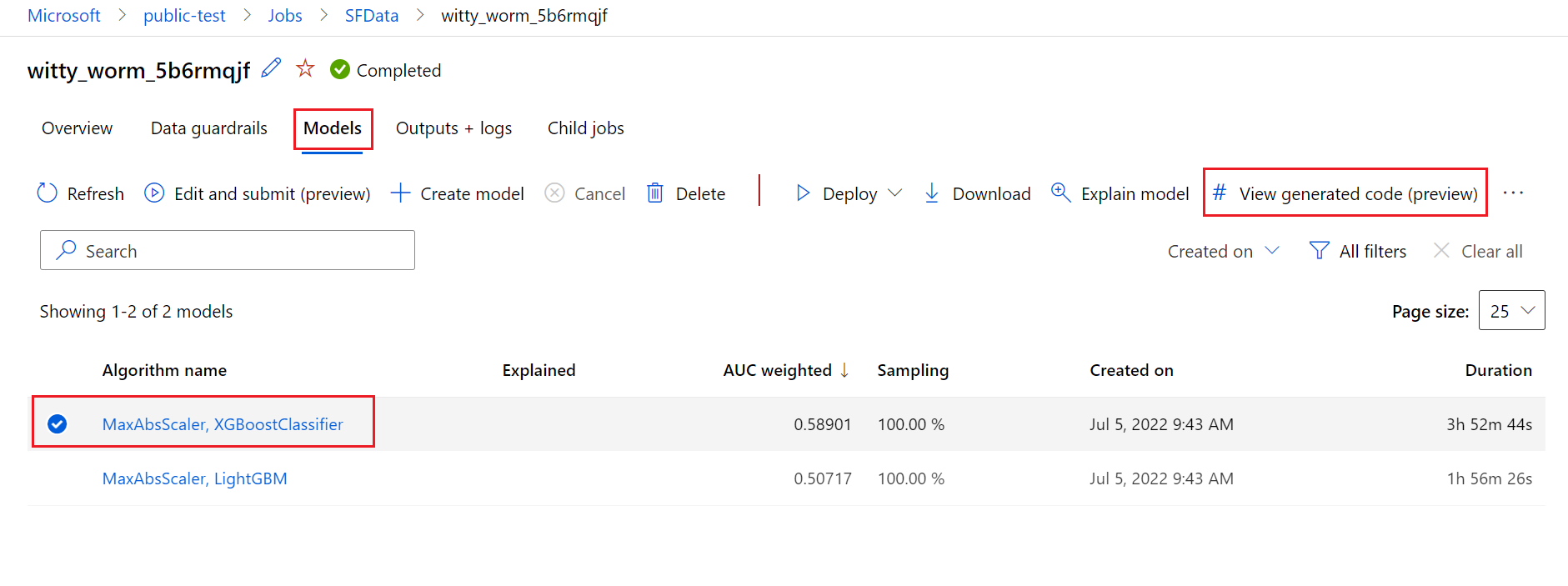
Menampilkan kode pelatihan untuk model ML Otomatis
Dalam artikel ini, Anda mempelajari cara melihat kode pelatihan yang dihasilkan dari model pelatihan pembelajaran mesin otomatis apa pun.
Pembuatan kode untuk model terlatih ML otomatis memungkinkan Anda melihat detail berikut yang digunakan ML otomatis guna melatih dan membuat model untuk proses tertentu.
- Praproses data
- Pemilihan algoritma
- Fiturisasi
- Hiperparameter
Anda dapat memilih model terlatih ML otomatis, yang direkomendasikan atau eksekusi turunan, dan melihat kode pelatihan Python yang dihasilkan yang membuat model spesifik tersebut.
Dengan kode pelatihan model yang dihasilkan, Anda dapat,
- Mempelajari fiturisasi dan hiperparameter apa yang digunakan algoritma model.
- Melacak/membuat versi/mengaudit model terlatih. Simpan kode berversi untuk melacak kode pelatihan spesifik mana yang digunakan dengan model yang akan disebarkan ke produksi.
- Menyesuaikan kode pelatihan dengan mengubah hiperparameter atau menerapkan keterampilan/pengalaman algoritma dan ML, dan melatih kembali model baru dengan kode kustom Anda.
Diagram berikut mengilustrasikan bahwa Anda dapat menghasilkan kode untuk eksperimen ML otomatis dengan semua jenis tugas. Pertama pilih model. Model yang Anda pilih akan disorot, lalu Azure Machine Learning akan menyalin file kode yang digunakan untuk membuat model dan menampilkannya ke folder bersama notebook Anda. Dari sini, Anda dapat melihat dan menyesuaikan kode sesuai kebutuhan.
Prasyarat
Ruang kerja Azure Machine Learning. Untuk membuat ruang kerja, lihat Membuat sumber daya ruang kerja.
Dengan mengikuti artikel ini, Anda diasumsikan memiliki pemahaman akan penyiapan percobaan pembelajaran mesin otomatis. Ikuti tutorial atau cara melihat pola desain percobaan pembelajaran mesin otomatis utama.
Pembuatan kode ML otomatis hanya tersedia untuk eksperimen yang dijalankan pada target komputasi Azure Machine Learning jarak jauh. Pembuatan kode tidak didukung untuk eksekusi lokal.
Semua eksekusi ML otomatis yang dipicu melalui Azure Machine Learning Studio, SDKv2 atau CLIv2 akan mengaktifkan pembuatan kode.
Mendapatkan kode yang dibuat dan artefak model
Secara default, setiap model terlatih ML otomatis menghasilkan kode pelatihannya setelah pelatihan selesai. ML otomatis menyimpan kode ini di outputs/generated_code eksperimen untuk model spesifik tersebut. Anda dapat melihatnya di antarmuka pengguna studio Azure Machine Learning pada tab Output + log dari model yang dipilih.
script.py Ini adalah kode pelatihan model yang mungkin ingin Anda analisis dengan langkah-langkah fiturisasi, algoritma khusus yang digunakan, dan hiperparameter.
script_run_notebook.ipynb Notebook dengan kode pelat boiler untuk menjalankan kode pelatihan model (script.py) di komputasi Azure Machine Learning melalui Azure Machine Learning SDKv2.
Setelah eksekusi pelatihan ML otomatis selesai, ada Anda dapat mengakses script.py file dan script_run_notebook.ipynb melalui antarmuka pengguna studio Azure Machine Learning.
Untuk melakukannya, buka tab Model dari halaman eksekusi induk eksperimen ML otomatis. Setelah memilih salah satu model terlatih, Anda dapat memilih tombol Tampilkan kode yang dihasilkan . Tombol ini mengarahkan Anda ke ekstensi portal Notebook, tempat Anda dapat melihat, mengedit, dan menjalankan kode yang dihasilkan untuk model tertentu yang dipilih.
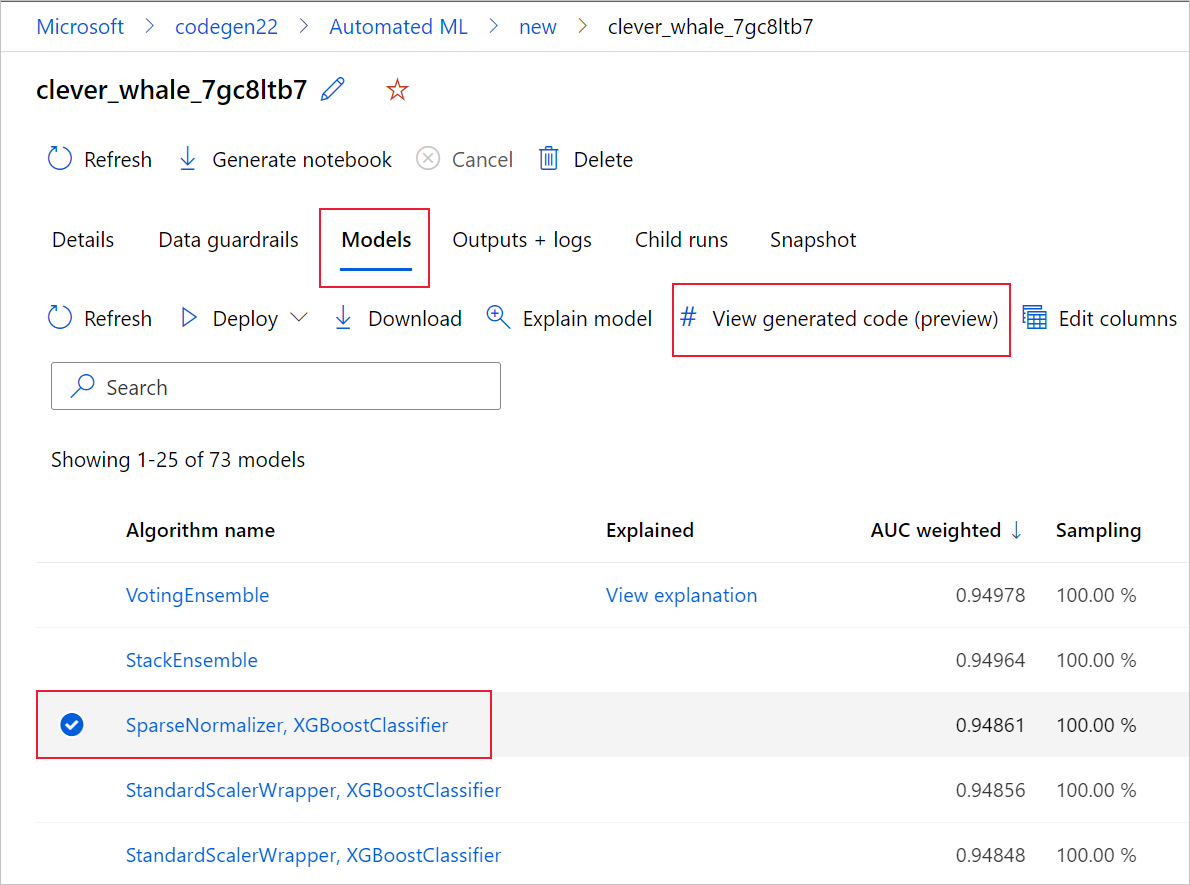
Anda juga dapat mengakses kode model yang dihasilkan dari bagian atas halaman eksekusi anak setelah Anda menavigasi ke halaman eksekusi anak dari model tertentu.
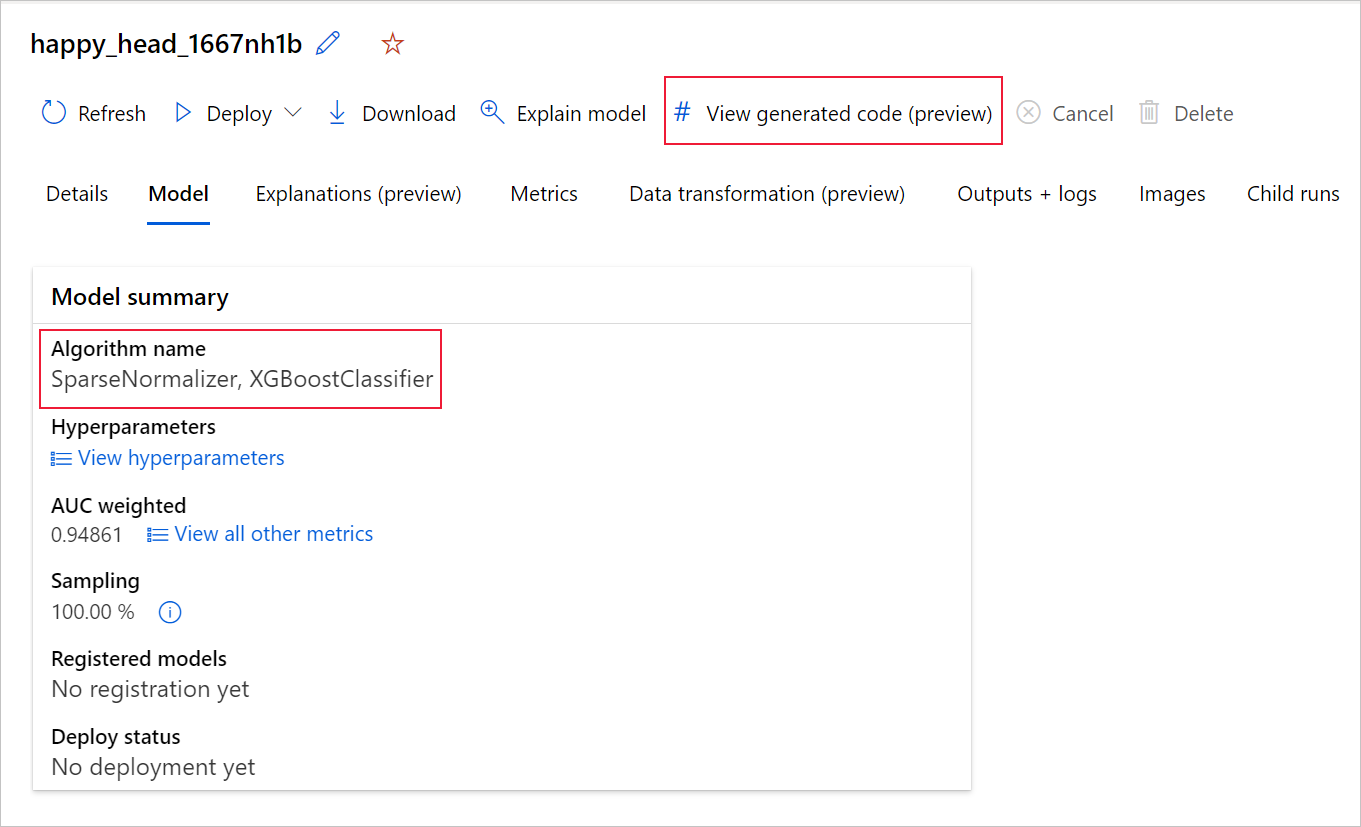
Jika Anda menggunakan Python SDKv2, Anda juga dapat mengunduh "script.py" dan "script_run_notebook.ipynb" dengan mengambil eksekusi terbaik melalui MLFlow & yang mengunduh artefak yang dihasilkan.
script.py
File script.py berisi logika inti yang diperlukan untuk melatih model dengan hiperparameter yang digunakan sebelumnya. Meskipun dimaksudkan untuk dijalankan dalam konteks eksekusi skrip Azure Machine Learning, dengan beberapa modifikasi, kode pelatihan model juga dapat dijalankan mandiri di lingkungan lokal Anda sendiri.
Skrip ini kurang lebih dapat dipecah menjadi beberapa bagian berikut: pemuatan data, penyiapan data, fiturisasi data, spesifikasi praprosesor/algoritma, dan pelatihan.
Pemuatan Data
Fungsi get_training_dataset() memuat himpunan data yang digunakan sebelumnya. Ini mengasumsikan bahwa skrip dijalankan dalam skrip Azure Machine Learning yang dijalankan di bawah ruang kerja yang sama dengan eksperimen asli.
def get_training_dataset(dataset_id):
from azureml.core.dataset import Dataset
from azureml.core.run import Run
logger.info("Running get_training_dataset")
ws = Run.get_context().experiment.workspace
dataset = Dataset.get_by_id(workspace=ws, id=dataset_id)
return dataset.to_pandas_dataframe()
Saat menjalankan sebagai bagian dari eksekusi skrip, Run.get_context().experiment.workspace mengambil ruang kerja yang benar. Namun, jika skrip ini dijalankan di dalam ruang kerja yang berbeda atau berjalan secara lokal, Anda perlu memodifikasi skrip untuk secara eksplisit menentukan ruang kerja yang sesuai.
Setelah ruang kerja telah diambil, himpunan data asli diambil oleh ID-nya. Himpunan data lain dengan struktur yang sama persis juga dapat ditentukan oleh ID atau nama dengan get_by_id() atau get_by_name(). Anda nanti dapat menemukan ID di skrip, di bagian yang sama seperti kode berikut.
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--training_dataset_id', type=str, default='xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxx', help='Default training dataset id is populated from the parent run')
args = parser.parse_args()
main(args.training_dataset_id)
Anda juga dapat memilih untuk mengganti seluruh fungsi ini dengan mekanisme pemuatan data Anda sendiri; satu-satunya batasan adalah bahwa nilai yang dikembalikan harus berupa kerangka data Pandas dan bahwa data harus memiliki bentuk yang sama seperti pada eksperimen awal.
Kode penyiapan data
Fungsi prepare_data() akan membersihkan data, membagi fitur dan kolom berat sampel, serta menyiapkan data untuk digunakan dalam pelatihan.
Fungsi ini dapat bervariasi tergantung pada jenis himpunan data dan jenis tugas eksperimen: klasifikasi, regresi, prakiraan rangkaian waktu, gambar, atau tugas NLP.
Contoh berikut menunjukkan bahwa secara umum, kerangka data dari langkah pemuatan data diteruskan. Jika ditentukan sebelumnya, kolom label dan bobot sampel akan diekstraksi dan baris yang berisi NaN akan dikeluarkan dari data input.
def prepare_data(dataframe):
from azureml.training.tabular.preprocessing import data_cleaning
logger.info("Running prepare_data")
label_column_name = 'y'
# extract the features, target and sample weight arrays
y = dataframe[label_column_name].values
X = dataframe.drop([label_column_name], axis=1)
sample_weights = None
X, y, sample_weights = data_cleaning._remove_nan_rows_in_X_y(X, y, sample_weights,
is_timeseries=False, target_column=label_column_name)
return X, y, sample_weights
Jika ingin melakukan penyiapan data tambahan, Anda dapat melakukannya pada langkah ini dengan menambahkan kode penyiapan data kustom Anda.
Kode fiturisasi data
Fungsi generate_data_transformation_config() menentukan langkah fiturisasi dalam alur akhir scikit-learn. Fitur dari eksperimen asli direproduksi di sini, bersama dengan parameternya.
Misalnya, kemungkinan transformasi data yang dapat terjadi dalam fungsi ini dapat didasarkan pada imputer seperti, SimpleImputer() dan CatImputer(), atau transformator seperti StringCastTransformer() dan LabelEncoderTransformer().
Berikut ini adalah transformator jenis StringCastTransformer() yang dapat digunakan untuk mentransformasikan sekumpulan kolom. Dalam hal ini, set ditunjukkan oleh column_names.
def get_mapper_0(column_names):
# ... Multiple imports to package dependencies, removed for simplicity ...
definition = gen_features(
columns=column_names,
classes=[
{
'class': StringCastTransformer,
},
{
'class': CountVectorizer,
'analyzer': 'word',
'binary': True,
'decode_error': 'strict',
'dtype': numpy.uint8,
'encoding': 'utf-8',
'input': 'content',
'lowercase': True,
'max_df': 1.0,
'max_features': None,
'min_df': 1,
'ngram_range': (1, 1),
'preprocessor': None,
'stop_words': None,
'strip_accents': None,
'token_pattern': '(?u)\\b\\w\\w+\\b',
'tokenizer': wrap_in_lst,
'vocabulary': None,
},
]
)
mapper = DataFrameMapper(features=definition, input_df=True, sparse=True)
return mapper
Perlu diketahui jika Anda memiliki banyak kolom yang perlu menerapkan fiturisasi/transformasi yang sama (misalnya, 50 kolom dalam beberapa grup kolom), kolom tersebut ditangani dengan pengelompokan berdasarkan jenisnya.
