Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Tutorial ini menunjukkan kepada Anda cara menangani peristiwa di akun penyimpanan yang memiliki kumpulan nama XML hierarkis.
Anda akan membuat solusi kecil yang memungkinkan pengguna untuk mengisi tabel Databricks Delta dengan mengunggah file nilai yang dipisahkan koma (csv) yang menjelaskan pesanan penjualan. Anda akan membangun solusi ini dengan menghubungkan langganan Event Grid, Fungsi Azure, dan Job Azure Databricks.
Dalam tutorial ini, Anda akan:
- Membuat langganan Event Grid yang memanggil Fungsi Azure.
- Membuat Fungsi Azure yang menerima pemberitahuan dari suatu peristiwa, lalu menjalankan pekerjaan di Azure Databricks.
- Membuat pekerjaan Databricks yang menyisipkan pesanan pelanggan ke dalam tabel Databricks Delta yang terletak di akun penyimpanan.
Kami akan membangun solusi ini secara terbalik, dimulai dengan ruang kerja Azure Databricks.
Prasyarat
Buat akun penyimpanan yang memiliki namespace hierarkis (Azure Data Lake Storage). Tutorial ini menggunakan akun penyimpanan bernama
contosoorders.Lihat Membuat akun penyimpanan untuk digunakan dengan Azure Data Lake Storage.
Pastikan akun pengguna Anda memiliki peran Storage Blob Data Contributor yang telah ditetapkan padanya.
Buat perwakilan layanan, buat rahasia klien, lalu berikan akses perwakilan layanan ke akun penyimpanan.
Lihat Tutorial: Menyambungkan ke Azure Data Lake Storage (Langkah 1 hingga 3). Setelah menyelesaikan langkah-langkah ini, pastikan untuk menempelkan ID penyewa, ID aplikasi, dan nilai rahasia klien ke dalam file teks. Anda akan membutuhkannya segera.
Jika Anda tidak memiliki langganan Azure, buat akun gratis sebelum Anda memulai.
Membuat pesanan penjualan
Pertama, buat file csv yang menjelaskan pesanan penjualan, lalu unggah file itu ke akun penyimpanan. Nantinya, Anda akan menggunakan data dari file ini untuk mengisi baris pertama dalam tabel Databricks Delta kami.
Navigasikan ke akun penyimpanan baru Anda di portal Microsoft Azure.
Pilih Storage browser->Blob containers->Add container dan buat kontainer baru bernama data.
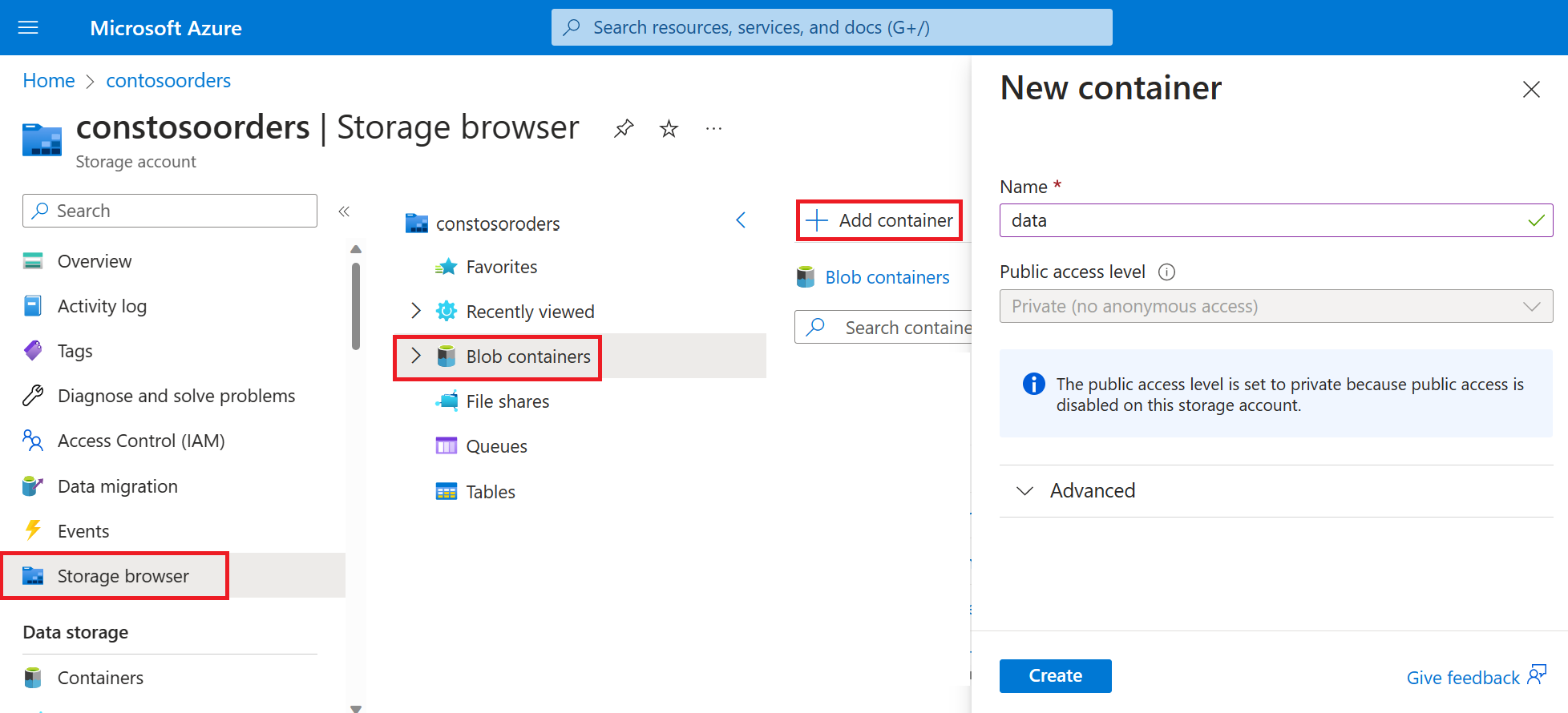
Dalam kontainer data, buat direktori bernama input.
Tempelkan teks berikut ke editor teks.
