Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
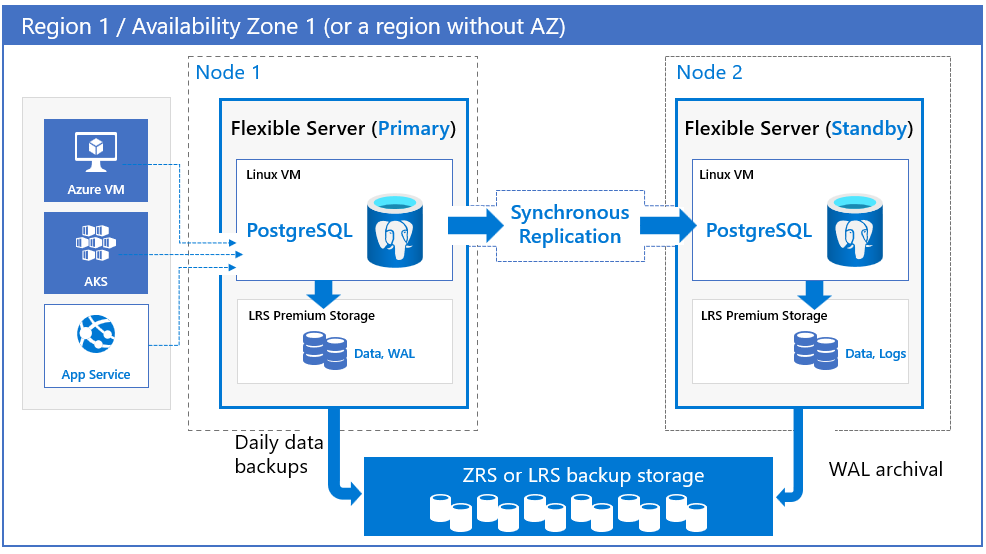
Azure Database for PostgreSQL mendukung ketersediaan tinggi dengan menyediakan replika utama dan siaga yang dipisahkan secara fisik. Model ketersediaan tinggi ini dirancang untuk memastikan bahwa data yang diterapkan tidak pernah hilang selama kegagalan. Dalam penyiapan ketersediaan tinggi (HA), data dikomit secara sinkron ke server utama dan siaga. Model ini dirancang agar database tidak menjadi satu titik kegagalan dalam arsitektur perangkat lunak Anda.
Secara default di sebagian besar wilayah, replika siaga Anda disebarkan ke zona ketersediaan yang berbeda dengan replika utama Anda (zona-redundan). Anda juga dapat menyebarkan replika utama dan siaga dalam zona ketersediaan (zonal) yang sama.
Fitur ketersediaan tinggi
Replika siaga disebarkan dalam konfigurasi VM yang sama dengan server utama, termasuk vCores, penyimpanan, dan pengaturan jaringan.
Anda dapat menambahkan dukungan zona ketersediaan untuk server database yang sudah ada.
Anda dapat menonaktifkan ketersediaan tinggi, yang akan menghapus replika siaga.
Anda dapat memilih zona ketersediaan untuk server database utama dan cadangan Anda untuk ketersediaan tinggi yang mendukung redundansi zona.
Operasi seperti berhenti, memulai, dan memulai ulang dilakukan pada server database primer dan siaga pada saat yang bersamaan.
Server database utama secara berkala melakukan pencadangan otomatis. Pada saat yang sama, replika siaga terus mengarsipkan log transaksi di penyimpanan cadangan. Untuk server zona-redundan, data cadangan disimpan pada penyimpanan zona redundan (ZRS). Data cadangan disimpan di penyimpanan redundan lokal (LRS) untuk server yang dikonfigurasi tanpa redundansi zona, server zonal (zona tunggal), dan di wilayah yang tidak mendukung zona ketersediaan.
Klien selalu tersambung ke nama host akhir server database utama.
Setiap perubahan pada parameter server juga diterapkan ke replika siaga.
Anda dapat memulai ulang server untuk mengambil perubahan parameter server statis apa pun.
Aktivitas perawatan berkala seperti peningkatan versi minor dilakukan terlebih dahulu pada sistem cadangan. Untuk mengurangi downtime, perangkat standby diangkat menjadi node utama agar beban kerja dapat terus berjalan saat tugas pemeliharaan diterapkan pada node lainnya.
Nota
Untuk memastikan fungsi high availability dengan benar, konfigurasikan nilai parameter server max_replication_slots dan max_wal_senders. Ketersediaan tinggi membutuhkan empat dari masing-masing sistem untuk menangani failover dan pembaruan yang mulus. Untuk pengaturan ketersediaan tinggi dengan lima replika baca dan 12 slot replikasi logis, atur nilai parameter max_replication_slots dan max_wal_senders ke 21. Konfigurasi ini diperlukan karena setiap replika baca dan setiap slot replikasi logis masing-masing memerlukan satu, ditambah empat yang diperlukan agar ketersediaan tinggi berfungsi dengan baik. Untuk informasi selengkapnya tentang max_replication_slots parameter dan max_wal_senders , lihat dokumentasi.
Jenis dukungan zona ketersediaan
Azure Database for PostgreSQL mendukung model redundan zona dan zonal untuk konfigurasi ketersediaan tinggi. Kedua konfigurasi ketersediaan tinggi memungkinkan kemampuan failover otomatis tanpa kehilangan data selama kejadian yang direncanakan maupun tidak direncanakan.
Zona-redundan. Ketersediaan tinggi zona redundan menyebarkan replika siaga di zona yang berbeda dengan kemampuan failover otomatis. Redundansi zona memberikan tingkat ketersediaan tertinggi, tetapi Anda perlu mengonfigurasi redundansi aplikasi di seluruh zona. Untuk alasan itu, pilih redundansi zona saat Anda menginginkan perlindungan dari kegagalan tingkat zona ketersediaan dan kapan latensi di seluruh zona ketersediaan dapat diterima. Meskipun mungkin ada beberapa dampak latensi pada penulisan dan komitmen karena replikasi sinkron, itu tidak memengaruhi kueri baca. Dampak ini khusus untuk beban kerja Anda, jenis SKU yang Anda pilih, dan wilayah.
Anda dapat memilih wilayah dan zona ketersediaan untuk server utama dan siaga. Server replika siaga disediakan di zona ketersediaan yang dipilih di wilayah yang sama dengan komputasi, penyimpanan, dan konfigurasi jaringan serupa dengan server utama. File data dan file log transaksi (log write-ahead, juga dikenal sebagai WAL) disimpan di penyimpanan redundan lokal (LRS) dalam setiap zona ketersediaan, secara otomatis menyimpan tiga salinan data. Konfigurasi yang redundan antar zona menyediakan isolasi fisik dari seluruh tumpukan antara server primer dan server siaga.

Opsi zona-redundan hanya tersedia di wilayah yang memiliki dukungan untuk zona ketersediaan.
Redundansi zona tidak didukung untuk:
- Tingkat komputasi yang dapat meledak
- Wilayah dengan ketersediaan zona tunggal
Zona yang sama (zonal). Pilih penyebaran zona ketika Anda ingin mencapai tingkat ketersediaan tertinggi dalam satu zona ketersediaan, tetapi dengan latensi jaringan terendah. Anda dapat memilih wilayah dan zona ketersediaan untuk menyebarkan server database utama Anda. Server replika siaga secara otomatis disediakan dan dikelola di zona ketersediaan yang sama - dengan komputasi, penyimpanan, dan konfigurasi jaringan serupa - sebagai server utama. Konfigurasi zonal melindungi database Anda dari kegagalan tingkat simpul dan juga membantu mengurangi waktu henti aplikasi selama peristiwa waktu henti yang direncanakan dan tidak direncanakan. Data dari server utama direplikasi ke replika siaga dalam mode sinkron. jika ada gangguan pada server utama, server secara otomatis beralih ke replika siaga.
Opsi penyebaran zonal tersedia di semua wilayah Azure tempat Anda dapat menyebarkan Server Fleksibel.


Nota
Model penyebaran zonal dan redundan zona secara arsitektur berperilaku sama. Berbagai diskusi di bagian berikut berlaku untuk keduanya kecuali disebutkan sebaliknya.
Pemulihan dari kegagalan zona
Zona redundansi: Azure Database for PostgreSQL secara otomatis melakukan failover ke server siaga dalam rentang waktu 60-120 detik tanpa kehilangan data.
Zonal: Jika zona gagal, server utama dan siaga tidak tersedia. Untuk memulihkan dari kegagalan tingkat zona, Anda dapat menggunakan cadangan untuk melakukan pemulihan ke titik waktu tertentu. Anda dapat memilih titik pemulihan kustom dengan waktu terbaru untuk memulihkan data terbaru. Server fleksibel baru disebarkan di zona lain yang tidak terpengaruh. Waktu yang dibutuhkan untuk melakukan pemulihan bergantung pada cadangan sebelumnya dan volume log transaksi yang perlu dipulihkan.
Untuk informasi selengkapnya tentang pemulihan point-in-time, lihat Backup dan pemulihan di Server fleksibel Azure Database for PostgreSQL.
