Tutorial: Melatih dan menyebarkan model klasifikasi gambar dengan contoh Notebook Jupyter
BERLAKU UNTUK: SDK Python azureml v1
SDK Python azureml v1
Dalam tutorial ini, Anda melatih model pembelajaran mesin di sumber daya komputasi jarak jauh. Anda menggunakan alur kerja pelatihan dan penyebaran untuk Azure Pembelajaran Mesin di Notebook Python Jupyter. Kemudian, Anda dapat menggunakan buku catatan sebagai templat untuk melatih model pembelajaran mesin Anda sendiri dengan data Anda sendiri.
Tutorial ini melatih regresi logistik sederhana dengan menggunakan himpunan data MNIST dan scikit-learn dengan Azure Machine Learning. MNIST adalah himpunan data populer yang terdiri dari 70.000 gambar skala abu-abu. Setiap gambar adalah digit tulisan tangan 28 x 28 piksel, yang mewakili angka dari nol hingga sembilan. Tujuannya adalah untuk membuat pengklasifikasi multi-kelas untuk mengidentifikasi digit yang diwakili gambar tertentu.
Pelajari cara melakukan tindakan berikut:
- Unduh himpunan data dan lihat datanya.
- Latih model klasifikasi gambar dan metrik log menggunakan MLflow.
- Sebarkan model untuk melakukan inferensi real time.
Prasyarat
- Selesaikan Mulai Cepat: Mulai menggunakan Azure Pembelajaran Mesin untuk:
- Buat ruang kerja.
- Membuat instans komputasi berbasis cloud untuk digunakan untuk lingkungan pengembangan Anda.
Menjalankan buku catatan di ruang kerja Anda
Azure Machine Learning menyertakan server buku catatan cloud di ruang kerja Anda untuk pengalaman tanpa pemasangan dan prakonfigurasi. Gunakan lingkungan Anda sendiri jika lebih suka memiliki kontrol atas lingkungan, paket, dan dependensi Anda.
Mengkloning folder buku catatan
Anda menyelesaikan persiapan eksperimen berikut dan menjalankan langkah-langkah di studio Azure Machine Learning. Antarmuka konsolidasi ini mencakup alat pembelajaran mesin untuk melakukan skenario ilmu data untuk praktisi ilmu data dari semua tingkat keterampilan.
Masuk ke Studio Azure Machine Learning.
Pilih langganan dan ruang kerja yang Anda buat.
Di sebelah kiri, pilih Buku catatan.
Di bagian atas, pilih tab Sampel.
Buka folder SDK v1.
Pilih tombol ... di sebelah kanan folder tutorial, lalu pilih Klon.
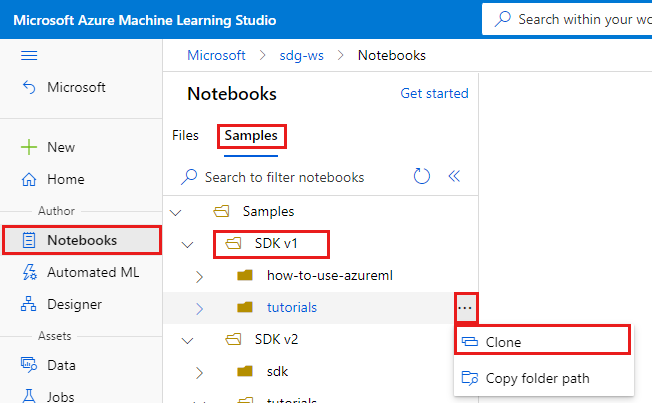
Daftar folder menunjukkan masing-masing pengguna yang mengakses ruang kerja. Pilih folder Anda untuk mengkloning folder tutorial di sana.
Membuka buku catatan yang dikloning
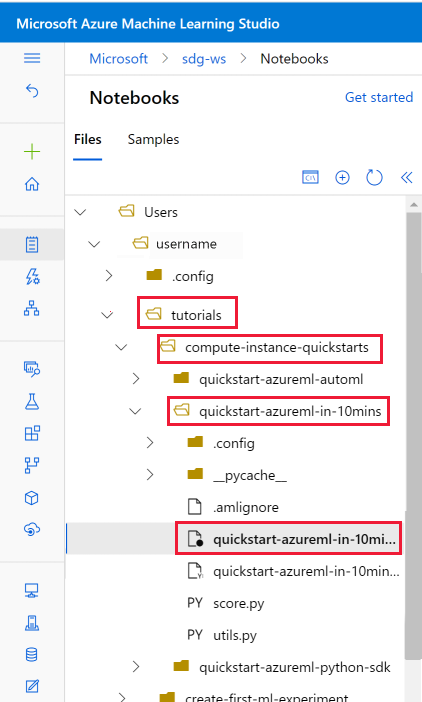
Buka folder tutorial yang dikloning ke bagian File pengguna.
Pilih file quickstart-azureml-in-10mins.ipynb dari folder compute-instance-quickstarts/quickstart-azureml-in-10mins Anda.
Memasang paket
Setelah instans komputasi berjalan dan kernel muncul, tambahkan sel kode baru untuk memasang paket yang diperlukan untuk tutorial ini.
Di bagian atas buku catatan, tambahkan sel kode.
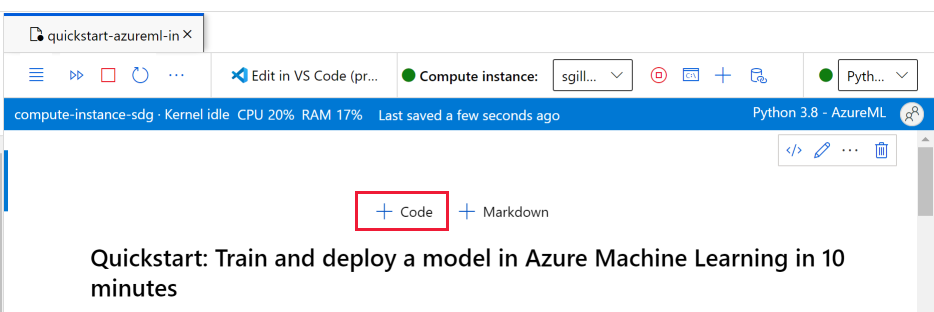
Tambahkan hal berikut ke dalam sel, lalu jalankan sel dengan menggunakan alat Jalankan atau dengan menggunakan Shift+Enter.
%pip install scikit-learn==0.22.1 %pip install scipy==1.5.2
Anda mungkin akan melihat beberapa peringatan pemasangan. Hal ini dapat diabaikan dengan aman.
Jalankan buku catatan
Tutorial ini dan file utils.py yang menyertainya juga tersedia di GitHub jika Anda ingin menggunakannya di lingkungan lokal Anda sendiri. Jika Anda tidak menggunakan instans komputasi, tambahkan %pip install azureml-sdk[notebooks] azureml-opendatasets matplotlib ke pemasangan di atas.
Penting
Bagian lain dari artikel ini berisi konten yang sama seperti yang Anda lihat di notebook.
Beralih ke Notebook Jupyter sekarang jika Anda ingin menjalankan kode sambil membaca. Untuk menjalankan sel kode tunggal di buku catatan, klik sel kode dan tekan Shift+Enter. Atau, jalankan seluruh notebook dengan memilih Jalankan semua dari toolbar atas.
Impor data
Sebelum anda melatih model, anda perlu memahami data yang anda gunakan untuk melatihnya. Di bagian ini, pelajari cara untuk:
- Mengunduh himpunan data MNIST
- Menampilkan beberapa sampel gambar
Anda menggunakan Azure Open Datasets untuk mendapatkan file data MNIST mentah. Azure Open Datasets adalah kumpulan himpunan data publik yang dapat Anda gunakan untuk menambahkan fitur khusus skenario ke solusi pembelajaran mesin untuk model yang lebih baik. Setiap himpunan data memiliki kelas yang sesuai, MNIST dalam hal ini, untuk mengambil data dengan cara yang berbeda.
import os
from azureml.opendatasets import MNIST
data_folder = os.path.join(os.getcwd(), "/tmp/qs_data")
os.makedirs(data_folder, exist_ok=True)
mnist_file_dataset = MNIST.get_file_dataset()
mnist_file_dataset.download(data_folder, overwrite=True)
Perhatikan datanya
Muat file terkompresi ke array numpy. Kemudian, gunakan matplotlib untuk merencanakan 30 gambar acak dari himpunan data dengan label di atasnya.
Perhatikan langkah ini memerlukan load_data fungsi, yang disertakan utils.py dalam file. File ini ditempatkan di folder yang sama dengan buku catatan ini. Fungsi load_data ini hanya menguraikan file terkompresi ke dalam array numpy.
from utils import load_data
import matplotlib.pyplot as plt
import numpy as np
import glob
# note we also shrink the intensity values (X) from 0-255 to 0-1. This helps the model converge faster.
X_train = (
load_data(
glob.glob(
os.path.join(data_folder, "**/train-images-idx3-ubyte.gz"), recursive=True
)[0],
False,
)
/ 255.0
)
X_test = (
load_data(
glob.glob(
os.path.join(data_folder, "**/t10k-images-idx3-ubyte.gz"), recursive=True
)[0],
False,
)
/ 255.0
)
y_train = load_data(
glob.glob(
os.path.join(data_folder, "**/train-labels-idx1-ubyte.gz"), recursive=True
)[0],
True,
).reshape(-1)
y_test = load_data(
glob.glob(
os.path.join(data_folder, "**/t10k-labels-idx1-ubyte.gz"), recursive=True
)[0],
True,
).reshape(-1)
# now let's show some randomly chosen images from the traininng set.
count = 0
sample_size = 30
plt.figure(figsize=(16, 6))
for i in np.random.permutation(X_train.shape[0])[:sample_size]:
count = count + 1
plt.subplot(1, sample_size, count)
plt.axhline("")
plt.axvline("")
plt.text(x=10, y=-10, s=y_train[i], fontsize=18)
plt.imshow(X_train[i].reshape(28, 28), cmap=plt.cm.Greys)
plt.show()
Kode menampilkan sekumpulan gambar acak dengan labelnya, mirip dengan ini:

Melatih model dan metrik log dengan MLflow
Latih model menggunakan kode berikut. Kode ini menggunakan autologging MLflow untuk melacak metrik dan artefak model log.
Anda akan menggunakan pengklasifikasi LogisticRegression dari kerangka kerja SciKit Learn untuk mengklasifikasikan data.
Catatan
Pelatihan model membutuhkan waktu sekitar 2 menit untuk diselesaikan.
# create the model
import mlflow
import numpy as np
from sklearn.linear_model import LogisticRegression
from azureml.core import Workspace
# connect to your workspace
ws = Workspace.from_config()
# create experiment and start logging to a new run in the experiment
experiment_name = "azure-ml-in10-mins-tutorial"
# set up MLflow to track the metrics
mlflow.set_tracking_uri(ws.get_mlflow_tracking_uri())
mlflow.set_experiment(experiment_name)
mlflow.autolog()
# set up the Logistic regression model
reg = 0.5
clf = LogisticRegression(
C=1.0 / reg, solver="liblinear", multi_class="auto", random_state=42
)
# train the model
with mlflow.start_run() as run:
clf.fit(X_train, y_train)
Lihat eksperimen
Di menu sebelah kiri di studio Azure Machine Learning, pilih Pekerjaan kemudian pilih pekerjaan Anda (azure-ml-in10-mins-tutorial). Pekerjaan adalah pengelompokan eksekusi dari skrip atau sepotong kode tertentu yang banyak. Beberapa pekerjaan dapat dikelompokkan bersama sebagai sebuah eksperimen.
Informasi untuk eksekusi disimpan pada pekerjaan. Jika nama tidak ada saat mengirimkan pekerjaan, jika Anda memilih eksekusi, Anda akan melihat berbagai tab yang berisi metrik, log, penjelasan, dll.
Kontrol versi model Anda dengan registri model
Anda dapat menggunakan pendaftaran model untuk menyimpan dan membuat versi model di ruang kerja Anda. Model terdaftar diidentifikasi berdasarkan nama dan versi. Setiap kali Anda mendaftarkan model dengan nama yang sama dengan yang sudah ada, registri akan meningkatkan versinya. Kode di bawah ini mendaftarkan dan membuat versi model yang Anda latih di atas. Setelah menjalankan sel kode berikut, Anda akan melihat model di registri dengan memilih Model di menu sebelah kiri di Azure Pembelajaran Mesin studio.
# register the model
model_uri = "runs:/{}/model".format(run.info.run_id)
model = mlflow.register_model(model_uri, "sklearn_mnist_model")
Menyebarkan model untuk inferensi real time
Di bagian ini, pelajari cara menyebarkan model sehingga aplikasi dapat menggunakan (inferensi) model melalui REST.
Membuat konfigurasi penyebaran
Sel kode mendapatkan lingkungan yang dikumpulkan, yang menentukan semua dependensi yang diperlukan untuk menghosting model (misalnya, paket seperti scikit-learn). Selain itu, Anda membuat konfigurasi penyebaran, yang menentukan jumlah komputasi yang diperlukan untuk menghosting model. Dalam hal ini, komputasi memiliki memori 1CPU dan 1 GB.
# create environment for the deploy
from azureml.core.environment import Environment
from azureml.core.conda_dependencies import CondaDependencies
from azureml.core.webservice import AciWebservice
# get a curated environment
env = Environment.get(
workspace=ws,
name="AzureML-sklearn-1.0"
)
env.inferencing_stack_version='latest'
# create deployment config i.e. compute resources
aciconfig = AciWebservice.deploy_configuration(
cpu_cores=1,
memory_gb=1,
tags={"data": "MNIST", "method": "sklearn"},
description="Predict MNIST with sklearn",
)
Menyebarkan model
Sel kode berikutnya ini menyebarkan model ke Instans Kontainer Azure.
Catatan
Penyebaran membutuhkan waktu sekitar 3 menit untuk diselesaikan. Tetapi mungkin lebih lama sampai tersedia untuk digunakan, mungkin selama 15 menit.**
%%time
import uuid
from azureml.core.model import InferenceConfig
from azureml.core.environment import Environment
from azureml.core.model import Model
# get the registered model
model = Model(ws, "sklearn_mnist_model")
# create an inference config i.e. the scoring script and environment
inference_config = InferenceConfig(entry_script="score.py", environment=env)
# deploy the service
service_name = "sklearn-mnist-svc-" + str(uuid.uuid4())[:4]
service = Model.deploy(
workspace=ws,
name=service_name,
models=[model],
inference_config=inference_config,
deployment_config=aciconfig,
)
service.wait_for_deployment(show_output=True)
File skrip penilaian yang direferensikan dalam kode sebelumnya dapat ditemukan di folder yang sama dengan buku catatan ini, dan memiliki dua fungsi:
- Fungsi
inityang dijalankan sekali ketika layanan dimulai - dalam fungsi ini Anda biasanya mendapatkan model dari registri dan mengatur variabel global - Fungsi
run(data)yang dijalankan setiap kali panggilan dilakukan ke layanan. Dalam fungsi ini, Anda biasanya memformat data input, menjalankan prediksi, dan membuat output hasil yang diprediksi.
Menampilkan titik akhir
Setelah model berhasil disebarkan, Anda dapat melihat titik akhir dengan menavigasi ke Titik Akhir di menu sebelah kiri di studio Azure Pembelajaran Mesin. Anda akan melihat status titik akhir (sehat/tidak sehat), log, dan konsumsi (bagaimana aplikasi dapat menggunakan model).
Menguji layanan model
Anda dapat menguji model dengan mengirimkan permintaan HTTP mentah untuk menguji layanan web.
# send raw HTTP request to test the web service.
import requests
# send a random row from the test set to score
random_index = np.random.randint(0, len(X_test) - 1)
input_data = '{"data": [' + str(list(X_test[random_index])) + "]}"
headers = {"Content-Type": "application/json"}
resp = requests.post(service.scoring_uri, input_data, headers=headers)
print("POST to url", service.scoring_uri)
print("label:", y_test[random_index])
print("prediction:", resp.text)
Membersihkan sumber daya
Jika Anda tidak akan terus menggunakan model ini, hapus Layanan model menggunakan:
# if you want to keep workspace and only delete endpoint (it will incur cost while running)
service.delete()
Jika Anda ingin mengontrol biaya lebih lanjut, hentikan instans komputasi dengan memilih tombol "Hentikan komputasi" di samping dropdown Komputasi. Kemudian mulai instans komputasi lagi saat Anda membutuhkannya.
Menghapus semuanya
Gunakan langkah-langkah ini untuk menghapus ruang kerja dan semua sumber daya komputasi Azure Machine Learning Anda.
Penting
Sumber daya yang Anda buat sebagai prasyarat untuk tutorial dan artikel cara penggunaan Azure Machine Learning lainnya.
Jika Anda tidak berencana menggunakan sumber daya yang sudah Anda buat, hapus sehingga Anda tidak dikenakan biaya apa pun:
Dari portal Microsoft Azure, pilih Grup sumber daya dari sisi sebelah kiri.
Dari daftar, pilih grup sumber daya yang Anda buat.
Pilih Hapus grup sumber daya.
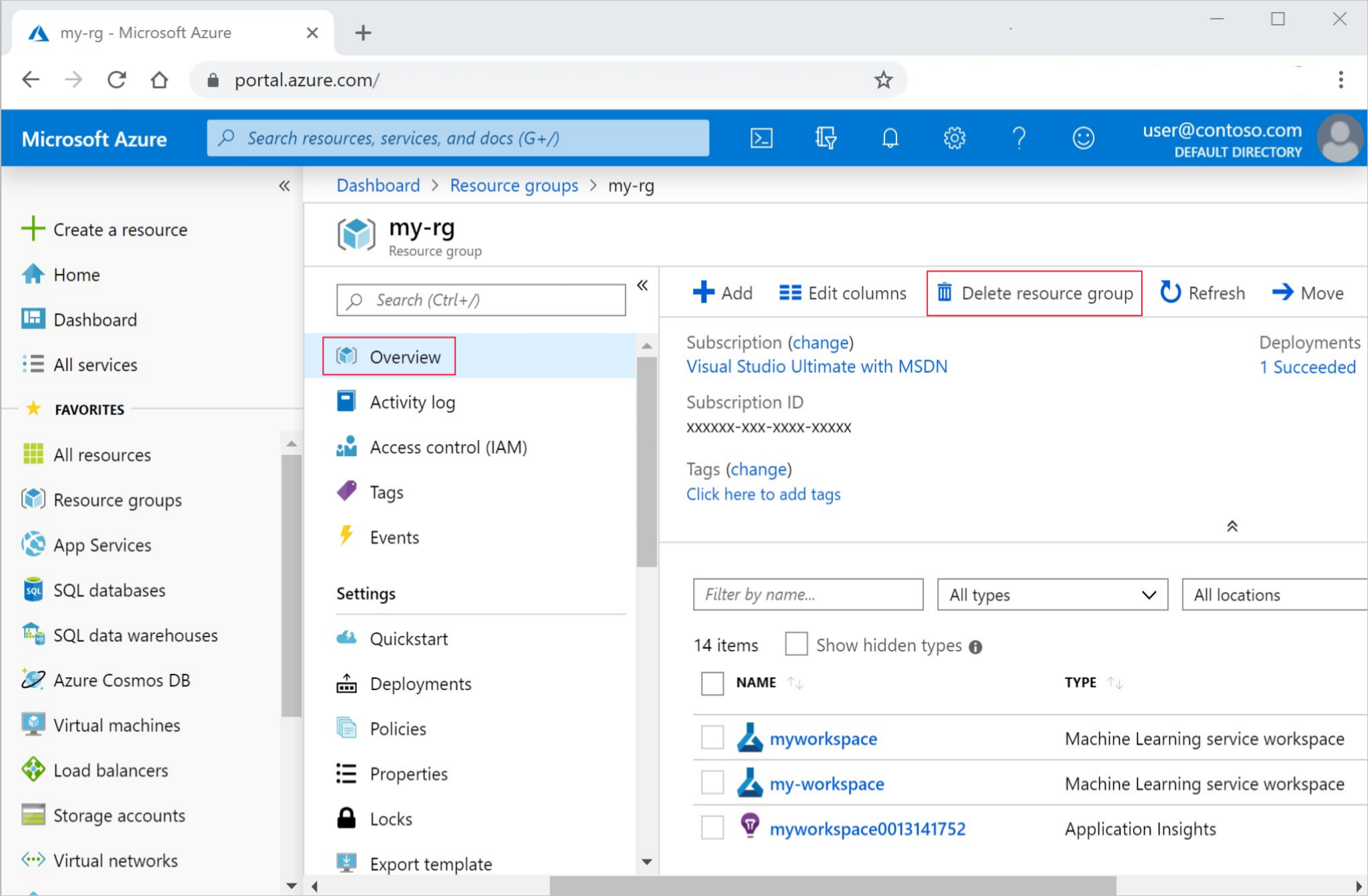
Masukkan nama grup sumber daya. Kemudian pilih Hapus.
Sumber daya terkait
- Pelajari semua opsi penyebaran untuk Azure Machine Learning.
- Pelajari cara mengautentikasi ke model yang disebarkan.
- Buat prediksi pada data dalam jumlah besar secara asinkron.
- Pantau model Azure Machine Learning Anda dengan Application Insights.