Dalam contoh berikut, perhatikan bahwa setiap grup menerapkan pemeta unik. Pemeta ini kemudian diterapkan ke masing-masing kolom grup tersebut.
def generate_data_transformation_config():
from sklearn.pipeline import FeatureUnion
column_group_1 = [['id'], ['ps_reg_01'], ['ps_reg_02'], ['ps_reg_03'], ['ps_car_11_cat'], ['ps_car_12'], ['ps_car_13'], ['ps_car_14'], ['ps_car_15'], ['ps_calc_01'], ['ps_calc_02'], ['ps_calc_03']]
column_group_2 = ['ps_ind_06_bin', 'ps_ind_07_bin', 'ps_ind_08_bin', 'ps_ind_09_bin', 'ps_ind_10_bin', 'ps_ind_11_bin', 'ps_ind_12_bin', 'ps_ind_13_bin', 'ps_ind_16_bin', 'ps_ind_17_bin', 'ps_ind_18_bin', 'ps_car_08_cat', 'ps_calc_15_bin', 'ps_calc_16_bin', 'ps_calc_17_bin', 'ps_calc_18_bin', 'ps_calc_19_bin', 'ps_calc_20_bin']
column_group_3 = ['ps_ind_01', 'ps_ind_02_cat', 'ps_ind_03', 'ps_ind_04_cat', 'ps_ind_05_cat', 'ps_ind_14', 'ps_ind_15', 'ps_car_01_cat', 'ps_car_02_cat', 'ps_car_03_cat', 'ps_car_04_cat', 'ps_car_05_cat', 'ps_car_06_cat', 'ps_car_07_cat', 'ps_car_09_cat', 'ps_car_10_cat', 'ps_car_11', 'ps_calc_04', 'ps_calc_05', 'ps_calc_06', 'ps_calc_07', 'ps_calc_08', 'ps_calc_09', 'ps_calc_10', 'ps_calc_11', 'ps_calc_12', 'ps_calc_13', 'ps_calc_14']
feature_union = FeatureUnion([
('mapper_0', get_mapper_0(column_group_1)),
('mapper_1', get_mapper_1(column_group_3)),
('mapper_2', get_mapper_2(column_group_2)),
])
return feature_union
Dengan pendekatan ini, Anda dapat memiliki kode yang lebih ringkas, tanpa menyertakan blok kode transformator untuk setiap kolom, yang bisa sangat merepotkan bahkan ketika Anda memiliki puluhan atau ratusan kolom dalam himpunan data Anda.
Dengan tugas klasifikasi dan regresi, [FeatureUnion] digunakan untuk fitur.
Untuk model prakiraan deret waktu, beberapa fitur yang sadar deret waktu dikumpulkan ke dalam alur scikit-learn, lalu dikemas dalam TimeSeriesTransformer.
Setiap fiturisasi yang disediakan pengguna untuk model prakiraan deret waktu terjadi sebelum yang disediakan oleh ML otomatis.
Kode spesifikasi praprosesor
Fungsi generate_preprocessor_config(), jika ada, akan menentukan langkah prapemrosesan yang harus dilakukan setelah fiturisasi di jalur akhir scikit-learn.
Biasanya, langkah prapemrosesan ini hanya terdiri dari standarisasi/normalisasi data yang dilakukan dengan sklearn.preprocessing.
ML otomatis hanya menentukan langkah prapemrosesan untuk model regresi dan klasifikasi non-ansambel.
Berikut ini contoh kode praprosesor yang dihasilkan:
def generate_preprocessor_config():
from sklearn.preprocessing import MaxAbsScaler
preproc = MaxAbsScaler(
copy=True
)
return preproc
Kode spesifikasi algoritma dan hiperparameter
Kode spesifikasi algoritma dan hiperparameter kemungkinan adalah yang paling diminati oleh banyak profesional ML.
Fungsi generate_algorithm_config() menentukan algoritma dan hiperparameter aktual untuk melatih model sebagai tahap terakhir dari alur scikit-learn akhir.
Contoh berikut menggunakan algoritma XGBoostClassifier dengan hiperparameter tertentu.
def generate_algorithm_config():
from xgboost.sklearn import XGBClassifier
algorithm = XGBClassifier(
base_score=0.5,
booster='gbtree',
colsample_bylevel=1,
colsample_bynode=1,
colsample_bytree=1,
gamma=0,
learning_rate=0.1,
max_delta_step=0,
max_depth=3,
min_child_weight=1,
missing=numpy.nan,
n_estimators=100,
n_jobs=-1,
nthread=None,
objective='binary:logistic',
random_state=0,
reg_alpha=0,
reg_lambda=1,
scale_pos_weight=1,
seed=None,
silent=None,
subsample=1,
verbosity=0,
tree_method='auto',
verbose=-10
)
return algorithm
Kode yang dihasilkan dalam banyak kasus menggunakan paket dan kelas perangkat lunak sumber terbuka (OSS). Ada contoh ketika kelas pengemas menengah digunakan untuk menyederhanakan kode yang lebih kompleks. Misalnya, pengklasifikasi XGBoost dan pustaka lain yang umum digunakan seperti algoritma LightGBM atau Scikit-Learn dapat diterapkan.
Sebagai Profesional ML, Anda dapat menyesuaikan kode konfigurasi algoritma tersebut dengan mengubah hiperparameternya sesuai kebutuhan berdasarkan keahlian dan pengalaman Anda untuk algoritma tersebut dan masalah ML khusus Anda.
Untuk model ansambel, generate_preprocessor_config_N() (jika diperlukan) dan generate_algorithm_config_N() ditentukan untuk setiap learner dalam model ansambel, dengan N mewakili penempatan setiap learner dalam daftar model ansambel. Untuk model ansambel tumpukan, learner meta generate_algorithm_config_meta() ditentukan.
Kode pelatihan ujung ke ujung
Pembuatan kode memancarkan build_model_pipeline() dan train_model() untuk mendefinisikan alur scikit-learn dan untuk memanggil fit().
def build_model_pipeline():
from sklearn.pipeline import Pipeline
logger.info("Running build_model_pipeline")
pipeline = Pipeline(
steps=[
('featurization', generate_data_transformation_config()),
('preproc', generate_preprocessor_config()),
('model', generate_algorithm_config()),
]
)
return pipeline
Alur scikit-learn mencakup langkah fiturisasi, praprosesor (jika digunakan), dan algoritma atau model.
Untuk model prakiraan deret waktu, alur scikit-learn dikemas dalam ForecastingPipelineWrapper, yang memiliki beberapa logika tambahan yang diperlukan untuk menangani data deret waktu dengan benar bergantung pada algoritma yang diterapkan.
Untuk semua jenis tugas, kami menggunakan PipelineWithYTransformer jika kolom label perlu dikodekan.
Setelah Anda memiliki alur scikit-Learn, yang tersisa untuk dipanggil adalah metode fit() untuk melatih model:
def train_model(X, y, sample_weights):
logger.info("Running train_model")
model_pipeline = build_model_pipeline()
model = model_pipeline.fit(X, y)
return model
Nilai pengembalian dari train_model() merupakan model yang dipasang/dilatih pada data input.
Kode utama yang menjalankan semua fungsi sebelumnya adalah sebagai berikut:
def main(training_dataset_id=None):
from azureml.core.run import Run
# The following code is for when running this code as part of an Azure Machine Learning script run.
run = Run.get_context()
setup_instrumentation(run)
df = get_training_dataset(training_dataset_id)
X, y, sample_weights = prepare_data(df)
split_ratio = 0.1
try:
(X_train, y_train, sample_weights_train), (X_valid, y_valid, sample_weights_valid) = split_dataset(X, y, sample_weights, split_ratio, should_stratify=True)
except Exception:
(X_train, y_train, sample_weights_train), (X_valid, y_valid, sample_weights_valid) = split_dataset(X, y, sample_weights, split_ratio, should_stratify=False)
model = train_model(X_train, y_train, sample_weights_train)
metrics = calculate_metrics(model, X, y, sample_weights, X_test=X_valid, y_test=y_valid)
print(metrics)
for metric in metrics:
run.log(metric, metrics[metric])
Setelah memiliki model terlatih, Anda dapat menggunakannya untuk membuat prediksi dengan metode predict(). Jika eksperimen Anda digunakan untuk model deret waktu, gunakan metode forecast() untuk prediksi.
y_pred = model.predict(X)
Terakhir, model akan diserialkan dan disimpan sebagai file .pkl bernama "model.pkl":
with open('model.pkl', 'wb') as f:
pickle.dump(model, f)
run.upload_file('outputs/model.pkl', 'model.pkl')
script_run_notebook.ipynb
Notebook script_run_notebook.ipynb berfungsi sebagai cara mudah untuk mengeksekusi script.py pada komputasi Azure Machine Learning.
Notebook ini mirip dengan notebook sampel ML otomatis yang ada, namun ada beberapa perbedaan utama seperti yang dijelaskan di bagian berikut.
Lingkungan
Biasanya, lingkungan pelatihan untuk menjalankan ML otomatis diatur secara otomatis oleh SDK. Namun, saat menjalankan skrip kustom berjalan seperti kode yang dihasilkan, ML otomatis tidak lagi mendorong proses, sehingga lingkungan harus ditentukan agar pekerjaan perintah berhasil.
Pembuatan kode menggunakan kembali lingkungan yang digunakan dalam eksperimen ML otomatis asli, jika memungkinkan. Tindakan ini akan menjamin eksekusi skrip pelatihan tidak gagal akibat dependensi yang hilang, dan memiliki keuntungan sampingan karena tidak memerlukan pembangunan kembali citra Docker, yang menghemat waktu dan sumber daya komputasi.
Jika Anda membuat perubahan pada script.py yang memerlukan dependensi tambahan, atau Anda ingin menggunakan lingkungan Anda sendiri, Anda perlu memperbarui lingkungan di yang script_run_notebook.ipynb sesuai.
Mengirim eksperimen
Karena kode yang dihasilkan tidak didorong oleh ML otomatis lagi, alih-alih membuat dan mengirimkan Pekerjaan AutoML, Anda perlu membuat Command Job dan memberikan kode yang dihasilkan (script.py) ke dalamnya.
Contoh berikut berisi parameter dan dependensi reguler yang diperlukan untuk menjalankan Pekerjaan Perintah, seperti komputasi, lingkungan, dll.
from azure.ai.ml import command, Input
# To test with new training / validation datasets, replace the default dataset id(s) taken from parent run below
training_dataset_id = '<DATASET_ID>'
dataset_arguments = {'training_dataset_id': training_dataset_id}
command_str = 'python script.py --training_dataset_id ${{inputs.training_dataset_id}}'
command_job = command(
code=project_folder,
command=command_str,
environment='AutoML-Non-Prod-DNN:25',
inputs=dataset_arguments,
compute='automl-e2e-cl2',
experiment_name='build_70775722_9249eda8'
)
returned_job = ml_client.create_or_update(command_job)
print(returned_job.studio_url) # link to naviagate to submitted run in Azure Machine Learning Studio
Langkah berikutnya
- Pelajari selengkapnya tentang cara dan tempat menerapkan model.
- Lihat cara mengaktifkan fitur interpretabilitas khususnya dalam eksperimen ML otomatis.