Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
BERLAKU UNTUK: Ekstensi ml Azure CLI v2 (saat ini)Python SDK azure-ai-ml v2 (saat ini)
Ekstensi ml Azure CLI v2 (saat ini)Python SDK azure-ai-ml v2 (saat ini)
Otomatiskan penyetelan hyperparameter yang efisien menggunakan Azure Machine Learning SDK v2 dan CLI v2 melalui jenis SweepJob.
- Menentukan ruang pencarian parameter untuk uji coba Anda
- Menentukan algoritma pengambilan sampel untuk pekerjaan pembersihan Anda
- Menentukan tujuan yang akan dioptimalkan
- Menentukan kebijakan penghentian awal untuk pekerjaan berperforma rendah
- Menentukan batas untuk pekerjaan pembersihan
- Meluncurkan eksperimen dengan konfigurasi yang ditentukan
- Memvisualisasikan pekerjaan pelatihan
- Memilih konfigurasi terbaik untuk model Anda
Apa itu penyetelan hyperparameter?
Hyperparameter adalah parameter yang dapat disesuaikan yang memungkinkan Anda mengontrol proses pelatihan model. Misalnya, dengan jaringan neural, Anda memutuskan jumlah lapisan tersembunyi dan jumlah simpul di setiap lapisan. Kinerja model sangat bergantung pada hyperparameter.
Penyetelan hyperparameter, juga disebut pengoptimalan hyperparameter, adalah proses menemukan konfigurasi hyperparameter yang menghasilkan kinerja terbaik. Proses ini cenderung bersifat manual dan mahal secara komputasi.
Azure Machine Learning memungkinkan Anda mengotomatiskan penyetelan hyperparameter dan menjalankan eksperimen secara paralel untuk mengoptimalkan hyperparameter secara efisien.
Menentukan ruang pencarian
Menyetel hyperparameter dengan mempelajari rentang nilai yang ditentukan untuk setiap hyperparameter.
Hyperparameter dapat bersifat diskret atau berkelanjutan, dan memiliki distribusi nilai yang dijelaskan oleh ekspresi parameter.
Hiperparameter diskrit
Hyperparameter diskret ditentukan sebagai Choice di antara nilai diskret.
Choice dapat berupa:
- satu atau beberapa nilai yang dipisahkan koma
- objek
range - objek
listarbitrer apa pun
from azure.ai.ml.sweep import Choice
command_job_for_sweep = command_job(
batch_size=Choice(values=[16, 32, 64, 128]),
number_of_hidden_layers=Choice(values=range(1,5)),
)
Dalam hal ini, batch_size salah satu nilai [16, 32, 64, 128] dan number_of_hidden_layers mengambil salah satu nilai [1, 2, 3, 4].
Hyperparameter diskret berikut juga dapat ditentukan menggunakan distribusi:
-
QUniform(min_value, max_value, q)- Menampilkan nilai seperti round(Uniform(min_value, max_value) / q) * q -
QLogUniform(min_value, max_value, q)- Menampilkan nilai seperti round(exp(Uniform(min_value, max_value)) / q) * q -
QNormal(mu, sigma, q)-Menampilkan nilai seperti round(Normal(mu, sigma) / q) * q -
QLogNormal(mu, sigma, q)- Menampilkan nilai seperti round(exp(Normal(mu, sigma)) / q) * q
Hiperparameter berkelanjutan
Hyperparameter berkelanjutan ditentukan sebagai distribusi dalam rentang nilai berkelanjutan:
-
Uniform(min_value, max_value)- Menampilkan nilai yang didistribusikan secara seragam antara min_value dan max_value -
LogUniform(min_value, max_value)- Menampilkan nilai yang digambarkan menurut exp(Uniform(min_value, max_value)) sehingga logaritma nilai yang ditampilkan didistribusikan secara seragam -
Normal(mu, sigma)- Mengembalikan nilai riil yang biasanya didistribusikan dengan rata-rata mu dan sigma simpangan baku -
LogNormal(mu, sigma)- Menampilkan nilai yang digambarkan menurut exp(Normal(mu, sigma)) sehingga logaritma dari nilai yang ditampilkan didistribusikan secara normal
Contoh definisi ruang parameter:
from azure.ai.ml.sweep import Normal, Uniform
command_job_for_sweep = command_job(
learning_rate=Normal(mu=10, sigma=3),
keep_probability=Uniform(min_value=0.05, max_value=0.1),
)
Kode ini mendefinisikan ruang pencarian dengan dua parameter - learning_rate dan keep_probability.
learning_rate memiliki distribusi normal dengan nilai rata-rata 10 dan simpangan baku 3.
keep_probability memiliki distribusi seragam dengan nilai minimum 0,05 dan nilai maksimum 0,1.
Untuk CLI, Anda dapat menggunakan skema YAML pekerjaan pembersihan, untuk menentukan ruang pencarian di YAML Anda:
search_space:
conv_size:
type: choice
values: [2, 5, 7]
dropout_rate:
type: uniform
min_value: 0.1
max_value: 0.2
Mengambil sampel ruang hyperparameter
Tentukan metode pengambilan sampel parameter untuk digunakan di atas ruang hyperparameter. Azure Machine Learning mendukung metode berikut:
- Pengambilan sampel acak
- Pengambilan sampel kisi
- Pengambilan sampel Bayesian
Pengambilan sampel acak
Pengambilan sampel acak mendukung hyperparameter diskret dan berkelanjutan. Pengambilan ini mendukung penghentian awal eksekusi berperforma rendah. Beberapa pengguna melakukan pencarian awal dengan pengambilan sampel acak dan kemudian mempersempit ruang pencarian untuk meningkatkan hasil.
Dalam pengambilan sampel acak, nilai hyperparameter dipilih secara acak dari ruang pencarian yang ditentukan. Setelah membuat pekerjaan perintah, Anda dapat menggunakan parameter pembersihan untuk menentukan algoritma pengambilan sampel.
from azure.ai.ml.sweep import Normal, Uniform, RandomParameterSampling
command_job_for_sweep = command_job(
learning_rate=Normal(mu=10, sigma=3),
keep_probability=Uniform(min_value=0.05, max_value=0.1),
batch_size=Choice(values=[16, 32, 64, 128]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "random",
...
)
Sobol
Sobol adalah jenis pengambilan sampel acak yang didukung oleh jenis pekerjaan pembersihan. Anda dapat menggunakan sobol untuk mereproduksi hasil Anda menggunakan nilai awal dan mencakup distribusi ruang pencarian secara lebih merata.
Agar dapat menggunakan sobol, gunakan kelas RandomParameterSampling untuk menambahkan nilai awal dan aturan seperti yang ditunjukkan pada contoh di bawah ini.
from azure.ai.ml.sweep import RandomParameterSampling
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = RandomParameterSampling(seed=123, rule="sobol"),
...
)
Pengambilan sampel kisi
Pengambilan sampel kisi mendukung hyperparameter diskrit. Menggunakan pengambilan sampel kisi jika Anda dapat menganggarkan untuk mencari ruang pencarian secara menyeluruh. Mendukung penghentian awal dari pekerjaan berperforma rendah.
Pengambilan sampel kisi melakukan pencarian kisi sederhana atas semua nilai yang memungkinkan. Pengambilan sampel kisi hanya dapat digunakan dengan hyperparameter choice. Misalnya, ruang berikut memiliki enam sampel:
from azure.ai.ml.sweep import Choice
command_job_for_sweep = command_job(
batch_size=Choice(values=[16, 32]),
number_of_hidden_layers=Choice(values=[1,2,3]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "grid",
...
)
Pengambilan sampel Bayesian
Pengambilan sampel bayes didasarkan pada algoritma pengoptimalan bayes. Pengambilan sampel ini memilih sampel berdasarkan cara sampel sebelumnya diambil, sehingga sampel baru meningkatkan metrik utama.
Pengambilan sampel bayes disarankan jika Anda memiliki anggaran yang cukup untuk menjelajahi ruang hyperparameter. Untuk hasil terbaik, kami merekomendasikan jumlah maksimum pekerjaan yang lebih besar dari atau sama dengan 20 kali jumlah hyperparameter yang disetel.
Jumlah pekerjaan serentak berdampak pada efektivitas proses penyetelan. Jumlah pekerjaan serentak yang lebih kecil dapat menyebabkan konvergensi pengambilan sampel yang lebih baik, karena tingkat paralelisme yang lebih kecil meningkatkan jumlah pekerjaan yang mendapat keuntungan dari eksekusi yang telah selesai sebelumnya.
Pengambilan sampel bayes hanya mendukung distribusi choice, uniform, dan quniform pada ruang pencarian.
from azure.ai.ml.sweep import Uniform, Choice
command_job_for_sweep = command_job(
learning_rate=Uniform(min_value=0.05, max_value=0.1),
batch_size=Choice(values=[16, 32, 64, 128]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "bayesian",
...
)
Menentukan tujuan pembersihan
Tentukan tujuan pekerjaan pembersihan Anda dengan menetapkan metrik utama dan sasaran yang ingin dioptimalkan oleh penyetelan hyperparameter. Setiap pekerjaan pelatihan dievaluasi untuk metrik utama. Kebijakan penghentian awal menggunakan metrik utama untuk mengidentifikasi eksekusi berperforma rendah.
-
primary_metric: Nama metrik utama harus sama persis dengan nama metrik yang telah dicatat di log oleh skrip pelatihan -
goal: Hal tersebut dapat berupaMaximizeatauMinimizedan menentukan apakah metrik utama akan dimaksimalkan atau diminimalkan saat mengevaluasi pekerjaan tersebut.
from azure.ai.ml.sweep import Uniform, Choice
command_job_for_sweep = command_job(
learning_rate=Uniform(min_value=0.05, max_value=0.1),
batch_size=Choice(values=[16, 32, 64, 128]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "bayesian",
primary_metric="accuracy",
goal="Maximize",
)
Sampel ini memaksimalkan "accuracy".
Membuat log metrik untuk penyetelan hyperparameter
Skrip pelatihan untuk model haru membuat log metrik utama selama pelatihan model menggunakan nama metrik sama yang sesuai sehingga SweepJob dapat mengaksesnya untuk penyesuaian hyperparameter.
Buat log metrik utama dalam skrip pelatihan Anda dengan cuplikan sampel berikut:
import mlflow
mlflow.log_metric("accuracy", float(val_accuracy))
Skrip pelatihan menghitung val_accuracy dan membuat log sebagai metrik utama "accuracy". Setiap kali metrik dicatat di log, metrik diterima oleh layanan penyetelan hyperparameter. Anda dapat menentukan frekuensi pelaporan sesuai keinginan Anda.
Untuk informasi selengkapnya tentang nilai pengelogan untuk pekerjaan pelatihan, lihat Mengaktifkan pengelogan di Azure Pembelajaran Mesin pekerjaan pelatihan.
Tentukan kebijakan penghentian dini
Secara otomatis mengakhiri pekerjaan berperforma buruk dengan kebijakan penghentian awal. Penghentian dini meningkatkan efisiensi komputasi.
Anda dapat mengonfigurasi parameter berikut yang mengontrol kapan kebijakan diterapkan:
-
evaluation_interval: frekuensi penerapan kebijakan. Setiap kali skrip pelatihan membuat log metrik utama dihitung sebagai satu interval.evaluation_interval1 akan menerapkan kebijakan setiap kali skrip pelatihan melaporkan metrik utama.evaluation_interval2 akan menerapkan kebijakan setiap waktu lain. Jika tidak ditentukan,evaluation_intervaldiatur ke 0 secara default. -
delay_evaluation: menunda evaluasi kebijakan pertama untuk jumlah interval yang ditentukan. Parameter ini adalah parameter opsional yang menghindari penghentian awal dari job pelatihan dengan mengizinkan semua konfigurasi berjalan untuk jumlah interval minimum. Jika ditentukan, kebijakan ini menerapkan setiap kelipatan evaluation_interval yang lebih besar dari atau sama dengan delay_evaluation. Jika tidak ditentukan,delay_evaluationdiatur ke 0 secara default.
Azure Machine Learning mendukung kebijakan penghentian dini berikut:
- Kebijakan bandit
- Kebijakan penghentian median
- Kebijakan pemilihan pemotongan
- Tidak ada kebijakan penghentian
Kebijakan bandit
Kebijakan bandit didasarkan pada faktor kelonggaran/jumlah kelonggaran dan interval evaluasi. Kebijakan bandit mengakhiri pekerjaan saat metrik utama tidak berada dalam faktor slack/jumlah slack tertentu dari pekerjaan paling sukses.
Menentukan parameter konfigurasi berikut:
slack_factoratauslack_amount: slack yang diizinkan sehubungan dengan pekerjaan pelatihan yang berperforma terbaik.slack_factormenentukan kelonggaran yang diperbolehkan sebagai rasio.slack_amountmenentukan kelonggaran yang diperbolehkan sebagai jumlah absolut, bukan rasio.Misalnya, pertimbangkan kebijakan Bandit yang diterapkan pada interval 10. Asumsikan bahwa pekerjaan berperforma terbaik pada interval 10 yang melaporkan metrik utama adalah 0,8 dengan sasaran untuk memaksimalkan metrik utama. Jika kebijakan menentukan
slack_factor0,2, setiap pekerjaan pelatihan yang metrik terbaiknya pada interval 10 kurang dari 0,66 (0,8/(1+slack_factor)) akan dihentikan.evaluation_interval: (opsional) frekuensi penerapan kebijakandelay_evaluation: (opsional) menunda evaluasi kebijakan pertama untuk jumlah interval yang ditentukan
from azure.ai.ml.sweep import BanditPolicy
sweep_job.early_termination = BanditPolicy(slack_factor = 0.1, delay_evaluation = 5, evaluation_interval = 1)
Dalam contoh ini, kebijakan penghentian dini diterapkan pada setiap interval ketika metrik dilaporkan, dimulai pada interval evaluasi 5. Setiap eksekusi yang metrik terbaiknya kurang dari (1/(1+0,1) atau 91% dari pekerjaan berperforma terbaik akan dihentikan.
Kebijakan penghentian median
Penghentian median adalah kebijakan penghentian awal berdasarkan eksekusi rata-rata metrik utama yang dilaporkan oleh pekerjaan tersebut. Kebijakan ini menghitung eksekusi rata-rata di semua pekerjaan pelatihan dan menghentikan pekerjaan yang nilai metrik utamanya lebih buruk dibandingkan median rata-rata.
Kebijakan ini mengambil parameter konfigurasi berikut:
-
evaluation_interval: frekuensi penerapan kebijakan (parameter opsional). -
delay_evaluation: menunda evaluasi kebijakan pertama untuk jumlah interval yang ditentukan (parameter opsional).
from azure.ai.ml.sweep import MedianStoppingPolicy
sweep_job.early_termination = MedianStoppingPolicy(delay_evaluation = 5, evaluation_interval = 1)
Dalam contoh ini, kebijakan penghentian dini diterapkan pada setiap interval mulai dari interval evaluasi 5. Pekerjaan dihentikan pada interval 5 jika metrik utama terbaiknya lebih buruk dibandingkan median rata-rata eksekusi selama interval 1:5 di semua pekerjaan pelatihan.
Kebijakan pemilihan pemotongan
Pemilihan pemotongan membatalkan persentase pekerjaan berperforma terendah yang dijalankan pada setiap interval evaluasi. Pekerjaan dibandingkan menggunakan metrik utama.
Kebijakan ini mengambil parameter konfigurasi berikut:
-
truncation_percentage: persentase pekerjaan berperforma untuk berhenti pada setiap interval evaluasi. Nilai bilangan bulat antara 1 dan 99. -
evaluation_interval: (opsional) frekuensi penerapan kebijakan -
delay_evaluation: (opsional) menunda evaluasi kebijakan pertama untuk jumlah interval yang ditentukan -
exclude_finished_jobs: menentukan apakah akan mengecualikan pekerjaan yang sudah selesai saat menerapkan kebijakan
from azure.ai.ml.sweep import TruncationSelectionPolicy
sweep_job.early_termination = TruncationSelectionPolicy(evaluation_interval=1, truncation_percentage=20, delay_evaluation=5, exclude_finished_jobs=true)
Dalam contoh ini, kebijakan penghentian dini diterapkan pada setiap interval mulai dari interval evaluasi 5. Pekerjaan akan berhenti pada interval 5 jika performanya pada interval 5 berada di 20% performa terendah di semua pekerjaan pada interval 5 dan akan mengecualikan pekerjaan yang selesai saat menerapkan kebijakan.
Tidak ada kebijakan penghentian (default)
Jika tidak ada kebijakan yang ditentukan, layanan penyetelan hiperparameter memungkinkan semua pekerjaan pelatihan dijalankan hingga selesai.
sweep_job.early_termination = None
Memilih kebijakan penghentian awal
- Untuk kebijakan konservatif yang menyediakan penghematan tanpa mengakhiri pekerjaan yang menjanjikan, pertimbangkan Policy Penghentian Median dengan
evaluation_interval1 dandelay_evaluation5. Ini adalah pengaturan konservatif yang dapat memberikan penghematan sekitar 25%-35% tanpa kehilangan metrik utama (berdasarkan data evaluasi kami). - Untuk penghematan yang lebih agresif, gunakan Kebijakan Bandit dengan kelonggaran yang lebih kecil atau Policy Pemilihan Pemotongan dengan persentase pemotongan yang lebih besar.
Menetapkan batasan untuk pekerjaan pembersihan Anda
Mengontrol anggaran sumber daya dengan menetapkan batasan untuk pekerjaan pembersihan Anda.
-
max_total_trials: Jumlah pekerjaan percobaan maksimum. Harus bilangan bulat antara 1 dan 1000. -
max_concurrent_trials: (opsional) Jumlah maksimum pekerjaan percobaan yang dapat berjalan serentak. Jika tidak ditentukan, max_total_trials jumlah pekerjaan yang diluncurkan secara paralel. Jika ditentukan, harus berupa bilangan bulat antara 1 dan 1000. -
timeout: Waktu maksimum dalam detik seluruh pekerjaan pembersihan diizinkan untuk dijalankan. Setelah batas ini tercapai, sistem membatalkan pekerjaan pembersihan, termasuk semua uji cobanya. -
trial_timeout: Waktu maksimum dalam detik yang diizinkan untuk dijalankan pada setiap pekerjaan percobaan. Setelah batas ini tercapai, sistem membatalkan uji coba.
Catatan
Jika max_total_trials dan batas waktu ditentukan, eksperimen penyetelan hiperparameter berakhir ketika yang pertama dari dua ambang batas ini tercapai.
