Melatih model regresi dengan ML otomatis dan Python (SDK v1)
BERLAKU UNTUK: Python SDK azureml v1
Python SDK azureml v1
Dalam artikel ini, Anda mempelajari cara melatih model regresi dengan Azure Pembelajaran Mesin Python SDK dengan menggunakan Azure Pembelajaran Mesin Automated ML. Model regresi memprediksi tarif penumpang untuk taksi yang beroperasi di New York City (NYC). Anda menulis kode dengan Python SDK untuk mengonfigurasi ruang kerja dengan data yang disiapkan, melatih model secara lokal dengan parameter kustom, dan menjelajahi hasilnya.
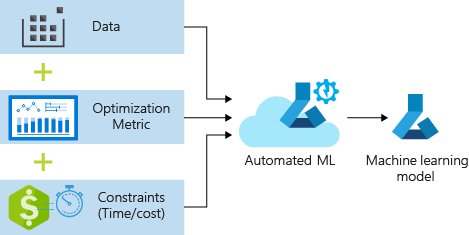
Proses ini menerima data pelatihan dan pengaturan konfigurasi. Ini secara otomatis melakukan iterasi melalui kombinasi metode normalisasi/standardisasi fitur yang berbeda, model, dan pengaturan hiperparameter untuk tiba di model terbaik. Diagram berikut mengilustrasikan alur proses untuk pelatihan model regresi:
Prasyarat
Langganan Azure. Anda dapat membuat akun gratis atau berbayar Azure Pembelajaran Mesin.
Ruang kerja atau instans komputasi Azure Pembelajaran Mesin. Untuk menyiapkan sumber daya ini, lihat Mulai Cepat: Mulai menggunakan Azure Pembelajaran Mesin.
Dapatkan data sampel yang disiapkan untuk latihan tutorial dengan memuat buku catatan ke ruang kerja Anda:
Buka ruang kerja Anda di studio Azure Pembelajaran Mesin, pilih Buku Catatan, lalu pilih tab Sampel.
Dalam daftar notebook, perluas >sampel SDK v1>tutorial>regresi-automl-nyc-taxi-data node.
Pilih buku catatan regresi-automated-ml.ipynb.
Untuk menjalankan setiap sel buku catatan sebagai bagian dari tutorial ini, pilih Kloning file ini.
Pendekatan alternatif: Jika mau, Anda dapat menjalankan latihan tutorial di lingkungan lokal. Tutorial ini tersedia di repositori Azure Pembelajaran Mesin Notebooks di GitHub. Untuk pendekatan ini, ikuti langkah-langkah berikut untuk mendapatkan paket yang diperlukan:
Jalankan
pip install azureml-opendatasets azureml-widgetsperintah pada komputer lokal Anda untuk mendapatkan paket yang diperlukan.
Mengunduh dan menyiapkan data
Paket Open Datasets berisi kelas yang mewakili setiap sumber data (seperti NycTlcGreen) untuk memfilter parameter tanggal dengan mudah sebelum mengunduh.
Kode berikut mengimpor paket yang diperlukan:
from azureml.opendatasets import NycTlcGreen
import pandas as pd
from datetime import datetime
from dateutil.relativedelta import relativedelta
Langkah pertama adalah membuat dataframe untuk data taksi. Saat Anda bekerja di lingkungan non-Spark, paket Open Datasets memungkinkan pengunduhan hanya satu bulan data pada satu waktu dengan kelas tertentu. Pendekatan ini membantu menghindari MemoryError masalah yang dapat terjadi dengan himpunan data besar.
Untuk mengunduh data taksi, ambil satu bulan secara berulang pada satu waktu. Sebelum Anda menambahkan kumpulan data berikutnya ke green_taxi_df dataframe, sampel 2.000 rekaman secara acak dari setiap bulan, lalu pratinjau data. Pendekatan ini membantu menghindari kembungnya dataframe.
Kode berikut membuat dataframe, mengambil data, dan memuatnya ke dalam dataframe:
green_taxi_df = pd.DataFrame([])
start = datetime.strptime("1/1/2015","%m/%d/%Y")
end = datetime.strptime("1/31/2015","%m/%d/%Y")
for sample_month in range(12):
temp_df_green = NycTlcGreen(start + relativedelta(months=sample_month), end + relativedelta(months=sample_month)) \
.to_pandas_dataframe()
green_taxi_df = green_taxi_df.append(temp_df_green.sample(2000))
green_taxi_df.head(10)
Tabel berikut ini memperlihatkan banyak kolom nilai dalam data taksi sampel:
| vendorID | lpepPickupDatetime | lpepDropoffDatetime | passengerCount | tripDistance | puLocationId | doLocationId | pickupLongitude | pickupLatitude | dropoffLongitude | ... | paymentType | fareAmount | extra | mtaTax | improvementSurcharge | tipAmount | tollsAmount | ehailFee | totalAmount | tripType |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 | 2015-01-30 18:38:09 | 2015-01-30 19:01:49 | 1 | 1.88 | Tidak | Tidak | -73.996155 | 40.690903 | -73.964287 | ... | 1 | 15.0 | 1.0 | 0,5 | 0,3 | 4.00 | 0.0 | Tidak | 20.80 | 1.0 |
| 1 | 2015-01-17 23:21:39 | 2015-01-17 23:35:16 | 1 | 2.70 | Tidak | Tidak | -73.978508 | 40.687984 | -73.955116 | ... | 1 | 11.5 | 0,5 | 0,5 | 0,3 | 2.55 | 0.0 | Tidak | 15.35 | 1.0 |
| 2 | 2015-01-16 01:38:40 | 2015-01-16 01:52:55 | 1 | 3.54 | Tidak | Tidak | -73.957787 | 40.721779 | -73.963005 | ... | 1 | 13,5 | 0,5 | 0,5 | 0,3 | 2.80 | 0.0 | Tidak | 17.60 | 1.0 |
| 2 | 2015-01-04 17:09:26 | 2015-01-04 17:16:12 | 1 | 1 | Tidak | Tidak | -73.919914 | 40.826023 | -73.904839 | ... | 2 | 6.5 | 0.0 | 0,5 | 0,3 | 0.00 | 0.0 | Tidak | 7,30 | 1.0 |
| 1 | 2015-01-14 10:10:57 | 2015-01-14 10:33:30 | 1 | 5.10 | Tidak | Tidak | -73.943710 | 40.825439 | -73.982964 | ... | 1 | 18.5 | 0.0 | 0,5 | 0,3 | 3.85 | 0.0 | Tidak | 23.15 | 1.0 |
| 2 | 2015-01-19 18:10:41 | 2015-01-19 18:32:20 | 1 | 7.41 | Tidak | Tidak | -73.940918 | 40.839714 | -73.994339 | ... | 1 | 24,0 | 0.0 | 0,5 | 0,3 | 4,80 | 0.0 | Tidak | 29.60 | 1.0 |
| 2 | 2015-01-01 15:44:21 | 2015-01-01 15:50:16 | 1 | 1.03 | Tidak | Tidak | -73.985718 | 40.685646 | -73.996773 | ... | 1 | 6.5 | 0.0 | 0,5 | 0,3 | 1.30 | 0.0 | Tidak | 8.60 | 1.0 |
| 2 | 2015-01-12 08:01:21 | 2015-01-12 08:14:52 | 5 | 2.94 | Tidak | Tidak | -73.939865 | 40.789822 | -73.952957 | ... | 2 | 12.5 | 0.0 | 0,5 | 0,3 | 0.00 | 0.0 | Tidak | 13.30 | 1.0 |
| 1 | 2015-01-16 21:54:26 | 2015-01-16 22:12:39 | 1 | 3 | Tidak | Tidak | -73.957939 | 40.721928 | -73.926247 | ... | 1 | 14,0 | 0,5 | 0,5 | 0,3 | 2.00 | 0.0 | Tidak | 17.30 | 1.0 |
| 2 | 2015-01-06 06:34:53 | 2015-01-06 06:44:23 | 1 | 2,31 | Tidak | Tidak | -73.943825 | 40.810257 | -73.943062 | ... | 1 | 10.0 | 0.0 | 0,5 | 0,3 | 2.00 | 0.0 | Tidak | 12,80 | 1.0 |
Sangat membantu untuk menghapus beberapa kolom yang tidak Anda butuhkan untuk pelatihan atau pembuatan fitur lainnya. Misalnya, Anda dapat menghapus kolom lpepPickupDatetime karena ML Otomatis secara otomatis menangani fitur berbasis waktu.
