Memotong dokumen besar untuk solusi pencarian vektor di Azure AI Search
Mempartisi dokumen besar menjadi potongan yang lebih kecil dapat membantu Anda tetap berada di bawah batas input token maksimum model penyematan. Misalnya, panjang maksimum teks input untuk model penyematan teks-ada-002 Azure OpenAI adalah 8.191 token. Mengingat bahwa setiap token sekitar empat karakter teks untuk model OpenAI umum, batas maksimum ini setara dengan sekitar 6.000 kata teks. Jika Anda menggunakan model ini untuk menghasilkan penyematan, sangat penting bahwa teks input tetap berada di bawah batas. Mempartisi konten Anda menjadi potongan memastikan bahwa data Anda dapat diproses oleh model penyematan dan Anda tidak kehilangan informasi karena pemotongan.
Kami merekomendasikan vektorisasi terintegrasi untuk potongan dan penyematan data bawaan. Vektorisasi terintegrasi mengambil dependensi pada pengindeks, keterampilan, keterampilan Pemisahan Teks, dan keterampilan penyematan seperti keterampilan Penyematan Azure OpenAI. Jika Anda tidak dapat menggunakan vektorisasi terintegrasi, artikel ini menjelaskan beberapa pendekatan untuk memotong konten Anda.
Teknik potongan umum
Pemotongan hanya diperlukan jika dokumen sumber terlalu besar untuk ukuran input maksimum yang diberlakukan oleh model.
Berikut adalah beberapa teknik potongan umum, dimulai dengan metode yang paling banyak digunakan:
Potongan ukuran tetap: Tentukan ukuran tetap yang cukup untuk paragraf yang bermakna secara semantik (misalnya, 200 kata) dan memungkinkan beberapa tumpang tindih (misalnya, 10-15% dari konten) dapat menghasilkan gugus yang baik sebagai input untuk menyematkan generator vektor.
Potongan berukuran variabel berdasarkan konten: Partisi data Anda berdasarkan karakteristik konten, seperti tanda baca akhir kalimat, penanda akhir baris, atau menggunakan fitur di pustaka Natural Language Processing (NLP). Struktur bahasa markdown juga dapat digunakan untuk memisahkan data.
Sesuaikan atau iterasi melalui salah satu teknik di atas. Misalnya, saat berhadapan dengan dokumen besar, Anda mungkin menggunakan gugus berukuran variabel, tetapi juga menambahkan judul dokumen ke potongan dari tengah dokumen untuk mencegah kehilangan konteks.
Pertimbangan tumpang tindih konten
Saat Anda memotong data, tumpang tindih sejumlah kecil teks antar gugus dapat membantu mempertahankan konteks. Sebaiknya mulai dengan tumpang tindih sekitar 10%. Misalnya, mengingat ukuran potongan tetap 256 token, Anda akan mulai menguji dengan tumpang tindih 25 token. Jumlah tumpang tindih yang sebenarnya bervariasi tergantung pada jenis data dan kasus penggunaan tertentu, tetapi kami telah menemukan bahwa 10-15% berfungsi untuk banyak skenario.
Faktor-faktor untuk pemotongan data
Ketika datang ke potongan data, pikirkan tentang faktor-faktor ini:
Bentuk dan kepadatan dokumen Anda. Jika Anda memerlukan teks atau bagian yang utuh, potongan dan potongan variabel yang lebih besar yang mempertahankan struktur kalimat dapat menghasilkan hasil yang lebih baik.
Kueri pengguna: Potongan yang lebih besar dan strategi yang tumpang tindih membantu mempertahankan konteks dan kekayaan semantik untuk kueri yang menargetkan informasi tertentu.
Model Bahasa Besar (LLM) memiliki pedoman performa untuk ukuran potongan. Anda perlu mengatur ukuran gugus yang paling sesuai untuk semua model yang Anda gunakan. Misalnya, jika Anda menggunakan model untuk ringkasan dan penyematan, pilih ukuran gugus optimal yang berfungsi untuk keduanya.