SLA
Model Zona-redundansi menawarkan waktu aktif untuk SLA sekitar 99,99%. Model Zonal menawarkan uptime SLA sekitar 99,95%.
Azure Database for PostgreSQL yang tidak memiliki ketersediaan tinggi
Meskipun tidak disarankan, Anda dapat mengonfigurasi server fleksibel tanpa mengaktifkan ketersediaan tinggi. Untuk server fleksibel yang dikonfigurasi tanpa ketersediaan tinggi, layanan ini menyediakan penyimpanan redundan secara lokal dengan tiga salinan data, dan ketahanan server bawaan untuk secara otomatis memulai ulang server yang mengalami crash dan memindahkan server ke simpul fisik lain. Konfigurasi ini menawarkan SLA waktu aktif yang lebih rendah daripada server dengan ketersediaan tinggi. Selama peristiwa failover yang direncanakan atau tidak direncanakan, jika server tidak berfungsi, layanan mempertahankan ketersediaan server dengan menggunakan prosedur otomatis berikut:
- Sebuah komputer virtual Linux baru telah disediakan.
- Penyimpanan dengan file data dipetakan ke komputer virtual baru.
- Mesin database PostgreSQL dibawa secara online di komputer virtual baru.
Gambar berikut menunjukkan transisi antara VM dan kegagalan penyimpanan.
**

Mengonfigurasi opsi Kritis Bisnis (Ketersediaan Tinggi)
Anda dapat mengonfigurasi ketersediaan tinggi (HA) dengan dua cara: ketersediaan tinggi zona-redundan, yang menempatkan server siaga di zona ketersediaan yang berbeda untuk ketahanan zona maksimum, atau ketersediaan tinggi zona yang sama, yang menyebarkan server siaga di zona yang sama dengan server utama untuk meminimalkan latensi.
Bagian 'Business Critical (Ketersediaan Tinggi)' menyediakan opsi untuk membuat server HA siaga dengan konfigurasi zona redundan . Untuk menyederhanakan konfigurasi dan memastikan ketahanan zona, portal menyediakan opsi ketahanan Zonal dengan dua tombol radio: Diaktifkan dan Dinonaktifkan. Memilih Aktifkan berupaya untuk membuat server siaga di zona ketersediaan yang berbeda (mode HA yang tahan terhadap gangguan zona). Jika wilayah tidak mendukung HA zona redundan, Anda dapat memilih kotak centang fallback untuk mengaktifkan HA zona yang sama (zonal).

Saat Anda memilih kotak centang fallback, sistem membuat server siaga di zona yang sama. Jika kapasitas zonal nanti tersedia, Azure akan secara otomatis memigrasikan beban kerja Anda dari HA zona yang sama ke HA zona-redundan. Jika Anda tidak memilih kotak centang dan kapasitas zonal tidak tersedia, pengaktifan KETERSEDIAAN TINGGI gagal. Desain ini memberlakukan HA zona redundan sebagai default sambil menyediakan fallback terkontrol untuk HA satu zona, memastikan beban kerja akhirnya mencapai ketahanan lintas zona penuh.
Membuat Azure Database for PostgreSQL dengan zona ketersediaan diaktifkan
Untuk mempelajari cara membuat Azure Database for PostgreSQL untuk ketersediaan tinggi dengan zona ketersediaan, lihat Quickstart: Membuat Azure Database for PostgreSQL di portal Azure.
Penyebaran dan migrasi ulang zona ketersediaan
Untuk mempelajari cara mengaktifkan atau menonaktifkan konfigurasi ketersediaan tinggi di server fleksibel Anda dalam model penyebaran zona-redundan dan zonal, lihat Mengelola ketersediaan tinggi di Server Fleksibel.
Memantau kesehatan ketersediaan tinggi
Pemantauan status kesehatan ketersediaan tinggi (HA) di Azure Database for PostgreSQL memberikan gambaran umum berkelanjutan tentang kesehatan dan kesiapan instans berkemampuan HA. Fitur pemantauan ini menggunakan kerangka kerja Resource Health Check (RHC) Azure untuk menunjukkan dan memberikan peringatan terhadap masalah apa pun yang mungkin memengaruhi kesiapan failover database Anda atau ketersediaan secara keseluruhan. Dengan menilai metrik utama seperti status koneksi, status failover, dan kesehatan replikasi data, pemantauan status kesehatan HA memungkinkan pemecahan masalah proaktif dan membantu mempertahankan waktu aktif dan performa database Anda.
Gunakan pemantauan status kesehatan HA untuk:
- Dapatkan wawasan real time tentang kesehatan replika primer dan siaga, dengan indikator status yang mengungkapkan potensi masalah, seperti performa yang terdegradasi atau pemblokiran jaringan.