Kode berikut menghapus 14 kolom dari data sampel:
columns_to_remove = ["lpepDropoffDatetime", "puLocationId", "doLocationId", "extra", "mtaTax",
"improvementSurcharge", "tollsAmount", "ehailFee", "tripType", "rateCodeID",
"storeAndFwdFlag", "paymentType", "fareAmount", "tipAmount"
]
for col in columns_to_remove:
green_taxi_df.pop(col)
green_taxi_df.head(5)
Membersihkan data
Langkah selanjutnya adalah membersihkan data.
Kode berikut menjalankan describe() fungsi pada kerangka data baru untuk menghasilkan statistik ringkasan untuk setiap bidang:
green_taxi_df.describe()
Tabel berikut ini memperlihatkan statistik ringkasan untuk bidang yang tersisa dalam data sampel:
| vendorID | passengerCount | tripDistance | pickupLongitude | pickupLatitude | dropoffLongitude | dropoffLatitude | totalAmount | |
|---|---|---|---|---|---|---|---|---|
| count | 24000.00 | 24000.00 | 24000.00 | 24000.00 | 24000.00 | 24000.00 | 24000.00 | 24000.00 |
| mean | 1.777625 | 1.373625 | 2.893981 | -73.827403 | 40.689730 | -73.819670 | 40.684436 | 14.892744 |
| Std | 0.415850 | 1.046180 | 3.072343 | 2.821767 | 1.556082 | 2.901199 | 1.599776 | 12.339749 |
| min | 1 | 0.00 | 0.00 | -74.357101 | 0.00 | -74.342766 | 0.00 | -120.80 |
| 25% | 2.00 | 1 | 1,05 | -73.959175 | 40.699127 | -73.966476 | 40.699459 | 8.00 |
| 50% | 2.00 | 1 | 1.93 | -73.945049 | 40.746754 | -73.944221 | 40.747536 | 11.30 |
| 75% | 2.00 | 1 | 3.70 | -73.917089 | 40.803060 | -73.909061 | 40.791526 | 17.80 |
| max | 2.00 | 8.00 | 154.28 | 0.00 | 41.109089 | 0.00 | 40.982826 | 425.00 |
Statistik ringkasan mengungkapkan beberapa bidang yang merupakan outlier, yang merupakan nilai yang mengurangi akurasi model. Untuk mengatasi masalah ini, filter bidang garis lintang/bujur (lat/panjang) sehingga nilai berada dalam batas area Manhattan. Pendekatan ini memfilter perjalanan taksi atau perjalanan yang lebih lama yang merupakan outlier sehubungan dengan hubungan mereka dengan fitur lain.
Selanjutnya, filter tripDistance bidang untuk nilai yang lebih besar dari nol tetapi kurang dari 31 mil (jarak hasrsine antara dua pasangan lat/panjang). Teknik ini menghilangkan perjalanan outlier panjang yang memiliki biaya perjalanan yang tidak konsisten.
Terakhir, totalAmount bidang memiliki nilai negatif untuk tarif taksi, yang tidak masuk akal dalam konteks model. Bidang ini passengerCount juga berisi data buruk di mana nilai minimum adalah nol.
