Mengakses data dalam pekerjaan
BERLAKU UNTUK: Ekstensi ml Azure CLI v2 (saat ini)Python SDK azure-ai-ml v2 (saat ini)
Ekstensi ml Azure CLI v2 (saat ini)Python SDK azure-ai-ml v2 (saat ini)
Dalam artikel ini, Anda belajar tentang:
- Cara membaca data dari penyimpanan Azure dalam pekerjaan Azure Pembelajaran Mesin.
- Cara menulis data dari pekerjaan Azure Pembelajaran Mesin Anda ke Azure Storage.
- Perbedaan antara mode pemasangan dan unduhan .
- Cara menggunakan identitas pengguna dan identitas terkelola untuk mengakses data.
- Pengaturan pemasangan tersedia dalam pekerjaan.
- Pengaturan pemasangan optimal untuk skenario umum.
- Cara mengakses aset data V1.
Prasyarat
Langganan Azure. Jika Anda tidak memiliki langganan Azure, buat akun gratis sebelum Anda memulai. Coba versi gratis atau berbayar Azure Machine Learning.
Ruang kerja Azure Machine Learning
Mulai Cepat
Sebelum Anda menjelajahi opsi terperinci yang tersedia untuk Anda saat mengakses data, kami terlebih dahulu menjelaskan cuplikan kode yang relevan untuk akses data.
Membaca data dari penyimpanan Azure dalam pekerjaan Azure Pembelajaran Mesin
Dalam contoh ini, Anda mengirimkan pekerjaan Azure Pembelajaran Mesin yang mengakses data dari akun penyimpanan blob publik. Namun, Anda dapat menyesuaikan cuplikan untuk mengakses data Anda sendiri di akun Azure Storage privat. Perbarui jalur seperti yang dijelaskan di sini. Azure Pembelajaran Mesin menangani autentikasi dengan mulus ke penyimpanan cloud, dengan passthrough Microsoft Entra. Saat mengirimkan pekerjaan, Anda dapat memilih:
- Identitas pengguna: Melewati identitas Microsoft Entra Anda untuk mengakses data
- Identitas terkelola: Gunakan identitas terkelola target komputasi untuk mengakses data
- Tidak Ada: Jangan tentukan identitas untuk mengakses data. Gunakan Tidak Ada saat menggunakan datastore berbasis kredensial (token kunci/SAS) atau saat mengakses data publik
Tip
Jika Anda menggunakan kunci atau token SAS untuk mengautentikasi, kami sarankan Anda membuat datastore Azure Pembelajaran Mesin, karena runtime akan secara otomatis terhubung ke penyimpanan tanpa paparan kunci/token.
from azure.ai.ml import command, Input, MLClient, UserIdentityConfiguration, ManagedIdentityConfiguration
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.identity import DefaultAzureCredential
# Set your subscription, resource group and workspace name:
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
# connect to the AzureML workspace
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# ==============================================================
# Set the URI path for the data.
# Supported `path` formats for input include:
# local: `./<path>
# Blob: wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>
# ADLS: abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# Data Asset: azureml:<my_data>:<version>
# Supported `path` format for output is:
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# We set the input path to a file on a public blob container
# ==============================================================
path = "wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv"
# ==============================================================
# What type of data does the path point to? Options include:
# data_type = AssetTypes.URI_FILE # a specific file
# data_type = AssetTypes.URI_FOLDER # a folder
# data_type = AssetTypes.MLTABLE # an mltable
# The path we set above is a specific file
# ==============================================================
data_type = AssetTypes.URI_FILE
# ==============================================================
# Set the mode. The popular modes include:
# mode = InputOutputModes.RO_MOUNT # Read-only mount on the compute target
# mode = InputOutputModes.DOWNLOAD # Download the data to the compute target
# ==============================================================
mode = InputOutputModes.RO_MOUNT
# ==============================================================
# You can set the identity you want to use in a job to access the data. Options include:
# identity = UserIdentityConfiguration() # Use the user's identity
# identity = ManagedIdentityConfiguration() # Use the compute target managed identity
# ==============================================================
# This example accesses public data, so we don't need an identity.
# You also set identity to None if you use a credential-based datastore
identity = None
# Set the input for the job:
inputs = {
"input_data": Input(type=data_type, path=path, mode=mode)
}
# This command job uses the head Linux command to print the first 10 lines of the file
job = command(
command="head ${{inputs.input_data}}",
inputs=inputs,
environment="azureml://registries/azureml/environments/sklearn-1.1/versions/4",
compute="cpu-cluster",
identity=identity,
)
# Submit the command
ml_client.jobs.create_or_update(job)
Menulis data dari pekerjaan Azure Pembelajaran Mesin Anda ke Azure Storage
Dalam contoh ini, Anda mengirimkan pekerjaan Azure Pembelajaran Mesin yang menulis data ke Azure Pembelajaran Mesin Datastore default Anda. Anda dapat secara opsional mengatur name nilai aset data Anda untuk membuat aset data dalam output.
from azure.ai.ml import command, Input, Output, MLClient
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.identity import DefaultAzureCredential
# Set your subscription, resource group and workspace name:
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
# connect to the AzureML workspace
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# ==============================================================
# Set the URI path for the data.
# Supported `path` formats for input include:
# local: `./<path>
# Blob: wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>
# ADLS: abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# Data Asset: azureml:<my_data>:<version>
# Supported `path` format for output is:
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# As an example, we set the input path to a file on a public blob container
# As an example, we set the output path to a folder in the default datastore
# ==============================================================
input_path = "wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv"
output_path = "azureml://datastores/workspaceblobstore/paths/quickstart-output/titanic.csv"
# ==============================================================
# What type of data are you pointing to?
# AssetTypes.URI_FILE (a specific file)
# AssetTypes.URI_FOLDER (a folder)
# AssetTypes.MLTABLE (a table)
# The path we set above is a specific file
# ==============================================================
data_type = AssetTypes.URI_FILE
# ==============================================================
# Set the input mode. The most commonly-used modes:
# InputOutputModes.RO_MOUNT
# InputOutputModes.DOWNLOAD
# Set the mode to Read Only (RO) to mount the data
# ==============================================================
input_mode = InputOutputModes.RO_MOUNT
# ==============================================================
# Set the output mode. The most commonly-used modes:
# InputOutputModes.RW_MOUNT
# InputOutputModes.UPLOAD
# Set the mode to Read Write (RW) to mount the data
# ==============================================================
output_mode = InputOutputModes.RW_MOUNT
# Set the input and output for the job:
inputs = {
"input_data": Input(type=data_type, path=input_path, mode=input_mode)
}
outputs = {
"output_data": Output(type=data_type,
path=output_path,
mode=output_mode,
# optional: if you want to create a data asset from the output,
# then uncomment `name` (`name` can be set without setting `version`, and in this way, we will set `version` automatically for you)
# name = "<name_of_data_asset>", # use `name` and `version` to create a data asset from the output
# version = "<version>",
)
}
# This command job copies the data to your default Datastore
job = command(
command="cp ${{inputs.input_data}} ${{outputs.output_data}}",
inputs=inputs,
outputs=outputs,
environment="azureml://registries/azureml/environments/sklearn-1.1/versions/4",
compute="cpu-cluster",
)
# Submit the command
ml_client.jobs.create_or_update(job)
Runtime data Azure Pembelajaran Mesin
Saat Anda mengirimkan pekerjaan, runtime data Azure Pembelajaran Mesin mengontrol beban data, dari lokasi penyimpanan ke target komputasi. Runtime data Azure Pembelajaran Mesin dioptimalkan untuk kecepatan dan efisiensi untuk tugas pembelajaran mesin. Manfaat utamanya meliputi:
- Beban data yang ditulis dalam bahasa Rust, bahasa yang dikenal dengan kecepatan tinggi dan efisiensi memori tinggi. Untuk unduhan data bersamaan, Rust menghindari masalah Python Global Interpreter Lock (GIL)
- Ringan; Karat tidak memiliki dependensi pada teknologi lain - misalnya JVM. Akibatnya, runtime menginstal dengan cepat, dan tidak menguras sumber daya tambahan (CPU, Memori) pada target komputasi
- Pemuatan data multi-proses (paralel)
- Melakukan prefetch data sebagai tugas latar belakang pada CPU, untuk memungkinkan pemanfaatan GPU yang lebih baik saat melakukan pembelajaran mendalam
- Penanganan autentikasi yang mulus ke penyimpanan cloud
- Menyediakan opsi untuk memasang data (streaming) atau mengunduh semua data. Untuk informasi selengkapnya, kunjungi bagian Pasang (streaming) dan Unduh .
- Integrasi mulus dengan fsspec - antarmuka pythonic terpadu ke sistem file lokal, jarak jauh, dan tersemat dan penyimpanan byte.
Tip
Kami menyarankan agar Anda memanfaatkan runtime data Azure Pembelajaran Mesin, alih-alih membuat kemampuan pemasangan/pengunduhan Anda sendiri dalam kode pelatihan (klien) Anda. Kami telah mengamati batasan throughput penyimpanan ketika kode klien menggunakan Python untuk mengunduh data dari penyimpanan, karena masalah Global Interpreter Lock (GIL).
Jalur
Saat Anda memberikan input/output data ke pekerjaan, Anda harus menentukan path parameter yang menunjuk ke lokasi data. Tabel ini memperlihatkan berbagai lokasi data yang didukung Azure Pembelajaran Mesin, dan juga memperlihatkan path contoh parameter:
| Lokasi | Contoh | Input | Output |
|---|---|---|---|
| Jalur pada komputer lokal Anda | ./home/username/data/my_data |
Y | N |
| Jalur pada server http milik publik | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
Y | N |
| Jalur pada Azure Storage | wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>abfss://<file_system>@<account_name>.dfs.core.windows.net/<path> |
Y, hanya untuk autentikasi berbasis identitas. | N |
| Jalur di Azure Pembelajaran Mesin Datastore | azureml://datastores/<data_store_name>/paths/<path> |
Y | Y |
| Jalur menuju ke Aset Data | azureml:<my_data>:<version> |
Y | N, tetapi Anda dapat menggunakan name dan version untuk membuat aset data dari output |
Mode
Saat menjalankan pekerjaan dengan input/output data, Anda dapat memilih dari opsi mode ini:
ro_mount: Pasang lokasi penyimpanan, sebagai baca-saja pada target komputasi disk lokal (SSD).rw_mount: Pasang lokasi penyimpanan, sebagai baca-tulis pada target komputasi disk lokal (SSD).download: Unduh data dari lokasi penyimpanan ke target komputasi disk lokal (SSD).upload: Unggah data dari target komputasi ke lokasi penyimpanan.eval_mount/eval_download: Mode ini unik untuk MLTable. Dalam beberapa skenario, MLTable dapat menghasilkan file yang mungkin terletak di akun penyimpanan yang berbeda dari akun penyimpanan yang menghosting file MLTable. Atau, MLTable dapat mem-subset atau mengacak data yang terletak di sumber daya penyimpanan. Tampilan subset/acak itu menjadi terlihat hanya jika runtime data Azure Pembelajaran Mesin benar-benar mengevaluasi file MLTable. Misalnya, diagram ini menunjukkan bagaimana MLTable yang digunakan denganeval_mountataueval_downloaddapat mengambil gambar dari dua kontainer penyimpanan yang berbeda, dan file anotasi yang terletak di akun penyimpanan yang berbeda, lalu memasang/mengunduh ke sistem file target komputasi jarak jauh.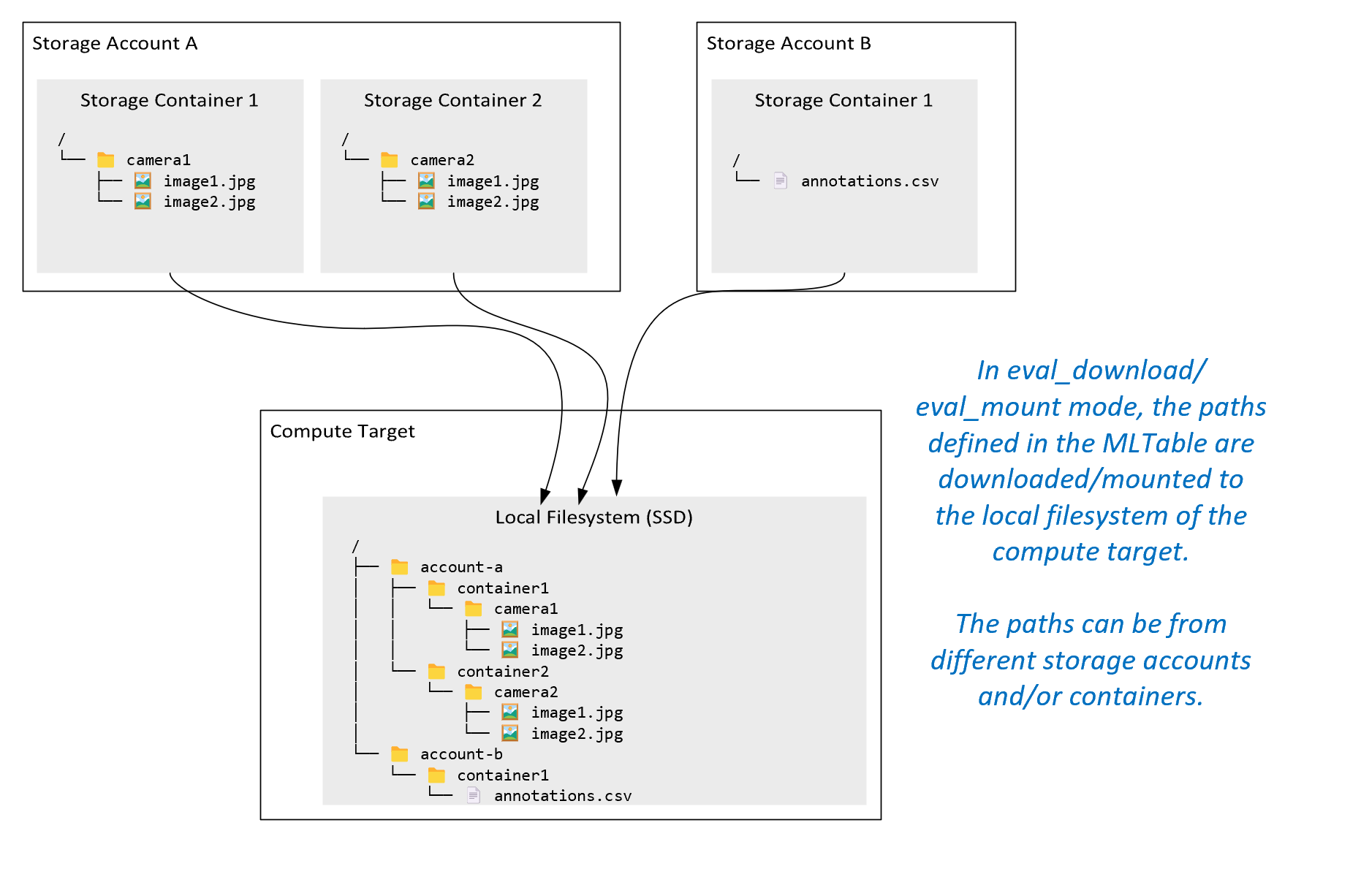
Folder
camera1, folder,camera2danannotations.csvfile kemudian dapat diakses pada sistem file target komputasi dalam struktur folder:/INPUT_DATA ├── account-a │ ├── container1 │ │ └── camera1 │ │ ├── image1.jpg │ │ └── image2.jpg │ └── container2 │ └── camera2 │ ├── image1.jpg │ └── image2.jpg └── account-b └── container1 └── annotations.csvdirect: Anda mungkin ingin membaca data langsung dari URI melalui API lain, daripada melalui runtime data Azure Pembelajaran Mesin. Misalnya, Anda mungkin ingin mengakses data pada wadah s3 (dengan URL gaya atau gayahttpsjalur yang dihosting virtual) menggunakan klien boto s3. Anda dapat memperoleh URI input sebagai string dengandirectmode . Anda melihat penggunaan mode langsung dalam Pekerjaan Spark, karena metode tahuspark.read_*()cara memproses URI. Untuk pekerjaan non-Spark, Anda bertanggung jawab untuk mengelola kredensial akses. Misalnya, Anda harus secara eksplisit menggunakan MSI komputasi, atau akses broker.

Tabel ini menunjukkan mode yang mungkin untuk kombinasi jenis/mode/input/output yang berbeda:
| Jenis | Input/Output | upload |
download |
ro_mount |
rw_mount |
direct |
eval_download |
eval_mount |
|---|---|---|---|---|---|---|---|---|
uri_folder |
Input | ✓ | ✓ | ✓ | ||||
uri_file |
Input | ✓ | ✓ | ✓ | ||||
mltable |
Input | ✓ | ✓ | ✓ | ✓ | ✓ | ||
uri_folder |
Output | ✓ | ✓ | |||||
uri_file |
Output | ✓ | ✓ | |||||
mltable |
Output | ✓ | ✓ | ✓ |
Unduh
Dalam mode unduhan, semua data input disalin ke disk lokal (SSD) target komputasi. Runtime data Azure Pembelajaran Mesin memulai skrip pelatihan pengguna, setelah semua data disalin. Ketika skrip pengguna dimulai, skrip membaca data dari disk lokal, sama seperti file lainnya. Setelah pekerjaan selesai, data dihapus dari disk target komputasi.
| Kelebihan | Kerugian |
|---|---|
| Saat pelatihan dimulai, semua data tersedia di disk lokal (SSD) target komputasi, untuk skrip pelatihan. Tidak diperlukan interaksi penyimpanan/jaringan Azure. | Himpunan data harus sepenuhnya sesuai pada disk target komputasi. |
| Setelah skrip pengguna dimulai, tidak ada dependensi pada penyimpanan/keandalan jaringan. | Seluruh himpunan data diunduh (jika pelatihan perlu memilih sebagian kecil data secara acak, sebagian besar unduhan kemudian terbuang). |
| Runtime data Azure Pembelajaran Mesin dapat menyejajarkan unduhan (perbedaan signifikan pada banyak file kecil) dan throughput jaringan/penyimpanan maks. | Pekerjaan menunggu hingga semua data diunduh ke disk lokal target komputasi. Untuk pekerjaan pembelajaran mendalam yang dikirimkan, GPU menganggur hingga data siap. |
| Tidak ada overhead yang tidak dapat ditolak yang ditambahkan oleh lapisan FUSE (pulang pergi: panggilan ruang pengguna dalam skrip pengguna → kernel → daemon fuse ruang pengguna → kernel → respons terhadap skrip pengguna di ruang pengguna) | Perubahan penyimpanan tidak tercermin pada data setelah pengunduhan selesai. |
Kapan menggunakan unduhan
- Data cukup kecil agar sesuai dengan disk target komputasi tanpa gangguan dengan pelatihan lain
- Pelatihan menggunakan sebagian besar atau semua himpunan data
- Pelatihan membaca file dari himpunan data lebih dari sekali
- Pelatihan harus melompat ke posisi acak file besar
- Tidak apa-apa untuk menunggu sampai semua data diunduh sebelum pelatihan dimulai
Pengaturan unduhan yang tersedia
Anda dapat menyetel pengaturan unduhan dengan variabel lingkungan ini dalam pekerjaan Anda:
| Nama Variabel Lingkungan | Jenis | Nilai Default | Deskripsi |
|---|---|---|---|
RSLEX_DOWNLOADER_THREADS |
u64 | NUMBER_OF_CPU_CORES * 4 |
Jumlah unduhan utas bersamaan yang dapat digunakan |
AZUREML_DATASET_HTTP_RETRY_COUNT |
u64 | 7 | Jumlah upaya coba lagi penyimpanan/ http permintaan individual untuk pulih dari kesalahan sementara. |
Dalam pekerjaan Anda, Anda dapat mengubah default di atas dengan mengatur variabel lingkungan - misalnya:
Untuk brevity, kami hanya menunjukkan cara menentukan variabel lingkungan dalam pekerjaan.
from azure.ai.ml import command
env_var = {
"RSLEX_DOWNLOADER_THREADS": 64,
"AZUREML_DATASET_HTTP_RETRY_COUNT": 10
}
job = command(
environment_variables=env_var
)
Mengunduh metrik performa
Ukuran VM target komputasi Anda berpengaruh pada waktu pengunduhan data Anda. Khususnya:
- Jumlah inti. Semakin banyak core yang tersedia, semakin banyak konkurensi dan oleh karena itu kecepatan unduhan yang lebih cepat.
- Bandwidth jaringan yang diharapkan. Setiap VM di Azure memiliki throughput maksimum dari Kartu Antarmuka Jaringan (NIC).
Catatan
Untuk VM GPU A100, runtime data Azure Pembelajaran Mesin dapat menjenuhkan NIC (Kartu Antarmuka Jaringan) saat mengunduh data ke target komputasi (~24 Gbit/dtk): Throughput maksimum teoritis memungkinkan.
Tabel ini memperlihatkan performa unduhan yang dapat ditangani runtime data Azure Pembelajaran Mesin untuk file 100 GB pada Standard_D15_v2 VM (20cores, throughput Jaringan 25 Gbit/dtk):
| Struktur data | Unduh saja (detik) | Mengunduh dan menghitung MD5 (detik) | Throughput Tercapai (Gbit/dtk) |
|---|---|---|---|
| File 10 x 10 GB | 55.74 | 260.97 | 14,35 Gbit/dtk |
| File 100 x 1 GB | 58.09 | 259.47 | 13,77 Gbit/dtk |
| File 1 x 100 GB | 96.13 | 300,61 | 8,32 Gbit/dtk |
Kita dapat melihat bahwa file yang lebih besar, dipecah menjadi file yang lebih kecil, dapat meningkatkan performa unduhan karena paralelisme. Kami menyarankan agar Anda menghindari file yang menjadi terlalu kecil (kurang dari 4 MB) karena waktu yang diperlukan untuk pengiriman permintaan penyimpanan meningkat, relatif terhadap waktu yang dihabiskan untuk mengunduh payload. Untuk informasi selengkapnya, baca Banyak masalah file kecil.
Mount (streaming)
Dalam mode pemasangan, kemampuan data Azure Pembelajaran Mesin menggunakan fitur Linux FUSE (filesystem di ruang pengguna), untuk membuat sistem file yang ditiru. Alih-alih mengunduh semua data ke disk lokal (SSD) target komputasi, runtime dapat bereaksi terhadap tindakan skrip pengguna secara real time. Misalnya, "buka file", "baca gugus 2-KB dari posisi X", "daftar konten direktori".
| Kelebihan | Kerugian |
|---|---|
| Data yang melebihi kapasitas disk lokal target komputasi dapat digunakan (tidak dibatasi oleh perangkat keras komputasi) | Menambahkan overhead modul FUSE Linux. |
| Tidak ada penundaan di awal pelatihan (tidak seperti mode unduhan). | Dependensi pada perilaku kode pengguna (jika kode pelatihan yang secara berurutan membaca file kecil dalam satu pemasangan utas juga meminta data dari penyimpanan, kode tersebut mungkin tidak memaksimalkan throughput jaringan atau penyimpanan). |
| Pengaturan lain yang tersedia untuk menyetel skenario penggunaan. | Tidak ada dukungan windows. |
| Hanya data yang diperlukan untuk pelatihan yang dibaca dari penyimpanan. |
Kapan menggunakan Mount
- Data besar, dan tidak cocok pada disk lokal target komputasi.
- Setiap simpul komputasi individu dalam kluster tidak perlu membaca seluruh himpunan data (file atau baris acak dalam pemilihan file csv, dll.).
- Penundaan menunggu semua data diunduh sebelum pelatihan dimulai dapat menjadi masalah (waktu GPU menganggur).
Pengaturan pemasangan yang tersedia
Anda dapat menyetel pengaturan pemasangan dengan variabel lingkungan ini dalam pekerjaan Anda:
| Nama variabel Env | Jenis | Nilai default | Deskripsi |
|---|---|---|---|
DATASET_MOUNT_ATTRIBUTE_CACHE_TTL |
u64 | Tidak diatur (cache tidak pernah kedaluwarsa) | Waktu, dalam milidetik, diperlukan untuk menyimpan getattr hasil panggilan dalam cache, dan untuk menghindari permintaan info ini berikutnya dari penyimpanan lagi. |
DATASET_RESERVED_FREE_DISK_SPACE |
u64 | 150 MB | Ditujukan untuk konfigurasi sistem, untuk menjaga komputasi tetap sehat. Apa pun nilai yang dimiliki pengaturan lain, runtime data Azure Pembelajaran Mesin tidak menggunakan byte terakhir RESERVED_FREE_DISK_SPACE ruang disk. |
DATASET_MOUNT_CACHE_SIZE |
usize | Tidak Terbatas | Mengontrol berapa banyak pemasangan ruang disk yang dapat digunakan. Nilai positif menetapkan nilai absolut dalam byte. Nilai negatif menetapkan berapa banyak ruang disk yang akan dilepaskan. Tabel ini menyediakan lebih banyak opsi cache disk. KBMendukung , MB dan GB pengubah untuk kenyamanan. |
DATASET_MOUNT_FILE_CACHE_PRUNE_THRESHOLD |
f64 | 1.0 | Pemasangan volume memulai pemangkasan cache saat cache diisi ke AVAILABLE_CACHE_SIZE * DATASET_MOUNT_FILE_CACHE_PRUNE_THRESHOLD. Harus antara 0 dan 1. Mengaturnya < 1 memicu pemangkasan cache latar belakang sebelumnya. AVAILABLE_CACHE_SIZE bukan variabel lingkungan yang dapat Anda ubah atau lihat secara langsung. Dalam konteks ini, ini mengacu pada "jumlah byte yang dihitung sistem sebagai tersedia untuk penembolokan." Nilai ini tergantung pada faktor-faktor seperti ukuran disk, jumlah ruang disk yang diperlukan untuk kesehatan sistem, dan konfigurasi yang diatur dalam variabel lingkungan (seperti DATASET_RESERVED_FREE_DISK_SPACE dan DATASET_MOUNT_CACHE_SIZE). |
DATASET_MOUNT_FILE_CACHE_PRUNE_TARGET |
f64 | 0,7 | Pemangkasan cache mencoba membebaskan setidaknya (1-DATASET_MOUNT_FILE_CACHE_PRUNE_TARGET) ruang cache. |
DATASET_MOUNT_READ_BLOCK_SIZE |
usize | 2 MB | Ukuran blok baca streaming. Ketika file cukup besar, minta setidaknya DATASET_MOUNT_READ_BLOCK_SIZE data dari penyimpanan, dan cache bahkan ketika operasi baca sekering yang diminta kurang. |
DATASET_MOUNT_READ_BUFFER_BLOCK_COUNT |
usize | 32 | Jumlah blok yang akan diambil sebelumnya (blok baca k memicu prefetching latar belakang blok k+1, ..., k.+DATASET_MOUNT_READ_BUFFER_BLOCK_COUNT) |
DATASET_MOUNT_READ_THREADS |
usize | NUMBER_OF_CORES * 4 |
Jumlah utas prefetching latar belakang. |
DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED |
bool | salah | Aktifkan penembolokan berbasis blok. |
DATASET_MOUNT_MEMORY_CACHE_SIZE |
usize | 128 MB | Berlaku hanya untuk penembolokan berbasis blok. Ukuran penembolokan berbasis blok RAM dapat digunakan. Nilai 0 menonaktifkan penembolokan memori sepenuhnya. |
DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED |
bool | benar | Berlaku hanya untuk penembolokan berbasis blok. Ketika diatur ke true, penembolokan berbasis blok menggunakan hard drive lokal untuk cache blok. |
DATASET_MOUNT_BLOCK_FILE_CACHE_MAX_QUEUE_SIZE |
usize | 512 MB | Berlaku hanya untuk penembolokan berbasis blok. Penembolokan berbasis blok menulis blok cache ke disk lokal di latar belakang. Pengaturan ini mengontrol berapa banyak pemasangan memori yang dapat digunakan untuk menyimpan blok yang menunggu flush ke cache disk lokal. |
DATASET_MOUNT_BLOCK_FILE_CACHE_WRITE_THREADS |
usize | NUMBER_OF_CORES * 2 |
Berlaku hanya untuk penembolokan berbasis blok. Jumlah penggunaan penembolokan berbasis blok utas latar belakang untuk menulis blok yang diunduh ke disk lokal target komputasi. |
DATASET_UNMOUNT_TIMEOUT_SECONDS |
u64 | 30 | Waktu dalam detik untuk unmount (dengan anggun) menyelesaikan semua operasi yang tertunda (misalnya, menghapus panggilan) sebelum menghentikan perulangan pesan pemasangan dengan paksa. |
Dalam pekerjaan Anda, Anda dapat mengubah default di atas dengan mengatur variabel lingkungan, misalnya:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": True
}
job = command(
environment_variables=env_var
)
Mode terbuka berbasis blok
Mode terbuka berbasis blok membagi setiap file menjadi blok dengan ukuran yang telah ditentukan sebelumnya (kecuali untuk blok terakhir). Permintaan baca dari posisi tertentu meminta blok yang sesuai dari penyimpanan, dan segera mengembalikan data yang diminta. Baca juga memicu prefetching latar belakang blok N berikutnya, menggunakan beberapa utas (dioptimalkan untuk baca berurutan). Blok yang diunduh di-cache dalam dua cache lapisan (RAM dan disk lokal).
| Kelebihan | Kerugian |
|---|---|
| Pengiriman data cepat ke skrip pelatihan (lebih sedikit pemblokiran untuk potongan yang belum diminta). | Pembacaan acak dapat membuang blok yang diambil sebelumnya. |
| Lebih banyak offload kerja ke utas latar belakang (prefetching / caching). Pelatihan kemudian dapat dilanjutkan. | Menambahkan overhead untuk menavigasi di antara cache, dibandingkan dengan pembacaan langsung dari file pada cache disk lokal (misalnya, dalam mode cache seluruh file). |
| Hanya data yang diminta (ditambah prefetching) yang dibaca dari penyimpanan. | |
| Untuk data yang cukup kecil, cache berbasis RAM cepat digunakan. |
Kapan menggunakan mode buka berbasis blok
Direkomendasikan untuk sebagian besar skenario kecuali ketika Anda memerlukan bacaan cepat dari lokasi file acak. Dalam kasus tersebut, gunakan mode buka Seluruh cache file.
Seluruh mode buka cache file
Ketika file di bawah folder pemasangan dibuka (misalnya, f = open(path, args)) dalam seluruh mode file, panggilan diblokir hingga seluruh file diunduh ke folder cache target komputasi pada disk. Semua panggilan baca berikutnya dialihkan ke file yang di-cache, sehingga tidak diperlukan interaksi penyimpanan. Jika cache tidak memiliki cukup ruang yang tersedia agar pas dengan file saat ini, pasang mencoba memangkas dengan menghapus file yang paling tidak baru digunakan dari cache. Dalam kasus di mana file tidak dapat pas pada disk (sehubungan dengan pengaturan cache), runtime data kembali ke mode streaming.
| Kelebihan | Kerugian |
|---|---|
| Tidak ada dependensi keandalan/throughput penyimpanan setelah file dibuka. | Panggilan terbuka diblokir hingga seluruh file diunduh. |
| Baca acak cepat (membaca potongan dari tempat acak file). | Seluruh file dibaca dari penyimpanan, bahkan ketika beberapa bagian file mungkin tidak diperlukan. |
Kapan harus menggunakannya
Ketika pembacaan acak diperlukan untuk file yang relatif besar yang melebihi 128 MB.
Penggunaan
Atur variabel DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED lingkungan ke false dalam pekerjaan Anda:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": False
}
job = command(
environment_variables=env_var
)
Mount: Mencantumkan file
Saat bekerja dengan jutaan file, hindari daftar rekursif - misalnya ls -R /mnt/dataset/folder/. Daftar rekursif memicu banyak panggilan untuk mencantumkan konten direktori direktori direktori induk. Kemudian memerlukan panggilan rekursif terpisah untuk setiap direktori di dalamnya, di semua tingkat anak. Biasanya, Azure Storage hanya mengizinkan 5000 elemen untuk dikembalikan per satu permintaan daftar. Akibatnya, daftar rekursif folder 1M yang masing-masing berisi 10 file memerlukan 1,000,000 / 5000 + 1,000,000 = 1,000,200 permintaan ke penyimpanan. Sebagai perbandingan, 1.000 folder dengan 10.000 file hanya akan memerlukan 1001 permintaan ke penyimpanan untuk daftar rekursif.
Pemasangan Azure Pembelajaran Mesin menangani daftar dengan cara yang malas. Oleh karena itu, untuk mencantumkan banyak file kecil, lebih baik menggunakan panggilan pustaka klien berulang (misalnya, os.scandir() di Python) alih-alih panggilan pustaka klien yang mengembalikan daftar lengkap (misalnya, os.listdir() di Python). Panggilan pustaka klien berulang mengembalikan generator, yang berarti tidak perlu menunggu hingga seluruh daftar dimuat. Kemudian dapat dilanjutkan lebih cepat.
Tabel ini membandingkan waktu yang diperlukan untuk Python os.scandir() dan os.listdir() fungsi untuk mencantumkan folder yang berisi ~4M file dalam struktur datar:
| Metrik | os.scandir() |
os.listdir() |
|---|---|---|
| Waktu untuk mendapatkan entri pertama (detik) | 0,67 | 553.79 |
| Waktu untuk mendapatkan entri 50k pertama (detik) | 9,56 | 562.73 |
| Waktu untuk mendapatkan semua entri (detik) | 558.35 | 582.14 |
Pengaturan pemasangan optimal untuk skenario umum
Untuk skenario umum tertentu, kami menunjukkan pengaturan pemasangan optimal yang perlu Anda atur dalam pekerjaan Azure Pembelajaran Mesin Anda.
Membaca file besar secara berurutan satu kali (memproses baris dalam file csv)
Sertakan pengaturan pemasangan ini di bagian environment_variables pekerjaan Azure Pembelajaran Mesin Anda:
Catatan
Untuk menggunakan komputasi tanpa server, hapus compute="cpu-cluster", dalam kode ini.
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": False, # Disable caching on disk
"DATASET_MOUNT_MEMORY_CACHE_SIZE": 0, # Disabling in-memory caching
# Increase the number of blocks used for prefetch. This leads to use of more RAM (2 MB * #value set).
# Can adjust up and down for fine-tuning, depending on the actual data processing pattern.
# An optimal setting based on our test ~= the number of prefetching threads (#CPU_CORES * 4 by default)
"DATASET_MOUNT_READ_BUFFER_BLOCK_COUNT": 80,
}
job = command(
environment_variables=env_var
)
Membaca file besar satu kali dari beberapa utas (memproses file csv yang dipartisi di beberapa utas)
Sertakan pengaturan pemasangan ini di bagian environment_variables pekerjaan Azure Pembelajaran Mesin Anda:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": False, # Disable caching on disk
"DATASET_MOUNT_MEMORY_CACHE_SIZE": 0, # Disabling in-memory caching
}
job = command(
environment_variables=env_var
)
Membaca jutaan file kecil (gambar) dari beberapa utas satu kali (pelatihan epoch tunggal pada gambar)
Sertakan pengaturan pemasangan ini di bagian environment_variables pekerjaan Azure Pembelajaran Mesin Anda:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": False, # Disable caching on disk
"DATASET_MOUNT_MEMORY_CACHE_SIZE": 0, # Disabling in-memory caching
}
job = command(
environment_variables=env_var
)
Membaca jutaan file kecil (gambar) dari beberapa utas beberapa kali (beberapa epoch pelatihan pada gambar)
Sertakan pengaturan pemasangan ini di bagian environment_variables pekerjaan Azure Pembelajaran Mesin Anda:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
}
job = command(
environment_variables=env_var
)
Membaca file besar dengan pencarian acak (seperti menyajikan database file dari folder yang dipasang)
Sertakan pengaturan pemasangan ini di bagian environment_variables pekerjaan Azure Pembelajaran Mesin Anda:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": False, # Disable block-based caching
}
job = command(
environment_variables=env_var
)
Mendiagnosis dan memecahkan hambatan pemuatan data
Saat pekerjaan Azure Pembelajaran Mesin dijalankan dengan data, mode input menentukan bagaimana byte dibaca dari penyimpanan dan di-cache pada disk SSD lokal target komputasi. Untuk mode unduhan, semua cache data pada disk, sebelum kode pengguna memulai eksekusinya. Oleh karena itu, faktor-faktor seperti
- jumlah utas paralel
- jumlah file
- ukuran file
memiliki efek pada kecepatan unduhan maksimum. Untuk pemasangan, kode pengguna harus mulai membuka file sebelum data mulai di-cache. Pengaturan pemasangan yang berbeda menghasilkan perilaku pembacaan dan penembolokan yang berbeda. Berbagai faktor memiliki efek pada kecepatan yang dimuat data dari penyimpanan:
- Lokalitas data ke komputasi: Lokasi penyimpanan dan target komputasi Anda harus sama. Jika target penyimpanan dan komputasi Anda terletak di wilayah yang berbeda, performa menuram karena data harus ditransfer di seluruh wilayah. Untuk informasi selengkapnya tentang cara memastikan bahwa data Anda terkolokasi dengan komputasi, kunjungi Data kolokasi dengan komputasi.
- Ukuran target komputasi: Komputasi kecil memiliki jumlah inti yang lebih rendah (kurang paralelisme) dan bandwidth jaringan yang diharapkan lebih kecil dibandingkan dengan ukuran komputasi yang lebih besar - kedua faktor memengaruhi performa pemuatan data.
- Misalnya, jika Anda menggunakan ukuran VM kecil, seperti
Standard_D2_v2(2 inti, 1500 Mbps NIC), dan Anda mencoba memuat data 50.000 MB (50 GB), waktu pemuatan data yang dapat dicapai terbaik adalah ~270 detik (dengan asumsi Anda menjenuhkan NIC pada throughput 187,5-MB/dtk). Sebaliknya,Standard_D5_v2(16 core, 12.000 Mbps) akan memuat data yang sama dalam ~33 detik (dengan asumsi Anda menjenuhkan NIC pada throughput 1500-MB/dtk).
- Misalnya, jika Anda menggunakan ukuran VM kecil, seperti
- Tingkat penyimpanan: Untuk sebagian besar skenario - termasuk Model Bahasa Besar (LLM) - penyimpanan standar menyediakan profil biaya/performa terbaik. Namun, jika Anda memiliki banyak file kecil, penyimpanan premium menawarkan profil biaya/performa yang lebih baik. Untuk informasi selengkapnya, baca opsi Azure Storage.
- Beban penyimpanan: Jika akun penyimpanan berada di bawah beban tinggi - misalnya, banyak simpul GPU dalam kluster yang meminta data - maka Anda berisiko mencapai kapasitas penyimpanan keluar. Untuk informasi selengkapnya, baca Beban penyimpanan. Jika Anda memiliki banyak file kecil yang membutuhkan akses secara paralel, Anda mungkin mencapai batas permintaan penyimpanan. Baca informasi terbaru tentang batas untuk kapasitas keluar dan permintaan penyimpanan di Target skala untuk akun penyimpanan standar.
- Pola akses data dalam kode pengguna: Saat Anda menggunakan mode pemasangan, data diambil berdasarkan tindakan buka/baca dalam kode Anda. Misalnya, saat membaca bagian acak dari file besar, pengaturan prefetching data default pemasangan dapat menyebabkan unduhan blok yang tidak akan dibaca. Anda mungkin perlu menyetel beberapa pengaturan untuk mencapai throughput maksimum. Untuk informasi selengkapnya, baca Pengaturan pemasangan optimal untuk skenario umum.
Menggunakan log untuk mendiagnosis masalah
Untuk mengakses log runtime data dari pekerjaan Anda:
- Pilih tab Output+Log dari halaman pekerjaan.
- Pilih folder system_logs, diikuti dengan folder data_capability.
- Anda akan melihat dua file log:
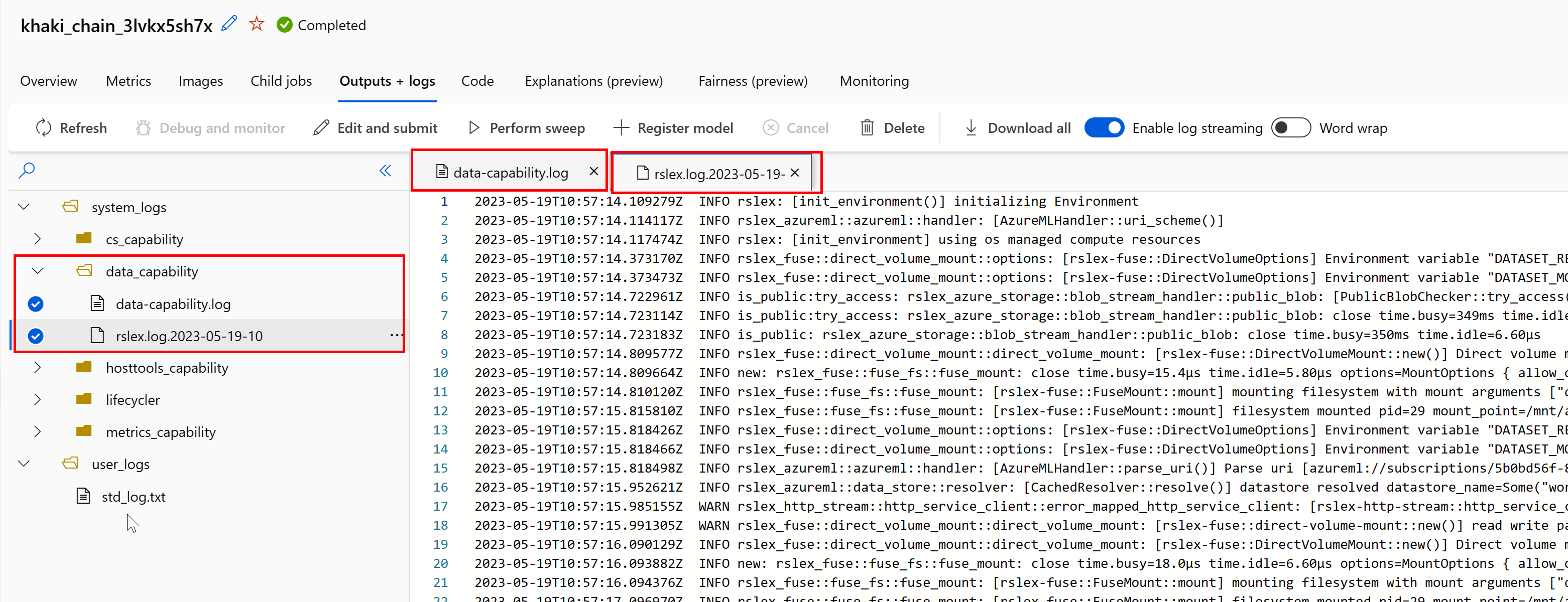

File log data-capability.log menunjukkan informasi tingkat tinggi tentang waktu yang dihabiskan untuk tugas pemuatan data utama. Misalnya, saat Anda mengunduh data, runtime mencatat waktu mulai dan selesai aktivitas unduhan:
INFO 2023-05-18 17:14:47,790 sdk_logger.py:44 [28] - ActivityStarted, download
INFO 2023-05-18 17:14:50,295 sdk_logger.py:44 [28] - ActivityCompleted: Activity=download, HowEnded=Success, Duration=2504.39 [ms]
Jika throughput unduhan adalah sebagian kecil dari bandwidth jaringan yang diharapkan untuk ukuran VM, Anda dapat memeriksa file log rslex.log.<>TANDA WAKTU. File ini berisi semua pencatatan butiran halus dari runtime berbasis Rust; misalnya, paralelisasi:
2023-05-18T14:08:25.388670Z INFO copy_uri:copy_uri:copy_dataset:write_streams_to_files:collect:reduce:reduce_and_combine:reduce:get_iter: rslex::prefetching: close time.busy=23.2µs time.idle=1.90µs sessionId=012ea46a-341c-4258-8aba-90bde4fdfb51 source=Dataset[Partitions: 1, Sources: 1] file_name_column=None break_on_first_error=true skip_existing_files=false parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 i=0 index=0
2023-05-18T14:08:25.388731Z INFO copy_uri:copy_uri:copy_dataset:write_streams_to_files:collect:reduce:reduce_and_combine:reduce: rslex::dataset_crossbeam: close time.busy=90.9µs time.idle=9.10µs sessionId=012ea46a-341c-4258-8aba-90bde4fdfb51 source=Dataset[Partitions: 1, Sources: 1] file_name_column=None break_on_first_error=true skip_existing_files=false parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 i=0
2023-05-18T14:08:25.388762Z INFO copy_uri:copy_uri:copy_dataset:write_streams_to_files:collect:reduce:reduce_and_combine:combine: rslex::dataset_crossbeam: close time.busy=1.22ms time.idle=9.50µs sessionId=012ea46a-341c-4258-8aba-90bde4fdfb51 source=Dataset[Partitions: 1, Sources: 1] file_name_column=None break_on_first_error=true skip_existing_files=false parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4
File rslex.log menyediakan detail tentang semua penyalinan file, apakah Anda memilih mode pemasangan atau unduhan atau tidak. Ini juga menjelaskan Pengaturan (variabel lingkungan) yang digunakan. Untuk memulai penelusuran kesalahan, periksa apakah Anda mengatur pengaturan Pemasangan optimal untuk skenario umum.
Memantau penyimpanan Azure
Di portal Azure, Anda dapat memilih akun Penyimpanan, lalu Metrik, untuk melihat metrik penyimpanan:

Anda kemudian memplot SuccessE2ELatency dengan SuccessServerLatency. Jika metrik menunjukkan SuccessE2ELatency yang tinggi dan SuccessServerLatency rendah, Anda memiliki utas terbatas yang tersedia, atau Anda kehabisan sumber daya seperti CPU, memori, atau bandwidth jaringan, Anda harus:
- Gunakan tampilan pemantauan di studio Azure Pembelajaran Mesin untuk memeriksa pemanfaatan CPU dan memori pekerjaan Anda. Jika Anda kekurangan CPU dan memori, pertimbangkan untuk meningkatkan ukuran VM target komputasi.
- Pertimbangkan untuk meningkat
RSLEX_DOWNLOADER_THREADSjika Anda mengunduh dan Anda tidak menggunakan CPU dan memori. Jika Anda menggunakan pemasangan, Anda harus meningkatkanDATASET_MOUNT_READ_BUFFER_BLOCK_COUNTuntuk melakukan lebih banyak prefetching, dan meningkatkanDATASET_MOUNT_READ_THREADSuntuk lebih banyak utas baca.
Jika metrik menunjukkan SuccessE2ELatency rendah dan SuccessServerLatency rendah, tetapi klien mengalami latensi tinggi, Anda memiliki keterlambatan dalam permintaan penyimpanan yang mencapai layanan. Anda harus memeriksa:
- Apakah jumlah utas yang digunakan untuk pemasangan/unduh (
DATASET_MOUNT_READ_THREADS/RSLEX_DOWNLOADER_THREADS) diatur terlalu rendah, relatif terhadap jumlah inti yang tersedia pada target komputasi. Jika pengaturan terlalu rendah, tingkatkan jumlah utas. - Apakah jumlah percobaan ulang untuk pengunduhan (
AZUREML_DATASET_HTTP_RETRY_COUNT) diatur terlalu tinggi. Jika demikian, kurangi jumlah percobaan ulang.
Memantau penggunaan disk selama pekerjaan
Dari studio Azure Pembelajaran Mesin, Anda juga dapat memantau IO disk target komputasi dan penggunaan selama eksekusi pekerjaan Anda. Navigasi ke pekerjaan Anda, dan pilih tab Pemantauan . Tab ini memberikan wawasan tentang sumber daya pekerjaan Anda, secara bergulir selama 30 hari. Contohnya:

Catatan
Pemantauan pekerjaan hanya mendukung sumber daya komputasi yang dikelola azure Pembelajaran Mesin. Pekerjaan dengan runtime kurang dari 5 menit tidak akan memiliki cukup data untuk mengisi tampilan ini.
Runtime data Azure Pembelajaran Mesin tidak menggunakan byte terakhir RESERVED_FREE_DISK_SPACE ruang disk, untuk menjaga komputasi tetap sehat (nilai defaultnya adalah 150MB). Jika disk Anda penuh, kode Anda menulis file ke disk tanpa mendeklarasikan file sebagai output. Oleh karena itu, periksa kode Anda untuk memastikan bahwa data tidak ditulis secara keliru ke disk sementara. Jika Anda harus menulis file ke disk sementara, dan sumber daya tersebut menjadi penuh, pertimbangkan:
- Meningkatkan Ukuran VM menjadi disk sementara yang memiliki disk sementara yang lebih besar
- Mengatur TTL pada data yang di-cache (
DATASET_MOUNT_ATTRIBUTE_CACHE_TTL), untuk menghapus menyeluruh data Anda dari disk
Kolokasikan data dengan komputasi
Perhatian
Jika penyimpanan dan komputasi Anda berada di wilayah yang berbeda, performa Anda menurut karena data harus ditransfer di seluruh wilayah. Ini meningkatkan biaya. Pastikan akun penyimpanan dan sumber daya komputasi Anda berada di wilayah yang sama.
Jika data Anda dan Ruang Kerja Azure Pembelajaran Mesin disimpan di wilayah yang berbeda, kami sarankan Anda menyalin data ke akun penyimpanan di wilayah yang sama dengan utilitas azcopy. AzCopy menggunakan API server-ke-server, sehingga data disalin langsung di antara server penyimpanan. Operasi salin ini tidak menggunakan bandwidth jaringan komputer Anda. Anda dapat meningkatkan throughput operasi ini dengan AZCOPY_CONCURRENCY_VALUE variabel lingkungan. Untuk mempelajari selengkapnya, lihat Meningkatkan konkurensi.
Beban penyimpanan
Satu akun penyimpanan dapat menjadi dibatasi ketika berada di bawah beban tinggi, ketika:
- Pekerjaan Anda menggunakan banyak simpul GPU
- Akun penyimpanan Anda memiliki banyak pengguna/aplikasi bersamaan yang mengakses data saat Anda menjalankan pekerjaan Anda
Bagian ini menunjukkan perhitungan untuk menentukan apakah pembatasan mungkin menjadi masalah untuk beban kerja Anda, dan cara mendekati pengurangan pembatasan.
Menghitung batas bandwidth
Akun Azure Storage memiliki batas keluar default 120 Gbit/dtk. Azure VM memiliki bandwidth jaringan yang berbeda, yang memiliki efek pada jumlah teoritis simpul komputasi yang diperlukan untuk mencapai kapasitas keluar default maksimum penyimpanan:
| Ukuran | Kartu GPU | vCPU | Memori: GiB | Penyimpanan sementara (SSD) GiB | Jumlah Kartu GPU | Memori GPU: GiB | Bandwidth jaringan yang diharapkan (Gbit/dtk) | Maks Default Keluar Akun Penyimpanan (Gbit/dtk)* | Jumlah Simpul yang akan mencapai kapasitas keluar default |
|---|---|---|---|---|---|---|---|---|---|
| Standard_ND96asr_v4 | A100 | 96 | 900 | 6000 | 8 | 40 | 24 | 120 | 5 |
| Standard_ND96amsr_A100_v4 | A100 | 96 | 1900 | 6400 | 8 | 80 | 24 | 120 | 5 |
| Standard_NC6s_v3 | V100 | 6 | 112 | 736 | 1 | 16 | 24 | 120 | 5 |
| Standard_NC12s_v3 | V100 | 12 | 224 | 1474 | 2 | 32 | 24 | 120 | 5 |
| Standard_NC24s_v3 | V100 | 24 | 448 | 2948 | 4 | 64 | 24 | 120 | 5 |
| Standard_NC24rs_v3 | V100 | 24 | 448 | 2948 | 4 | 64 | 24 | 120 | 5 |
| Standard_NC4as_T4_v3 | T4 | 4 | 28 | 180 | 1 | 16 | 8 | 120 | 15 |
| Standard_NC8as_T4_v3 | T4 | 8 | 56 | 360 | 1 | 16 | 8 | 120 | 15 |
| Standard_NC16as_T4_v3 | T4 | 16 | 110 | 360 | 1 | 16 | 8 | 120 | 15 |
| Standard_NC64as_T4_v3 | T4 | 64 | 440 | 2880 | 4 | 64 | 32 | 120 | 3 |
Kedua SKU A100/V100 memiliki bandwidth jaringan maksimum per simpul 24 Gbit/dtk. Jika setiap simpul yang membaca data dari satu akun dapat membaca mendekati maksimum teoritis 24 Gbit/dtk, kapasitas keluar akan terjadi dengan lima simpul. Penggunaan enam simpul komputasi atau lebih akan mulai menurunkan throughput data di semua simpul.
Penting
Jika beban kerja Anda membutuhkan lebih dari 6 simpul A100/V100, atau Anda yakin Anda akan melebihi kapasitas penyimpanan keluar default (120Gbit/dtk), hubungi dukungan (melalui Portal Microsoft Azure) dan minta peningkatan batas keluar penyimpanan.
Menskalakan di beberapa akun penyimpanan
Anda mungkin melebihi kapasitas keluar maksimum penyimpanan, dan/atau Anda mungkin mencapai batas tingkat permintaan. Jika masalah ini terjadi, kami sarankan Anda menghubungi dukungan terlebih dahulu, untuk meningkatkan batas ini pada akun penyimpanan.
Jika Anda tidak dapat meningkatkan kapasitas keluar maksimum atau batas tingkat permintaan, Anda harus mempertimbangkan untuk mereplikasi data di beberapa akun penyimpanan. Salin data ke beberapa akun dengan Azure Data Factory, Azure Storage Explorer, atau azcopy, dan pasang semua akun dalam pekerjaan pelatihan Anda. Hanya data yang diakses pada pemasangan yang diunduh. Oleh karena itu, kode pelatihan Anda dapat membaca RANK dari variabel lingkungan, untuk memilih mana dari beberapa input yang dipasang untuk dibaca. Definisi pekerjaan Anda lolos dalam daftar akun penyimpanan:
$schema: https://azuremlschemas.azureedge.net/latest/commandJob.schema.json
code: src
command: >-
python train.py
--epochs ${{inputs.epochs}}
--learning-rate ${{inputs.learning_rate}}
--data ${{inputs.cifar_storage1}}, ${{inputs.cifar_storage2}}
inputs:
epochs: 1
learning_rate: 0.2
cifar_storage1:
type: uri_folder
path: azureml://datastores/storage1/paths/cifar
cifar_storage2:
type: uri_folder
path: azureml://datastores/storage2/paths/cifar
environment: azureml:AzureML-pytorch-1.9-ubuntu18.04-py37-cuda11-gpu@latest
compute: azureml:gpu-cluster
distribution:
type: pytorch
process_count_per_instance: 1
resources:
instance_count: 2
display_name: pytorch-cifar-distributed-example
experiment_name: pytorch-cifar-distributed-example
description: Train a basic convolutional neural network (CNN) with PyTorch on the CIFAR-10 dataset, distributed via PyTorch.
Kode python pelatihan Anda kemudian dapat digunakan RANK untuk mendapatkan akun penyimpanan khusus untuk simpul tersebut:
import argparse
import os
parser = argparse.ArgumentParser()
parser.add_argument('--data', nargs='+')
args = parser.parse_args()
world_size = int(os.environ["WORLD_SIZE"])
rank = int(os.environ["RANK"])
local_rank = int(os.environ["LOCAL_RANK"])
data_path_for_this_rank = args.data[rank]
Banyak masalah file kecil
Membaca file dari penyimpanan melibatkan pembuatan permintaan untuk setiap file. Jumlah permintaan per file bervariasi, berdasarkan ukuran file dan pengaturan perangkat lunak yang menangani pembacaan file.
File biasanya dibaca dalam blok berukuran 1-4 MB. File yang lebih kecil dari blok dibaca dengan satu permintaan (GET file.jpg 0-4MB), dan file yang lebih besar dari blok memiliki satu permintaan yang dibuat per blok (GET file.jpg 0-4MB, GET file.jpg 4-8 MB). Tabel ini menunjukkan bahwa file yang lebih kecil dari blok 4-MB menghasilkan lebih banyak permintaan penyimpanan dibandingkan dengan file yang lebih besar:
| # File | Ukuran File | Ukuran data total | Ukuran blok | # Permintaan penyimpanan |
|---|---|---|---|---|
| 2.000.000 | 500KB | 1 TB | 4 MB | 2.000.000 |
| 1,000 | 1 GB | 1 TB | 4 MB | 256.000 |
Untuk file kecil, interval latensi sebagian besar melibatkan penanganan permintaan ke penyimpanan, bukan transfer data. Oleh karena itu, kami menawarkan rekomendasi ini untuk meningkatkan ukuran file:
- Untuk data yang tidak terstruktur (gambar, teks, video, dll.), arsipkan (zip/tar) file kecil bersama-sama, untuk menyimpannya sebagai file yang lebih besar yang dapat dibaca dalam beberapa gugus. File yang diarsipkan yang lebih besar ini dapat dibuka di sumber daya komputasi, dan PyTorch Archive DataPipes dapat mengekstrak file yang lebih kecil.
- Untuk data terstruktur (CSV, parket, dll.), periksa proses ETL Anda, untuk memastikan bahwa file menyatukan untuk meningkatkan ukuran. Spark memiliki
repartition()metode dancoalesce()untuk membantu meningkatkan ukuran file.
Jika Anda tidak dapat meningkatkan ukuran file, jelajahi opsi Azure Storage Anda.
Opsi Azure Storage
Azure Storage menawarkan dua tingkatan - standar dan premium:
| Penyimpanan | Skenario |
|---|---|
| Azure Blob - Standar (HDD) | Data Anda disusun dalam blob yang lebih besar - gambar, video, dll. |
| Azure Blob - Premium (SSD) | Tingkat transaksi tinggi, objek yang lebih kecil, atau persyaratan latensi penyimpanan yang rendah secara konsisten |
Tip
Untuk file kecil "banyak" (besaran KB), sebaiknya gunakan premium (SSD) karena biaya penyimpanan kurang dari biaya menjalankan komputasi GPU.
Membaca aset data untuk V1
Bagian ini menjelaskan cara membaca V1 FileDataset dan TabularDataset entitas data dalam pekerjaan V2.
Membaca FileDataset
Input Dalam objek , tentukan type sebagai AssetTypes.MLTABLE dan mode sebagai InputOutputModes.EVAL_MOUNT:
Catatan
Untuk menggunakan komputasi tanpa server, hapus compute="cpu-cluster", dalam kode ini.
Untuk informasi selengkapnya tentang objek MLClient, opsi inisialisasi objek MLClient, dan cara menyambungkan ke ruang kerja, kunjungi Menyambungkan ke ruang kerja.
from azure.ai.ml import command
from azure.ai.ml.entities import Data
from azure.ai.ml import Input
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.ai.ml import MLClient
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
filedataset_asset = ml_client.data.get(name="<filedataset_name>", version="<version>")
my_job_inputs = {
"input_data": Input(
type=AssetTypes.MLTABLE,
path=filedataset_asset.id,
mode=InputOutputModes.EVAL_MOUNT
)
}
job = command(
code="./src", # Local path where the code is stored
command="ls ${{inputs.input_data}}",
inputs=my_job_inputs,
environment="<environment_name>:<version>",
compute="cpu-cluster",
)
# Submit the command
returned_job = ml_client.jobs.create_or_update(job)
# Get a URL for the job status
returned_job.services["Studio"].endpoint
Membaca TabularDataset
Input Dalam objek , tentukan type sebagai AssetTypes.MLTABLE, dan mode sebagai InputOutputModes.DIRECT:
Catatan
Untuk menggunakan komputasi tanpa server, hapus compute="cpu-cluster", dalam kode ini.
from azure.ai.ml import command
from azure.ai.ml.entities import Data
from azure.ai.ml import Input
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.ai.ml import MLClient
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
filedataset_asset = ml_client.data.get(name="<tabulardataset_name>", version="<version>")
my_job_inputs = {
"input_data": Input(
type=AssetTypes.MLTABLE,
path=filedataset_asset.id,
mode=InputOutputModes.DIRECT
)
}
job = command(
code="./src", # Local path where the code is stored
command="python train.py --inputs ${{inputs.input_data}}",
inputs=my_job_inputs,
environment="<environment_name>:<version>",
compute="cpu-cluster",
)
# Submit the command
returned_job = ml_client.jobs.create_or_update(job)
# Get a URL for the status of the job
returned_job.services["Studio"].endpoint