Contoh alur & himpunan data untuk perancang Azure Machine Learning
Gunakan contoh bawaan perancang Azure Machine Learning untuk mulai membangun alur pembelajaran mesin Anda sendiri dengan cepat. Repositori GitHub perancang Azure Machine Learning berisi dokumentasi mendetail untuk membantu Anda memahami beberapa skenario pembelajaran mesin umum.
Prasyarat
- Langganan Azure. Jika Anda tidak memiliki langganan Azure, buatlah akun gratis
- Ruang kerja Azure Machine Learning
Penting
Jika Anda tidak melihat elemen grafis yang disebutkan dalam dokumen ini, seperti tombol di studio atau perancang, Anda mungkin tidak memiliki tingkat izin yang tepat ke ruang kerja. Silakan hubungi administrator langganan Azure Anda untuk memverifikasi bahwa Anda telah diberikan tingkat akses yang benar. Untuk informasi selengkapnya, lihat Mengelola pengguna dan peran.
Gunakan sampel alur
Perancang menyimpan salinan alur sampel ke ruang kerja studio Anda. Anda dapat mengedit alur untuk menyesuaikannya dengan kebutuhan Anda dan menyimpannya sebagai milik Anda. Gunakan sebagai titik awal untuk memulai proyek Anda.
Berikut cara menggunakan sampel perancang:
Masuk ke ml.azure.com, dan pilih ruang kerja yang ingin Anda gunakan.
Pilih Perancang.
Pilih sampel alur di bawah bagian Alur baru.
Pilih Tampilkan sampel lainnya untuk mengetahui daftar lengkap sampel.
Untuk menjalankan alur, pertama-tama Anda harus menetapkan target komputasi default untuk menjalankan alur.
Di panel Pengaturan di sebelah kanan kanvas, klik Pilih target komputasi.
Dalam dialog yang muncul, pilih target komputasi yang sudah ada atau buat yang baru. Pilih Simpan.
Pilih Kirim di bagian atas kanvas untuk mengirimkan pekerjaan alur.
Tergantung sampel alur dan pengaturan komputasi, penyelesaian pekerjaan mungkin memerlukan waktu beberapa saat. Pengaturan komputasi default memiliki ukuran node minimum 0, yang berarti bahwa perancang harus mengalokasikan sumber daya setelah tidak aktif. Pekerjaan alur berulang akan memerlukan waktu lebih sedikit karena sumber daya komputasi sudah dialokasikan. Selain itu, perancang menggunakan hasil cache untuk setiap komponen untuk lebih meningkatkan efisiensi.
Setelah alur selesai berjalan, Anda dapat meninjau alur dan melihat output untuk setiap komponen guna mempelajari selengkapnya. Gunakan langkah-langkah berikut untuk melihat output komponen:
- Klik kanan komponen di kanvas yang outputnya ingin Anda lihat.
- Pilih Visualisasikan.
Gunakan sampel sebagai titik awal untuk beberapa skenario pembelajaran mesin yang paling umum.
Regresi
Jelajahi sampel regresi bawaan ini.
| Contoh judul | Deskripsi |
|---|---|
| Regresi - Prediksi Harga Mobil (Dasar) | Prediksi harga mobil menggunakan regresi linier. |
| Regresi - Prediksi Harga Mobil (Tingkat Lanjut) | Prediksi harga mobil menggunakan hutan keputusan dan regresor pohon keputusan yang ditingkatkan. Bandingkan model untuk menemukan algoritma terbaik. |
Klasifikasi
Jelajahi sampel klasifikasi bawaan ini. Anda dapat mempelajari selengkapnya tentang sampel dengan membuka sampel dan melihat komentar komponen di perancang.
| Contoh judul | Deskripsi |
|---|---|
| Klasifikasi Biner dengan Pemilihan Fitur - Prediksi Pendapatan | Prediksi pendapatan sebagai tinggi atau rendah, menggunakan pohon keputusan yang didorong dua kelas. Gunakan korelasi Pearson untuk memilih fitur. |
| Klasifikasi Biner dengan skrip Python kustom - Prediksi Risiko Kredit | Mengklasifikasikan aplikasi kredit sebagai risiko tinggi atau rendah. Gunakan komponen Execute Python Script untuk menghitung data Anda. |
| Klasifikasi Biner - Prediksi Hubungan Pelanggan | Prediksi kehilangan churn pelanggan menggunakan pohon keputusan yang didorong dua kelas. Gunakan SMOTE untuk mengambil sampel data yang bias. |
| Klasifikasi Teks - Himpunan Data Wikipedia SP 500 | Klasifikasikan jenis perusahaan dari artikel Wikipedia dengan regresi logistik multikelas. |
| Klasifikasi Multikelas - Pengenalan Huruf | Buat ansambel pengklasifikasi biner untuk mengklasifikasikan surat tertulis. |
Computer Vision
Jelajahi sampel visi komputer bawaan ini. Anda dapat mempelajari selengkapnya tentang sampel dengan membuka sampel dan melihat komentar komponen di perancang.
| Contoh judul | Deskripsi |
|---|---|
| Klasifikasi Gambar menggunakan DenseNet | Gunakan komponen visi komputer untuk membangun model klasifikasi gambar berdasarkan PyTorch DenseNet. |
Pemberi Rekomendasi
Jelajahi sampel rekomendasi bawaan ini. Anda dapat mempelajari selengkapnya tentang sampel dengan membuka sampel dan melihat komentar komponen di perancang.
| Contoh judul | Deskripsi |
|---|---|
| Rekomendasi berbasis Luas & Mendalam - Prediksi Peringkat Restoran | Bangun mesin rekomendasi restoran dari fitur dan peringkat restoran/pengguna. |
| Rekomendasi - Tweet Rating Film | Buat mesin pemberi rekomendasi film dari fitur dan peringkat film/pengguna. |
Utilitas
Pelajari selengkapnya tentang sampel yang menunjukkan utilitas dan fitur pembelajaran mesin. Anda dapat mempelajari selengkapnya tentang sampel dengan membuka sampel dan melihat komentar komponen di perancang.
| Contoh judul | Deskripsi |
|---|---|
| Klasifikasi Biner menggunakan Model Wabbit Vowpal - Prediksi Pendapatan Dewasa | Vowpal Wabbit adalah sistem pembelajaran mesin yang mendorong perbatasan pembelajaran mesin dengan teknik seperti online, hashing, allreduce, pengurangan, learning2search, aktif, dan pembelajaran interaktif. Sampel ini menunjukkan cara menggunakan model Vowpal Wabbit untuk membangun model klasifikasi biner. |
| Gunakan skrip R kustom - Prediksi Keterlambatan Penerbangan | Gunakan skrip R khusus untuk memprediksi apakah penerbangan penumpang terjadwal akan tertunda lebih dari 15 menit. |
| Validasi Silang untuk Klasifikasi Biner - Prediksi Pendapatan Dewasa | Gunakan validasi silang guna membangun pengklasifikasi biner untuk penghasilan dewasa. |
| Pentingnya Fitur Permutasi | Gunakan fitur permutasi penting untuk menghitung skor penting untuk himpunan data pengujian. |
| Sesuaikan Parameter untuk Klasifikasi Biner - Prediksi Pendapatan Dewasa | Gunakan Tune Model Hyperparameters untuk menemukan hyperparameter optimal untuk membangun pengklasifikasi biner. |
Himpunan data
Saat Anda membuat alur baru di perancang Azure Machine Learning, sejumlah himpunan data sampel disertakan secara default. Himpunan data sampel ini digunakan oleh alur sampel di beranda p.
Himpunan data sampel tersedia di bawah kategori Himpunan data-Sampel. Anda dapat menemukannya di palet komponen di sebelah kiri kanvas di perancang. Anda dapat menggunakan salah satu himpunan data ini di alur Anda sendiri dengan menyeretnya ke kanvas.
| Nama himpunan data | Deskripsi himpunan data |
|---|---|
| Himpunan data Klasifikasi Biner Pendapatan Sensus Dewasa | Subset himpunan data Sensus 1994, menggunakan orang dewasa yang bekerja di atas usia 16 tahun dengan indeks pendapatan yang disesuaikan > 100. Penggunaan: Mengklasifikasi orang menggunakan demografi untuk memprediksi apakah seseorang mendapat penghasilan lebih dari 50K setahun. Penelitian Terkait: Kohavi, R., Becker, B., (1996). Repositori Pembelajaran Mesin UCI. Irvine, CA: Universitas California, Sekolah Tinggi Informasi dan Ilmu Komputer |
| Data harga mobil (Mentah) | Informasi tentang mobil dengan membuat dan model, termasuk harga, fitur seperti jumlah silinder dan MPG, serta skor risiko asuransi. Skor risiko awalnya dikaitkan dengan harga otomatis. Kemudian, disesuaikan untuk risiko aktual dalam proses yang dikenal sebagai aktuaris sebagai simbol. Nilai +3 menunjukkan bahwa otomatis berisiko, dan nilai -3 berarti mungkin aman. Penggunaan: Memprediksi skor risiko berdasarkan fitur, menggunakan regresi atau klasifikasi multivariat. Penelitian Terkait: Schlimmer, J.C. (1987). Repositori Pembelajaran Mesin UCI. Irvine, CA: Universitas California, Sekolah Tinggi Informasi dan Ilmu Komputer. |
| Label Appetency CRM Dibagikan | Label dari tantangan prediksi hubungan pelanggan KDD Cup 2009 (orange_small_train_appetency.label). |
| Label Churn CRM Dibagikan | Label dari tantangan prediksi hubungan pelanggan KDD Cup 2009 (orange_small_train_churn.labels). |
| Himpunan Data CRM Dibagikan | Data ini berasal dari tantangan prediksi hubungan pelanggan KDD Cup Tahun 2009 (orange_small_train.data.zip). Himpunan data berisi 50K pelanggan dari perusahaan Telekomunikasi Prancis, Orange. Setiap pelanggan memiliki 230 fitur anonim, 190 di antaranya numerik dan 40 kategoris. Fiturnya sangat jarang. |
| Label Penjualan CRM Dibagikan | Label dari tantangan prediksi hubungan pelanggan KDD Cup 2009 (orange_large_train_upselling.labels |
| Data Keterlambatan Penerbangan | Data performa penerbangan penumpang tepat waktu yang diambil dari kumpulan data TranStats dari Departemen Transportasi A.S. (Tepat Waktu). Himpunan data mencakup periode waktu April-Oktober Tahun 2013. Sebelum mengunggah ke perancang, himpunan data diproses sebagai berikut: - Himpunan data difilter untuk hanya mencakup 70 bandara tersibuk di benua AS - Penerbangan yang dibatalkan diberi label sebagai tertunda lebih dari 15 menit - Penerbangan yang dialihkan difilter - Kolom berikut dipilih: Year, Month, DayofMonth, DayOfWeek, Carrier, OriginAirportID, DestAirportID, CRSDepTime, DepDelay, DepDel15, CRSArrTime, ArrDelay, ArrDel15, Canceled |
| Himpunan data UCI Kartu Kredit Jerman | Himpunan data UCI Statlog (Kartu Kredit Jerman) (Statlog+German+Credit+Data), menggunakan file german.data. Himpunan data mengklasifikasikan orang, yang dijelaskan melalui sekumpulan atribut, sebagai risiko kredit rendah atau tinggi. Setiap contoh mewakili seseorang. Ada 20 fitur, baik numerik maupun kategoris, dan label biner (nilai risiko kredit). Entri risiko kredit yang tinggi memiliki label = 2, entri risiko kredit yang rendah memiliki label = 1. Biaya salah mengklasifikasikan contoh risiko rendah setinggi 1, sedangkan biaya salah mengklasifikasikan contoh risiko tinggi serendah 5. |
| Judul Film IMDB | Himpunan data berisi informasi tentang film yang dinilai dalam tweet X: ID film IMDB, nama film, genre, dan tahun produksi. Ada 17 ribu film dalam himpunan data. Himpunan data diperkenalkan dalam makalah “S. Dooms, T. De Pessemier dan L. Martens. MovieTweetings: Himpunan Data Rating Film yang Dikumpulkan Dari Twitter. Lokakarya tentang Crowdsourcing dan Komputasi Manusia untuk Sistem Pemberi Rekomendasi, CrowdRec di RecSys 2013." |
| Peringkat Film | Himpunan data adalah versi tambahan dari himpunan data Movie Tweetings. Himpunan data memiliki peringkat 170K untuk film, yang diekstrak dari tweet terstruktur dengan baik di X. Setiap instans mewakili tweet dan merupakan tuple: ID pengguna, ID film IMDB, peringkat, tanda waktu, jumlah favorit untuk tweet ini, dan jumlah retweet tweet ini. Himpunan data tersedia oleh A. Said, S. Dooms, B. Loni and D. Tikk untuk Recommender Systems Challenge 2014. |
| Himpunan Data Cuaca | Pengamatan cuaca berbasis darat per jam dari NOAA (data gabungan dari 201304 hingga 201310). Data cuaca mencakup pengamatan yang terbuat dari stasiun cuaca bandara, yang mencakup periode April-Oktober 2013. Sebelum mengunggah ke perancang, himpunan data diproses sebagai berikut: - ID stasiun cuaca dipetakan ke ID bandara yang sesuai - Stasiun cuaca yang tidak terkait dengan 70 bandara tersibuk difilter - Kolom Tanggal dibagi menjadi kolom Tahun, Bulan, dan Hari terpisah - Kolom berikut dipilih: AirportID, Year, Month, Day, Time, TimeZone, SkyCondition, Visibility, WeatherType, DryBulbFarenheit, DryBulbCelsius, WetBulbFarenheit, WetBulbCelsius, DewPointFarenheit, DewPointCelsius, RelativeHumidity, WindSpeed, WindDirection, ValueForWindCharacter, StationPressure, PressureTendency, PressureChange, SeaLevelPressure, RecordType, HourlyPrecip, Altimeter |
| Himpunan Data Wikipedia SP 500 | Data berasal dari Wikipedia (https://www.wikipedia.org/) didasarkan pada artikel masing-masing perusahaan S&P 500, disimpan sebagai data XML. Sebelum mengunggah ke perancang, himpunan data diproses sebagai berikut: - Mengekstrak konten teks untuk setiap perusahaan tertentu - Menghapus pemformatan wiki - Menghapus karakter non-alfanumerik - Mengonversi semua teks menjadi huruf kecil - Kategori perusahaan yang diketahui ditambahkan Perhatikan bahwa untuk beberapa perusahaan artikel tidak dapat ditemukan, sehingga jumlah data kurang dari 500. |
| Data Fitur Restoran | Sekumpulan metadata tentang restoran dan fiturnya, seperti jenis makanan, gaya makan, dan lokasi. Penggunaan: Gunakan himpunan data ini, dikombinasikan dengan dua himpunan data restoran lain, untuk melatih dan menguji sistem pemberi rekomendasi. Penelitian Terkait: Bache, K. dan Lichman, M. (2013). Repositori Pembelajaran Mesin UCI. Irvine, CA: Universitas California, Sekolah Tinggi Informasi dan Ilmu Komputer. |
| Peringkat Restoran | Berisi peringkat yang diberikan oleh pengguna ke restoran dalam skala 0 hingga 2. Penggunaan: Gunakan himpunan data ini, dikombinasikan dengan dua himpunan data restoran lain, untuk melatih dan menguji sistem pemberi rekomendasi. Penelitian Terkait: Bache, K. dan Lichman, M. (2013). Repositori Pembelajaran Mesin UCI. Irvine, CA: Universitas California, Sekolah Tinggi Informasi dan Ilmu Komputer. |
| Data Pelanggan Restoran | Serangkaian metadata tentang pelanggan, termasuk demografi dan preferensi. Penggunaan: Gunakan himpunan data ini, dikombinasikan dengan dua himpunan data restoran lain, untuk melatih dan menguji sistem pemberi rekomendasi. Penelitian Terkait: Bache, K. dan Lichman, M. (2013). Repositori Pembelajaran Mesin UCI Irvine, CA: University of California, School of Information dan Computer Science. |
Membersihkan sumber daya
Penting
Anda dapat menggunakan sumber daya yang Anda buat sebagai prasyarat untuk tutorial dan artikel cara penggunaan Azure Machine Learning lainnya.
Menghapus semuanya
Jika Anda tidak berencana menggunakan apa pun yang Anda buat, hapus seluruh grup sumber daya agar Anda tidak ditagih biaya apa pun.
Dari portal Microsoft Azure, pilih Grup sumber daya di sebelah kiri jendela.
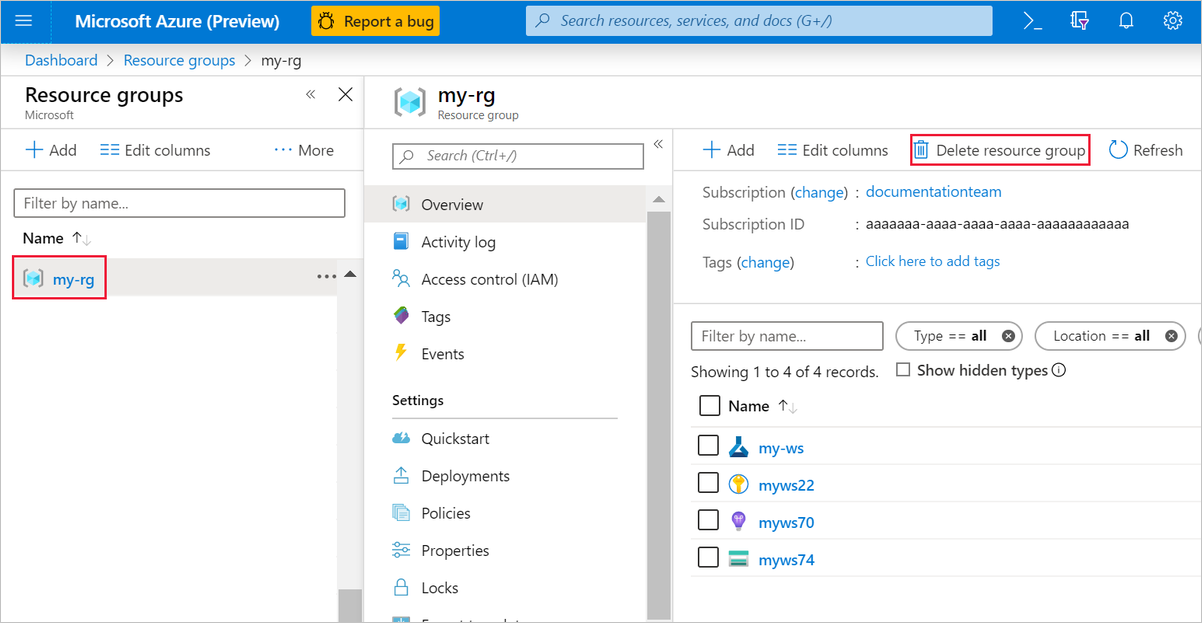
Dalam daftar, pilih grup sumber daya yang Anda buat.
Pilih Hapus grup sumber daya.
Menghapus grup sumber daya juga menghapus semua sumber daya yang Anda buat daam perancang.
Menghapus aset individu
Di perancang tempat Anda membuat eksperimen, hapus aset individu dengan memilihnya, lalu pilih tombol Hapus.
Target komputasi yang Anda buat di sini secara otomatis diskalakan otomatis ke nol node ketika tidak digunakan. Tindakan ini diambil untuk mengurangi biaya. Jika Anda ingin menghapus target komputasi, lakukan langkah-langkah berikut:
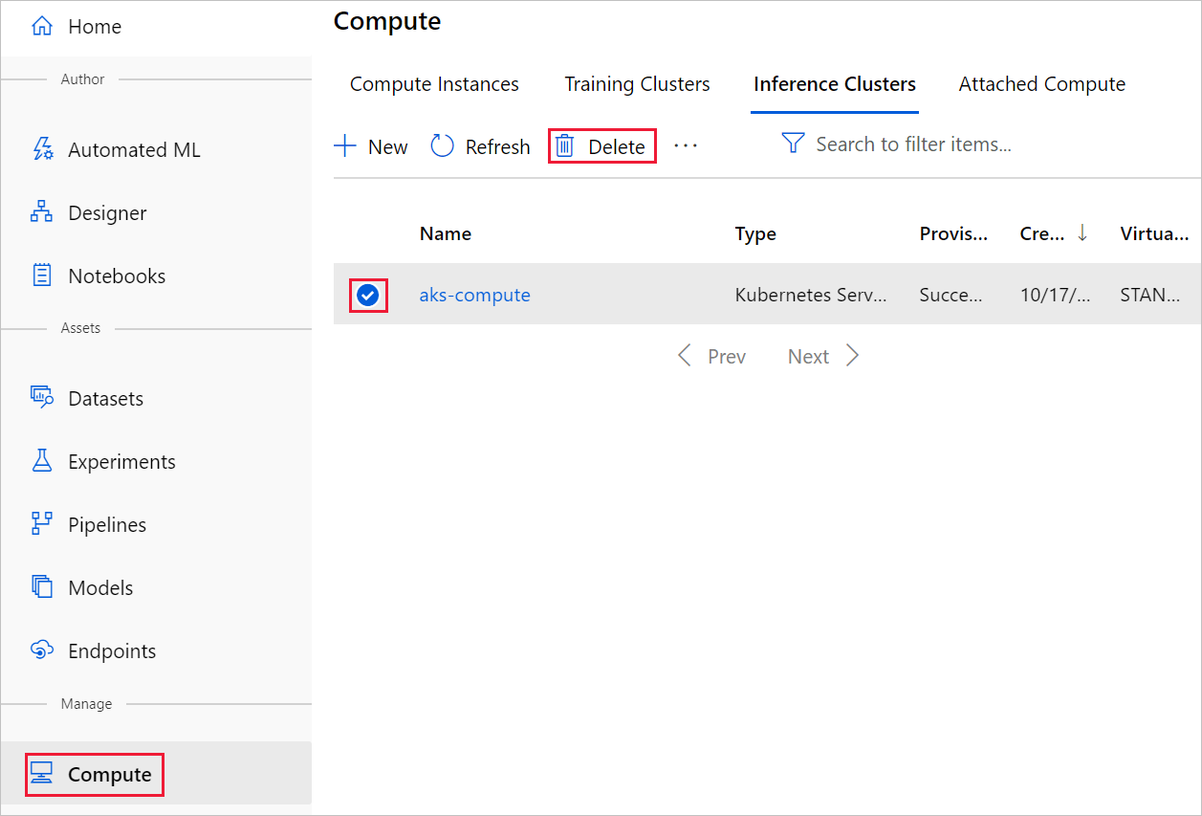
Anda dapat membatalkan pendaftaran himpunan data dari ruang kerja Anda dengan memilih setiap himpunan data dan memilih Batal Pendaftaran.
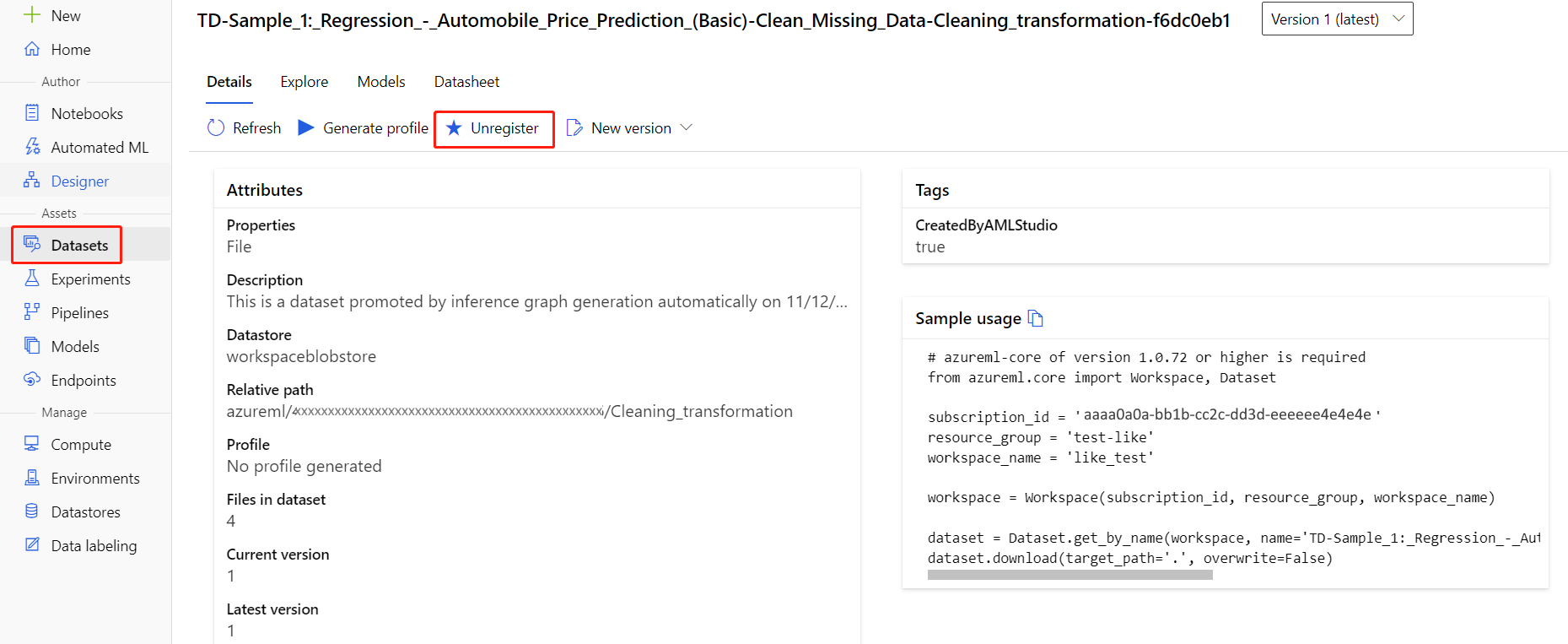
Untuk menghapus himpunan data, buka akun penyimpanan menggunakan portal Microsoft Azure atau Azure Storage Explorer dan hapus aset tersebut secara manual.
Langkah berikutnya
Pelajari dasar-dasar analisis prediktif dan pembelajaran mesin dengan Tutorial: Memprediksi harga mobil dengan perancang