Mengekstrak teks dan informasi dari gambar dengan menggunakan pengayaan AI
Melalui pengayaan AI, Azure AI Search memberi Anda beberapa opsi untuk membuat dan mengekstrak teks yang dapat dicari dari gambar, termasuk:
- OCR untuk pengenalan karakter optik teks dan digit
- Analisis Gambar yang menjelaskan gambar melalui fitur visual
- Keterampilan kustom untuk memanggil pemrosesan gambar eksternal apa pun yang ingin Anda berikan
Dengan menggunakan OCR, Anda dapat mengekstrak teks dari foto atau gambar yang berisi teks alfanumerik, seperti kata STOP dalam tanda berhenti. Melalui analisis gambar, Anda dapat menghasilkan representasi teks gambar, seperti dandelion untuk foto dandelion, atau warna kuning. Anda juga dapat mengekstrak metadata tentang gambar, seperti ukurannya.
Artikel ini membahas dasar-dasar bekerja dengan gambar, dan juga menjelaskan beberapa skenario umum, seperti bekerja dengan gambar yang disematkan, keterampilan kustom, dan melapisi visualisasi pada gambar asli.
Untuk bekerja dengan konten gambar dalam set keterampilan, Anda memerlukan:
- File sumber yang menyertakan gambar
- Pengindeks pencarian, dikonfigurasi untuk tindakan gambar
- Set keterampilan dengan keterampilan bawaan atau kustom yang memanggil OCR atau analisis gambar
- Indeks pencarian dengan bidang untuk menerima output teks yang dianalisis, ditambah pemetaan bidang output di pengindeks yang menetapkan asosiasi
Secara opsional, Anda dapat menentukan proyeksi untuk menerima output yang dianalisis gambar ke dalam penyimpanan pengetahuan untuk skenario penambangan data.
Menyiapkan file sumber
Pemrosesan gambar digerakkan oleh pengindeks, yang berarti bahwa input mentah harus berada di sumber data yang didukung.
- Analisis gambar mendukung JPEG, PNG, GIF, dan BMP
- OCR mendukung JPEG, PNG, BMP, dan TIF
Gambar adalah file biner mandiri atau disematkan dalam dokumen, seperti file aplikasi PDF, RTF, atau Microsoft. Maksimal 1.000 gambar dapat diekstrak dari dokumen tertentu. Jika ada lebih dari 1.000 gambar dalam dokumen, 1.000 gambar pertama diekstraksi dan kemudian peringatan dihasilkan.
Azure Blob Storage adalah penyimpanan yang paling sering digunakan untuk pemrosesan gambar di Azure AI Search. Ada tiga tugas utama yang terkait dengan pengambilan gambar dari kontainer blob:
Aktifkan akses ke konten dalam kontainer. Jika Anda menggunakan akses penuh string koneksi yang menyertakan kunci, kunci memberi Anda izin ke konten. Atau, Anda dapat mengautentikasi menggunakan ID Microsoft Entra atau menyambungkan sebagai layanan tepercaya.
Buat sumber data jenis azureblob yang tersambung ke kontainer blob yang menyimpan file Anda.
Tinjau batas tingkat layanan untuk memastikan bahwa data sumber Anda berada di bawah ukuran maksimum dan batas kuantitas untuk pengindeks dan pengayaan.
Mengonfigurasi pengindeks untuk pemrosesan gambar
Setelah file sumber disiapkan, aktifkan normalisasi gambar dengan mengatur imageAction parameter dalam konfigurasi pengindeks. Normalisasi gambar membantu membuat gambar lebih seragam untuk pemrosesan hilir. Normalisasi gambar mencakup operasi berikut:
- Gambar besar diubah ukurannya menjadi tinggi dan lebar maksimum untuk membuatnya seragam.
- Untuk gambar yang memiliki metadata yang menentukan orientasi, rotasi gambar disesuaikan untuk pemuatan vertikal.
Penyesuaian metadata diambil dalam jenis kompleks yang dibuat untuk setiap gambar. Anda tidak dapat menolak persyaratan normalisasi gambar. Keterampilan yang mengulangi gambar, seperti OCR dan analisis gambar, mengharapkan gambar yang dinormalisasi.
Buat atau perbarui pengindeks untuk mengatur properti konfigurasi:
{ "parameters": { "configuration": { "dataToExtract": "contentAndMetadata", "parsingMode": "default", "imageAction": "generateNormalizedImages" } } }Atur
dataToExtractkecontentAndMetadata(diperlukan).Verifikasi bahwa
parsingModediatur ke default (diperlukan).Parameter ini menentukan granularitas dokumen pencarian yang dibuat dalam indeks. Mode default menyiapkan korespondensi satu-ke-satu sehingga satu blob menghasilkan satu dokumen pencarian. Jika dokumen besar, atau jika keterampilan memerlukan potongan teks yang lebih kecil, Anda dapat menambahkan keterampilan Pemisahan Teks yang membagi dokumen menjadi halaman untuk tujuan pemrosesan. Tetapi untuk skenario pencarian, satu blob per dokumen diperlukan jika pengayaan mencakup pemrosesan gambar.
Atur
imageActionuntuk mengaktifkan simpulnormalized_imagesdi pohon pengayaan (diperlukan):generateNormalizedImagesuntuk menghasilkan array gambar yang dinormalisasi sebagai bagian dari pemecahan dokumen.generateNormalizedImagePerPage(hanya berlaku untuk PDF) untuk menghasilkan array gambar yang dinormalisasi di mana setiap halaman dalam PDF dirender ke satu gambar output. Untuk file non-PDF, perilaku parameter ini mirip seolah-olah Anda telah mengaturgenerateNormalizedImages. Namun, pengaturangenerateNormalizedImagePerPagedapat membuat operasi pengindeksan kurang berkinerja berdasarkan desain (terutama untuk dokumen besar) karena beberapa gambar harus dihasilkan.
Secara opsional, sesuaikan lebar atau tinggi gambar yang dinormalisasi yang dihasilkan:
normalizedImageMaxWidthdalam piksel. Defaultnya adalah 2.000. Nilai maksimum adalah 10.000.normalizedImageMaxHeightdalam piksel. Defaultnya adalah 2.000. Nilai maksimum adalah 10.000.
Default 2.000 piksel untuk lebar dan tinggi maksimum gambar yang dinormalisasi didasarkan pada ukuran maksimum yang didukung oleh keterampilan OCR dan keterampilan analisis gambar. Keterampilan OCR mendukung lebar dan tinggi maksimum 4.200 untuk bahasa non-bahasa Inggris, dan 10.000 untuk bahasa Inggris. Jika Anda meningkatkan batas maksimum, pemrosesan bisa gagal pada gambar yang lebih besar tergantung pada definisi set keterampilan Anda dan bahasa dokumen.
Secara opsional, atur kriteria jenis file jika beban kerja menargetkan jenis file tertentu. Konfigurasi pengindeks blob mencakup pengaturan penyertaan dan pengecualian file. Anda dapat memfilter file yang tidak Anda inginkan.
