Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Azure Managed Instance for Apache Cassandra menyediakan operasi penyebaran dan penskalaan otomatis untuk pusat data Apache Cassandra sumber terbuka terkelola. Fitur ini mempercepat skenario hibrid dan membantu mengurangi pemeliharaan yang sedang berlangsung.
Mulai cepat ini menunjukkan cara menggunakan portal Microsoft Azure untuk membuat kluster Apache Spark yang dikelola sepenuhnya di dalam jaringan virtual Azure dari kluster Azure Managed Instance for Apache Cassandra Anda. Anda membuat kluster Spark di Azure Databricks. Nantinya, Anda dapat membuat atau melampirkan buku catatan ke kluster, membaca data dari sumber data yang berbeda, dan menganalisis wawasan.
Anda juga dapat mempelajari lebih lanjut dengan instruksi terperinci tentang Menyebarkan Azure Databricks di jaringan virtual Azure Anda (injeksi jaringan virtual).
Prasyarat
Jika Anda tidak memiliki langganan Azure, buat akun gratis sebelum Anda memulai.
Membuat kluster Azure Databricks
Ikuti langkah-langkah ini untuk membuat kluster Azure Databricks di jaringan virtual yang memiliki Azure Managed Instance for Apache Cassandra:
Masuk ke portal Azure.
Di panel kiri, temukan Grup sumber daya. Akses grup sumber daya Anda yang berisi jaringan virtual tempat instans terkelola Anda disebarkan.
Buka sumber daya Jaringan virtual, dan catat ruang Alamat.
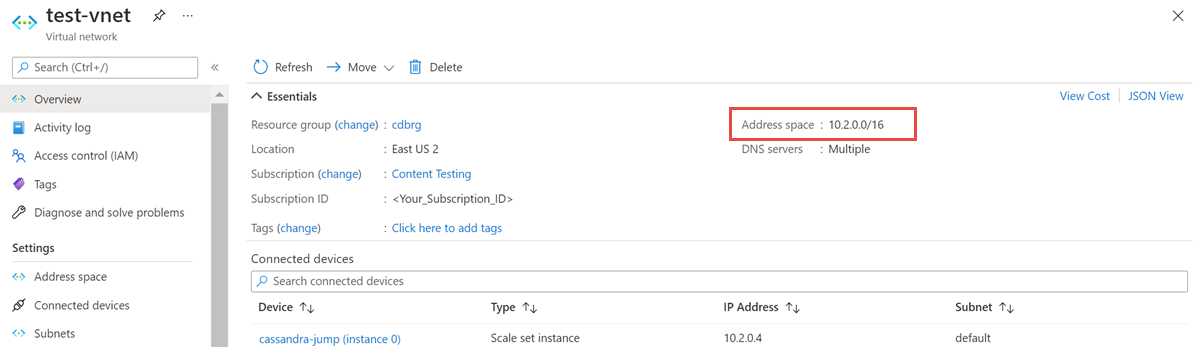
Dari grup sumber daya, pilih Tambahkan dan cari Azure Databricks di bidang pencarian.
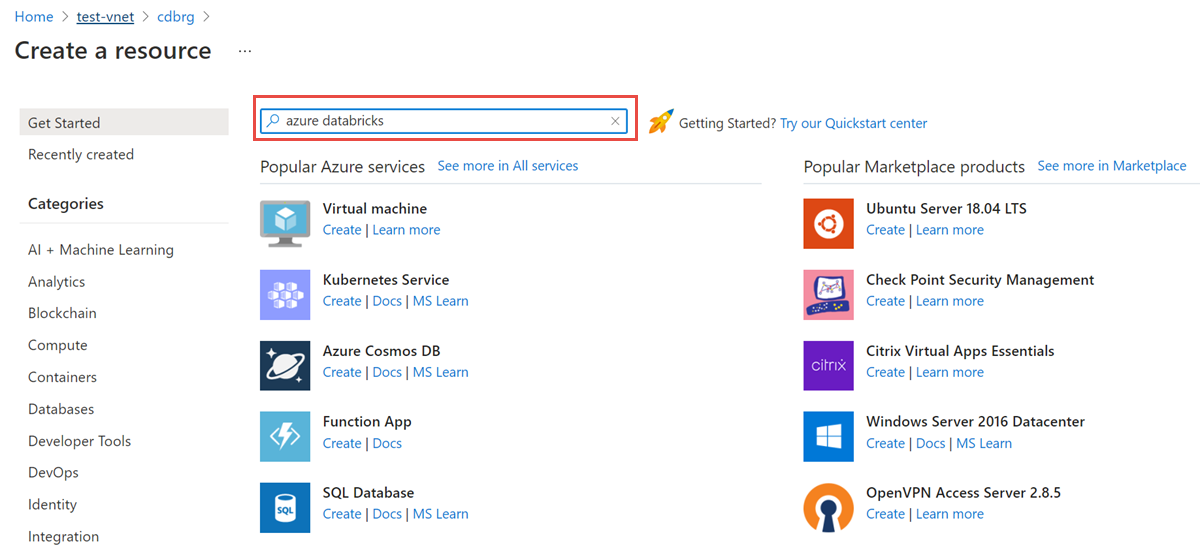
Pilih Buat untuk membuat akun Azure Databricks.
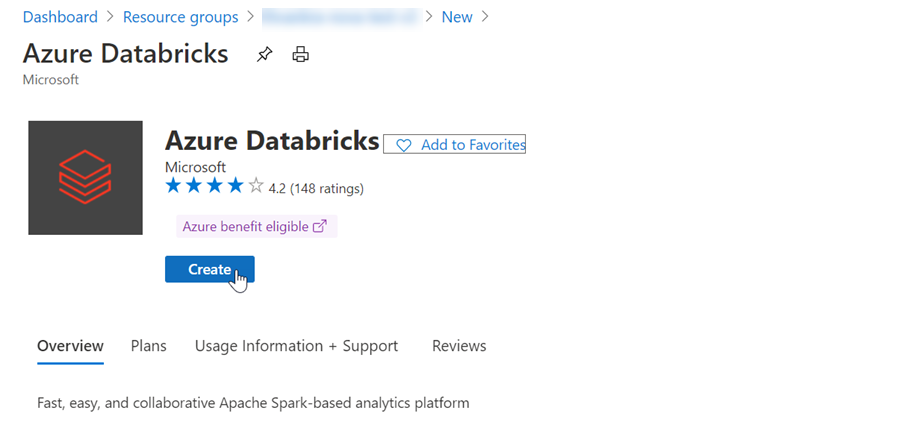
Masukkan nilai berikut:
- Nama ruang kerja: Berikan nama untuk ruang kerja Azure Databricks Anda.
- Wilayah: Pastikan untuk memilih wilayah yang sama dengan jaringan virtual Anda.
- Tingkat Harga: Pilih Standar, Premium, atau Uji Coba. Untuk informasi selengkapnya tentang tingkatan ini, lihat halaman harga Azure Databricks.
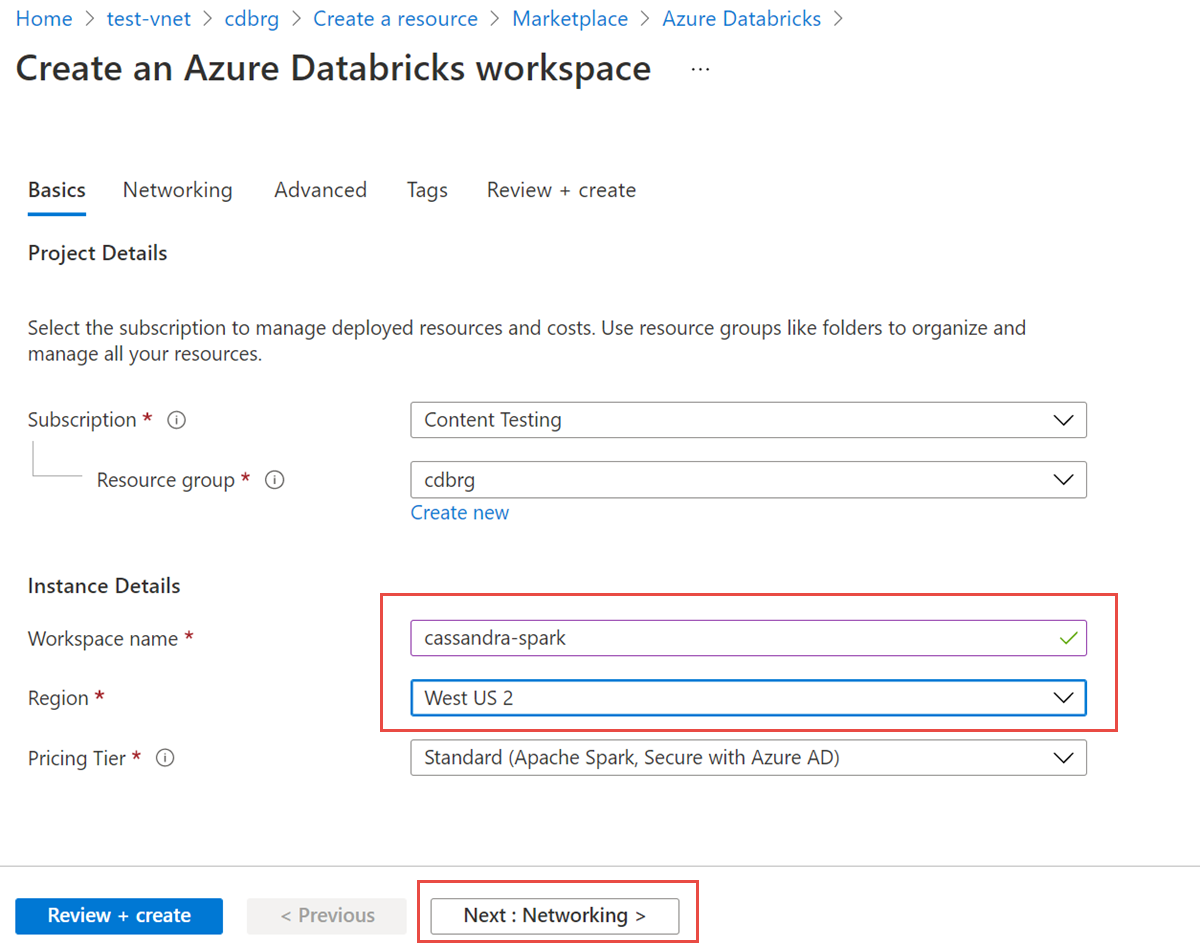
Pilih tab Jaringan , dan masukkan detail berikut ini:
- Menyebarkan ruang kerja Azure Databricks di Virtual Network (VNet) Anda: Pilih Ya.
