Pembersihan dan pemilihan model untuk prakiraan di AutoML
Artikel ini berfokus pada cara AutoML mencari dan memilih model prakiraan. Silakan lihat artikel gambaran umum metode untuk informasi lebih umum tentang metodologi prakiraan di AutoML. Instruksi dan contoh untuk model prakiraan pelatihan di AutoML dapat ditemukan di artikel prakiraan AutoML untuk rangkaian waktu kami.
Pembersihan model
Tugas pusat untuk AutoML adalah melatih dan mengevaluasi beberapa model dan memilih yang terbaik sehubungan dengan metrik utama yang diberikan. Kata "model" di sini mengacu pada kelas model - seperti ARIMA atau Hutan Acak - dan pengaturan hyper-parameter tertentu yang membedakan model dalam kelas. Misalnya, ARIMA mengacu pada kelas model yang berbagi templat matematika dan serangkaian asumsi statistik. Pelatihan, atau pas, model ARIMA memerlukan daftar bilangan bulat positif yang menentukan bentuk matematika model yang tepat; ini adalah parameter hiper. ARIMA(1, 0, 1) dan ARIMA(2, 1, 2) memiliki kelas yang sama, tetapi parameter hiper yang berbeda dan, sehingga, dapat secara terpisah sesuai dengan data pelatihan dan dievaluasi satu sama lain. Pencarian AutoML, atau sapuan, di atas kelas model yang berbeda dan dalam kelas dengan berbagai parameter hyper.
Tabel berikut menunjukkan berbagai metode pembersihan hyper-parameter yang digunakan AutoML untuk kelas model yang berbeda:
| Grup kelas model | Jenis model | Metode pembersihan hyper-parameter |
|---|---|---|
| Naif, Naif Musiman, Rata-rata, Rata-rata Musiman | Deret waktu | Tidak ada pembersihan di dalam kelas karena kesederhanaan model |
| Smoothing Eksponensial, ARIMA(X) | Deret waktu | Pencarian kisi untuk pembersihan dalam kelas |
| Prophet | Regresi | Tidak ada pembersihan di dalam kelas |
| Linear SGD, LARS LASSO, Elastic Net, K Nearest Neighbors, Decision Tree, Random Forest, Extremely Randomized Trees, Gradient Boosted Trees, LightGBM, XGBoost | Regresi | Layanan rekomendasi model AutoML secara dinamis mengeksplorasi ruang hyper-parameter |
| PrakiraanTCN | Regresi | Daftar statis model diikuti oleh pencarian acak atas ukuran jaringan, rasio dropout, dan tingkat pembelajaran. |
Untuk deskripsi jenis model yang berbeda, lihat bagian model prakiraan dari artikel gambaran umum metode.
Jumlah pembersihan yang dilakukan AutoML tergantung pada konfigurasi pekerjaan prakiraan. Anda dapat menentukan kriteria penghentian sebagai batas waktu atau batas jumlah uji coba, atau secara setara dengan jumlah model. Logika penghentian dini dapat digunakan dalam kedua kasus untuk berhenti menyapu jika metrik utama tidak membaik.
Pemilihan model
Pencarian dan pemilihan model prakiraan AutoML berlanjut dalam tiga fase berikut:
- Sapu model rangkaian waktu dan pilih model terbaik dari setiap kelas menggunakan metode kemungkinan yang dipidana.
- Sapu model regresi dan beri peringkat, bersama dengan model rangkaian waktu terbaik dari fase 1, sesuai dengan nilai metrik utamanya dari set validasi.
- Buat model ansambel dari model peringkat teratas, hitung metrik validasinya, dan beri peringkat dengan model lain.
Model dengan nilai metrik peringkat teratas pada akhir fase 3 ditunjuk sebagai model terbaik.
Penting
Fase akhir pemilihan model AutoML selalu menghitung metrik pada data di luar sampel . Artinya, data yang tidak digunakan untuk menyesuaikan model. Ini membantu melindungi dari over-fitting.
AutoML memiliki dua konfigurasi validasi - validasi silang dan data validasi eksplisit. Dalam kasus validasi silang, AutoML menggunakan konfigurasi input untuk membuat pemisahan data menjadi lipatan pelatihan dan validasi. Urutan waktu harus dipertahankan dalam pemisahan ini, sehingga AutoML menggunakan apa yang disebut Rolling Origin Cross Validation yang membagi rangkaian menjadi data pelatihan dan validasi menggunakan titik waktu asal. Menggeser asal-usul tepat waktu menghasilkan lipatan validasi silang. Setiap lipatan validasi berisi cakrawala pengamatan berikutnya segera mengikuti posisi asal untuk lipatan yang diberikan. Strategi ini mempertahankan integritas data rangkaian waktu dan mengurangi risiko kebocoran informasi.
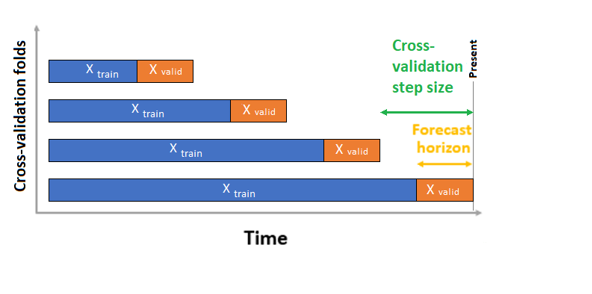
AutoML mengikuti prosedur validasi silang yang biasa, melatih model terpisah pada setiap lipatan dan rata-rata metrik validasi dari semua lipatan.
Validasi silang untuk pekerjaan prakiraan dikonfigurasi dengan mengatur jumlah lipatan validasi silang dan, secara opsional, jumlah periode waktu antara dua lipatan validasi silang berturut-turut. Lihat panduan pengaturan validasi silang kustom untuk informasi selengkapnya dan contoh mengonfigurasi validasi silang untuk prakiraan.
Anda juga dapat membawa data validasi Anda sendiri. Pelajari selengkapnya di artikel mengonfigurasi pemisahan data dan validasi silang di AutoML (SDK v1).
Langkah berikutnya
- Pelajari selengkapnya tentang cara menyiapkan AutoML untuk melatih model prakiraan rangkaian waktu.
- Telusuri Tanya Jawab Umum Prakiraan AutoML.
- Pelajari tentang fitur kalender untuk prakiraan rangkaian waktu di AutoML.
- Pelajari tentang cara AutoML menggunakan pembelajaran mesin untuk membangun model prakiraan.