- Siapkan pemberitahuan tepat waktu pada setiap perubahan status HA, sehingga Anda dapat segera mengambil tindakan untuk mengatasi potensi gangguan.
- Optimalkan kesiapan failover dengan mengidentifikasi dan mengatasi masalah sebelum memengaruhi operasi database.
Untuk panduan terperinci tentang mengonfigurasi dan menginterpretasikan status kesehatan HA, lihat pemantauan status kesehatan High Availability (HA) untuk Azure Database for PostgreSQL.
Batasan ketersediaan tinggi
Replikasi antara server utama dan server siaga dilakukan secara sinkron.
Anda tidak dapat menggunakan server HA cadangan untuk permintaan pembacaan.
Bergantung pada beban kerja dan aktivitas di server utama, proses failover mungkin memakan waktu lebih dari 120 detik karena replika siaga perlu pulih sebelum dapat dipromosikan.
Server cadangan biasanya memulihkan file WAL pada kecepatan 40 MB per detik. Untuk versi yang lebih besar, tingkat ini dapat meningkat hingga sebanyak 200 MB/dtk. Jika beban kerja Anda melebihi batas ini, Anda mungkin mengalami waktu pemulihan yang lebih lama baik selama failover maupun setelah membuat siaga baru.
Memulai ulang server database utama juga memulai ulang replika siaga.
Anda tidak dapat mengonfigurasi siaga tambahan.
Anda tidak dapat menjadwalkan tugas manajemen yang diinisiasi oleh pelanggan pada saat jendela pemeliharaan yang terkelola.
Peristiwa yang direncanakan seperti komputasi skala dan penyimpanan skala terjadi pada server cadangan terlebih dahulu, baru kemudian di server utama. Saat ini, server tidak melakukan failover untuk operasi yang direncanakan ini.
Mengonfigurasi zona ketersediaan antara privat (jaringan virtual) dan akses publik dengan titik akhir privat tidak didukung. Anda harus mengonfigurasi zona ketersediaan dalam jaringan virtual (dilintasi di seluruh zona ketersediaan dalam satu wilayah) atau akses publik dengan titik akhir privat.
Anda hanya dapat mengonfigurasi zona ketersediaan dalam satu wilayah. Anda tidak dapat mengonfigurasi zona ketersediaan di seluruh wilayah.
Komponen dan alur kerja ketersediaan tinggi
Penyelesaian transaksi
Transaksi aplikasi memicu penulisan dan komit yang pertama kali dicatat ke WAL di server utama. Server utama mengalirkan log ini ke server siaga dengan menggunakan protokol streaming Postgres. Ketika penyimpanan server siaga mempertahankan log, server utama mengakui penyelesaian tulis. Aplikasi melakukan transaksinya hanya setelah pengakuan ini. Round-trip tambahan ini menambah latensi pada aplikasi Anda. Persentase dampak tergantung pada aplikasi. Proses konfirmasi ini tidak menunggu log diterapkan ke server cadangan. Server cadangan tetap dalam mode pemulihan hingga diaktifkan.
Pemeriksaan kesehatan
Pemantauan kesehatan server yang fleksibel secara berkala memeriksa kesehatan server utama dan siaga. Setelah beberapa ping, jika pemantauan kesehatan mendeteksi bahwa server utama tidak dapat dijangkau, layanan memulai failover otomatis ke server siaga. Algoritma pemantauan kesehatan menggunakan beberapa titik data untuk menghindari situasi positif palsu.
Mode Pemulihan
Server fleksibel mendukung dua mode failover, Failover terencana dan Failover yang tidak direncanakan. Pada kedua mode, setelah replikasi berhenti, server siaga menjalankan pemulihan sebelum promosi dalam mode primer dan terbuka untuk baca/tulis. Dengan entri DNS otomatis yang diperbarui dengan titik akhir server utama baru, aplikasi dapat terhubung ke server dengan menggunakan titik akhir yang sama. Server siaga baru dibuat di latar belakang, sehingga aplikasi Anda dapat mempertahankan konektivitas.
Status ketersediaan tinggi
Sistem terus memantau kesehatan server primer dan siaga. Dibutuhkan tindakan yang tepat untuk memperbaiki masalah, termasuk memicu failover ke server siaga. Tabel berikut ini mencantumkan kemungkinan status ketersediaan tinggi:
| Keadaan | Deskripsi |
|---|---|
| Initializing | Dalam proses membuat server siaga baru. |
| Mereplikasi Data | Setelah siaga dibuat, siaga tersebut akan menyusul ke primernya. |
| Sehat | Replikasi dalam status stabil dan sehat. |
| Pemindahan | Server database sedang dalam tahap berpindah ke server cadangan. |
| Menghapus Mode Siaga | Dalam proses menghapus server siaga. |
| Tidak Diaktifkan | Ketersediaan tinggi tidak diaktifkan. |
Nota
Anda dapat mengaktifkan ketersediaan tinggi selama pembuatan server atau di lain waktu. Jika Anda mengaktifkan atau menonaktifkan ketersediaan tinggi selama tahap pasca-buat, lakukan saat aktivitas server utama rendah.
Operasi berstatus stabil
Aplikasi klien PostgreSQL terhubung ke server utama dengan menggunakan nama server DB. Server utama langsung melayani pembacaan aplikasi. Pada saat yang sama, aplikasi menerima konfirmasi komitmen dan penulisan hanya setelah data log tersimpan persisten di server utama dan replika siaga. Karena ekstra perjalanan pulang pergi ini, aplikasi dapat mengharapkan latensi yang ditingkatkan untuk penulisan dan penerapan. Anda dapat memantau status kesehatan ketersediaan tinggi di portal.
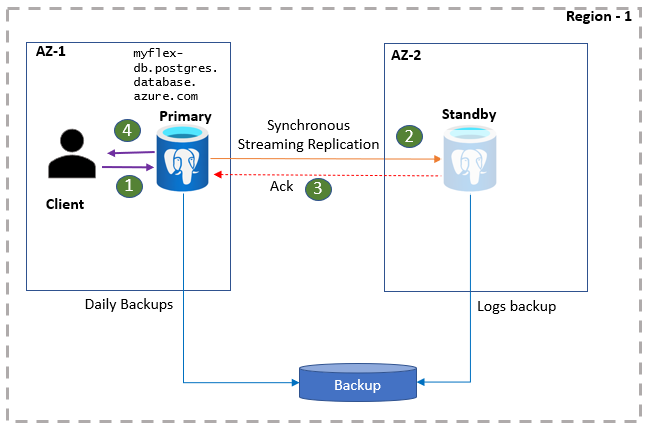
- Klien tersambung ke server fleksibel dan melakukan operasi tulis.
- Perubahan mereplikasi ke situs siaga.
- Primer menerima pengakuan.
- Penulisan data dan komit dikonfirmasi.
Pemulihan ke titik waktu tertentu untuk server dengan ketersediaan tinggi
Untuk server fleksibel yang dikonfigurasi dengan ketersediaan tinggi, sistem mereplikasi data log secara real time ke server siaga. Setiap kesalahan pengguna di server utama - seperti penurunan tabel yang tidak disengaja atau pembaruan data yang salah - direplikasi ke replika siaga. Jadi, Anda tidak dapat menggunakan mode siaga untuk memulihkan dari kesalahan logis tersebut. Untuk memulihkan dari kesalahan tersebut, Anda harus melakukan pemulihan dari titik waktu tertentu dari cadangan. Dengan menggunakan kemampuan pemulihan point-in-time server yang fleksibel, Anda dapat memulihkan ke waktu sebelum kesalahan terjadi. Server database baru dipulihkan sebagai server fleksibel zonal (zona tunggal) dengan nama server baru yang disediakan pengguna untuk database yang dikonfigurasi dengan ketersediaan tinggi. Anda dapat menggunakan server yang dipulihkan untuk beberapa kasus penggunaan:
Gunakan server yang dipulihkan untuk produksi dan secara opsional mengaktifkan ketersediaan tinggi dengan replika siaga pada zona yang sama atau zona lain di wilayah yang sama.
Jika Anda ingin memulihkan objek, ekspor dari server database yang dipulihkan dan impor ke server database produksi Anda.
Jika Anda ingin mengkloning server database Anda untuk tujuan pengujian dan pengembangan atau memulihkan untuk tujuan lain, Anda dapat melakukan pemulihan titik waktu.
Untuk mempelajari cara melakukan pemulihan pada titik waktu dari server fleksibel, lihat Pemulihan titik waktu server fleksibel.
Dukungan failover
Kegagalan terencana
Peristiwa waktu henti yang direncanakan mencakup pembaruan perangkat lunak Azure yang terjadwal dan berkala, serta peningkatan versi minor. Anda juga dapat menggunakan failover yang direncanakan untuk mengembalikan server utama ke zona ketersediaan pilihan. Saat Anda mengonfigurasi ketersediaan tinggi, operasi ini terlebih dahulu berlaku untuk replika siaga sementara aplikasi terus mengakses server utama. Setelah proses memperbarui replika siaga, ia menguras koneksi server utama dan memicu failover yang mengaktifkan replika siaga sebagai server utama dengan nama server database yang sama. Aplikasi klien terhubung kembali dengan nama server database yang sama ke server utama baru dan dapat melanjutkan operasi mereka. Proses ini membuat server siaga baru di zona yang sama dengan primer lama.
Petunjuk / Saran
Ketika Anda memiliki server fleksibel redundan zona, Anda juga dapat menggunakan failover terencana untuk memindahkan server utama ke zona ketersediaan yang dipilih dengan waktu henti yang dikurangi. Misalnya, server utama Anda dapat berada di zona ketersediaan yang berbeda dari aplikasi setelah failover yang tidak direncanakan. Proses failover yang direncanakan memindahkan primer kembali ke zona aslinya, dan membuat server siaga baru di zona yang sama dengan primer lama.
Untuk operasi lain yang dimulai pengguna seperti menskalakan komputasi atau menskalakan penyimpanan, proses menerapkan perubahan pada sistem siaga terlebih dahulu, lalu pada sistem primer. Saat ini, layanan tidak beralih ke mode siaga. Oleh karena itu, saat operasi skala berjalan di server utama, aplikasi mengalami waktu henti yang singkat.
Anda juga dapat menggunakan fitur ini untuk melakukan failover ke server siaga dengan mengurangi waktu henti. Misalnya, server utama Anda dapat berada di zona ketersediaan yang berbeda dari aplikasi setelah failover yang tidak direncanakan. Anda ingin membawa server utama kembali ke zona sebelumnya untuk dikolokasikan dengan aplikasi Anda.
Ketika Anda menjalankan fitur ini, proses pertama-tama menyiapkan server siaga untuk memastikannya mengejar transaksi terbaru, memungkinkan aplikasi untuk terus melakukan baca dan tulis. Proses ini mengaktifkan cadangan dan memutuskan koneksi dengan yang utama. Aplikasi Anda dapat terus menulis ke server utama sementara proses membuat server siaga baru di latar belakang. Tabel berikut menjelaskan langkah-langkah yang terlibat dengan failover yang direncanakan:
| Step | Deskripsi | Apakah waktu henti aplikasi diharapkan? |
|---|---|---|
| 1 | Tunggu hingga server siaga mengejar ketinggalan dengan server utama. | No |
| 2 | Sistem pemantauan internal memulai alur kerja pindah alih. | No |
| 3 | Penulisan aplikasi diblokir ketika server siaga dekat dengan nomor urutan log utama (LSN). | Yes |
| 4 | Server siaga dipromosikan menjadi server independen. | Yes |
| 5 | Catatan DNS diperbarui dengan alamat IP server siaga baru. | Yes |
| 6 | Aplikasi terhubung kembali dan melanjutkan baca/tulisnya dengan primer baru. | No |
| 7 | Server siaga baru dibuat. Untuk server zonasi redundan, server baru diletakkan di zonasi lain. | No |
| 8 | Server siaga mulai memulihkan log (dari Azure Blob) yang terlewat selama proses penyiapan. | No |
| 9 | Kondisi stabil antara server utama dan server siaga telah tercipta. | No |
| 10 | Proses failover yang direncanakan sudah selesai. | No |
Waktu henti aplikasi dimulai pada langkah 3 dan dapat melanjutkan operasi setelah langkah 5. Langkah-langkah lainnya terjadi di latar belakang tanpa memengaruhi penulisan dan penerapan aplikasi.
Petunjuk / Saran
Dengan server fleksibel, Anda dapat secara opsional menjadwalkan aktivitas pemeliharaan yang dimulai Azure dengan memilih jendela 60 menit pada hari preferensi Anda ketika aktivitas pada database diperkirakan rendah. Tugas pemeliharaan Azure seperti patching atau peningkatan versi minor dilakukan selama periode tersebut. Jika Anda tidak memilih jendela kustom, sistem mengalokasikan jendela satu jam antara pukul 23.00 dan 07.00 waktu setempat untuk server Anda. Aktivitas pemeliharaan yang diprakarsai oleh Azure ini juga dilaksanakan pada replika siaga untuk server fleksibel yang dikonfigurasi dengan zona ketersediaan.
Untuk daftar kemungkinan peristiwa waktu henti yang direncanakan, lihat Peristiwa waktu henti yang direncanakan.
Kegagalan tidak terencana
Waktu henti yang tidak diencana dapat terjadi sebagai akibat dari gangguan tak terduga seperti kesalahan perangkat keras yang mendasarinya, masalah jaringan, dan bug perangkat lunak. Jika server database yang dikonfigurasi dengan ketersediaan tinggi tidak berfungsi secara tiba-tiba, proses mengaktifkan replika siaga dan klien dapat melanjutkan operasi mereka. Jika Anda tidak mengonfigurasi ketersediaan tinggi (HA), dan upaya hidupkan ulang gagal, proses secara otomatis menyediakan server database baru. Meskipun waktu henti yang tidak diencana tidak dapat dihindari, server fleksibel membantu mengurangi waktu henti dengan melakukan operasi pemulihan secara otomatis tanpa memerlukan intervensi manusia.
Untuk informasi tentang failover dan waktu henti yang tidak direncanakan, termasuk kemungkinan skenario, lihat Mitigasi Waktu Henti yang Tidak Direncanakan.
Failover paksa
Anda dapat menggunakan failover paksa untuk pengujian failover, untuk mensimulasikan skenario pemadaman yang tidak direncanakan saat menjalankan beban kerja produksi Anda dan mengamati waktu henti aplikasi Anda. Anda juga dapat menggunakan failover paksa saat server utama Anda menjadi tidak responsif.
Failover yang dipaksakan menyebabkan server utama offline dan memulai alur kerja failover di mana operasi promosi siaga dilakukan. Setelah server cadangan menyelesaikan proses pemulihan hingga data terakhir yang di-commit, statusnya diubah menjadi server utama. Catatan DNS diperbarui, dan aplikasi Anda bisa tersambung ke server utama yang dipromosikan. Aplikasi Anda dapat terus menulis ke server utama sementara server siaga baru dibuat di latar belakang, yang tidak memengaruhi waktu aktif.
Tabel berikut ini menjelaskan langkah-langkah selama failover paksa:
| Step | Deskripsi | Apakah waktu henti aplikasi diharapkan? |
|---|---|---|
| 1 | Server utama berhenti segera setelah menerima permintaan failover. | Yes |
| 2 | Aplikasi mengalami downtime saat server utama sedang terhenti. | Yes |
| 3 | Sistem pemantauan internal mendeteksi kegagalan dan memulai failover ke server siaga. | Yes |
| 4 | Server siaga memasuki mode pemulihan sebelum sepenuhnya dipromosikan sebagai server independen. | Yes |
| 5 | Proses failover menunggu pemulihan sistem siaga selesai. | Yes |
| 6 | Setelah server aktif, proses memperbarui catatan DNS dengan nama host yang sama tetapi menggunakan alamat IP siaga. | Yes |
| 7 | Aplikasi dapat terhubung kembali ke server utama baru dan melanjutkan operasi. | No |
| 8 | Server siaga di zona pilihan didirikan. | No |
| 9 | Server siaga mulai memulihkan log (dari Azure Blob) yang terlewatkan selama pendiriannya. | No |
| 10 | Kondisi stabil antara server utama dan server siaga telah tercipta. | No |
| 11 | Proses failover paksa sudah selesai. | No |
Waktu henti aplikasi dimulai setelah langkah 1 dan berlanjut hingga langkah 6 selesai. Langkah-langkah lain berjalan di latar belakang tanpa memengaruhi penulisan dan penerapan aplikasi.
Penting
Proses failover end-to-end mencakup (a) melakukan failover ke server siaga setelah kejadian kegagalan utama dan (b) menetapkan server siaga baru dalam keadaan stabil. Karena aplikasi Anda mengalami waktu henti hingga failover ke cadangan selesai, ukur waktu henti dari perspektif aplikasi/klien Anda daripada hanya proses failover end-to-end secara keseluruhan.
Pertimbangan saat melakukan failover paksa
Durasi operasi end-to-end secara keseluruhan dapat lebih lama daripada waktu tidak beroperasi yang sebenarnya dialami oleh aplikasi.
Penting
Selalu amati waktu henti dari perspektif aplikasi!
Jangan melakukan failover secara berturut-turut. Tunggu setidaknya 15-20 menit di antara failover, sehingga server siaga baru dapat sepenuhnya dibuat.
Lakukan failover paksa selama periode aktivitas rendah untuk mengurangi waktu henti.
Praktik terbaik untuk statistik PostgreSQL setelah failover
Setelah failover PostgreSQL, mempertahankan performa database yang optimal melibatkan pemahaman peran pg_statistic yang berbeda dan tampilan pg_stat_* . Tabel pg_statistic menyimpan statistik pengoptimal, yang sangat penting untuk perencana kueri. Statistik ini mencakup distribusi data dalam tabel dan tetap utuh setelah failover, memastikan bahwa perencana kueri dapat terus mengoptimalkan eksekusi kueri secara efektif berdasarkan informasi distribusi data historis yang akurat.
Sebaliknya, pg_stat_* tampilan, menyediakan statistik aktivitas runtime seperti jumlah pemindaian, tuple yang dibaca, dan pembaruan, disimpan dalam memori dan diatur ulang setelah failover. Contohnya adalah pg_stat_user_tables, yang melacak aktivitas untuk tabel yang ditentukan pengguna. Reset ini secara akurat mencerminkan status operasional primer baru tetapi juga berarti hilangnya metrik aktivitas historis yang dapat menginformasikan proses autovacuum dan efisiensi operasional lainnya.
Mengingat perbedaan ini, Anda dapat mempertimbangkan untuk menjalankan pg_stat_* data (misalnya, pg_stat_user_tables) dengan statistik aktivitas vakum baru, membantu proses autovacuum, yang pada gilirannya, memastikan bahwa performa database tetap optimal dalam peran barunya. Langkah proaktif ini menjejaki kesenjangan antara mempertahankan statistik pengoptimal penting dan me-refresh metrik aktivitas untuk selaras dengan status database saat ini.
Dukungan replikasi logis dengan KETERSEDIAAN TINGGI
Saat menggunakan replikasi logis atau decoding logis dengan Ketersediaan Tinggi (HA) di server fleksibel Azure Database for PostgreSQL, penting untuk memahami bagaimana slot replikasi bertingkah selama failover dan cara memastikan kelangsungan replikasi.
PostgreSQL 16 dan yang lebih lama
Di PostgreSQL 16 dan versi sebelumnya, slot replikasi logis tidak dipertahankan secara otomatis di server siaga setelah failover. Untuk mempertahankan replikasi logis di seluruh failover, Anda harus:
- Aktifkan
pg_failover_slotsekstensi - Konfigurasikan pengaturan yang diperlukan seperti:
hot_standby_feedback = on
Tanpa konfigurasi ini, replikasi logis mungkin berhenti berfungsi setelah failover karena slot replikasi tidak tersedia di primer baru.
PostgreSQL 17 dan yang lebih baru
Dimulai dengan PostgreSQL 17, sinkronisasi slot replikasi logis didukung secara bawaan. Ketika dikonfigurasi dengan benar, slot replikasi secara otomatis disinkronkan ke server siaga.
Untuk mengaktifkan perilaku ini:
- Atur
sync_replication_slots = on - Atur
hot_standby_feedback = on
Dengan pengaturan ini, slot replikasi logis dipertahankan selama failover, dan replikasi dapat dilanjutkan tanpa memerlukan ekstensi. Untuk detailnya, lihat dokumentasi ekstensi PG_Failover_Slots .
Pertimbangan penting
- Slot replikasi logis dikelola di server utama, tetapi juga harus ada di siaga untuk memastikan replikasi logis berlanjut setelah failover HA.
- Tampilan sistem (misalnya, kueri
pg_replication_slots) hanya memperlihatkan status pada utama dan tidak mengonfirmasi apakah slot dalam keadaan sinkronisasi dengan siaga. Sistem dapat tampak sehat pada primer tetapi tetap belum siap failover untuk mempertahankan slot replikasi logis pada siaga.
Memeriksa kesiapan failover untuk replikasi logis
Untuk membantu memvalidasi kesiapan failover, Anda dapat menggunakan metrik Azure Monitor logical_replication_slot_sync_status (Pratinjau).
Penting
Untuk memancarkan metrik ini, pastikan parameter metrics.collector_database_activity server diatur ke on.
Metrik ini menunjukkan apakah slot replikasi logis disinkronkan di antara HA primer dan siaga:
-
1menunjukkan bahwa slot disinkronkan antara utama dan siaga. -
0menunjukkan bahwa slot tidak disinkronkan pada siaga.
Jika nilai metrik adalah 0, replikasi logis mungkin terus berfungsi pada primer saat ini, tetapi mungkin tidak berlanjut setelah failover. Untuk daftar lengkap metrik replikasi logis, lihat Pemantauan replikasi logis.
Nota
Status sinkronisasi ini mencerminkan status di seluruh simpul HA dan tidak dapat diverifikasi menggunakan tampilan sistem pada primer saja. Pertimbangkan untuk menggunakan metrik ini dengan pemberitahuan untuk mendeteksi kapan replikasi logis tidak siap untuk failover, terutama sebelum peristiwa pemeliharaan atau failover yang direncanakan. Pertimbangkan untuk mengonfigurasi pemberitahuan saat metrik ini tetap 0 untuk periode berkelanjutan.