{ "parameters" : { "configuration" : { "indexedFileNameExtensions" : ".pdf, .docx", "excludedFileNameExtensions" : ".png, .jpeg" } } }
Tentang gambar yang dinormalisasi
Ketika imageAction diatur ke nilai selain tidak ada, bidang baru normalized_images berisi array gambar. Setiap gambar adalah jenis kompleks yang memiliki anggota berikut:
| Anggota gambar | Deskripsi |
|---|---|
| data | BASE64 pengodean untai (karakter) gambar yang dinormalkan dalam format JPEG. |
| lebar | Lebar gambar yang dinormalkan dalam piksel. |
| tinggi | Tinggi gambar yang dinormalkan dalam piksel. |
| originalWidth | Lebar asli gambar sebelum normalisasi. |
| originalHeight | Tinggi asli gambar sebelum normalisasi. |
| rotasiDariOriginal | Rotasi berlawanan arah jarum jam dalam derajat yang terjadi untuk membuat gambar yang dinormalisasi. Nilai antara 0 derajat dan 360 derajat. Langkah ini membaca metadata dari gambar yang dihasilkan oleh kamera atau pemindai. Biasanya kelipatan 90 derajat. |
| kontenOffset | Karakter diimbangi di dalam bidang konten tempat gambar diekstraksi. Bidang ini hanya berlaku untuk file dengan gambar yang disematkan. contentOffset untuk gambar yang diekstrak dari dokumen PDF selalu di akhir teks pada halaman tempat gambar diekstraksi dalam dokumen. Ini berarti gambar muncul setelah semua teks di halaman tersebut, terlepas dari lokasi asli gambar di halaman. |
| pageNumber | Jika gambar diekstrak atau dirender dari PDF, bidang ini berisi nomor halaman dalam PDF yang diekstrak atau dirender dari, mulai dari 1. Jika gambar bukan dari PDF, bidang ini adalah 0. |
Nilai sampel dari normalized_images:
[
{
"data": "BASE64 ENCODED STRING OF A JPEG IMAGE",
"width": 500,
"height": 300,
"originalWidth": 5000,
"originalHeight": 3000,
"rotationFromOriginal": 90,
"contentOffset": 500,
"pageNumber": 2
}
]
Menentukan set keterampilan untuk pemrosesan gambar
Bagian ini melengkapi artikel referensi keterampilan dengan menyediakan konteks untuk bekerja dengan input keterampilan, output, dan pola, karena berkaitan dengan pemrosesan gambar.
Buat atau perbarui set keterampilan untuk menambahkan keterampilan.
Tambahkan templat untuk OCR dan Analisis Gambar dari portal, atau salin definisi dari dokumentasi referensi keterampilan. Masukkan ke dalam array keterampilan definisi set keterampilan Anda.
Jika perlu, sertakan kunci multi-layanan di properti layanan Azure AI dari set keterampilan. Azure AI Search melakukan panggilan ke sumber daya layanan Azure AI yang dapat ditagih untuk OCR dan analisis gambar untuk transaksi yang melebihi batas gratis (20 per pengindeks per hari). Layanan Azure AI harus berada di wilayah yang sama dengan layanan pencarian Anda.
Jika gambar asli disematkan dalam file PDF atau aplikasi seperti PPTX atau DOCX, Anda perlu menambahkan keterampilan Penggabungan Teks jika Anda ingin output gambar dan output teks bersama-sama. Bekerja dengan gambar yang disematkan dibahas lebih lanjut dalam artikel ini.
Setelah kerangka kerja dasar set keterampilan Anda dibuat dan layanan Azure AI dikonfigurasi, Anda dapat fokus pada setiap keterampilan gambar individu, menentukan input dan konteks sumber, dan memetakan output ke bidang baik di indeks atau penyimpanan pengetahuan.
Catatan
Untuk contoh set keterampilan yang menggabungkan pemrosesan gambar dengan pemrosesan bahasa alami hilir, lihat Tutorial REST: Menggunakan REST dan AI untuk menghasilkan konten yang dapat dicari dari blob Azure. Ini menunjukkan cara memberi umpan output pencitraan keterampilan ke dalam pengenalan entitas dan ekstraksi frasa kunci.
Input untuk pemrosesan gambar
Seperti disebutkan, gambar diekstrak selama pemecahan dokumen dan kemudian dinormalisasi sebagai langkah awal. Gambar yang dinormalisasi adalah input ke keterampilan pemrosesan gambar apa pun, dan selalu diwakili dalam pohon dokumen yang diperkaya dengan salah satu dari dua cara:
/document/normalized_images/*adalah untuk dokumen yang diproses secara keseluruhan./document/normalized_images/*/pagesadalah untuk dokumen yang diproses dalam gugus (halaman).
Apakah Anda menggunakan OCR dan analisis gambar dalam hal yang sama, input memiliki konstruksi yang hampir sama:
{
"@odata.type": "#Microsoft.Skills.Vision.OcrSkill",
"context": "/document/normalized_images/*",
"detectOrientation": true,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [ ]
},
{
"@odata.type": "#Microsoft.Skills.Vision.ImageAnalysisSkill",
"context": "/document/normalized_images/*",
"visualFeatures": [ "tags", "description" ],
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [ ]
}
Memetakan output ke bidang pencarian
Dalam set keterampilan, Analisis Gambar dan output keterampilan OCR selalu berupa teks. Teks output direpresentasikan sebagai simpul di pohon dokumen internal yang diperkaya, dan setiap simpul harus dipetakan ke bidang dalam indeks pencarian, atau ke proyeksi di penyimpanan pengetahuan, untuk membuat konten tersedia di aplikasi Anda.
Dalam set keterampilan, tinjau
outputsbagian dari setiap keterampilan untuk menentukan simpul mana yang ada dalam dokumen yang diperkaya:{ "@odata.type": "#Microsoft.Skills.Vision.OcrSkill", "context": "/document/normalized_images/*", "detectOrientation": true, "inputs": [ ], "outputs": [ { "name": "text", "targetName": "text" }, { "name": "layoutText", "targetName": "layoutText" } ] }Buat atau perbarui indeks pencarian untuk menambahkan bidang untuk menerima output keterampilan.
Dalam contoh kumpulan bidang berikut, konten adalah konten blob. Metadata_storage_name berisi nama file (diatur
retrievableke true). Metadata_storage_path adalah jalur unik blob dan merupakan kunci dokumen default. Merged_content adalah output dari Gabungan Teks (berguna saat gambar disematkan).Teks dan layoutText adalah output keterampilan OCR dan harus menjadi koleksi string untuk menangkap semua output yang dihasilkan OCR untuk seluruh dokumen.
"fields": [ { "name": "content", "type": "Edm.String", "filterable": false, "retrievable": true, "searchable": true, "sortable": false }, { "name": "metadata_storage_name", "type": "Edm.String", "filterable": true, "retrievable": true, "searchable": true, "sortable": false }, { "name": "metadata_storage_path", "type": "Edm.String", "filterable": false, "key": true, "retrievable": true, "searchable": false, "sortable": false }, { "name": "merged_content", "type": "Edm.String", "filterable": false, "retrievable": true, "searchable": true, "sortable": false }, { "name": "text", "type": "Collection(Edm.String)", "filterable": false, "retrievable": true, "searchable": true }, { "name": "layoutText", "type": "Collection(Edm.String)", "filterable": false, "retrievable": true, "searchable": true } ],Perbarui pengindeks untuk memetakan output skillset (simpul di pohon pengayaan) ke bidang indeks.
Dokumen yang diperkaya bersifat internal. Untuk eksternalisasi simpul dalam pohon dokumen yang diperkaya, siapkan pemetaan bidang output yang menentukan bidang indeks mana yang menerima konten simpul. Data yang diperkaya diakses oleh aplikasi Anda melalui bidang indeks. Contoh berikut menunjukkan simpul teks (output OCR) dalam dokumen yang diperkaya yang dipetakan ke bidang teks dalam indeks pencarian.
"outputFieldMappings": [ { "sourceFieldName": "/document/normalized_images/*/text", "targetFieldName": "text" }, { "sourceFieldName": "/document/normalized_images/*/layoutText", "targetFieldName": "layoutText" } ]Jalankan pengindeks untuk memanggil pengambilan dokumen sumber, pemrosesan gambar, dan pengindeksan.
Memverifikasi hasil
Jalankan kueri terhadap indeks untuk memeriksa hasil pemrosesan gambar. Gunakan Search Explorer sebagai klien pencarian, atau alat apa pun yang mengirim permintaan HTTP. Kueri berikut memilih bidang yang berisi output pemrosesan gambar.
POST /indexes/[index name]/docs/search?api-version=[api-version]
{
"search": "*",
"select": "metadata_storage_name, text, layoutText, imageCaption, imageTags"
}
OCR mengenali teks dalam file gambar. Ini berarti bahwa bidang OCR (teks dan layoutText) kosong jika dokumen sumber adalah teks murni atau gambar murni. Demikian pula, bidang analisis gambar (imageCaption dan imageTags) kosong jika input dokumen sumber adalah teks yang ketat. Eksekusi pengindeks memancarkan peringatan jika input pencitraan kosong. Peringatan tersebut diharapkan ketika simpul tidak diisi dalam dokumen yang diperkaya. Ingat bahwa pengindeksan blob memungkinkan Anda menyertakan atau mengecualikan jenis file jika Anda ingin bekerja dengan jenis konten dalam isolasi. Anda dapat menggunakan pengaturan ini untuk mengurangi kebisingan selama pengindeks berjalan.
