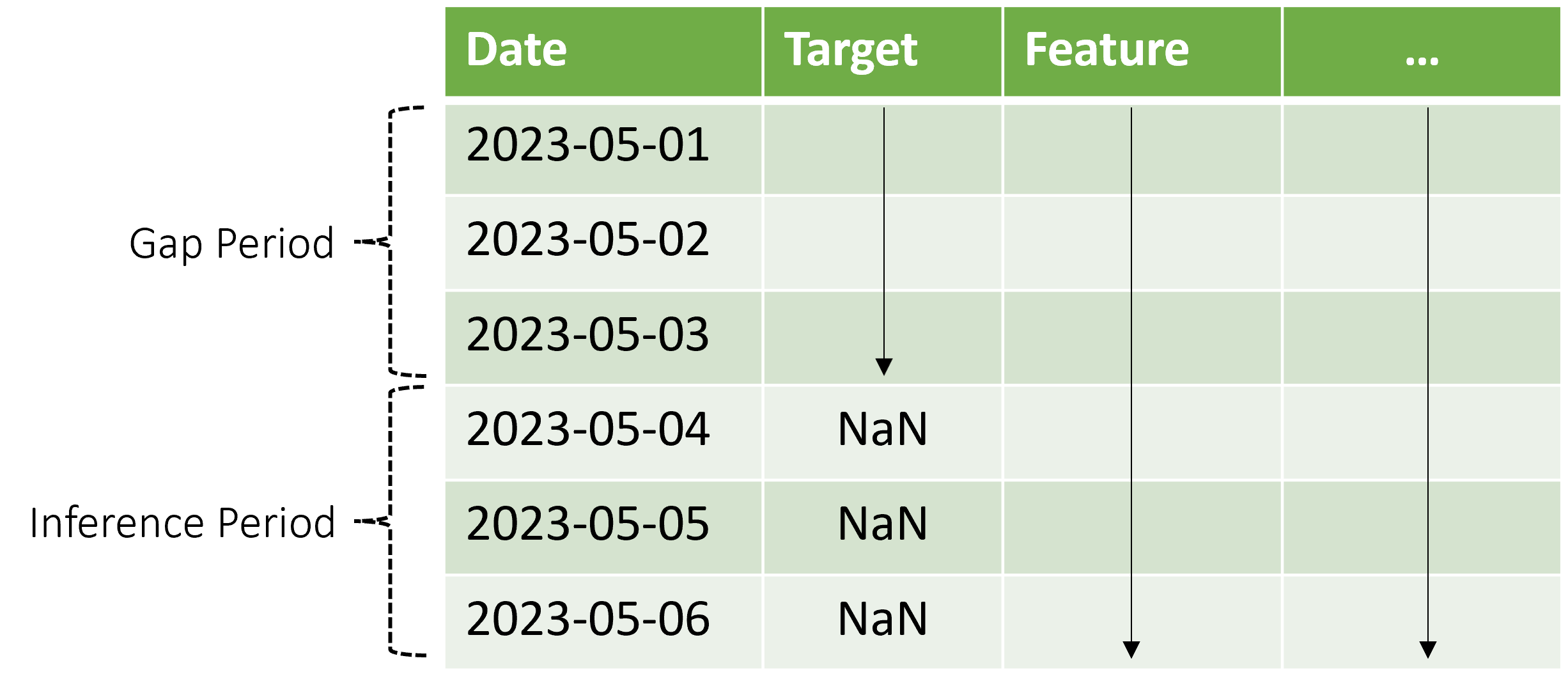
Nilai yang diketahui dari target dan fitur disediakan untuk 2023-05-01 melalui 2023-05-03. Nilai target yang hilang dimulai pada 2023-05-04 menunjukkan bahwa periode inferensi dimulai pada tanggal tersebut.
AutoML menggunakan data konteks baru untuk memperbarui lag dan fitur lookback lainnya, dan juga untuk memperbarui model seperti ARIMA yang menjaga status internal. Operasi ini tidak memperbarui atau mem-refit parameter model.
Evaluasi model
Evaluasi adalah proses menghasilkan prediksi pada set pengujian yang diadakan dari data pelatihan dan metrik komputasi dari prediksi ini yang memandu keputusan penyebaran model. Oleh karena itu, ada mode inferensi yang cocok untuk evaluasi model: perkiraan bergulir.
Prosedur praktik terbaik untuk mengevaluasi model prakiraan adalah menggulung prakiraan terlatih ke depan waktu selama set pengujian, rata-rata metrik kesalahan di beberapa jendela prediksi. Prosedur ini terkadang disebut backtest. Idealnya, set pengujian untuk evaluasi relatif panjang terhadap cakrawala prakiraan model. Perkiraan kesalahan prakiraan mungkin berisik secara statistik dan, oleh karena itu, kurang dapat diandalkan.
Diagram berikut menunjukkan contoh sederhana dengan tiga jendela prakiraan:
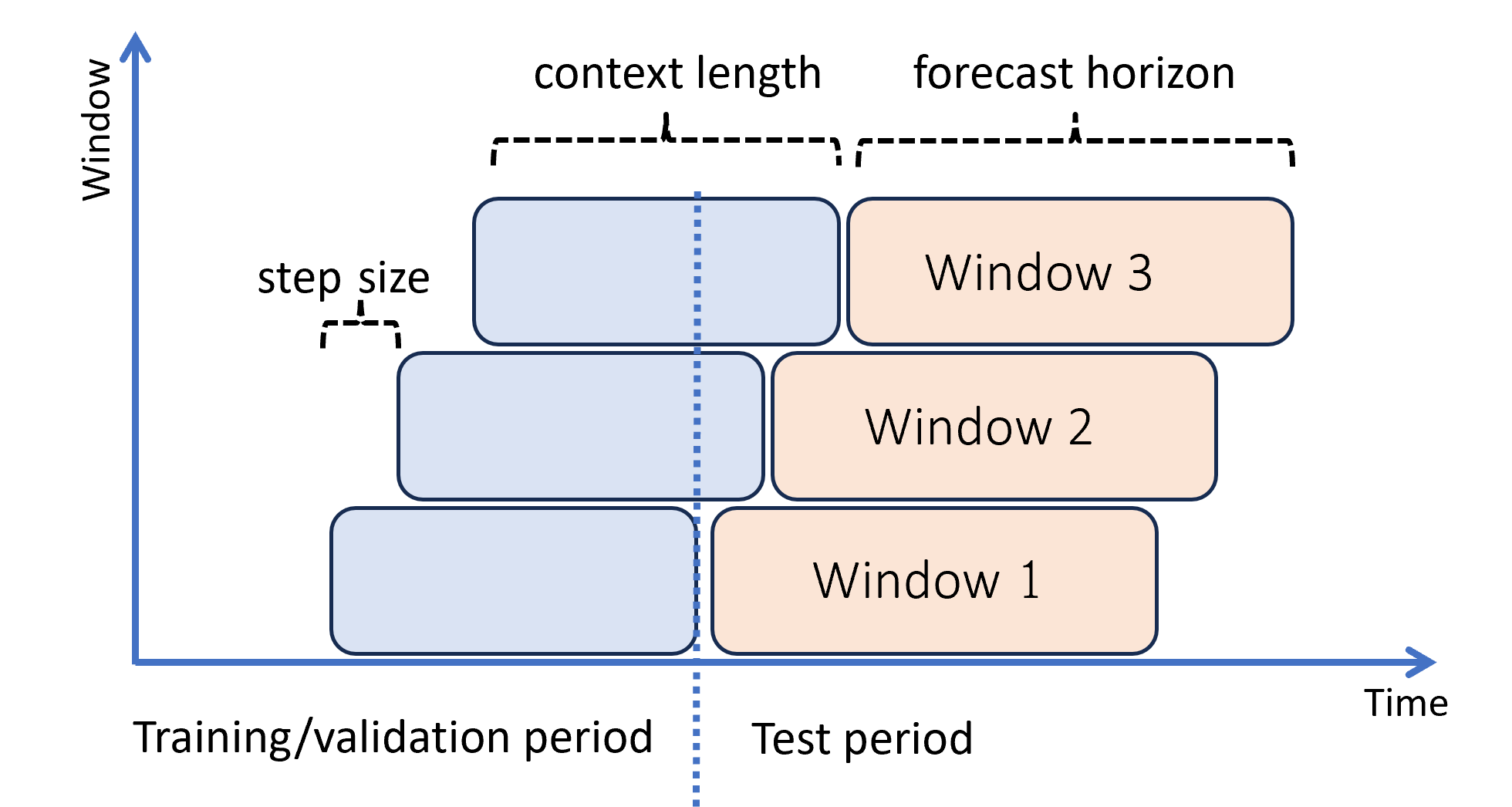
Diagram ini mengilustrasikan tiga parameter evaluasi bergulir:
- Panjang konteks adalah jumlah riwayat yang diperlukan model untuk membuat prakiraan.
- Cakrawala prakiraan adalah seberapa jauh ke depan pada waktu prakiraan dilatih untuk memprediksi.
- Ukuran langkah adalah seberapa jauh ke depan pada waktu jendela bergulir maju pada setiap iterasi pada set pengujian.
Konteks maju bersama dengan jendela prakiraan. Nilai aktual dari set pengujian digunakan untuk membuat prakiraan saat berada dalam jendela konteks saat ini. Tanggal terbaru nilai aktual yang digunakan untuk jendela prakiraan tertentu disebut waktu asal jendela. Tabel berikut menunjukkan contoh output dari prakiraan bergulir tiga jendela dengan cakrawala tiga hari dan ukuran langkah satu hari:
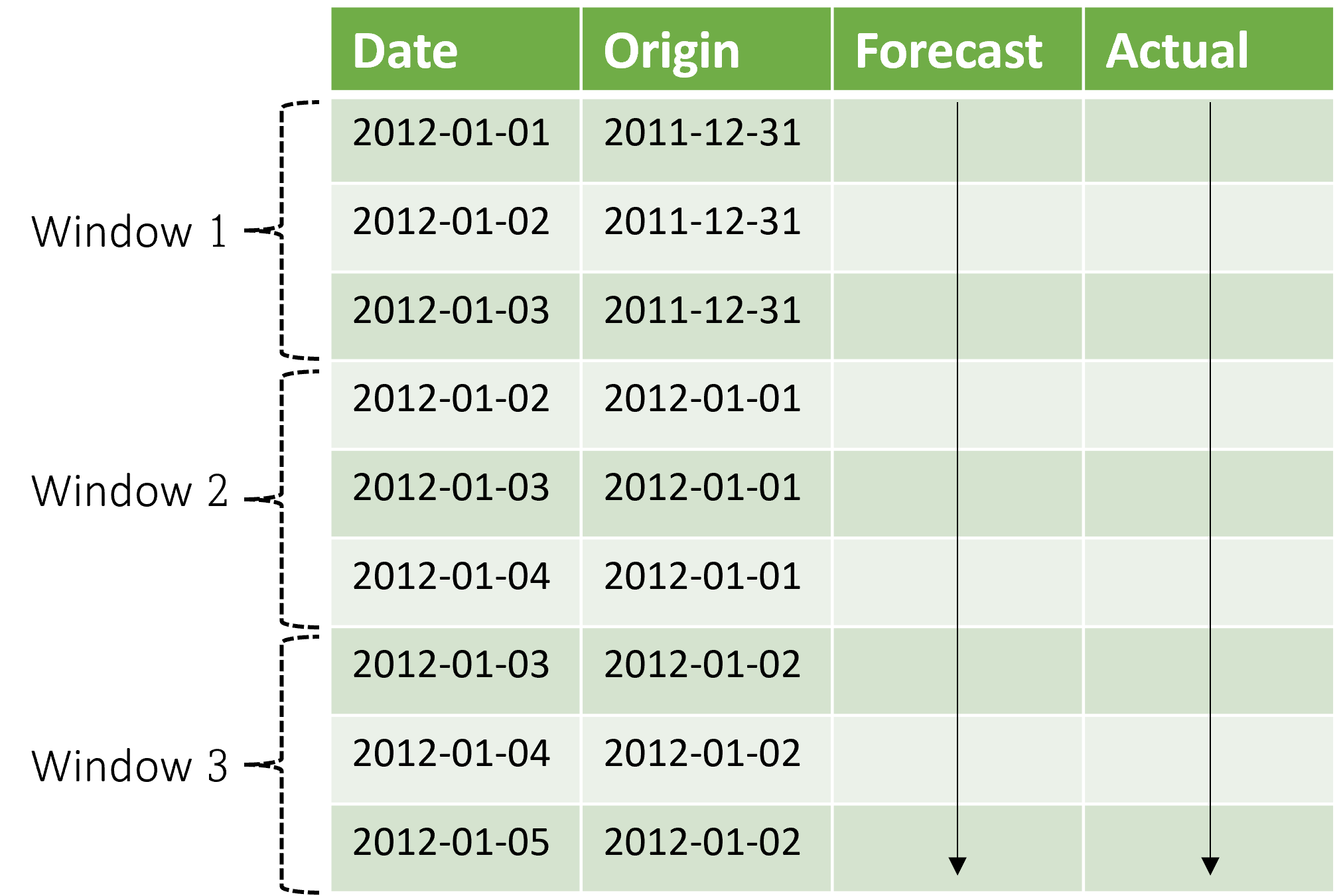
Dengan tabel seperti ini, Anda dapat memvisualisasikan prakiraan versus metrik evaluasi aktual dan komputasi yang diinginkan. Alur AutoML dapat menghasilkan prakiraan bergulir pada set pengujian dengan komponen inferensi.
Catatan
Ketika periode pengujian memiliki panjang yang sama dengan cakrawala prakiraan, prakiraan bergulir memberikan satu jendela prakiraan hingga cakrawala.
Metrik evaluasi
Skenario bisnis tertentu biasanya mendorong pilihan ringkasan atau metrik evaluasi. Beberapa pilihan umum mencakup contoh berikut:
- Plot nilai target yang diamati versus nilai yang diperkirakan untuk memeriksa apakah dinamika data tertentu yang diambil model
- Rata-rata kesalahan persentase absolut (MAPE) antara nilai aktual dan prakiraan
- Kesalahan kuadrat rata-rata akar (RMSE), mungkin dengan normalisasi, antara nilai aktual dan prakiraan
- Kesalahan absolut rata-rata (MAE), mungkin dengan normalisasi, antara nilai aktual dan prakiraan
Ada banyak kemungkinan lain, tergantung pada skenario bisnis. Anda mungkin perlu membuat utilitas pasca-pemrosesan Anda sendiri untuk menghitung metrik evaluasi dari hasil inferensi atau prakiraan bergulir. Untuk informasi selengkapnya tentang metrik, lihat Metrik regresi/prakiraan.
Konten terkait
- Pelajari selengkapnya tentang cara menyiapkan AutoML untuk melatih model prakiraan rangkaian waktu.
- Pelajari tentang cara AutoML menggunakan pembelajaran mesin untuk membangun model prakiraan.
- Baca jawaban atas tanya jawab umum tentang prakiraan di AutoML.