Cara penggugusan cocok dengan alur kerja
Jika Anda memiliki dokumen besar, Anda harus menyisipkan langkah pemotongan ke dalam alur kerja pengindeksan dan kueri yang memecah teks besar. Saat menggunakan vektorisasi terintegrasi, strategi pemotongan default menggunakan keterampilan Pemisahan Teks diterapkan. Anda juga dapat menerapkan strategi penggugusan kustom menggunakan keterampilan kustom. Beberapa pustaka yang menyediakan potongan meliputi:
Sebagian besar pustaka menyediakan teknik penggugusan umum untuk ukuran tetap, ukuran variabel, atau kombinasi. Anda juga dapat menentukan tumpang tindih yang menduplikasi sejumlah kecil konten di setiap gugus untuk pelestarian konteks.
Contoh pemotongan
Contoh berikut menunjukkan bagaimana strategi pemotongan diterapkan pada file PDF e-book Bumi di Malam Hari NASA:
Contoh keterampilan Pemisahan Teks
Pemotongan data terintegrasi melalui keterampilan Pemisahan Teks umumnya tersedia.
Bagian ini menjelaskan pemotongan data bawaan menggunakan pendekatan berbasis keterampilan dan parameter keterampilan Pemisahan Teks.
Contoh notebook untuk contoh ini dapat ditemukan di repositori azure-search-vector-samples .
Atur textSplitMode untuk memecah konten menjadi potongan yang lebih kecil:
pages(default). Potongan terdiri dari beberapa kalimat.sentences. Potongan-potongan terdiri dari kalimat tunggal. Apa yang merupakan "kalimat" bergantung pada bahasa. Dalam bahasa Inggris, tanda baca akhir kalimat standar seperti.atau!digunakan. Bahasa dikontrol olehdefaultLanguageCodeparameter .
Parameter pages menambahkan parameter tambahan:
maximumPageLengthmenentukan jumlah maksimum karakter 1 atau token 2 di setiap gugus. Pemisah teks menghindari kalimat putus, sehingga jumlah karakter aktual tergantung pada konten.pageOverlapLengthmenentukan berapa banyak karakter dari akhir halaman sebelumnya yang disertakan di awal halaman berikutnya. Jika diatur, ini harus kurang dari setengah panjang halaman maksimum.maximumPagesToTakemenentukan berapa banyak halaman/potongan yang akan diambil dari dokumen. Nilai defaultnya adalah 0, yang berarti mengambil semua halaman atau potongan dari dokumen.
1 Karakter tidak selaras dengan definisi token. Jumlah token yang diukur oleh LLM mungkin berbeda dari ukuran karakter yang diukur oleh keterampilan Pemisahan Teks.
2 Potongan token tersedia dalam pratinjau 2024-09-01 dan menyertakan parameter tambahan untuk menentukan tokenizer dan token apa pun yang seharusnya tidak dibagi selama penggugusan.
Tabel berikut menunjukkan bagaimana pilihan parameter memengaruhi jumlah gugus total dari e-book Bumi di Malam Hari:
textSplitMode |
maximumPageLength |
pageOverlapLength |
Jumlah Total Gugus |
|---|---|---|---|
pages |
1000 | 0 | 172 |
pages |
1000 | 200 | 216 |
pages |
2000 | 0 | 85 |
pages |
2000 | 500 | 113 |
pages |
5000 | 0 | 34 |
pages |
5000 | 500 | 38 |
sentences |
T/A | T/A | 13361 |
textSplitMode Menggunakan hasil pages dalam sebagian besar gugus yang memiliki jumlah karakter total yang dekat dengan maximumPageLength. Jumlah karakter gugus bervariasi karena perbedaan di mana batas kalimat berada di dalam gugus. Panjang token gugus bervariasi karena perbedaan isi gugus.
Histogram berikut menunjukkan bagaimana distribusi panjang karakter gugus dibandingkan dengan panjang token gugus untuk gpt-35-turbo saat menggunakan textSplitMode dari pages, a maximumPageLength dari 2000, dan pageOverlapLength 500 di Bumi di malam hari e-book:
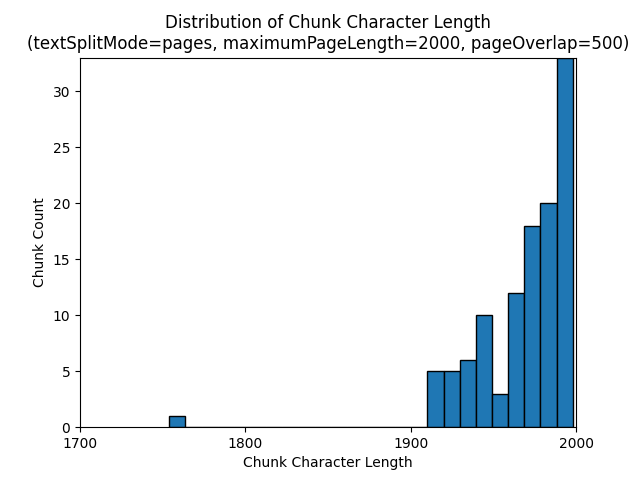
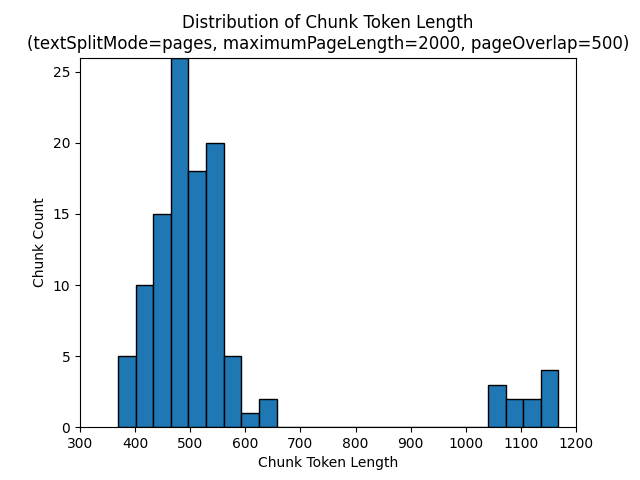
textSplitMode Menggunakan hasil sentences dalam sejumlah besar potongan yang terdiri dari kalimat individu. Potongan-potongan ini secara signifikan lebih kecil daripada yang diproduksi oleh pages, dan jumlah token gugus lebih cocok dengan jumlah karakter.
Histogram berikut menunjukkan bagaimana distribusi panjang karakter gugus dibandingkan dengan panjang token gugus untuk gpt-35-turbo saat menggunakan textSplitMode di sentences Bumi di e-book Malam:
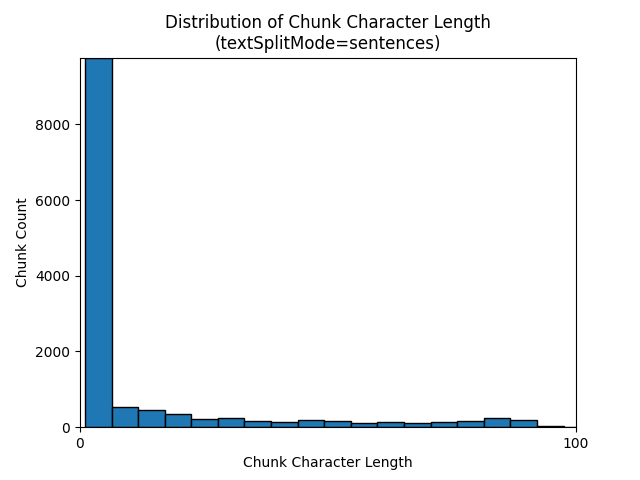
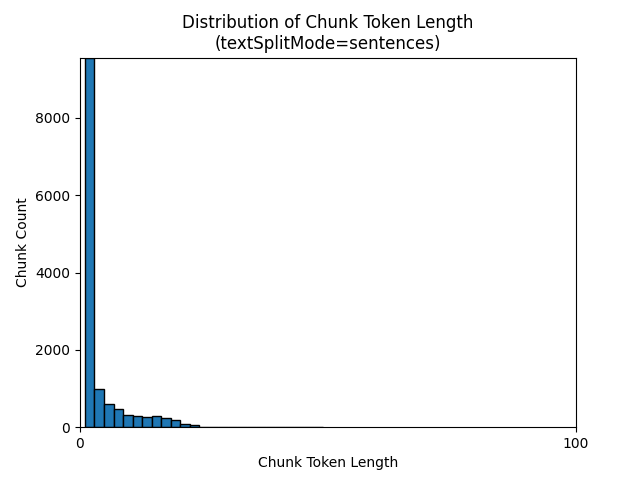
Pilihan parameter yang optimal tergantung pada bagaimana gugus akan digunakan. Untuk sebagian besar aplikasi, disarankan untuk memulai dengan parameter default berikut:
textSplitMode |
maximumPageLength |
pageOverlapLength |
|---|---|---|
pages |
2000 | 500 |
Contoh pemotongan data LangChain
LangChain menyediakan pemuat dokumen dan pemisah teks. Contoh ini menunjukkan kepada Anda cara memuat PDF, mendapatkan jumlah token, dan menyiapkan pemisah teks. Mendapatkan jumlah token membantu Anda membuat keputusan berdasarkan informasi tentang ukuran gugus.
Contoh notebook untuk contoh ini dapat ditemukan di repositori azure-search-vector-samples .
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader("./data/earth_at_night_508.pdf")
pages = loader.load()
print(len(pages))
Output menunjukkan 200 dokumen atau halaman dalam PDF.
Untuk mendapatkan perkiraan jumlah token untuk halaman ini, gunakan TikToken.
import tiktoken
tokenizer = tiktoken.get_encoding('cl100k_base')
def tiktoken_len(text):
tokens = tokenizer.encode(
text,
disallowed_special=()
)
return len(tokens)
tiktoken.encoding_for_model('gpt-3.5-turbo')
# create the length function
token_counts = []
for page in pages:
token_counts.append(tiktoken_len(page.page_content))
min_token_count = min(token_counts)
avg_token_count = int(sum(token_counts) / len(token_counts))
max_token_count = max(token_counts)
# print token counts
print(f"Min: {min_token_count}")
print(f"Avg: {avg_token_count}")
print(f"Max: {max_token_count}")
Output menunjukkan bahwa tidak ada halaman yang memiliki token nol, panjang token rata-rata per halaman adalah 189 token, dan jumlah token maksimum halaman apa pun adalah 1.583.
Mengetahui ukuran token rata-rata dan maksimum memberi Anda wawasan tentang pengaturan ukuran gugus. Meskipun Anda dapat menggunakan rekomendasi standar 2000 karakter dengan tumpang tindih 500 karakter, dalam hal ini masuk akal untuk lebih rendah mengingat jumlah token dari dokumen sampel. Bahkan, mengatur nilai tumpang tindih yang terlalu besar dapat mengakibatkan tidak ada tumpang tindih yang muncul sama sekali.
from langchain.text_splitter import RecursiveCharacterTextSplitter
# split documents into text and embeddings
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
length_function=len,
is_separator_regex=False
)
chunks = text_splitter.split_documents(pages)
print(chunks[20])
print(chunks[21])
Output untuk dua gugus berturut-turut menunjukkan teks dari gugus pertama yang tumpang tindih ke gugus kedua. Output diedit ringan untuk keterbacaan.
'x Earth at NightForeword\nNASA’s Earth at Night explores the brilliance of our planet when it is in darkness. \n It is a compilation of stories depicting the interactions between science and \nwonder, and I am pleased to share this visually stunning and captivating exploration of \nour home planet.\nFrom space, our Earth looks tranquil. The blue ethereal vastness of the oceans \nharmoniously shares the space with verdant green land—an undercurrent of gentle-ness and solitude. But spending time gazing at the images presented in this book, our home planet at night instantly reveals a different reality. Beautiful, filled with glow-ing communities, natural wonders, and striking illumination, our world is bustling with activity and life.**\nDarkness is not void of illumination. It is the contrast, the area between light and'** metadata={'source': './data/earth_at_night_508.pdf', 'page': 9}
'**Darkness is not void of illumination. It is the contrast, the area between light and **\ndark, that is often the most illustrative. Darkness reminds me of where I came from and where I am now—from a small town in the mountains, to the unique vantage point of the Nation’s capital. Darkness is where dreamers and learners of all ages peer into the universe and think of questions about themselves and their space in the cosmos. Light is where they work, where they gather, and take time together.\nNASA’s spacefaring satellites have compiled an unprecedented record of our \nEarth, and its luminescence in darkness, to captivate and spark curiosity. These missions see the contrast between dark and light through the lenses of scientific instruments. Our home planet is full of complex and dynamic cycles and processes. These soaring observers show us new ways to discern the nuances of light created by natural and human-made sources, such as auroras, wildfires, cities, phytoplankton, and volcanoes.' metadata={'source': './data/earth_at_night_508.pdf', 'page': 9}
Kemampuan Kustom
Sampel pembuatan penggugusan dan penyematan berukuran tetap menunjukkan pembuatan penggugusan dan penyematan vektor menggunakan model penyematan Azure OpenAI. Sampel ini menggunakan keterampilan kustom Azure AI Search di repositori Power Skills untuk membungkus langkah penggugusan.