Catatan
Jumlah pekerjaan percobaan serentak dibatasi pada sumber daya yang tersedia dalam target komputasi tertentu. Pastikan bahwa target komputasi memiliki sumber daya yang tersedia untuk konkurensi yang diinginkan.
sweep_job.set_limits(max_total_trials=20, max_concurrent_trials=4, timeout=1200)
Kode ini mengonfigurasi eksperimen penyetelan hyperparameter untuk menggunakan maksimum 20 total pekerjaan uji coba, menjalankan empat pekerjaan percobaan pada satu waktu dengan batas waktu 1.200 detik untuk seluruh pekerjaan pembersihan.
Mengonfigurasi eksperimen penyetelan hyperparameter
Untuk mengonfigurasi eksperimen penyetelan hyperparameter Anda, berikan hal berikut:
- Ruang pencarian hyperparameter yang ditentukan
- Algoritma pengambilan sampel Anda
- Kebijakan penghentian dini Anda
- Tujuan Anda
- Batas Sumber Daya
- CommandJob atau CommandComponent
- SweepJob
SweepJob dapat menjalankan pembersihan hyperparameter pada Komponen Perintah atau Perintah.
Catatan
Target komputasi yang digunakan di sweep_job harus memiliki sumber daya yang cukup untuk tingkat konkurensi Anda. Untuk informasi selengkapnya tentang target komputasi, lihat Target komputasi.
Mengonfigurasi eksperimen penyetelan hyperparameter:
from azure.ai.ml import MLClient
from azure.ai.ml import command, Input
from azure.ai.ml.sweep import Choice, Uniform, MedianStoppingPolicy
from azure.identity import DefaultAzureCredential
# Create your base command job
command_job = command(
code="./src",
command="python main.py --iris-csv ${{inputs.iris_csv}} --learning-rate ${{inputs.learning_rate}} --boosting ${{inputs.boosting}}",
environment="AzureML-lightgbm-3.2-ubuntu18.04-py37-cpu@latest",
inputs={
"iris_csv": Input(
type="uri_file",
path="https://azuremlexamples.blob.core.windows.net/datasets/iris.csv",
),
"learning_rate": 0.9,
"boosting": "gbdt",
},
compute="cpu-cluster",
)
# Override your inputs with parameter expressions
command_job_for_sweep = command_job(
learning_rate=Uniform(min_value=0.01, max_value=0.9),
boosting=Choice(values=["gbdt", "dart"]),
)
# Call sweep() on your command job to sweep over your parameter expressions
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm="random",
primary_metric="test-multi_logloss",
goal="Minimize",
)
# Specify your experiment details
sweep_job.display_name = "lightgbm-iris-sweep-example"
sweep_job.experiment_name = "lightgbm-iris-sweep-example"
sweep_job.description = "Run a hyperparameter sweep job for LightGBM on Iris dataset."
# Define the limits for this sweep
sweep_job.set_limits(max_total_trials=20, max_concurrent_trials=10, timeout=7200)
# Set early stopping on this one
sweep_job.early_termination = MedianStoppingPolicy(
delay_evaluation=5, evaluation_interval=2
)
command_job disebut sebagai fungsi sehingga kami dapat menerapkan ekspresi parameter pada input pembersihan. Lalu, fungsi sweep dikonfigurasikan dengan trial, sampling-algorithm, objective, limits, dan compute. Cuplikan kode di atas diambil dari contoh buku catatan Menjalankan pembersihan hyperparameter pada Command atau CommandComponent. Dalam sampel ini, learning_rate parameter dan boosting disetel. Penghentian awal pekerjaan ditentukan oleh MedianStoppingPolicy, yang menghentikan pekerjaan yang nilai metrik utamanya lebih buruk daripada median rata-rata di semua pekerjaan pelatihan.( lihat Referensi kelas MedianStoppingPolicy).
Untuk melihat cara nilai parameter diterima, diurai, dan diteruskan ke skrip pelatihan untuk disetel, lihat sampel kode ini
Penting
Setiap pekerjaan pembersihan parameter memulai ulang pelatihan dari awal, termasuk membangun ulang model dan semua pemuat data. Anda dapat meminimalkan biaya ini dengan menggunakan Azure Machine Learning atau proses manual untuk melakukan persiapan data sebanyak mungkin sebelum pekerjaan pelatihan.
Mengirimkan eksperimen penyetelan hyperparameter
Setelah Anda menentukan konfigurasi penyetelan hyperparameter, kirimkan pekerjaan:
# submit the sweep
returned_sweep_job = ml_client.create_or_update(sweep_job)
# get a URL for the status of the job
returned_sweep_job.services["Studio"].endpoint
Memvisualisasikan pekerjaan penyetelan hyperparameter
Anda dapat memvisualisasikan semua pekerjaan penyetelan hyperparameter Anda di studio Azure Machine Learning. Untuk informasi selengkapnya tentang cara menampilkan eksperimen di portal, lihat Menampilkan data pekerjaan di studio.
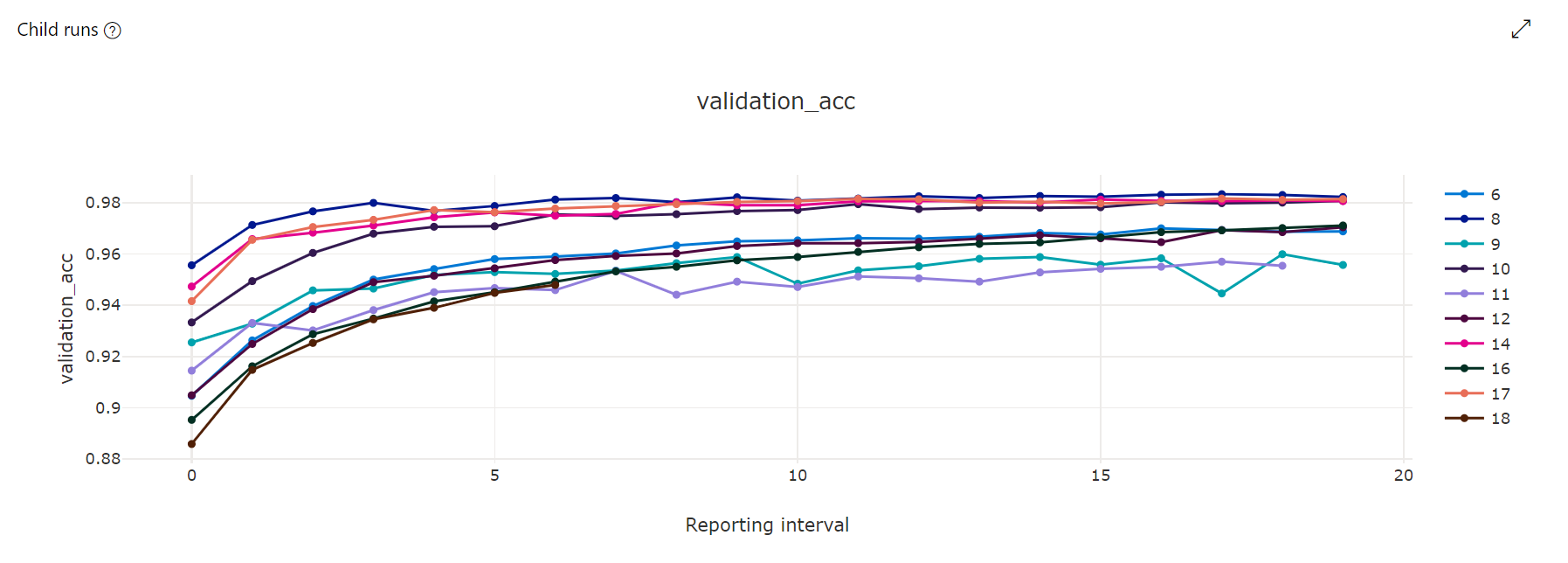
Bagan metrik: Visualisasi ini melacak metrik yang dicatat untuk setiap pekerjaan turunan hyperdrive selama durasi penyetelan hyperparameter. Setiap baris mewakili pekerjaan turunan, dan setiap titik mengukur nilai metrik utama pada iterasi runtime.
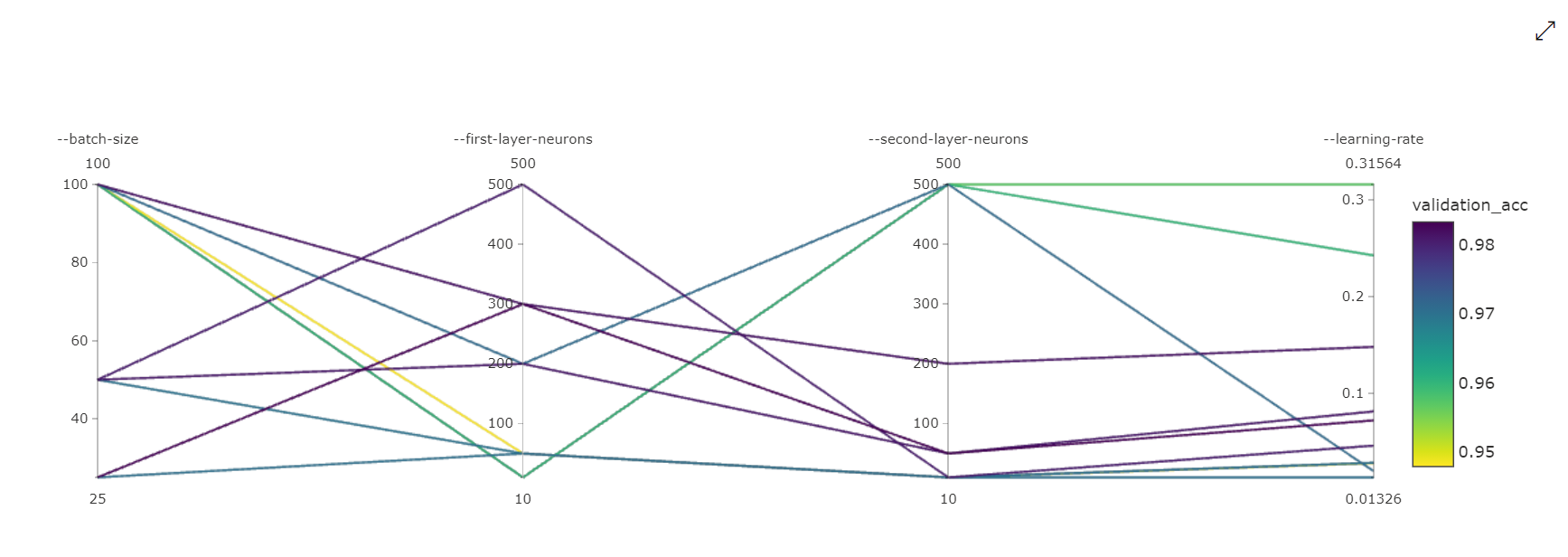
Bagan Koordinat Paralel: Visualisasi ini menunjukkan korelasi antara performa metrik utama dan nilai hyperparameter individu. Bagan interaktif melalui pergerakan sumbu (pilih dan seret oleh label sumbu), dan dengan menyoroti nilai di seluruh sumbu tunggal (pilih dan seret secara vertikal di sepanjang sumbu tunggal untuk menyoroti rentang nilai yang diinginkan). Bagan koordinat paralel menyertakan sumbu pada bagian paling kanan bagan yang memplot nilai metrik terbaik yang sesuai dengan hiperparameter yang ditetapkan untuk instans pekerjaan tersebut. Sumbu ini diberikan untuk memproyeksikan legenda gradien bagan ke data dengan cara yang lebih mudah dibaca.
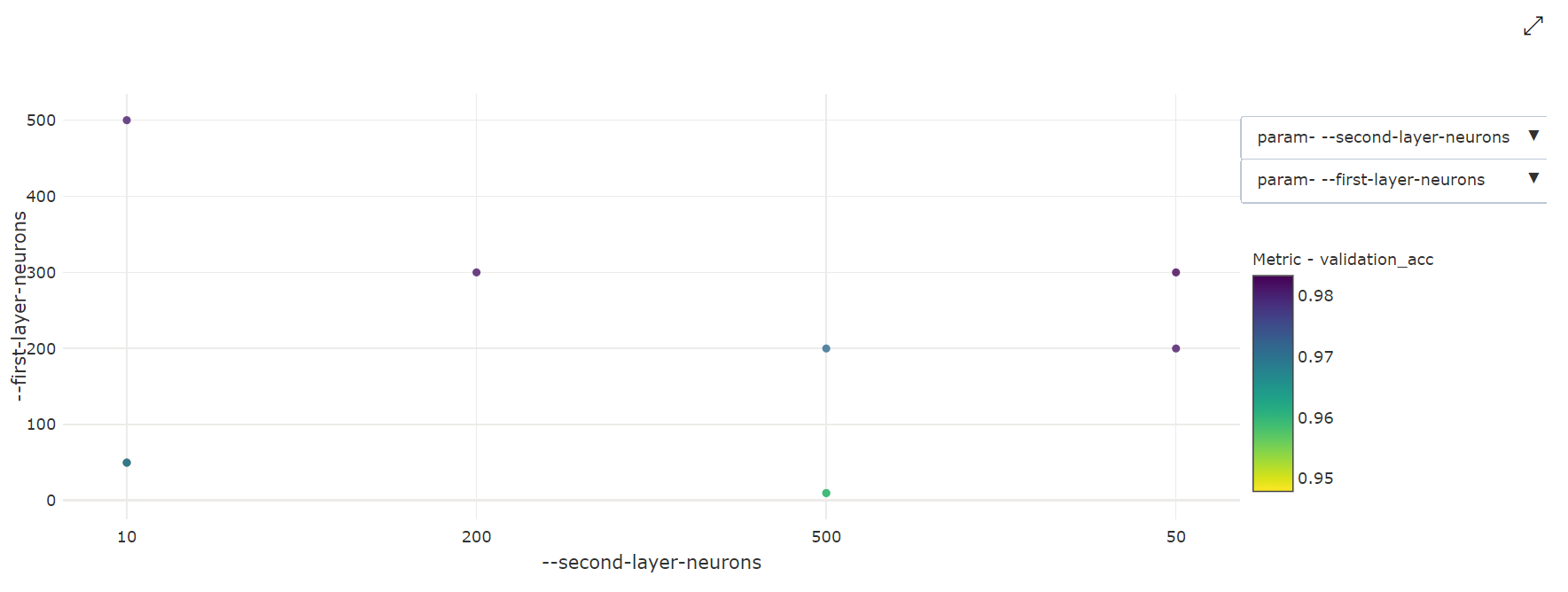
Bagan Sebar 2 Dimensi: Visualisasi ini menunjukkan korelasi antara dua hyperparameter individu bersama dengan nilai metrik utama terkait.
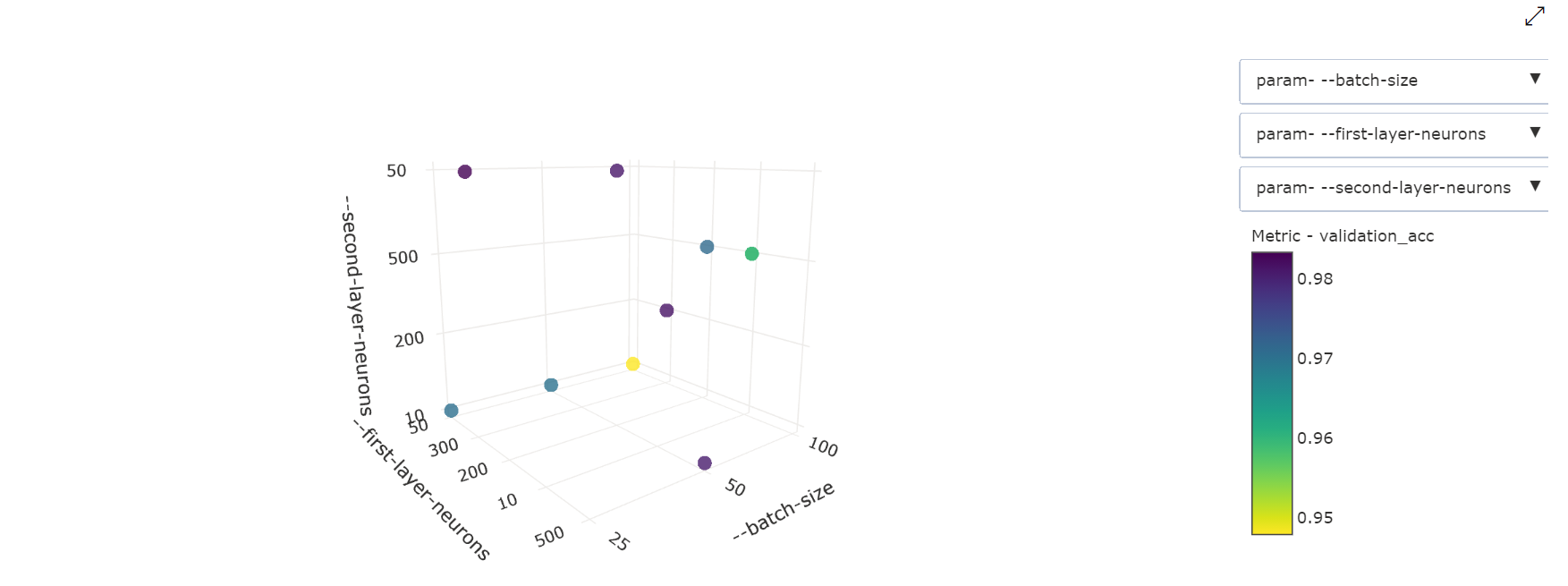
Bagan Sebar 3 Dimensi:Visualisasi ini sama dengan 2D tetapi memungkinkan tiga dimensi korelasi hyperparameter dengan nilai metrik utama. Anda juga dapat memilih dan menyeret untuk mengorientasikan ulang bagan untuk melihat korelasi yang berbeda dalam ruang 3D.
Menemukan pekerjaan percobaan terbaik
Setelah semua pekerjaan penyetelan hyperparameter selesai, ambil output percobaan terbaik Anda:
# Download best trial model output
ml_client.jobs.download(returned_sweep_job.name, output_name="model")
Anda dapat menggunakan CLI untuk mengunduh semua output default dan bernama dari pekerjaan percobaan terbaik dan log pekerjaan pembersihan.
az ml job download --name <sweep-job> --all
Secara opsional, untuk mengunduh output percobaan terbaik saja
az ml job download --name <sweep-job> --output-name model