Mengevaluasi hasil eksperimen pembelajaran mesin otomatis
Dalam artikel ini, pelajari cara mengevaluasi dan membandingkan model yang dilatih oleh eksperimen pembelajaran mesin otomatis (ML otomatis). Selama kursus eksperimen ML otomatis, banyak pekerjaan dibuat dan setiap pekerjaan membuat model. Untuk setiap model, ML otomatis membuat metrik evaluasi dan bagan yang membantu Anda mengukur performa model. Anda selanjutnya dapat menghasilkan dasbor AI Yang Bertanggung Jawab untuk melakukan penilaian holistik dan penelusuran kesalahan model terbaik yang direkomendasikan secara default. Ini termasuk wawasan seperti penjelasan model, penjelajah kewajaran dan performa, penjelajah data, analisis kesalahan model. Pelajari selengkapnya tentang cara membuat dasbor AI yang Bertanggung Jawab.
Misalnya, ML otomatis membuat bagan berikut berdasarkan jenis eksperimen.
Penting
Item yang ditandai (pratinjau) dalam artikel ini sedang dalam pratinjau publik. Versi pratinjau disediakan tanpa perjanjian tingkat layanan, dan tidak disarankan untuk beban kerja produksi. Fitur tertentu mungkin tidak didukung atau mungkin memiliki kemampuan terbatas. Untuk mengetahui informasi selengkapnya, lihat Ketentuan Penggunaan Tambahan untuk Pratinjau Microsoft Azure.
Prasyarat
- Langganan Azure. (Jika Anda tidak memiliki langganan Azure, buat akun gratis sebelum memulai)
- Eksperimen Azure Pembelajaran Mesin dibuat dengan:
- Studio Azure Machine Learning (tidak perlu kode)
- Azure Machine Learning Python SDK
Melihat hasil pekerjaan
Setelah eksperimen ML otomatis Anda selesai, riwayat pekerjaan bisa ditemukan melalui:
- Browser dengan studio Azure Machine Learning
- Notebook Jupyter menggunakan widget JobDetails Jupyter
Langkah-langkah dan video berikut, menunjukkan kepada Anda cara melihat metrik dan bagan evaluasi model dan histori eksekusi di studio:
- Masuk ke studio dan arahkan ke ruang kerja Anda.
- Di menu sebelah kiri, pilih Pekerjaan.
- Pilih eksperimen Anda dari daftar eksperimen.
- Dalam tabel di bagian bawah halaman, pilih pekerjaan ML otomatis.
- Di tab Model, pilih Nama algoritme untuk model yang ingin Anda evaluasi.
- Di tab Metrik, gunakan kotak centang di sebelah kiri untuk melihat metrik dan bagan.
Metrik klasifikasi
ML otomatis menghitung metrik performa untuk setiap model klasifikasi yang dibuat untuk eksperimen Anda. Metrik ini didasarkan pada penerapan scikit learn.
Banyak metrik klasifikasi ditentukan untuk klasifikasi biner pada dua kelas, dan memerlukan rata-rata atas kelas untuk membuat satu skor untuk klasifikasi multi-kelas. Scikit-learn menyediakan beberapa metode rata-rata, tiga di antara ML otomatisnya mengekspos: makro, mikro, dan tertimbang.
- Makro - Menghitung metrik untuk setiap kelas dan mengambil rata-rata tidak tertimbang
- Mikro - Menghitung metrik secara global dengan menghitung total positif sejati, negatif palsu, dan positif palsu (independen dari kelas).
- Tertimbang - Menghitung metrik untuk setiap kelas dan mengambil rata-rata tertimbang berdasarkan jumlah sampel per kelas.
Meskipun setiap metode rata-rata memiliki keuntungannya, satu pertimbangan umum saat memilih metode yang sesuai adalah ketidakseimbangan kelas. Jika kelas memiliki jumlah sampel yang berbeda, mungkin lebih informatif untuk menggunakan rata-rata makro yang mana kelas minoritas diberikan bobot yang sama dengan kelas mayoritas. Pelajari lebih lanjut tentang metrik biner vs multikelas dalam ML otomatis.
Tabel berikut ini meringkas metrik performa model yang dihitung ML otomatis untuk setiap model klasifikasi yang dibuat untuk eksperimen Anda. Untuk detail selengkapnya, lihat dokumentasi scikit-learn yang ditautkan di bidang Penghitungan setiap metrik.
Catatan
Lihat bagian metrik gambar untuk mengetahui detail lainnya tentang metrik untuk model klasifikasi gambar.
| Metrik | Deskripsi | Penghitungan |
|---|---|---|
| AUC | AUC adalah Area di bawah Kurva Karakteristik Operasi Penerima. Tujuan: Lebih dekat ke 1 semakin baik Rentang: [0, 1] Nama metrik yang didukung meliputi, AUC_macro, rata-rata aritmatika AUC untuk setiap kelas.AUC_micro, dihitung dengan menghitung total positif benar, negatif palsu, dan positif palsu. AUC_weighted, nilai rata-rata aritmatika untuk setiap kelas, dihitung dengan jumlah instans sejati di setiap kelas. AUC_binary, nilai AUC dengan memperlakukan satu kelas tertentu sebagai kelas true dan menggabungkan semua kelas lainnya sebagai kelas false. |
Penghitungan |
| akurasi | Akurasi adalah rasio prediksi yang sama persis dengan label kelas yang benar. Tujuan: Lebih dekat ke 1 semakin baik Rentang: [0, 1] |
Penghitungan |
| average_precision | Presisi rata-rata merangkum kurva presisi-recall sebagai rata-rata tertimbang presisi yang dicapai pada setiap ambang, dengan peningkatan pengenalan dari ambang sebelumnya yang digunakan sebagai berat. Tujuan: Lebih dekat ke 1 semakin baik Rentang: [0, 1] Nama metrik yang didukung meliputi, average_precision_score_macro, rata-rata aritmatika dari skor presisi rata-rata setiap kelas.average_precision_score_micro, dihitung dengan menghitung total positif benar, negatif palsu, dan positif palsu.average_precision_score_weighted, nilai rata-rata aritmatika skor presisi rata-rata untuk setiap kelas, dihitung dengan jumlah instans sejati di setiap kelas. average_precision_score_binary, nilai presisi rata-rata dengan memperlakukan satu kelas tertentu sebagai kelas true dan menggabungkan semua kelas lainnya sebagai kelas false. |
Penghitungan |
| balanced_accuracy | Akurasi seimbang adalah rata-rata aritmatika pengenalan untuk setiap kelas. Tujuan: Lebih dekat ke 1 semakin baik Rentang: [0, 1] |
Penghitungan |
| f-measure | f-measure adalah rata-rata harmonis presisi dan pengenalan. Ini adalah ukuran seimbang dari positif palsu dan negatif palsu. Namun, tidak memperhitungkan negatif sejati. Tujuan: Lebih dekat ke 1 semakin baik Rentang: [0, 1] Nama metrik yang didukung meliputi, f1_score_macro: rata-rata aritmatika f-measure untuk setiap kelas. f1_score_micro: dihitung dengan menghitung total positif sejati, negatif palsu, dan positif palsu. f1_score_weighted: tertimbang rata-rata dengan frekuensi kelas f-measure untuk setiap kelas. f1_score_binary, nilai f1 dengan memperlakukan satu kelas tertentu sebagai kelas true dan menggabungkan semua kelas lainnya sebagai kelas false. |
Penghitungan |
| log_loss | Ini adalah fungsi kehilangan yang digunakan dalam regresi logistik (multinomial) dan ekstensinya seperti jaringan saraf, ditentukan sebagai kemungkinan log negatif dari label sejati mengingat prediksi pengklasifikasi probabilistik. Tujuan: Lebih dekat ke 0 semakin baik Rentang: [0, inf) |
Penghitungan |
| norm_macro_recall | Pengenalan makro yang dinormalisasi adalah pengenalan makro rata-rata dan dinormalisasi, sehingga performa acak memiliki skor 0, dan performa sempurna memiliki skor 1. Tujuan: Lebih dekat ke 1 semakin baik Rentang: [0, 1] |
(recall_score_macro - R) / (1 - R) yang mana, R adalah nilai yang diharapkan recall_score_macro untuk prediksi acak.R = 0.5 untuk klasifikasi biner. R = (1 / C) untuk masalah klasifikasi kelas C. |
| matthews_correlation | Koefisien korelasi Mattews adalah ukuran akurasi yang seimbang, yang bisa digunakan meskipun satu kelas memiliki lebih banyak sampel daripada yang lain. Koefisien 1 menunjukkan prediksi sempurna, prediksi acak 0, dan prediksi terbalik -1. Tujuan: Lebih dekat ke 1 semakin baik Rentang: [-1, 1] |
Penghitungan |
| presisi | Presisi adalah kemampuan model untuk menghindari pelabelan sampel negatif sebagai positif. Tujuan: Lebih dekat ke 1 semakin baik Rentang: [0, 1] Nama metrik yang didukung meliputi, precision_score_macro, rata-rata aritmatika presisi untuk setiap kelas. precision_score_micro: dihitung secara global dengan menghitung total positif sejati dan positif palsu. precision_score_weighted, nilai rata-rata aritmatika untuk setiap kelas, dihitung dengan jumlah instans sejati di setiap kelas. precision_score_binary, nilai presisi dengan memperlakukan satu kelas tertentu sebagai kelas true dan menggabungkan semua kelas lainnya sebagai kelas false. |
Penghitungan |
| pengenalan | Pengenalan adalah kemampuan model untuk mendeteksi semua sampel positif. Tujuan: Lebih dekat ke 1 semakin baik Rentang: [0, 1] Nama metrik yang didukung meliputi, recall_score_macro, rata-rata aritmatika pengenalan untuk setiap kelas. recall_score_micro: dihitung secara global dengan menghitung total positif benar, negatif palsu, dan positif palsu.recall_score_weighted, nilai rata-rata aritmatika pengenalan untuk setiap kelas, dihitung dengan jumlah instans sejati di setiap kelas. recall_score_binary, nilai pengenalan dengan memperlakukan satu kelas tertentu sebagai kelas true dan menggabungkan semua kelas lainnya sebagai kelas false. |
Penghitungan |
| weighted_accuracy | Akurasi tertimbang adalah akurasi yang mana setiap sampel dihitung oleh jumlah total sampel yang termasuk dalam kelas yang sama. Tujuan: Lebih dekat ke 1 semakin baik Rentang: [0, 1] |
Penghitungan |
Metrik klasifikasi biner vs. multikelas
ML otomatis secara otomatis mendeteksi apakah data adalah data biner dan juga memungkinkan pengguna mengaktifkan metrik klasifikasi biner bahkan jika data tersebut adalah data multikelas dengan menentukan kelas true . Metrik klasifikasi multikelas dilaporkan jika himpunan data memiliki dua kelas atau lebih. Metrik klasifikasi biner hanya dilaporkan ketika data adalah biner.
Perhatikan, metrik klasifikasi multikelas ditujukan untuk klasifikasi multikelas. Saat diterapkan ke himpunan data biner, metrik ini tidak memperlakukan kelas apa pun sebagai true kelas, seperti yang mungkin Anda harapkan. Metrik yang jelas dimaksudkan untuk multikelas dengan akhiran micro, macro, atau weighted. Contoh meliputi average_precision_score, f1_score, precision_score, recall_score, dan AUC. Misalnya, alih-alih menghitung pengenalan sebagai tp / (tp + fn), pengenalan rata-rata multikelas (micro, macro, atau weighted) rata-rata di atas kedua kelas himpunan data klasifikasi biner. Ini setara dengan menghitung pengenalan untuk kelas true dan kelas false secara terpisah, dan kemudian mengambil rata-rata keduanya.
Selain itu, meskipun deteksi otomatis klasifikasi biner didukung, tetap disarankan untuk selalu menentukan true kelas secara manual untuk memastikan metrik klasifikasi biner dihitung untuk kelas yang benar.
Untuk mengaktifkan metrik untuk himpunan data klasifikasi biner ketika himpunan data itu sendiri adalah multikelas, pengguna hanya perlu menentukan kelas yang akan diperlakukan sebagai true kelas dan metrik ini dihitung.
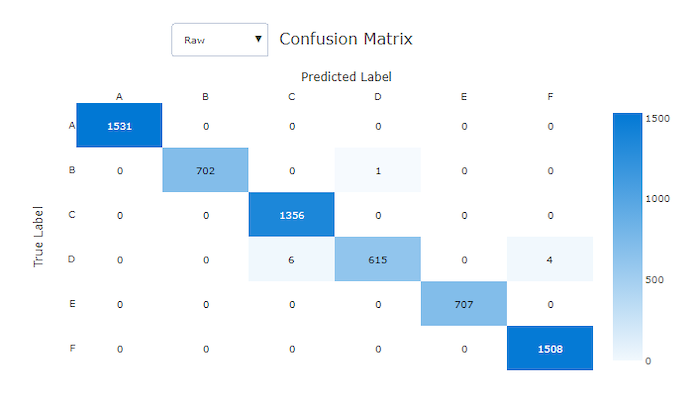
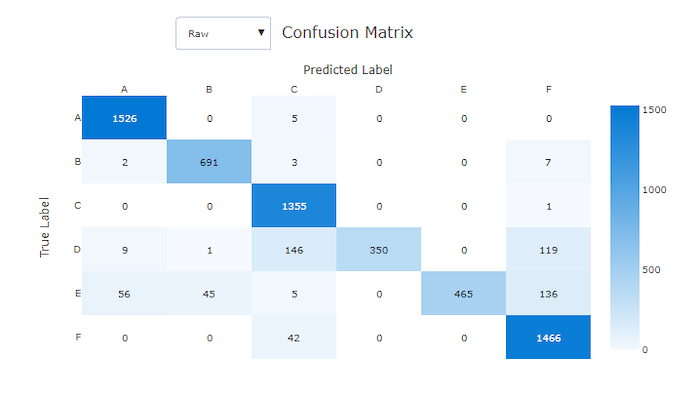
Matriks kebingungan
Matriks kebingungan memberikan visual tentang bagaimana model pembelajaran mesin membuat kesalahan sistematis dalam prediksinya untuk model klasifikasi. Kata "kebingungan" dalam nama berasal dari model "membingungkan" atau salah memberi label sampel. Sel pada baris i dan kolom j dalam matriks kebingungan berisi jumlah sampel dalam himpunan data evaluasi yang termasuk dalam kelas C_i dan diklasifikasikan oleh model sebagai kelas C_j.
Di studio, sel yang lebih gelap menunjukkan jumlah sampel yang lebih tinggi. Memilih Tampilan yang Dinormalisasi di menu dropdown menormalkan setiap baris matriks untuk memperlihatkan persentase kelas C_i yang diprediksi menjadi kelas C_j. Keuntungan dari tampilan Mentah default adalah Anda bisa melihat apakah ketidakseimbangan dalam distribusi kelas aktual menyebabkan model salah mengklasifikasikan sampel dari kelas minoritas, masalah umum dalam himpunan data yang tidak seimbang.
Matriks kebingungan dari model yang baik memiliki sebagian besar sampel di sepanjang diagonal.
Matriks kebingungan untuk model yang baik
Matriks kebingungan untuk model yang buruk
Kurva ROC
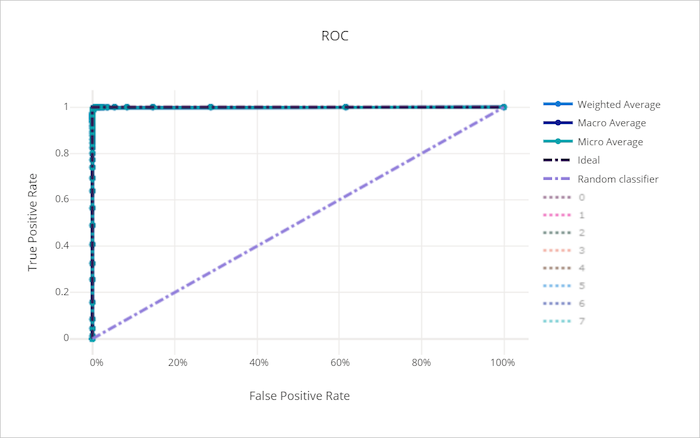
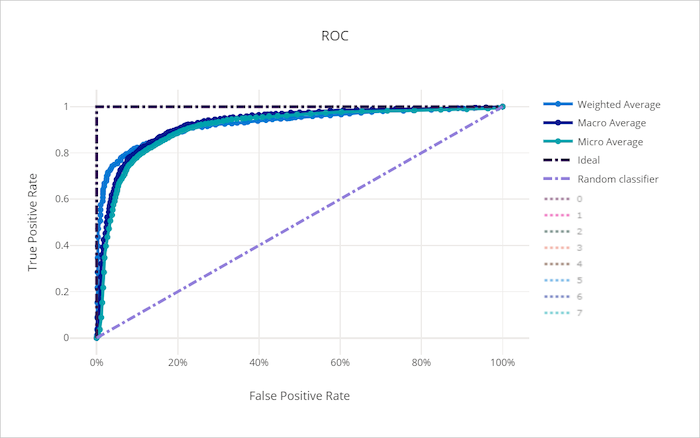
Kurva karakteristik operasi penerima (ROC) membuat plot hubungan antara tingkat positif sejati (TPR) dan tingkat positif palsu (FPR) saat ambang keputusan berubah. Kurva ROC bisa kurang informatif saat melatih model pada himpunan data dengan ketidakseimbangan kelas tinggi, karena kelas mayoritas bisa menghilangkan kontribusi dari kelas minoritas.
Area di bawah kurva (AUC) bisa ditafsirkan sebagai proporsi sampel yang diklasifikasikan dengan benar. Lebih tepatnya, AUC adalah probabilitas bahwa pengklasifikasi memberi peringkat sampel positif yang dipilih secara acak lebih tinggi daripada sampel negatif yang dipilih secara acak. Bentuk kurva memberikan intuisi untuk hubungan antara TPR dan FPR sebagai fungsi ambang klasifikasi atau batas keputusan.
Kurva yang mendekati pojok kiri atas bagan mendekati TPR 100% dan FPR 0%, model terbaik. Model acak akan menghasilkan kurva ROC di sepanjang garis y = x dari pojok kiri bawah ke kanan atas. Model yang lebih buruk dari acak akan memiliki kurva ROC yang turun di bawah garis y = x.
Tip
Untuk eksperimen klasifikasi, masing-masing bagan garis yang diproduksi untuk model ML otomatis bisa digunakan untuk mengevaluasi model per kelas atau rata-rata di semua kelas. Anda bisa beralih di antara tampilan yang berbeda ini dengan mengklik label kelas di legenda di sebelah kanan bagan.
Kurva ROC untuk model yang baik
Kurva ROC untuk model yang buruk
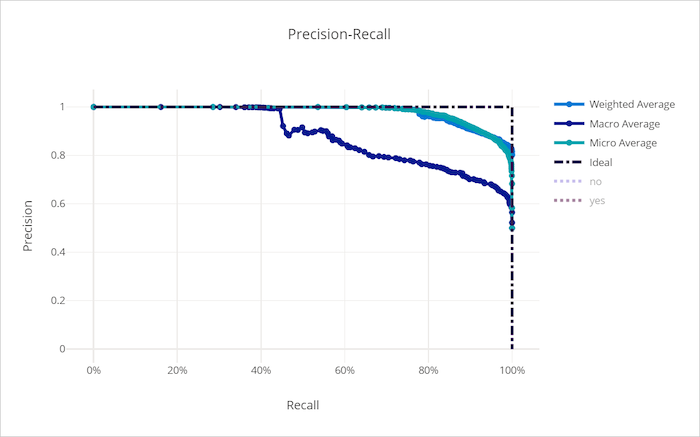
Kurva pengenalan presisi
Kurva precision-recall membuat plot hubungan antara presisi dan pengenalan saat ambang keputusan berubah. Pengenalan adalah kemampuan model mendeteksi semua sampel positif dan presisi adalah kemampuan model untuk menghindari pelabelan sampel negatif sebagai positif. Beberapa masalah bisnis mungkin memerlukan pengenalan yang lebih tinggi dan beberapa presisi yang lebih tinggi tergantung pada kepentingan relatif menghindari negatif palsu vs positif palsu.
Tip
Untuk eksperimen klasifikasi, masing-masing bagan garis yang diproduksi untuk model ML otomatis bisa digunakan untuk mengevaluasi model per kelas atau rata-rata di semua kelas. Anda bisa beralih di antara tampilan yang berbeda ini dengan mengklik label kelas di legenda di sebelah kanan bagan.
Kurva precision-recall untuk model yang baik
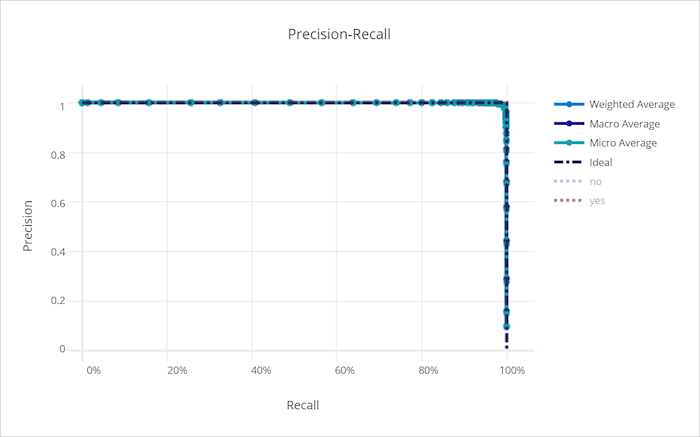
Kurva precision-recall untuk model yang buruk
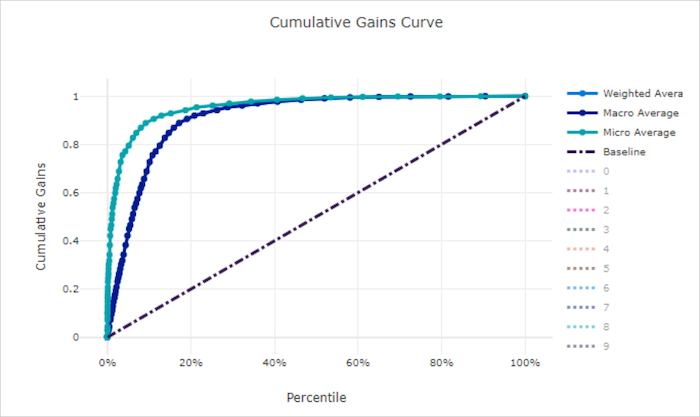
Kurva perolehan kumulatif
Kurva perolehan kumulatif membuat plot persentase sampel positif yang diklasifikasikan dengan benar sebagai fungsi dari persentase sampel yang dipertimbangkan yang mana kami mempertimbangkan sampel dalam urutan probabilitas yang diprediksi.
Untuk menghitung perolehan, pertama-tama urutkan semua sampel dari probabilitas tertinggi hingga terendah yang diprediksi oleh model. Kemudian ambil x% prediksi keyakinan tertinggi. Bagi jumlah sampel positif yang terdeteksi dalam x% dengan jumlah total sampel positif untuk mendapatkan perolehan. Perolehan kumulatif adalah persentase sampel positif yang kami deteksi saat mempertimbangkan beberapa persen dari data yang kemungkinan besar termasuk dalam kelas positif.
Model sempurna memberi peringkat semua sampel positif di atas semua sampel negatif yang memberikan kurva perolehan kumulatif yang terdiri dari dua segmen lurus. Yang pertama adalah garis dengan kemiringan 1 / x dari (0, 0) ke (x, 1) yang mana x adalah fraksi sampel yang termasuk dalam kelas positif (1 / num_classesjika kelas seimbang). Yang kedua adalah garis horizontal dari (x, 1) ke (1, 1). Pada segmen pertama, semua sampel positif diklasifikasikan dengan benar dan perolehan kumulatif masuk ke 100% dalam sampel x% pertama yang dipertimbangkan.
Model acak garis besar memiliki kurva perolehan kumulatif berikut di y = x mana untuk x% sampel yang hanya dipertimbangkan tentang x% total sampel positif terdeteksi. Model yang sempurna untuk himpunan data seimbang memiliki kurva rata-rata mikro dan garis rata-rata makro yang memiliki ke miring num_classes hingga perolehan kumulatif adalah 100% dan kemudian horizontal hingga persentase data adalah 100.
Tip
Untuk eksperimen klasifikasi, masing-masing bagan garis yang diproduksi untuk model ML otomatis bisa digunakan untuk mengevaluasi model per kelas atau rata-rata di semua kelas. Anda bisa beralih di antara tampilan yang berbeda ini dengan mengklik label kelas di legenda di sebelah kanan bagan.
Kurva perolehan kumulatif untuk model yang baik
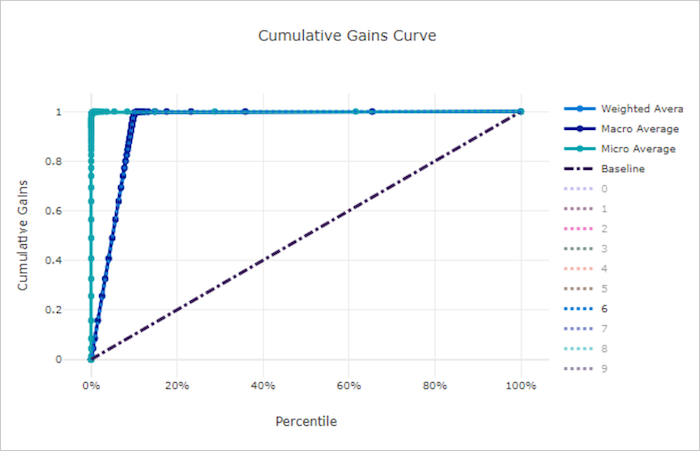
Kurva perolehan kumulatif untuk model yang buruk
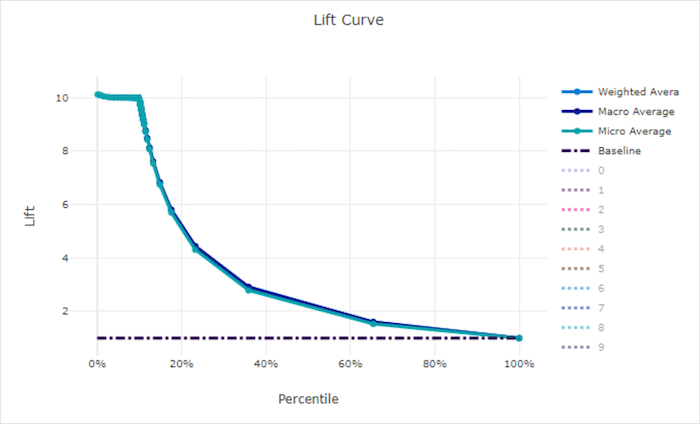
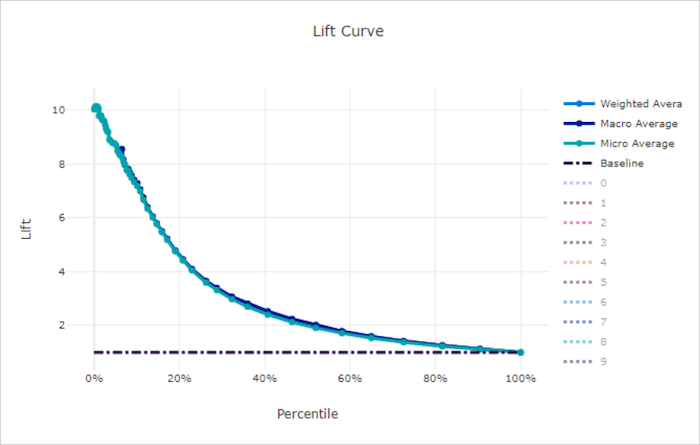
Kurva angkat
Kurva angkat menunjukkan berapa kali lebih baik performa model dibandingkan dengan model acak. Angkat didefinisikan sebagai rasio perolehan kumulatif terhadap perolehan kumulatif model acak (yang seharusnya selalu 1).
Performa relatif ini memperhitungkan fakta bahwa klasifikasi semakin sulit saat Anda meningkatkan jumlah kelas. (Model acak salah memprediksi pecahan sampel yang lebih tinggi dari himpunan data dengan 10 kelas dibandingkan dengan himpunan data dengan dua kelas)
Kurva angkat garis besar adalah garis y = 1 yang mana performa model konsisten dengan model acak. Secara umum, kurva angkat untuk model yang baik lebih tinggi pada bagan tersebut dan lebih jauh dari sumbu x, menunjukkan bahwa ketika model paling percaya diri dalam prediksinya, model tersebut berkinerja lebih baik daripada tebakan acak.
Tip
Untuk eksperimen klasifikasi, masing-masing bagan garis yang diproduksi untuk model ML otomatis bisa digunakan untuk mengevaluasi model per kelas atau rata-rata di semua kelas. Anda bisa beralih di antara tampilan yang berbeda ini dengan mengklik label kelas di legenda di sebelah kanan bagan.
Kurva angkat untuk model yang baik
Kurva angkat untuk model yang buruk
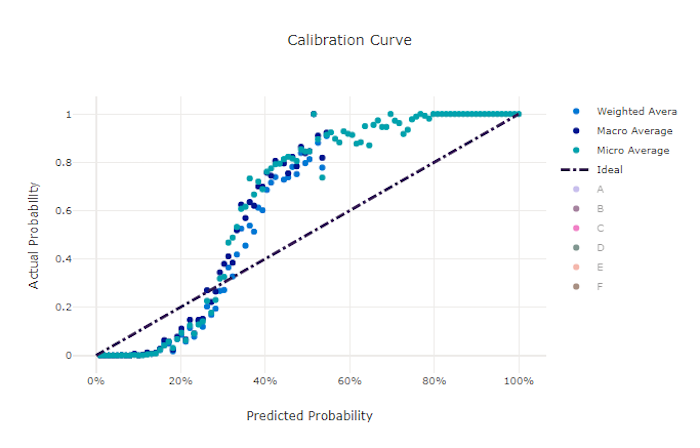
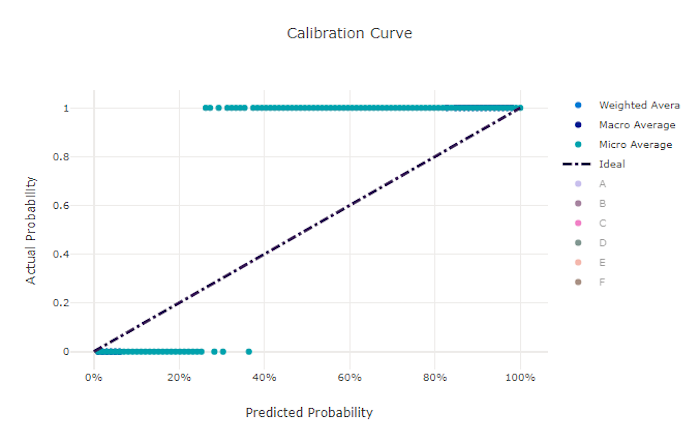
Kurva kalibrasi
Kurva kalibrasi membuat plot keyakinan model pada prediksinya terhadap proporsi sampel positif di setiap tingkat keyakinan. Model yang dikalibrasi dengan baik akan mengklasifikasikan 100% prediksi dengan benar yang menetapkan keyakinan 100%, 50% dari prediksi yang ditetapkannya 50% keyakinan, 20% dari prediksi yang menetapkan keyakinan 20%, dan sebagainya. Model yang dikalibrasi dengan sempurna memiliki kurva kalibrasi mengikuti y = x garis di mana model dengan sempurna memprediksi probabilitas sampel milik setiap kelas.
Model yang terlalu percaya diri memprediksi probabilitas mendekati nol dan satu, jarang tidak pasti tentang kelas setiap sampel dan kurva kalibrasi akan terlihat mirip dengan "S" mundur. Model yang kurang percaya diri menetapkan probabilitas yang lebih rendah rata-rata ke kelas yang diprediksinya dan kurva kalibrasi terkait terlihat mirip dengan "S". Kurva kalibrasi tidak menggambarkan kemampuan model untuk mengklasifikasikan dengan benar, tetapi sebaliknya kemampuannya untuk menetapkan keyakinan dengan benar pada prediksinya. Model yang buruk masih bisa memiliki kurva kalibrasi yang baik jika model dengan benar menetapkan keyakinan rendah dan ketidakpastian tinggi.
Catatan
Kurva kalibrasi sensitif terhadap jumlah sampel, sehingga set validasi kecil bisa membuat hasil yang bising yang bisa sulit ditafsirkan. Ini tidak selalu berarti bahwa model tidak dikalibrasi dengan baik.
Kurva kalibrasi untuk model yang baik
Kurva kalibrasi untuk model yang buruk
Metrik regresi/prakiraan
ML otomatis menghitung metrik performa yang sama untuk setiap model yang dihasilkan, terlepas dari apakah itu adalah eksperimen regresi atau prakiraan. Metrik ini juga mengalami normalisasi untuk memungkinkan perbandingan antara model yang dilatih pada data dengan rentang yang berbeda. Untuk mempelajari lebih lanjut, lihat normalisasi metrik.
Tabel berikut ini meringkas metrik performa model yang dibuat untuk eksperimen regresi dan prakiraan. Seperti metrik klasifikasi, metrik ini juga didasarkan pada penerapan scikit learn. Dokumentasi scikit learn yang sesuai ditautkan, di bidang Penghitungan.
| Metrik | Deskripsi | Penghitungan |
|---|---|---|
| explained_variance | Varians yang dijelaskan mengukur sejauh mana model memperhitungkan variasi dalam variabel target. Ini adalah persen penurunan varians data asli ke varian kesalahan. Ketika rata-rata kesalahan adalah 0, itu sama dengan koefisien penentuan (lihat r2_score dalam bagan berikut). Tujuan: Lebih dekat ke 1 semakin baik Rentang: (-inf, 1] |
Penghitungan |
| mean_absolute_error | Kesalahan absolut rata-rata adalah nilai yang diharapkan dari nilai absolut selisih antara target dan prediksi. Tujuan: Lebih dekat ke 0 semakin baik Rentang: [0, inf) Jenis: mean_absolute_error normalized_mean_absolute_error, mean_absolute_error dipisahkan oleh rentang data. |
Penghitungan |
| mean_absolute_percentage_error | Kesalahan persentase absolut rata-rata (MAPE) adalah ukuran perbedaan rata-rata antara nilai yang diprediksi dan nilai aktual. Tujuan: Lebih dekat ke 0 semakin baik Rentang: [0, inf) |
|
| median_absolute_error | Kesalahan absolut median adalah median dari semua perbedaan absolut antara target dan prediksi. Kehilangan ini kuat untuk outlier. Tujuan: Lebih dekat ke 0 semakin baik Rentang: [0, inf) Jenis: median_absolute_errornormalized_median_absolute_error, mean_absolute_error dibagi dengan rentang data. |
Penghitungan |
| r2_score | R2 (koefisien penentuan) mengukur pengurangan proporsional dalam mean squared error (MSE) relatif terhadap total varian data yang diamati. Tujuan: Lebih dekat ke 1 semakin baik Rentang: [-1, 1] Catatan: R2 sering memiliki rentang (-inf, 1]. MSE bisa lebih besar dari varians yang diamati, sehingga R2 bisa memiliki nilai negatif yang sangat besar, tergantung pada data dan prediksi model. Klip ML otomatis melaporkan skor R2 di -1, jadi nilai -1 untuk R2 kemungkinan berarti bahwa skor R2 yang sebenarnya kurang dari -1. Pertimbangkan nilai metrik lain dan properti data saat menginterpretasikan skor R2 negatif. |
Penghitungan |
| root_mean_squared_error | Root mean squared error (RMSE) adalah akar kuadrat dari perbedaan kuadrat yang diharapkan antara target dan prediksi. Untuk estimator yang tidak bias, RMSE sama dengan simpangan baku. Tujuan: Lebih dekat ke 0 semakin baik Rentang: [0, inf) Jenis: root_mean_squared_error normalized_root_mean_squared_error: root_mean_squared_error dibagi dengan rentang data. |
Penghitungan |
| root_mean_squared_log_error | Akar berarti kesalahan log kuadrat adalah akar kuadrat dari kesalahan logaritma kuadrat yang diharapkan. Tujuan: Lebih dekat ke 0 semakin baik Rentang: [0, inf) Jenis: root_mean_squared_log_error normalized_root_mean_squared_log_error: root_mean_squared_log_error dibagi dengan rentang data. |
Penghitungan |
| spearman_correlation | Korelasi Spearman adalah ukuran nonparametric dari monotonisitas hubungan antara dua himpunan data. Tidak seperti korelasi Pearson, korelasi Spearman tidak mengasumsikan bahwa kedua himpunan data biasanya didistribusikan. Seperti koefisien korelasi lainnya, Spearman bervariasi antara -1 dan 1 dengan 0 menyiratkan tidak ada korelasi. Korelasi -1 atau 1 menyiratkan hubungan monotonik yang tepat. Spearman adalah metrik korelasi urutan peringkat yang berarti bahwa perubahan pada nilai yang diprediksi atau aktual tidak akan mengubah hasil Spearman jika mereka tidak mengubah urutan peringkat nilai yang diprediksi atau aktual. Tujuan: Lebih dekat ke 1 semakin baik Rentang: [-1, 1] |
Penghitungan |
Normalisasi metrik
ML otomatis menormalkan metrik regresi dan prakiraan, yang memungkinkan perbandingan antara model yang dilatih pada data dengan rentang yang berbeda. Model yang dilatih pada data dengan rentang yang lebih besar memiliki kesalahan yang lebih tinggi daripada model yang sama yang dilatih pada data dengan rentang yang lebih kecil, kecuali kesalahan itu dinormalisasi.
Meskipun tidak ada metode standar untuk menormalkan metrik kesalahan, ML otomatis mengambil pendekatan umum untuk membagi kesalahan dengan rentang data: normalized_error = error / (y_max - y_min)
Catatan
Rentang data tidak disimpan dengan model. Jika Anda melakukan inferensi dengan model yang sama pada rangkaian pengujian holdout, y_min dan y_max dapat berubah sesuai dengan data pengujian dan metrik yang dinormalisasi mungkin tidak langsung digunakan untuk membandingkan performa pada rangkaian pelatihan dan pengujian. Anda dapat meneruskan nilai y_min dan y_max dari set pelatihan Anda agar perbandingan seimbang.
Metrik prakiraan: normalisasi dan agregasi
Menghitung metrik untuk memperkirakan evaluasi model memerlukan beberapa pertimbangan khusus ketika data berisi beberapa rangkaian waktu. Ada dua pilihan alami untuk menggabungkan metrik melalui beberapa seri:
- Rata-rata makro di mana metrik evaluasi dari setiap seri diberikan bobot yang sama,
- Rata-rata mikro di mana metrik evaluasi untuk setiap prediksi memiliki bobot yang sama.
Kasus-kasus ini memiliki analogi langsung ke makro dan rata-rata mikro dalam klasifikasi multi-kelas.
Perbedaan antara makro dan rata-rata mikro bisa menjadi penting saat memilih metrik utama untuk pemilihan model. Misalnya, pertimbangkan skenario ritel di mana Anda ingin memperkirakan permintaan untuk pilihan produk konsumen. Beberapa produk menjual pada volume yang lebih tinggi daripada yang lain. Jika Anda memilih RMSE rata-rata mikro sebagai metrik utama, ada kemungkinan bahwa item volume tinggi berkontribusi sebagian besar kesalahan pemodelan dan, jadi, mendominasi metrik. Algoritma pemilihan model mungkin mendukung model dengan akurasi yang lebih tinggi pada item volume tinggi daripada pada yang volume rendah. Sebaliknya, RMSE rata-rata makro yang dinormalisasi memberikan item volume rendah sekitar bobot yang sama dengan item volume tinggi.
Tabel berikut mencantumkan metrik prakiraan AutoML mana yang menggunakan makro vs. rata-rata mikro:
| Makro rata-rata | Rata-rata mikro |
|---|---|
normalized_mean_absolute_error, , normalized_median_absolute_errornormalized_root_mean_squared_error,normalized_root_mean_squared_log_error |
mean_absolute_error, , root_mean_squared_errormedian_absolute_error, root_mean_squared_log_error, r2_score, explained_variance, , spearman_correlation,mean_absolute_percentage_error |
Perhatikan bahwa metrik rata-rata makro menormalkan setiap seri secara terpisah. Metrik yang dinormalisasi dari setiap seri kemudian dirata-ratakan untuk memberikan hasil akhir. Pilihan makro vs. mikro yang benar tergantung pada skenario bisnis, tetapi kami umumnya merekomendasikan menggunakan normalized_root_mean_squared_error.
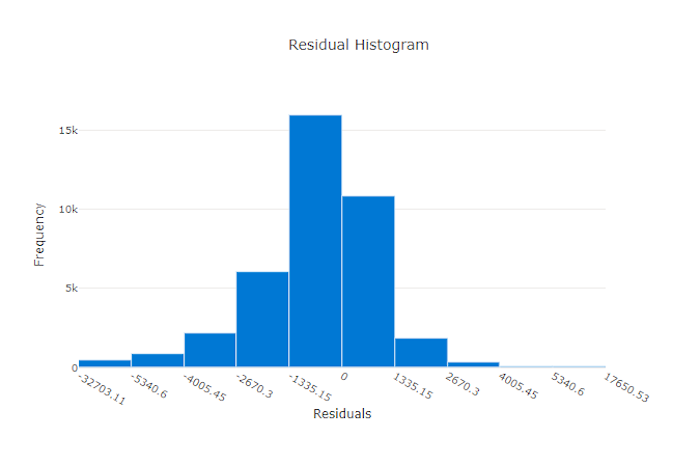
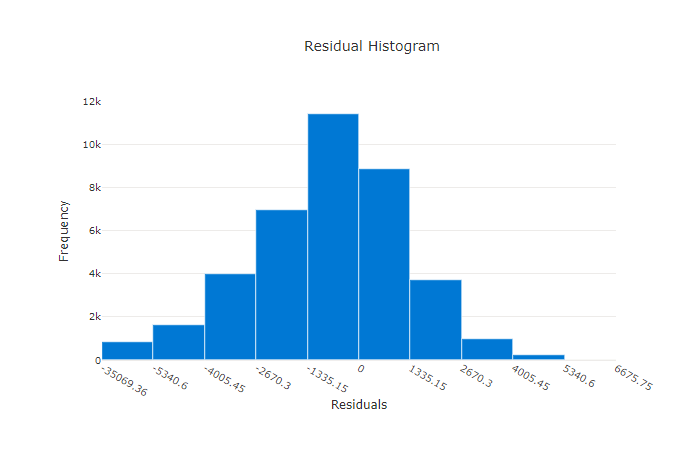
Residu
Bagan residu adalah histogram dari kesalahan prediksi (residu) yang dibuat untuk eksperimen regresi dan prakiraan. Residu dihitung sebagai y_predicted - y_true untuk semua sampel dan kemudian ditampilkan sebagai histogram untuk menunjukkan bias model.
Dalam contoh ini, kedua model sedikit bias untuk memprediksi lebih rendah dari nilai aktual. Ini tidak jarang untuk himpunan data dengan distribusi target aktual yang condong, tetapi menunjukkan performa model yang lebih buruk. Model yang baik memiliki distribusi residu yang memuncak pada nol dengan beberapa residu pada ekstrem. Model yang lebih buruk memiliki distribusi residu yang tersebar dengan lebih sedikit sampel sekitar nol.
Bagan residu untuk model yang baik
Bagan residu untuk model yang buruk
Diprediksi vs. true
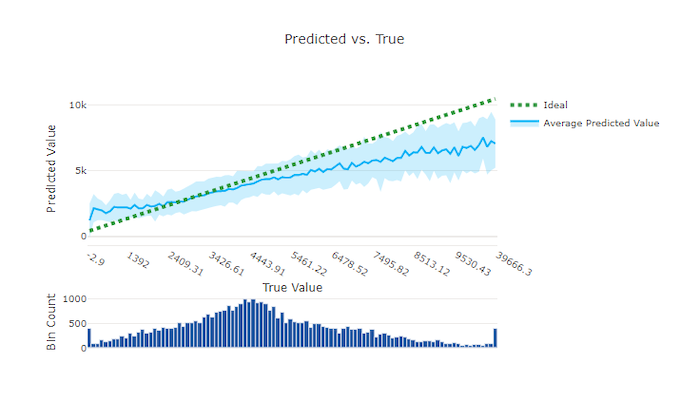
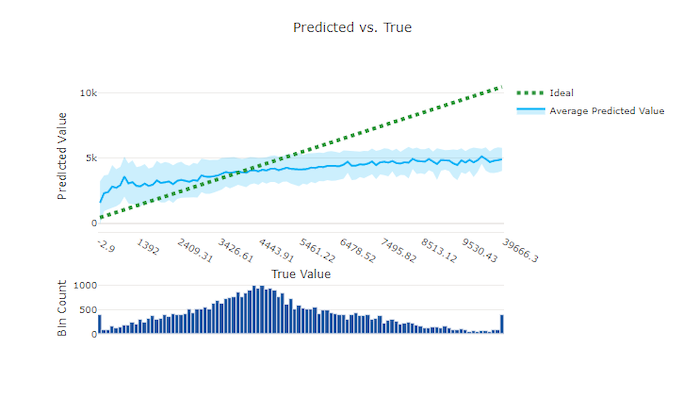
Untuk eksperimen regresi dan prakiraan, bagan yang diprediksi vs. true membuat plot hubungan antara fitur target (nilai sejati/aktual) dan prediksi model. Nilai sejati terikat di sepanjang sumbu x dan untuk setiap bin, nilai rata-rata yang diprediksi dibuat plot dengan bilah kesalahan. Ini memungkinkan Anda melihat apakah model bias terhadap prediksi nilai-nilai tertentu. Baris menampilkan prediksi rata-rata dan area berbayang menunjukkan varian prediksi di sekitar rata-rata itu.
Seringkali, nilai benar yang paling umum memiliki prediksi paling akurat dengan varian terendah. Jarak garis tren dari garis y = x ideal yang mana ada beberapa nilai true merupakan ukuran performa model yang baik pada outlier. Anda bisa menggunakan histogram di bagian bawah bagan untuk alasan tentang distribusi data aktual. Termasuk lebih banyak sampel data yang mana distribusi jarang bisa meningkatkan performa model pada data yang tidak terlihat.
Dalam contoh ini, perhatikan bahwa model yang lebih baik memiliki garis yang diprediksi vs. true yang lebih dekat ke garis y = x ideal.
Bagan yang diprediksi vs. true untuk model yang baik
Bagan yang diprediksi vs. true untuk model yang buruk
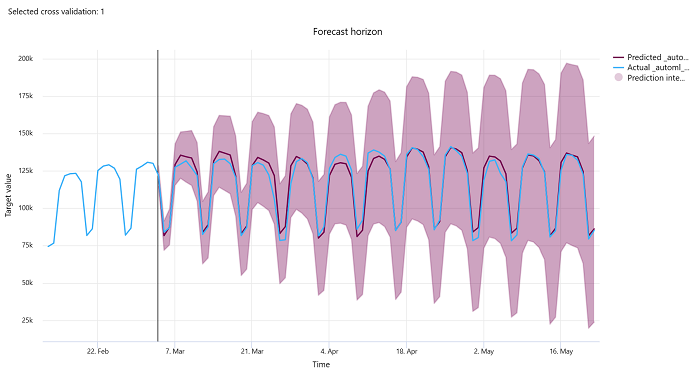
Cakrawala prakiraan
Untuk eksperimen prakiraan, bagan horizon prakiraan memplot hubungan antara nilai yang diprediksi model dan nilai aktual yang dipetakan dari waktu ke waktu per lipatan validasi silang, hingga lima lipatan. Sumbu x memetakan waktu berdasarkan frekuensi yang Anda berikan selama pengaturan latihan. Garis vertikal dalam bagan menandai titik horizon prakiraan juga disebut sebagai garis horizon, yang merupakan periode waktu di mana Anda ingin mulai menghasilkan prediksi. Di sebelah kiri garis horizon prakiraan, Anda dapat melihat data pelatihan historis untuk memvisualisasikan tren sebelumnya dengan lebih baik. Di sebelah kanan horizon prakiraan, Anda dapat memvisualisasikan prediksi (garis ungu) terhadap aktual (garis biru) untuk bagian validasi silang dan pengidentifikasi deret waktu yang berbeda. Area ungu yang diarsir menunjukkan interval kepercayaan atau varians prediksi di sekitar rata-rata tersebut.
Anda dapat memilih kombinasi lipatan validasi silang dan pengidentifikasi deret waktu mana yang akan ditampilkan dengan mengklik ikon pensil yang diedit di sudut kanan atas bagan. Pilih dari lima lipatan validasi silang pertama dan hingga 20 pengidentifikasi rangkaian waktu yang berbeda untuk memvisualisasikan bagan untuk berbagai rangkaian waktu Anda.
Penting
Bagan ini tersedia dalam pelatihan yang dijalankan untuk model yang dihasilkan dari data pelatihan dan validasi serta dalam eksekusi pengujian berdasarkan data pelatihan dan data pengujian. Kami mengizinkan hingga 20 poin data sebelum dan hingga 80 poin data setelah asal prakiraan. Untuk model DNN, bagan dalam eksekusi pelatihan ini menunjukkan data dari epoch terakhir yaitu setelah model dilatih sepenuhnya. Bagan dalam uji coba ini dapat memiliki celah sebelum garis horizon jika data validasi disediakan secara eksplisit selama pelatihan berjalan. Ini karena data pelatihan dan data pengujian digunakan dalam eksekusi pengujian meninggalkan data validasi yang menghasilkan kesenjangan.
Metrik untuk model gambar (pratinjau)
ML otomatis menggunakan gambar dari himpunan data validasi untuk mengevaluasi performa model. Performa model diukur pada tingkat waktu untuk memahami perkembangan pelatihan. Waktu berlalu jika seluruh himpunan data diteruskan ke depan dan ke belakang melalui jaringan neural tepat sekali.
Metrik klasifikasi gambar
Metrik utama untuk evaluasi adalah akurasi untuk model klasifikasi biner dan multi-kelas serta IoU(Intersection over Union) untuk model klasifikasi multi-label. Metrik klasifikasi untuk model klasifikasi gambar sama dengan metrik yang ditentukan di bagian metrik klasifikasi. Nilai kerugian yang terkait dengan waktu juga dicatat yang dapat memudahkan pemantauan perkembangan pelatihan berlangsung dan menentukan apakah model terlalu cocok atau kurang cocok.
Setiap prediksi dari model klasifikasi dikaitkan dengan skor keyakinan, yang menunjukkan tingkat keyakinan yang digunakan untuk melakukan prediksi. Model klasifikasi gambar multilabel secara default dievaluasi dengan ambang skor 0,5, yang berarti hanya prediksi dengan setidaknya tingkat keyakinan ini dianggap sebagai prediksi positif untuk kelas terkait. Klasifikasi multikelas tidak menggunakan ambang skor tetapi sebaliknya, kelas dengan skor keyakinan maksimum dianggap sebagai prediksi.
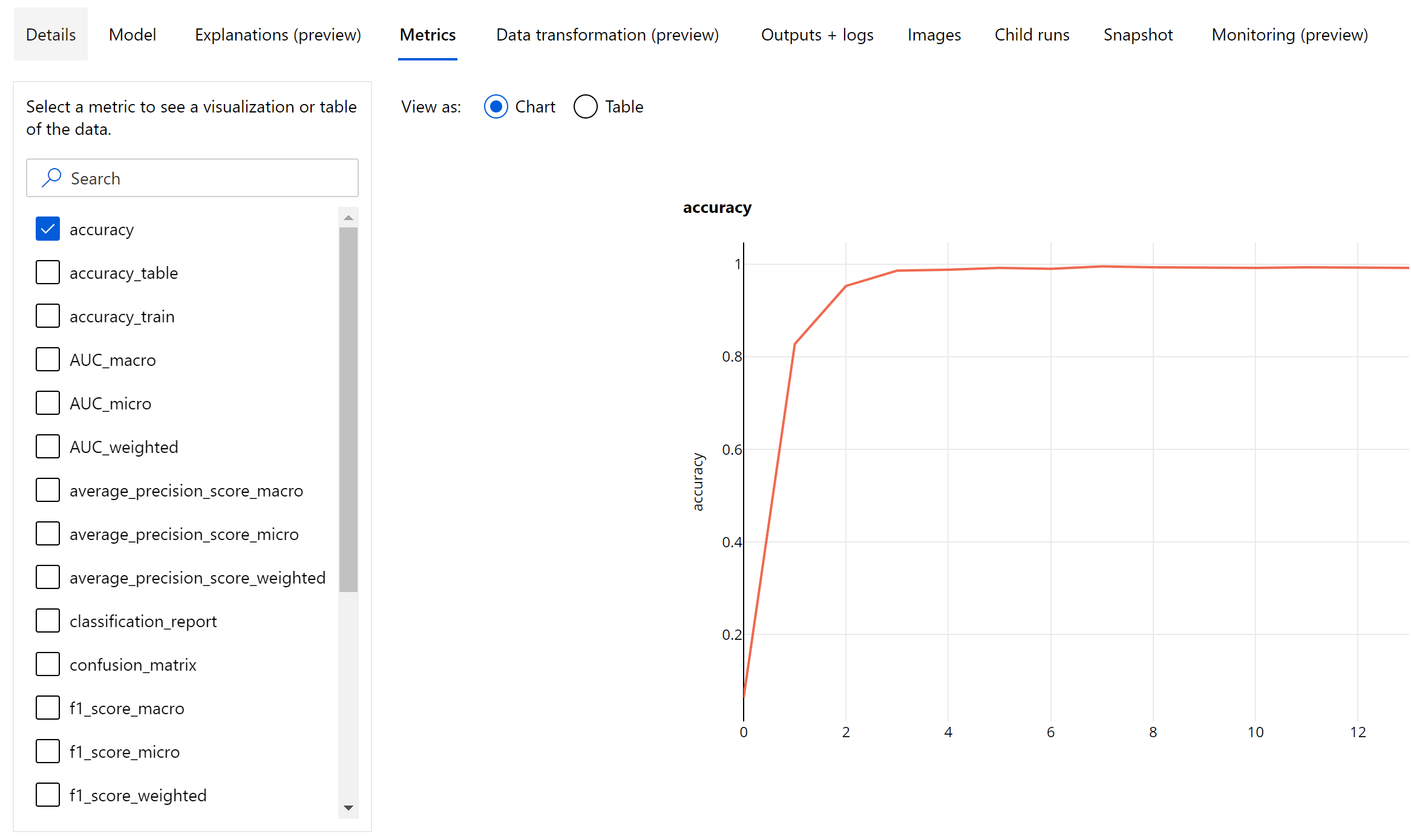
Metrik tingkat waktu untuk klasifikasi gambar
Berbeda dengan metrik klasifikasi untuk himpunan data tabular, model klasifikasi gambar mencatat semua metrik klasifikasi pada tingkat waktu seperti yang ditunjukkan di bawah.
Metrik ringkasan untuk klasifikasi gambar
Terlepas dari metrik skalar yang dicatat pada tingkat waktu, model klasifikasi gambar juga mencatat metrik ringkasan seperti matriks kebingungan, bagan klasifikasi termasuk kurva ROC, kurva pengenalan presisi, dan laporan klasifikasi untuk model dari waktu terbaik saat kita mendapatkan skor metrik utama tertinggi (akurasi).
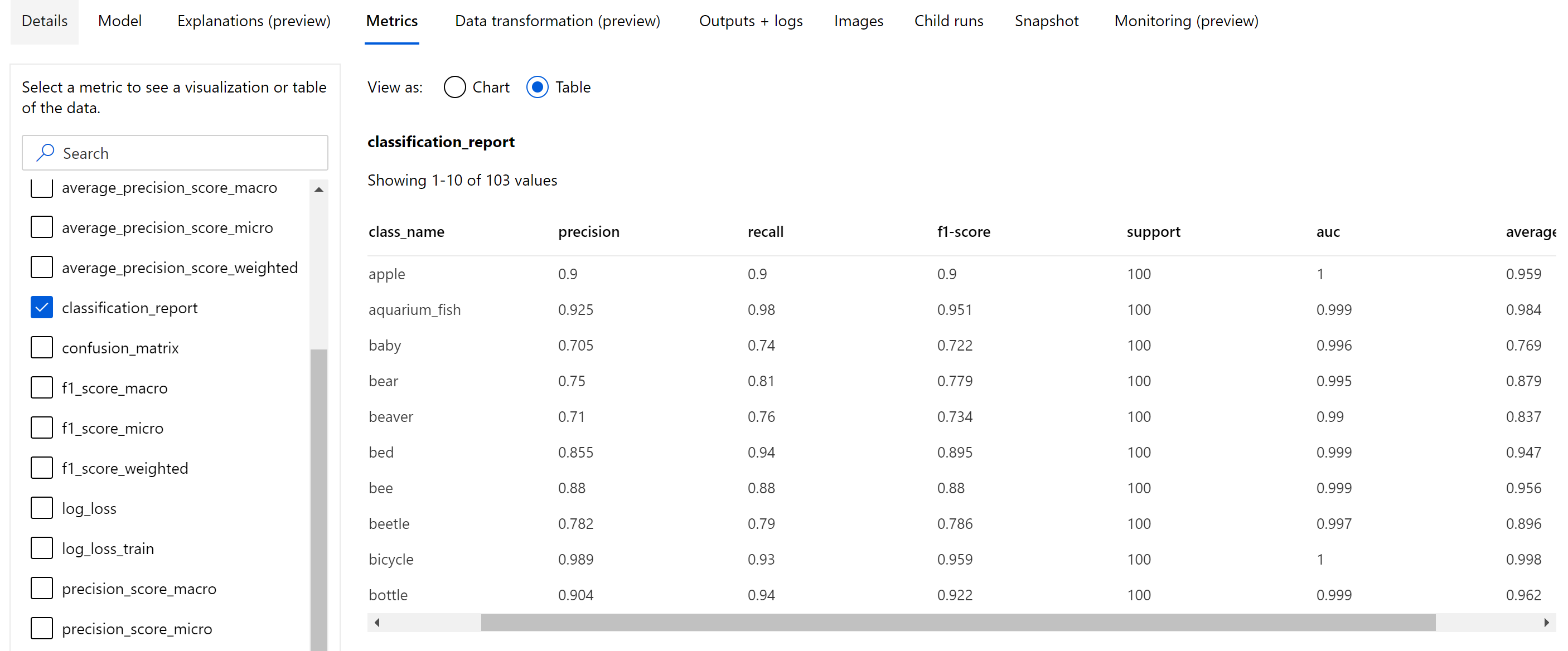
Laporan klasifikasi menyediakan nilai tingkat kelas untuk metrik seperti presisi, pengenalan, skor f1, dukungan, auc, dan average_precision dengan berbagai tingkat rata-rata - mikro, makro, dan tertimbang seperti yang ditunjukkan di bawah ini. Lihat definisi metrik dari bagian metrik klasifikasi .
Metrik segmentasi Instans dan deteksi objek
Setiap prediksi dari deteksi objek gambar atau model segmentasi instans dikaitkan dengan skor keyakinan.
Prediksi dengan skor keyakinan yang lebih besar dari ambang skor adalah output sebagai prediksi dan digunakan dalam penghitungan metrik, yang nilai default-nya merupakan model spesifik dan dapat dilihat dari halaman penyetelan hyperparameter (box_score_thresholdhyperparameter).
Komputasi metrik deteksi objek gambar dan model segmentasi instans didasarkan pada pengukuran tumpang tindih yang ditentukan oleh metrik yang disebut IoU (Intersection over Union) yang dihitung dengan membagi area tumpang tindih antara kebenaran dasar dan prediksi oleh area penyatuan kebenaran dasar dan prediksi. IoU yang dihitung dari setiap prediksi dibandingkan dengan ambang tumpang tindih yang disebut ambang IoU, yang menentukan berapa banyak prediksi yang harus tumpang tindih dengan kebenaran dasar yang dianotasi pengguna untuk dianggap sebagai prediksi positif. Jika IoU yang dihitung dari prediksi kurang dari ambang tumpang tindih, prediksi tidak akan dianggap sebagai prediksi positif untuk kelas terkait.
Metrik utama untuk evaluasi deteksi objek gambar dan model segmentasi instans adalah presisi menengah rata-rata (mAP). mAP adalah nilai rata-rata presisi rata-rata (AP) di semua kelas. Model deteksi objek ML otomatis mendukung komputasi mAP menggunakan dua metode populer berikut.
Metrik Pascal VOC:
mAP Pascal VOC adalah cara penghitungan mAP default untuk model segmentasi deteksi/instans objek. Metode mAP gaya Pascal VOC menghitung area dengan versi kurva pengenalan presisi. p(rᵢ) pertama, yang merupakan presisi pada pengenalan i dihitung untuk semua nilai pengenalan unik. p(rᵢ) kemudian diganti dengan presisi maksimum yang diperoleh untuk semua pengenalan r' >= rᵢ. Nilai presisi menurun secara monoton dalam versi kurva ini. Metrik mAP Pascal VOC dievaluasi secara default dengan ambang IoU 0,5. Penjelasan mendetail tentang konsep dapat ditemukan di \blog ini.
Metrik COCO:
Metode evaluasi COCO menggunakan metode interpolasi 101 poin untuk perhitungan AP bersama dengan rata-rata lebih dari sepuluh ambang IoU. AP@[.5:.95] bersesuaian dengan AP rata-rata untuk IoU dari 0,5 hingga 0,95 dengan ukuran langkah 0,05. ML otomatis mencatat semua 12 metrik yang ditentukan oleh metode COCO termasuk AP dan AR (pengenalan rata-rata) pada berbagai skala dalam log aplikasi sementara antarmuka pengguna metrik hanya menunjukkan mAP pada ambang IoU 0,5.
Tip
Evaluasi model deteksi objek gambar dapat menggunakan metrik COCO jika hyperparameter validation_metric_type diatur ke 'coco' seperti yang dijelaskan di bagian penyetelan hyperparameter.
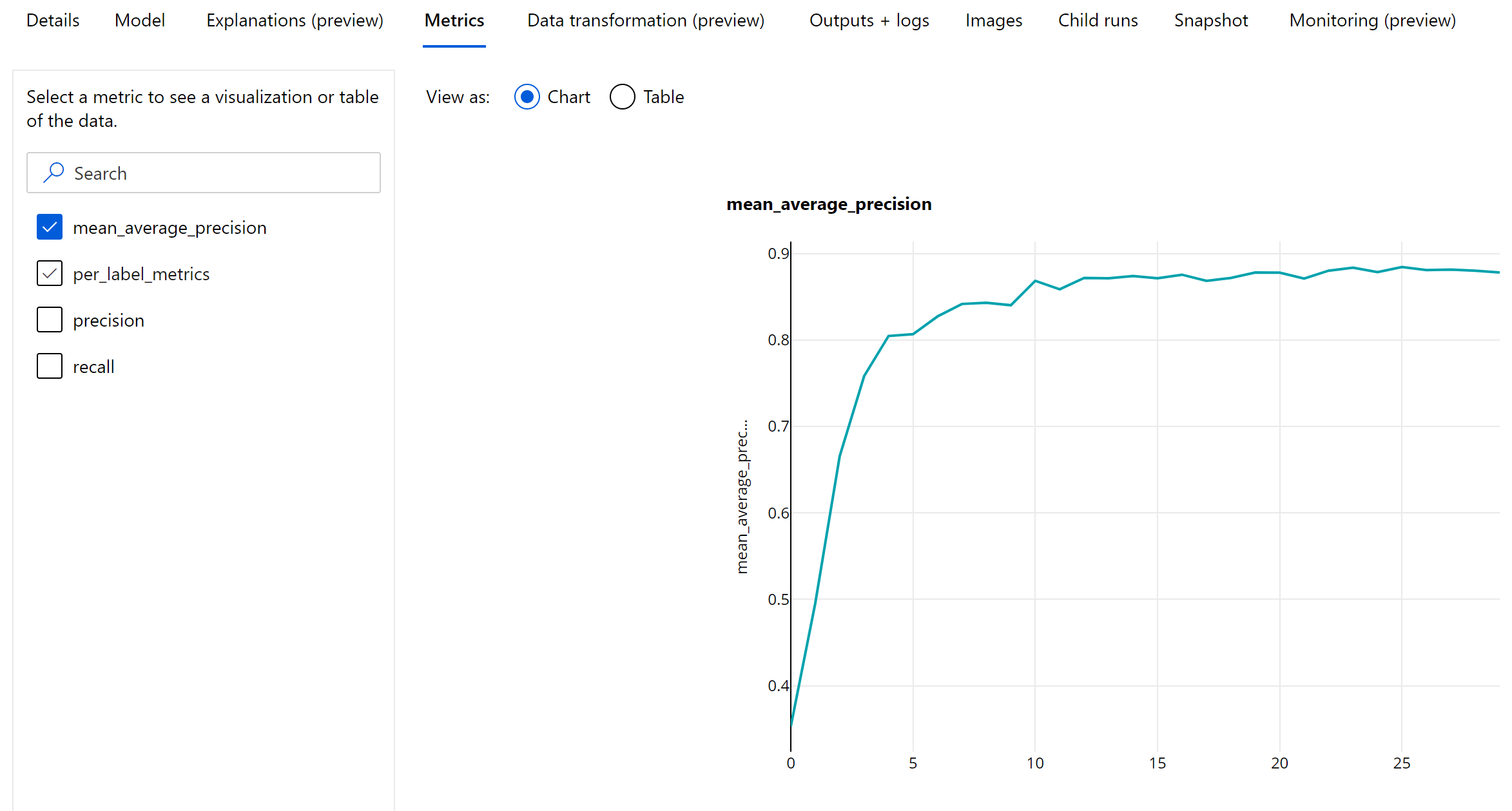
Metrik tingkat waktu untuk deteksi objek dan segmentasi instans
Nilai mAP, presisi, dan pengenalan dicatat pada tingkat epoch untuk model segmentasi deteksi objek gambar/instans. Metrik mAP, presisi, dan pengenalan juga dicatat pada tingkat kelas dengan nama 'per_label_metrics'. 'per_label_metrics' harus dianggap sebagai tabel.
Catatan
Metrik tingkat waktu untuk presisi, pengenalan, dan per_label_metrics tidak tersedia jika metode 'coco' digunakan.
Dasbor AI yang bertanggung jawab untuk model AutoML terbaik yang direkomendasikan (pratinjau)
Dasbor Azure Pembelajaran Mesin Responsible AI menyediakan satu antarmuka untuk membantu Anda menerapkan Responsible AI dalam praktiknya secara efektif dan efisien. Dasbor AI yang bertanggung jawab hanya didukung menggunakan data tabular dan hanya didukung pada model klasifikasi dan regresi. Ini menyatukan beberapa alat AI Bertanggung Jawab yang matang di bidang:
- Penilaian performa dan kewajaran model
- Eksplorasi data
- Interpretasi pembelajaran mesin
- Analisis kesalahan
Meskipun metrik dan bagan evaluasi model baik untuk mengukur kualitas umum model, operasi seperti memeriksa kewajaran model, melihat penjelasannya (juga dikenal sebagai himpunan data mana yang menampilkan model yang digunakan untuk membuat prediksinya), memeriksa kesalahannya dan potensi titik buta sangat penting saat mempraktikkan AI yang bertanggung jawab. Itulah sebabnya ML otomatis menyediakan dasbor AI yang Bertanggung Jawab untuk membantu Anda mengamati berbagai wawasan untuk model Anda. Lihat cara menampilkan dasbor AI yang bertanggung jawab di studio Azure Pembelajaran Mesin.
Lihat bagaimana Anda dapat menghasilkan dasbor ini melalui UI atau SDK.
Penjelasan model dan pentingnya fitur
Meskipun metrik dan bagan evaluasi model baik untuk mengukur kualitas umum model, memeriksa himpunan data mana yang digunakan model untuk membuat prediksi sangat penting saat mempraktikkan AI yang bertanggung jawab. Itulah sebabnya ML otomatis menyediakan dasbor penjelasan model untuk mengukur dan melaporkan kontribusi relatif dari fitur himpunan data. Lihat cara melihat dasbor penjelasan di studio Azure Machine Learning.
Catatan
Interpretabilitas, penjelasan model terbaik, tidak tersedia untuk eksperimen perkiraan ML otomatis yang merekomendasikan algoritme berikut sebagai model terbaik:
- TCNForecaster
- AutoArima
- EksponensialSmoothing
- Prophet
- Tengah
- Naive
- Seasonal Average
- Seasonal Naive
Langkah berikutnya
- Cobalah contoh buku catatan penjelasan model pembelajaran mesin otomatis.
- Untuk pertanyaan khusus ML otomatis, jangkau askautomatedml@microsoft.com.