Kode berikut memfilter anomali nilai ini dengan menggunakan fungsi kueri. Kode kemudian menghapus beberapa kolom terakhir yang tidak diperlukan untuk pelatihan:
final_df = green_taxi_df.query("pickupLatitude>=40.53 and pickupLatitude<=40.88")
final_df = final_df.query("pickupLongitude>=-74.09 and pickupLongitude<=-73.72")
final_df = final_df.query("tripDistance>=0.25 and tripDistance<31")
final_df = final_df.query("passengerCount>0 and totalAmount>0")
columns_to_remove_for_training = ["pickupLongitude", "pickupLatitude", "dropoffLongitude", "dropoffLatitude"]
for col in columns_to_remove_for_training:
final_df.pop(col)
Langkah terakhir dalam urutan ini adalah memanggil describe() fungsi lagi pada data untuk memastikan pembersihan berfungsi seperti yang diharapkan. Anda sekarang memiliki serangkaian data taksi, liburan, dan cuaca yang disiapkan dan dibersihkan untuk digunakan untuk pelatihan model pembelajaran mesin:
final_df.describe()
Konfigurasi ruang kerja
Buat objek ruang kerja dari ruang kerja yang sudah ada. Ruang kerja adalah kelas yang menerima informasi langganan dan sumber daya Azure Anda. Ruang kerja juga membuat sumber daya cloud untuk memantau dan melacak eksekusi model Anda.
Kode berikut memanggil Workspace.from_config() fungsi untuk membaca file config.json dan memuat detail autentikasi ke dalam objek bernama ws.
from azureml.core.workspace import Workspace
ws = Workspace.from_config()
Objek ws digunakan di seluruh kode lainnya dalam tutorial ini.
Membagi data menjadi kumpulan pelatihan dan pengujian
Pisahkan data menjadi set pelatihan dan pengujian dengan menggunakan train_test_split fungsi di pustaka scikit-learn . Fungsi ini memisahkan data ke dalam kumpulan data x (fitur) untuk pelatihan model dan kumpulan data y (nilai yang akan diprediksi) untuk pengujian.
Parameter test_size menentukan persentase data yang akan dialokasikan ke pengujian. Parameter random_state menetapkan seed ke generator acak sehingga pemisahan pengujian dan pelatihan Anda bersifat deterministik.
Kode berikut memanggil train_test_split fungsi untuk memuat himpunan data x dan y:
from sklearn.model_selection import train_test_split
x_train, x_test = train_test_split(final_df, test_size=0.2, random_state=223)
Tujuan dari langkah ini adalah untuk menyiapkan poin data untuk menguji model jadi yang tidak digunakan untuk melatih model. Poin-poin ini digunakan untuk mengukur akurasi sejati. Model yang terlatih dengan baik adalah model yang dapat membuat prediksi yang akurat dari data yang tidak terlihat. Anda sekarang memiliki data yang disiapkan untuk melatih otomatis model pembelajaran mesin.
Melatih model secara otomatis
Untuk melatih model secara otomatis, ikuti langkah-langkah berikut:
Tentukan pengaturan untuk eksperimen yang dijalankan. Lampirkan data pelatihan Anda ke konfigurasi, dan ubah pengaturan yang mengontrol proses pelatihan.
Kirim eksperimen untuk penyetelan model. Setelah Anda mengirimkan eksperimen, proses berulang melalui algoritma pembelajaran mesin yang berbeda dan pengaturan hiperparameter, mematuhi batasan yang Anda tentukan. Proses ini memilih model yang paling cocok dengan mengoptimalkan metrik akurasi.
