Buat dan jalankan saluran pembelajaran mesin dengan Azure Machine Learning SDK
BERLAKU UNTUK: Python SDK azureml v1
Python SDK azureml v1
Dalam artikel ini, Anda mempelajari cara membuat dan menjalankan saluran pembelajaran mesin dengan menggunakan Azure Machine Learning SDK. Gunakan Saluran ML untuk membuat alur kerja yang merangkai berbagai fase ML. Kemudian, publikasikan saluran tersebut untuk kemudian diakses atau dibagikan dengan orang lain. Lacak saluran ML untuk melihat kinerja model Anda di dunia nyata dan untuk mendeteksi drift data. Saluran ML sangat ideal untuk skenario penilaian batch, menggunakan berbagai komputasi, menggunakan kembali langkah-langkah alih-alih menjalankan, dan berbagi alur kerja ML dengan orang lain.
Artikel ini bukan tutorial. Untuk panduan tentang membuat saluran pertama Anda, lihat Tutorial: Membuat saluran Azure Machine Learning untuk penilaian batch atau Menggunakan ML otomatis dalam saluran Azure Machine Learning di Python.
Meskipun Anda dapat menggunakan jenis alur berbeda yang disebut Alur Azure untuk otomatisasi CI/CD tugas ML, jenis alur tersebut tidak disimpan di ruang kerja Anda. Bandingkan saluran yang berbeda ini.
Saluran ML yang Anda buat terlihat oleh anggota ruang kerja Azure Machine Learning Anda.
Saluran ML dijalankan pada target komputasi (lihat Apa itu target komputasi di Azure Machine Learning). Saluran dapat membaca dan menulis data ke dan dari lokasi Azure Storage yang didukung.
Jika Anda tidak memiliki langganan Azure, buat akun gratis sebelum Anda memulai. Coba versi gratis atau berbayar Azure Machine Learning.
Prasyarat
Ruang kerja Azure Machine Learning. Membuat sumber daya ruang kerja.
Konfigurasikan lingkungan pengembangan Anda untuk menginstal Azure Machine Learning SDK, atau gunakan instans komputasi Azure Machine Learning dengan SDK yang sudah diinstal.
Mulailah dengan melampirkan ruang kerja Anda:
import azureml.core
from azureml.core import Workspace, Datastore
ws = Workspace.from_config()
Menyiapkan sumber daya pembelajaran mesin
Buat sumber daya yang diperlukan untuk menjalankan saluran ML:
Siapkan penyimpanan data yang digunakan untuk mengakses data yang diperlukan dalam langkah-langkah saluran.
Mengonfigurasi objek
Datasetuntuk menunjuk ke data persisten yang berada di, atau dapat diakses, sebuah datastore. Mengonfigurasi objekOutputFileDatasetConfiguntuk data sementara yang dilewatkan di antara langkah-langkah salulran.Siapkan target komputasi pada tempat langkah-langkah saluran Anda akan berjalan.
Siapkan penyimpanan data
Sebuah datastore menyimpan data untuk diakses saluran. Setiap ruang kerja memiliki datastore default. Anda dapat mendaftarkan lebih banyak datastore.
Saat Anda membuat ruang kerja, Azure Files dan Azure Blob dilampirkan ke ruang kerja. Default datastore didaftarkan untuk menyambungkan ke penyimpanan Azure Blob. Untuk mempelajari selengkapnya, lihat Memutuskan kapan menggunakan Azure Files, Azure Blobs, atau Azure Disks.
# Default datastore
def_data_store = ws.get_default_datastore()
# Get the blob storage associated with the workspace
def_blob_store = Datastore(ws, "workspaceblobstore")
# Get file storage associated with the workspace
def_file_store = Datastore(ws, "workspacefilestore")
Langkah-langkah umumnya mengkonsumsi data dan menghasilkan data output. Satu langkah dapat membuat data seperti model, direktori dengan model dan file dependen, atau data sementara. Data ini kemudian tersedia untuk langkah lain nanti di saluran. Untuk mempelajari selengkapnya tentang menyambungkan saluran ke data Anda, lihat artikel Cara Mengakses Data dan Cara Mendaftarkan Kumpulan Data.
