Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Akselerasi kueri memungkinkan aplikasi dan kerangka kerja analitik untuk mengoptimalkan pemrosesan data secara dramatis dengan hanya mengambil data yang mereka butuhkan untuk melakukan operasi tertentu. Ini mengurangi waktu dan daya pemrosesan yang diperlukan untuk mendapatkan wawasan penting tentang data yang disimpan.
Gambaran Umum
Akselerasi kueri menerima predikat pemfilteran dan proyeksi kolom, yang memungkinkan aplikasi memfilter baris dan kolom pada saat data dibaca dari disk. Hanya data yang memenuhi kondisi predikat yang ditransfer melalui jaringan ke aplikasi. Ini mengurangi latensi jaringan dan biaya komputasi.
Anda dapat menggunakan SQL untuk menentukan predikat filter baris dan proyeksi kolom dalam permintaan akselerasi kueri. Permintaan hanya memproses satu file. Oleh karena itu, fitur relasional lanjutan SQL, seperti gabungan dan grup berdasarkan agregat, tidak didukung. Akselerasi kueri mendukung data berformat CSV dan JSON sebagai input untuk setiap permintaan.
Fitur akselerasi kueri tidak terbatas pada Data Lake Storage (akun penyimpanan yang mengaktifkan namespace hierarkis). Akselerasi kueri kompatibel dengan blob di akun penyimpanan yang tidak mengaktifkan namespace hierarkis. Ini berarti Bahwa Anda dapat mencapai pengurangan latensi jaringan dan biaya komputasi yang sama ketika Anda memproses data yang sudah Anda simpan sebagai blob di akun penyimpanan.
Untuk contoh cara menggunakan akselerasi kueri dalam aplikasi klien, lihat Memfilter data dengan menggunakan akselerasi kueri Azure Data Lake Storage.
Aliran Data
Diagram berikut mengilustrasikan bagaimana aplikasi umum menggunakan akselerasi kueri untuk memproses data.
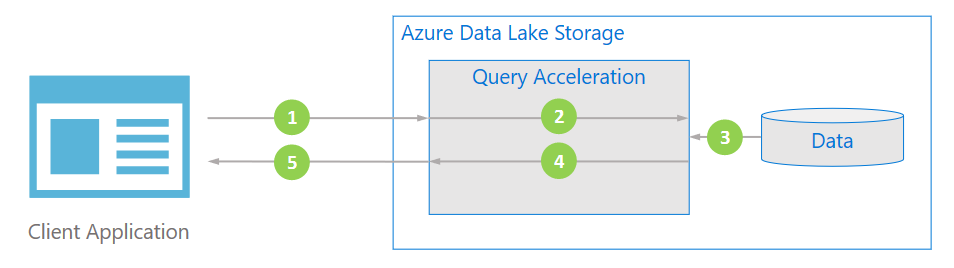
Aplikasi klien meminta data file dengan menentukan predikat dan proyeksi kolom.
Akselerasi kueri mengurai kueri SQL yang ditentukan dan mendistribusikan pekerjaan untuk mengurai dan memfilter data.
Prosesor membaca data dari disk, mengurai data dengan menggunakan format yang sesuai, lalu memfilter data dengan menerapkan predikat dan proyeksi kolom yang ditentukan.
Akselerasi kueri menggabungkan pecahan respons untuk mengalirkan kembali ke aplikasi klien.
Aplikasi klien menerima dan mengurai respons yang dialirkan. Aplikasi tidak perlu memfilter data lain dan dapat menerapkan perhitungan atau transformasi yang diinginkan secara langsung.
Performa yang lebih baik dengan biaya yang lebih rendah
Akselerasi kueri mengoptimalkan performa dengan mengurangi jumlah data yang ditransfer dan diproses oleh aplikasi Anda.
Untuk menghitung nilai agregat, aplikasi biasanya mengambil semua data dari file, lalu memproses dan memfilter data secara lokal. Analisis pola input/output untuk beban kerja analitik mengungkapkan bahwa aplikasi biasanya hanya memerlukan 20% data yang mereka baca untuk melakukan perhitungan tertentu. Statistik ini berlaku bahkan setelah menerapkan teknik seperti pemangkasan partisi. Ini berarti bahwa 80% data tersebut secara tidak perlu ditransfer melalui jaringan, diurai, dan difilter oleh aplikasi. Pola ini, dirancang untuk menghapus data yang tidak perlu, menimbulkan biaya komputasi yang signifikan.
Meskipun Azure memiliki jaringan terdepan di industri, dalam hal throughput dan latensi, mentransfer data dengan sia-sia melintasi jaringan tersebut masih berdampak negatif pada kinerja aplikasi. Dengan memfilter data yang tidak diinginkan selama permintaan penyimpanan, akselerasi kueri menghilangkan biaya ini.
Selain itu, beban CPU yang diperlukan untuk mengurai dan memfilter data yang tidak diperlukan mengharuskan aplikasi Anda untuk menyediakan jumlah yang lebih besar dan VM yang lebih besar untuk melakukan pekerjaannya. Dengan mentransfer beban komputasi ini ke akselerasi kueri, aplikasi dapat mewujudkan penghematan biaya yang signifikan.
Aplikasi yang dapat memperoleh manfaat dari akselerasi kueri
Akselerasi kueri dirancang untuk kerangka kerja analitik terdistribusi dan aplikasi pemrosesan data.
Kerangka kerja analitik terdistribusi seperti Apache Spark dan Apache Hive, menyertakan lapisan abstraksi penyimpanan dalam kerangka kerja. Mesin ini juga mencakup pengoptimal kueri yang dapat menggabungkan pengetahuan tentang kemampuan layanan I/O yang mendasarinya saat menentukan rencana kueri yang optimal untuk kueri pengguna. Kerangka kerja ini mulai mengintegrasikan akselerasi kueri. Akibatnya, pengguna kerangka kerja ini melihat latensi kueri yang ditingkatkan dan total biaya kepemilikan yang lebih rendah tanpa harus membuat perubahan apa pun pada kueri.
Akselerasi kueri juga dirancang untuk aplikasi pemrosesan data. Jenis aplikasi ini biasanya melakukan transformasi data skala besar yang mungkin tidak langsung mengarah ke wawasan analitik sehingga mereka tidak selalu menggunakan kerangka kerja analitik terdistribusi yang ditetapkan. Aplikasi ini sering memiliki hubungan yang lebih langsung dengan layanan penyimpanan yang mendasar sehingga mereka dapat memperoleh manfaat langsung dari fitur seperti akselerasi kueri.
Untuk contoh bagaimana aplikasi dapat mengintegrasikan akselerasi kueri, lihat Memfilter data dengan menggunakan akselerasi kueri Azure Data Lake Storage.
Penetapan Harga
Karena peningkatan beban komputasi dalam layanan Azure Data Lake Storage, model harga untuk menggunakan akselerasi kueri berbeda dari model transaksi Azure Data Lake Storage normal. Akselerasi kueri membebankan biaya untuk jumlah data yang dipindai serta biaya untuk jumlah data yang dikembalikan ke pemanggil. Untuk informasi selengkapnya, lihat Harga Azure Data Lake Storage.
Terlepas dari perubahan pada model penagihan, model harga Akselerasi Kueri dirancang untuk menurunkan total biaya kepemilikan untuk beban kerja, mengingat pengurangan biaya VM yang jauh lebih mahal.