Menentukan pengaturan pelatihan
Tentukan parameter eksperimen dan pengaturan model untuk pelatihan. Lihat daftar lengkap pengaturan. Mengirimkan eksperimen dengan pengaturan default ini membutuhkan waktu sekitar 5-20 menit. Untuk mengurangi waktu proses, kurangi experiment_timeout_hours parameter .
| Properti | Nilai dalam tutorial ini | Deskripsi |
|---|---|---|
iteration_timeout_minutes |
10 | Batas waktu dalam menit untuk setiap iterasi. Tingkatkan nilai ini untuk set data yang lebih besar yang membutuhkan lebih banyak waktu untuk setiap iterasi. |
experiment_timeout_hours |
0,3 | Jumlah waktu maksimum dalam jam yang diperlukan semua iterasi sebelum eksperimen diakhiri. |
enable_early_stopping |
Benar | Bendera untuk mengaktifkan penghentian dini jika skor tidak membaik dalam jangka pendek. |
primary_metric |
spearman_correlation | Metrik yang ingin Anda optimalkan. Model yang paling sesuai dipilih berdasarkan metrik ini. |
featurization |
auto | Nilai otomatis memungkinkan eksperimen untuk memproses data input sebelumnya, termasuk menangani data yang hilang, mengonversi teks menjadi numerik, dan sebagainya. |
verbosity |
logging.INFO | Mengontrol tingkat pencatatan. |
n_cross_validations |
5 | Jumlah pemisahan validasi silang yang akan dilakukan saat data validasi tidak ditentukan. |
Kode berikut mengirimkan eksperimen:
import logging
automl_settings = {
"iteration_timeout_minutes": 10,
"experiment_timeout_hours": 0.3,
"enable_early_stopping": True,
"primary_metric": 'spearman_correlation',
"featurization": 'auto',
"verbosity": logging.INFO,
"n_cross_validations": 5
}
Kode berikut memungkinkan Anda menggunakan pengaturan pelatihan yang **kwargs ditentukan sebagai parameter ke AutoMLConfig objek. Selain itu, Anda menentukan data pelatihan dan jenis model, yang dalam regression hal ini.
from azureml.train.automl import AutoMLConfig
automl_config = AutoMLConfig(task='regression',
debug_log='automated_ml_errors.log',
training_data=x_train,
label_column_name="totalAmount",
**automl_settings)
Catatan
Langkah-langkah pra-pemrosesan ML otomatis (normalisasi fitur, menangani data yang hilang, mengonversi teks ke numerik, dan sebagainya) menjadi bagian dari model yang mendasarinya. Saat Anda menggunakan model untuk prediksi, langkah-langkah pra-pemrosesan yang sama yang diterapkan selama pelatihan diterapkan ke data input Anda secara otomatis.
Melatih model regresi otomatis
Buat objek eksperimen di ruang kerja Anda. Eksperimen berfungsi sebagai kontainer untuk pekerjaan individu Anda. Teruskan objek yang ditentukan automl_config ke eksperimen, dan atur output ke True untuk melihat kemajuan selama pekerjaan.
Setelah Anda memulai eksperimen, pembaruan output yang ditampilkan langsung saat eksperimen berjalan. Untuk setiap iterasi, Anda akan melihat jenis model, durasi eksekusi, dan akurasi pelatihan. Bidang BEST melacak skor pelatihan terbaik yang berjalan berdasarkan jenis metrik Anda:
from azureml.core.experiment import Experiment
experiment = Experiment(ws, "Tutorial-NYCTaxi")
local_run = experiment.submit(automl_config, show_output=True)
Berikut output-nya:
Running on local machine
Parent Run ID: AutoML_1766cdf7-56cf-4b28-a340-c4aeee15b12b
Current status: DatasetFeaturization. Beginning to featurize the dataset.
Current status: DatasetEvaluation. Gathering dataset statistics.
Current status: FeaturesGeneration. Generating features for the dataset.
Current status: DatasetFeaturizationCompleted. Completed featurizing the dataset.
Current status: DatasetCrossValidationSplit. Generating individually featurized CV splits.
Current status: ModelSelection. Beginning model selection.
