Buat himpunan data Azure Machine Learning dari Azure Open Datasets
Perhatian
Artikel ini mereferensikan CentOS, distribusi Linux yang mendekati status End Of Life (EOL). Harap pertimbangkan penggunaan dan perencanaan Anda yang sesuai. Untuk informasi selengkapnya, lihat panduan Akhir Masa Pakai CentOS.
Dalam artikel ini, Anda mempelajari cara membawa data pengayaan yang dikurasi ke dalam eksperimen pembelajaran mesin lokal atau jarak jauh dengan himpunan data Azure Machine Learning dan Azure Open Datasets.
Dengan membuat Himpunan data Azure Machine Learning, Anda membuat referensi ke lokasi sumber data, beserta salinan metadatanya. Karena himpunan data jarang dievaluasi, dan data tetap berada di lokasi yang ada, Anda
- Tidak dikenakan biaya penyimpanan tambahan.
- Tidak berisiko mengubah sumber data asli Anda secara tidak sengaja.
- Tingkatkan kecepatan performa alur kerja Pembelajaran Mesin.
Untuk mengetahui letak yang sesuai untuk himpunan data di alur kerja akses data keseluruhan Azure Machine Learning, baca artikel Mengakses data dengan aman.
Azure Open Datasets adalah himpunan data publik yang dikurasi yang dapat digunakan untuk menambahkan fitur khusus skenario guna memperkaya solusi prediktif Anda dan meningkatkan akurasinya. Lihat Katalog Open Datasets untuk mendapatkan data domain publik yang dapat membantu Anda melatih model pembelajaran mesin, seperti:
- cuaca
- sensus
- hari libur
- keamanan publik
- lokasi
Open Datasets berada di awan di Microsoft Azure dan disertakan dalam Azure Machine Learning Python SDK dan studio Azure Machine Learning.
Prasyarat
Untuk artikel ini, Anda memerlukan:
Langganan Azure. Jika Anda tidak memilikinya, buat akun gratis sebelum memulai. Coba versi gratis atau berbayar Azure Machine Learning.
Azure Machine Learning SDK untuk Python diinstal, yang mencakup paket
azureml-datasets.- Buat instans komputasi Azure Machine Learning, yang merupakan lingkungan pengembangan yang dikonfigurasi dan dikelola sepenuhnya yang berisi buku catatan terintegrasi dan SDK yang sudah dipasang.
ATAU
- Lakukan di lingkungan Python Anda dan instal SDK berdasarkan petunjuk ini.
Catatan
Beberapa kelas himpunan data memiliki dependensi pada paket azureml-dataprep, yang hanya kompatibel dengan Python 64-bit. Untuk pengguna Linux, kelas tersebut hanya didukung pada distribusi berikut: Red Hat Enterprise Linux (7, 8), Ubuntu (14.04, 16.04, 18.04), Fedora (27, 28), Debian (8, 9), dan CentOS (7).
Buat himpunan data dengan SDK
Untuk membuat himpunan data Azure Machine Learning melalui kelas Azure Open Datasets di Python SDK, pastikan Anda telah menginstal paket dengan pip install azureml-opendatasets. Setiap himpunan data diskrit diwakili oleh kelasnya sendiri di SDK, dan kelas tertentu tersedia sebagai Azure Machine LearningTabularDataset, FileDataset, atau keduanya. Lihat dokumentasi referensi untuk daftar lengkap kelas opendatasets.
Anda dapat mengambil kelas opendatasets tertentu sebagai TabularDataset atau FileDataset, yang memungkinkan Anda untuk memanipulasi dan/atau mengunduh file secara langsung. Kelas lain bisa mendapatkan himpunan data hanya dengan menggunakan get_tabular_dataset() atau fungsi get_file_dataset() dari kelas Dataset di Python SDK.
Kode berikut menunjukkan bahwa kelas opendatasets MNIST dapat mengembalikan TabularDataset atau FileDataset.
from azureml.core import Dataset
from azureml.opendatasets import MNIST
# MNIST class can return either TabularDataset or FileDataset
tabular_dataset = MNIST.get_tabular_dataset()
file_dataset = MNIST.get_file_dataset()
Dalam contoh ini, kelas opendatasets Diabetes hanya tersedia sebagai TabularDataset, sehingga menggunakan get_tabular_dataset().
from azureml.opendatasets import Diabetes
from azureml.core import Dataset
# Diabetes class can return ONLY TabularDataset and must be called from the static function
diabetes_tabular = Diabetes.get_tabular_dataset()
Mendaftarkan himpunan data
Daftarkan himpunan data Azure Machine Learning dengan ruang kerja Anda sehingga Anda dapat membagikannya dengan orang lain dan menggunakannya kembali di seluruh eksperimen di ruang kerja Anda. Saat Anda mendaftarkan himpunan data Azure Machine Learning yang dibuat dari Open Datasets, tidak ada data yang segera diunduh, tetapi data akan diakses nanti saat diminta (selama pelatihan, misalnya) dari lokasi penyimpanan pusat.
Untuk mendaftarkan himpunan data Anda dengan ruang kerja, gunakan metode register() ini.
titanic_ds = titanic_ds.register(workspace=workspace,
name='titanic_ds',
description='titanic training data')
Buat himpunan data dengan studio
Anda juga dapat membuat himpunan data Azure Machine Learning dari Azure Open Datasets menggunakan studio Azure Machine Learning, antarmuka web terkonsolidasi yang mencakup alat pembelajaran mesin untuk melakukan skenario ilmu data bagi praktisi ilmu data dari semua tingkat keterampilan.
Catatan
Himpunan data yang dibuat melalui studio Azure Machine Learning secara otomatis didaftarkan ke ruang kerja.
Di ruang kerja Anda, pilih tab Datasets di bawah Assets. Pada menu dropdown Buat himpunan data, pilih Dari Open Datasets.
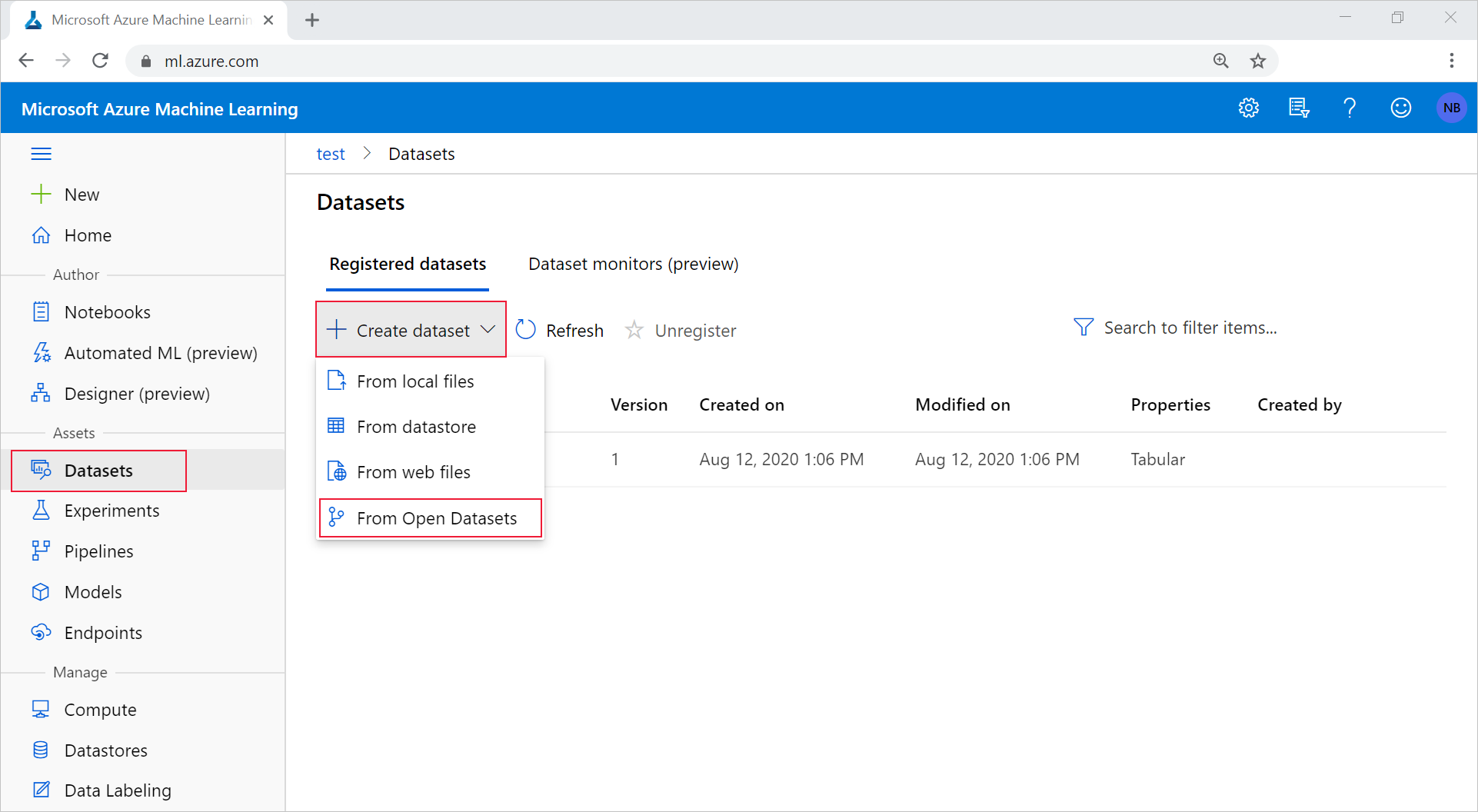
Pilih himpunan data dengan memilih petaknya. (Anda memiliki opsi untuk memfilter menggunakan bilah pencarian.) Pilih Berikutnya.