Kueri alternatif untuk memeriksa hasil mungkin menyertakan konten dan bidang merged_content . Perhatikan bahwa bidang tersebut menyertakan konten untuk file blob apa pun, bahkan bidang di mana tidak ada pemrosesan gambar yang dilakukan.
Tentang output keterampilan
Output keterampilan termasuk text (OCR), layoutText (OCR), merged_content, captions (analisis gambar), tags (analisis gambar):
textmenyimpan output yang dihasilkan OCR. Simpul ini harus dipetakan ke bidang jenisCollection(Edm.String). Ada satutextbidang per dokumen pencarian yang terdiri dari string yang dibatasi koma untuk dokumen yang berisi beberapa gambar. Ilustrasi berikut menunjukkan output OCR untuk tiga dokumen. Pertama adalah dokumen yang berisi file tanpa gambar. Kedua adalah dokumen (file gambar) yang berisi satu kata, Microsoft. Ketiga adalah dokumen yang berisi beberapa gambar, beberapa tanpa teks apa pun ("",)."value": [ { "@search.score": 1, "metadata_storage_name": "facts-about-microsoft.html", "text": [] }, { "@search.score": 1, "metadata_storage_name": "guthrie.jpg", "text": [ "Microsoft" ] }, { "@search.score": 1, "metadata_storage_name": "Azure AI services and Content Intelligence.pptx", "text": [ "", "Microsoft", "", "", "", "Azure AI Search and Augmentation Combining Microsoft Azure AI services and Azure Search" ] } ]layoutTextmenyimpan informasi yang dihasilkan OCR tentang lokasi teks di halaman, yang dijelaskan dalam hal kotak pembatas dan koordinat gambar yang dinormalisasi. Simpul ini harus dipetakan ke bidang jenisCollection(Edm.String). Ada satulayoutTextbidang per dokumen pencarian yang terdiri dari string yang dibatasi koma.merged_contentmenyimpan output keterampilan Penggabungan Teks, dan harus berupa satu bidang besar jenisEdm.Stringyang berisi teks mentah dari dokumen sumber, dengan disematkantextsebagai pengganti gambar. Jika file hanya teks, maka OCR dan analisis gambar tidak ada hubungannya, danmerged_contentsama dengancontent(properti blob yang berisi konten blob).imageCaptionmenangkap deskripsi gambar sebagai tag individu dan deskripsi teks yang lebih panjang.imageTagsmenyimpan tag tentang gambar sebagai kumpulan kata kunci, satu koleksi untuk semua gambar dalam dokumen sumber.
Cuplikan layar berikut adalah ilustrasi PDF yang menyertakan teks dan gambar yang disematkan. Pemecahan dokumen mendeteksi tiga gambar yang disematkan: kawanan burung camar, peta, elang. Teks lain dalam contoh (termasuk judul, judul, dan teks isi) diekstrak sebagai teks dan dikecualikan dari pemrosesan gambar.
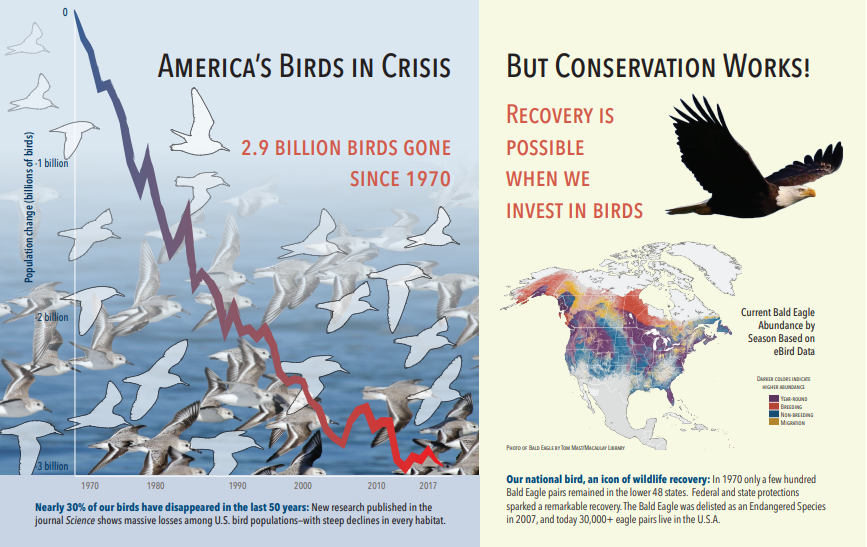
Output analisis gambar diilustrasikan dalam JSON berikut (hasil pencarian). Definisi keterampilan memungkinkan Anda menentukan fitur visual mana yang menarik. Untuk contoh ini, tag dan deskripsi diproduksi, tetapi ada lebih banyak output yang dapat dipilih.
imageCaptionoutput adalah array deskripsi, satu per gambar, ditandai dengantagsterdiri dari kata tunggal dan frasa yang lebih panjang yang menggambarkan gambar. Perhatikan tag yang terdiri dari sekawanan burung camar berenang di air, atau close up burung.imageTagsoutput adalah array tag tunggal, yang tercantum dalam urutan pembuatan. Perhatikan bahwa tag diulang. Tidak ada agregasi atau pengelompokan.
"imageCaption": [
"{\"tags\":[\"bird\",\"outdoor\",\"water\",\"flock\",\"many\",\"lot\",\"bunch\",\"group\",\"several\",\"gathered\",\"pond\",\"lake\",\"different\",\"family\",\"flying\",\"standing\",\"little\",\"air\",\"beach\",\"swimming\",\"large\",\"dog\",\"landing\",\"jumping\",\"playing\"],\"captions\":[{\"text\":\"a flock of seagulls are swimming in the water\",\"confidence\":0.70419257326275686}]}",
"{\"tags\":[\"map\"],\"captions\":[{\"text\":\"map\",\"confidence\":0.99942880868911743}]}",
"{\"tags\":[\"animal\",\"bird\",\"raptor\",\"eagle\",\"sitting\",\"table\"],\"captions\":[{\"text\":\"a close up of a bird\",\"confidence\":0.89643581933539462}]}",
. . .
"imageTags": [
"bird",
"outdoor",
"water",
"flock",
"animal",
"bunch",
"group",
"several",
"drink",
"gathered",
"pond",
"different",
"family",
"same",
"map",
"text",
"animal",
"bird",
"bird of prey",
"eagle"
. . .
Skenario: Gambar yang disematkan di PDF
Ketika gambar yang ingin Anda proses disematkan dalam file lain, seperti PDF atau DOCX, alur pengayaan hanya mengekstrak gambar dan kemudian meneruskannya ke OCR atau analisis gambar untuk diproses. Ekstraksi gambar terjadi selama fase pemecahan dokumen, dan setelah gambar dipisahkan, mereka tetap terpisah kecuali Anda secara eksplisit menggabungkan output yang diproses kembali ke teks sumber.
Penggabungan Teks digunakan untuk menempatkan output pemrosesan gambar kembali ke dalam dokumen. Meskipun Penggabungan Teks bukan persyaratan yang sulit, ini sering dipanggil sehingga output gambar (teks OCR, layoutText OCR, tag gambar, keterangan gambar) dapat diintroduksi kembali ke dalam dokumen. Tergantung pada keterampilannya, output gambar menggantikan gambar biner yang disematkan dengan teks di tempat yang setara. Output Analisis Gambar dapat digabungkan di lokasi gambar. Output OCR selalu muncul di akhir setiap halaman.
Alur kerja berikut menguraikan proses ekstraksi gambar, analisis, penggabungan, dan cara memperluas alur untuk mendorong output yang diproses gambar ke keterampilan berbasis teks lainnya seperti Pengenalan Entitas atau Terjemahan Teks.
Setelah menyambungkan ke sumber data, pengindeks memuat dan memecahkan dokumen sumber, mengekstrak gambar dan teks, dan mengantrekan setiap jenis konten untuk diproses. Dokumen yang diperkaya yang hanya terdiri dari simpul akar (dokumen) dibuat.
Gambar dalam antrean dinormalisasi dan diteruskan ke dokumen yang diperkaya sebagai simpul dokumen/normalized_images .
Pengayaan gambar dijalankan, menggunakan
"/document/normalized_images"sebagai input.Output gambar diteruskan ke pohon dokumen yang diperkaya, dengan setiap output sebagai simpul terpisah. Output bervariasi menurut keterampilan (teks dan layoutText untuk OCR; tag dan keterangan untuk Analisis Gambar).
Opsional tetapi direkomendasikan jika Anda ingin dokumen pencarian menyertakan teks dan teks asal gambar bersama-sama, Penggabungan Teks berjalan, menggabungkan representasi teks gambar tersebut dengan teks mentah yang diekstrak dari file. Potongan teks dikonsolidasikan ke dalam satu string besar, di mana teks disisipkan terlebih dahulu dalam string dan kemudian output teks OCR atau tag gambar dan keterangan.
Output Penggabungan Teks sekarang menjadi teks definitif untuk menganalisis keterampilan hilir apa pun yang melakukan pemrosesan teks. Misalnya, jika set keterampilan Anda menyertakan OCR dan Pengenalan Entitas, input ke Pengenalan Entitas harus (
"document/merged_text"targetName dari output keterampilan Penggabungan Teks).Setelah semua keterampilan dijalankan, dokumen yang diperkaya selesai. Pada langkah terakhir, pengindeks merujuk ke pemetaan bidang output untuk mengirim konten yang diperkaya ke bidang individual dalam indeks pencarian.
Contoh set keterampilan berikut membuat bidang yang merged_text berisi teks asli dokumen Anda dengan teks OCRed yang disematkan sebagai pengganti gambar yang disematkan. Ini juga mencakup keterampilan Pengenalan Entitas yang menggunakan merged_text sebagai input.
Minta sintaks tubuh
{
"description": "Extract text from images and merge with content text to produce merged_text",
"skills":
[
{
"description": "Extract text (plain and structured) from image.",
"@odata.type": "#Microsoft.Skills.Vision.OcrSkill",
"context": "/document/normalized_images/*",
"defaultLanguageCode": "en",
"detectOrientation": true,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [
{
"name": "text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.MergeSkill",
"description": "Create merged_text, which includes all the textual representation of each image inserted at the right location in the content field.",
"context": "/document",
"insertPreTag": " ",
"insertPostTag": " ",
"inputs": [
{
"name":"text", "source": "/document/content"
},
{
"name": "itemsToInsert", "source": "/document/normalized_images/*/text"
},
{
"name":"offsets", "source": "/document/normalized_images/*/contentOffset"
}
],
"outputs": [
{
"name": "mergedText", "targetName" : "merged_text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"context": "/document",
"categories": [ "Person"],
"defaultLanguageCode": "en",
"minimumPrecision": 0.5,
"inputs": [
{
"name": "text", "source": "/document/merged_text"
}
],
"outputs": [
{
"name": "persons", "targetName": "people"
}
]
}
]
}
Sekarang setelah Anda memiliki merged_text bidang, Anda dapat memetakannya sebagai bidang yang dapat dicari dalam definisi pengindeks Anda. Semua konten file Anda, termasuk teks gambar, akan dapat dicari.
Skenario: Memvisualisasikan kotak pembatas
Skenario umum lainnya adalah memvisualisasikan informasi tata letak hasil pencarian. Misalnya, Anda mungkin ingin menyoroti di mana sepotong teks ditemukan dalam gambar sebagai bagian dari hasil pencarian Anda.
Karena langkah OCR dilakukan pada gambar yang dinormalisasi, koordinat tata letak berada di ruang gambar yang dinormalisasi, tetapi jika Anda perlu menampilkan gambar asli, konversi titik koordinat dalam tata letak ke sistem koordinat gambar asli.
Algoritma berikut mengilustrasikan pola:
/// <summary>
/// Converts a point in the normalized coordinate space to the original coordinate space.
/// This method assumes the rotation angles are multiples of 90 degrees.
/// </summary>
public static Point GetOriginalCoordinates(Point normalized,
int originalWidth,
int originalHeight,
int width,
int height,
double rotationFromOriginal)
{
Point original = new Point();
double angle = rotationFromOriginal % 360;
if (angle == 0 )
{
original.X = normalized.X;
original.Y = normalized.Y;
} else if (angle == 90)
{
original.X = normalized.Y;
original.Y = (width - normalized.X);
} else if (angle == 180)
{
original.X = (width - normalized.X);
original.Y = (height - normalized.Y);
} else if (angle == 270)
{
original.X = height - normalized.Y;
original.Y = normalized.X;
}
double scalingFactor = (angle % 180 == 0) ? originalHeight / height : originalHeight / width;
original.X = (int) (original.X * scalingFactor);
original.Y = (int)(original.Y * scalingFactor);
return original;
}
Skenario: Keterampilan gambar kustom
Gambar juga dapat diteruskan ke dalam dan dikembalikan dari keterampilan khusus. Skillset base64-encode gambar yang diteruskan ke dalam keterampilan kustom. Untuk menggunakan gambar dalam keterampilan kustom, atur "/document/normalized_images/*/data" sebagai input ke keterampilan kustom. Dalam kode keterampilan kustom Anda, base64-decode untai (karakter) sebelum mengonversinya menjadi gambar. Untuk mengembalikan gambar ke set keterampilan, dasarkan64-encode gambar sebelum mengembalikannya ke set keterampilan.
Gambar dikembalikan sebagai objek dengan properti berikut.
{
"$type": "file",
"data": "base64String"
}
Repositori sampel Azure Search Python memiliki sampel lengkap yang diimplementasikan dalam Python dari keterampilan kustom yang memperkaya gambar.
Meneruskan gambar ke keterampilan kustom
Untuk skenario di mana Anda memerlukan keterampilan khusus untuk mengerjakan gambar, Anda dapat meneruskan gambar ke keterampilan kustom, dan mengembalikan teks atau gambar. Set keterampilan berikut berasal dari sampel.
Set keterampilan berikut mengambil gambar yang dinormalkan (diperoleh selama peretasan dokumen), dan output irisan gambar.
Contoh set keterampilan
{
"description": "Extract text from images and merge with content text to produce merged_text",
"skills":
[
{
"@odata.type": "#Microsoft.Skills.Custom.WebApiSkill",
"name": "ImageSkill",
"description": "Segment Images",
"context": "/document/normalized_images/*",
"uri": "https://your.custom.skill.url",
"httpMethod": "POST",
"timeout": "PT30S",
"batchSize": 100,
"degreeOfParallelism": 1,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [
{
"name": "slices",
"targetName": "slices"
}
],
"httpHeaders": {}
}
]
}
Contoh keterampilan kustom
Set keterampilan kustom itu sendiri adalah eksternal untuk set keterampilan. Dalam hal ini, ini adalah kode Python yang pertama kali mengulangi batch rekaman permintaan dalam format keterampilan kustom, lalu mengonversi string yang dikodekan base64 menjadi gambar.
# deserialize the request, for each item in the batch
for value in values:
data = value['data']
base64String = data["image"]["data"]
base64Bytes = base64String.encode('utf-8')
inputBytes = base64.b64decode(base64Bytes)
# Use numpy to convert the string to an image
jpg_as_np = np.frombuffer(inputBytes, dtype=np.uint8)
# you now have an image to work with
Demikian pula untuk mengembalikan gambar, kembalikan string yang dikodekan base64 dalam objek JSON dengan $type properti file.
def base64EncodeImage(image):
is_success, im_buf_arr = cv2.imencode(".jpg", image)
byte_im = im_buf_arr.tobytes()
base64Bytes = base64.b64encode(byte_im)
base64String = base64Bytes.decode('utf-8')
return base64String
base64String = base64EncodeImage(jpg_as_np)
result = {
"$type": "file",
"data": base64String
}