Tutorial: Melatih model klasifikasi dengan AutoML tanpa kode di studio Azure Machine Learning
Pelajari cara melatih model klasifikasi dengan AutoML tanpa kode menggunakan ML otomatis Azure Machine Learning di studio Azure Machine Learning. Model klasifikasi ini memprediksi apakah klien akan berlangganan deposito berjangka tetap dengan lembaga keuangan.
Dengan ML otomatis, Anda dapat mengotomatiskan tugas-tugas yang memakan banyak waktu. Pembelajaran mesin otomatis dengan cepat mengulangi banyak kombinasi algoritme dan hiperparameter untuk membantu Anda menemukan model terbaik berdasarkan metrik keberhasilan yang Anda pilih.
Anda tidak akan menulis kode apa pun dalam tutorial ini, Anda akan menggunakan antarmuka studio untuk melakukan pelatihan. Anda akan mempelajari cara melakukan tugas berikut:
- Buat ruang kerja Azure Machine Learning.
- Jalankan eksperimen pembelajaran mesin otomatis.
- Jelajahi detail model.
- Sebarkan model yang direkomendasikan.
Coba juga pembelajaran mesin otomatis untuk jenis model lain berikut:
- Untuk contoh perkiraan tanpa kode, lihat Tutorial: Perkiraan permintaan & AutoML.
- Untuk contoh kode pertama model deteksi objek, lihat Tutorial: Melatih model deteksi objek dengan AutoML dan Python,
Prasyarat
Langganan Azure. Jika Anda tidak memiliki langganan Azure, buat akun gratis.
Unduh file data bankmarketing_train.csv. Kolom y menunjukkan jika pelanggan berlangganan deposito berjangka tetap, yang kemudian diidentifikasi sebagai kolom target untuk prediksi dalam tutorial ini.
Membuat ruang kerja
Ruang kerja Azure Machine Learning adalah sumber daya dasar di cloud yang Anda gunakan untuk melakukan eksperimen, melatih, dan menyebarkan model pembelajaran mesin. Hal ini mengikat langganan Azure dan grup sumber daya Anda dengan objek yang mudah dikonsumsi dalam layanan.
Dalam tutorial ini, selesaikan langkah-langkah berikut untuk membuat ruang kerja dan melanjutkan tutorial.
Masuk ke Studio Azure Machine Learning
Pilih Buat ruang kerja
Berikan informasi berikut untuk mengonfigurasi ruang kerja baru Anda:
| Bidang | Deskripsi |
|---|---|
| Nama ruang kerja | Masukkan nama unik yang mengidentifikasi ruang kerja Anda. Tidak boleh ada ruang kerja dengan nama yang sama di seluruh grup sumber daya. Gunakan nama yang mudah ingat dan berbeda dengan ruang kerja yang dibuat oleh orang lain. Nama ruang kerja tidak peka huruf besar/kecil. |
| Langganan | Pilih langganan Azure yang ingin Anda gunakan. |
| Grup sumber daya | Gunakan grup sumber daya yang sudah ada di langganan Anda atau masukkan nama untuk membuat grup sumber daya baru. Grup sumber daya menyimpan sumber daya terkait untuk solusi Azure. Anda memerlukan peran kontributor atau pemilik untuk menggunakan grup sumber daya yang ada. Untuk informasi selengkapnya tentang akses, lihat Mengelola akses ke ruang kerja Azure Machine Learning. |
| Wilayah | Pilih wilayah Azure terdekat dengan pengguna dan sumber daya data untuk membuat ruang kerja Anda. |
- Pilih Buat untuk membuat ruang kerja
Untuk informasi selengkapnya tentang sumber daya Azure, lihat langkah-langkah dalam artikel ini, Buat sumber daya yang Anda perlukan untuk memulai.
Untuk cara lain membuat ruang kerja di Azure, Kelola ruang kerja Azure Pembelajaran Mesin di portal atau dengan Python SDK (v2).
Membuat pekerjaan Pembelajaran Mesin Otomatis
Anda menyelesaikan penyiapan eksperimen berikut dan menjalankan langkah-langkah melalui studio Azure Machine Learning di https://ml.azure.com, antarmuka web gabungan yang mencakup alat pembelajaran mesin untuk melakukan skenario ilmu data bagi praktisi ilmu data dari semua tingkat keahlian. Studio pada browser Internet Explorer tidak didukung.
Pilih langganan dan ruang kerja yang Anda buat.
Di panel kiri, pilih ML Otomatis di bawah bagian Penulisan .
Karena ini adalah eksperimen ML otomatis pertama Anda, Anda akan melihat daftar kosong dan tautan ke dokumentasi.
Pilih +Pekerjaan ML otomatis baru.
Membuat dan memuat himpunan data sebagai aset data
Sebelum mengonfigurasi eksperimen, unggah file data ke ruang kerja Anda dalam bentuk aset data Azure Pembelajaran Mesin. Dalam kasus tutorial ini, Anda dapat menganggap aset data sebagai himpunan data Anda untuk pekerjaan AutoML. Dengan demikian, Anda dapat memastikan bahwa data untuk eksperimen diformat dengan benar.
Buat aset data baru dengan memilih Dari file lokal dari menu drop-down +Buat aset data.
Pada formulir Info dasar, beri nama aset data Anda dan berikan deskripsi opsional. Antarmuka ML otomatis saat ini hanya mendukung TabularDatasets, sehingga jenis himpunan data harus ditetapkan ke Tabular secara default.
Pilih Berikutnya di bagian kiri bawah
Pada formulir Pemilihan datastore dan file, pilih datastore default yang secara otomatis disiapkan selama pembuatan ruang kerja Anda, workspaceblobstore (Azure Blob Storage). Di sinilah Anda akan mengunggah file data untuk membuatnya tersedia di ruang kerja Anda.
Pilih Unggah file dari drop-down Unggah.
Pilih file bankmarketing_train.csv pada komputer lokal Anda. Ini adalah file yang Anda unduh sebagai prasyarat.
Pilih Berikutnya di kiri bawah, untuk mengunggahnya ke kontainer default yang secara otomatis disiapkan selama pembuatan ruang kerja Anda.
Setelah pengunggahan selesai, formulir Pengaturan dan pratinjau telah diisi sebelumnya berdasarkan jenis file.
Verifikasi bahwa data Anda diformat dengan benar melalui formulir Skema . Data harus diisi sebagai berikut. Setelah Anda memverifikasi bahwa data akurat, pilih Berikutnya.
Bidang Deskripsi Nilai untuk tutorial Format file Menentukan tata letak dan jenis data yang disimpan dalam sebuah file. Berbatas Pemisah Satu atau beberapa karakter untuk menentukan batas antara, wilayah independen yang terpisah dalam teks biasa atau aliran data lainnya. Koma Pengodean Mengidentifikasi bit ke tabel skema karakter apa yang akan digunakan untuk membaca himpunan data Anda. UTF-8 Header kolom Menunjukkan bagaimana header himpunan data, jika ada, akan diperlakukan. Semua file memiliki header yang sama Lewati baris Menunjukkan berapa banyak, jika ada, baris yang dilewati dalam himpunan data. Tidak Formulir Skema memungkinkan konfigurasi data Anda lebih lanjut untuk eksperimen ini. Untuk contoh ini, pilih sakelar pengalih untuk day_of_week, agar tidak menyertakannya. Pilih Selanjutnya.
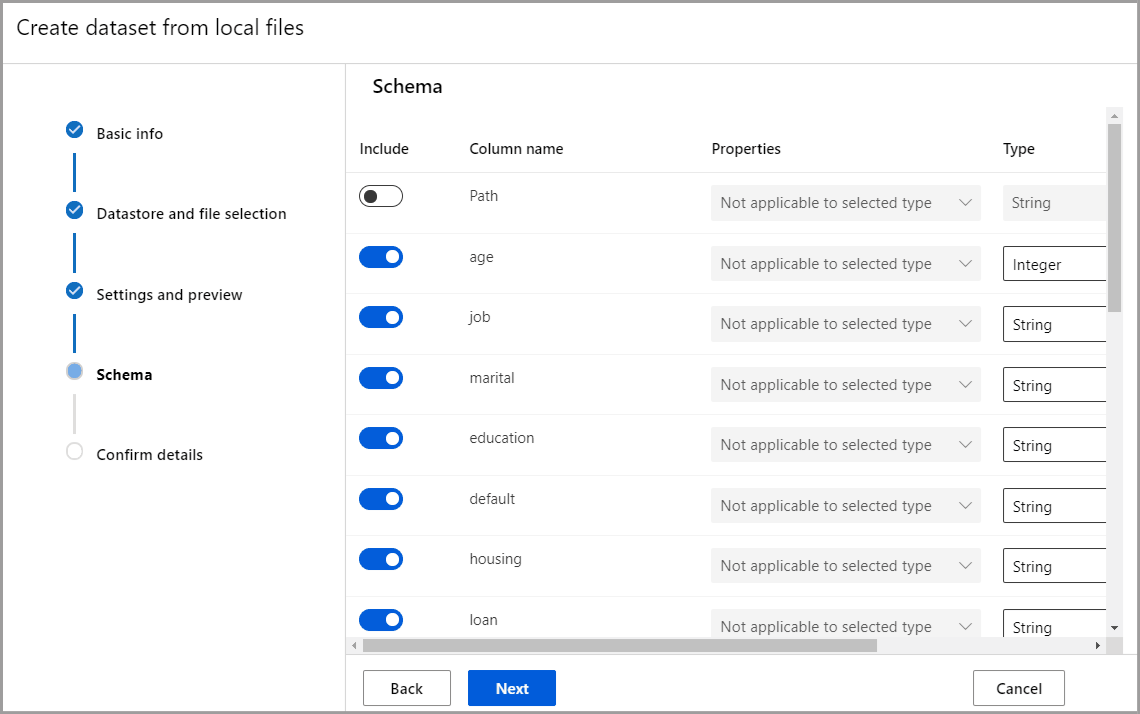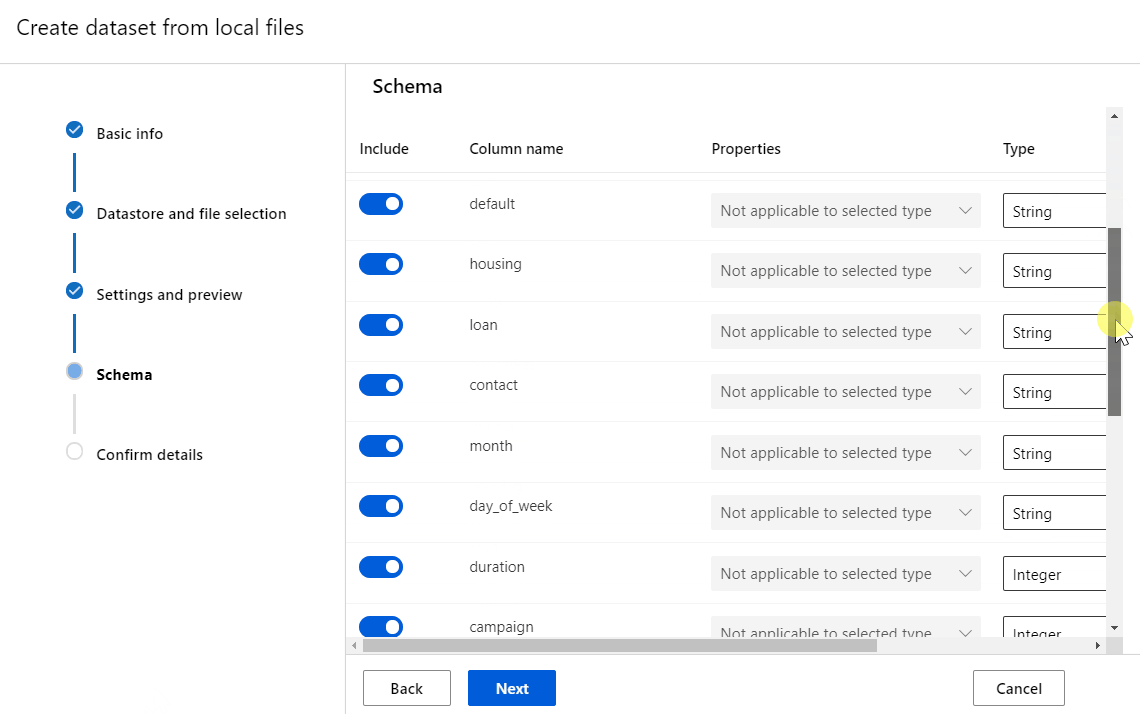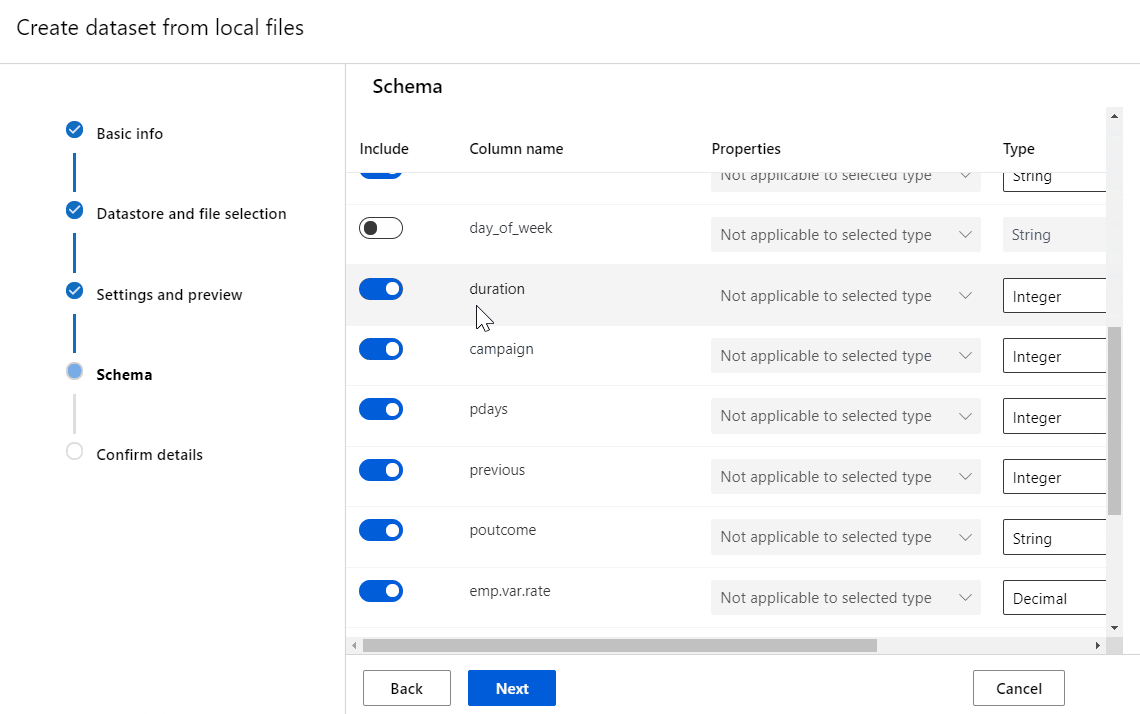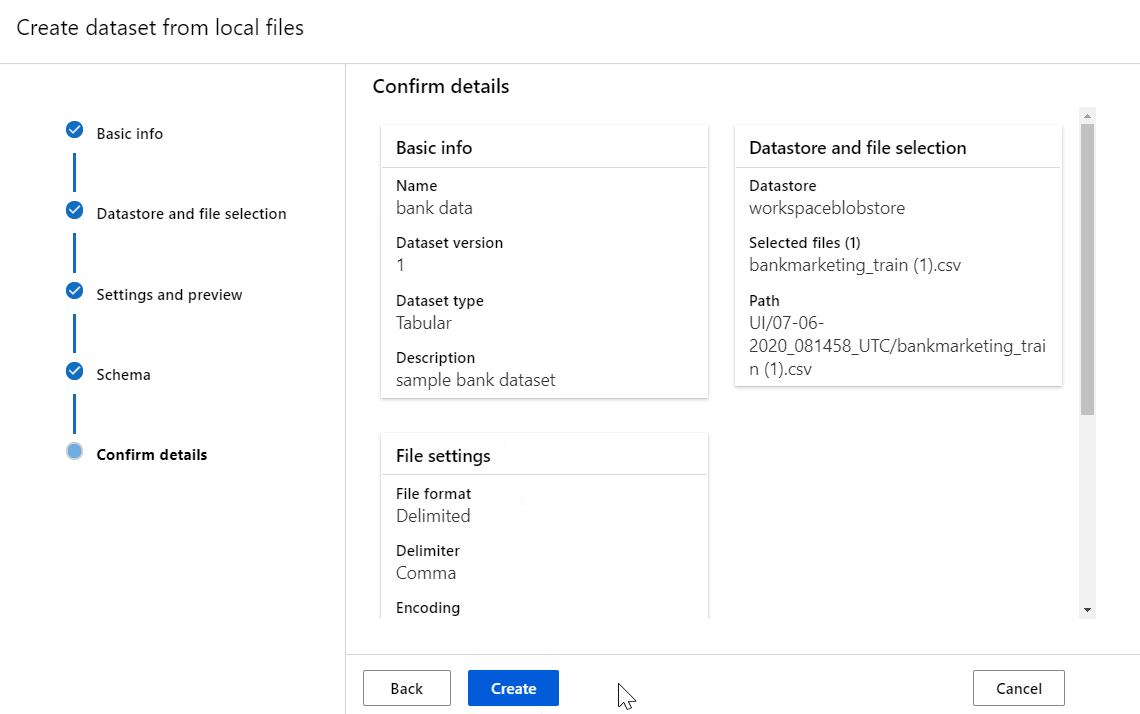
Pada formulir Konfirmasi detail, pastikan bahwa informasi cocok dengan apa yang sebelumnya diisi pada formulir Info dasar, pemilihan Penyimpanan Data dan file serta Pengaturan dan pratinjau.
Pilih Buat untuk menyelesaikan pembuatan himpunan data Anda.
Pilih himpunan data Anda setelah muncul dalam daftar.
Tinjau data dengan memilih aset data dan lihat tab pratinjau yang terisi untuk memastikan Anda tidak menyertakan day_of_week, lalu pilih Tutup.
Pilih Selanjutnya.
Mengonfigurasi pekerjaan
Setelah memuat dan mengonfigurasi data, Anda dapat menyiapkan eksperimen. Penyetelan ini mencakup tugas desain eksperimen seperti, memilih ukuran lingkungan komputasi Anda dan menentukan kolom apa yang ingin Anda prediksi.
Pilih tombol radioBuat baru.
Isi formulir Konfigurasikan Pekerjaan sebagai berikut:
Masukkan nama eksperimen ini:
my-1st-automl-experimentPilih y sebagai kolom target yang ingin Anda prediksi. Kolom ini menunjukkan apakah klien berlangganan deposito berjangka atau tidak.
Pilih kluster komputasi sebagai jenis komputasi Anda.
Target komputasi adalah lingkungan sumber daya lokal atau berbasis cloud yang digunakan untuk menjalankan skrip pelatihan Anda atau menghosting penyebaran layanan Anda. Untuk eksperimen ini, Anda dapat mencoba komputasi tanpa server berbasis cloud (pratinjau) atau membuat komputasi berbasis cloud Anda sendiri.
- Untuk menggunakan komputasi tanpa server, aktifkan fitur pratinjau, pilih Tanpa Server, dan lewati sisa langkah ini.
- Untuk membuat target komputasi Anda sendiri, pilih +Baru untuk mengonfigurasi target komputasi Anda.
Isi formulir Pilih mesin virtual untuk menyiapkan komputer Anda.
Bidang Deskripsi Nilai untuk tutorial Lokasi Wilayah tempat Anda ingin menjalankan mesin US Barat 2 Tingkat mesin virtual Pilih prioritas yang harus dimiliki eksperimen Anda Khusus Jenis komputer virtual Pilih jenis komputer virtual untuk komputasi Anda. CPU (Unit Pemrosesan Pusat) Ukuran komputer virtual Pilih jenis komputer virtual untuk komputasi Anda. Daftar ukuran yang direkomendasikan diberikan berdasarkan data dan jenis eksperimen Anda. Standard_DS12_V2 Pilih Berikutnya untuk mengisi formulir Konfigurasi pengaturan.
Bidang Deskripsi Nilai untuk tutorial Nama komputasi Nama unik yang mengidentifikasi konteks komputasi Anda. automl-compute Node Min/Maks Untuk data profil, Anda harus menetapkan 1 atau beberapa Simpul. Node minimal: 1
Node maksimal: 6Detik siaga menurunkan skala Waktu siaga sebelum kluster secara otomatis diturunkan skalanya ke jumlah node minimum. 120 (default) Pengaturan tingkat lanjut Pengaturan untuk mengonfigurasi dan mengotorisasi jaringan virtual untuk eksperimen Anda. Tidak Pilih Buat untuk membuat target komputasi Anda.
Perlu beberapa menit untuk menyelesaikan.
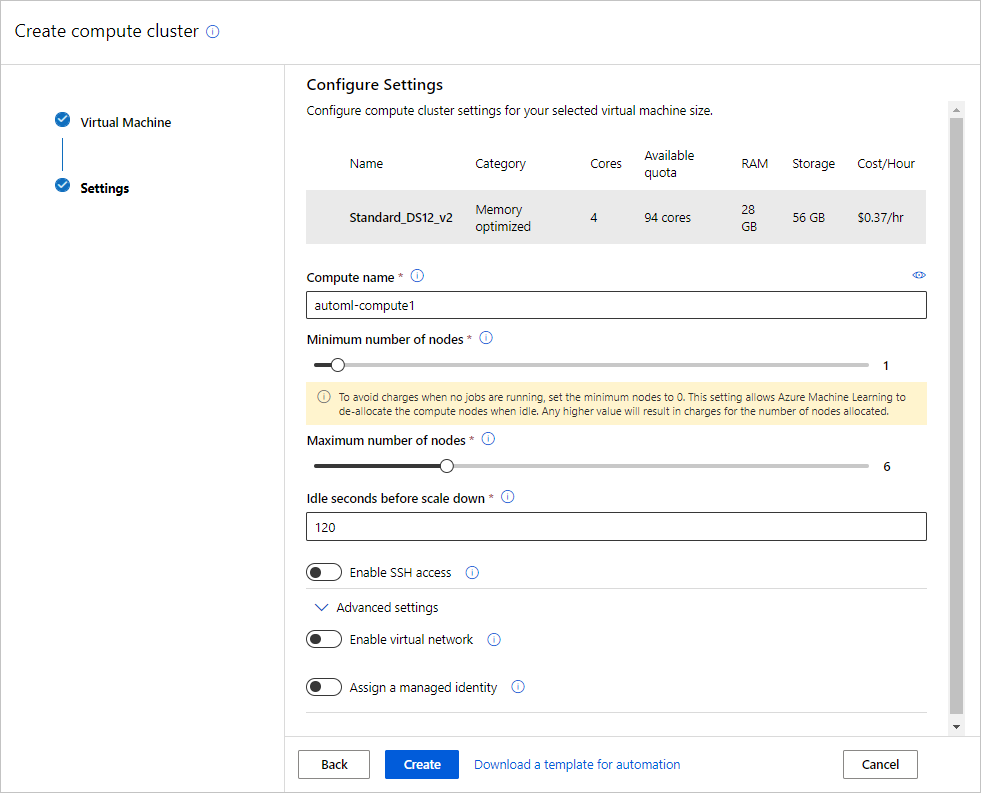
Setelah pembuatan, pilih target komputasi baru Anda dari menu drop-down.
Pilih Selanjutnya.
Pada formulir Pilih tugas dan setelan, selesaikan penyiapan untuk eksperimen ML otomatis Anda dengan menentukan jenis tugas pembelajaran mesin dan pengaturan konfigurasi.
Pilih Klasifikasi sebagai jenis tugas pembelajaran mesin.
Pilih Tampilkan pengaturan konfigurasi tambahan dan isi bidang sebagai berikut. Pengaturan ini untuk mengontrol pekerjaan pelatihan dengan lebih baik. Jika tidak, pengaturan default diterapkan berdasarkan pilihan eksperimen dan data.
Konfigurasi tambahan Deskripsi Nilai untuk tutorial Metrik utama Metrik evaluasi yang akan diukur oleh algoritma pembelajaran mesin. AUC_weighted Menjelaskan model terbaik Secara otomatis menunjukkan kemampuan menjelaskan pada model terbaik yang dibuat oleh Pembelajaran Mesin otomatis. Aktifkan Algoritma yang diblokir Algoritma yang ingin Anda kecualikan dari pekerjaan pelatihan Tidak Pengaturan klasifikasi tambahan Pengaturan ini membantu meningkatkan akurasi model Anda Label kelas positif: Tidak ada Kriteria keluar Jika kriteria terpenuhi, pekerjaan pelatihan dihentikan. Waktu pekerjaan pelatihan (jam): 1
Ambang nilai metrik: Tidak adaKonkurensi Jumlah maksimum iterasi paralel yang dijalankan per iterasi Iterasi bersamaan maksimum: 5 Pilih Simpan.
Pilih Selanjutnya.
Pada formulir [Opsional] Validasi dan uji,
- Pilih validasi silang k-fold sebagai Jenis validasi Anda.
- Pilih 2 sebagai Jumlah validasi silang Anda.
Pilih Selesai untuk menjalankan eksperimen. Layar Detail Pekerjaan terbuka dengan Status pekerjaan di bagian atas saat persiapan eksperimen dimulai. Status ini diperbarui saat eksperimen berlangsung. Pemberitahuan juga muncul di sudut kanan atas studio, untuk memberi tahu mengenai status eksperimen Anda.
Penting
Persiapan membutuhkan waktu 10-15 menit untuk mempersiapkan eksekusi eksperimen.
Setelah dijalankan, hal ini membutuhkan waktu 2-3 menit lebih lama untuk masing-masing iterasi.
Selama proses produksi, Anda mungkin akan menunggu sebentar. Tetapi untuk tutorial ini, sebaiknya Anda mulai menjelajahi algoritma yang diuji pada tab Model setelah selesai, sementara yang lain masih berjalan.
Menjelajahi model
Arahkan ke tab Model untuk melihat algoritma (model) yang diuji. Secara default, model diurutkan berdasarkan skor metrik saat selesai. Untuk tutorial ini, model yang mendapat skor tertinggi berdasarkan metrik AUC_weighted yang dipilih berada di bagian atas daftar.
Sambil menunggu semua model eksperimen selesai, pilih Nama algoritma model yang sudah selesai guna mengeksplorasi detail performanya.
Contoh berikut mengarahkan melalui tab Detail dan Metrik untuk melihat properti, metrik, dan bagan performa model yang dipilih.
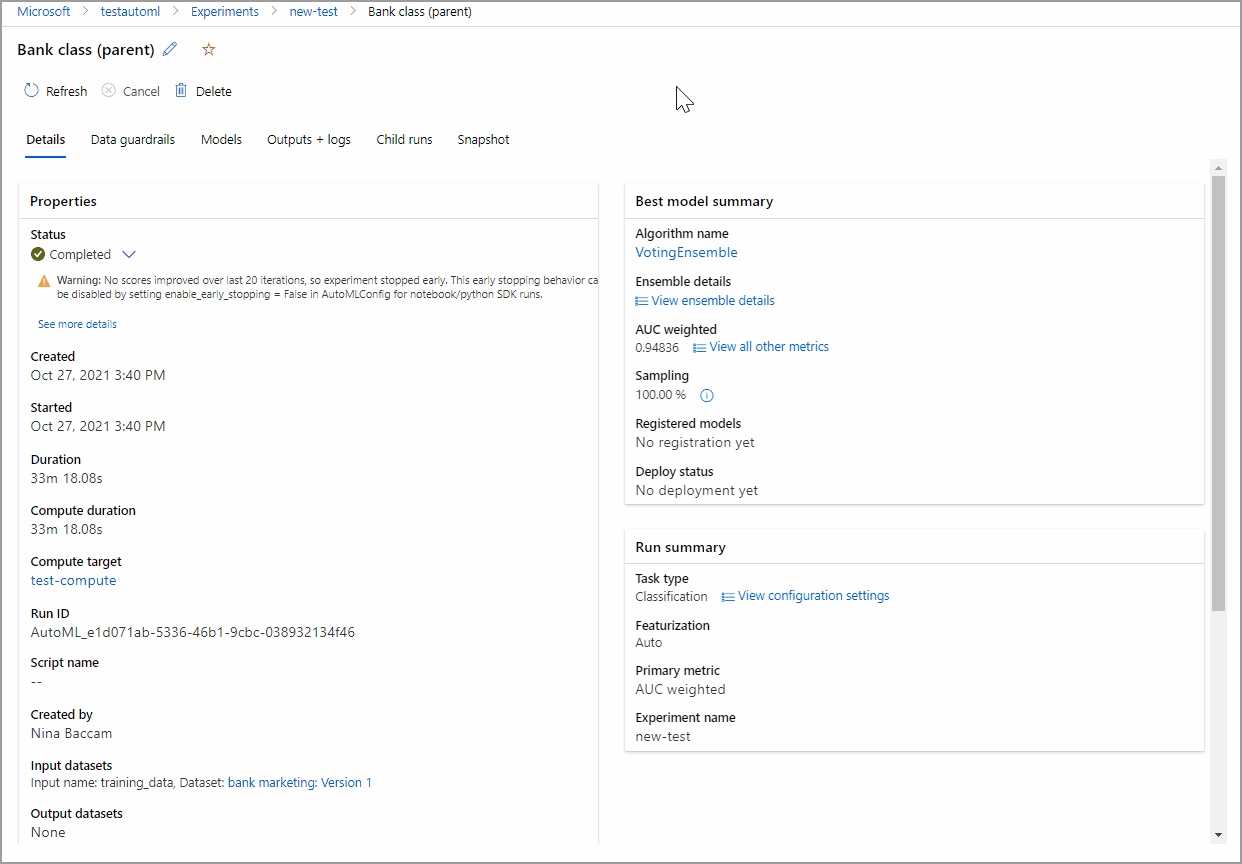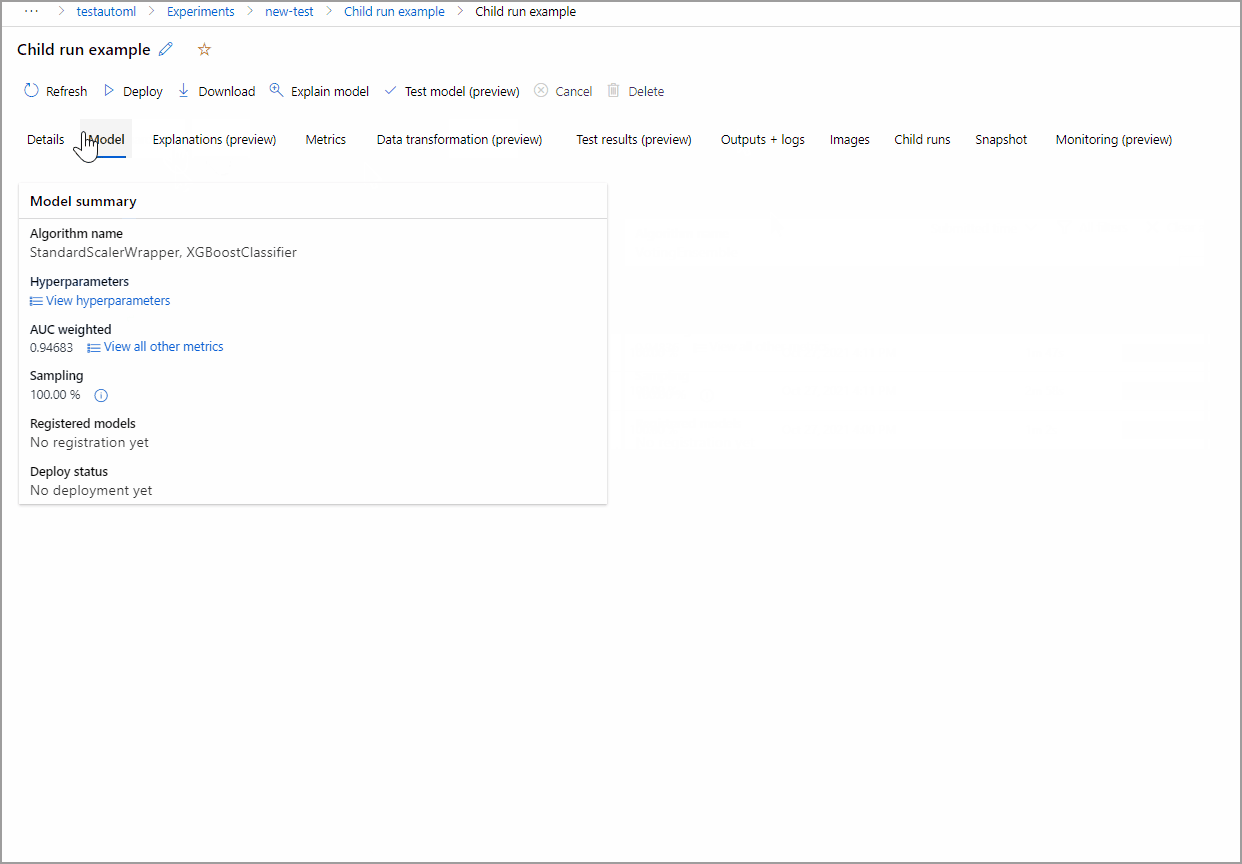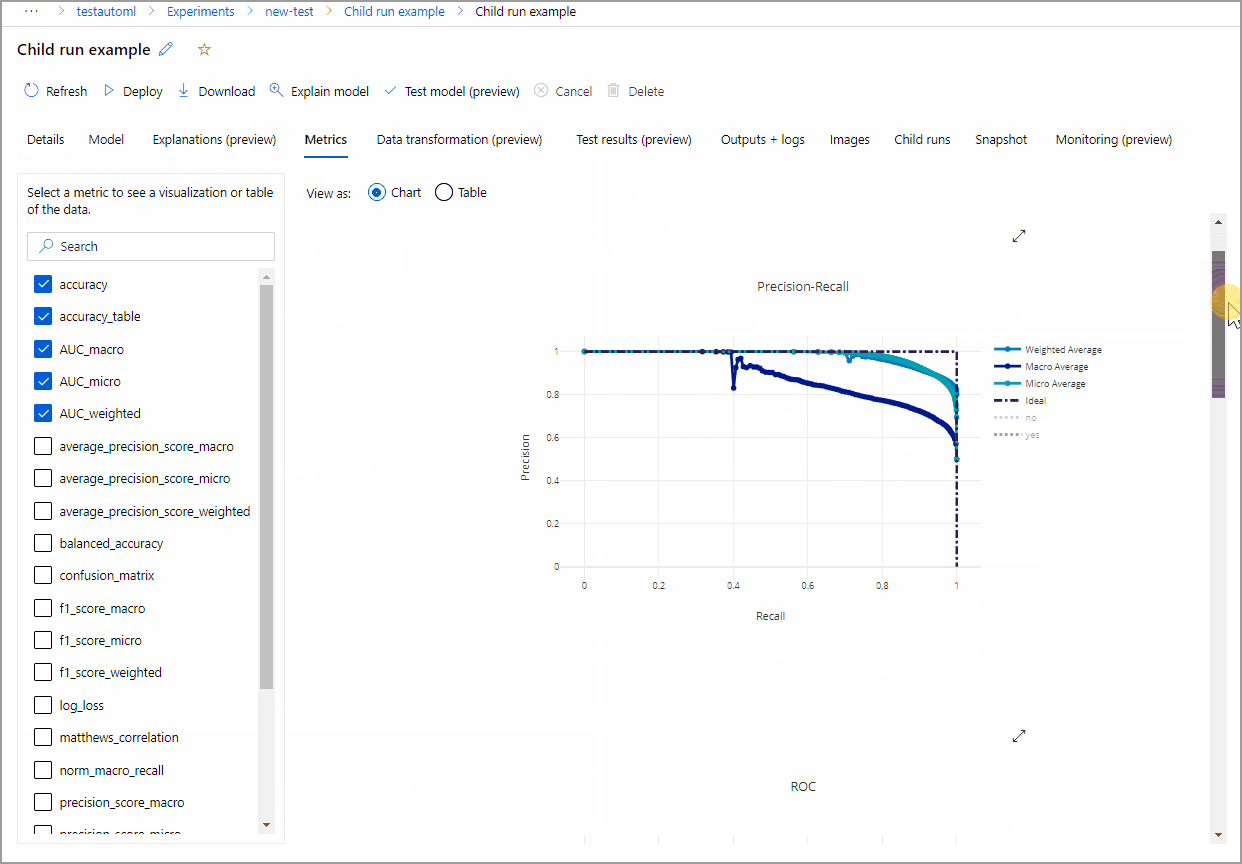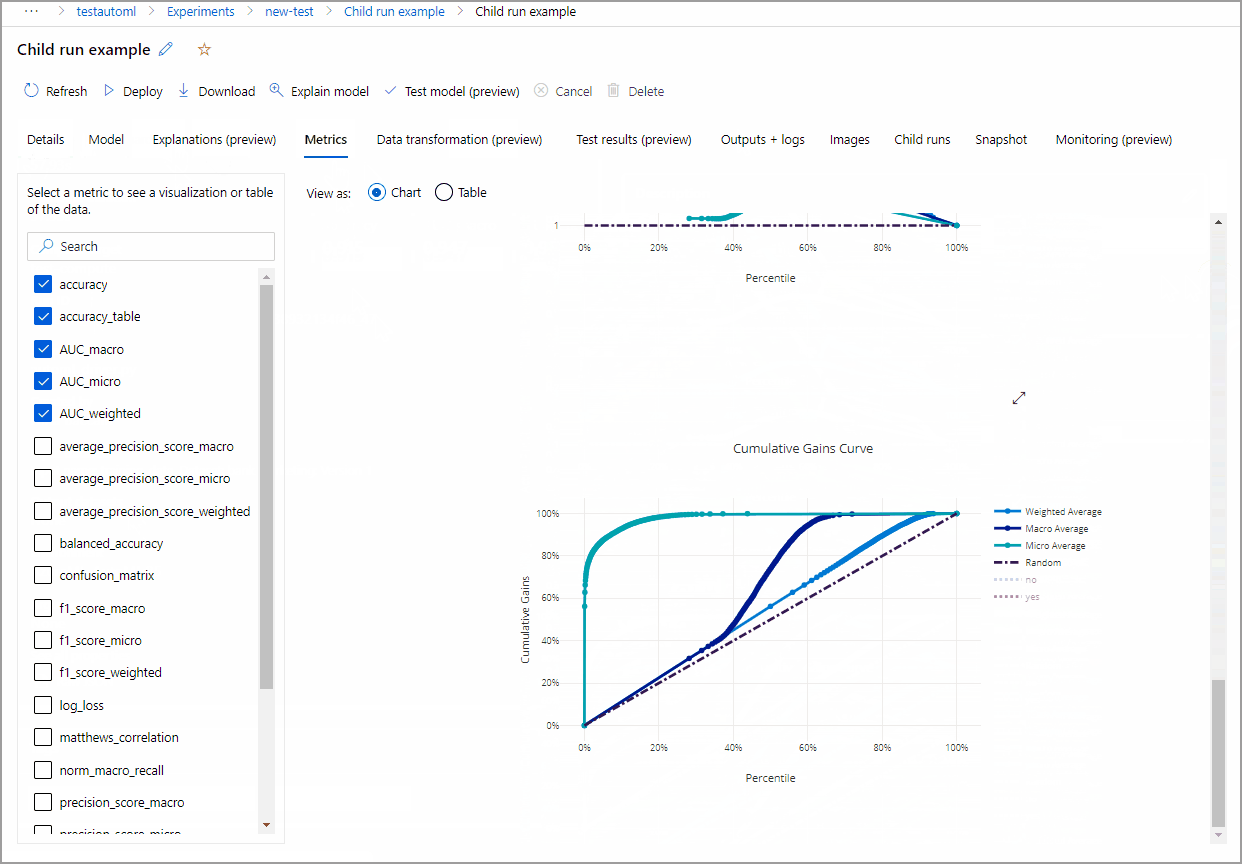
Penjelasan model
Sambil menunggu model selesai, Anda juga dapat melihat penjelasan model dan melihat fitur data mana (mentah atau direkayasa) yang memengaruhi prediksi model tertentu.
Penjelasan model ini dapat dihasilkan sesuai permintaan, dan dirangkum dalam dasbor penjelasan model yang merupakan bagian dari tab Penjelasan (pratinjau).
Untuk menghasilkan penjelasan model,
Pilih Pekerjaan 1 di bagian atas untuk menavigasi kembali ke layar Model.
Pilih tab Model.
Untuk tutorial ini, pilih model MaxAbsScaler, LightGBM pertama.
Pilih tombol Jelaskan model di bagian atas. Di sebelah kanan, panel Jelaskan model muncul.
Pilih automl-compute yang Anda buat sebelumnya. Kluster komputasi ini memulai pekerjaan turunan untuk menghasilkan penjelasan model.
Pilih Buat di bagian bawah. Pesan sukses hijau muncul di bagian atas layar Anda.
Catatan
Pekerjaan yang dapat dijelaskan membutuhkan waktu sekitar 2-5 menit untuk diselesaikan.
Pilih tombol Penjelasan (pratinjau). Tab ini akan terisi setelah proses penjelasan selesai.
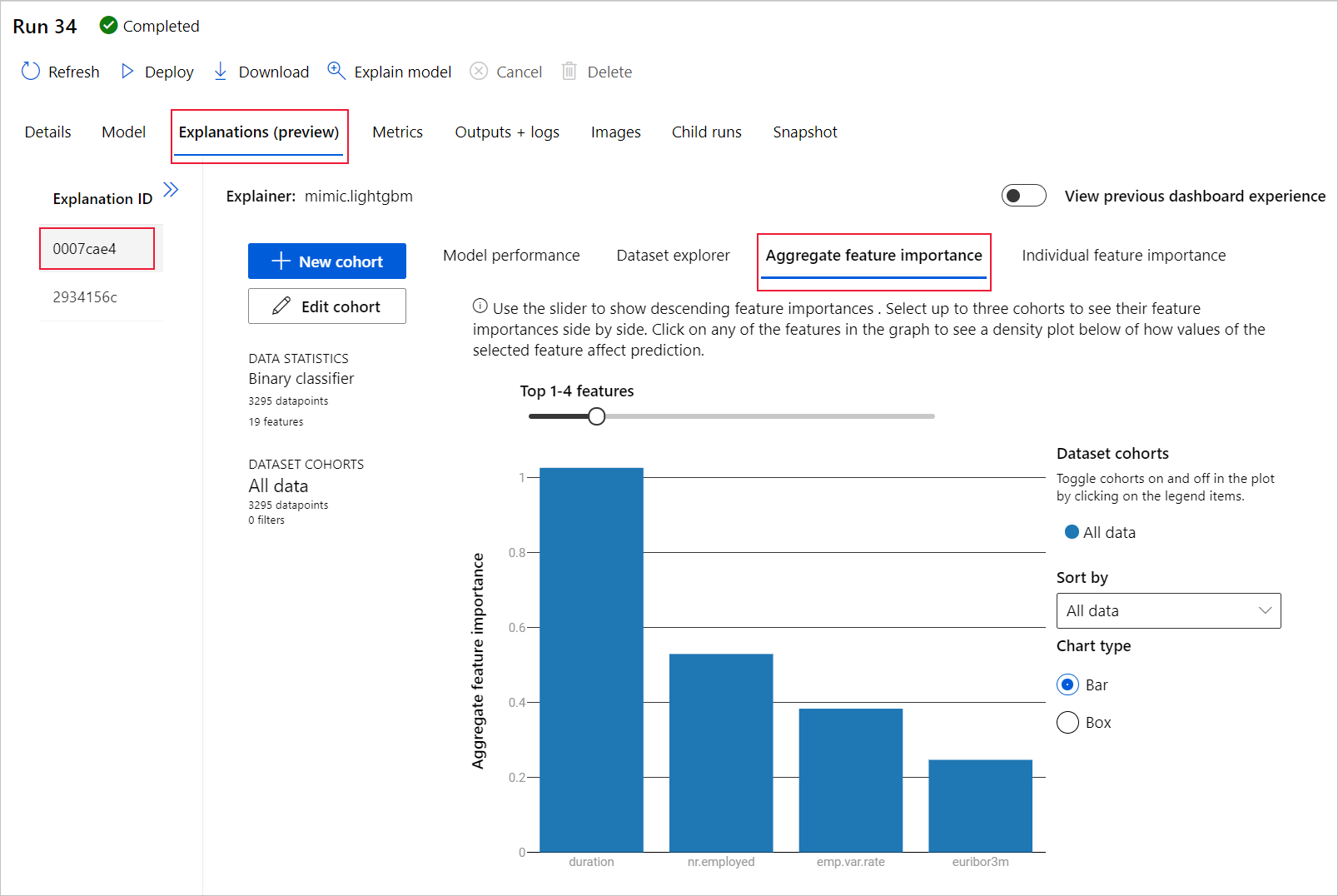
Di sebelah kiri, luaskan panel dan pilih baris yang bertuliskan mentah di bagian Fitur.
Pilih tab Kepentingan fitur Agregat di sebelah kanan. Bagan ini menunjukkan fitur data mana yang memengaruhi prediksi model yang dipilih.
Dalam contoh ini, durasi tampaknya memiliki pengaruh paling besar pada prediksi model ini.
Menyebarkan model terbaik
Antarmuka pembelajaran mesin otomatis memungkinkan Anda untuk menyebarkan model terbaik sebagai layanan web dalam beberapa langkah. Penyebaran adalah integrasi model sehingga model dapat memprediksi data baru dan mengidentifikasi area peluang potensial.
Untuk percobaan ini, penyebaran ke layanan web berarti bahwa lembaga keuangan sekarang memiliki solusi web yang berulang dan terukur untuk mengidentifikasi calon nasabah deposito berjangka tetap.
Periksa untuk melihat apakah eksperimen Anda selesai. Untuk melakukannya, navigasikan kembali ke halaman pekerjaan induk dengan memilih Pekerjaan 1 di bagian atas layar Anda. Status Selesai ditampilkan di kiri atas layar.
Setelah eksperimen selesai, halaman Detail diisi dengan bagian Ringkasan model terbaik. Dalam konteks eksperimen ini, VotingEnsemble dianggap sebagai model terbaik, berdasarkan metrik AUC_weighted.
Kami menyebarkan model ini, tetapi ingat, penyebaran membutuhkan waktu sekitar 20 menit untuk selesai. Proses penyebaran memerlukan beberapa langkah termasuk mendaftarkan model, membuat sumber daya, dan mengonfigurasikan penyebaran untuk layanan web.
Pilih VotingEnsemble untuk membuka halaman khusus model.
Pilih menu Sebarkan di kiri atas dan pilih Sebarkan ke layanan web.
Isi panel Sebarkan model sebagai berikut:
Bidang Nilai Nama penyebaran my-automl-deploy Deskripsi penyebaran Penyebaran eksperimen pembelajaran mesin otomatis pertama saya Tipe komputasi Pilih Instans Kontainer Azure (ACI) Aktifkan autentikasi Nonaktifkan. Menggunakan penyebaran kustom Nonaktifkan. Penonaktifan memungkinkan file driver default (skrip penilaian) dan file lingkungan akan dihasilkan secara otomatis. Untuk contoh ini, kami menggunakan default yang diberikan di menu Tingkat Lanjut.
Pilih Sebarkan.
Pesan sukses berwarna hijau muncul di bagian atas layar Pekerjaan, dan di panel Ringkasan model, pesan status muncul di bawah Status penyebaran. Pilih Refresh secara berkala untuk memeriksa status penyebaran.
Sekarang Anda memiliki layanan web operasional untuk membuat prediksi.
Lanjutkan ke Langkah-Langkah Berikutnya untuk mempelajari selengkapnya tentang cara menggunakan layanan web baru, dan menguji prediksi Anda menggunakan dukungan Azure Machine Learning bawaan Power BI.
Membersihkan sumber daya
File penyebaran lebih besar dari file data dan eksperimen, sehingga harga file lebih mahal untuk disimpan. Hapus file penyebaran saja untuk mengurangi biaya akun Anda, atau jika ingin menyimpan ruang kerja dan file eksperimen Anda. Jika tidak, hapus seluruh grup sumber daya, jika Anda tidak berencana untuk menggunakan file mana pun.
Hapus instans penyebaran
Hapus instans penyebaran saja dari Azure Machine Learning di https://ml.azure.com/, jika Anda ingin menyimpan grup sumber daya dan ruang kerja untuk tutorial dan eksplorasi lainnya.
Buka Azure Machine Learning. Buka ruang kerja Anda, dan di sebelah kiri, di panel Aset, pilih Titik Akhir.
Pilih penyebaran yang ingin Anda hapus dan pilih Hapus.
Pilih Lanjutkan.
Hapus grup sumber daya
Penting
Sumber daya yang Anda buat sebagai prasyarat untuk tutorial dan artikel cara penggunaan Azure Machine Learning lainnya.
Jika Anda tidak berencana menggunakan sumber daya yang sudah Anda buat, hapus sehingga Anda tidak dikenakan biaya apa pun:
Dari portal Microsoft Azure, pilih Grup sumber daya dari sisi sebelah kiri.
Dari daftar, pilih grup sumber daya yang Anda buat.
Pilih Hapus grup sumber daya.
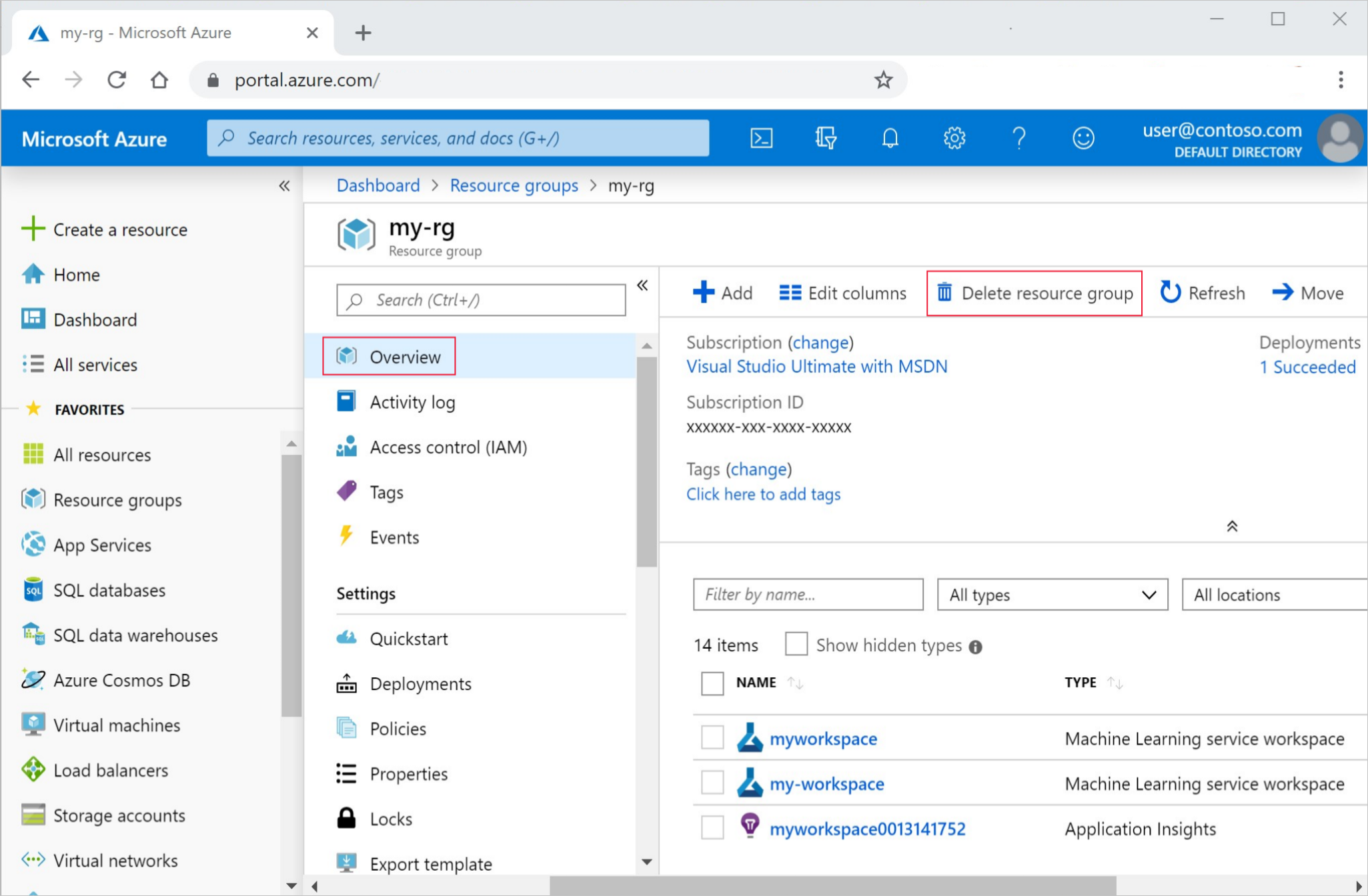
Masukkan nama grup sumber daya. Kemudian pilih Hapus.
Langkah berikutnya
Dalam tutorial pembelajaran mesin otomatis ini, Anda menggunakan antarmuka Pembelajaran Mesin otomatis Azure Machine Learning untuk membuat dan menyebarkan model klasifikasi. Lihat artikel ini untuk mengetahui informasi selengkapnya dan langkah-langkah berikutnya:
- Pelajari selengkapnya tentang pembelajaran mesin otomatis.
- Untuk mengetahui informasi selengkapnya tentang metrik dan bagan klasifikasi, lihat artikel Memahami hasil pembelajaran mesin otomatis.
Catatan
Himpunan data Pemasaran Bank ini tersedia di bawah Lisensi Creative Commons (CCO: Domain Publik). Setiap hak dalam konten individual database dilisensikan di bawah Lisensi Konten Database dan tersedia di Kaggle. Himpunan data ini awalnya tersedia dalam Database Azure Machine Learning UCI.
[Moro dkk., 2014] S. Moro, P. Cortez dan P. Rita. Pendekatan Berbasis Data untuk Memprediksi Keberhasilan Telemarketing Bank. Sistem Dukungan Keputusan, Elsevier, 62:22-31, Juni 2014.
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk