Dalam artikel ini, Anda akan mempelajari cara menggunakan Open Neural Network Exchange (ONNX) untuk membuat prediksi pada model visi komputer yang dihasilkan dari pembelajaran mesin otomatis (AutoML) di Azure Pembelajaran Mesin.
Agar dapat menggunakan ONNX untuk prediksi, Anda perlu:
Unduh file model ONNX dari eksekusi pelatihan AutoML.
Memahami input dan output dari model ONNX.
Praproses data Anda sehingga berada dalam format yang diperlukan untuk gambar input.
Lakukan inferensi dengan ONNX Runtime untuk Python.
Memvisualkan prediksi untuk tugas deteksi objek dan segmentasi instans.
ONNX adalah standar terbuka untuk pembelajaran mesin dan model pembelajaran mendalam. Ini memungkinkan impor dan ekspor model (interoperabilitas) di seluruh kerangka kerja AI yang populer. Untuk detail lebih lanjut, jelajahi proyek ONNX GitHub.
ONNX Runtime adalah proyek open-source yang mendukung inferensi lintas platform. ONNX Runtime menyediakan API di seluruh bahasa pemrograman (termasuk Python, C++, C#, C, Java, dan JavaScript). Anda dapat menggunakan API ini untuk melakukan inferensi pada gambar input. Setelah Anda mendapatkan model yang telah diekspor ke format ONNX, Anda dapat menggunakan API ini pada bahasa pemrograman apa pun yang dibutuhkan proyek Anda.
Dalam panduan ini, Anda mempelajari cara menggunakan API Python untuk ONNX Runtime untuk membuat prediksi pada gambar untuk tugas visi populer. Anda dapat menggunakan model yang diekspor ONNX ini dalam berbagai bahasa.
Instal paket onnxruntime. Metode dalam artikel ini telah diuji dengan versi 1.3.0 hingga 1.8.0.
Unduh file model ONNX
Anda dapat mengunduh file model ONNX dari eksekusi AutoML dengan menggunakan UI studio Azure Machine Learning atau Azure Machine Learning Python SDK. Sebaiknya Anda melakukan pengunduhan melalui SDK dengan nama eksperimen dan ID yang dijalankan induk.
Studio Azure Machine Learning
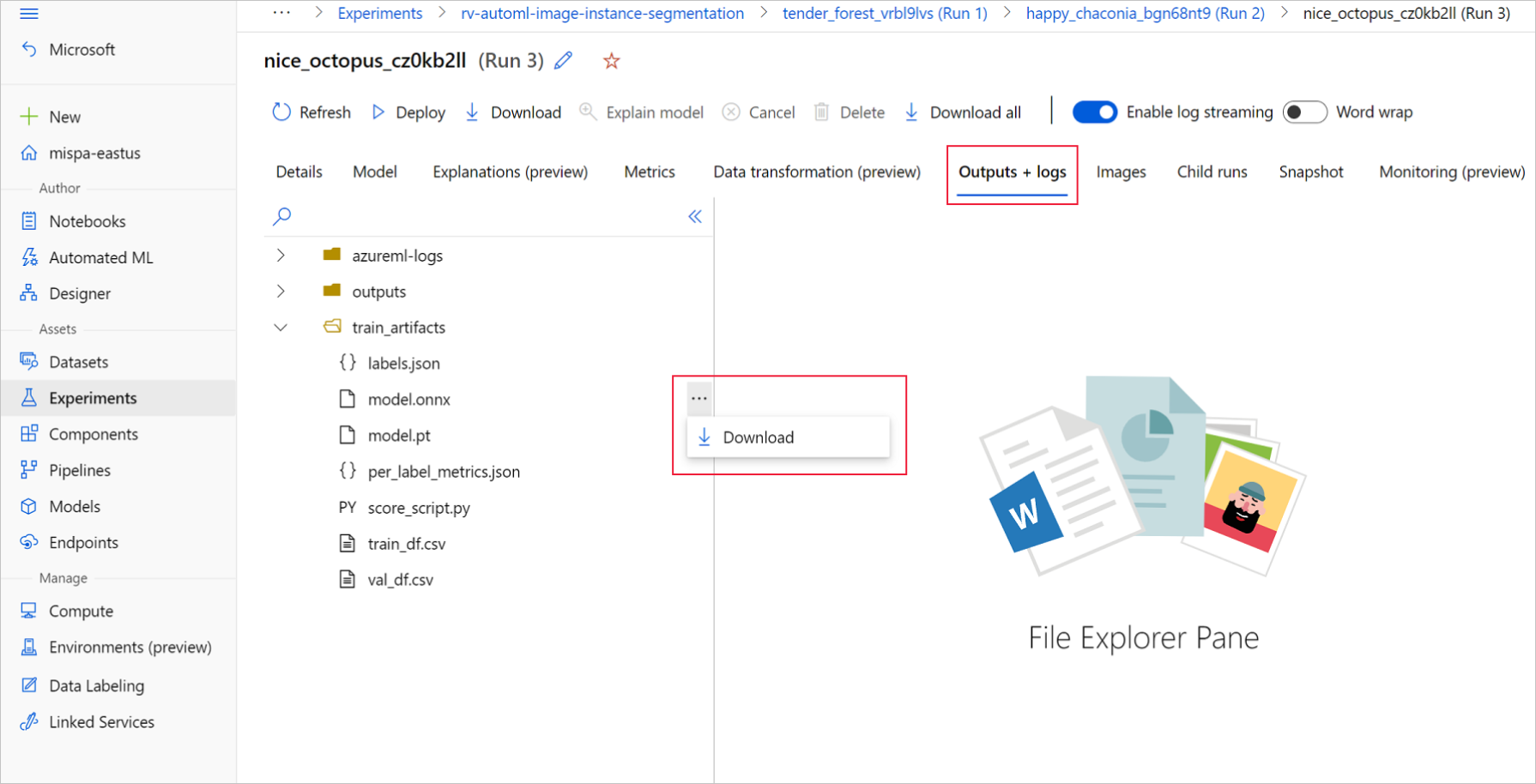
Di studio Azure Machine Learning, buka eksperimen Anda dengan menggunakan hyperlink ke eksperimen yang dihasilkan di buku catatan pelatihan, atau dengan memilih nama eksperimen pada tab Eksperimen di bawah Aset. Kemudian pilih eksekusi anak terbaik.
Dalam eksekusi anak terbaik, buka Outputs + logs>train_artifacts. Gunakan tombol Unduh untuk mengunduh file berikut secara manual:
labels.json: File yang berisi semua kelas atau label dalam himpunan data pelatihan.
model.onnx: Model dalam format ONNX.
Simpan file model yang diunduh dalam direktori. Contoh dalam artikel ini menggunakan direktori ./automl_models.
Azure Machine Learning Python SDK
Dengan SDK, Anda dapat memilih eksekusi anak terbaik (berdasarkan metrik utama) dengan nama eksperimen dan ID eksekusi induk. Kemudian, Anda dapat mengunduh file labels.json dan model.onnx.
Kode berikut mengembalikan eksekusi anak terbaik berdasarkan metrik utama yang relevan.
from azure.identity import DefaultAzureCredential
from azure.ai.ml import MLClient
mlflow_client = MlflowClient()
credential = DefaultAzureCredential()
ml_client = None
try:
ml_client = MLClient.from_config(credential)
except Exception as ex:
print(ex)
# Enter details of your Azure Machine Learning workspace
subscription_id = ''
resource_group = ''
workspace_name = ''
ml_client = MLClient(credential, subscription_id, resource_group, workspace_name)
import mlflow
from mlflow.tracking.client import MlflowClient
# Obtain the tracking URL from MLClient
MLFLOW_TRACKING_URI = ml_client.workspaces.get(
name=ml_client.workspace_name
).mlflow_tracking_uri
mlflow.set_tracking_uri(MLFLOW_TRACKING_URI)
# Specify the job name
job_name = ''
# Get the parent run
mlflow_parent_run = mlflow_client.get_run(job_name)
best_child_run_id = mlflow_parent_run.data.tags['automl_best_child_run_id']
# get the best child run
best_run = mlflow_client.get_run(best_child_run_id)
Unduh file labels.json, yang berisi semua kelas atau label dalam himpunan data pelatihan.
local_dir = './automl_models'
if not os.path.exists(local_dir):
os.mkdir(local_dir)
labels_file = mlflow_client.download_artifacts(
best_run.info.run_id, 'train_artifacts/labels.json', local_dir
)
Dalam kasus inferensi batch untuk Deteksi Objek dan Segmentasi Instans menggunakan model ONNX, lihat bagian tentang pembuatan model untuk penilaian batch.
Pembuatan model untuk penilaian batch
Secara default, AutoML untuk Gambar mendukung penilaian batch untuk klasifikasi. Tetapi deteksi objek dan segmentasi instans model ONNX tidak mendukung inferensi batch. Dalam hal inferensi batch untuk deteksi objek dan segmentasi instans, gunakan prosedur berikut untuk menghasilkan model ONNX untuk ukuran batch yang diperlukan. Model yang dihasilkan untuk ukuran batch tertentu tidak berfungsi untuk ukuran batch lainnya.
Unduh file lingkungan conda dan buat objek lingkungan yang akan digunakan dengan pekerjaan perintah.
# Download conda file and define the environment
conda_file = mlflow_client.download_artifacts(
best_run.info.run_id, "outputs/conda_env_v_1_0_0.yml", local_dir
)
from azure.ai.ml.entities import Environment
env = Environment(
name="automl-images-env-onnx",
description="environment for automl images ONNX batch model generation",
image="mcr.microsoft.com/azureml/openmpi4.1.0-cuda11.1-cudnn8-ubuntu18.04",
conda_file=conda_file,
)
Gunakan argumen spesifik model berikut untuk mengirimkan skrip. Untuk detail selengkapnya tentang argumen, lihat model hiperparameter tertentu dan untuk nama model deteksi objek yang didukung, lihat bagian arsitektur model yang didukung.
Untuk mendapatkan nilai argumen yang diperlukan untuk membuat model penilaian batch, lihat skrip penilaian yang dihasilkan di bawah folder output dari eksekusi pelatihan AutoML. Gunakan nilai hiperparameter yang tersedia dalam variabel pengaturan model di dalam file penilaian untuk menjalankan eksekusi turunan.
Untuk klasifikasi gambar multikelas, model ONNX yang dihasilkan untuk eksekusi turunan yang dijalankan mendukung penilaian batch secara default. Oleh karena itu, tidak diperlukan argumen khusus model untuk jenis tugas ini dan Anda dapat melompat ke bagian Muat label dan file model ONNX.
Untuk klasifikasi gambar multi-label, model ONNX yang dihasilkan untuk yang dijalankan eksekusi turunan mendukung penilaian batch secara default. Oleh karena itu, tidak diperlukan argumen khusus model untuk jenis tugas ini dan Anda dapat melompat ke bagian Muat label dan file model ONNX.
inputs = {'model_name': 'fasterrcnn_resnet34_fpn', # enter the faster rcnn or retinanet model name
'batch_size': 8, # enter the batch size of your choice
'height_onnx': 600, # enter the height of input to ONNX model
'width_onnx': 800, # enter the width of input to ONNX model
'job_name': job_name,
'task_type': 'image-object-detection',
'min_size': 600, # minimum size of the image to be rescaled before feeding it to the backbone
'max_size': 1333, # maximum size of the image to be rescaled before feeding it to the backbone
'box_score_thresh': 0.3, # threshold to return proposals with a classification score > box_score_thresh
'box_nms_thresh': 0.5, # NMS threshold for the prediction head
'box_detections_per_img': 100 # maximum number of detections per image, for all classes
}
inputs = {'model_name': 'yolov5', # enter the yolo model name
'batch_size': 8, # enter the batch size of your choice
'height_onnx': 640, # enter the height of input to ONNX model
'width_onnx': 640, # enter the width of input to ONNX model
'job_name': job_name,
'task_type': 'image-object-detection',
'img_size': 640, # image size for inference
'model_size': 'small', # size of the yolo model
'box_score_thresh': 0.1, # threshold to return proposals with a classification score > box_score_thresh
'box_iou_thresh': 0.5
}
inputs = {'model_name': 'maskrcnn_resnet50_fpn', # enter the maskrcnn model name
'batch_size': 8, # enter the batch size of your choice
'height_onnx': 600, # enter the height of input to ONNX model
'width_onnx': 800, # enter the width of input to ONNX model
'job_name': job_name,
'task_type': 'image-instance-segmentation',
'min_size': 600, # minimum size of the image to be rescaled before feeding it to the backbone
'max_size': 1333, # maximum size of the image to be rescaled before feeding it to the backbone
'box_score_thresh': 0.3, # threshold to return proposals with a classification score > box_score_thresh
'box_nms_thresh': 0.5, # NMS threshold for the prediction head
'box_detections_per_img': 100 # maximum number of detections per image, for all classes
}
Unduh dan simpan file ONNX_batch_model_generator_automl_for_images.py di direktori saat ini dan kirimkan skrip. Gunakan pekerjaan perintah berikut untuk mengirimkan skrip ONNX_batch_model_generator_automl_for_images.pyyang tersedia di repositori GitHub azureml-examples, untuk menghasilkan model ONNX dengan ukuran batch tertentu. Dalam kode berikut, lingkungan model terlatih digunakan untuk mengirimkan skrip ini untuk menghasilkan dan menyimpan model ONNX ke direktori output.
Untuk klasifikasi gambar multikelas, model ONNX yang dihasilkan untuk eksekusi turunan yang dijalankan mendukung penilaian batch secara default. Oleh karena itu, tidak diperlukan argumen khusus model untuk jenis tugas ini dan Anda dapat melompat ke bagian Muat label dan file model ONNX.
Untuk klasifikasi gambar multi-label, model ONNX yang dihasilkan untuk yang dijalankan eksekusi turunan mendukung penilaian batch secara default. Oleh karena itu, tidak diperlukan argumen khusus model untuk jenis tugas ini dan Anda dapat melompat ke bagian Muat label dan file model ONNX.
from azure.ai.ml import command
job = command(
code="./onnx_generator_files", # local path where the code is stored
command="python ONNX_batch_model_generator_automl_for_images.py --model_name ${{inputs.model_name}} --batch_size ${{inputs.batch_size}} --height_onnx ${{inputs.height_onnx}} --width_onnx ${{inputs.width_onnx}} --job_name ${{inputs.job_name}} --task_type ${{inputs.task_type}} --min_size ${{inputs.min_size}} --max_size ${{inputs.max_size}} --box_score_thresh ${{inputs.box_score_thresh}} --box_nms_thresh ${{inputs.box_nms_thresh}} --box_detections_per_img ${{inputs.box_detections_per_img}}",
inputs=inputs,
environment=env,
compute=compute_name,
display_name="ONNX-batch-model-generation-rcnn",
description="Use the PyTorch to generate ONNX batch scoring model.",
)
returned_job = ml_client.create_or_update(job)
ml_client.jobs.stream(returned_job.name)
from azure.ai.ml import command
job = command(
code="./onnx_generator_files", # local path where the code is stored
command="python ONNX_batch_model_generator_automl_for_images.py --model_name ${{inputs.model_name}} --batch_size ${{inputs.batch_size}} --height_onnx ${{inputs.height_onnx}} --width_onnx ${{inputs.width_onnx}} --job_name ${{inputs.job_name}} --task_type ${{inputs.task_type}} --img_size ${{inputs.img_size}} --model_size ${{inputs.model_size}} --box_score_thresh ${{inputs.box_score_thresh}} --box_iou_thresh ${{inputs.box_iou_thresh}}",
inputs=inputs,
environment=env,
compute=compute_name,
display_name="ONNX-batch-model-generation",
description="Use the PyTorch to generate ONNX batch scoring model.",
)
returned_job = ml_client.create_or_update(job)
ml_client.jobs.stream(returned_job.name)
from azure.ai.ml import command
job = command(
code="./onnx_generator_files", # local path where the code is stored
command="python ONNX_batch_model_generator_automl_for_images.py --model_name ${{inputs.model_name}} --batch_size ${{inputs.batch_size}} --height_onnx ${{inputs.height_onnx}} --width_onnx ${{inputs.width_onnx}} --job_name ${{inputs.job_name}} --task_type ${{inputs.task_type}} --min_size ${{inputs.min_size}} --max_size ${{inputs.max_size}} --box_score_thresh ${{inputs.box_score_thresh}} --box_nms_thresh ${{inputs.box_nms_thresh}} --box_detections_per_img ${{inputs.box_detections_per_img}}",
inputs=inputs,
environment=env,
compute=compute_name,
display_name="ONNX-batch-model-generation-maskrcnn",
description="Use the PyTorch to generate ONNX batch scoring model.",
)
returned_job = ml_client.create_or_update(job)
ml_client.jobs.stream(returned_job.name)
Setelah model batch dihasilkan, unduh dari output>Outputs+logs secara manual, atau gunakan metode berikut:
batch_size = 8 # use the batch size used to generate the model
returned_job_run = mlflow_client.get_run(returned_job.name)
# Download run's artifacts/outputs
onnx_model_path = mlflow_client.download_artifacts(
returned_job_run.info.run_id, 'outputs/model_'+str(batch_size)+'.onnx', local_dir
)
Setelah langkah pengunduhan model, Anda menggunakan paket ONNX Runtime Python untuk melakukan inferensi dengan menggunakan file model.onnx. Untuk tujuan demonstrasi, artikel ini menggunakan himpunan data dari Cara menyiapkan himpunan data gambar untuk setiap tugas visi.
Kami melatih model untuk semua tugas visi dengan himpunan data masing-masing untuk menunjukkan inferensi model ONNX.
Memuat label dan file model ONNX
Cuplikan kode berikut memuat label.json, tempat nama kelas dipesan. Artinya, jika model ONNX memprediksi ID label sebagai 2, maka sesuai dengan nama label yang diberikan pada indeks ketiga dalam file labels.json.
import json
import onnxruntime
labels_file = "automl_models/labels.json"
with open(labels_file) as f:
classes = json.load(f)
print(classes)
try:
session = onnxruntime.InferenceSession(onnx_model_path)
print("ONNX model loaded...")
except Exception as e:
print("Error loading ONNX file: ", str(e))
Dapatkan detail input dan output yang diharapkan untuk model ONNX
Ketika Anda memiliki model, penting untuk mengetahui beberapa detail dengan model spesifik dan tugas spesifik. Detail ini mencakup jumlah input dan jumlah output, bentuk atau format input yang diharapkan untuk pra-pemrosesan gambar, dan bentuk output sehingga Anda mengetahui output dengan model spesifik atau tugas spesifik.
sess_input = session.get_inputs()
sess_output = session.get_outputs()
print(f"No. of inputs : {len(sess_input)}, No. of outputs : {len(sess_output)}")
for idx, input_ in enumerate(range(len(sess_input))):
input_name = sess_input[input_].name
input_shape = sess_input[input_].shape
input_type = sess_input[input_].type
print(f"{idx} Input name : { input_name }, Input shape : {input_shape}, \
Input type : {input_type}")
for idx, output in enumerate(range(len(sess_output))):
output_name = sess_output[output].name
output_shape = sess_output[output].shape
output_type = sess_output[output].type
print(f" {idx} Output name : {output_name}, Output shape : {output_shape}, \
Output type : {output_type}")
Format input dan output yang diharapkan untuk model ONNX
Setiap model ONNX memiliki seperangkat format input dan output yang telah ditentukan.
Contoh ini menerapkan model yang dilatih pada himpunan data fridgeObjects dengan 134 citra dan 4 kelas/label untuk menjelaskan inferensi model ONNX. Untuk informasi selengkapnya tentang pelatihan tugas klasifikasi gambar, lihat buku catatan klasifikasi gambar multi-kelas.
Format input
Input adalah citra yang telah diproses sebelumnya.
Masukkan nama
Bentuk input
Jenis input
Deskripsi
input1
(batch_size, num_channels, height, width)
ndarray(float)
Input adalah gambar yang telah diproses sebelumnya, dengan bentuk (1, 3, 224, 224) untuk ukuran batch 1, dan tinggi serta lebar 224. Angka-angka ini sesuai dengan nilai-nilai yang digunakan untuk crop_size dalam contoh pelatihan.
Format output
Output adalah array logits untuk semua kelas/label.
Nama output
Bentuk output
Jenis output
Deskripsi
output1
(batch_size, num_classes)
ndarray(float)
Model mengembalikan logits (tanpa softmax). Misalnya, untuk kelas ukuran batch 1 dan 4, ia mengembalikan (1, 4).
Input adalah gambar yang telah diproses sebelumnya.
Masukkan nama
Bentuk input
Jenis input
Deskripsi
input1
(batch_size, num_channels, height, width)
ndarray(float)
Input adalah gambar yang telah diproses sebelumnya, dengan bentuk (1, 3, 224, 224) untuk ukuran batch 1, dan tinggi serta lebar 224. Angka-angka ini sesuai dengan nilai-nilai yang digunakan untuk crop_size dalam contoh pelatihan.
Format output
Output adalah array logits untuk semua kelas/label.
Nama output
Bentuk output
Jenis output
Deskripsi
output1
(batch_size, num_classes)
ndarray(float)
Model mengembalikan logits (tanpa sigmoid). Misalnya, untuk kelas ukuran batch 1 dan 4, ia mengembalikan (1, 4).
Contoh deteksi objek ini menggunakan model yang dilatih pada dataset deteksi fridgeObjects dari 128 gambar dan 4 kelas / label untuk menjelaskan inferensi model ONNX. Contoh ini melatih model R-CNN yang Lebih Cepat untuk menunjukkan langkah-langkah inferensi. Untuk informasi selengkapnya tentang model deteksi objek pelatihan, lihat buku catatan deteksi objek.
Format input
Input adalah gambar yang telah diproses sebelumnya.
Masukkan nama
Bentuk input
Jenis input
Deskripsi
Input
(batch_size, num_channels, height, width)
ndarray(float)
Input adalah gambar yang telah diproses sebelumnya, dengan bentuk (1, 3, 600, 800) untuk ukuran batch 1, dan tinggi 600 serta lebar 800.
Format output
Output adalah tuple dari output_names dan prediksi. Di sini, output_names dan predictions adalah daftar dengan panjang masing-masing 3*batch_size. Untuk urutan output R-CNN yang lebih cepat adalah kotak, label, dan skor, sedangkan untuk output RetinaNet adalah kotak, skor, label.
Nama output
Bentuk output
Jenis output
Deskripsi
output_names
(3*batch_size)
Daftar kunci
Untuk ukuran batch 2, output_names adalah ['boxes_0', 'labels_0', 'scores_0', 'boxes_1', 'labels_1', 'scores_1']
predictions
(3*batch_size)
Daftar ndarray(float)
Untuk ukuran batch 2, predictions ambil bentuk [(n1_boxes, 4), (n1_boxes), (n1_boxes), (n2_boxes, 4), (n2_boxes), (n2_boxes)]. Di sini, nilai pada setiap indeks sesuai dengan indeks yang sama di output_names.
Tabel berikut ini menjelaskan kotak, label, dan skor yang dikembalikan untuk setiap sampel dalam batch gambar.
Nama
Bentuk
Tipe
Deskripsi
Kotak
(n_boxes, 4), dengan setiap kotak memiliki x_min, y_min, x_max, y_max
ndarray(float)
Model mengembalikan n kotak dengan koordinat kiri atas dan kanan bawah.
Label
(n_boxes)
ndarray(float)
Label atau ID kelas dari suatu objek di setiap kotak.
Skor
(n_boxes)
ndarray(float)
Skor kepercayaan suatu objek di setiap kotak.
Contoh deteksi objek ini menggunakan model yang dilatih pada dataset deteksi fridgeObjects dari 128 gambar dan 4 kelas / label untuk menjelaskan inferensi model ONNX. Contoh ini melatih model YOLO untuk menunjukkan langkah-langkah inferensi. Untuk informasi selengkapnya tentang model deteksi objek pelatihan, lihat buku catatan deteksi objek.
Format input
Input adalah gambar yang telah diproses sebelumnya, dengan bentuk (1, 3, 640, 640) untuk ukuran batch 1, dan tinggi serta lebar 640. Angka-angka ini sesuai dengan nilai-nilai yang digunakan dalam contoh pelatihan.
Masukkan nama
Bentuk input
Jenis input
Deskripsi
Input
(batch_size, num_channels, height, width)
ndarray(float)
Input adalah gambar yang telah diproses sebelumnya, dengan bentuk (1, 3, 640, 640) untuk ukuran batch 1, dan tinggi 640 serta lebar 640.
Format output
Prediksi model ONNX berisi beberapa output. Output pertama diperlukan untuk melakukan penindasan nonmax untuk deteksi. Untuk kemudahan penggunaan, ML otomatis menampilkan format output setelah langkah pascaproses NMS. Output setelah NMS adalah daftar kotak, label, dan skor untuk setiap sampel dalam batch.
Nama output
Bentuk output
Jenis output
Deskripsi
Output
(batch_size)
Daftar ndarray(float)
Model mengembalikan deteksi kotak untuk setiap sampel dalam batch
Setiap sel dalam daftar menunjukkan deteksi kotak sampel dengan bentuk (n_boxes, 6), dengan setiap kotak memiliki x_min, y_min, x_max, y_max, confidence_score, class_id.
Untuk contoh segmentasi contoh ini, Anda menggunakan model Mask R-CNN yang telah dilatih pada himpunan data fridgeObjects dengan 128 gambar dan 4 kelas / label untuk menjelaskan kesimpulan model ONNX. Untuk informasi selengkapnya tentang pelatihan model segmentasi instans, lihat buku catatan segmentasi instans.
Penting
Hanya Mask R-CNN yang didukung untuk tugas segmentasi instans. Format input dan output hanya didasarkan pada Mask R-CNN.
Format input
Input adalah citra yang telah diproses sebelumnya. Model ONNX untuk Mask R-CNN telah diekspor untuk bekerja dengan gambar dari berbagai bentuk. Kami menyarankan Anda mengubah ukurannya menjadi ukuran tetap yang konsisten dengan ukuran gambar pelatihan, untuk performa yang lebih baik.
Masukkan nama
Bentuk input
Jenis input
Deskripsi
Input
(batch_size, num_channels, height, width)
ndarray(float)
Input adalah gambar yang telah diproses sebelumnya, dengan bentuk (1, 3, input_image_height, input_image_width) untuk ukuran batch 1, dan tinggi serta lebar yang mirip dengan gambar input.
Format output
Output adalah tuple dari output_names dan prediksi. Di sini, output_names dan predictions adalah daftar dengan panjang masing-masing 4*batch_size.
Nama output
Bentuk output
Jenis output
Deskripsi
output_names
(4*batch_size)
Daftar kunci
Untuk ukuran batch 2, output_names adalah ['boxes_0', 'labels_0', 'scores_0', 'masks_0', 'boxes_1', 'labels_1', 'scores_1', 'masks_1']
predictions
(4*batch_size)
Daftar ndarray(float)
Untuk ukuran batch 2, predictions ambil bentuk [(n1_boxes, 4), (n1_boxes), (n1_boxes), (n1_boxes, 1, height_onnx, width_onnx), (n2_boxes, 4), (n2_boxes), (n2_boxes), (n2_boxes, 1, height_onnx, width_onnx)]. Di sini, nilai pada setiap indeks sesuai dengan indeks yang sama di output_names.
Nama
Bentuk
Tipe
Deskripsi
Kotak
(n_boxes, 4), dengan setiap kotak memiliki x_min, y_min, x_max, y_max
ndarray(float)
Model mengembalikan n kotak dengan koordinat kiri atas dan kanan bawah.
Label
(n_boxes)
ndarray(float)
Label atau ID kelas dari suatu objek di setiap kotak.
Skor
(n_boxes)
ndarray(float)
Skor kepercayaan suatu objek di setiap kotak.
Masker
(n_boxes, 1, height_onnx, width_onnx)
ndarray(float)
Masker (poligon) dari objek yang terdeteksi dengan tinggi dan lebar pada bentuk gambar input.
Lakukan langkah-langkah prapemrosesan berikut untuk inferensi model ONNX:
Konversikan gambar ke RGB.
Ubah ukuran gambar menjadi nilai valid_resize_size dan valid_resize_size yang sesuai dengan nilai yang digunakan dalam transformasi himpunan data validasi selama pelatihan. Nilai default untuk valid_resize_size adalah 256.
Pangkas bagian tengah gambar ke height_onnx_crop_size dan width_onnx_crop_size. Ini sesuai dengan valid_crop_size, dengan nilai default 224.
Ubah HxWxC ke CxHxW.
Konversi ke jenis float.
Normalisasi dengan mean = [0.485, 0.456, 0.406] dan std = [0.229, 0.224, 0.225] dari ImageNet.
Jika Anda memilih nilai yang berbeda untuk hiperparametervalid_resize_size dan valid_crop_size selama pelatihan, maka nilai-nilai tersebut harus digunakan.
Dapatkan bentuk input yang diperlukan untuk model ONNX.
import glob
import numpy as np
from PIL import Image
def preprocess(image, resize_size, crop_size_onnx):
"""Perform pre-processing on raw input image
:param image: raw input image
:type image: PIL image
:param resize_size: value to resize the image
:type image: Int
:param crop_size_onnx: expected height of an input image in onnx model
:type crop_size_onnx: Int
:return: pre-processed image in numpy format
:rtype: ndarray 1xCxHxW
"""
image = image.convert('RGB')
# resize
image = image.resize((resize_size, resize_size))
# center crop
left = (resize_size - crop_size_onnx)/2
top = (resize_size - crop_size_onnx)/2
right = (resize_size + crop_size_onnx)/2
bottom = (resize_size + crop_size_onnx)/2
image = image.crop((left, top, right, bottom))
np_image = np.array(image)
# HWC -> CHW
np_image = np_image.transpose(2, 0, 1) # CxHxW
# normalize the image
mean_vec = np.array([0.485, 0.456, 0.406])
std_vec = np.array([0.229, 0.224, 0.225])
norm_img_data = np.zeros(np_image.shape).astype('float32')
for i in range(np_image.shape[0]):
norm_img_data[i,:,:] = (np_image[i,:,:]/255 - mean_vec[i])/std_vec[i]
np_image = np.expand_dims(norm_img_data, axis=0) # 1xCxHxW
return np_image
# following code loads only batch_size number of images for demonstrating ONNX inference
# make sure that the data directory has at least batch_size number of images
test_images_path = "automl_models_multi_cls/test_images_dir/*" # replace with path to images
# Select batch size needed
batch_size = 8
# you can modify resize_size based on your trained model
resize_size = 256
# height and width will be the same for classification
crop_size_onnx = height_onnx_crop_size
image_files = glob.glob(test_images_path)
img_processed_list = []
for i in range(batch_size):
img = Image.open(image_files[i])
img_processed_list.append(preprocess(img, resize_size, crop_size_onnx))
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Dengan PyTorch
import glob
import torch
import numpy as np
from PIL import Image
from torchvision import transforms
def _make_3d_tensor(x) -> torch.Tensor:
"""This function is for images that have less channels.
:param x: input tensor
:type x: torch.Tensor
:return: return a tensor with the correct number of channels
:rtype: torch.Tensor
"""
return x if x.shape[0] == 3 else x.expand((3, x.shape[1], x.shape[2]))
def preprocess(image, resize_size, crop_size_onnx):
transform = transforms.Compose([
transforms.Resize(resize_size),
transforms.CenterCrop(crop_size_onnx),
transforms.ToTensor(),
transforms.Lambda(_make_3d_tensor),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
img_data = transform(image)
img_data = img_data.numpy()
img_data = np.expand_dims(img_data, axis=0)
return img_data
# following code loads only batch_size number of images for demonstrating ONNX inference
# make sure that the data directory has at least batch_size number of images
test_images_path = "automl_models_multi_cls/test_images_dir/*" # replace with path to images
# Select batch size needed
batch_size = 8
# you can modify resize_size based on your trained model
resize_size = 256
# height and width will be the same for classification
crop_size_onnx = height_onnx_crop_size
image_files = glob.glob(test_images_path)
img_processed_list = []
for i in range(batch_size):
img = Image.open(image_files[i])
img_processed_list.append(preprocess(img, resize_size, crop_size_onnx))
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Lakukan langkah-langkah prapemrosesan berikut untuk inferensi model ONNX. Langkah-langkah ini sama untuk klasifikasi gambar multi-kelas.
Konversikan gambar ke RGB.
Ubah ukuran gambar menjadi nilai valid_resize_size dan valid_resize_size yang sesuai dengan nilai yang digunakan dalam transformasi himpunan data validasi selama pelatihan. Nilai default untuk valid_resize_size adalah 256.
Pangkas bagian tengah gambar ke height_onnx_crop_size dan width_onnx_crop_size. Ini sesuai dengan valid_crop_size dan nilai defaultnya adalah 224.
Ubah HxWxC ke CxHxW.
Konversi ke jenis float.
Normalisasi dengan mean = [0.485, 0.456, 0.406] dan std = [0.229, 0.224, 0.225] dari ImageNet.
Jika Anda memilih nilai yang berbeda untuk hiperparametervalid_resize_size dan valid_crop_size selama pelatihan, maka nilai-nilai tersebut harus digunakan.
Dapatkan bentuk input yang diperlukan untuk model ONNX.
import glob
import numpy as np
from PIL import Image
def preprocess(image, resize_size, crop_size_onnx):
"""Perform pre-processing on raw input image
:param image: raw input image
:type image: PIL image
:param resize_size: value to resize the image
:type image: Int
:param crop_size_onnx: expected height of an input image in onnx model
:type crop_size_onnx: Int
:return: pre-processed image in numpy format
:rtype: ndarray 1xCxHxW
"""
image = image.convert('RGB')
# resize
image = image.resize((resize_size, resize_size))
# center crop
left = (resize_size - crop_size_onnx)/2
top = (resize_size - crop_size_onnx)/2
right = (resize_size + crop_size_onnx)/2
bottom = (resize_size + crop_size_onnx)/2
image = image.crop((left, top, right, bottom))
np_image = np.array(image)
# HWC -> CHW
np_image = np_image.transpose(2, 0, 1) # CxHxW
# normalize the image
mean_vec = np.array([0.485, 0.456, 0.406])
std_vec = np.array([0.229, 0.224, 0.225])
norm_img_data = np.zeros(np_image.shape).astype('float32')
for i in range(np_image.shape[0]):
norm_img_data[i,:,:] = (np_image[i,:,:] / 255 - mean_vec[i]) / std_vec[i]
np_image = np.expand_dims(norm_img_data, axis=0) # 1xCxHxW
return np_image
# following code loads only batch_size number of images for demonstrating ONNX inference
# make sure that the data directory has at least batch_size number of images
test_images_path = "automl_models_multi_label/test_images_dir/*" # replace with path to images
# Select batch size needed
batch_size = 8
# you can modify resize_size based on your trained model
resize_size = 256
# height and width will be the same for classification
crop_size_onnx = height_onnx_crop_size
image_files = glob.glob(test_images_path)
img_processed_list = []
for i in range(batch_size):
img = Image.open(image_files[i])
img_processed_list.append(preprocess(img, resize_size, crop_size_onnx))
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Dengan PyTorch
import glob
import torch
import numpy as np
from PIL import Image
from torchvision import transforms
def _make_3d_tensor(x) -> torch.Tensor:
"""This function is for images that have less channels.
:param x: input tensor
:type x: torch.Tensor
:return: return a tensor with the correct number of channels
:rtype: torch.Tensor
"""
return x if x.shape[0] == 3 else x.expand((3, x.shape[1], x.shape[2]))
def preprocess(image, resize_size, crop_size_onnx):
"""Perform pre-processing on raw input image
:param image: raw input image
:type image: PIL image
:param resize_size: value to resize the image
:type image: Int
:param crop_size_onnx: expected height of an input image in onnx model
:type crop_size_onnx: Int
:return: pre-processed image in numpy format
:rtype: ndarray 1xCxHxW
"""
transform = transforms.Compose([
transforms.Resize(resize_size),
transforms.CenterCrop(crop_size_onnx),
transforms.ToTensor(),
transforms.Lambda(_make_3d_tensor),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
img_data = transform(image)
img_data = img_data.numpy()
img_data = np.expand_dims(img_data, axis=0)
return img_data
# following code loads only batch_size number of images for demonstrating ONNX inference
# make sure that the data directory has at least batch_size number of images
test_images_path = "automl_models_multi_label/test_images_dir/*" # replace with path to images
# Select batch size needed
batch_size = 8
# you can modify resize_size based on your trained model
resize_size = 256
# height and width will be the same for classification
crop_size_onnx = height_onnx_crop_size
image_files = glob.glob(test_images_path)
img_processed_list = []
for i in range(batch_size):
img = Image.open(image_files[i])
img_processed_list.append(preprocess(img, resize_size, crop_size_onnx))
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Untuk deteksi objek dengan arsitektur R-CNN Yang Lebih Cepat, ikuti langkah-langkah prapemrosepakatan yang sama dengan klasifikasi gambar, kecuali untuk pemangkasan gambar. Anda dapat mengubah ukuran gambar dengan tinggi 600 dan lebar 800. Anda bisa mendapatkan tinggi dan lebar input yang diharapkan dengan kode berikut.
import glob
import numpy as np
from PIL import Image
def preprocess(image, height_onnx, width_onnx):
"""Perform pre-processing on raw input image
:param image: raw input image
:type image: PIL image
:param height_onnx: expected height of an input image in onnx model
:type height_onnx: Int
:param width_onnx: expected width of an input image in onnx model
:type width_onnx: Int
:return: pre-processed image in numpy format
:rtype: ndarray 1xCxHxW
"""
image = image.convert('RGB')
image = image.resize((width_onnx, height_onnx))
np_image = np.array(image)
# HWC -> CHW
np_image = np_image.transpose(2, 0, 1) # CxHxW
# normalize the image
mean_vec = np.array([0.485, 0.456, 0.406])
std_vec = np.array([0.229, 0.224, 0.225])
norm_img_data = np.zeros(np_image.shape).astype('float32')
for i in range(np_image.shape[0]):
norm_img_data[i,:,:] = (np_image[i,:,:] / 255 - mean_vec[i]) / std_vec[i]
np_image = np.expand_dims(norm_img_data, axis=0) # 1xCxHxW
return np_image
# following code loads only batch_size number of images for demonstrating ONNX inference
# make sure that the data directory has at least batch_size number of images
test_images_path = "automl_models_od/test_images_dir/*" # replace with path to images
image_files = glob.glob(test_images_path)
img_processed_list = []
for i in range(batch_size):
img = Image.open(image_files[i])
img_processed_list.append(preprocess(img, height_onnx, width_onnx))
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Untuk deteksi objek dengan arsitektur YOLO, ikuti langkah-langkah pra-pemrosesan yang sama dengan klasifikasi gambar, kecuali untuk pemangkasan gambar. Anda dapat mengubah ukuran gambar dengan tinggi 600 dan lebar 800, dan mendapatkan tinggi dan lebar input yang diharapkan dengan kode berikut.
import glob
import numpy as np
from yolo_onnx_preprocessing_utils import preprocess
# use height and width based on the generated model
test_images_path = "automl_models_od_yolo/test_images_dir/*" # replace with path to images
image_files = glob.glob(test_images_path)
img_processed_list = []
pad_list = []
for i in range(batch_size):
img_processed, pad = preprocess(image_files[i])
img_processed_list.append(img_processed)
pad_list.append(pad)
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Penting
Hanya Mask R-CNN yang didukung untuk tugas segmentasi instans. Langkah pra-pemrosesan hanya didasarkan pada Mask R-CNN.
Lakukan langkah-langkah prapemrosesan berikut untuk inferensi model ONNX:
Konversikan gambar ke RGB.
Mengubah ukuran gambar.
Ubah HxWxC ke CxHxW.
Konversi ke jenis float.
Normalisasi dengan mean = [0.485, 0.456, 0.406] dan std = [0.229, 0.224, 0.225] dari ImageNet.
Untuk resize_height dan resize_width, Anda juga dapat menggunakan nilai-nilai yang Anda gunakan selama pelatihan, dibatasi oleh min_size dan max_sizehiperparameter untuk Mask R-CNN.
import glob
import numpy as np
from PIL import Image
def preprocess(image, resize_height, resize_width):
"""Perform pre-processing on raw input image
:param image: raw input image
:type image: PIL image
:param resize_height: resize height of an input image
:type resize_height: Int
:param resize_width: resize width of an input image
:type resize_width: Int
:return: pre-processed image in numpy format
:rtype: ndarray of shape 1xCxHxW
"""
image = image.convert('RGB')
image = image.resize((resize_width, resize_height))
np_image = np.array(image)
# HWC -> CHW
np_image = np_image.transpose(2, 0, 1) # CxHxW
# normalize the image
mean_vec = np.array([0.485, 0.456, 0.406])
std_vec = np.array([0.229, 0.224, 0.225])
norm_img_data = np.zeros(np_image.shape).astype('float32')
for i in range(np_image.shape[0]):
norm_img_data[i,:,:] = (np_image[i,:,:]/255 - mean_vec[i])/std_vec[i]
np_image = np.expand_dims(norm_img_data, axis=0) # 1xCxHxW
return np_image
# following code loads only batch_size number of images for demonstrating ONNX inference
# make sure that the data directory has at least batch_size number of images
# use height and width based on the trained model
# use height and width based on the generated model
test_images_path = "automl_models_is/test_images_dir/*" # replace with path to images
image_files = glob.glob(test_images_path)
img_processed_list = []
for i in range(batch_size):
img = Image.open(image_files[i])
img_processed_list.append(preprocess(img, height_onnx, width_onnx))
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Inferensi dengan ONNX Runtime
Kesimpulan dengan ONNX Runtime berbeda untuk setiap tugas visi komputer.
def get_predictions_from_ONNX(onnx_session, img_data):
"""Perform predictions with ONNX runtime
:param onnx_session: onnx model session
:type onnx_session: class InferenceSession
:param img_data: pre-processed numpy image
:type img_data: ndarray with shape 1xCxHxW
:return: scores with shapes
(1, No. of classes in training dataset)
:rtype: numpy array
"""
sess_input = onnx_session.get_inputs()
sess_output = onnx_session.get_outputs()
print(f"No. of inputs : {len(sess_input)}, No. of outputs : {len(sess_output)}")
# predict with ONNX Runtime
output_names = [ output.name for output in sess_output]
scores = onnx_session.run(output_names=output_names,\
input_feed={sess_input[0].name: img_data})
return scores[0]
scores = get_predictions_from_ONNX(session, img_data)
def get_predictions_from_ONNX(onnx_session,img_data):
"""Perform predictions with ONNX runtime
:param onnx_session: onnx model session
:type onnx_session: class InferenceSession
:param img_data: pre-processed numpy image
:type img_data: ndarray with shape 1xCxHxW
:return: scores with shapes
(1, No. of classes in training dataset)
:rtype: numpy array
"""
sess_input = onnx_session.get_inputs()
sess_output = onnx_session.get_outputs()
print(f"No. of inputs : {len(sess_input)}, No. of outputs : {len(sess_output)}")
# predict with ONNX Runtime
output_names = [ output.name for output in sess_output]
scores = onnx_session.run(output_names=output_names,\
input_feed={sess_input[0].name: img_data})
return scores[0]
scores = get_predictions_from_ONNX(session, img_data)
def get_predictions_from_ONNX(onnx_session, img_data):
"""perform predictions with ONNX runtime
:param onnx_session: onnx model session
:type onnx_session: class InferenceSession
:param img_data: pre-processed numpy image
:type img_data: ndarray with shape 1xCxHxW
:return: boxes, labels , scores
(No. of boxes, 4) (No. of boxes,) (No. of boxes,)
:rtype: tuple
"""
sess_input = onnx_session.get_inputs()
sess_output = onnx_session.get_outputs()
# predict with ONNX Runtime
output_names = [output.name for output in sess_output]
predictions = onnx_session.run(output_names=output_names,\
input_feed={sess_input[0].name: img_data})
return output_names, predictions
output_names, predictions = get_predictions_from_ONNX(session, img_data)
def get_predictions_from_ONNX(onnx_session,img_data):
"""perform predictions with ONNX Runtime
:param onnx_session: onnx model session
:type onnx_session: class InferenceSession
:param img_data: pre-processed numpy image
:type img_data: ndarray with shape 1xCxHxW
:return: boxes, labels , scores
:rtype: list
"""
sess_input = onnx_session.get_inputs()
sess_output = onnx_session.get_outputs()
# predict with ONNX Runtime
output_names = [ output.name for output in sess_output]
pred = onnx_session.run(output_names=output_names,\
input_feed={sess_input[0].name: img_data})
return pred[0]
result = get_predictions_from_ONNX(session, img_data)
Model segmentasi instans memprediksi kotak, label, skor, dan masker. ONNX menghasilkan masker yang diprediksi per instans, bersama dengan kotak pembatas yang sesuai dan skor kepercayaan kelas. Anda mungkin perlu mengonversi dari masker biner ke poligon jika perlu.
def get_predictions_from_ONNX(onnx_session, img_data):
"""Perform predictions with ONNX runtime
:param onnx_session: onnx model session
:type onnx_session: class InferenceSession
:param img_data: pre-processed numpy image
:type img_data: ndarray with shape 1xCxHxW
:return: boxes, labels , scores , masks with shapes
(No. of instances, 4) (No. of instances,) (No. of instances,)
(No. of instances, 1, HEIGHT, WIDTH))
:rtype: tuple
"""
sess_input = onnx_session.get_inputs()
sess_output = onnx_session.get_outputs()
# predict with ONNX Runtime
output_names = [ output.name for output in sess_output]
predictions = onnx_session.run(output_names=output_names,\
input_feed={sess_input[0].name: img_data})
return output_names, predictions
output_names, predictions = get_predictions_from_ONNX(session, img_data)
Terapkan softmax() pada nilai yang diprediksi untuk mendapatkan skor kepercayaan klasifikasi (probabilitas) untuk setiap kelas. Maka prediksi akan menjadi kelas dengan probabilitas tertinggi.
conf_scores = torch.nn.functional.softmax(torch.from_numpy(scores), dim=1)
class_preds = torch.argmax(conf_scores, dim=1)
print("predicted classes:", ([(class_idx.item(), classes[class_idx]) for class_idx in class_preds]))
Langkah ini berbeda dari klasifikasi multi-kelas. Anda perlu menerapkan sigmoid ke logits (output ONNX) guna mendapatkan skor kepercayaan untuk klasifikasi gambar multi-label.
Tanpa PyTorch
def sigmoid(x):
return 1 / (1 + np.exp(-x))
# we apply a threshold of 0.5 on confidence scores
score_threshold = 0.5
conf_scores = sigmoid(scores)
image_wise_preds = np.where(conf_scores > score_threshold)
for image_idx, class_idx in zip(image_wise_preds[0], image_wise_preds[1]):
print('image: {}, class_index: {}, class_name: {}'.format(image_files[image_idx], class_idx, classes[class_idx]))
Dengan PyTorch
# we apply a threshold of 0.5 on confidence scores
score_threshold = 0.5
conf_scores = torch.sigmoid(torch.from_numpy(scores))
image_wise_preds = torch.where(conf_scores > score_threshold)
for image_idx, class_idx in zip(image_wise_preds[0], image_wise_preds[1]):
print('image: {}, class_index: {}, class_name: {}'.format(image_files[image_idx], class_idx, classes[class_idx]))
Untuk klasifikasi multi-kelas dan multi-label, Anda dapat mengikuti langkah yang sama yang disebutkan sebelumnya untuk semua arsitektur model yang didukung di AutoML.
Untuk deteksi objek, prediksi secara otomatis berada pada skala height_onnx, width_onnx. Untuk mengubah koordinat kotak yang diprediksi ke dimensi asli, Anda dapat menerapkan penghitungan berikut.
Xmin * original_width/width_onnx
Ymin * original_height/height_onnx
Xmax * original_width/width_onnx
Ymax * original_height/height_onnx
Pilihan lainnya adalah menggunakan kode berikut untuk menskalakan dimensi kotak agar berada dalam kisaran [0, 1]. Melakukan hal tersebut memungkinkan koordinat kotak dikalikan dengan tinggi dan lebar gambar asli dengan koordinat masing-masing (seperti yang dijelaskan di bagian prediksi visualisasi) untuk mendapatkan kotak dalam dimensi gambar asli.
def _get_box_dims(image_shape, box):
box_keys = ['topX', 'topY', 'bottomX', 'bottomY']
height, width = image_shape[0], image_shape[1]
box_dims = dict(zip(box_keys, [coordinate.item() for coordinate in box]))
box_dims['topX'] = box_dims['topX'] * 1.0 / width
box_dims['bottomX'] = box_dims['bottomX'] * 1.0 / width
box_dims['topY'] = box_dims['topY'] * 1.0 / height
box_dims['bottomY'] = box_dims['bottomY'] * 1.0 / height
return box_dims
def _get_prediction(boxes, labels, scores, image_shape, classes):
bounding_boxes = []
for box, label_index, score in zip(boxes, labels, scores):
box_dims = _get_box_dims(image_shape, box)
box_record = {'box': box_dims,
'label': classes[label_index],
'score': score.item()}
bounding_boxes.append(box_record)
return bounding_boxes
# Filter the results with threshold.
# Please replace the threshold for your test scenario.
score_threshold = 0.8
filtered_boxes_batch = []
for batch_sample in range(0, batch_size*3, 3):
# in case of retinanet change the order of boxes, labels, scores to boxes, scores, labels
# confirm the same from order of boxes, labels, scores output_names
boxes, labels, scores = predictions[batch_sample], predictions[batch_sample + 1], predictions[batch_sample + 2]
bounding_boxes = _get_prediction(boxes, labels, scores, (height_onnx, width_onnx), classes)
filtered_bounding_boxes = [box for box in bounding_boxes if box['score'] >= score_threshold]
filtered_boxes_batch.append(filtered_bounding_boxes)
Kode berikut membuat kotak, label, dan skor. Gunakan detail kotak pembatas ini untuk melakukan langkah-langkah pasca pemrosesan yang sama seperti yang Anda lakukan untuk model R-CNN yang Lebih Cepat.
Anda dapat menggunakan langkah-langkah yang disebutkan untuk Faster R-CNN (dalam kasus Mask R-CNN, setiap sampel memiliki empat elemen kotak, label, skor, topeng) atau merujuk ke bagian prediksi visualisasi untuk segmentasi instans.
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
 Python SDK azure-ai-ml v2 (saat ini)
Python SDK azure-ai-ml v2 (saat ini)