Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Latensi, terkadang dirujuk sebagai waktu respons, adalah jumlah waktu aplikasi harus menunggu permintaan selesai. Latensi dapat secara langsung mempengaruhi performa aplikasi. Latensi rendah biasanya penting untuk skenario dengan manusia dalam perulangan, seperti melakukan transaksi kartu kredit atau memuat halaman web. Sistem yang perlu memproses peristiwa masuk dengan nilai tinggi, seperti pencatatan telemetri atau peristiwa IoT, juga memerlukan latensi rendah. Artikel ini menjelaskan cara memahami dan mengukur latensi untuk operasi pada blob blok, dan cara mendesain aplikasi Anda untuk latensi rendah.
Azure Storage menawarkan dua opsi performa yang berbeda untuk blob blok: premium dan standar. Blob blok premium menawarkan latensi yang jauh lebih rendah dan lebih konsisten daripada blob blok standar melalui disk SSD dengan performa tinggi. Untuk informasi selengkapnya, lihat Akun penyimpanan blob blok premium.
Tentang latensi Azure Storage
Latensi Azure Storage berkaitan dengan tingkat permintaan untuk operasi Azure Storage. Tingkat permintaan juga disebut dengan operasi input/output per detik (IOPS).
Untuk menghitung tingkat permintaan, pertama-tama tentukan lamanya waktu yang diperlukan setiap permintaan agar bisa selesai, lalu hitung berapa banyak permintaan yang dapat diproses per detik. Misalnya, asumsikan permintaan membutuhkan 50 milidetik (ms) untuk diselesaikan. Aplikasi yang menggunakan satu utas dengan satu operasi baca atau tulis yang luar biasa harus mencapai 20 IOPS (1 detik atau 1000 ms / 50 ms per permintaan). Secara teoritis, jika jumlah utas digandakan menjadi dua, maka aplikasi harus dapat mencapai 40 IOPS. Jika operasi baca atau tulis asinkron luar biasa untuk setiap utas digandakan menjadi dua, maka aplikasi harus dapat mencapai 80 IOPS.
Dalam praktiknya, tingkat permintaan tidak selalu menskalakan secara linear, karena atas hulu pada klien dari penjadwalan tugas, peralihan konteks, dan sebagainya. Di sisi layanan, dapat terjadi variabilitas dalam latensi karena tugas pada sistem Azure Storage, perbedaan dalam media penyimpanan yang digunakan, kebisingan dari beban kerja lain, tugas pemeliharaan, dan faktor lainnya. Akhirnya, koneksi jaringan antara klien dan server dapat memengaruhi latensi Azure Storage karena kemacetan, perutean ulang, atau gangguan lainnya.
Bandwidth Azure Storage, juga disebut sebagai throughput, terkait dengan tingkat permintaan dan dapat dihitung dengan mengalikan tingkat permintaan (IOPS) berdasarkan ukuran permintaan. Misalnya, dengan asumsi 160 permintaan per detik, masing-masing data 256 KiB menghasilkan throughput 40.960 KiB per detik atau 40 MiB per detik.
Metrik latensi untuk blob blok
Azure Storage menyediakan dua metrik latensi untuk blob blok. Metrik ini dapat dilihat di portal Microsoft Azure:
Latensi end-to-end (E2E) mengukur interval dari saat Azure Storage menerima paket pertama permintaan hingga Azure Storage menerima pengakuan klien pada paket terakhir respons.
Latensi server mengukur interval dari saat Azure Storage menerima paket terakhir permintaan hingga paket pertama respons dikembalikan dari Azure Storage.
Gambar berikut menunjukkan Latensi E2E Keberhasilan Rata-Rata dan Latensi Server Keberhasilan Rata-Rata untuk contoh beban kerja yang memanggil operasi Get Blob:
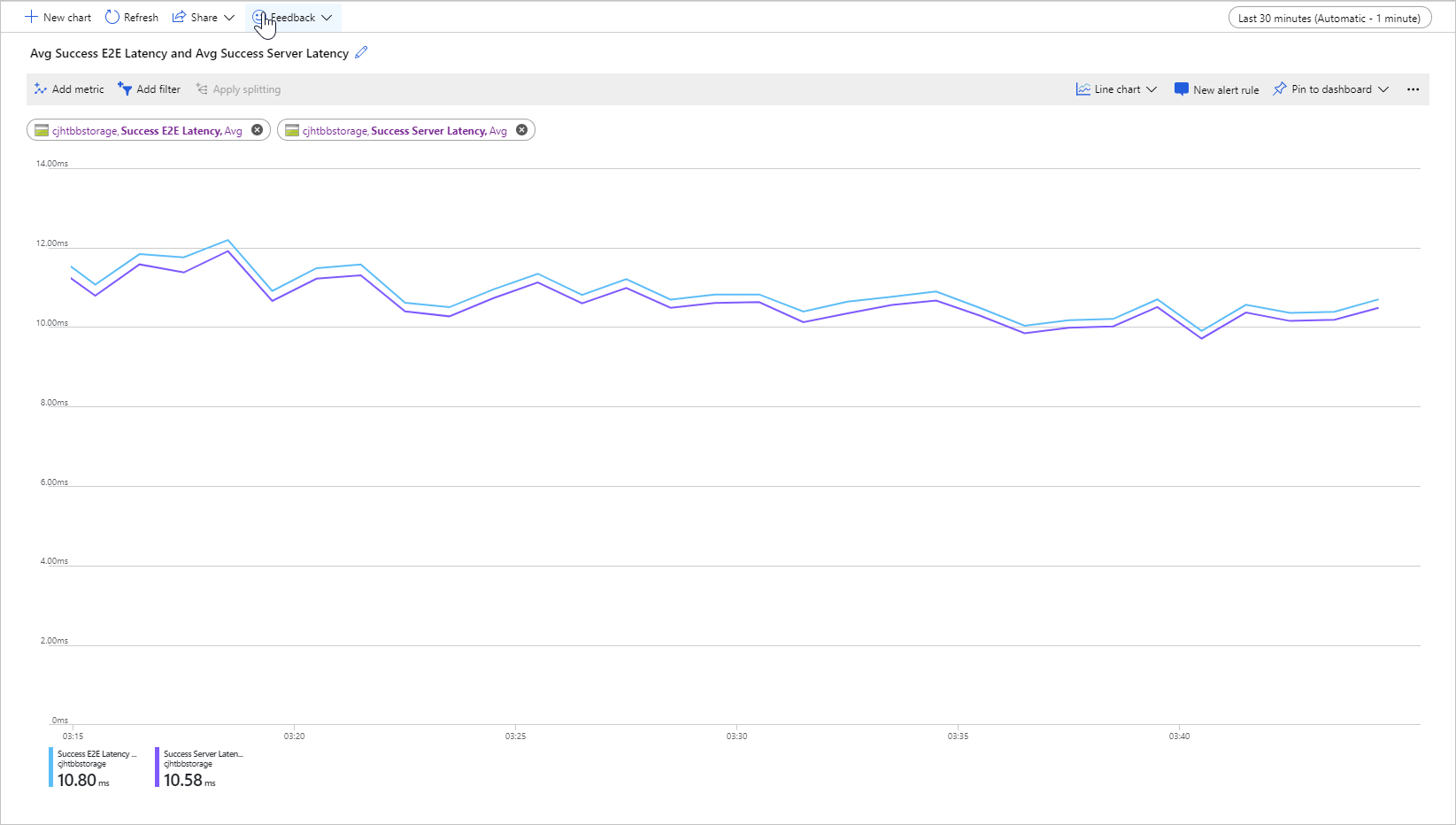
Dalam kondisi normal, ada sedikit kesenjangan antara latensi end-to-end dan latensi server, yang ditunjukkan gambar untuk beban kerja sampel.
Jika Anda meninjau metrik latensi end-to-end dan server Anda, dan menemukan bahwa latensi end-to-end jauh lebih tinggi dari latensi server, lalu menyelidiki dan mengatasi sumber latensi tambahan.
Jika latensi end-to-end dan server Anda serupa, tetapi Anda memerlukan latensi yang lebih rendah, pertimbangkan untuk bermigrasi ke penyimpanan blob blok premium.
Faktor-faktor yang mempengaruhi latensi
Faktor utama yang mempengaruhi latensi adalah ukuran operasi. Dibutuhkan waktu lebih lama untuk menyelesaikan operasi yang lebih besar, karena jumlah data yang ditransfer melalui jaringan dan diproses oleh Azure Storage.
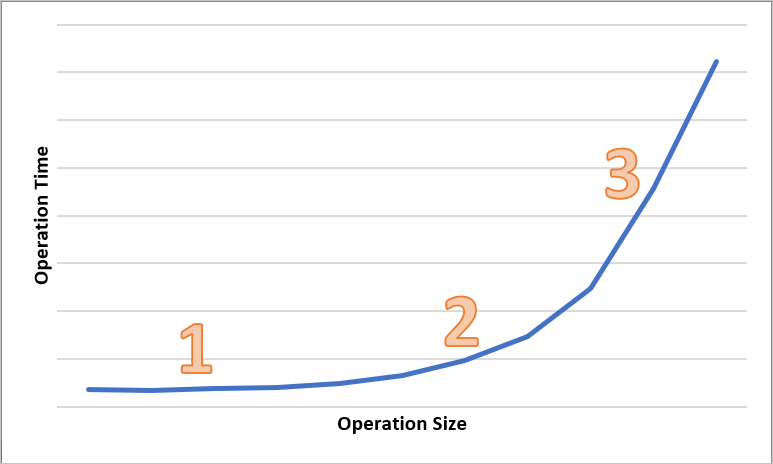
Diagram berikut menunjukkan total waktu untuk operasi dengan berbagai ukuran. Untuk sejumlah kecil data, interval latensi sebagian besar dihabiskan untuk menangani permintaan, dibandingkan mentransfer data. Interval latensi hanya meningkat sedikit saat ukuran operasi meningkat (ditandai 1 dalam diagram di bawah). Ketika ukuran operasi makin meningkat, lebih banyak waktu dihabiskan untuk mentransfer data, sehingga interval latensi total dibagi antara penanganan permintaan dan transfer data (ditandai 2 dalam diagram di bawah). Dengan ukuran operasi yang lebih besar, interval latensi hampir secara eksklusif dihabiskan untuk mentransfer data dan penanganan permintaan sebagian besar tidak signifikan (ditandai 3 dalam diagram di bawah).
Faktor konfigurasi klien seperti konkurensi dan pembuatan utas juga mempengaruhi latensi. Throughput keseluruhan tergantung pada berapa banyak permintaan penyimpanan dalam penerbangan pada titik waktu tertentu dan cara aplikasi Anda menangani pembuatan utas. Sumber daya klien termasuk CPU, memori, penyimpanan lokal, dan antarmuka jaringan juga dapat memengaruhi latensi.
Memproses permintaan Azure Storage memerlukan CPU dan sumber daya memori klien. Jika klien berada di bawah tekanan karena komputer virtual yang kurang bertenaga atau beberapa proses menghindar dalam sistem, ada lebih sedikit sumber daya yang tersedia untuk memproses permintaan Azure Storage. Setiap ketidakcocokan atau kurangnya sumber daya klien akan mengakibatkan meningkatnya latensi end-to-end tanpa peningkatan latensi server, meningkatkan kesenjangan antara dua metrik.
Yang tak kalah penting adalah antarmuka jaringan dan pipa jaringan antara klien dan Azure Storage. Jarak fisik saja bisa menjadi faktor penting, misalnya jika VM klien berada di wilayah atau lokal Azure yang berbeda. Faktor lain seperti hop jaringan, perutean ISP, dan status internet dapat memengaruhi latensi penyimpanan secara keseluruhan.
Untuk menilai latensi, pertama-tama buat metrik garis besar untuk skenario Anda. Metrik garis besar memberi Anda latensi end-to-end dan server yang diharapkan dalam konteks lingkungan aplikasi Anda, tergantung pada profil beban kerja Anda, pengaturan konfigurasi aplikasi, sumber daya klien, pipa jaringan, dan faktor lainnya. Ketika Anda memiliki metrik garis besar, Anda dapat lebih mudah mengidentifikasi kondisi abnormal versus normal. Metrik garis besar juga memungkinkan Anda mengamati efek parameter yang diubah, seperti konfigurasi aplikasi atau ukuran VM.