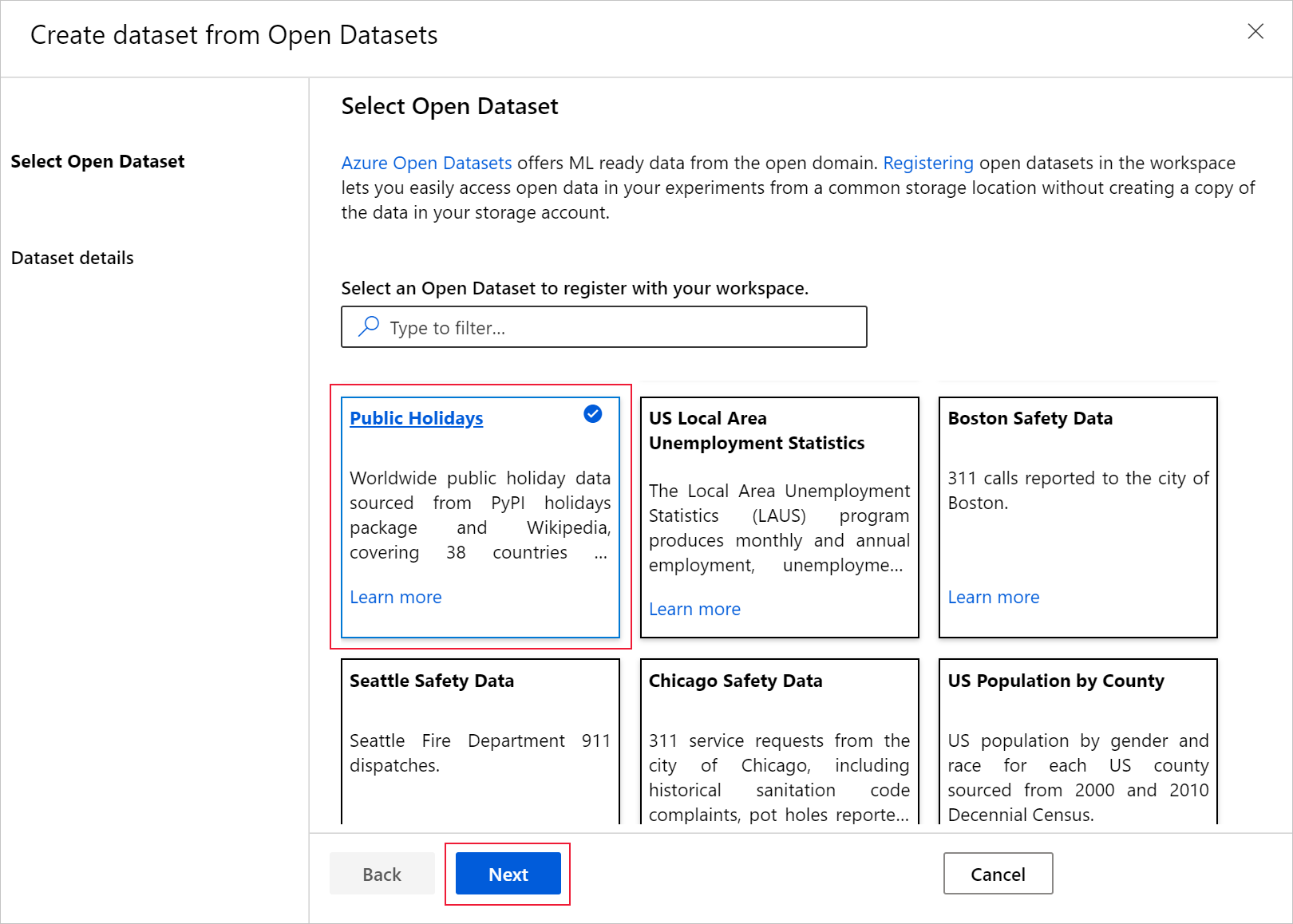
Pilih nama untuk mendaftarkan himpunan data, dan secara opsional memfilter data menggunakan filter yang tersedia. Dalam hal ini, untuk himpunan data hari libur nasional, Anda memfilter periode waktu menjadi satu tahun dan kode negara hanya untuk AS. Lihat Katalog Azure Open Datasets untuk detail data seperti, deskripsi bidang dan rentang tanggal. Pilih Buat.
Himpunan data sekarang tersedia di ruang kerja Anda di bawah Datasets. Anda dapat menggunakannya dengan cara yang sama seperti himpunan data lain yang telah dibuat.
Akses himpunan data untuk eksperimen Anda
Gunakan himpunan data Anda dalam eksperimen pembelajaran mesin untuk melatih model ML. Pelajari selengkapnya tentang cara berlatih dengan himpunan data.
Contoh buku catatan
Untuk contoh dan demonstrasi fungsionalitas Open Datasets, lihat contoh buku catatan ini.