- Virtual Network: Dari daftar dropdown, pilih jaringan virtual tempat instans terkelola Anda berada.
- Nama Subnet Publik: Masukkan nama untuk subnet publik.
- Rentang CIDR Subnet Publik: Masukkan rentang IP untuk subnet publik.
- Nama Subnet Privat: Masukkan nama untuk subnet privat.
- Rentang CIDR Subnet Privat: Masukkan rentang IP untuk subnet privat.
Untuk menghindari tabrakan rentang, pastikan Anda memilih rentang yang lebih tinggi. Jika perlu, gunakan kalkulator subnet visual untuk membagi rentang.
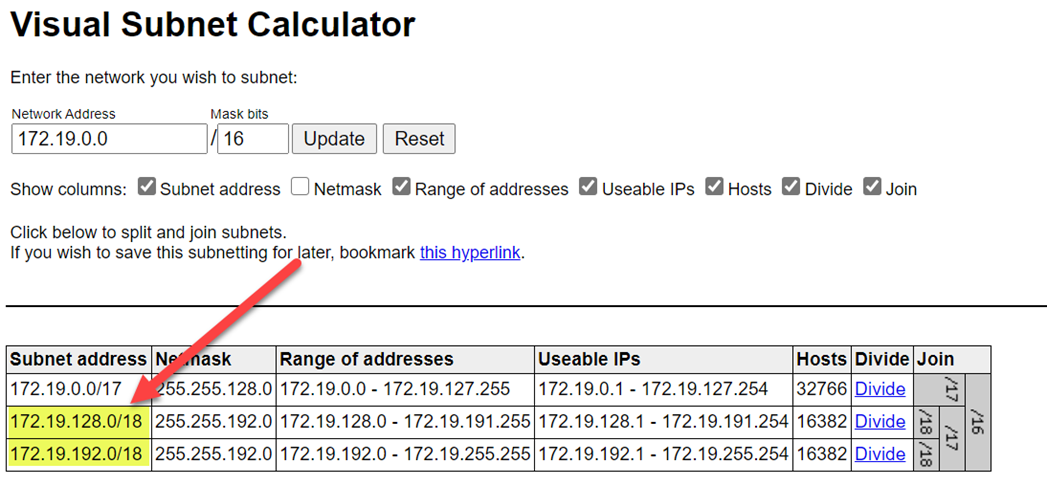
Cuplikan layar berikut ini memperlihatkan contoh detail pada panel jaringan.
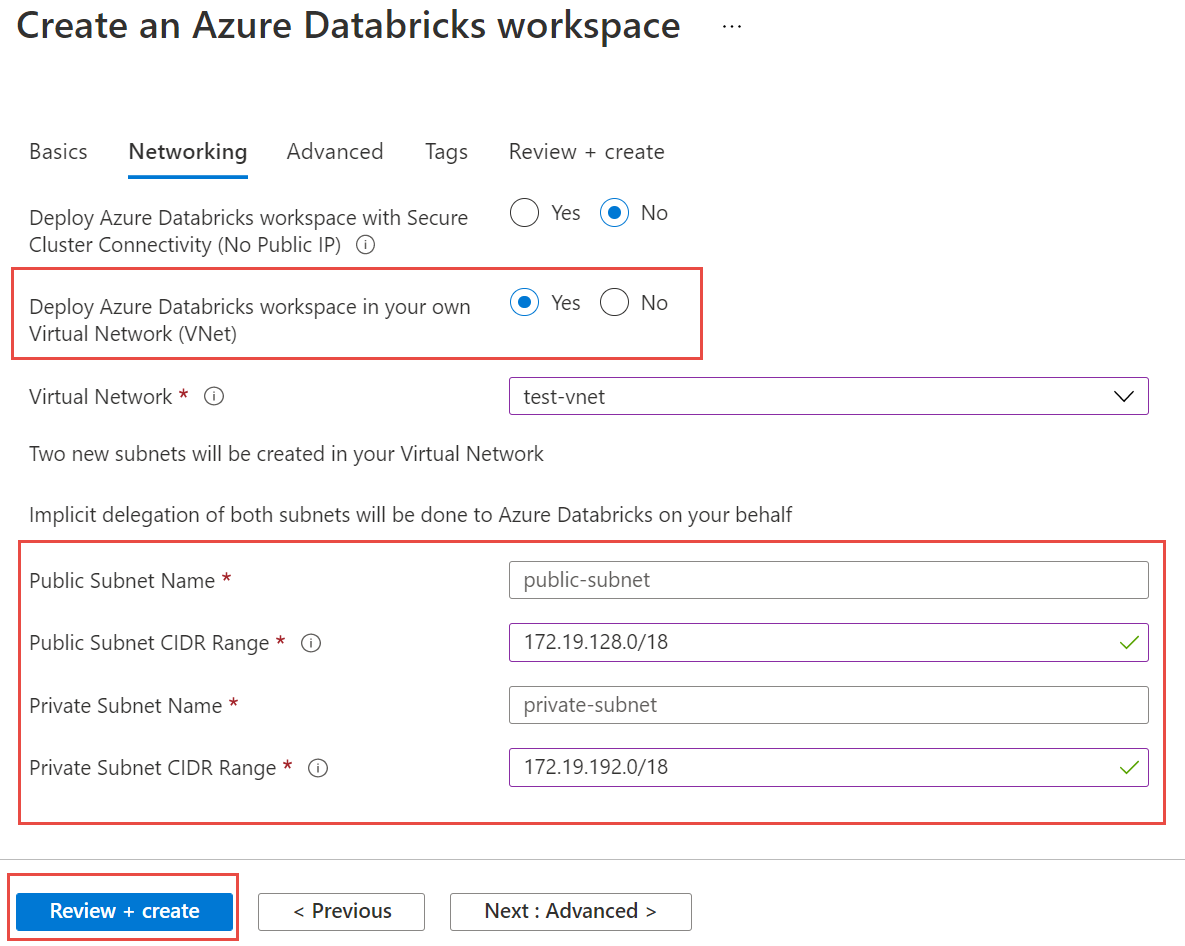
Pilih Tinjau + buat, lalu pilih Buat untuk menyebarkan ruang kerja.
Buka ruang kerja setelah ruang kerja tersebut dibuat.
Anda dialihkan ke portal Azure Databricks. Dari portal, pilih Kluster Baru.
Pada panel Kluster baru , terima nilai default untuk semua bidang selain bidang berikut ini:
- Nama Kluster: Masukkan nama untuk kluster.
- Versi Runtime Databricks: Kami sarankan Anda memilih runtime Azure Databricks versi 7.5 atau yang lebih baru, untuk dukungan Spark 3.x.

Perluas Opsi Tingkat Lanjut, dan tambahkan konfigurasi berikut. Pastikan untuk mengganti IP node dan kredensial.
spark.cassandra.connection.host <node1 IP>,<node 2 IP>, <node IP> spark.cassandra.auth.password cassandra spark.cassandra.connection.port 9042 spark.cassandra.auth.username cassandra spark.cassandra.connection.ssl.enabled trueAnda perlu menambahkan pustaka Apache Spark Cassandra Connector ke kluster Anda untuk tersambung ke titik akhir asli dan Azure Cosmos DB Cassandra. Di kluster Anda, pilih Pustaka>Instal Maven Baru>, lalu tambahkan
com.datastax.spark:spark-cassandra-connector-assembly_2.12:3.0.0di bidang Koordinat Maven.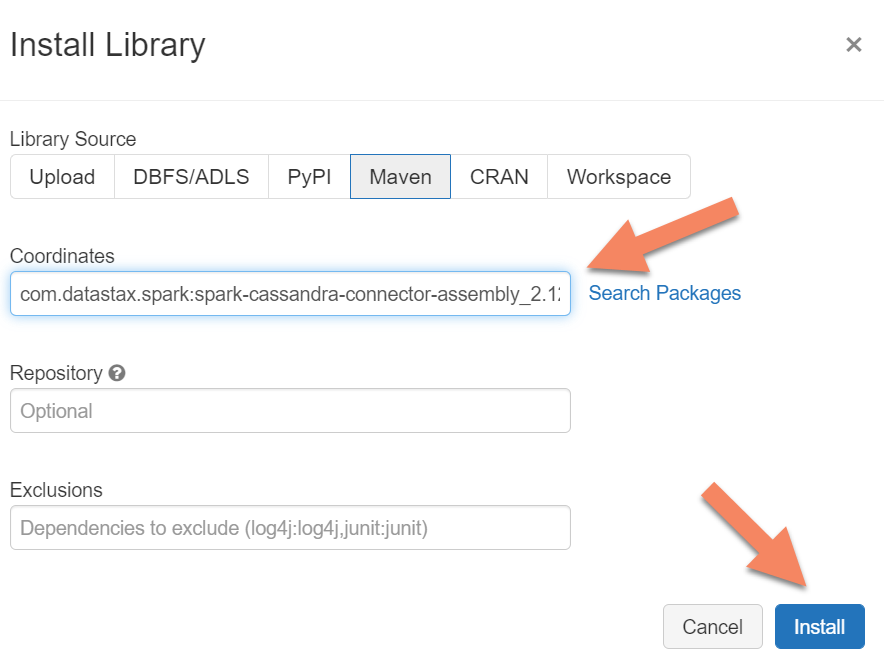
Pilih Instal.
Membersihkan sumber daya
Jika Anda tidak akan terus menggunakan kluster instans terkelola ini, ikuti langkah-langkah berikut untuk menghapusnya:
- Di menu sebelah kiri portal Microsoft Azure, pilih Grup sumber daya.
- Dari daftar, pilih grup sumber daya yang Anda buat untuk quickstart ini.
- Pada panel Ringkasan grup sumber daya, pilih Hapus grup sumber daya.
- Pada panel berikutnya, masukkan nama grup sumber daya yang akan dihapus, lalu pilih Hapus.
Langkah selanjutnya
Dalam panduan memulai cepat ini, Anda mempelajari cara membuat kluster Apache Spark yang dikelola sepenuhnya di dalam jaringan virtual kluster dari Azure Managed Instance untuk kluster Apache Cassandra Anda. Selanjutnya, pelajari cara mengelola sumber daya kluster dan pusat data.