Tutorial: Melatih model pembelajaran mesin pertama Anda (SDK v1, bagian 2 dari 3)
BERLAKU UNTUK: Python SDK azureml v1
Python SDK azureml v1
Tutorial ini menunjukkan kepada Anda cara melatih model pembelajaran mesin di Azure Machine Learning. Tutorial ini adalah bagian 2 dari seri tutorial dua bagian.
Di Bagian 1: Menjalankan "Hello world!" seri ini, Anda telah belajar cara menggunakan skrip kontrol untuk menjalankan pekerjaan di cloud.
Dalam tutorial ini, langkah Anda selanjutnya adalah mengirimkan skrip yang melatih model pembelajaran mesin. Contoh ini membantu Anda memahami bagaimana Azure Pembelajaran Mesin memudahkan perilaku yang konsisten antara penelusuran kesalahan lokal dan eksekusi jarak jauh.
Di tutorial ini, Anda akan:
- Membuat skrip pelatihan.
- Menggunakan Conda untuk menentukan lingkungan Azure Machine Learning.
- Membuat skrip kontrol.
- Memahami kelas Azure Machine Learning (
Environment,Run,Metrics). - Kirim dan jalankan skrip pelatihan Anda.
- Melihat output kode Anda di cloud.
- Mencatat metrik ke Azure Machine Learning.
- Melihat metrik Anda di cloud.
Prasyarat
- Menyelesaikan bagian 1 dari seri ini.
Membuat skrip pelatihan
Pertama Anda mendefinisikan arsitektur jaringan saraf dalam file model.py. Semua kode pelatihan Anda masuk ke subdirektori src , termasuk model.py.
Kode pelatihan diambil dari contoh pengantar ini dari PyTorch. Konsep Azure Pembelajaran Mesin berlaku untuk kode pembelajaran mesin apa pun, bukan hanya PyTorch.
Membuat file model.py dalam subfolder src. Salin kode berikut ke dalam file:
import torch.nn as nn import torch.nn.functional as F class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(3, 6, 5) self.pool = nn.MaxPool2d(2, 2) self.conv2 = nn.Conv2d(6, 16, 5) self.fc1 = nn.Linear(16 * 5 * 5, 120) self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, 10) def forward(self, x): x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = x.view(-1, 16 * 5 * 5) x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.fc3(x) return xPada bilah alat, pilih Simpan untuk menyimpan file. Tutup tab jika Anda menginginkannya.
Selanjutnya, tentukan skrip pelatihan di subfolder src juga. Skrip ini mengunduh himpunan data CIFAR10 dengan menggunakan API
torchvision.datasetPyTorch, menyiapkan jaringan yang didefinisikan dalam model.py, dan melatihnya untuk dua epoch dengan menggunakan SGD standar dan cross-entropy loss.Membuat skrip train.py di subfolder src:
import torch import torch.optim as optim import torchvision import torchvision.transforms as transforms from model import Net # download CIFAR 10 data trainset = torchvision.datasets.CIFAR10( root="../data", train=True, download=True, transform=torchvision.transforms.ToTensor(), ) trainloader = torch.utils.data.DataLoader( trainset, batch_size=4, shuffle=True, num_workers=2 ) if __name__ == "__main__": # define convolutional network net = Net() # set up pytorch loss / optimizer criterion = torch.nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) # train the network for epoch in range(2): running_loss = 0.0 for i, data in enumerate(trainloader, 0): # unpack the data inputs, labels = data # zero the parameter gradients optimizer.zero_grad() # forward + backward + optimize outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # print statistics running_loss += loss.item() if i % 2000 == 1999: loss = running_loss / 2000 print(f"epoch={epoch + 1}, batch={i + 1:5}: loss {loss:.2f}") running_loss = 0.0 print("Finished Training")Anda sekarang memiliki struktur folder berikut:

Menguji secara lokal
Pilih Simpan dan jalankan skrip di terminal untuk menjalankan skrip train.py langsung pada instans komputasi.
Setelah skrip selesai, pilih Refresh di atas folder file. Anda melihat folder data baru yang disebut memulai/data Perluas folder ini untuk melihat data yang diunduh.

Membuat lingkungan Python
Azure Machine Learning menyediakan konsep lingkungan untuk mewakili lingkungan versi Python yang dapat direproduksi untuk menjalankan eksperimen. Anda juga dapat membuat lingkungan dari Conda lokal atau lingkungan pip.
Pertama, Anda membuat file dengan dependensi paket.
Buat file Python baru di folder memulai bernama
pytorch-env.yml:name: pytorch-env channels: - defaults - pytorch dependencies: - python=3.7 - pytorch - torchvisionPada bilah alat, pilih Simpan untuk menyimpan file. Tutup tab jika Anda menginginkannya.
Membuat skrip kontrol
Perbedaan antara skrip kontrol berikut dan yang biasa Anda gunakan untuk mengirimkan "Hello world!" terletak pada penambahan beberapa baris tambahan untuk mengatur lingkungan.
Buat file Python baru di folder memulai bernama run-pytorch.py:
# run-pytorch.py
from azureml.core import Workspace
from azureml.core import Experiment
from azureml.core import Environment
from azureml.core import ScriptRunConfig
if __name__ == "__main__":
ws = Workspace.from_config()
experiment = Experiment(workspace=ws, name='day1-experiment-train')
config = ScriptRunConfig(source_directory='./src',
script='train.py',
compute_target='cpu-cluster')
# set up pytorch environment
env = Environment.from_conda_specification(
name='pytorch-env',
file_path='pytorch-env.yml'
)
config.run_config.environment = env
run = experiment.submit(config)
aml_url = run.get_portal_url()
print(aml_url)
Tip
Jika Anda menggunakan nama yang berbeda saat membuat kluster komputasi, pastikan untuk menyesuaikan nama dalam kode compute_target='cpu-cluster' juga.
Memahami perubahan kode
env = ...
Rujuk file dependensi yang telah Anda buat di atas.
config.run_config.environment = env
Menambahkan lingkungan ke ScriptRunConfig.
Mengirimkan eksekusi ke Azure Pembelajaran Mesin
Pilih Simpan dan jalankan skrip di terminal untuk menjalankan skrip run-pytorch.py.
Anda melihat tautan di jendela terminal yang terbuka. Pilih tautan untuk melihat pekerjaan.
Catatan
Anda mungkin melihat beberapa peringatan yang dimulai dengan Kegagalan saat memuat azureml_run_type_providers.... Anda dapat mengabaikan peringatan ini. Gunakan tautan di bagian bawah peringatan ini untuk melihat output Anda.
Melihat output
- Di halaman yang terbuka, Anda akan melihat status pekerjaan. Pertama kali Anda menjalankan skrip ini, Azure Pembelajaran Mesin membangun gambar Docker baru dari lingkungan PyTorch Anda. Seluruh pekerjaan mungkin memakan waktu sekitar 10 menit untuk diselesaikan. Gambar ini akan digunakan kembali dalam pekerjaan selanjutnya untuk membuat proses berjalan jauh lebih cepat.
- Anda dapat melihat log build Docker di studio Azure Machine Learning. untuk melihat log build:
- Pilih tab Output + log.
- Pilih folder azureml-logs .
- Pilih 20_image_build_log.txt.
- Saat status pekerjaan Selesai, pilih Output + log.
- Pilih user_logs, lalu std_log.txt untuk melihat output pekerjaan Anda.
Downloading https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to ../data/cifar-10-python.tar.gz
Extracting ../data/cifar-10-python.tar.gz to ../data
epoch=1, batch= 2000: loss 2.19
epoch=1, batch= 4000: loss 1.82
epoch=1, batch= 6000: loss 1.66
...
epoch=2, batch= 8000: loss 1.51
epoch=2, batch=10000: loss 1.49
epoch=2, batch=12000: loss 1.46
Finished Training
Jika Anda melihat kesalahan Your total snapshot size exceeds the limit, folder data terletak di nilai source_directory yang digunakan dalam ScriptRunConfig.
Pilih ... di akhir folder, lalu pilih Pindahkan untuk memindahkan data ke folder memulai.
Mencatat metrik pelatihan
Sekarang Setelah Anda memiliki pelatihan model di Azure Machine Learning, mulai lacak beberapa metrik performa.
Skrip pelatihan saat ini mencetak metrik ke terminal. Azure Machine Learning menyediakan mekanisme untuk mencatat metrik dengan fungsionalitas yang lebih banyak. Dengan menambahkan beberapa baris kode, Anda mendapatkan kemampuan untuk mengontrol metrik di studio dan membandingkan metrik di antara beberapa pekerjaan.
Mengubah train.py untuk menyertakan pembuatan log
Ubah skrip train.py Anda untuk menyertakan dua baris kode lagi:
import torch import torch.optim as optim import torchvision import torchvision.transforms as transforms from model import Net from azureml.core import Run # ADDITIONAL CODE: get run from the current context run = Run.get_context() # download CIFAR 10 data trainset = torchvision.datasets.CIFAR10( root='./data', train=True, download=True, transform=torchvision.transforms.ToTensor() ) trainloader = torch.utils.data.DataLoader( trainset, batch_size=4, shuffle=True, num_workers=2 ) if __name__ == "__main__": # define convolutional network net = Net() # set up pytorch loss / optimizer criterion = torch.nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) # train the network for epoch in range(2): running_loss = 0.0 for i, data in enumerate(trainloader, 0): # unpack the data inputs, labels = data # zero the parameter gradients optimizer.zero_grad() # forward + backward + optimize outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # print statistics running_loss += loss.item() if i % 2000 == 1999: loss = running_loss / 2000 # ADDITIONAL CODE: log loss metric to AML run.log('loss', loss) print(f'epoch={epoch + 1}, batch={i + 1:5}: loss {loss:.2f}') running_loss = 0.0 print('Finished Training')Simpan file ini, lalu tutup tab jika anda menginginkannya.
Memahami dua baris kode tambahan
Dalam train.py, Anda mengakses objek eksekusi dari dalam skrip pelatihan itu sendiri menggunakan metode Run.get_context() dan menggunakannya untuk mencatat metrik:
# ADDITIONAL CODE: get run from the current context
run = Run.get_context()
...
# ADDITIONAL CODE: log loss metric to AML
run.log('loss', loss)
Metrik dalam Azure Machine Learning:
- Diatur berdasarkan eksperimen dan eksekusi, sehingga mudah untuk melacak dan membandingkan metrik.
- Dilengkapi dengan UI, sehingga Anda dapat memvisualisasikan performa pelatihan di studio.
- Dirancang untuk menskalakan, sehingga manfaat ini tetap ada bahkan saat Anda menjalankan ratusan eksperimen.
Memperbarui file lingkungan Conda
Skrip train.py baru saja mengambil dependensi baru pada azureml.core. Perbarui pytorch-env.yml untuk menerapkan perubahan ini:
name: pytorch-env
channels:
- defaults
- pytorch
dependencies:
- python=3.7
- pytorch
- torchvision
- pip
- pip:
- azureml-sdk
Pastikan bahwa Anda menyimpan file ini sebelum mengirimkan eksekusi.
Mengirimkan eksekusi ke Azure Pembelajaran Mesin
Pilih tab untuk skrip run-pytorch.py , lalu pilih Simpan dan jalankan skrip di terminal untuk menjalankan ulang skrip run-pytorch.py . Pastikan Anda menyimpan perubahan terlebih pytorch-env.yml dahulu.
Ketika mengunjungi studio, sekarang Anda dapat membuka tab Metrik dan melihat pembaruan langsung tentang kehilangan pelatihan model! Mungkin perlu waktu 1 hingga 2 menit sebelum proses pelatihan dimulai.

Membersihkan sumber daya
Jika Anda berencana untuk melanjutkan sekarang ke tutorial lain, atau untuk memulai pekerjaan pelatihan Anda sendiri, lewati ke Sumber daya terkait.
Menghentikan instans komputasi
Jika Anda tidak akan menggunakannya sekarang, hentikan instans komputasi:
- Di studio, di sebelah kiri, pilih Komputasi.
- Di tab atas, pilih Instans komputasi
- Pilih instans komputasi dalam daftar.
- Di toolbar atas, pilih Hentikan.
Menghapus semua sumber daya
Penting
Sumber daya yang Anda buat sebagai prasyarat untuk tutorial dan artikel cara penggunaan Azure Machine Learning lainnya.
Jika Anda tidak berencana menggunakan sumber daya yang sudah Anda buat, hapus sehingga Anda tidak dikenakan biaya apa pun:
Di portal Azure, di kotak pencarian, masukkan Grup sumber daya dan pilih dari hasil.
Dari daftar, pilih grup sumber daya yang Anda buat.
Di halaman Gambaran Umum , pilih Hapus grup sumber daya.
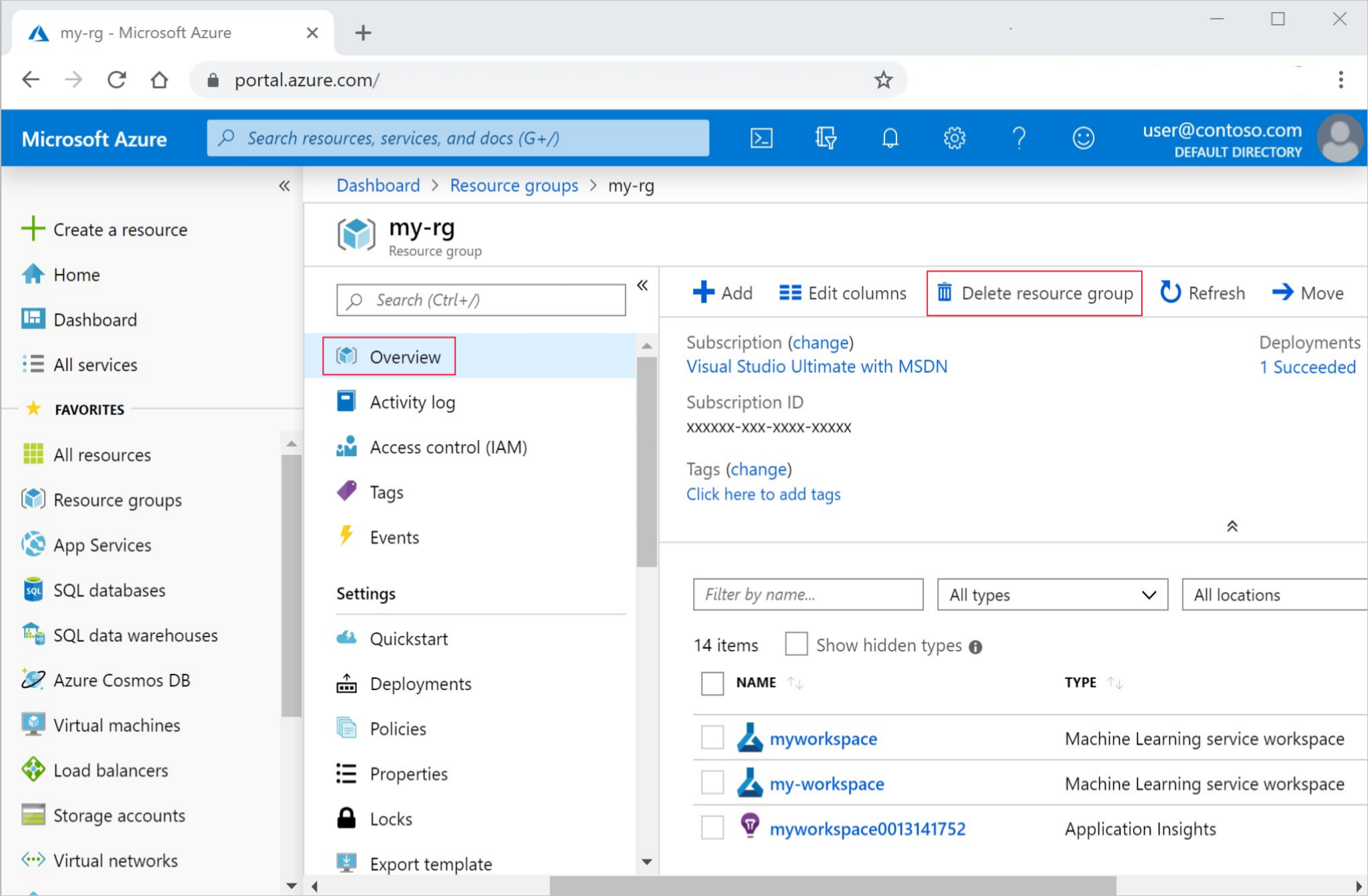
Masukkan nama grup sumber daya. Kemudian pilih Hapus.
Anda juga dapat menyimpan grup sumber daya tetapi menghapus satu ruang kerja. Tampilkan properti ruang kerja dan pilih Hapus.
Sumber daya terkait
Dalam sesi ini, Anda telah naik tingkat dari skrip dasar "Hello world!" ke skrip pelatihan yang lebih realistis yang membutuhkan lingkungan Python tertentu untuk dijalankan. Anda melihat cara menggunakan lingkungan Azure Machine Learning yang dikuratori. Terakhir, Anda telah mempelajari cara menggunakan beberapa baris kode untuk mencatat metrik ke Azure Machine Learning.
Ada cara lain untuk membuat lingkungan Azure Machine Learning, termasuk dari file pip requirements.txt atau dari lingkungan Conda lokal yang ada.