Melacak eksperimen Azure Databricks ML dengan MLflow dan Azure Machine Learning
MLflow adalah pustaka sumber terbuka untuk mengelola siklus hidup eksperimen pembelajaran mesin. Anda dapat menggunakan MLflow untuk mengintegrasikan Azure Databricks dengan Azure Pembelajaran Mesin untuk memastikan Anda mendapatkan yang terbaik dari kedua produk.
Dalam artikel ini, Anda akan mempelajari:
- Pustaka yang diperlukan untuk menggunakan MLflow dengan Azure Databricks dan Azure Pembelajaran Mesin.
- Cara melacak eksekusi Azure Databricks dengan MLflow di Azure Pembelajaran Mesin.
- Cara mencatat model dengan MLflow untuk mendaftarkannya di Azure Pembelajaran Mesin.
- Cara menyebarkan dan menggunakan model yang terdaftar di Azure Pembelajaran Mesin.
Prasyarat
- Instal paket
azureml-mlflow, yang menangani konektivitas dengan Azure Machine Learning, termasuk autentikasi. - Ruang kerja dan kluster Azure Databricks.
- Membuat ruang kerja Azure Machine Learning.
Contoh buku catatan
Model Pelatihan di Azure Databricks dan menyebarkannya di Azure Pembelajaran Mesin menunjukkan cara melatih model di Azure Databricks dan menyebarkannya di Azure Pembelajaran Mesin. Ini juga termasuk cara menangani kasus di mana Anda juga ingin melacak eksperimen dan model dengan instans MLflow di Azure Databricks dan memanfaatkan Azure Pembelajaran Mesin untuk penyebaran.
Menginstal pustaka
Untuk menginstal pustaka pada kluster Anda, navigasi ke tab Pustaka dan pilih Instal Baru
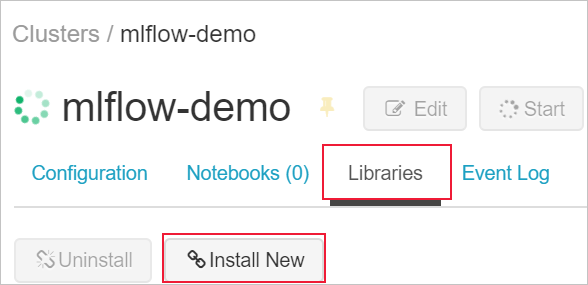
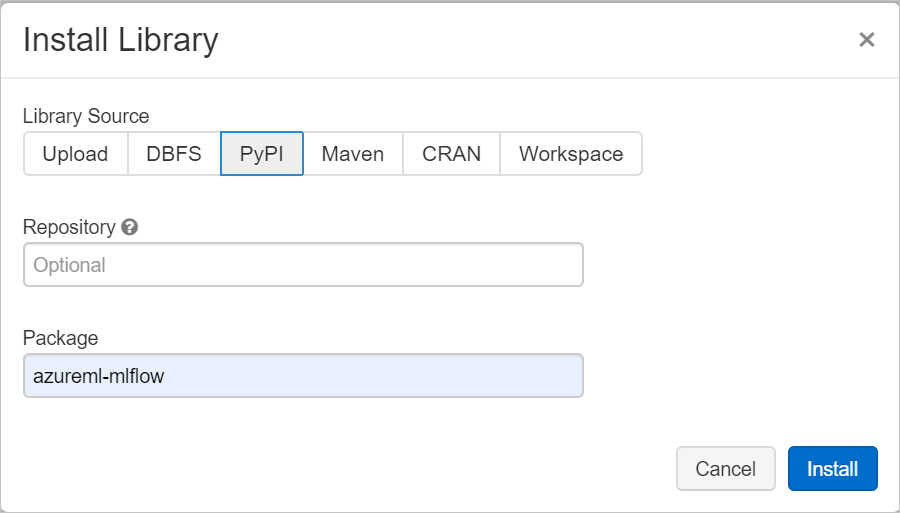
Di bidang Paket, ketik azureml-mlflow lalu pilih instal. Ulangi langkah ini seperlunya untuk menginstal paket tambahan lainnya ke kluster Anda sebagai eksperimen.
Lacak Azure Databricks berjalan dengan MLflow
Azure Databricks dapat dikonfigurasi untuk melacak eksperimen menggunakan MLflow dengan dua cara:
- Lacak ruang kerja Azure Databricks dan ruang kerja Azure Machine Learning Anda (pelacakan ganda)
- Melacak secara eksklusif di ruang kerja Azure Machine Learning
Secara default, pelacakan ganda dikonfigurasi untuk Anda saat Anda menautkan ruang kerja Azure Databricks Anda.
Pelacakan ganda di Azure Databricks dan Azure Machine Learning
Menautkan ruang kerja ADB ke ruang kerja Azure Machine Learning memungkinkan Anda melacak data eksperimen di ruang kerja Azure Machine Learning dan ruang kerja Azure Databricks secara bersamaan. Ini disebut sebagai Pelacakan ganda.
Peringatan
Pelacakan ganda di ruang kerja Azure Machine Learning yang mendukung tautan pribadi saat ini tidak didukung. Konfigurasikan pelacakan eksklusif dengan ruang kerja Azure Machine Learning Anda.
Peringatan
Pelacakan ganda tidak didukung di Microsoft Azure yang dioperasikan oleh 21Vianet saat ini. Konfigurasikan pelacakan eksklusif dengan ruang kerja Azure Machine Learning Anda.
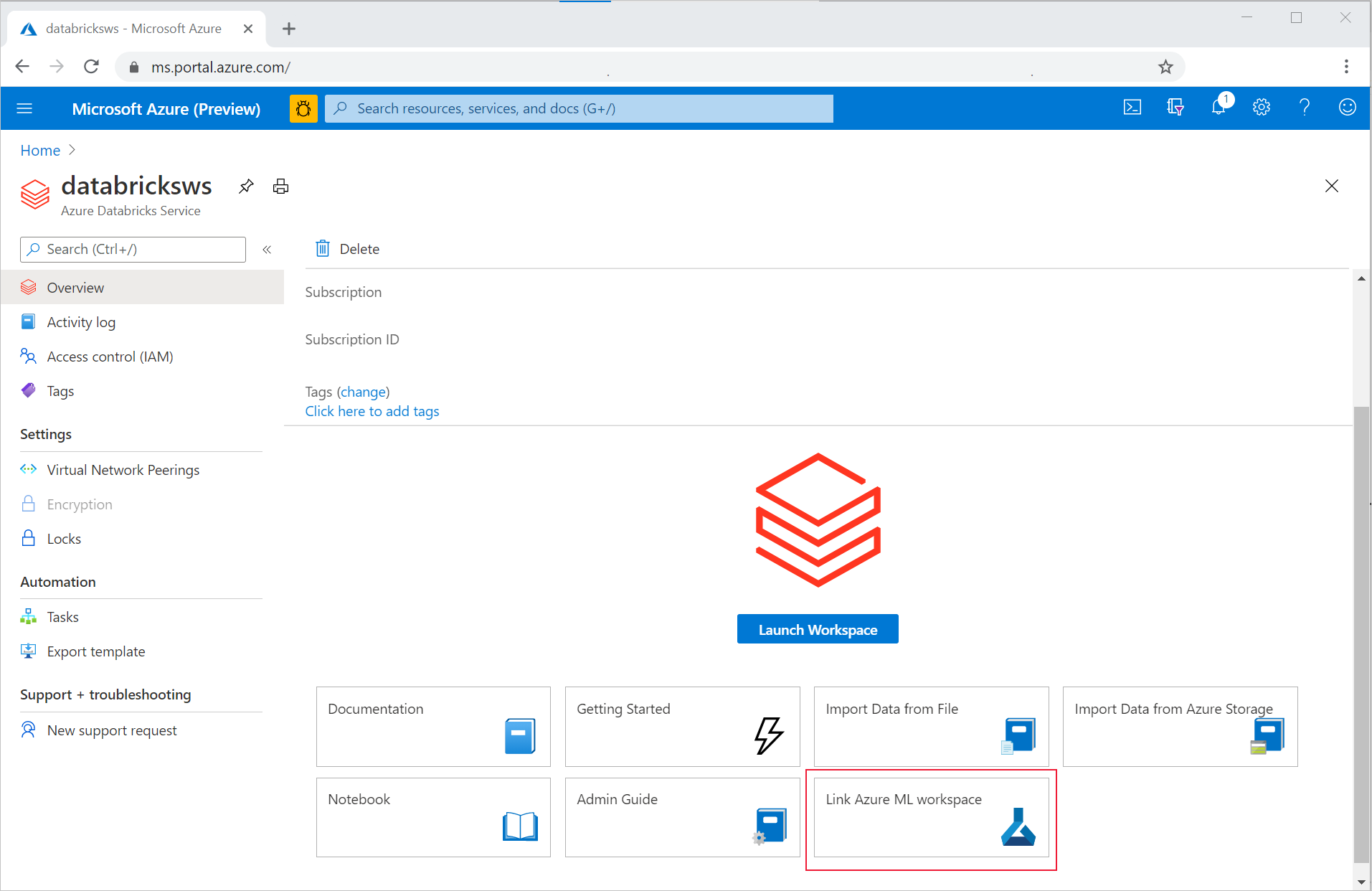
Untuk menautkan ruang kerja ADB Anda ke ruang kerja Azure Machine Learning yang baru atau yang sudah ada,
- Masuk ke portal Microsoft Azure.
- Arahkan ke halaman Ringkasan ruang kerja ADB Anda.
- Pilih tombol Tautkan ruang kerja Pembelajaran Mesin Azure di kanan bawah.
Setelah Anda menautkan ruang kerja Azure Databricks dengan ruang kerja Azure Machine Learning, Pelacakan MLflow secara otomatis diatur untuk dilacak di semua tempat berikut:
- Ruang kerja Azure Machine Learning yang ditautkan.
- Ruang kerja ADB asli Anda.
Anda dapat menggunakan MLflow di Azure Databricks dengan cara yang sama seperti yang biasa Anda gunakan. Contoh berikut menetapkan nama eksperimen seperti yang biasanya dilakukan di Azure Databricks dan mulai mencatat beberapa parameter:
import mlflow
experimentName = "/Users/{user_name}/{experiment_folder}/{experiment_name}"
mlflow.set_experiment(experimentName)
with mlflow.start_run():
mlflow.log_param('epochs', 20)
pass
Catatan
Berbeda dengan pelacakan, registri model tidak mendukung pendaftaran model secara bersamaan pada Azure Machine Learning dan Azure Databricks. Salah satu dari keduanya harus digunakan. Harap baca bagian Mendaftarkan model di registri dengan MLflow untuk detail selengkapnya.
Melacak secara eksklusif di ruang kerja Azure Machine Learning
Jika Anda lebih suka mengelola eksperimen terlacak di lokasi terpusat, Anda dapat menyetel pelacakan MLflow ke hanya melacak di ruang kerja Azure Machine Learning Anda. Konfigurasi ini memiliki keuntungan mengaktifkan jalur penyebaran yang lebih mudah menggunakan opsi penyebaran Azure Machine Learning.
Peringatan
Untuk ruang kerja Azure Machine Learning yang mengaktifkan tautan pribadi, Anda harus menyebarkan Azure Databricks di jaringan Anda sendiri (injeksi VNet) untuk memastikan konektivitas yang tepat.
Anda harus mengonfigurasi URI pelacakan MLflow untuk mengarahkan secara eksklusif ke Azure Machine Learning, seperti yang ditunjukkan dalam contoh berikut:
Mengonfigurasi URI pelacakan
Dapatkan URI pelacakan untuk ruang kerja Anda:
BERLAKU UNTUK:
 ekstensi ml Azure CLI v2 (saat ini)
ekstensi ml Azure CLI v2 (saat ini)Masuk dan konfigurasikan ruang kerja Anda:
az account set --subscription <subscription> az configure --defaults workspace=<workspace> group=<resource-group> location=<location>Anda bisa mendapatkan URI pelacakan menggunakan
az ml workspaceperintah :az ml workspace show --query mlflow_tracking_uri
Mengonfigurasi URI pelacakan:
Kemudian metode
set_tracking_uri()tersebut mengarahkan URI pelacakan MLflow ke URI tersebut.import mlflow mlflow.set_tracking_uri(mlflow_tracking_uri)Tip
Saat mengerjakan lingkungan bersama, seperti kluster Azure Databricks, kluster Azure Synapse Analytics, atau sejenisnya, berguna untuk mengatur variabel
MLFLOW_TRACKING_URIlingkungan di tingkat kluster untuk secara otomatis mengonfigurasi URI pelacakan MLflow untuk menunjuk ke Azure Pembelajaran Mesin untuk semua sesi yang berjalan di kluster daripada melakukannya per sesi.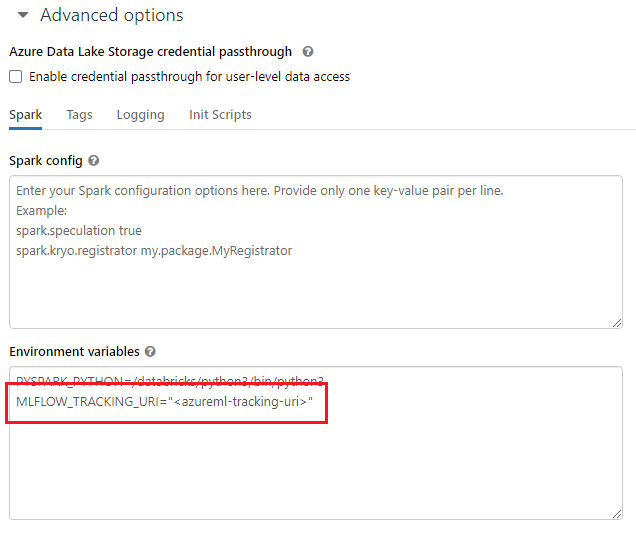
Setelah variabel lingkungan dikonfigurasi, eksperimen apa pun yang berjalan di kluster tersebut akan dilacak di Azure Pembelajaran Mesin.
Mengonfigurasi autentikasi
Setelah pelacakan dikonfigurasi, Anda juga perlu mengonfigurasi bagaimana autentikasi perlu terjadi ke ruang kerja terkait. Secara default, plugin Azure Pembelajaran Mesin untuk MLflow akan melakukan autentikasi interaktif dengan membuka browser default untuk meminta kredensial. Lihat Mengonfigurasi MLflow untuk Azure Pembelajaran Mesin: Mengonfigurasi autentikasi ke cara tambahan untuk mengonfigurasi autentikasi untuk MLflow di ruang kerja Azure Pembelajaran Mesin.
Untuk pekerjaan interaktif di mana ada pengguna yang terhubung ke sesi, Anda dapat mengandalkan Autentikasi Interaktif dan karenanya tidak ada tindakan lebih lanjut yang diperlukan.
Peringatan
Autentikasi browser interaktif akan memblokir eksekusi kode saat meminta kredensial. Ini bukan opsi yang cocok untuk autentikasi di lingkungan tanpa pengawas seperti pekerjaan pelatihan. Sebaiknya konfigurasikan mode autentikasi lainnya.
Untuk skenario di mana eksekusi tanpa pengawas diperlukan, Anda harus mengonfigurasi perwakilan layanan untuk berkomunikasi dengan Azure Pembelajaran Mesin.
import os
os.environ["AZURE_TENANT_ID"] = "<AZURE_TENANT_ID>"
os.environ["AZURE_CLIENT_ID"] = "<AZURE_CLIENT_ID>"
os.environ["AZURE_CLIENT_SECRET"] = "<AZURE_CLIENT_SECRET>"
Tip
Saat bekerja pada lingkungan bersama, disarankan untuk mengonfigurasi variabel lingkungan ini di komputasi. Sebagai praktik terbaik, kelola sebagai rahasia dalam instans Azure Key Vault jika memungkinkan. Misalnya, di Azure Databricks Anda dapat menggunakan rahasia dalam variabel lingkungan sebagai berikut dalam konfigurasi kluster: AZURE_CLIENT_SECRET={{secrets/<scope-name>/<secret-name>}}. Lihat Mereferensikan rahasia dalam variabel lingkungan untuk cara melakukannya di Azure Databricks atau lihat dokumentasi serupa di platform Anda.
Nama eksperimen dalam Azure Machine Learning
Ketika MLflow dikonfigurasi untuk melacak eksperimen secara eksklusif di ruang kerja Azure Machine Learning, konvensi penamaan eksperimen harus mengikuti konvensi penamaan yang digunakan oleh Azure Machine Learning. Di Azure Databricks, eksperimen diberi nama dengan jalur ke tempat eksperimen disimpan seperti /Users/alice@contoso.com/iris-classifier. Namun, dalam Azure Machine Learning, Anda harus memberikan nama eksperimen secara langsung. Seperti dalam contoh sebelumnya, eksperimen yang sama akan dinamai iris-classifier secara langsung:
mlflow.set_experiment(experiment_name="experiment-name")
Parameter pelacakan, metrik, dan artefak
Anda dapat menggunakan MLflow di Azure Databricks dengan cara yang sama seperti yang biasa Anda gunakan. Untuk detailnya, lihat Log & lihat metrik dan file log.
Model pengelogan dengan MLflow
Setelah model Anda dilatih, Anda dapat mencatatnya ke server pelacakan dengan metode mlflow.<model_flavor>.log_model(). <model_flavor>, mengacu pada kerangka kerja yang terkait dengan model. Pelajari rasa model apa yang didukung. Dalam contoh berikut, model yang dibuat dengan pustaka Spark MLLib sedang didaftarkan:
mlflow.spark.log_model(model, artifact_path = "model")
Patut disebutkan bahwa rasa spark tidak sesuai dengan fakta bahwa kami melatih model di kluster Spark tetapi karena kerangka kerja pelatihan yang digunakan (Anda dapat melatih model dengan sempurna menggunakan TensorFlow dengan Spark dan karenanya rasa yang akan digunakan adalah tensorflow).
Model dicatat di dalam eksekusi yang sedang dilacak. Itu artinya bahwa model tersedia baik di Azure Databricks dan Azure Machine Learning (default) atau secara eksklusif di Azure Machine Learning jika Anda mengonfigurasi URI pelacakan untuk mengarah ke Azure Machine Learning.
Penting
Perhatikan bahwa di sini parameter registered_model_name belum ditentukan. Baca bagian Mendaftarkan model di registri dengan MLflow untuk detail selengkapnya tentang implikasi parameter tersebut dan cara kerja registri.
Mendaftarkan model di registri dengan MLflow
Dibandingkan dengan pelacakan, registri model tidak dapat beroperasi secara bersamaan di Azure Databricks dan Azure Machine Learning. Salah satu dari keduanya harus digunakan. Secara default, ruang kerja Azure Databricks digunakan untuk registri model; kecuali Anda memilih untuk mengatur Pelacakan MLFlow agar hanya melacak di ruang kerja Azure Machine Learning Anda, maka registri model adalah ruang kerja Azure Machine Learning.
Kemudian, dengan pertimbangan Anda menggunakan konfigurasi default, baris berikut akan mencatat model di dalam eksekusi Azure Databricks dan Azure Machine Learning yang sesuai, tetapi hanya akan mendaftarkannya di Azure Databricks:
mlflow.spark.log_model(model, artifact_path = "model",
registered_model_name = 'model_name')
Jika model terdaftar dengan nama tidak ada, metode ini mendaftarkan model baru, membuat versi 1, dan mengembalikan objek MLflow ModelVersion.
Jika sudah ada model terdaftar dengan nama, metode akan membuat versi model baru dan mengembalikan objek versi.
Menggunakan Azure Machine Learning terdaftar dengan MLflow
Jika Anda ingin menggunakan Azure Machine Learning Model terdaftar alih-alih Azure Databricks, kami sarankan Anda mengatur Pelacakan MLflow untuk hanya melacak di ruang kerja Azure Machine Learning Anda. Ini akan menghapus ambiguitas mengenai tempat model sedang didaftarkan dan menyederhanakan kompleksitas.
Namun, jika Anda ingin terus menggunakan kemampuan pelacakan ganda tetapi mendaftarkan model di Azure Pembelajaran Mesin, Anda dapat menginstruksikan MLflow untuk menggunakan Azure Pembelajaran Mesin untuk registri model dengan mengonfigurasi URI MLflow Model Registry. URI ini memiliki format dan nilai yang sama persis dengan URI pelacakan MLflow.
mlflow.set_registry_uri(azureml_mlflow_uri)
Catatan
Nilai azureml_mlflow_uri diperoleh dengan cara yang sama seperti yang ditunjukkan di Mengatur Pelacakan MLflow untuk hanya melacak di ruang kerja Azure Machine Learning Anda
Untuk contoh lengkap tentang skenario ini, silakan periksa contoh Model pelatihan di Azure Databricks dan sebarkan di Azure Pembelajaran Mesin.
Menyebarkan dan mengonsumsi model yang terdaftar di Azure Machine Learning
Model yang terdaftar di Layanan Azure Machine Learning yang menggunakan MLflow dapat dikonsumsi sebagai:
Titik akhir Azure Machine Learning (real-time dan batch): Penyebaran ini memungkinkan Anda memanfaatkan kemampuan penyebaran Azure Machine Learning untuk inferensi real time dan batch dalam Azure Container Instances (ACI) Azure Kubernetes (AKS) atau titik akhir Inferensi Terkelola (MIR) kami.
Objek model MLFlow atau UDF Pandas, yang dapat digunakan di buku catatan Azure Databricks dalam alur streaming atau batch.
Menyebarkan model ke titik akhir Azure Machine Learning
Anda dapat memanfaatkan plugin azureml-mlflow untuk menyebarkan model ke ruang kerja Azure Machine Learning Anda. Periksa halaman Cara menyebarkan model MLflow untuk detail lengkap tentang cara menyebarkan model ke target yang berbeda.
Penting
Model perlu didaftarkan di registri Azure Machine Learning untuk menyebarkannya. Jika model Anda terdaftar di instans MLflow di dalam Azure Databricks, Anda harus mendaftarkannya lagi di Azure Machine Learning. Jika demikian, silakan periksa contoh Model pelatihan di Azure Databricks dan sebarkan di Azure Pembelajaran Mesin
Menyebarkan model ke ADB untuk penilaian batch menggunakan UDF
Anda dapat memilih Azure Databricks untuk penilaian batch. Dengan memanfaatkan Mlflow, Anda dapat menyelesaikan model apa pun dari registri yang terhubung dengan Anda. Anda biasanya akan menggunakan salah satu dari dua metode berikut:
- Jika model Anda dilatih dan dibangun dengan pustaka Spark (seperti
MLLib), gunakanmlflow.pyfunc.spark_udfuntuk memuat model dan menggunakannya sebagai UDF Spark Pandas untuk menilai data baru. - Jika model Anda tidak dilatih atau dibangun dengan pustaka Spark, gunakan
mlflow.pyfunc.load_modelataumlflow.<flavor>.load_modeluntuk memuat model di driver kluster. Perhatikan bahwa dengan cara ini, paralelisasi atau distribusi kerja apa pun yang ingin Anda lakukan di kluster perlu diorkestrasi oleh Anda. Selain itu, perhatikan bahwa MLflow tidak menginstal pustaka apa pun yang diperlukan model Anda untuk dijalankan. Pustaka tersebut perlu diinstal di kluster sebelum menjalankannya.
Contoh berikut menunjukkan cara memuat model dari registri bernama uci-heart-classifier dan menggunakannya sebagai Spark Pandas UDF untuk menilai data baru.
from pyspark.sql.types import ArrayType, FloatType
model_name = "uci-heart-classifier"
model_uri = "models:/"+model_name+"/latest"
#Create a Spark UDF for the MLFlow model
pyfunc_udf = mlflow.pyfunc.spark_udf(spark, model_uri)
Tip
Periksa Memuat model dari registri untuk cara lain untuk mereferensikan model dari registri.
Setelah model dimuat, Anda dapat menggunakan untuk menilai data baru:
#Load Scoring Data into Spark Dataframe
scoreDf = spark.table({table_name}).where({required_conditions})
#Make Prediction
preds = (scoreDf
.withColumn('target_column_name', pyfunc_udf('Input_column1', 'Input_column2', ' Input_column3', …))
)
display(preds)
Membersihkan sumber daya
Jika Anda ingin menyimpan ruang kerja Azure Databricks, tetapi tidak lagi memerlukan ruang kerja Azure Pembelajaran Mesin, Anda dapat menghapus ruang kerja Azure Pembelajaran Mesin. Tindakan ini mengakibatkan membatalkan tautan ruang kerja Azure Databricks dan ruang kerja Azure Pembelajaran Mesin.
Jika Anda tidak berencana untuk menggunakan metrik dan artefak yang dicatat di ruang kerja Anda, kemampuan untuk menghapusnya satu per satu tidak tersedia saat ini. Sebagai gantinya, hapus grup sumber daya yang berisi akun penyimpanan dan ruang kerja, sehingga Anda tidak dikenakan biaya apa pun:
Dari portal Microsoft Azure, pilih Grup sumber daya dari sisi sebelah kiri.
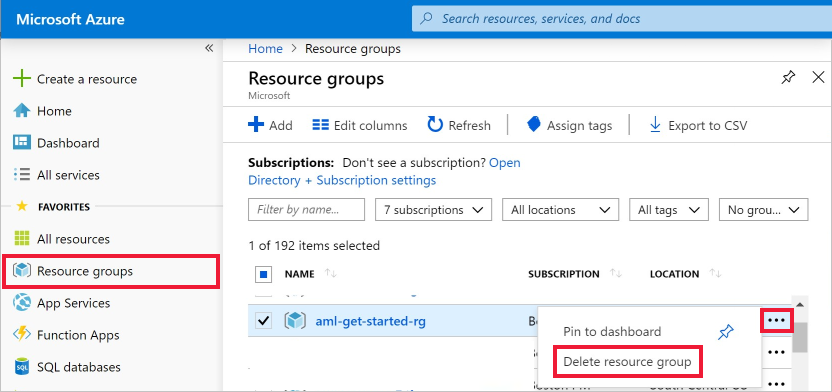
Dari daftar, pilih grup sumber daya yang Anda buat.
Pilih Hapus grup sumber daya.
Masukkan nama grup sumber daya. Kemudian pilih Hapus.