Router inferensi dan persyaratan konektivitas Azure Pembelajaran Mesin
Router inferensi Azure Pembelajaran Mesin adalah komponen penting untuk inferensi real time dengan kluster Kubernetes. Dalam artikel ini, Anda dapat mempelajari tentang:
- Apa itu router inferensi Azure Machine Learning
- Cara kerja penskalaan otomatis
- Cara mengonfigurasi dan memenuhi performa permintaan inferensi (# permintaan per detik dan latensi)
- Persyaratan konektivitas untuk kluster inferensi AKS
Apa itu router inferensi Azure Machine Learning
Router inferensi Azure Pembelajaran Mesin adalah komponen front-end (azureml-fe) yang disebarkan pada kluster AKS atau Arc Kubernetes pada waktu penyebaran ekstensi Azure Pembelajaran Mesin. Ini memiliki fungsi berikut:
- Merutekan permintaan inferensi masuk dari penyeimbang muatan kluster atau pengontrol ingress ke pod model yang sesuai.
- Seimbangkan muatan semua permintaan inferensi masuk dengan perutean terkoordinasi cerdas.
- Mengelola penskalakan otomatis pod model.
- Kemampuan yang toleran terhadap kesalahan dan failover, memastikan permintaan inferensi selalu dilayani untuk aplikasi bisnis penting.
Langkah-langkah berikut adalah bagaimana permintaan diproses oleh front-end:
- Klien mengirim permintaan ke penyeimbang muatan.
- Penyeimbang muatan mengirim ke salah satu front-end.
- Front-end menemukan router layanan (instans front-end yang bertindak sebagai koordinator) untuk layanan.
- Router layanan memilih back-end dan mengembalikannya ke front-end.
- Front-end meneruskan permintaan ke back-end.
- Setelah permintaan diproses, back-end mengirimkan respons ke komponen front-end.
- Front-end menyebarluaskan respons kembali ke klien.
- Front-end menginformasikan router layanan bahwa back-end telah selesai diproses dan tersedia untuk permintaan lain.
Diagram berikut menggambarkan alur ini:
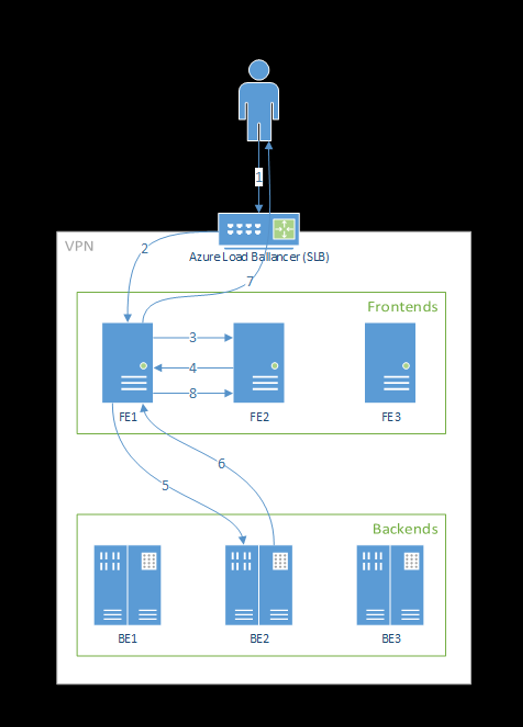
Seperti yang Anda lihat dari diagram di atas, secara default 3 azureml-fe instans dibuat selama penyebaran ekstensi Azure Pembelajaran Mesin, satu instans bertindak sebagai peran koordinasi, dan instans lain melayani permintaan inferensi masuk. Instans koordinasi memiliki semua informasi tentang pod model dan membuat keputusan tentang pod model mana yang akan melayani permintaan masuk, sementara instans azureml-fe penyajian bertanggung jawab untuk merutekan permintaan ke pod model yang dipilih dan menyebarluaskan respons kembali ke pengguna asli.
Penskalaan otomatis
Router inferensi Azure Pembelajaran Mesin menangani penskalaan otomatis untuk semua penyebaran model pada kluster Kubernetes. Karena semua permintaan inferensi melaluinya, router ini memiliki data yang diperlukan untuk secara otomatis menskalakan model yang diterapkan.
Penting
Jangan aktifkan Kubernetes Horizontal Pod Autoscaler (HPA) untuk penyebaran model. Melakukannya akan menyebabkan dua komponen auto-scaling bersaing satu sama lain. Azureml-fe dirancang untuk menskalakan model skala otomatis yang disebarkan oleh Azure Pembelajaran Mesin, di mana HPA harus menebak atau memperkirakan pemanfaatan model dari metrik generik seperti penggunaan CPU atau konfigurasi metrik kustom.
Azureml-fe tidak menskalakan jumlah node dalam klaster AKS, karena ini dapat menyebabkan kenaikan biaya yang tidak terduga. Sebaliknya, ini menskalakan jumlah replika untuk model dalam batas klaster fisik. Jika Anda perlu menskalakan jumlah node dalam klaster, Anda dapat menskalakan klaster secara manual atau mengonfigurasi penskala otomatis kluster AKS.
Penskalaan otomatis dapat dikontrol oleh properti scale_settings dalam YAML penyebaran. Contoh berikut menunjukkan cara mengaktifkan penskalaan otomatis:
# deployment yaml
# other properties skipped
scale_setting:
type: target_utilization
min_instances: 3
max_instances: 15
target_utilization_percentage: 70
polling_interval: 10
# other deployment properties continue
Keputusan untuk meningkatkan atau menurunkan skala didasarkan pada utilization of the current container replicas.
utilization_percentage = (The number of replicas that are busy processing a request + The number of requests queued in azureml-fe) / The total number of current replicas
Jika angka ini melebihi target_utilization_percentage, maka lebih banyak replika akan dibuat. Apabila lebih rendah, maka replika dikurangi. Secara default, target utilisasi adalah 70%.
Keputusan untuk menambahkan replika sangat bersemangat dan cepat (sekitar 1 detik). Keputusan untuk menghapus replika bersifat konservatif (sekitar 1 menit).
Misalnya, jika Anda ingin menyebarkan layanan model dan ingin mengetahui banyak instans (pod/replika) harus dikonfigurasi untuk permintaan target per detik (RPS) dan waktu respons target. Anda dapat menghitung replika yang diperlukan dengan menggunakan kode berikut:
from math import ceil
# target requests per second
targetRps = 20
# time to process the request (in seconds)
reqTime = 10
# Maximum requests per container
maxReqPerContainer = 1
# target_utilization. 70% in this example
targetUtilization = .7
concurrentRequests = targetRps * reqTime / targetUtilization
# Number of container replicas
replicas = ceil(concurrentRequests / maxReqPerContainer)
Performa azureml-fe
Dapat azureml-fe mencapai permintaan 5 K per detik (QPS) dengan latensi yang baik, memiliki overhead rata-rata tidak melebihi 3 ms dan 15 ms pada persentil 99%.
Catatan
Jika Anda memiliki persyaratan RPS yang lebih tinggi dari 10K, pertimbangkan opsi berikut:
- Tingkatkan permintaan/batas sumber daya untuk
azureml-fepod; secara default memiliki batas sumber daya memori 2 vCPU dan 1,2G. - Tingkatkan jumlah instans untuk
azureml-fe. Secara default, Azure Pembelajaran Mesin membuat 3 atau 1azureml-feinstans per kluster.- Jumlah instans ini tergantung pada konfigurasi
inferenceRouterHAentensi Azure Pembelajaran Mesin Anda. - Jumlah instans yang ditingkatkan tidak dapat dipertahankan, karena akan ditimpa dengan nilai yang Dikonfigurasi setelah ekstensi ditingkatkan.
- Jumlah instans ini tergantung pada konfigurasi
- Hubungi pakar Microsoft untuk mendapatkan bantuan.
Memahami persyaratan konektivitas untuk kluster inferensi AKS
Kluster AKS disebarkan dengan salah satu dari dua model jaringan berikut:
- Sumber daya jaringan biasanya dibuat dan dikonfigurasi saat klaster AKS disebarkan.
- Jaringan Antarmuka Jaringan Kontainer Azure (CNI) - Kluster AKS terhubung ke sumber daya dan konfigurasi jaringan virtual yang ada.
Untuk jaringan Kubenet, jaringan dibuat dan dikonfigurasi dengan benar untuk Azure Machine Learning service. Untuk jaringan CNI, Anda perlu memahami persyaratan konektivitas dan memastikan resolusi DNS dan konektivitas keluar untuk inferensi AKS. Misalnya, Anda mungkin memerlukan langkah tambahan jika Anda menggunakan firewall untuk memblokir lalu lintas jaringan.
Diagram berikut menangkap semua persyaratan konektivitas untuk inferensi AKS. Panah hitam mewakili komunikasi yang sebenarnya, dan panah biru mewakili nama domain. Anda mungkin perlu menambahkan entri untuk host ini ke firewall Anda atau ke server DNS kustom Anda.
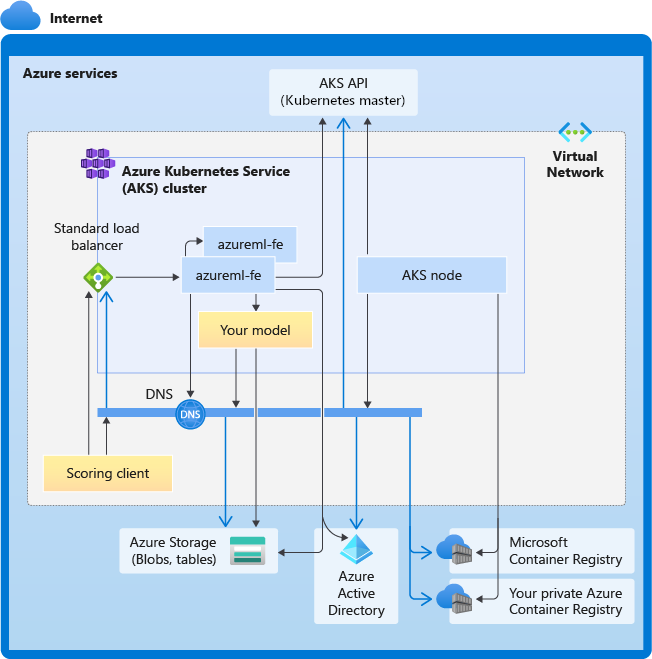
Untuk persyaratan konektivitas AKS umum, lihat Mengontrol lalu lintas keluar untuk node kluster di Azure Kubernetes Service.
Untuk mengakses layanan Azure Pembelajaran Mesin di belakang firewall, lihat Mengonfigurasi lalu lintas jaringan masuk dan keluar.
Persyaratan resolusi DNS secara keseluruhan
Resolusi DNS dalam VNet yang ada berada di bawah kendali Anda. Misalnya, firewall atau server DNS kustom. Host berikut harus dapat dijangkau:
| Nama Host | Digunakan oleh |
|---|---|
<cluster>.hcp.<region>.azmk8s.io |
Server API AKS |
mcr.microsoft.com |
Microsoft Container Registry (MCR) |
<ACR name>.azurecr.io |
Azure Container Registry (ACR) Anda |
<account>.blob.core.windows.net |
Akun Azure Storage (penyimpanan blob) |
api.azureml.ms |
Autentikasi Microsoft Entra |
ingest-vienna<region>.kusto.windows.net |
Titik akhir Kusto untuk mengunggah telemetri |
Persyaratan konektivitas dalam urutan kronologis: dari pembuatan klaster hingga penyebaran model
Tepat setelah azureml-fe disebarkan, azureml-fe akan mencoba untuk memulai dan ini mengharuskan untuk:
- Mengatasi DNS untuk server API AKS
- Kueri server API AKS untuk menemukan instans lain dari dirinya sendiri (instans ini adalah layanan multi-pod)
- Menyambungkan ke contoh lain itu sendiri
Setelah azureml-fe dimulai, diperlukan konektivitas berikut agar azureml-fe berfungsi dengan baik:
- Menyambungkan ke Azure Storage untuk mengunduh konfigurasi dinamis
- Atasi DNS untuk server autentikasi Microsoft Entra api.azureml.ms dan berkomunikasi dengannya saat layanan yang disebarkan menggunakan autentikasi Microsoft Entra.
- Kueri AKS API server untuk menemukan model yang disebarkan
- Berkomunikasi dengan POD model yang disebarkan
Pada waktu penyebaran model, untuk penyebaran model yang sukses, node AKS harus dapat:
- Mengatasi DNS untuk ACR pelanggan
- Unduh gambar dari ACR pelanggan
- Mengatasi DNS untuk BLOB Azure tempat model disimpan
- Unduh model dari BLOB Azure
Setelah model disebarkan dan layanan dimulai, azureml-fe akan secara otomatis menemukannya menggunakan AKS API dan akan siap untuk merutekan permintaan ke sana. Ini harus dapat berkomunikasi dengan pod model.
Catatan
Jika model yang diterapkan memerlukan konektivitas apa pun (misalnya kueri database eksternal atau layanan REST lainnya, mengunduh BLOB dll), maka resolusi DNS dan komunikasi keluar untuk layanan ini harus diaktifkan.