Keandalan di Azure Traffic Manager
Artikel ini berisi rekomendasi keandalan khusus untuk Azure Traffic Manager serta pemulihan bencana lintas wilayah dan dukungan kelangsungan bisnis untuk Azure Traffic Manager.
Untuk gambaran umum yang lebih rinci tentang prinsip keandalan di Azure, lihat Keandalan Azure.
Rekomendasi keandalan
Bagian ini berisi rekomendasi untuk mencapai ketahanan dan ketersediaan. Setiap rekomendasi termasuk dalam salah satu dari dua kategori:
Item kesehatan mencakup area seperti item konfigurasi dan fungsi yang tepat dari komponen utama yang membentuk Azure Workload Anda, seperti pengaturan konfigurasi Sumber Daya Azure, dependensi pada layanan lain, dan sebagainya.
Item risiko mencakup area seperti persyaratan ketersediaan dan pemulihan, pengujian, pemantauan, penyebaran, dan item lain yang, jika dibiarkan tidak terselesaikan, meningkatkan kemungkinan masalah di lingkungan.
Matriks prioritas rekomendasi keandalan
Setiap rekomendasi ditandai sesuai dengan matriks prioritas berikut:
| Gambar | Prioritas | Deskripsi |
|---|---|---|
| Sangat Penting | Perbaikan langsung diperlukan. | |
| Medium | Perbaiki dalam waktu 3-6 bulan. | |
| Kurang Penting | Perlu ditinjau. |
Ringkasan rekomendasi keandalan
Ketersediaan
 Status Monitor Traffic Manager harus Online
Status Monitor Traffic Manager harus Online
Status pemantauan harus online untuk menyediakan failover untuk beban kerja aplikasi. Jika kesehatan Traffic Manager Anda menampilkan status Terdegradasi , maka status satu atau beberapa titik akhir juga dapat Diturunkan.
Untuk informasi selengkapnya tentang pemantauan titik akhir Traffic Manager, lihat Pemantauan titik akhir Traffic Manager.
Untuk memecahkan masalah status terdegradasi di Azure Traffic Manager, lihat Memecahkan masalah status terdegradasi di Azure Traffic Manager.
Profil traffic manager harus memiliki lebih dari satu titik akhir
Saat mengonfigurasi azure traffic manager, Anda harus menyediakan minimal dua titik akhir untuk melakukan failover beban kerja ke instans lain.
Untuk mempelajari tentang jenis titik akhir Traffic Manager, lihat Titik akhir Traffic Manager.
Efisiensi Sistem
 Nilai TTL profil pengguna harus dalam 60 detik
Nilai TTL profil pengguna harus dalam 60 detik
Time to Live (TTL) memengaruhi tingkat kebaruan respons yang akan dilakukan klien saat mengajukan permintaan ke Azure Traffic Manager. Mengurangi nilai TTL berarti klien akan diarahkan ke titik akhir yang berfungsi lebih cepat jika terjadi kegagalan. Konfigurasikan TTL Anda hingga 60 detik untuk merutekan lalu lintas ke titik akhir kesehatan secepat mungkin.
Untuk informasi selengkapnya tentang mengonfigurasi DNS TTL, lihat Mengonfigurasi DNS Time to Live.
Pemulihan dari bencana
Mengonfigurasi setidaknya satu titik akhir dalam wilayah lain
Profil harus memiliki lebih dari satu titik akhir untuk memastikan ketersediaan jika salah satu titik akhir gagal. Disarankan juga bahwa titik akhir berada di berbagai wilayah.
Untuk mempelajari tentang jenis titik akhir Traffic Manager, lihat Titik akhir Traffic Manager.
Pastikan titik akhir dikonfigurasi ke "(Semua Dunia)" untuk profil geografis
Untuk perutean geografis, lalu lintas diarahkan ke titik akhir berdasarkan wilayah yang ditentukan. Jika suatu wilayah gagal, tidak ada failover yang telah ditentukan sebelumnya. Memiliki titik akhir di mana Pengelompokan Regional dikonfigurasi ke "Semua (Dunia)" untuk profil geografis akan menghindari pengait hitam lalu lintas dan menjamin layanan tetap tersedia.
Untuk mempelajari cara menambahkan dan mengonfigurasi titik akhir, lihat Menambahkan, menonaktifkan, mengaktifkan, menghapus, atau memindahkan titik akhir.
Pemulihan bencana lintas wilayah dan kelangsungan bisnis
Pemulihan bencana (DR) adalah tentang pemulihan dari peristiwa berdampak tinggi, seperti bencana alam atau penyebaran gagal yang mengakibatkan waktu henti dan kehilangan data. Terlepas dari penyebabnya, obat terbaik untuk bencana adalah rencana DR yang terdefinisi dan teruji dengan baik dan desain aplikasi yang secara aktif mendukung DR. Sebelum Anda mulai berpikir tentang membuat rencana pemulihan bencana Anda, lihat Rekomendasi untuk merancang strategi pemulihan bencana.
Ketika datang ke DR, Microsoft menggunakan model tanggung jawab bersama. Dalam model tanggung jawab bersama, Microsoft memastikan bahwa infrastruktur dasar dan layanan platform tersedia. Pada saat yang sama, banyak layanan Azure tidak secara otomatis mereplikasi data atau mundur dari wilayah yang gagal untuk mereplikasi silang ke wilayah lain yang diaktifkan. Untuk layanan tersebut, Anda bertanggung jawab untuk menyiapkan rencana pemulihan bencana yang berfungsi untuk beban kerja Anda. Sebagian besar layanan yang berjalan pada penawaran platform as a service (PaaS) Azure menyediakan fitur dan panduan untuk mendukung DR dan Anda dapat menggunakan fitur khusus layanan untuk mendukung pemulihan cepat untuk membantu mengembangkan rencana DR Anda.
Azure Traffic Manager adalah penyeimbang beban lalu lintas berbasis DNS yang memungkinkan Anda mendistribusikan lalu lintas ke aplikasi publik Anda di seluruh wilayah Azure global. Traffic Manager juga menyediakan titik akhir publik Anda dengan ketersediaan tinggi dan respons cepat.
Traffic Manager menggunakan DNS untuk mengarahkan permintaan klien ke titik akhir layanan yang sesuai berdasarkan metode perutean lalu lintas. Manajer lalu lintas juga menyediakan pemantauan kesehatan untuk setiap titik akhir. Titik akhir dapat menjadi layanan yang menghadap internet yang dihosting di dalam atau di luar Azure. Traffic Manager menyediakan berbagai metode perutean lalu lintas dan opsi pemantauan titik akhiragar sesuai dengan kebutuhan aplikasi yang berbeda dan model failover otomatis. Traffic Manager tahan terhadap kegagalan, termasuk kegagalan seluruh wilayah Azure.
Pemulihan bencana dalam geografi multi-wilayah
DNS adalah salah satu mekanisme paling efisien untuk mengalihkan lalu lintas jaringan. DNS efisien karena DNS sering bersifat global dan eksternal ke pusat data. DNS juga diisolasi dari kegagalan tingkat regional atau zona ketersediaan (AZ).
Ada dua aspek teknis untuk menyiapkan arsitektur pemulihan bencana Anda:
Penggunaan mekanisme penyebaran untuk mereplikasi instans, data, dan konfigurasi antara lingkungan utama dan siaga. Jenis pemulihan bencana ini dapat dilakukan secara asli melalui Azure Site Recovery, lihat Dokumentasi Azure Site Recovery melalui appliance/layanan mitra Microsoft Azure seperti Veritas atau NetApp.
Pengembangan solusi untuk mengalihkan lalu lintas jaringan/web dari situs utama ke situs siaga. Jenis pemulihan bencana ini dapat dicapai melalui Azure DNS, Azure Traffic Manager (DNS), atau penyeimbang beban global pihak ketiga.
Artikel ini berfokus khusus pada perencanaan pemulihan bencana Azure Traffic Manager.
Deteksi, pemberitahuan, dan manajemen pemadaman
Selama bencana, titik akhir utama akan dicari dan status berubah menjadi terdegradasi dan situs pemulihan bencana tetap Online. Secara default, Traffic Manager mengirimkan semua lalu lintas ke titik akhir utama (prioritas tertinggi). Jika titik akhir utama tampak terdegradasi, Traffic Manager merutekan lalu lintas ke titik akhir kedua selama ia tetap sehat. Seseorang dapat mengonfigurasi lebih banyak titik akhir dalam Traffic Manager yang dapat berfungsi sebagai titik akhir perlindungan kegagalan ekstra, atau, sebagai penyeimbang beban yang berbagi beban antar titik akhir.
Menyiapkan pemulihan bencana dan deteksi pemadaman
Ketika Anda memiliki arsitektur yang kompleks dan beberapa set sumber daya yang mampu melakukan fungsi yang sama, Anda dapat mengonfigurasi Azure Traffic Manager (berdasarkan DNS) untuk memeriksa kesehatan sumber daya Anda dan merutekan lalu lintas dari sumber daya yang tidak sehat ke sumber daya yang sehat.
Dalam contoh berikut, wilayah primer maupun wilayah sekunder memiliki penyebaran penuh. Penyebaran ini mencakup layanan cloud dan database yang disinkronkan.
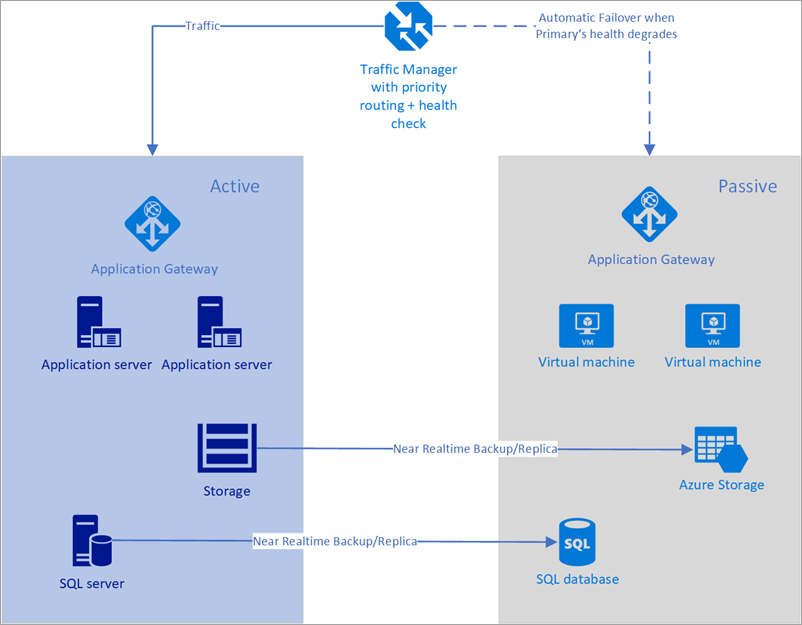
Figur - Failover otomatis menggunakan Azure Traffic Manager
Akan tetapi, hanya wilayah primer yang secara aktif menangani permintaan jaringan dari pengguna. Wilayah sekunder akan aktif hanya saat wilayah primer mengalami gangguan layanan. Dalam hal ini, semua permintaan jaringan baru dirutekan ke wilayah sekunder. Karena pencadangan database hampir seketika, semua penyeimbang beban memiliki IP yang dapat diperiksa kesehatannya, dan instans selalu aktif dan berjalan, topologi ini menyediakan pilihan untuk masuk ke RTO rendah dan perlindungan kegagalan tanpa intervensi manual. Wilayah perlindungan kegagalan sekunder harus siap sedia bekerja segera manakala terjadi kegagalan wilayah primer.
Skenario ini ideal untuk penggunaan Azure Traffic Manager yang memiliki probe bawaan untuk berbagai jenis pemeriksaan kesehatan termasuk http / https dan TCP. Azure Traffic Manager juga memiliki mesin aturan yang dapat dikonfigurasi untuk melindungi kegagalan ketika kegagalan terjadi seperti yang dijelaskan di bawah ini. Mari pertimbangkan solusi berikut untuk menggunakan Traffic Manager:
- Pelanggan memiliki titik akhir Region #1 yang dikenal sebagai prod.contoso.com dengan IP statis 100.168.124.44 dan titik akhir wilayah #2 yang dikenal sebagai dr.contoso.com dengan IP statis 100.168.124.43.
- Masing-masing lingkungan ini dikedepankan melalui properti yang menghadap publik seperti penyeimbang beban. Penyeimbang beban dapat dikonfigurasi untuk memiliki titik akhir berbasis DNS atau nama domain yang sepenuhnya memenuhi syarat (FQDN) seperti yang ditampilkan di atas.
- Semua instans di Wilayah 2 merupakan replikasi mendekati waktu nyata dari Wilayah 1. Selain itu, gambar mesin selalu diperbarui, dan semua data perangkat lunak/konfigurasi di-patch dan sejalan dengan Wilayah 1.
- Penyekalaan otomatis telah dikonfigurasi terlebih dahulu.
Untuk mengonfigurasi failover dengan Azure Traffic Manager:
Buat profil Azure Traffic Manager baru Buat profil Azure Traffic manager baru dengan nama contoso123 dan pilih metode Perutean sebagai Prioritas. Jika Anda memiliki grup sumber daya yang sudah ada sebelumnya yang ingin Anda kaitkan, maka Anda dapat memilih grup sumber daya yang ada, jika tidak, membuat grup sumber daya baru.
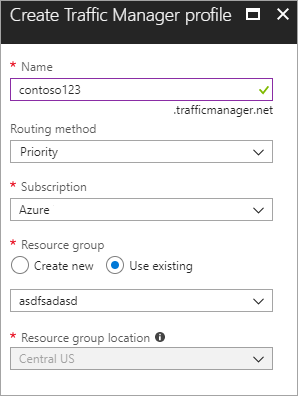
Figur - Membuat profil Traffic Manager
Membuat titik akhir dalam profil Traffic Manager
Dalam langkah ini, Anda membuat titik akhir yang mengarah ke situs produksi dan pemulihan bencana. Di sini, pilih Jenis sebagai titik akhir eksternal, tetapi jika sumber daya di-host di Azure, maka Anda juga dapat memilih Titik akhir Azure. Jika Anda memilih Titik akhir Azure, berikutnya pilih Sumber daya target yang merupakan App Service atau IP Publik yang dialokasikan oleh Azure. Prioritas diatur sebagai 1 karena ini adalah layanan utama untuk Wilayah 1. Demikian pula, buat juga titik akhir pemulihan bencana dalam Traffic Manager.
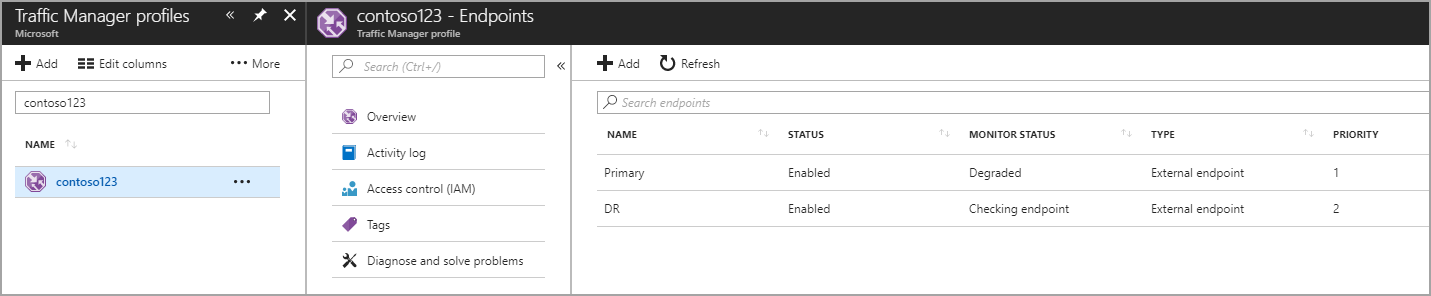
Figur - Membuat titik akhir pemulihan bencana
Menyiapkan konfigurasi pemeriksaan kesehatan dan perlindungan kegagalan
Dalam langkah ini, Anda mengatur DNS TTL ke 10 detik, yang dikenali oleh sebagian besar penyelesai masalah berulang yang menghadap internet. Konfigurasi ini artinya tidak ada penyelesai masalah DNS yang akan menembolok informasi selama lebih dari 10 detik.
Untuk pengaturan monitor titik akhir, jalur saat ini diatur dengan / atau root, tetapi Anda dapat mengkustomisasi pengaturan titik akhir untuk mengevaluasi jalur, contohnya, prod.contoso.com/index.
Contoh di bawah ini menampilkan https sebagai protokol pencarian. Akan tetapi, Anda juga dapat memilih http atau tcp. Pilihan protokol tergantung pada aplikasi akhir. Interval pencarian diatur ke 10 detik, yang memungkinkan pencarian cepat, dan coba lagi diatur ke 3. Akibatnya, Traffic Manager akan melindungi kegagalan titik akhir kedua jika tiga interval berturut-turut mendaftarkan kegagalan.
Rumus berikut menentukan total waktu untuk failover otomatis:
Time for failover = TTL + Retry * Probing intervalDan dalam hal ini, nilainya adalah 10 + 3 * 10 = 40 detik (Maks).
Jika Coba Lagi diatur ke 1 dan TTL diatur ke 10 detik, maka waktu untuk perlindungan kegagalan = 10 + 1 * 10 = 20 detik.
Atur Coba Lagi ke nilai yang lebih besar dari 1 untuk menghilangkan kemungkinan perlindungan kegagalan karena positif palsu atau kedipan jaringan minor apa pun.
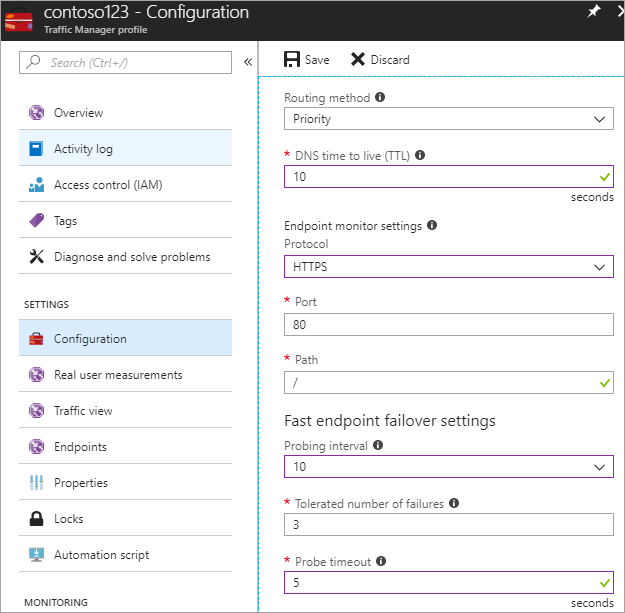
Figur - Menyiapkan konfigurasi pemeriksaan kesehatan dan perlindungan kegagalan
Langkah berikutnya
Pelajari selengkapnya tentang Azure Traffic Manager.
Pelajari selengkapnya tentang Azure DNS.