InvoiceNo,StockCode,Description,Quantity,InvoiceDate,UnitPrice,CustomerID,Country 536365,85123A,WHITE HANGING HEART T-LIGHT HOLDER,6,12/1/2010 8:26,2.55,17850,United KingdomSimpan file ini ke komputer lokal Anda dan beri nama data.csv.
Di browser penyimpanan, unggah file ini ke folder input .
Membuat pekerjaan di Azure Databricks
Di bagian ini, Anda akan melakukan tugas-tugas ini:
- Membuat ruang kerja Azure Databricks.
- Buat buku catatan.
- Buat dan mengisi tabel Databricks Delta.
- Tambahkan kode yang menyisipkan baris ke dalam tabel Databricks Delta.
- Buat pekerjaan.
Membuat ruang kerja Azure Databricks
Di bagian ini, Anda membuat ruang kerja Azure Databricks menggunakan portal Microsoft Azure.
Membuat ruang kerja Azure Databricks. Beri nama ruang
contoso-orderskerja tersebut . Lihat Membuat ruang kerja Azure Databricks.Membuat sebuah kluster. Beri nama kluster
customer-order-cluster. Lihat Buat kluster.Buat buku catatan. Beri nama buku catatan
configure-customer-tabledan pilih Python sebagai bahasa default buku catatan. Lihat Membuat buku catatan.
Membuat dan mengisi tabel Databricks Delta
Di buku catatan yang Anda buat, salin dan tempel blok kode berikut ini ke dalam sel pertama, tapi jangan jalankan kode ini dulu.
** Ganti nilai tempat penampung
appId,password,tenantdi dalam blok kode ini dengan nilai yang telah Anda kumpulkan setelah menyelesaikan prasyarat dari tutorial ini.dbutils.widgets.text('source_file', "", "Source File") spark.conf.set("fs.azure.account.auth.type", "OAuth") spark.conf.set("fs.azure.account.oauth.provider.type", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider") spark.conf.set("fs.azure.account.oauth2.client.id", "<appId>") spark.conf.set("fs.azure.account.oauth2.client.secret", "<password>") spark.conf.set("fs.azure.account.oauth2.client.endpoint", "https://login.microsoftonline.com/<tenant>/oauth2/token") adlsPath = 'abfss://data@contosoorders.dfs.core.windows.net/' inputPath = adlsPath + dbutils.widgets.get('source_file') customerTablePath = adlsPath + 'delta-tables/customers'Kode ini membuat widget bernama source_file. Nantinya, Anda akan membuat Fungsi Azure yang memanggil kode ini dan meneruskan jalur file ke widget tersebut. Kode ini juga mengautentikasi perwakilan layanan Anda dengan akun penyimpanan, dan membuat beberapa variabel yang akan Anda gunakan di sel lain.
Catatan
Dalam pengaturan produksi, pertimbangkan untuk menyimpan kunci autentikasi Anda di Azure Databricks. Kemudian, tambahkan kunci pencarian ke blok kode Anda alih-alih kunci autentikasi.
Misalnya, alih-alih menggunakan baris kode ini:spark.conf.set("fs.azure.account.oauth2.client.secret", "<password>"), Anda akan menggunakan baris kode berikut:spark.conf.set("fs.azure.account.oauth2.client.secret", dbutils.secrets.get(scope = "<scope-name>", key = "<key-name-for-service-credential>")).
Setelah Anda menyelesaikan tutorial ini, lihat artikel Azure Data Lake Storage di Situs Web Azure Databricks untuk melihat contoh pendekatan ini.Tekan kunci SHIFT + ENTER untuk menjalankan kode di blok ini.
Salin dan tempel blok kode berikut ke dalam sel yang berbeda, lalu tekan kunci SHIFT + ENTER untuk menjalankan kode di blok ini.
from pyspark.sql.types import StructType, StructField, DoubleType, IntegerType, StringType inputSchema = StructType([ StructField("InvoiceNo", IntegerType(), True), StructField("StockCode", StringType(), True), StructField("Description", StringType(), True), StructField("Quantity", IntegerType(), True), StructField("InvoiceDate", StringType(), True), StructField("UnitPrice", DoubleType(), True), StructField("CustomerID", IntegerType(), True), StructField("Country", StringType(), True) ]) rawDataDF = (spark.read .option("header", "true") .schema(inputSchema) .csv(adlsPath + 'input') ) (rawDataDF.write .mode("overwrite") .format("delta") .saveAsTable("customer_data", path=customerTablePath))Kode ini membuat tabel Databricks Delta di akun penyimpanan Anda, lalu memuat beberapa data awal dari file csv yang Anda unggah sebelumnya.
Setelah blok kode ini berhasil dijalankan, hapus blok kode ini dari buku catatan Anda.
Tambahkan kode yang menyisipkan baris ke dalam tabel Databricks Delta
Salin dan tempel blok kode berikut ke dalam sel yang berbeda, tapi jangan jalankan sel ini.
upsertDataDF = (spark .read .option("header", "true") .csv(inputPath) ) upsertDataDF.createOrReplaceTempView("customer_data_to_upsert")Kode ini menyisipkan data ke dalam tampilan tabel sementara dengan menggunakan data dari file csv. Jalur ke file csv itu berasal dari widget input yang Anda buat di langkah sebelumnya.
Salin dan tempel blok kode berikut ke dalam sel yang berbeda. Kode ini menggabungkan konten tampilan tabel sementara dengan tabel Databricks Delta.
%sql MERGE INTO customer_data cd USING customer_data_to_upsert cu ON cd.CustomerID = cu.CustomerID WHEN MATCHED THEN UPDATE SET cd.StockCode = cu.StockCode, cd.Description = cu.Description, cd.InvoiceNo = cu.InvoiceNo, cd.Quantity = cu.Quantity, cd.InvoiceDate = cu.InvoiceDate, cd.UnitPrice = cu.UnitPrice, cd.Country = cu.Country WHEN NOT MATCHED THEN INSERT (InvoiceNo, StockCode, Description, Quantity, InvoiceDate, UnitPrice, CustomerID, Country) VALUES ( cu.InvoiceNo, cu.StockCode, cu.Description, cu.Quantity, cu.InvoiceDate, cu.UnitPrice, cu.CustomerID, cu.Country)
Membuat Pekerjaan
Buat Pekerjaan yang menjalankan buku catatan yang Anda buat sebelumnya. Nantinya, Anda akan membuat Fungsi Azure yang menjalankan pekerjaan ini saat acara dinaikkan.
Pilih >.
Beri nama pekerjaan, pilih notebook yang Anda buat dan klaster. Lalu, pilih Buat untuk membuat pekerjaan.
Buat Fungsi Azure
Buat Fungsi Azure yang menjalankan Pekerjaan.
Di ruang kerja Azure Databricks Anda, klik nama pengguna Azure Databricks Anda di bilah atas, lalu dari daftar drop-down, pilih Pengaturan Pengguna.
Pada tab Token akses, pilih Hasilkan token baru.
Salin token yang muncul, lalu klik Selesai.
Di sudut atas ruang kerja Databricks, pilih ikon orang, lalu pilih Pengaturan pengguna.

Pilih tombol Buat token baru, lalu pilih tombol Hasilkan .
Pastikan untuk menyalin token ke tempat yang aman. Fungsi Azure Anda memerlukan token ini untuk otentikasi dengan Databricks sehingga dapat menjalankan Pekerjaan.
Pada menu portal Microsoft Azure atau halaman Beranda, pilih Buat sumber daya.
Di halaman Baru, pilih Komputasi>Aplikasi Fungsi.
Di tab Dasar-dasarhalaman Buat Aplikasi Fungsi, pilih grup sumber daya, lalu ubah atau verifikasi pengaturan berikut ini:
Pengaturan Nilai Nama Aplikasi Fungsi contosoorder Stak waktu jalan .NET Terbitkan Kode Sistem Operasi Windows Jenis rencana Konsumsi (Tanpa Server) Pilih Tinjau + buat, lalu pilih Buat.
Saat penyebaran selesai, pilih Buka sumber daya untuk membuka halaman gambaran umum Aplikasi Fungsi.
Di grup Pengaturan, pilih Konfigurasi.
Di halaman Pengaturan Aplikasi pilih tombol Pengaturan aplikasi baru untuk menambahkan setiap pengaturan.

Tambahkan pengaturan berikut:
Nama pengaturan Nilai DBX_INSTANCE Wilayah ruang kerja databricks Anda. Misalnya: westus2.azuredatabricks.netDBX_PAT Token akses pribadi yang Anda hasilkan sebelumnya. DBX_JOB_ID Pengidentifikasi dari pekerjaan yang sedang berjalan. Pilih Simpan untuk menerapkan pengaturan ini.
Di grup Fungsi, pilih Fungsi, lalu pilih Buat.
Pilih Pemicu Azure Event Grid.
Pasang ekstensi Microsoft.Azure.WebJobs.Extensions.EventGrid jika Anda diminta untuk melakukannya. Jika Anda harus memasangnya, maka Anda harus memilih Pemicu Azure Event Grid lagi untuk membuat fungsi.
Panel Fungsi Baru muncul.
Di panel Fungsi Baru, beri nama fungsi UpsertOrder, lalu pilih tombol Buat .
Ganti konten file kode dengan kode ini, lalu pilih tombol Simpan :
#r "Azure.Messaging.EventGrid" #r "System.Memory.Data" #r "Newtonsoft.Json" #r "System.Text.Json" using Azure.Messaging.EventGrid; using Azure.Messaging.EventGrid.SystemEvents; using Newtonsoft.Json; using Newtonsoft.Json.Linq; private static HttpClient httpClient = new HttpClient(); public static async Task Run(EventGridEvent eventGridEvent, ILogger log) { log.LogInformation("Event Subject: " + eventGridEvent.Subject); log.LogInformation("Event Topic: " + eventGridEvent.Topic); log.LogInformation("Event Type: " + eventGridEvent.EventType); log.LogInformation(eventGridEvent.Data.ToString()); if (eventGridEvent.EventType == "Microsoft.Storage.BlobCreated" || eventGridEvent.EventType == "Microsoft.Storage.FileRenamed") { StorageBlobCreatedEventData fileData = eventGridEvent.Data.ToObjectFromJson<StorageBlobCreatedEventData>(); if (fileData.Api == "FlushWithClose") { log.LogInformation("Triggering Databricks Job for file: " + fileData.Url); var fileUrl = new Uri(fileData.Url); var httpRequestMessage = new HttpRequestMessage { Method = HttpMethod.Post, RequestUri = new Uri(String.Format("https://{0}/api/2.0/jobs/run-now", System.Environment.GetEnvironmentVariable("DBX_INSTANCE", EnvironmentVariableTarget.Process))), Headers = { { System.Net.HttpRequestHeader.Authorization.ToString(), "Bearer " + System.Environment.GetEnvironmentVariable("DBX_PAT", EnvironmentVariableTarget.Process)}, { System.Net.HttpRequestHeader.ContentType.ToString(), "application/json" } }, Content = new StringContent(JsonConvert.SerializeObject(new { job_id = System.Environment.GetEnvironmentVariable("DBX_JOB_ID", EnvironmentVariableTarget.Process), notebook_params = new { source_file = String.Join("", fileUrl.Segments.Skip(2)) } })) }; var response = await httpClient.SendAsync(httpRequestMessage); response.EnsureSuccessStatusCode(); } } }
Kode ini memilah informasi tentang peristiwa penyimpanan yang dinaikkan, lalu membuat pesan permintaan dengan url file yang memicu peristiwa tersebut. Sebagai bagian dari pesan, fungsi ini meneruskan nilai ke widget source_file yang Anda buat sebelumnya. Kode fungsi mengirim pesan ke Pekerjaan Databricks dan menggunakan token yang Anda peroleh sebelumnya sebagai autentikasi.
Buat langganan Event Grid
Di bagian ini, Anda akan membuat langganan Event Grid yang memanggil Fungsi Azure saat file diunggah ke akun penyimpanan.
Pilih Integrasi, lalu di halaman Integrasi , pilih Pemicu Event Grid.
Di panel Edit Pemicu , beri nama peristiwa
eventGridEvent, lalu pilih Buat Langganan peristiwa.Catatan
Nama
eventGridEventcocok dengan parameter bernama yang diteruskan ke Azure Function.Di tab Dasar-dasarhalaman Buat Langganan Peristiwa, ubah atau verifikasi pengaturan berikut ini:
Pengaturan Nilai Nama langganan-acara-pemesanan-contoso Jenis topik Akun Penyimpanan Sumber Daya contosoorders Nama topik sistem <create any name>Filter ke Jenis Peristiwa Blob Dibuat, dan Blob Dihapus Pilih tombol Buat.
Menguji langganan Event Grid
Buat file bernama
customer-order.csv, tempelkan informasi berikut ke file tersebut, dan simpan ke komputer lokal Anda.InvoiceNo,StockCode,Description,Quantity,InvoiceDate,UnitPrice,CustomerID,Country 536371,99999,EverGlow Single,228,1/1/2018 9:01,33.85,20993,Sierra LeoneDi Storage Explorer, unggah file ini ke folder input di akun penyimpanan Anda.
Mengunggah file akan meningkatkan peristiwa Microsoft.Storage.BlobCreated. Event Grid memberi tahu semua pelanggan tentang acara tersebut. Dalam kasus kami, Azure Functions adalah satu-satunya pelanggan. Fungsi Azure memilah parameter peristiwa untuk menentukan peristiwa mana yang terjadi. Kemudian meneruskan URL file ke tugas Databricks. Job Databricks membaca file, dan menambahkan baris ke tabel Databricks Delta yang terdapat di akun penyimpanan Anda.
Untuk memeriksa apakah pekerjaan berhasil, lihat hasil untuk pekerjaan Anda. Anda akan melihat status penyelesaian. Untuk informasi selengkapnya tentang cara melihat pelaksanaan untuk pekerjaan, lihat Menampilkan pelaksanaan untuk pekerjaan
Di sel buku kerja baru, jalankan kueri ini dalam sel untuk melihat tabel delta yang diperbarui.
%sql select * from customer_dataTabel yang dikembalikan menampilkan catatan terbaru.

Untuk memperbarui rekaman ini, buat file bernama
customer-order-update.csv, tempelkan informasi berikut ke dalam file tersebut, dan simpan ke komputer lokal Anda.InvoiceNo,StockCode,Description,Quantity,InvoiceDate,UnitPrice,CustomerID,Country 536371,99999,EverGlow Single,22,1/1/2018 9:01,33.85,20993,Sierra LeoneFile csv ini hampir identik dengan yang sebelumnya kecuali kuantitas pesanan diubah dari
228ke22.Di Storage Explorer, unggah file ini ke folder input di akun penyimpanan Anda.
Jalankan
selectkueri lagi untuk melihat tabel delta yang diperbarui.%sql select * from customer_dataTabel yang dikembalikan memperlihatkan rekaman yang diperbarui.

Membersihkan sumber daya
Saat tidak perlu lagi, hapus grup sumber daya dan semua sumber daya terkait. Untuk melakukannya, pilih grup sumber daya untuk akun penyimpanan dan pilih Hapus.