****************************************************************************************************
ITERATION: The iteration being evaluated.
PIPELINE: A summary description of the pipeline being evaluated.
DURATION: Time taken for the current iteration.
METRIC: The result of computing score on the fitted pipeline.
BEST: The best observed score thus far.
****************************************************************************************************
ITERATION PIPELINE DURATION METRIC BEST
0 StandardScalerWrapper RandomForest 0:00:16 0.8746 0.8746
1 MinMaxScaler RandomForest 0:00:15 0.9468 0.9468
2 StandardScalerWrapper ExtremeRandomTrees 0:00:09 0.9303 0.9468
3 StandardScalerWrapper LightGBM 0:00:10 0.9424 0.9468
4 RobustScaler DecisionTree 0:00:09 0.9449 0.9468
5 StandardScalerWrapper LassoLars 0:00:09 0.9440 0.9468
6 StandardScalerWrapper LightGBM 0:00:10 0.9282 0.9468
7 StandardScalerWrapper RandomForest 0:00:12 0.8946 0.9468
8 StandardScalerWrapper LassoLars 0:00:16 0.9439 0.9468
9 MinMaxScaler ExtremeRandomTrees 0:00:35 0.9199 0.9468
10 RobustScaler ExtremeRandomTrees 0:00:19 0.9411 0.9468
11 StandardScalerWrapper ExtremeRandomTrees 0:00:13 0.9077 0.9468
12 StandardScalerWrapper LassoLars 0:00:15 0.9433 0.9468
13 MinMaxScaler ExtremeRandomTrees 0:00:14 0.9186 0.9468
14 RobustScaler RandomForest 0:00:10 0.8810 0.9468
15 StandardScalerWrapper LassoLars 0:00:55 0.9433 0.9468
16 StandardScalerWrapper ExtremeRandomTrees 0:00:13 0.9026 0.9468
17 StandardScalerWrapper RandomForest 0:00:13 0.9140 0.9468
18 VotingEnsemble 0:00:23 0.9471 0.9471
19 StackEnsemble 0:00:27 0.9463 0.9471
Menjelajahi hasil
Jelajahi hasil pelatihan otomatis dengan widget Jupyter. Widget memungkinkan Anda untuk melihat grafik dan tabel dari semua perulangan pekerjaan individual, bersama dengan metrik akurasi pelatihan dan metadata. Selain itu, Anda dapat memfilter metrik akurasi yang berbeda dari metrik utama dengan pemilih dropdown.
Kode berikut menghasilkan grafik untuk menjelajahi hasilnya:
from azureml.widgets import RunDetails
RunDetails(local_run).show()
Detail eksekusi untuk widget Jupyter:

Bagan plot untuk widget Jupyter:

Mengambil model terbaik
Kode berikut memungkinkan Anda memilih model terbaik dari iterasi Anda. Fungsi get_output mengembalikan proses terbaik dan model yang tepat untuk pemanggilan terbaik terakhir. Dengan menggunakan kelebihan beban pada get_output fungsi, Anda dapat mengambil model terbaik yang dijalankan dan dipasang untuk metrik yang dicatat atau iterasi tertentu.
best_run, fitted_model = local_run.get_output()
print(best_run)
print(fitted_model)
Menguji akurasi model terbaik
Gunakan model terbaik untuk menjalankan prediksi pada kumpulan data pengujian guna memprediksi tarif taksi. Fungsi ini predict menggunakan model terbaik dan memprediksi nilai y, biaya perjalanan, dari himpunan x_test data.
Kode berikut mencetak 10 nilai biaya pertama yang diprediksi dari himpunan y_predict data:
y_test = x_test.pop("totalAmount")
y_predict = fitted_model.predict(x_test)
print(y_predict[:10])
Hitung root mean squared error hasilnya. Konversikan y_test dataframe menjadi daftar dan bandingkan dengan nilai yang diprediksi. Fungsi ini mean_squared_error mengambil dua array nilai dan menghitung kesalahan kuadrat rata-rata di antaranya. Mengambil akar kuadrat dari hasil memberikan kesalahan dalam unit yang sama dengan variabel y, biaya. Metrik ini menunjukkan kira-kira seberapa jauh prediksi tarif taksi dari nilai tarif aktual.
from sklearn.metrics import mean_squared_error
from math import sqrt
y_actual = y_test.values.flatten().tolist()
rmse = sqrt(mean_squared_error(y_actual, y_predict))
rmse
Jalankan kode berikut untuk menghitung kesalahan persentase absolut rata-rata (MAPE) dengan menggunakan kumpulan data y_actual dan y_predict penuh. Metrik ini menghitung perbedaan absolut antara setiap nilai yang diprediksi dan nilai sesungguhnya, serta menjumlahkan semua perbedaan. Lalu mengekspresikan jumlah tersebut sebagai persentase dari total nilai sesungguhnya.
sum_actuals = sum_errors = 0
for actual_val, predict_val in zip(y_actual, y_predict):
abs_error = actual_val - predict_val
if abs_error < 0:
abs_error = abs_error * -1
sum_errors = sum_errors + abs_error
sum_actuals = sum_actuals + actual_val
mean_abs_percent_error = sum_errors / sum_actuals
print("Model MAPE:")
print(mean_abs_percent_error)
print()
print("Model Accuracy:")
print(1 - mean_abs_percent_error)
Berikut output-nya:
Model MAPE:
0.14353867606052823
Model Accuracy:
0.8564613239394718
Dari dua metrik akurasi prediksi, Anda melihat bahwa model ini cukup baik dalam memprediksi tarif taksi dari fitur kumpulan data, biasanya dalam +- $4.00, dan sekitar 15% kesalahan.
Proses pengembangan model pembelajaran mesin tradisional sangat intensif sumber daya. Ini membutuhkan pengetahuan domain yang signifikan dan investasi waktu untuk menjalankan dan membandingkan hasil puluhan model. Menggunakan pembelajaran mesin otomatis adalah cara yang bagus untuk menguji dengan cepat banyak model berbeda untuk skenario Anda.
Membersihkan sumber daya
Jika Anda tidak berencana untuk mengerjakan tutorial Azure Pembelajaran Mesin lainnya, selesaikan langkah-langkah berikut untuk menghapus sumber daya yang tidak lagi Anda butuhkan.
Menghentikan komputasi
Jika Anda menggunakan komputasi, Anda dapat menghentikan komputer virtual saat tidak menggunakannya dan mengurangi biaya Anda:
Buka ruang kerja Anda di studio Azure Pembelajaran Mesin, dan pilih Komputasi.
Dalam daftar, pilih komputasi yang ingin Anda hentikan, lalu pilih Hentikan.
Ketika Anda siap untuk menggunakan komputasi lagi, Anda dapat menghidupkan ulang komputer virtual.
Menghapus sumber daya lain
Jika Anda tidak berencana untuk menggunakan sumber daya yang Anda buat dalam tutorial ini, Anda dapat menghapusnya dan menghindari dikenakan biaya lebih lanjut.
Ikuti langkah-langkah ini untuk menghapus grup sumber daya dan semua sumber daya:
Di portal Microsoft Azure, buka Grup sumber daya.
Dalam daftar, pilih grup sumber daya yang Anda buat dalam tutorial ini, lalu pilih Hapus grup sumber daya.
Pada perintah konfirmasi, masukkan nama grup sumber daya, lalu pilih Hapus.
Jika Anda ingin menyimpan grup sumber daya, dan menghapus satu ruang kerja saja, ikuti langkah-langkah berikut:
Di portal Azure, buka grup sumber daya yang berisi ruang kerja yang ingin Anda hapus.
Pilih ruang kerja, pilih Properti, lalu pilih Hapus.
Langkah selanjutnya
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk