Manipulasi data dengan kumpulan Apache Spark (tidak digunakan lagi)
BERLAKU UNTUK: Python SDK azureml v1
Python SDK azureml v1
Peringatan
Integrasi Azure Synapse Analytics dengan Azure Machine Learning yang tersedia di Python SDK v1 tidak digunakan lagi. Pengguna dapat terus menggunakan ruang kerja Synapse yang terdaftar di Azure Machine Learning sebagai layanan tertaut. Namun, ruang kerja Synapse baru tidak dapat lagi terdaftar di Azure Machine Learning sebagai layanan tertaut. Sebaiknya gunakan komputasi Synapse Terkelola (Otomatis) dan kumpulan Synapse Spark terpasang yang tersedia di CLI v2 dan Python SDK v2. Silakan lihat https://aka.ms/aml-spark untuk detail lebih lanjut.
Dalam artikel ini, Anda mempelajari cara melakukan tugas perselisihan data secara interaktif dalam sesi Synapse khusus, yang didukung oleh Azure Synapse Analytics, di buku catatan Jupyter menggunakan SDK Python Azure Machine Learning.
Jika Anda lebih suka menggunakan alur Azure Machine Learning, lihat Cara menggunakan Apache Spark (didukung oleh Azure Synapse Analytics) di alur pembelajaran mesin (pratinjau) Anda.
Untuk panduan tentang cara menggunakan Azure Synapse Analytics dengan ruang kerja Synapse, lihat rangkaian memulai Azure Synapse Analytics.
Azure Machine Learning dan integrasi Azure Synapse Analytics
Integrasi Azure Synapse Analytics dengan Azure Machine Learning (pratinjau) memungkinkan Anda melampirkan kumpulan Apache Spark yang didukung oleh Azure Synapse untuk eksplorasi dan persiapan data interaktif. Dengan integrasi ini, Anda dapat memiliki komputasi khusus untuk perselisihan data dalam skala besar, semuanya dalam buku catatan Python yang sama yang Anda gunakan untuk melatih model pembelajaran mesin Anda.
Prasyarat
Membuat ruang kerja Azure Synapse Analytics di portal Azure.
Buat kumpulan Apache Spark menggunakan portal Microsoft Azure, alat web, atau Studio Synapse.
Konfigurasikan lingkungan pengembangan Anda untuk menginstal Azure Machine Learning SDK, atau gunakan instans komputasi Azure Machine Learning dengan SDK yang sudah diinstal.
Instal paket
azureml-synapse(pratinjau) dengan kode berikut:pip install azureml-synapseTautkan ruang kerja Azure Machine Learning dan ruang kerja Azure Synapse Analytics dengan SDK Python Azure Machine Learning atau melalui studio Azure Machine Learning
Lampirkan kumpulan Synapse Spark sebagai target komputasi.
Meluncurkan kumpulan Synapse Spark untuk tugas perselisihan data
Untuk memulai penyiapan data dengan kumpulan Apache Spark, tentukan nama komputasi Spark Synapse terlampir. Nama ini dapat ditemukan melalui studio Azure Machine Learning di bawah tab Komputasi terlampir.
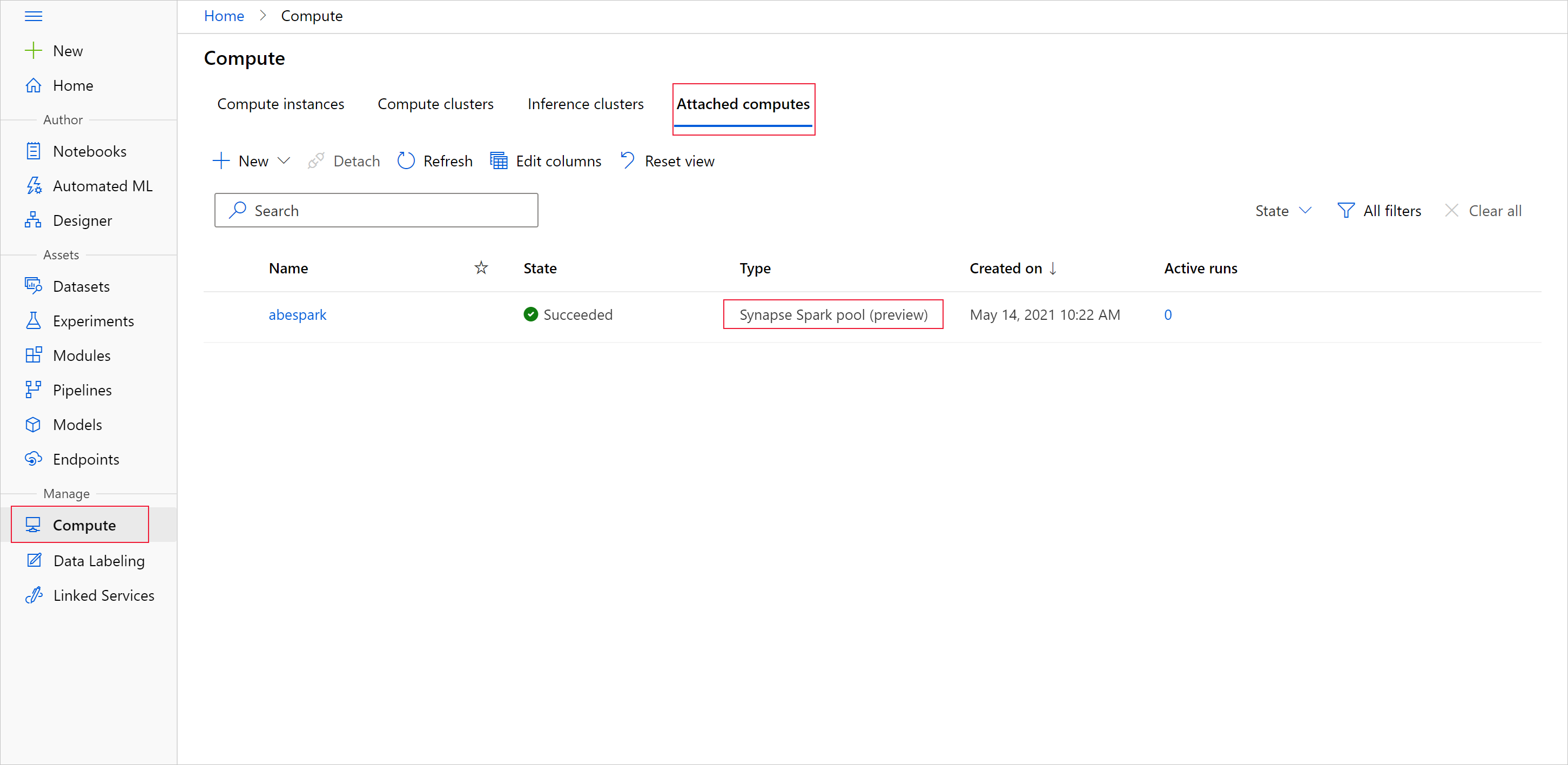
Penting
Untuk terus menggunakan kumpulan Apache Spark, Anda harus menunjukkan sumber daya komputasi mana yang akan digunakan di seluruh tugas perselisihan data dengan %synapse untuk satu baris kode dan %%synapse untuk beberapa baris. Pelajari selengkapnya tentang perintah ajaib %synapse.
%synapse start -c SynapseSparkPoolAlias
Setelah sesi dimulai, Anda dapat memeriksa metadata sesi.
%synapse meta
Anda dapat menentukan lingkungan Azure Machine Learning yang akan digunakan selama sesi Apache Spark Anda. Hanya dependensi Conda yang ditentukan dalam lingkungan yang akan berlaku. Gambar Docker tidak didukung.
Peringatan
Dependensi Python yang ditentukan dalam dependensi Conda lingkungan tidak didukung di kumpulan Apache Spark. Saat ini, hanya versi Python tetap yang didukung.
Periksa versi Python Anda dengan menyertakan sys.version_info dalam skrip Anda.
Kode berikut, membuat lingkungan, myenv, yang menginstal azureml-core versi 1.20.0 dan numpy versi 1.17.0 sebelum sesi dimulai. Anda kemudian dapat menyertakan lingkungan ini dalam pernyataan start sesi Apache Spark Anda.
from azureml.core import Workspace, Environment
# creates environment with numpy and azureml-core dependencies
ws = Workspace.from_config()
env = Environment(name="myenv")
env.python.conda_dependencies.add_pip_package("azureml-core==1.20.0")
env.python.conda_dependencies.add_conda_package("numpy==1.17.0")
env.register(workspace=ws)
Untuk memulai penyiapan data dengan kumpulan Apache Spark dan lingkungan kustom Anda, tentukan nama kumpulan Apache Spark dan lingkungan mana yang akan digunakan selama sesi Apache Spark. Selain itu, Anda dapat memberikan ID langganan Anda, grup sumber daya ruang kerja pembelajaran mesin, dan nama ruang kerja pembelajaran mesin.
%synapse start -c SynapseSparkPoolAlias -e myenv -s AzureMLworkspaceSubscriptionID -r AzureMLworkspaceResourceGroupName -w AzureMLworkspaceName
Memuat data dari penyimpanan
Setelah sesi Apache Spark Anda dimulai, baca di data yang ingin Anda siapkan. Pemuatan data didukung untuk penyimpanan Azure Blob dan Azure Data Lake Storage Generasi 1 dan 2.
Ada dua cara untuk memuat data dari layanan penyimpanan ini:
Muat data langsung dari penyimpanan menggunakan jalur Hadoop Distributed Files System (HDFS).
Baca dalam data dari himpunan data Azure Machine Learning yang sudah ada.
Untuk mengakses layanan penyimpanan ini, Anda memerlukan izin Storage Blob Data Reader. Jika Anda berencana menulis data kembali ke layanan penyimpanan ini, Anda memerlukan izin Storage Blob Data Contributor. Pelajari lebih lanjut tentang izin dan peran penyimpanan.
Memuat data dengan jalur Hadoop Distributed Files System (HDFS)
Untuk memuat dan membaca data dari penyimpanan dengan jalur HDFS yang sesuai, Anda harus memiliki info masuk autentikasi akses data Anda yang tersedia. Info masuk ini berbeda tergantung pada jenis penyimpanan Anda.
Kode berikut menunjukkan cara membaca data dari penyimpanan Azure Blob ke dalam dataframe Spark dengan token tanda tangan akses bersama (SAS) atau kunci akses Anda.
%%synapse
# setup access key or SAS token
sc._jsc.hadoopConfiguration().set("fs.azure.account.key.<storage account name>.blob.core.windows.net", "<access key>")
sc._jsc.hadoopConfiguration().set("fs.azure.sas.<container name>.<storage account name>.blob.core.windows.net", "<sas token>")
# read from blob
df = spark.read.option("header", "true").csv("wasbs://demo@dprepdata.blob.core.windows.net/Titanic.csv")
Kode berikut menunjukkan cara membaca data dari Azure Data Lake Storage Generasi 1 (ADLS Gen 1) dengan info masuk utama layanan Anda.
%%synapse
# setup service principal which has access of the data
sc._jsc.hadoopConfiguration().set("fs.adl.account.<storage account name>.oauth2.access.token.provider.type","ClientCredential")
sc._jsc.hadoopConfiguration().set("fs.adl.account.<storage account name>.oauth2.client.id", "<client id>")
sc._jsc.hadoopConfiguration().set("fs.adl.account.<storage account name>.oauth2.credential", "<client secret>")
sc._jsc.hadoopConfiguration().set("fs.adl.account.<storage account name>.oauth2.refresh.url",
"https://login.microsoftonline.com/<tenant id>/oauth2/token")
df = spark.read.csv("adl://<storage account name>.azuredatalakestore.net/<path>")
Kode berikut menunjukkan cara membaca data dari Azure Data Lake Storage Generasi 2 (ADLS Gen 2) dengan info masuk utama layanan Anda.
%%synapse
# setup service principal which has access of the data
sc._jsc.hadoopConfiguration().set("fs.azure.account.auth.type.<storage account name>.dfs.core.windows.net","OAuth")
sc._jsc.hadoopConfiguration().set("fs.azure.account.oauth.provider.type.<storage account name>.dfs.core.windows.net", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider")
sc._jsc.hadoopConfiguration().set("fs.azure.account.oauth2.client.id.<storage account name>.dfs.core.windows.net", "<client id>")
sc._jsc.hadoopConfiguration().set("fs.azure.account.oauth2.client.secret.<storage account name>.dfs.core.windows.net", "<client secret>")
sc._jsc.hadoopConfiguration().set("fs.azure.account.oauth2.client.endpoint.<storage account name>.dfs.core.windows.net",
"https://login.microsoftonline.com/<tenant id>/oauth2/token")
df = spark.read.csv("abfss://<container name>@<storage account>.dfs.core.windows.net/<path>")
Membaca data dari himpunan data yang terdaftar
Anda juga bisa mendapatkan himpunan data terdaftar yang sudah ada di ruang kerja Anda dan melakukan penyiapan data di atasnya dengan mengonversinya menjadi dataframe spark.
Contoh berikut mengautentikasi ke ruang kerja, mendapatkan TabularDataset terdaftar, blob_dset, yang mereferensikan file dalam penyimpanan blob, dan mengonversinya menjadi dataframe spark. Saat mengonversi himpunan data menjadi dataframe spark, Anda dapat menggunakan eksplorasi data pyspark dan pustaka persiapan.
%%synapse
from azureml.core import Workspace, Dataset
subscription_id = "<enter your subscription ID>"
resource_group = "<enter your resource group>"
workspace_name = "<enter your workspace name>"
ws = Workspace(workspace_name = workspace_name,
subscription_id = subscription_id,
resource_group = resource_group)
dset = Dataset.get_by_name(ws, "blob_dset")
spark_df = dset.to_spark_dataframe()
Melakukan tugas perselisihan data
Setelah mengambil dan menjelajahi data, Anda dapat melakukan tugas perselisihan data.
Kode berikut, diperluas berdasarkan contoh HDFS di bagian sebelumnya dan memfilter data dalam dataframe spark, df, berdasarkan kolom Survivor dan grup yang mencantumkan menurut Usia
%%synapse
from pyspark.sql.functions import col, desc
df.filter(col('Survived') == 1).groupBy('Age').count().orderBy(desc('count')).show(10)
df.show()
Menyimpan data ke penyimpanan dan menghentikan sesi spark
Setelah eksplorasi dan penyiapan data selesai, simpan data yang disiapkan untuk digunakan nanti di akun penyimpanan Anda di Azure.
Dalam contoh berikut, data yang disiapkan ditulis kembali ke penyimpanan Azure Blob dan menimpa file Titanic.csv asli di direktori training_data. Untuk menulis kembali ke penyimpanan, Anda memerlukan izin Storage Blob Data Contributor. Pelajari lebih lanjut tentang izin dan peran penyimpanan.
%% synapse
df.write.format("csv").mode("overwrite").save("wasbs://demo@dprepdata.blob.core.windows.net/training_data/Titanic.csv")
Setelah menyelesaikan penyiapan data dan menyimpan data yang disiapkan ke penyimpanan, berhenti menggunakan kumpulan Apache Spark dengan perintah berikut.
%synapse stop
Membuat himpunan data untuk mewakili data yang disiapkan
Saat Anda siap untuk menggunakan data yang disiapkan untuk pelatihan model, sambungkan ke penyimpanan Anda dengan datastore Azure Machine Learning, dan tentukan file mana yang ingin Anda gunakan dengan himpunan data Azure Machine Learning.
Contoh kode berikut,
- Mengasumsikan Anda sudah membuat datastore yang tersambung ke layanan penyimpanan tempat Anda menyimpan data yang disiapkan.
- Mendapatkan datastore yang ada,
mydatastore, dari ruang kerja,wsdengan metode get(). - Membuat FileDataset,
train_ds, yang mereferensikan file data yang disiapkan yang terletak di direktoritraining_datadimydatastore. - Membuat variabel
input1, yang dapat digunakan di lain waktu untuk membuat file data himpunan datatrain_dsyang tersedia untuk target komputasi untuk tugas pelatihan Anda.
from azureml.core import Datastore, Dataset
datastore = Datastore.get(ws, datastore_name='mydatastore')
datastore_paths = [(datastore, '/training_data/')]
train_ds = Dataset.File.from_files(path=datastore_paths, validate=True)
input1 = train_ds.as_mount()
Menggunakan ScriptRunConfig untuk mengirimkan eksekusi eksperimen ke kumpulan Synapse Spark
Jika Anda siap untuk mengotomatisasi dan membuat tugas perselisihan data, Anda dapat mengirimkan eksekusi eksperimen ke kumpulan Synapse Spark terlampir dengan objek ScriptRunConfig.
Demikian pula, jika Anda memiliki alur Azure Machine Learning, Anda dapat menggunakan SynapseSparkStep untuk menentukan kumpulan Synapse Spark Anda sebagai target komputasi untuk langkah penyiapan data di alur Anda.
Membuat data Anda tersedia untuk kumpulan Synapse Spark bergantung pada jenis himpunan data Anda.
- Untuk FileDataset, Anda dapat menggunakan metode
as_hdfs()ini. Saat eksekusi dikirim, himpunan data tersedia untuk kumpulan Synapse Spark sebagai sistem file terdistribusi Hadoop (HFDS). - Untuk TabularDataset, Anda dapat menggunakan metode
as_named_input()ini.
Kode berikut,
- Membuat variabel
input2dari FileDatasettrain_dsyang dibuat dalam contoh kode sebelumnya. - Membuat variabel
outputdengan kelas HDFSOutputDatasetConfiguration. Setelah eksekusi selesai, kelas ini memungkinkan kami menyimpan output eksekusi sebagai himpunan data,testdi datastore,mydatastore. Di ruang kerja Azure Machine Learning, himpunan datatestterdaftar dengan namaregistered_dataset. - Mengonfigurasi pengaturan yang harus digunakan eksekusi untuk melakukan pada kumpulan Synapse Spark.
- Menentukan parameter ScriptRunConfig untuk,
- Gunakan
dataprep.py, untuk eksekusi. - Tentukan data mana yang akan digunakan sebagai input dan cara membuatnya tersedia untuk kumpulan Synapse Spark.
- Tentukan tempat untuk menyimpan data output,
output.
- Gunakan
from azureml.core import Dataset, HDFSOutputDatasetConfig
from azureml.core.environment import CondaDependencies
from azureml.core import RunConfiguration
from azureml.core import ScriptRunConfig
from azureml.core import Experiment
input2 = train_ds.as_hdfs()
output = HDFSOutputDatasetConfig(destination=(datastore, "test").register_on_complete(name="registered_dataset")
run_config = RunConfiguration(framework="pyspark")
run_config.target = synapse_compute_name
run_config.spark.configuration["spark.driver.memory"] = "1g"
run_config.spark.configuration["spark.driver.cores"] = 2
run_config.spark.configuration["spark.executor.memory"] = "1g"
run_config.spark.configuration["spark.executor.cores"] = 1
run_config.spark.configuration["spark.executor.instances"] = 1
conda_dep = CondaDependencies()
conda_dep.add_pip_package("azureml-core==1.20.0")
run_config.environment.python.conda_dependencies = conda_dep
script_run_config = ScriptRunConfig(source_directory = './code',
script= 'dataprep.py',
arguments = ["--file_input", input2,
"--output_dir", output],
run_config = run_config)
Untuk informasi selengkapnya tentang run_config.spark.configuration dan konfigurasi Spark umum, lihat Kelas SparkConfiguration dan dokumentasi konfigurasi Apache Spark.
Setelah objek ScriptRunConfig Anda disiapkan, Anda dapat mengirimkan eksekusi.
from azureml.core import Experiment
exp = Experiment(workspace=ws, name="synapse-spark")
run = exp.submit(config=script_run_config)
run
Untuk detail lebih lanjut, seperti skrip dataprep.py yang digunakan dalam contoh ini, lihat contoh notebook.
Setelah data Anda disiapkan, Anda kemudian dapat menggunakannya sebagai input untuk pekerjaan pelatihan Anda. Dalam contoh kode yang disebutkan di atas, registered_dataset adalah yang akan Anda tentukan sebagai data input untuk pekerjaan pelatihan.
Contoh buku catatan
Lihat contoh buku catatan untuk konsep dan demonstrasi selengkapnya tentang kemampuan integrasi Azure Synapse Analytics dan Azure Machine Learning.
- Jalankan sesi Spark interaktif dari buku catatan di ruang kerja Azure Machine Learning Anda.
- Kirim eksekusi eksperimen Azure Machine Learning dengan kumpulan Synapse Spark sebagai target komputasi Anda.