Cara menggunakan Apache Spark (didukung oleh Azure Synapse Analytics) di alur pembelajaran mesin Anda (tidak digunakan lagi)
BERLAKU UNTUK: Python SDK azureml v1
Python SDK azureml v1
Peringatan
Integrasi Azure Synapse Analytics dengan Azure Pembelajaran Mesin, tersedia di Python SDK v1, tidak digunakan lagi. Pengguna masih dapat menggunakan ruang kerja Synapse, yang terdaftar di Azure Pembelajaran Mesin, sebagai layanan tertaut. Namun, ruang kerja Synapse baru tidak dapat lagi terdaftar di Azure Machine Learning sebagai layanan tertaut. Sebaiknya gunakan komputasi Spark tanpa server dan kumpulan Synapse Spark yang terpasang, tersedia di CLI v2 dan Python SDK v2. Untuk informasi selengkapnya, kunjungi https://aka.ms/aml-spark.
Dalam artikel ini, Anda mempelajari cara menggunakan kumpulan Apache Spark yang didukung oleh Azure Synapse Analytics sebagai target komputasi untuk langkah persiapan data di alur Azure Pembelajaran Mesin. Anda mempelajari bagaimana satu alur dapat menggunakan sumber daya komputasi yang cocok untuk langkah tertentu - misalnya, persiapan atau pelatihan data. Anda juga akan mempelajari bagaimana data disiapkan untuk langkah Spark dan bagaimana data tersebut diteruskan ke langkah berikutnya.
Prasyarat
Buat ruang kerja Azure Machine Learning untuk menyimpan semua sumber daya alur Anda
Konfigurasikan lingkungan pengembangan Anda untuk memasang Azure Machine Learning SDK, atau gunakan instans komputasi Azure Machine Learning dengan SDK yang sudah dipasang
Buat ruang kerja Azure Synapse Analytics dan kumpulan Apache Spark. Untuk informasi selengkapnya, kunjungi Mulai Cepat: Membuat kumpulan Apache Spark tanpa server menggunakan Synapse Studio
Menautkan ruang kerja Azure Machine Learning dan Azure Synapse Analytics
Anda membuat dan mengelola kumpulan Apache Spark di ruang kerja Azure Synapse Analytics. Untuk mengintegrasikan kumpulan Apache Spark dengan ruang kerja Azure Machine Learning, Anda harus menautkan ke ruang kerja Azure Synapse Analytics. Setelah menautkan ruang kerja Azure Pembelajaran Mesin dan ruang kerja Azure Synapse Analytics, Anda dapat melampirkan kumpulan Apache Spark dengan
Python SDK, seperti yang dijelaskan kemudian
Templat Azure Resource Manager (ARM). Untuk informasi selengkapnya, kunjungi Contoh templat ARM
- Anda dapat menggunakan baris perintah untuk mengikuti templat ARM, menambahkan layanan tertaut, dan melampirkan kumpulan Apache Spark dengan sampel kode ini:
az deployment group create --name --resource-group <rg_name> --template-file "azuredeploy.json" --parameters @"azuredeploy.parameters.json"
Penting
Agar berhasil menautkan ke ruang kerja Synapse, Anda harus diberikan peran Pemilik ruang kerja Synapse. Periksa akses Anda di portal Azure.
Layanan tertaut akan mendapatkan identitas terkelola (SAI) yang ditetapkan sistem pada waktu pembuatan. Anda harus menetapkan layanan tautan ini SAI peran "Administrator Synapse Apache Spark" dari Synapse Studio, sehingga dapat mengirimkan pekerjaan Spark (lihat Cara mengelola penetapan peran RBAC Synapse di Synapse Studio).
Anda juga harus memberi pengguna ruang kerja Azure Pembelajaran Mesin peran "Kontributor", dari portal Azure manajemen sumber daya.
Ambil tautan antara ruang kerja Azure Synapse Analytics dan ruang kerja Azure Machine Learning Anda
Kode ini menunjukkan cara mengambil layanan tertaut di ruang kerja Anda:
from azureml.core import Workspace, LinkedService, SynapseWorkspaceLinkedServiceConfiguration
ws = Workspace.from_config()
for service in LinkedService.list(ws) :
print(f"Service: {service}")
# Retrieve a known linked service
linked_service = LinkedService.get(ws, 'synapselink1')
Pertama, Workspace.from_config() akses ruang kerja Azure Pembelajaran Mesin Anda dengan konfigurasi dalam config.json file. (Untuk informasi lebih lanjut, kunjungi Membuat file konfigurasi ruang kerja). Kemudian, kode mencetak semua layanan tertaut yang tersedia di ruang kerja. Terakhir, LinkedService.get() mengambil layanan tertaut bernama 'synapselink1'.
Lampirkan kumpulan Apache spark Anda sebagai target komputasi untuk Azure Machine Learning
Untuk menggunakan kumpulan Apache spark Anda untuk memberi daya pada langkah dalam alur pembelajaran mesin, Anda harus melampirkannya sebagai untuk langkah alur, seperti yang ComputeTarget ditunjukkan dalam sampel kode ini:
from azureml.core.compute import SynapseCompute, ComputeTarget
attach_config = SynapseCompute.attach_configuration(
linked_service = linked_service,
type="SynapseSpark",
pool_name="spark01") # This name comes from your Synapse workspace
synapse_compute=ComputeTarget.attach(
workspace=ws,
name='link1-spark01',
attach_configuration=attach_config)
synapse_compute.wait_for_completion()
Kode pertama-tama SynapseComputemengonfigurasi . Argumen linked_service adalah objek LinkedService yang Anda buat atau ambil di langkah sebelumnya. Argumen typeharus SynapseSpark. Argumen pool_name di SynapseCompute.attach_configuration() harus cocok dengan kumpulan yang ada di ruang kerja Azure Synapse Analytics Anda. Untuk informasi selengkapnya tentang pembuatan kumpulan Apache spark di ruang kerja Azure Synapse Analytics, kunjungi Mulai Cepat: Membuat kumpulan Apache Spark tanpa server menggunakan Synapse Studio. Jenisnya attach_config adalah ComputeTargetAttachConfiguration.
Setelah pembuatan konfigurasi, buat pembelajaran ComputeTarget mesin dengan meneruskan Workspace nilai dan ComputeTargetAttachConfiguration , dan nama tempat Anda ingin merujuk ke komputasi dalam ruang kerja pembelajaran mesin. Panggilan ke ComputeTarget.attach() tidak sinkron, sehingga sampel diblokir hingga panggilan selesai.
Membuat SynapseSparkStep yang menggunakan kumpulan Apache Spark tertaut
Sampel buku catatan Pekerjaan Spark di kumpulan Apache Spark menentukan alut pembelajaran mesin sederhana. Pertama, notebook mendefinisikan langkah persiapan data, didukung oleh yang synapse_compute ditentukan pada langkah sebelumnya. Kemudian, notebook menentukan langkah pelatihan yang didukung oleh target komputasi yang lebih sesuai untuk pelatihan. Contoh notebook menggunakan database kelangsungan hidup Titanic untuk menampilkan input dan output data. Ini sebenarnya tidak membersihkan data atau membuat model prediktif. Karena sampel ini tidak benar-benar melibatkan pelatihan, langkah pelatihan menggunakan sumber daya komputasi berbasis CPU yang murah.
Data mengalir ke alur pembelajaran mesin melalui DatasetConsumptionConfig objek, yang dapat menyimpan data tabular atau set file. Data sering berasal dari file dalam penyimpanan blob di penyimpanan data ruang kerja. Sampel kode ini menunjukkan kode umum yang membuat input untuk alur pembelajaran mesin:
from azureml.core import Dataset
datastore = ws.get_default_datastore()
file_name = 'Titanic.csv'
titanic_tabular_dataset = Dataset.Tabular.from_delimited_files(path=[(datastore, file_name)])
step1_input1 = titanic_tabular_dataset.as_named_input("tabular_input")
# Example only: it wouldn't make sense to duplicate input data, especially one as tabular and the other as files
titanic_file_dataset = Dataset.File.from_files(path=[(datastore, file_name)])
step1_input2 = titanic_file_dataset.as_named_input("file_input").as_hdfs()
Sampel kode mengasumsikan bahwa file Titanic.csv berada dalam penyimpanan blob. Kode menunjukkan cara membaca file baik sebagai dan TabularDataset sebagai FileDataset. Kode ini hanya untuk tujuan demonstrasi, karena akan menjadi membingungkan untuk menduplikasi input atau untuk menafsirkan satu sumber data sebagai sumber daya yang berisi tabel, dan secara ketat sebagai file.
Penting
Untuk menggunakan FileDataset sebagai input, Anda memerlukan azureml-core versi setidaknya 1.20.0. Anda dapat menentukan ini dengan kelas , seperti yang Environment dibahas nanti. Saat langkah selesai, Anda dapat menyimpan data output, seperti yang ditunjukkan dalam sampel kode ini:
from azureml.data import HDFSOutputDatasetConfig
step1_output = HDFSOutputDatasetConfig(destination=(datastore,"test")).register_on_complete(name="registered_dataset")
Dalam sampel kode ini, datastore akan menyimpan data dalam file bernama test. Data akan tersedia dalam ruang kerja pembelajaran mesin sebagai Dataset, dengan nama registered_dataset.
Selain data, langkah alur dapat memiliki dependensi Python per langkah. Selain itu, objek individual SynapseSparkStep dapat menentukan konfigurasi Azure Synapse Apache Spark yang tepat. Untuk menunjukkan ini, sampel kode berikut menentukan bahwa azureml-core versi paket harus setidaknya 1.20.0. Seperti disebutkan sebelumnya, persyaratan untuk azureml-core paket ini diperlukan untuk menggunakan FileDataset sebagai input.
from azureml.core.environment import Environment
from azureml.pipeline.steps import SynapseSparkStep
env = Environment(name="myenv")
env.python.conda_dependencies.add_pip_package("azureml-core>=1.20.0")
step_1 = SynapseSparkStep(name = 'synapse-spark',
file = 'dataprep.py',
source_directory="./code",
inputs=[step1_input1, step1_input2],
outputs=[step1_output],
arguments = ["--tabular_input", step1_input1,
"--file_input", step1_input2,
"--output_dir", step1_output],
compute_target = 'link1-spark01',
driver_memory = "7g",
driver_cores = 4,
executor_memory = "7g",
executor_cores = 2,
num_executors = 1,
environment = env)
Kode ini menentukan satu langkah dalam alur Azure Pembelajaran Mesin. Nilai environment kode ini menetapkan versi tertentu azureml-core , dan kode dapat menambahkan dependensi conda atau pip lainnya sesuai kebutuhan.
SynapseSparkStep Zip dan mengunggah ./code subdirektori dari komputer lokal. Direktori tersebut dibuat ulang di server komputasi, dan langkah menjalankan skrip dari direktori tersebut dataprep.py . Dan inputs outputs dari langkah itu step1_input1adalah objek , step1_input2, dan step1_output yang dibahas sebelumnya. Cara termudah untuk mengakses nilai-nilai tersebut dalam skrip dataprep.py adalah dengan mengaitkannya dengan arguments bernama.
Kumpulan argumen berikutnya ke SynapseSparkStep konstruktor mengontrol Apache Spark. compute_target adalah 'link1-spark01' yang kami lampirkan sebagai target komputasi sebelumnya. Parameter lain menentukan memori dan inti yang ingin kami gunakan.
Contoh buku catatan menggunakan kode ini untuk dataprep.py:
import os
import sys
import azureml.core
from pyspark.sql import SparkSession
from azureml.core import Run, Dataset
print(azureml.core.VERSION)
print(os.environ)
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--tabular_input")
parser.add_argument("--file_input")
parser.add_argument("--output_dir")
args = parser.parse_args()
# use dataset sdk to read tabular dataset
run_context = Run.get_context()
dataset = Dataset.get_by_id(run_context.experiment.workspace,id=args.tabular_input)
sdf = dataset.to_spark_dataframe()
sdf.show()
# use hdfs path to read file dataset
spark= SparkSession.builder.getOrCreate()
sdf = spark.read.option("header", "true").csv(args.file_input)
sdf.show()
sdf.coalesce(1).write\
.option("header", "true")\
.mode("append")\
.csv(args.output_dir)
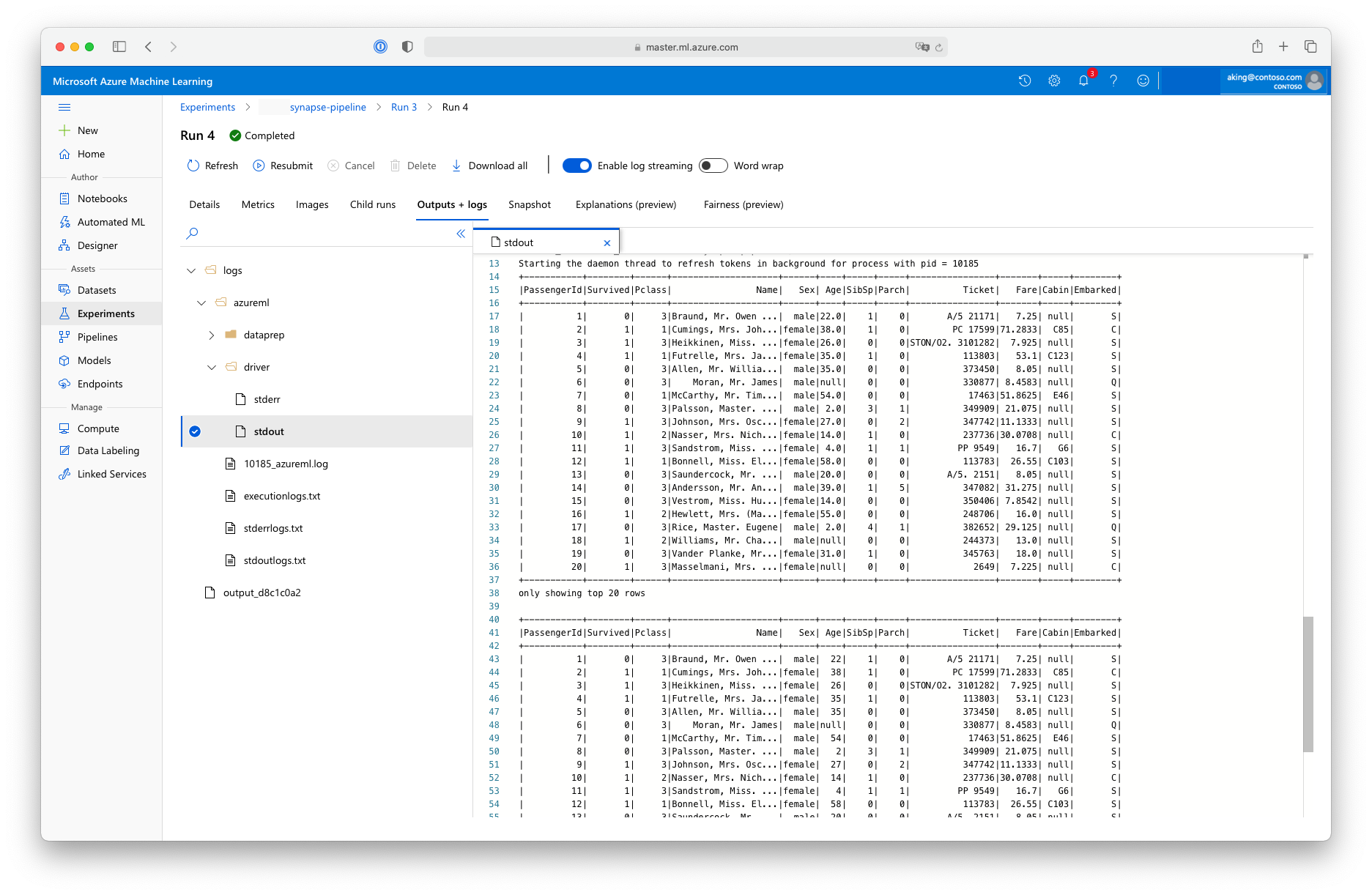
Skrip "persiapan data" ini tidak melakukan transformasi data nyata, tetapi menunjukkan cara mengambil data, mengonversinya ke dataframe Spark, dan cara melakukan beberapa manipulasi Apache Spark dasar. Untuk menemukan output di studio Azure Pembelajaran Mesin, buka pekerjaan anak, pilih tab Output + log, dan buka file, seperti yang logs/azureml/driver/stdout ditunjukkan pada cuplikan layar ini:
Menggunakan SynapseSparkStep dalam alur
Contoh berikutnya menggunakan output dari yang SynapseSparkStep dibuat di bagian sebelumnya. Langkah lain dalam alur mungkin memiliki lingkungan unik mereka sendiri, dan mungkin berjalan pada sumber daya komputasi yang berbeda yang sesuai dengan tugas yang ditangani. Sampel buku catatan menjalankan "langkah pelatihan" pada kluster CPU kecil:
from azureml.core.compute import AmlCompute
cpu_cluster_name = "cpucluster"
if cpu_cluster_name in ws.compute_targets:
cpu_cluster = ComputeTarget(workspace=ws, name=cpu_cluster_name)
print('Found existing cluster, use it.')
else:
compute_config = AmlCompute.provisioning_configuration(vm_size='STANDARD_D2_V2', max_nodes=1)
cpu_cluster = ComputeTarget.create(ws, cpu_cluster_name, compute_config)
print('Allocating new CPU compute cluster')
cpu_cluster.wait_for_completion(show_output=True)
step2_input = step1_output.as_input("step2_input").as_download()
step_2 = PythonScriptStep(script_name="train.py",
arguments=[step2_input],
inputs=[step2_input],
compute_target=cpu_cluster_name,
source_directory="./code",
allow_reuse=False)
Kode ini membuat sumber daya komputasi baru jika perlu. Kemudian, ini mengonversi hasilnya step1_output menjadi input untuk langkah pelatihan. Opsi ini as_download() berarti bahwa data dipindahkan ke sumber daya komputasi, menghasilkan akses yang lebih cepat. Jika data sangat besar sehingga tidak akan muat pada hard drive komputasi lokal, Anda harus menggunakan as_mount() opsi untuk mengalirkan data dengan FUSE sistem file. compute_target dari langkah kedua ini adalah 'cpucluster', bukan sumber daya 'link1-spark01' yang Anda gunakan dalam langkah penyiapan data. Langkah ini menggunakan skrip sederhana train.py alih-alih skrip yang dataprep.py Anda gunakan di langkah sebelumnya. Contoh buku catatan memiliki detail train.py skrip.
Setelah menentukan semua langkah, Anda dapat membuat dan menjalankan alur Anda.
from azureml.pipeline.core import Pipeline
pipeline = Pipeline(workspace=ws, steps=[step_1, step_2])
pipeline_run = pipeline.submit('synapse-pipeline', regenerate_outputs=True)
Kode ini membuat alur yang terdiri dari langkah persiapan data pada kumpulan Apache Spark, didukung oleh Azure Synapse Analytics (step_1) dan langkah pelatihan (step_2). Azure memeriksa dependensi data antara langkah-langkah untuk menghitung grafik eksekusi. Dalam hal ini, hanya ada satu dependensi langsung. Di sini, step2_input tentu memerlukan step1_output.
Panggilan pipeline.submit membuat, jika perlu, Eksperimen bernama synapse-pipeline, dan secara asinkron memulai Pekerjaan di dalamnya. Langkah-langkah individual dalam alur berjalan sebagai Pekerjaan Anak dari pekerjaan utama ini, dan halaman Eksperimen Studio dapat memantau dan meninjau langkah-langkah tersebut.
Langkah berikutnya
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk