Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
BERLAKU UNTUK: Ekstensi ml Azure CLI v2 (saat ini)
Ekstensi ml Azure CLI v2 (saat ini)
Dalam artikel ini, Anda mempelajari cara membuat dan menjalankan alur pembelajaran mesin dengan menggunakan Azure CLI dan komponen. Anda dapat membuat alur tanpa menggunakan komponen, tetapi komponen memberikan fleksibilitas dan mengaktifkan penggunaan kembali. Alur Azure Machine Learning dapat didefinisikan dalam YAML dan dijalankan dari CLI, ditulis di Python, atau disusun di Perancang studio Azure Machine Learning melalui antarmuka pengguna seret dan letakkan. Artikel ini berfokus pada CLI.
Prasyarat
Sebuah langganan Azure. Jika Anda tidak memilikinya, buat akun gratis sebelum memulai. Coba versi gratis atau berbayar Azure Machine Learning.
Ekstensi Azure CLI untuk Pembelajaran Mesin, diinstal dan disiapkan.
Klon dari repositori contoh. Anda dapat menggunakan perintah ini untuk mengkloning repositori:
git clone https://github.com/Azure/azureml-examples --depth 1 cd azureml-examples/cli/jobs/pipelines-with-components/basics
Bahan baca awal yang disarankan
Buat pipeline pertama Anda dengan komponen
Pertama, Anda akan membuat alur dengan komponen dengan menggunakan contoh. Melakukannya memberi Anda kesan awal tentang seperti apa alur dan komponen di Azure Machine Learning.
cli/jobs/pipelines-with-components/basics Di direktori azureml-examples repositori, buka 3b_pipeline_with_data subdirektori. Ada tiga jenis file dalam direktori ini. Ini adalah file yang perlu Anda buat saat membuat alur Anda sendiri.
pipeline.yml. File YAML ini mendefinisikan alur pembelajaran mesin. Ini menjelaskan cara memecah tugas pembelajaran mesin penuh menjadi alur kerja multistep. Misalnya, pertimbangkan tugas pembelajaran mesin sederhana menggunakan data historis untuk melatih model prakiraan penjualan. Anda mungkin ingin membuat alur kerja berurutan yang berisi langkah-langkah pemrosesan data, pelatihan model, dan evaluasi model. Setiap langkah adalah komponen yang memiliki antarmuka yang terdefinisi dengan baik dan dapat dikembangkan, diuji, dan dioptimalkan secara independen. YAML alur juga menentukan bagaimana langkah-langkah anak tersambung ke langkah lain dalam alur. Misalnya, langkah pelatihan model menghasilkan file model dan file model diteruskan ke langkah evaluasi model.
component.yml. File YAML ini menentukan komponen. Mereka berisi informasi berikut:
- Metadata: Nama, nama tampilan, versi, deskripsi, jenis, dan sebagainya. Metadata membantu menjelaskan dan mengelola komponen.
- Antarmuka: Input dan output. Misalnya, komponen pelatihan model mengambil data pelatihan dan jumlah epoch sebagai input dan menghasilkan file model terlatih sebagai output. Setelah antarmuka ditentukan, tim yang berbeda dapat mengembangkan dan menguji komponen secara independen.
- Perintah, kode, dan lingkungan: Perintah, kode, dan lingkungan untuk menjalankan komponen. Perintah adalah perintah shell untuk menjalankan komponen. Kode biasanya mengacu pada direktori kode sumber. Lingkungan dapat berupa lingkungan Azure Machine Learning (yang dikelola atau dibuat oleh pelanggan), citra Docker, atau lingkungan conda.
component_src. Ini adalah direktori kode sumber untuk komponen tertentu. Mereka berisi kode sumber yang dijalankan dalam komponen. Anda dapat menggunakan bahasa pilihan Anda, termasuk Python, R, dan lainnya. Kode harus dijalankan oleh perintah shell. Kode sumber dapat mengambil beberapa input dari baris perintah shell untuk mengontrol bagaimana langkah ini dijalankan. Misalnya, langkah pelatihan mungkin melibatkan data pelatihan, tingkat pembelajaran, dan jumlah epoch dalam mengendalikan proses pelatihan. Argumen perintah shell digunakan untuk meneruskan input dan output ke kode.
Sekarang Anda akan membuat alur dengan menggunakan 3b_pipeline_with_data contoh . Setiap file dijelaskan lebih lanjut di bagian berikut.
Pertama, cantumkan sumber daya komputasi yang tersedia dengan menggunakan perintah berikut:
az ml compute list
Jika Anda tidak memilikinya, buat kluster yang disebut cpu-cluster dengan menjalankan perintah ini:
Catatan
Lewati langkah ini untuk menggunakan komputasi tanpa server.
az ml compute create -n cpu-cluster --type amlcompute --min-instances 0 --max-instances 10
Sekarang buat pekerjaan alur yang ditentukan dalam file pipeline.yml dengan menjalankan perintah berikut. Target komputasi dirujuk dalam file pipeline.yml sebagai azureml:cpu-cluster. Jika target komputasi Anda menggunakan nama yang berbeda, jangan lupa untuk memperbaruinya dalam file pipeline.yml.
az ml job create --file pipeline.yml
Anda harus menerima kamus JSON dengan informasi tentang pekerjaan alur, termasuk:
| Kunci | Deskripsi |
|---|---|
name |
Nama pekerjaan berbasis GUID. |
experiment_name |
Nama tempat pekerjaan akan diatur di studio. |
services.Studio.endpoint |
URL untuk memantau dan meninjau pekerjaan alur. |
status |
Status pekerjaan. Mungkin akan pada Preparing saat ini. |
services.Studio.endpoint Buka URL untuk melihat visualisasi alur:
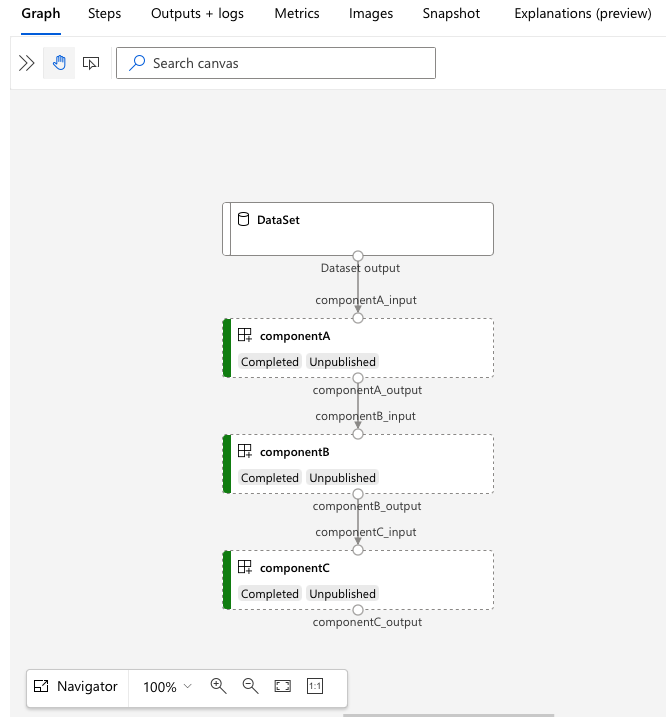
Memahami YAML definisi alur
Sekarang Anda akan melihat definisi alur dalam file 3b_pipeline_with_data/pipeline.yml .
Catatan
Untuk menggunakan komputasi tanpa server, ganti default_compute: azureml:cpu-cluster dengan default_compute: azureml:serverless dalam file ini.
$schema: https://azuremlschemas.azureedge.net/latest/pipelineJob.schema.json
type: pipeline
display_name: 3b_pipeline_with_data
description: Pipeline with 3 component jobs with data dependencies
settings:
default_compute: azureml:cpu-cluster
outputs:
final_pipeline_output:
mode: rw_mount
jobs:
component_a:
type: command
component: ./componentA.yml
inputs:
component_a_input:
type: uri_folder
path: ./data
outputs:
component_a_output:
mode: rw_mount
component_b:
type: command
component: ./componentB.yml
inputs:
component_b_input: ${{parent.jobs.component_a.outputs.component_a_output}}
outputs:
component_b_output:
mode: rw_mount
component_c:
type: command
component: ./componentC.yml
inputs:
component_c_input: ${{parent.jobs.component_b.outputs.component_b_output}}
outputs:
component_c_output: ${{parent.outputs.final_pipeline_output}}
# mode: upload
Tabel berikut ini menjelaskan field yang paling umum digunakan dari skema YAML pipeline. Untuk mempelajari lebih lanjut , lihat skema YAML alur lengkap.
| Kunci | Deskripsi |
|---|---|
type |
Diperlukan. Jenis pekerjaan. Ini harus pipeline untuk pekerjaan alur. |
display_name |
Nama tampilan pekerjaan jalur pengolahan di antarmuka pengguna studio. Dapat diedit di antarmuka pengguna studio. Ini tidak harus unik untuk semua pekerjaan dalam ruang kerja. |
jobs |
Diperlukan. Kamus pekerjaan individual untuk dijalankan sebagai langkah-langkah dalam jalur pemrosesan. Pekerjaan ini dianggap sebagai pekerjaan turunan dari pekerjaan alur induk. Dalam rilis saat ini, jenis tugas yang didukung dalam proses adalah command dan sweep. |
inputs |
Kamus input untuk pekerjaan rangkaian. Kunci merujuk pada nama untuk input dalam konteks tugas, dan nilainya adalah nilai input. Anda dapat merujuk masukan alur kerja ini dengan masukan pekerjaan langkah individual di dalam alur kerja dengan ekspresi ${{ parent.inputs.<input_name> }}. |
outputs |
Kamus konfigurasi output dari pekerjaan pemrosesan alur. Kuncinya adalah nama untuk output dalam konteks pekerjaan, dan nilainya adalah konfigurasi output. Anda dapat mereferensikan output alur ini dengan output pekerjaan langkah individual dalam alur dengan menggunakan ${{ parents.outputs.<output_name> }} ekspresi . |
Contoh 3b_pipeline_with_data berisi alur tiga langkah.
- Tiga langkah tersebut didefinisikan di bagian
jobs. Ketiga langkah tersebut berjeniscommand. Definisi setiap langkah berada dalam file yang sesuaicomponent*.yml. Anda dapat melihat file YAML komponen di direktori 3b_pipeline_with_data .componentA.ymldijelaskan di bagian berikutnya. - Alur ini memiliki dependensi data, yang umum dalam alur dunia nyata. Komponen A mengambil input data dari folder lokal di bawah
./data(baris 18-21) dan meneruskan outputnya ke komponen B (baris 29). Output Komponen A dapat dirujuk sebagai${{parent.jobs.component_a.outputs.component_a_output}}. -
default_computemenentukan komputasi default untuk alur. Jika komponen di bawahjobsmenentukan komputasi yang berbeda, pengaturan khusus komponen dihormati.

Membaca dan menulis data dalam pipa
Salah satu skenario umum adalah membaca dan menulis data dalam pipa. Di Azure Machine Learning, Anda menggunakan skema yang sama untuk membaca dan menulis data untuk semua jenis pekerjaan (pekerjaan alur, pekerjaan perintah, dan pekerjaan pembersihan). Berikut ini adalah contoh penggunaan data dalam alur untuk skenario umum:
- Data lokal
- File web dengan URL publik
- Azure Pembelajaran Mesin datastore dan jalur
- Aset data Azure Pembelajaran Mesin
Memahami definisi komponen YAML
Berikut adalah file componentA.yml , contoh YAML yang menentukan komponen:
$schema: https://azuremlschemas.azureedge.net/latest/commandComponent.schema.json
type: command
name: component_a
display_name: componentA
version: 1
inputs:
component_a_input:
type: uri_folder
outputs:
component_a_output:
type: uri_folder
code: ./componentA_src
environment:
image: python
command: >-
python hello.py --componentA_input ${{inputs.component_a_input}} --componentA_output ${{outputs.component_a_output}}
Tabel ini menentukan bidang YAML komponen yang paling umum digunakan. Untuk mempelajari lebih lanjut , lihat skema YAML komponen lengkap.
| Kunci | Deskripsi |
|---|---|
name |
Diperlukan. Nama komponen. Ini harus unik di seluruh ruang kerja Azure Machine Learning. Ini harus dimulai dengan huruf kecil. Huruf kecil, angka, dan garis bawah (_) diperbolehkan. Panjang maksimum adalah 255 karakter. |
display_name |
Nama tampilan komponen di antarmuka pengguna studio. Ini tidak harus unik dalam ruang kerja. |
command |
Diperlukan. Perintah yang akan dijalankan. |
code |
Jalur lokal ke direktori kode sumber yang akan diunggah dan digunakan untuk komponen. |
environment |
Diperlukan. Lingkungan yang digunakan untuk menjalankan komponen. |
inputs |
Kamus komponen input. Kuncinya adalah nama untuk input dalam konteks komponen, dan nilainya adalah definisi input komponen. Anda dapat mereferensikan input dalam perintah dengan menggunakan ${{ inputs.<input_name> }} ekspresi . |
outputs |
Kamus keluaran komponen. Kuncinya adalah nama untuk output dalam konteks komponen, dan nilainya adalah definisi output komponen. Anda dapat mereferensikan output dalam perintah dengan menggunakan ${{ outputs.<output_name> }} ekspresi . |
is_deterministic |
Apakah akan menggunakan kembali hasil pekerjaan sebelumnya jika input komponen tidak berubah. Nilai defaultnya adalah true. Pengaturan ini juga dikenal sebagai penggunaan kembali secara default. Skenario umum saat diatur ke false adalah memaksa memuat ulang data dari penyimpanan cloud atau URL. |
Dalam contoh dalam 3b_pipeline_with_data/componentA.yml, komponen A memiliki satu input data dan satu output data, yang dapat disambungkan ke langkah lain dalam alur induk. Semua file di bagian code dalam komponen YAML akan diunggah ke Azure Machine Learning saat pekerjaan pipeline dikirimkan. Dalam contoh ini, file di bawah ./componentA_src akan diunggah. (Baris 16 dalam componentA.yml.) Anda dapat melihat kode sumber yang diunggah di antarmuka pengguna studio: klik dua kali langkah componentA di grafik dan buka tab Kode , seperti yang ditunjukkan pada cuplikan layar berikut. Anda dapat melihat bahwa ini adalah skrip hello-world yang melakukan pencetakan sederhana, dan menulis tanggal dan waktu saat ini ke jalur componentA_output. Komponen mengambil input dan menyediakan output melalui baris perintah. Ini ditangani di hello.py melalui argparse.

Input dan output
Input dan output menentukan antarmuka komponen. Input dan output dapat berupa nilai literal (dari jenis string, , number, integeratau boolean) atau objek yang berisi skema input.
Input objek (dari jenis uri_file, uri_folder, mltable, mlflow_model, atau custom_model) dapat tersambung ke langkah lain dalam pekerjaan alur induk untuk meneruskan data/model ke langkah lain. Dalam grafik pipeline, input tipe objek dirender sebagai titik koneksi.
Input nilai harfiah (string, number, integer, boolean) adalah parameter yang dapat Anda teruskan ke komponen saat runtime. Anda dapat menambahkan nilai default input harfiah di default bidang . Untuk jenis number dan integer, Anda juga dapat menambahkan nilai minimum dan maksimum dengan menggunakan kolom min dan max. Jika nilai input kurang dari minimum atau lebih dari maksimum, alur gagal pada validasi. Validasi dilakukan sebelum Anda mengirimkan pekerjaan pipeline, yang dapat menghemat waktu. Validasi berfungsi untuk CLI, Python SDK, dan UI Perancang. Cuplikan layar berikut menunjukkan contoh validasi di UI Perancang. Demikian pula, Anda dapat menentukan nilai yang diizinkan dalam enum bidang.

Jika Anda ingin menambahkan input ke komponen, Anda perlu melakukan pengeditan di tiga tempat:
- Bidang
inputspada komponen YAML. - Bidang
commandpada komponen YAML. - Kode sumber pada komponen untuk menangani masukan melalui baris perintah.
Lokasi ini ditandai dengan kotak hijau di cuplikan layar sebelumnya.
Untuk mempelajari selengkapnya tentang input dan output, lihat Mengelola input dan output untuk komponen dan alur.
Lingkungan
Lingkungan adalah lingkungan tempat komponen berjalan. Ini bisa berupa platform Azure Machine Learning (yang dikurasi atau yang terdaftar khusus), citra Docker, atau lingkungan conda. Lihat contoh berikut:
-
Aset lingkungan terdaftar di Azure Machine Learning. Lingkungan dirujuk dalam komponen dengan sintaks
azureml:<environment-name>:<environment-version>. - Citra Docker publik.
- File Conda. File conda perlu digunakan bersama dengan gambar dasar.
Mendaftarkan komponen untuk digunakan kembali dan berbagi
Meskipun beberapa komponen khusus untuk alur tertentu, manfaat nyata komponen berasal dari penggunaan kembali dan berbagi. Anda dapat mendaftarkan komponen di ruang kerja Azure Machine Learning agar tersedia untuk digunakan kembali. Komponen terdaftar mendukung penerapan versi otomatis sehingga Anda dapat memperbarui komponen tetapi memastikan bahwa alur yang memerlukan versi yang lebih lama akan terus berfungsi.
Di repositori azureml-examples, buka folder cli/jobs/pipelines-with-components/basics/1b_e2e_registered_components.
Untuk mendaftarkan model, gunakan perintah az ml component create:
az ml component create --file train.yml
az ml component create --file score.yml
az ml component create --file eval.yml
Setelah perintah ini berjalan hingga selesai, Anda dapat melihat komponen di studio, di bawahKomponen>:

Pilih komponen. Anda melihat informasi terperinci untuk setiap versi komponen.
Tab Detail memperlihatkan informasi dasar seperti nama komponen, siapa yang membuatnya, dan versinya. Ada bidang yang dapat diedit untuk Tag dan Deskripsi. Anda dapat menggunakan tag untuk menambahkan kata kunci pencarian. Bidang deskripsi mendukung pemformatan Markdown. Anda harus menggunakannya untuk menjelaskan fungsionalitas komponen dan penggunaan dasar Anda.
Pada tab Pekerjaan , Anda akan melihat riwayat semua pekerjaan yang menggunakan komponen.
Menggunakan komponen terdaftar di pekerjaan alur file YAML
Sekarang Anda akan menggunakan 1b_e2e_registered_components sebagai contoh bagaimana menggunakan komponen terdaftar dalam pipeline YAML.
1b_e2e_registered_components Buka direktori dan buka pipeline.yml file. Kunci dan nilai-nilai di bidang inputs dan outputs mirip dengan yang sudah dibahas. Satu-satunya perbedaan yang signifikan adalah nilai bidang component dalam entri jobs.<job_name>.component. Nilainya component dalam bentuk azureml:<component_name>:<component_version>. Definisi train-job , misalnya, menentukan bahwa versi terbaru komponen my_train terdaftar harus digunakan:
type: command
component: azureml:my_train@latest
inputs:
training_data:
type: uri_folder
path: ./data
max_epocs: ${{parent.inputs.pipeline_job_training_max_epocs}}
learning_rate: ${{parent.inputs.pipeline_job_training_learning_rate}}
learning_rate_schedule: ${{parent.inputs.pipeline_job_learning_rate_schedule}}
outputs:
model_output: ${{parent.outputs.pipeline_job_trained_model}}
services:
my_vscode:
Mengelola komponen
Anda dapat memeriksa detail komponen dan mengelola komponen dengan menggunakan CLI v2. Gunakan az ml component -h untuk mendapatkan instruksi terperinci tentang perintah komponen. Tabel berikut mencantumkan semua perintah yang tersedia. Lihat contoh lainnya dalam referensi Azure CLI.
| Perintah | Deskripsi |
|---|---|
az ml component create |
Buat komponen. |
az ml component list |
Mencantumkan komponen di ruang kerja. |
az ml component show |
Tampilkan detail komponen. |
az ml component update |
Memperbarui komponen. Hanya beberapa bidang (deskripsi, display_name) yang mendukung pembaruan. |
az ml component archive |
Mengarsipkan kontainer komponen. |
az ml component restore |
Memulihkan komponen yang diarsipkan. |