Mengonfigurasi data Dataset dan OutputFileDatasetConfig dengan objek
Cara yang disukai untuk memberikan data ke saluran adalah kumpulan data objek. Objek Dataset menunjuk ke data yang tinggal di atau dapat diakses dari pusat data atau di URL Web. Kelas Dataset bersifat abstrak, jadi Anda akan membuat instans dari FileDataset (merujuk ke satu atau beberapa file) atau TabularDataset yang dibuat oleh salah satu atau beberapa file dengan kolom data yang dibatasi.
Anda membuat metode Dataset penggunaan seperti from_files atau from_delimited_files.
from azureml.core import Dataset
my_dataset = Dataset.File.from_files([(def_blob_store, 'train-images/')])
Data menengah (atau output dari langkah) diwakili oleh objek OutputFileDatasetConfig. output_data1 diproduksi sebagai output dari sebuah langkah. Secara opsional, data ini dapat didaftarkan sebagai kumpulan data dengan panggilan register_on_complete. Jika Anda membuat langkah OutputFileDatasetConfig dalam satu langkah dan menggunakannya sebagai input ke langkah lain, dependensi data di antara langkah-langkah tersebut membuat urutan eksekusi implisit dalam saluran.
Objek-objekOutputFileDatasetConfig mengembalikan direktori, dan secara default menulis output ke penyimpanan data default ruang kerja.
from azureml.data import OutputFileDatasetConfig
output_data1 = OutputFileDatasetConfig(destination = (datastore, 'outputdataset/{run-id}'))
output_data_dataset = output_data1.register_on_complete(name = 'prepared_output_data')
Penting
Data perantara yang disimpan menggunakan OutputFileDatasetConfig tidak otomatis dihapus oleh Azure.
Anda harus menghapus data menengah secara terprogram di akhir saluran run, menggunakan datastore dengan kebijakan penyimpanan data singkat, atau secara teratur melakukan pembersihan manual.
Tip
Hanya unggah file yang relevan dengan pekerjaan yang ada. Setiap perubahan pada file dalam direktori data akan dianggap sebagai alasan untuk menjalankan kembali langkah tersebut saat alur dijalankan di lain waktu meski penggunaan kembali ditentukan.
Membuat target komputasi
Dalam Azure Machine Learning, istilah komputasi (atau target komputasi) mengacu pada komputer atau kluster yang melakukan langkah komputasi dalam alur pembelajaran mesin Anda. Lihat target komputasi untuk pelatihan model untuk daftar lengkap target komputasi dan Buat target komputasi tentang cara membuat dan melampirkannya ke ruang kerja Anda. Proses untuk membuat dan atau melampirkan target komputasi sama, baik Anda melatih model atau menjalankan langkah alur. Setelah Anda membuat dan melampirkan target komputasi Anda, gunakan ComputeTarget objek di langkah saluran Anda.
Penting
Melakukan operasi manajemen pada target komputasi tidak didukung dari pekerjaan jarak jauh di dalam. Karena alur pembelajaran mesin dikirimkan sebagai tugas jarak jauh, jangan gunakan operasi manajemen pada target komputasi dari dalam alur.
Komputasi Azure Machine Learning
Anda dapat membuat komputasi Azure Machine Learning untuk menjalankan langkah-langkah Anda. Kode untuk target komputasi lainnya serupa, dengan parameter yang sedikit berbeda, tergantung pada jenisnya.
from azureml.core.compute import ComputeTarget, AmlCompute
compute_name = "aml-compute"
vm_size = "STANDARD_NC6"
if compute_name in ws.compute_targets:
compute_target = ws.compute_targets[compute_name]
if compute_target and type(compute_target) is AmlCompute:
print('Found compute target: ' + compute_name)
else:
print('Creating a new compute target...')
provisioning_config = AmlCompute.provisioning_configuration(vm_size=vm_size, # STANDARD_NC6 is GPU-enabled
min_nodes=0,
max_nodes=4)
# create the compute target
compute_target = ComputeTarget.create(
ws, compute_name, provisioning_config)
# Can poll for a minimum number of nodes and for a specific timeout.
# If no min node count is provided it will use the scale settings for the cluster
compute_target.wait_for_completion(
show_output=True, min_node_count=None, timeout_in_minutes=20)
# For a more detailed view of current cluster status, use the 'status' property
print(compute_target.status.serialize())
Mengonfigurasi lingkungan menjalankan pelatihan
Langkah selanjutnya adalah memastikan bahwa jalannya pelatihan jarak jauh memiliki semua dependensi yang dibutuhkan oleh langkah-langkah pelatihan. Dependensi dan konteks waktu berjalan diatur dengan membuat dan mengonfigurasi satu RunConfiguration objek.
from azureml.core.runconfig import RunConfiguration
from azureml.core.conda_dependencies import CondaDependencies
from azureml.core import Environment
aml_run_config = RunConfiguration()
# `compute_target` as defined in "Azure Machine Learning compute" section above
aml_run_config.target = compute_target
USE_CURATED_ENV = True
if USE_CURATED_ENV :
curated_environment = Environment.get(workspace=ws, name="AzureML-sklearn-0.24-ubuntu18.04-py37-cpu")
aml_run_config.environment = curated_environment
else:
aml_run_config.environment.python.user_managed_dependencies = False
# Add some packages relied on by data prep step
aml_run_config.environment.python.conda_dependencies = CondaDependencies.create(
conda_packages=['pandas','scikit-learn'],
pip_packages=['azureml-sdk', 'azureml-dataset-runtime[fuse,pandas]'],
pin_sdk_version=False)
Kode di atas memperlihatkan dua opsi untuk menangani dependensi. Seperti yang disajikan, dengan USE_CURATED_ENV = True, konfigurasi didasarkan pada lingkungan yang direkayasai. Lingkungan yang terbentuk adalah "disiapkan" dengan perpustakaan umum yang saling bergantung dan bisa lebih cepat dibawa secara daring. Lingkungan yang direkayasa telah membuat gambar Docker di Microsoft Container Registry. Untuk informasi selengkapnya, lihat Lingkungan Azure Machine Learning terkuratori.
Jalur yang diambil jika Anda merubah USE_CURATED_ENV ke False menampilkan pola untuk secara eksplisit mengatur dependensi Anda. Dalam skenario itu, gambar Docker kustom baru akan dibuat dan didaftar dalam Azure Container Registry dalam grup sumber daya Anda (lihat Pengenalan registri kontainer Docker pribadi di Azure). Membangun dan mendaftarkan gambar ini bisa memakan waktu beberapa menit.
Membentuk langkah-langkah alur Anda
Setelah sumber daya komputasi dan lingkungan dibuat, Anda siap untuk menentukan langkah-langkah alur Anda. Ada banyak langkah bawaan yang tersedia melalui Azure Machine Learning SDK, seperti yang Anda lihat pada dokumentasi referensi untuk azureml.pipeline.steps paket tersebut. Kelas yang paling fleksibel adalah PythonScriptStep,yang menjalankan skrip Python.
from azureml.pipeline.steps import PythonScriptStep
dataprep_source_dir = "./dataprep_src"
entry_point = "prepare.py"
# `my_dataset` as defined above
ds_input = my_dataset.as_named_input('input1')
# `output_data1`, `compute_target`, `aml_run_config` as defined above
data_prep_step = PythonScriptStep(
script_name=entry_point,
source_directory=dataprep_source_dir,
arguments=["--input", ds_input.as_download(), "--output", output_data1],
compute_target=compute_target,
runconfig=aml_run_config,
allow_reuse=True
)
Kode di atas menunjukkan langkah saluran awal yang khas. Kode persiapan data Anda berada dalam subdirektori (dalam contoh ini,"prepare.py" dalam direktori "./dataprep.src"). Sebagai bagian dari proses pembuatan saluran, direktori ini di-zip dan diunggah ke compute_target dan langkah menjalankan skrip yang ditentukan sebagai nilai untuk script_name.
Nilai argumentsmenentukan input dan output langkah. Dalam contoh di atas, data dasar adalah kumpulan data my_dataset. Data yang sesuai akan diunduh ke sumber daya komputasi karena kode menentukannya sebagai as_download(). Skrip prepare.pymengerjakan apa pun tugas transformasi data yang sesuai dengan tugas yang ada dan menghasilkan data ke output_data1, dari jenis OutputFileDatasetConfig. Untuk informasi selengkapnya, lihat Memindahkan data ke dalam dan di antara langkah-langkah saluran ML (Python).
Langkah akan berjalan pada mesin yang ditentukan oleh compute_target, menggunakan konfigurasi aml_run_config.
Penggunaan kembali hasil sebelumnya ( allow_reuse ) adalah kunci ketika menggunakan saluran di lingkungan kolaboratif karena menghilangkan tayangan ulang yang tidak perlu menawarkan kelincahan. Penggunaan kembali adalah perilaku default saat script_name, input, dan parameter langkah tetap sama. Ketika penggunaan kembali diperbolehkan, hasil dari eksekusi sebelumnya segera dikirim ke langkah berikutnya. Jika allow_reuse diatur ke False, eksekusi baru akan selalu dihasilkan untuk langkah ini selama eksekusi saluran.
Dimungkinkan untuk membuat saluran dengan satu langkah, tetapi hampir selalu Anda akan memilih untuk membagi keseluruhan proses Anda menjadi beberapa langkah. Misalnya, Anda mungkin memiliki langkah-langkah untuk persiapan data, pelatihan, perbandingan model, dan penyebaran. Misalnya, orang mungkin membayangkan bahwa setelah data_prep_step yang ditentukan di atas, langkah berikutnya mungkin adalah pelatihan:
train_source_dir = "./train_src"
train_entry_point = "train.py"
training_results = OutputFileDatasetConfig(name = "training_results",
destination = def_blob_store)
train_step = PythonScriptStep(
script_name=train_entry_point,
source_directory=train_source_dir,
arguments=["--prepped_data", output_data1.as_input(), "--training_results", training_results],
compute_target=compute_target,
runconfig=aml_run_config,
allow_reuse=True
)
Kode di atas mirip dengan kode dalam langkah persiapan data. Kode pelatihan berada dalam direktori yang terpisah dari kode persiapan data. OutputFileDatasetConfigOutput langkah persiapan data, output_data1digunakan sebagai input ke langkah pelatihan. Objek OutputFileDatasetConfig baru, training_results dibuat untuk menyimpan hasil untuk perbandingan atau langkah penyebaran selanjutnya.
Untuk contoh kode lainnya, lihat cara membuat saluran ML dua langkah dan cara menulis data kembali ke penyimpanan data setelah menjalankan penyelesaian.
Setelah Anda menentukan langkah-langkah, Anda menyusun saluran dengan menggunakan beberapa atau semua langkah tersebut.
Catatan
Tidak ada file atau data yang diunggah ke Azure Machine Learning saat Anda menentukan langkah-langkah atau menyusun saluran. File-file ini diunggah saat Anda memanggil Experiment.submit().
# list of steps to run (`compare_step` definition not shown)
compare_models = [data_prep_step, train_step, compare_step]
from azureml.pipeline.core import Pipeline
# Build the pipeline
pipeline1 = Pipeline(workspace=ws, steps=[compare_models])
Menggunakan kumpulan data
Himpunan data yang dibuat dari penyimpanan Azure Blob, Azure Files, ADLS Gen1, Azure Data Lake Storage Gen2, Azure SQL Database, dan Azure Database for PostgreSQL dapat digunakan sebagai input untuk langkah alur apa pun. Anda dapat menulis output ke DataTransferStep, DatabricksStep, atau jika Anda ingin menulis data ke datastore tertentu menggunakan OutputFileDatasetConfig.
Penting
Menulis data output kembali ke penyimpanan data menggunakan OutputFileDatasetConfig hanya didukung untuk Azure Blob, Azure File Share, ADLS Gen 1 dan Gen 2.
dataset_consuming_step = PythonScriptStep(
script_name="iris_train.py",
inputs=[iris_tabular_dataset.as_named_input("iris_data")],
compute_target=compute_target,
source_directory=project_folder
)
Anda kemudian mengambil kumpulan data di saluran Anda dengan menggunakan kamus Run.input_datasets anda.
# iris_train.py
from azureml.core import Run, Dataset
run_context = Run.get_context()
iris_dataset = run_context.input_datasets['iris_data']
dataframe = iris_dataset.to_pandas_dataframe()
Garis Run.get_context() patut disorot. Fungsi ini mengambil Run yang mewakili jalankan eksperimental saat ini. Dalam sampel di atas, kami menggunakannya untuk mengambil kumpulan data terdaftar. Penggunaan umum lain dari objek Run ini adalah untuk mengambil eksperimen itu sendiri dan ruang kerja tempat eksperimen berada:
# Within a PythonScriptStep
ws = Run.get_context().experiment.workspace
Untuk detail selengkapnya, termasuk cara alternatif untuk meneruskan dan mengakses data, lihat Memindahkan data ke dalam dan di antara langkah-langkah saluran ML (Python).
Caching/(penembolokan) & digunakan kembali
Untuk mengoptimalkan dan menyesuaikan perilaku alur Anda, Anda dapat melakukan beberapa hal seputar penembolokan dan penggunaan ulang. Misalnya, Anda dapat memilih untuk:
- Nonaktifkan penggunaan kembali default menjalankan langkah output dengan mengatur
allow_reuse=Falseselama definisi langkah. Penggunaan kembali adalah kunci ketika menggunakan saluran di lingkungan kolaboratif karena menghilangkan tayangan yang tidak perlu menawarkan kelincahan. Namun, Anda dapat memilih untuk tidak menggunakannya kembali. - Paksa regenerasi output untuk semua langkah dalam menjalankan dengan
pipeline_run = exp.submit(pipeline, regenerate_outputs=True)
Secara default, allow_reuse untuk langkah-langkah diaktifkan dan source_directory yang ditentukan dalam definisi langkah di-hash-kan. Jadi, jika skrip untuk langkah tertentu tetap sama (script_name, input, dan parameter), dan tidak ada yang lain di source_directory yang berubah, output dari langkah sebelumnya akan digunakan kembali, pekerjaan tidak dikirimkan ke komputasi, dan hasil dari eksekusi sebelumnya langsung tersedia untuk langkah berikutnya.
step = PythonScriptStep(name="Hello World",
script_name="hello_world.py",
compute_target=aml_compute,
source_directory=source_directory,
allow_reuse=False,
hash_paths=['hello_world.ipynb'])
Catatan
Jika nama input data berubah, langkah akan dijalankan kembali, meskipun data pokok tidak berubah. Anda harus secara eksplisit mengatur bidang name dari data input (data.as_input(name=...)). Jika Anda tidak mengatur nilai ini secara eksplisit, bidang name akan diatur ke guid acak dan hasil langkah tidak akan digunakan kembali.
Mengirim alur
Saat Anda mengirimkan saluran, Azure Machine Learning memeriksa dependensi untuk setiap langkah dan mengunggah snapshot direktori sumber yang Anda tentukan. Jika tidak ada direktori sumber yang ditentukan, direktori lokal saat ini akan diunggah. Snapshot juga disimpan sebagai bagian dari percobaan di ruang kerja Anda.
Penting
Untuk mencegah file yang tidak perlu disertakan dalam cuplikan, buat file abaikan (.gitignore atau .amlignore) di direktori. Tambahkan file dan direktori untuk dikecualikan ke file ini. Untuk informasi selengkapnya tentang sintaks yang digunakan di dalam file ini, lihat sintaks dan pola untuk .gitignore. File .amlignore menggunakan sintaks yang sama. Jika kedua file ada, file .amlignore digunakan dan file .gitignore tidak digunakan.
Untuk informasi selengkapnya, lihat Snapshots.
from azureml.core import Experiment
# Submit the pipeline to be run
pipeline_run1 = Experiment(ws, 'Compare_Models_Exp').submit(pipeline1)
pipeline_run1.wait_for_completion()
Saat Pertama kali menjalankan saluran, Azure Machine Learning:
Mengunduh snapshot proyek ke target komputasi dari penyimpanan Blob yang terkait dengan ruang kerja.
Menyusun gambar Docker yang sesuai dengan setiap langkah dalam saluran.
Mengunduh gambar Docker untuk setiap langkah ke target komputasi dari registri kontainer.
Mengonfigurasi akses ke objek
DatasetdanOutputFileDatasetConfig. Untukas_mount()mode akses, FUSE digunakan untuk menyediakan akses virtual. Jika pemasangan tidak didukung atau jika pengguna menetapkan akses sebagaias_upload(), data akan disalin ke target komputasi.Menjalankan langkah dalam target komputasi yang ditentukan dalam definisi langkah.
Membuat artefak, seperti log, stdout dan stderr, metrik, dan output yang ditentukan oleh langkah tersebut. Artefak ini kemudian diunggah dan disimpan di penyimpanan data default pengguna.
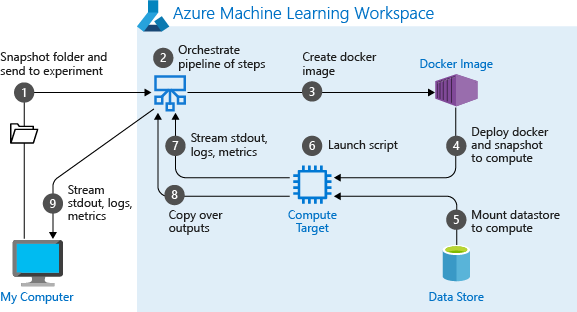
Untuk informasi selengkapnya, lihat referensi Kelas Eksperimen.
Menggunakan parameter saluran untuk argumen yang berubah pada waktu inferensi
Terkadang, argumen untuk langkah-langkah individual dalam saluran berkaitan dengan periode pengembangan dan pelatihan: hal-hal seperti tingkat pelatihan dan momentum, atau jalur ke file data atau konfigurasi. Namun, ketika model disebarkan, Anda dapat secara dinamis meneruskan argumen yang Anda simpulkan (yaitu, kueri yang Anda buat untuk dijawab oleh model!). Anda harus membuat jenis parameter saluran argumen ini. Untuk melakukan ini di Python, gunakan class azureml.pipeline.core.PipelineParameter, seperti yang ditunjukkan dalam cuplikan kode berikut:
from azureml.pipeline.core import PipelineParameter
pipeline_param = PipelineParameter(name="pipeline_arg", default_value="default_val")
train_step = PythonScriptStep(script_name="train.py",
arguments=["--param1", pipeline_param],
target=compute_target,
source_directory=project_folder)
Cara kerja lingkungan Python dengan parameter pipeline
Seperti yang dibahas sebelumnya dalam Mengonfigurasi lingkungan pelaksanaan pelatihan, status lingkungan, dan dependensi pustaka Python ditentukan menggunakan Environment objek. Secara umum, Anda dapat menentukan versi yang sudah adaEnvironment dengan merujuk pada namanya dan, secara opsional, versi:
aml_run_config = RunConfiguration()
aml_run_config.environment.name = 'MyEnvironment'
aml_run_config.environment.version = '1.0'
Namun, jika Anda memilih untuk menggunakan objek PipelineParameter untuk mengatur variabel secara dinamis pada runtime untuk langkah alur, Anda tidak dapat menggunakan teknik ini untuk merujuk ke Environment yang ada. Sebagai gantinya, jika Anda ingin menggunakan PipelineParameter objek, Anda harus mengatur environmentbidang objek RunConfigurationke objek Environment. Anda bertanggung jawab untuk memastikan bahwa tindakan seperti Environment itu memiliki ketergantungan pada paket Python eksternal yang ditetapkan dengan benar.
Menampilkan hasil saluran pipa
Lihat daftar semua alur Anda dan detail prosesnya di studio:
Masuk ke Studio Azure Machine Learning.
Di sebelah kiri, pilih Saluran untuk melihat semua alur Anda berjalan.
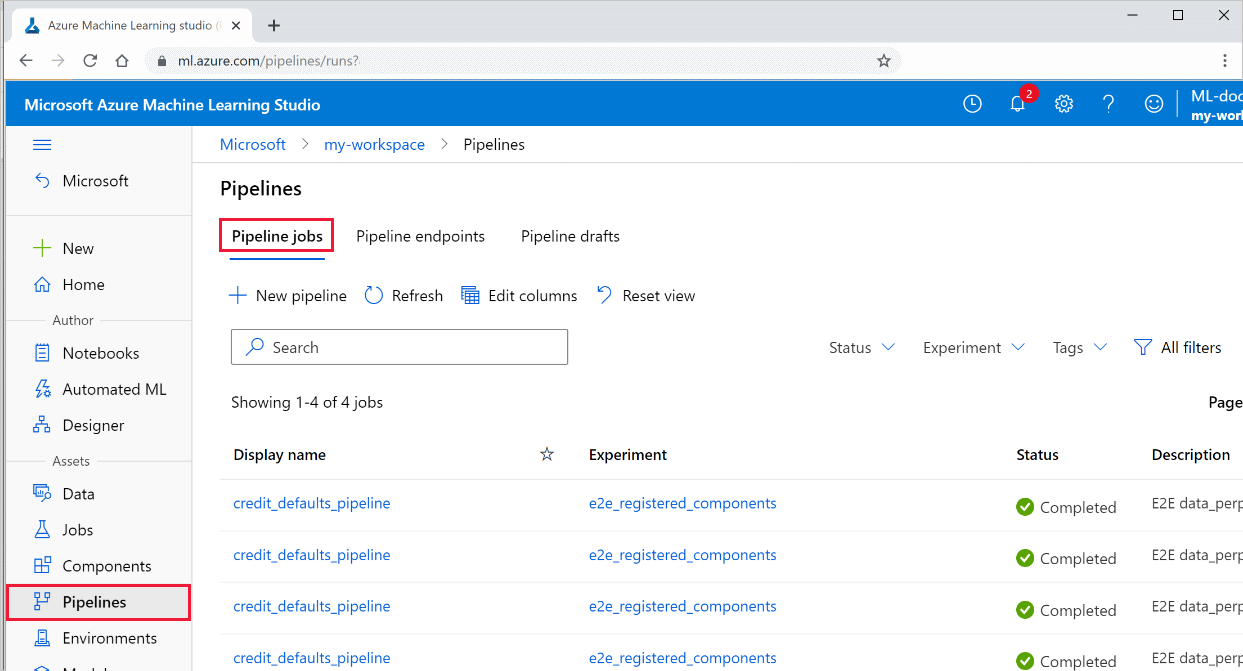
Pilih saluran tertentu untuk melihat hasil yang dijalankan.
Pelacakan dan integrasi Git
Ketika Anda memulai eksekusi pelatihan di mana direktori sumber adalah repositori Git lokal, informasi tentang repositori tersebut disimpan dalam riwayat eksekusi. Untuk informasi lebih lanjut, lihat Integrasi Git untuk Azure Machine Learning.
Langkah berikutnya
- Untuk berbagi saluran Anda dengan kolega atau pelanggan, lihat Menerbitkan saluran pembelajaran mesin
- Gunakan notebook Jupyter ini di GitHub untuk menjelajahi saluran pembelajaran mesin lebih lanjut
- Lihat referensi SDK untuk bantuan dengan paket azureml-pipelines-core dan paket azureml-pipelines-steps
- Lihat cara menggunakan tips tentang debugging dan pemecahan masalah saluran=
- Pelajari cara menjalankan notebook dengan mengikuti artikel Menggunakan notebook Jupyter untuk menjelajahi layanan ini.
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk