Pola desain tabel
Artikel ini menjelaskan beberapa pola yang sesuai untuk digunakan dengan solusi layanan Tabel. Selain itu, Anda akan melihat bagaimana Anda secara praktis dapat mengatasi beberapa masalah dan trade-off yang dibahas dalam artikel desain penyimpanan Tabel lainnya. Diagram berikut ini meringkas hubungan antara pola yang berbeda:
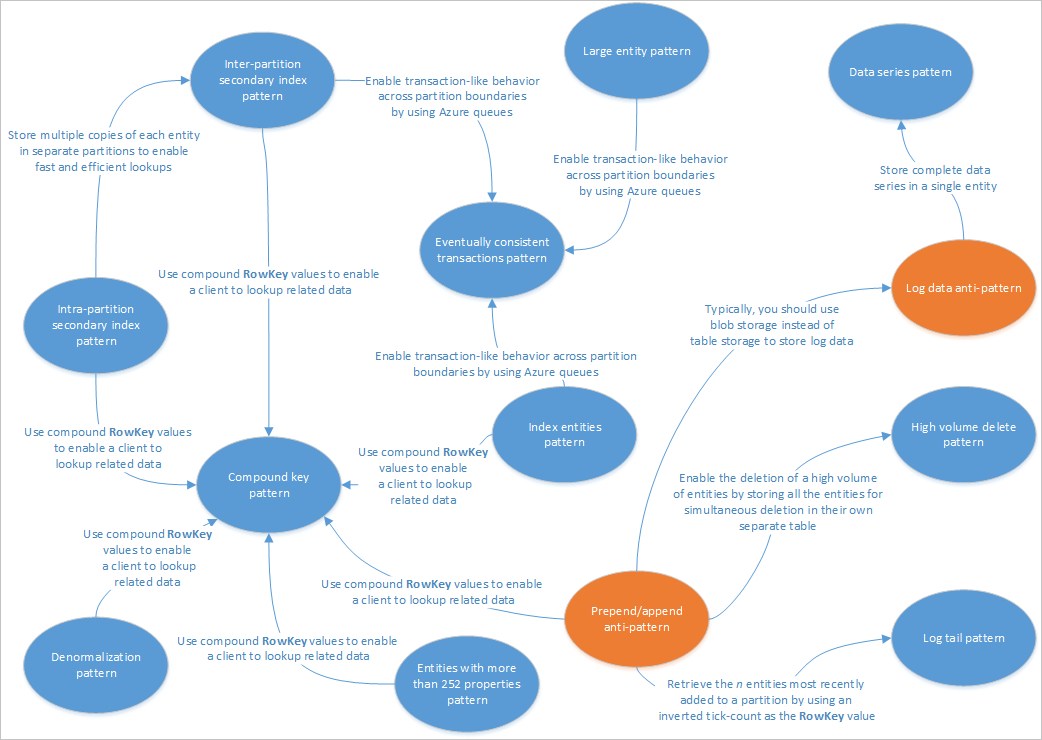
Peta pola di atas menyoroti beberapa hubungan antara pola (biru) dan anti-pola (oranye) yang didokumentasikan dalam panduan ini. Ada banyak pola lain yang patut dipertimbangkan. Misalnya, salah satu skenario utama untuk Layanan Tabel adalah menggunakan Pola Tampilan Terwujud dari pola Command Query Responsibility Segregation (CQRS).
Pola indeks sekunder intra-partisi
Simpan beberapa salinan dari setiap entitas menggunakan nilai RowKey yang berbeda (di partisi yang sama) untuk mengaktifkan pencarian yang cepat dan efisien serta urutan pengurutan alternatif dengan menggunakan nilai RowKey yang berbeda. Pembaruan antarsalinan dapat dijaga konsistensinya menggunakan transaksi grup entitas (EGT).
Konteks dan masalah
Layanan Tabel secara otomatis mengindeks entitas menggunakan nilai PartitionKey dan RowKey. Ini memungkinkan aplikasi klien untuk mengambil entitas secara efisien menggunakan nilai-nilai ini. Misalnya, menggunakan struktur tabel yang ditunjukkan di bawah ini, aplikasi klien dapat menggunakan kueri titik untuk mengambil entitas karyawan individual dengan menggunakan nama departemen dan ID karyawan (nilai PartitionKey dan RowKey). Klien juga dapat mengambil entitas yang diurutkan berdasarkan ID karyawan di setiap departemen.
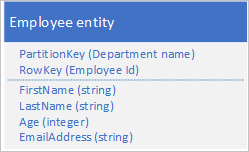
Jika Anda juga ingin dapat menemukan entitas karyawan berdasarkan nilai properti lain seperti alamat email, Anda harus menggunakan pemindaian partisi yang kurang efisien untuk menemukan kecocokan. Ini karena layanan tabel tidak menyediakan indeks sekunder. Selain itu, tidak ada opsi untuk meminta daftar karyawan yang diurutkan dalam urutan yang berbeda dari urutan RowKey.
Solution
Untuk mengatasi kekurangan indeks sekunder, Anda dapat menyimpan beberapa salinan dari setiap entitas dengan setiap salinan menggunakan nilai RowKey yang berbeda. Jika Anda menyimpan entitas dengan struktur yang ditunjukkan di bawah ini, Anda dapat mengambil entitas karyawan secara efisien berdasarkan alamat email atau ID karyawan. Nilai awalan untuk RowKey, "empid_" dan "email_" memungkinkan Anda untuk mengkueri satu karyawan atau berbagai karyawan dengan menggunakan berbagai alamat email atau ID karyawan.

Dua kriteria filter berikut (satu mencari berdasarkan ID karyawan dan satu mencari dengan alamat email) keduanya menentukan kueri titik:
- $filter=(PartitionKey eq 'Sales') dan (RowKey eq 'empid_000223')
- $filter=(PartitionKey eq 'Sales') dan (RowKey eq 'email_jonesj@contoso.com')
Jika Anda mengkueri rentang entitas karyawan, Anda bisa menentukan rentang yang diurutkan dalam urutan ID karyawan, atau rentang yang diurutkan dalam urutan alamat email dengan membuat kueri entitas dengan awalan yang sesuai di RowKey.
Untuk menemukan semua karyawan di departemen Penjualan dengan ID karyawan dalam rentang 000100 hingga 000199 gunakan: $filter=(PartitionKey eq 'Penjualan') dan (RowKey ge 'empid_000100') dan (RowKey le 'empid_000199')
Untuk menemukan semua karyawan di departemen Penjualan dengan alamat email yang dimulai dengan penggunaan huruf 'a': $filter=(PartitionKey eq 'Penjualan') dan (RowKey ge 'email_a') dan(RowKey lt 'email_b')
Sintaks filter yang digunakan dalam contoh di atas berasal dari REST API layanan Tabel, untuk informasi selengkapnya, lihat Entitas Kueri.
Masalah dan pertimbangan
Pertimbangkan poin-poin berikut saat memutuskan cara menerapkan pola ini:
Penyimpanan tabel relatif murah untuk digunakan sehingga biaya overhead penyimpanan data duplikat seharusnya tidak menjadi perhatian utama. Namun, Anda harus selalu mengevaluasi biaya desain berdasarkan persyaratan penyimpanan yang diantisipasi dan hanya menambahkan entitas duplikat untuk mendukung kueri yang akan dijalankan oleh aplikasi klien Anda.
Karena entitas indeks sekunder disimpan di partisi yang sama dengan entitas asli, Anda harus memastikan bahwa Anda tidak melebihi target skalabilitas untuk masing-masing partisi.
Anda dapat menjaga konsistensi entitas duplikat satu sama lain dengan menggunakan EGT untuk memperbarui dua salinan entitas secara atomik. Hal ini menyiratkan bahwa Anda harus menyimpan semua salinan entitas di partisi yang sama. Untuk informasi selengkapnya, lihat bagian Menggunakan Transaksi Grup Entitas.
Nilai yang digunakan untuk RowKey harus unik untuk setiap entitas. Pertimbangkan untuk menggunakan nilai kunci gabungan.
Mengisi nilai numerik di RowKey (misalnya, ID karyawan 000223), memungkinkan pengurutan dan pemfilteran yang benar berdasarkan batas atas dan bawah.
Anda tidak perlu menduplikasi semua properti entitas Anda. Misalnya, jika kueri yang mencari entitas menggunakan alamat email di RowKey tidak memerlukan usia karyawan, entitas ini dapat memiliki struktur berikut:
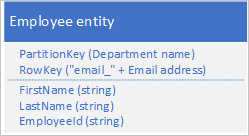
Biasanya lebih baik menyimpan data duplikat dan memastikan bahwa Anda bisa mengambil semua data yang Anda butuhkan dengan satu kueri, daripada menggunakan satu kueri untuk menemukan entitas dan kueri lainnya untuk mencari data yang diperlukan.
Kapan menggunakan pola ini
Gunakan pola ini saat aplikasi klien Anda perlu mengambil entitas menggunakan berbagai kunci yang berbeda, saat klien Anda perlu mengambil entitas dalam urutan yang berbeda, dan di mana Anda dapat mengidentifikasi setiap entitas menggunakan berbagai nilai unik. Namun, Anda harus yakin bahwa Anda tidak melebihi batas skalabilitas partisi saat Anda melakukan pencarian entitas menggunakan nilai RowKey yang berbeda.
Pola dan panduan terkait
Pola dan panduan berikut mungkin juga relevan saat menerapkan pola ini:
- Pola indeks sekunder antar-partisi
- Pola kunci gabungan
- Transaksi Grup Entitas
- Bekerja dengan jenis entitas heterogen
Pola indeks sekunder antar-partisi
Simpan beberapa salinan dari setiap entitas menggunakan nilai RowKey yang berbeda di partisi terpisah atau di tabel terpisah untuk mengaktifkan pencarian yang cepat dan efisien serta urutan pengurutan alternatif dengan menggunakan nilai RowKey yang berbeda.
Konteks dan masalah
Layanan Tabel secara otomatis mengindeks entitas menggunakan nilai PartitionKey dan RowKey. Ini memungkinkan aplikasi klien untuk mengambil entitas secara efisien menggunakan nilai-nilai ini. Misalnya, menggunakan struktur tabel yang ditunjukkan di bawah ini, aplikasi klien dapat menggunakan kueri titik untuk mengambil entitas karyawan individual dengan menggunakan nama departemen dan ID karyawan (nilai PartitionKey dan RowKey). Klien juga dapat mengambil entitas yang diurutkan berdasarkan ID karyawan di setiap departemen.
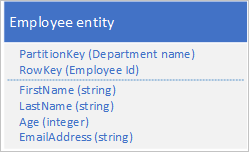
Jika Anda juga ingin dapat menemukan entitas karyawan berdasarkan nilai properti lain seperti alamat email, Anda harus menggunakan pemindaian partisi yang kurang efisien untuk menemukan kecocokan. Ini karena layanan tabel tidak menyediakan indeks sekunder. Selain itu, tidak ada opsi untuk meminta daftar karyawan yang diurutkan dalam urutan yang berbeda dari urutan RowKey.
Anda mengantisipasi volume transaksi yang tinggi terhadap entitas ini dan ingin meminimalkan risiko layanan Tabel yang membatasi klien Anda.
Solution
Untuk mengatasi kekurangan indeks sekunder, Anda dapat menyimpan beberapa salinan dari setiap entitas dengan setiap salinan menggunakan nilai PartitionKey dan RowKey yang berbeda. Jika Anda menyimpan entitas dengan struktur yang ditunjukkan di bawah ini, Anda dapat mengambil entitas karyawan secara efisien berdasarkan alamat email atau ID karyawan. Nilai awalan untuk PartitionKey, "empid_" dan "email_" memungkinkan Anda mengidentifikasi indeks mana yang ingin Anda gunakan untuk kueri.

Dua kriteria filter berikut (satu mencari berdasarkan ID karyawan dan satu mencari dengan alamat email) keduanya menentukan kueri titik:
- $filter=(PartitionKey eq 'empid_Penjualan') dan (RowKey eq '000223')
- $filter=(PartitionKey eq 'email_Penjualan') dan (RowKey eq 'jonesj@contoso.com')
Jika Anda mengkueri rentang entitas karyawan, Anda bisa menentukan rentang yang diurutkan dalam urutan ID karyawan, atau rentang yang diurutkan dalam urutan alamat email dengan membuat kueri entitas dengan awalan yang sesuai di RowKey.
- Untuk menemukan semua karyawan di departemen Penjualan dengan ID karyawan dalam rentang 000100 hingga 000199 yang diurutkan dalam urutan ID karyawan, gunakan: $filter = (PartitionKey eq 'empid_Penjualan') dan (RowKey ge '000100') dan (RowKey le '000199 ')
- Untuk menemukan semua karyawan di departemen Penjualan dengan alamat email yang dimulai dengan 'a' yang diurutkan dalam urutan alamat email, gunakan: $filter=(PartitionKey eq 'email_Penjualan') dan (RowKey ge 'a') dan (RowKey lt 'b')
Sintaks filter yang digunakan dalam contoh di atas berasal dari REST API layanan Tabel, untuk informasi selengkapnya, lihat Entitas Kueri.
Masalah dan pertimbangan
Pertimbangkan poin-poin berikut saat memutuskan cara menerapkan pola ini:
Anda dapat mempertahankan entitas duplikat yang konsisten pada akhirnya satu sama lain dengan menggunakan pola transaksi yang konsisten pada akhirnya untuk mempertahankan entitas indeks utama dan sekunder.
Penyimpanan tabel relatif murah untuk digunakan sehingga biaya overhead penyimpanan data duplikat seharusnya tidak menjadi perhatian utama. Namun, Anda harus selalu mengevaluasi biaya desain berdasarkan persyaratan penyimpanan yang diantisipasi dan hanya menambahkan entitas duplikat untuk mendukung kueri yang akan dijalankan oleh aplikasi klien Anda.
Nilai yang digunakan untuk RowKey harus unik untuk setiap entitas. Pertimbangkan untuk menggunakan nilai kunci gabungan.
Mengisi nilai numerik di RowKey (misalnya, ID karyawan 000223), memungkinkan pengurutan dan pemfilteran yang benar berdasarkan batas atas dan bawah.
Anda tidak perlu menduplikasi semua properti entitas Anda. Misalnya, jika kueri yang mencari entitas menggunakan alamat email di RowKey tidak memerlukan usia karyawan, entitas ini dapat memiliki struktur berikut:
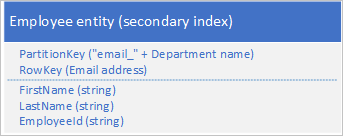
Biasanya lebih baik menyimpan data duplikat dan memastikan bahwa Anda bisa mengambil semua data yang Anda butuhkan dengan satu kueri daripada menggunakan satu kueri untuk menemukan entitas menggunakan indeks sekunder dan kueri lainnya untuk mencari data yang diperlukan di indeks utama.
Kapan menggunakan pola ini
Gunakan pola ini saat aplikasi klien Anda perlu mengambil entitas menggunakan berbagai kunci yang berbeda, saat klien Anda perlu mengambil entitas dalam urutan yang berbeda, dan di mana Anda dapat mengidentifikasi setiap entitas menggunakan berbagai nilai unik. Gunakan pola ini saat Anda ingin menghindari melebihi batas skalabilitas partisi saat Anda melakukan pencarian entitas menggunakan nilai RowKey yang berbeda.
Pola dan panduan terkait
Pola dan panduan berikut mungkin juga relevan saat menerapkan pola ini:
- Pola transaksi yang konsisten pada akhirnya
- Pola indeks sekunder intra-partisi
- Pola kunci gabungan
- Transaksi Grup Entitas
- Bekerja dengan jenis entitas heterogen
Pola transaksi yang konsisten pada akhirnya
Aktifkan perilaku konsisten pada akhirnya di seluruh batas partisi atau batas sistem penyimpanan dengan menggunakan antrean Azure.
Konteks dan masalah
EGT memungkinkan transaksi atomik di beberapa entitas yang berbagi kunci partisi yang sama. Untuk alasan kinerja dan skalabilitas, Anda mungkin memutuskan untuk menyimpan entitas yang memiliki persyaratan konsistensi di partisi terpisah atau dalam sistem penyimpanan terpisah: dalam skenario seperti itu, Anda tidak dapat menggunakan EGT untuk menjaga konsistensi. Misalnya, Anda mungkin memiliki persyaratan untuk mempertahankan konsistensi akhir antara:
- Entitas yang disimpan di dua partisi berbeda di tabel yang sama, di tabel berbeda, atau di akun penyimpanan berbeda.
- Entitas yang disimpan dalam layanan Tabel dan blob yang disimpan dalam Blob service.
- Entitas yang disimpan dalam layanan Tabel dan file dalam sistem file.
- Entitas yang disimpan dalam layanan Tabel namun diindeks menggunakan layanan Azure Cognitive Search.
Solution
Dengan menggunakan antrean Azure, Anda dapat menerapkan solusi yang memberikan konsistensi akhir di dua atau lebih partisi atau sistem penyimpanan. Untuk menggambarkan pendekatan ini, asumsikan Anda memiliki persyaratan untuk dapat mengarsipkan entitas karyawan lama. Entitas karyawan lama jarang dikueri dan harus dikecualikan dari kegiatan apa pun yang berurusan dengan karyawan saat ini. Untuk menerapkan persyaratan ini, Anda menyimpan karyawan aktif di tabel Saat ini dan karyawan lama di tabel Arsip. Pengarsipan karyawan mengharuskan Anda untuk menghapus entitas dari tabel Saat Ini dan menambahkan entitas ke tabel Arsip, tetapi Anda tidak dapat menggunakan EGT untuk melakukan dua operasi ini. Untuk menghindari risiko kegagalan yang menyebabkan entitas muncul di kedua tabel atau tidak sama sekali, operasi arsip harus selalu konsisten. Diagram urutan berikut menguraikan langkah-langkah dalam operasi ini. Detail lebih lanjut disediakan untuk jalur pengecualian dalam teks berikut.
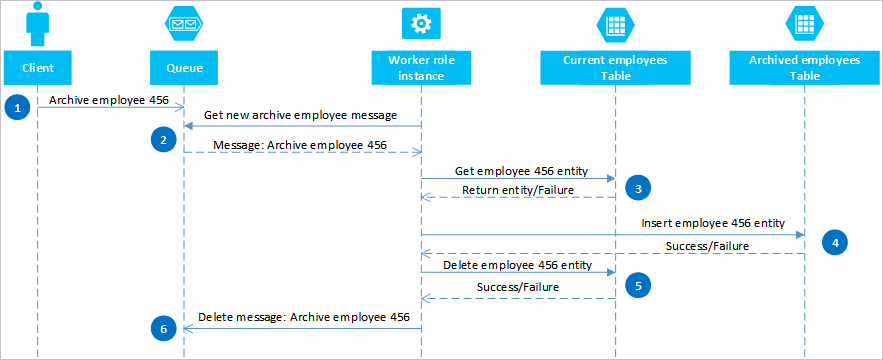
Klien memulai operasi arsip dengan menempatkan pesan pada antrean Azure, dalam contoh ini untuk mengarsipkan karyawan #456. Peran pekerja mengumpulkan antrean untuk pesan baru; ketika menemukannya, itu membaca pesan dan meninggalkan salinan tersembunyi di antrean. Peran pekerja selanjutnya mengambil salinan entitas dari tabel Saat Ini, menyisipkan salinan dalam tabel Arsip, lalu menghapus yang asli dari tabel Saat Ini. Akhirnya, jika tidak ada kesalahan dari langkah-langkah sebelumnya, peran pekerja menghapus pesan tersembunyi dari antrean.
Dalam contoh ini, langkah 4 menyisipkan karyawan ke dalam tabel Arsip. Itu bisa menambahkan karyawan ke blob di Blob service atau file dalam sistem file.
Memulihkan dari kegagalan
Penting bahwa operasi pada langkah 4 dan 5 harus idempotent jika peran pekerja perlu memulai kembali operasi arsip. Jika Anda menggunakan layanan Tabel, untuk langkah 4, Anda harus menggunakan operasi "sisipkan atau ganti"; untuk langkah 5, Anda harus menggunakan operasi "hapus jika ada" di perpustakaan klien yang Anda gunakan. Jika Anda menggunakan sistem penyimpanan lain, Anda harus menggunakan operasi idempoten yang sesuai.
Jika peran pekerja tidak pernah menyelesaikan langkah 6, maka setelah waktu habis pesan muncul kembali pada antrean yang siap untuk peran pekerja untuk mencoba mengolahnya kembali. Peran pekerja dapat memeriksa berapa kali pesan di antrean telah dibaca dan, jika perlu, menandainya sebagai pesan "racun" untuk diselidiki dengan mengirimkannya ke antrean terpisah. Untuk informasi selengkapnya tentang membaca pesan antrean dan memeriksa jumlah yang dihapus dari antrean, lihat Mendapatkan Pesan.
Beberapa kesalahan dari layanan Tabel dan Antrean adalah kesalahan sementara, dan aplikasi klien Anda harus menyertakan logika coba lagi yang sesuai untuk menanganinya.
Masalah dan pertimbangan
Pertimbangkan poin-poin berikut saat memutuskan cara menerapkan pola ini:
- Solusi ini tidak menyediakan isolasi transaksi. Misalnya, klien dapat membaca tabel Saat Ini dan Arsip saat peran pekerja berada di antara langkah 4 dan 5, dan melihat tampilan data yang tidak konsisten. Data akan konsisten pada akhirnya.
- Anda harus yakin bahwa langkah 4 dan 5 idempoten untuk memastikan konsistensi akhir.
- Anda dapat menskalakan solusi dengan menggunakan beberapa antrean dan instans peran pekerja.
Kapan menggunakan pola ini
Gunakan pola ini ketika Anda ingin menjamin konsistensi akhir antara entitas yang ada di partisi atau tabel yang berbeda. Anda dapat memperluas pola ini untuk memastikan konsistensi akhirnya untuk operasi di seluruh layanan Tabel dan Blob service dan sumber data non-Azure Storage lainnya seperti database atau sistem file.
Pola dan panduan terkait
Pola dan panduan berikut mungkin juga relevan saat menerapkan pola ini:
- Transaksi Grup Entitas
- Menggabungkan atau mengganti
Catatan
Jika isolasi transaksi penting untuk solusi Anda, Anda harus mempertimbangkan untuk mendesain ulang tabel Anda untuk memungkinkan Anda menggunakan EGT.
Pola entitas indeks
Pertahankan entitas indeks untuk memungkinkan pencarian efisien yang mengembalikan daftar entitas.
Konteks dan masalah
Layanan Tabel secara otomatis mengindeks entitas menggunakan nilai PartitionKey dan RowKey. Ini memungkinkan aplikasi klien untuk mengambil entitas secara efisien menggunakan kueri titik. Misalnya, menggunakan struktur tabel yang ditunjukkan di bawah ini, aplikasi klien dapat secara efisien mengambil entitas karyawan individu dengan menggunakan nama departemen dan ID karyawan (PartitionKey dan RowKey).

Jika Anda juga ingin dapat mengambil daftar entitas karyawan berdasarkan nilai properti non-unik lainnya, seperti nama belakang mereka, Anda harus menggunakan pemindaian partisi yang kurang efisien untuk menemukan kecocokan daripada menggunakan indeks untuk mencarinya secara langsung. Ini karena layanan tabel tidak menyediakan indeks sekunder.
Solution
Untuk mengaktifkan pencarian berdasarkan nama belakang dengan struktur entitas yang ditunjukkan di atas, Anda harus mempertahankan daftar ID karyawan. Jika Anda ingin mengambil entitas karyawan dengan nama belakang tertentu, seperti Jones, Anda harus terlebih dahulu menemukan daftar ID karyawan untuk karyawan dengan Jones sebagai nama belakang mereka, dan kemudian ambil entitas karyawan tersebut. Ada tiga opsi utama untuk menyimpan daftar ID karyawan:
- Menggunakan penyimpanan blob.
- Membuat entitas indeks dalam partisi yang sama dengan entitas karyawan.
- Membuat entitas indeks dalam partisi atau tabel terpisah.
Opsi #1: Menggunakan penyimpanan blob
Untuk opsi pertama, Anda membuat blob untuk setiap nama belakang yang unik, dan di setiap blob menyimpan daftar nilai PartitionKey (departemen) dan RowKey (ID karyawan) untuk karyawan yang memiliki nama belakang tersebut. Ketika Anda menambahkan atau menghapus karyawan, Anda harus memastikan bahwa konten blob yang relevan konsisten pada akhirnya dengan entitas karyawan.
Opsi #2: Membuat entitas indeks dalam partisi yang sama
Untuk opsi kedua, gunakan entitas indeks yang menyimpan data berikut:
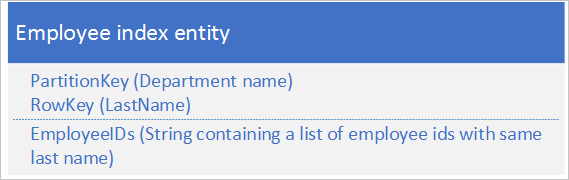
Properti EmployeeID berisi daftar ID karyawan untuk karyawan dengan nama belakang yang disimpan di RowKey.
Langkah-langkah berikut menguraikan proses yang harus Anda ikuti saat menambahkan karyawan baru jika Anda menggunakan opsi kedua. Dalam contoh ini, kami menambahkan karyawan dengan ID 000152 dan nama belakang Jones di departemen Penjualan:
- Ambil entitas indeks dengan nilai PartitionKey "Penjualan" dan nilai RowKey "Jones." Simpan ETag entitas ini untuk digunakan di langkah 2.
- Buat transaksi grup entitas (yaitu, operasi batch) yang menyisipkan entitas karyawan baru (nilai PartitionKey "Penjualan" dan nilai RowKey "000152"), dan memperbarui entitas indeks (nilai PartitionKey "Penjualan" dan nilai RowKey "Jones") dengan menambahkan ID karyawan baru ke daftar di bidang EmployeeID. Untuk informasi selengkapnya tentang transaksi grup entitas, lihat Transaksi Grup Entitas.
- Jika transaksi grup entitas gagal karena kesalahan konkurensi optimis (orang lain baru saja memodifikasi entitas indeks), maka Anda perlu memulai lagi dari langkah 1.
Anda dapat menggunakan pendekatan serupa untuk menghapus karyawan jika Anda menggunakan opsi kedua. Mengubah nama belakang karyawan sedikit lebih kompleks karena Anda harus menjalankan transaksi grup entitas yang memperbarui tiga entitas: entitas karyawan, entitas indeks untuk nama belakang lama, dan entitas indeks untuk nama belakang baru. Anda harus mengambil setiap entitas sebelum membuat perubahan apa pun untuk mengambil nilai ETag yang kemudian dapat Anda gunakan untuk melakukan pembaruan menggunakan konkurensi optimis.
Langkah-langkah berikut menguraikan proses yang harus Anda ikuti ketika Anda perlu mencari semua karyawan dengan nama belakang tertentu di sebuah departemen jika Anda menggunakan opsi kedua. Dalam contoh ini, kami mencari semua karyawan dengan nama belakang Jones di departemen Penjualan:
- Ambil entitas indeks dengan nilai PartitionKey "Penjualan" dan nilai RowKey "Jones."
- Mengurai daftar Id karyawan di bidang EmployeeID.
- Jika Anda memerlukan informasi tambahan tentang masing-masing karyawan ini (seperti alamat email mereka), ambil masing-masing entitas karyawan menggunakan nilai PartitionKey "Penjualan" dan nilai RowKey dari daftar karyawan yang Anda peroleh di langkah 2.
Opsi #3: Membuat entitas indeks dalam partisi atau tabel terpisah
Untuk opsi ketiga, gunakan entitas indeks yang menyimpan data berikut:

Properti EmployeeDetails berisi daftar ID karyawan dan nama departemen untuk karyawan dengan nama belakang yang disimpan di RowKey.
Dengan opsi ketiga, Anda tidak dapat menggunakan EGT untuk menjaga konsistensi karena entitas indeks berada di partisi terpisah dari entitas karyawan. Pastikan bahwa entitas indeks konsisten pada akhirnya dengan entitas karyawan.
Masalah dan pertimbangan
Pertimbangkan poin-poin berikut saat memutuskan cara menerapkan pola ini:
- Solusi ini memerlukan setidaknya dua kueri untuk mengambil entitas yang cocok: satu untuk meminta entitas indeks untuk mendapatkan daftar nilai RowKey, lalu kueri untuk mengambil setiap entitas dalam daftar.
- Mengingat bahwa entitas individu memiliki ukuran maksimum 1 MB, opsi #2 dan opsi #3 dalam solusi mengasumsikan bahwa daftar ID karyawan untuk nama belakang yang diberikan tidak pernah lebih besar dari 1 MB. Jika ukuran daftar ID karyawan cenderung lebih besar dari 1 MB, gunakan opsi #1 dan simpan data indeks dalam penyimpanan blob.
- Jika Anda menggunakan opsi #2 (menggunakan EGT untuk menangani penambahan dan penghapusan karyawan, dan mengubah nama belakang karyawan) Anda harus mengevaluasi apakah volume transaksi akan mendekati batas skalabilitas dalam partisi tertentu. Jika demikian, Anda harus mempertimbangkan solusi yang konsisten pada akhirnya (opsi #1 atau opsi #3) yang menggunakan antrean untuk menangani permintaan pembaruan dan memungkinkan Anda untuk menyimpan entitas indeks Anda di partisi terpisah dari entitas karyawan.
- Opsi #2 dalam solusi ini mengasumsikan bahwa Anda ingin mencari nama belakang dalam suatu departemen: misalnya, Anda ingin mengambil daftar karyawan dengan nama belakang Jones di departemen Penjualan. Jika Anda ingin dapat mencari semua karyawan dengan nama belakang Jones di seluruh organisasi, gunakan opsi #1 atau opsi #3.
- Anda dapat menerapkan solusi berbasis antrean yang memberikan konsistensi akhir (lihat Pola transaksi yang konsisten pada akhirnya untuk detail selengkapnya).
Kapan menggunakan pola ini
Gunakan pola ini saat Anda ingin mencari sekumpulan entitas yang semuanya memiliki nilai properti umum, seperti semua karyawan dengan nama belakang Jones.
Pola dan panduan terkait
Pola dan panduan berikut mungkin juga relevan saat menerapkan pola ini:
- Pola kunci gabungan
- Pola transaksi yang konsisten pada akhirnya
- Transaksi Grup Entitas
- Bekerja dengan jenis entitas heterogen
Pola denormalisasi
Gabungkan data terkait bersama dalam satu entitas untuk memungkinkan Anda mengambil semua data yang dibutuhkan dengan kueri satu titik.
Konteks dan masalah
Dalam database relasional, Anda biasanya menormalkan data untuk menghapus duplikasi yang menghasilkan kueri yang mengambil data dari beberapa tabel. Jika Anda menormalkan data Anda di tabel Azure, Anda harus melakukan beberapa perjalanan pulang pergi dari klien ke server untuk mengambil data terkait Anda. Misalnya, dengan struktur tabel yang diperlihatkan di bawah, Anda memerlukan dua perjalanan pulang pergi untuk mengambil detail untuk sebuah departemen: satu untuk mengambil entitas departemen yang menyertakan ID manajer, dan kemudian permintaan lainnya untuk mengambil detail manajer di entitas karyawan.

Solution
Alih-alih menyimpan data dalam dua entitas terpisah, lakukan denormalisasi data dan simpan salinan detail manajer di entitas departemen. Misalnya:
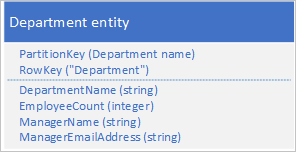
Dengan entitas departemen yang disimpan dengan properti ini, Anda sekarang dapat mengambil semua detail yang Anda butuhkan tentang departemen menggunakan kueri titik.
Masalah dan pertimbangan
Pertimbangkan poin-poin berikut saat memutuskan cara menerapkan pola ini:
- Ada beberapa biaya overhead yang terkait dengan menyimpan beberapa data dua kali. Manfaat kinerja (yang dihasilkan dari lebih sedikit permintaan ke layanan penyimpanan) biasanya melebihi kenaikan marjinal dalam biaya penyimpanan (dan biaya ini sebagian diimbangi dengan pengurangan jumlah transaksi yang Anda perlukan untuk mengambil rincian departemen).
- Anda harus menjaga konsistensi dari dua entitas yang menyimpan informasi tentang manajer. Anda dapat menangani masalah konsistensi dengan menggunakan EGT untuk memperbarui beberapa entitas dalam satu transaksi atom: dalam kasus ini, entitas departemen, dan entitas karyawan untuk manajer departemen disimpan di partisi yang sama.
Kapan menggunakan pola ini
Gunakan pola ini jika Anda sering mencari informasi terkait. Pola ini mengurangi jumlah kueri yang harus dibuat klien Anda untuk mengambil data yang diperlukan.
Pola dan panduan terkait
Pola dan panduan berikut mungkin juga relevan saat menerapkan pola ini:
- Pola kunci gabungan
- Transaksi Grup Entitas
- Bekerja dengan jenis entitas heterogen
Pola kunci gabungan
Gunakan nilai RowKey gabungan untuk memungkinkan klien mencari data terkait dengan satu kueri titik.
Konteks dan masalah
Dalam database relasional, wajar untuk menggunakan penggabungan dalam kueri untuk mengembalikan bagian data terkait ke klien dalam satu kueri. Misalnya, Anda dapat menggunakan ID karyawan untuk mencari daftar entitas terkait yang berisi performa dan meninjau data karyawan tersebut.
Misalnya Anda menyimpan entitas karyawan di layanan Tabel menggunakan struktur berikut:
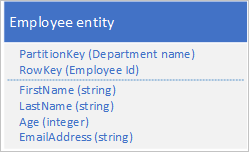
Anda juga perlu menyimpan data historis yang berkaitan dengan tinjauan dan kinerja untuk setiap tahun karyawan telah bekerja untuk organisasi Anda dan Anda harus dapat mengakses informasi ini berdasarkan tahun. Salah satu opsinya adalah membuat tabel lain yang menyimpan entitas dengan struktur berikut:
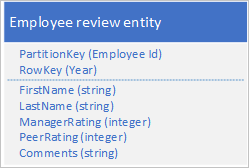
Perhatikan bahwa dengan pendekatan ini Anda dapat memutuskan untuk menduplikasi beberapa informasi (seperti nama depan dan nama belakang) di entitas baru untuk memungkinkan Anda mengambil data Anda dengan satu permintaan. Namun, Anda tidak dapat menjaga konsistensi yang kuat karena Anda tidak dapat menggunakan EGT untuk memperbarui dua entitas secara atomik.
Solution
Simpan jenis entitas baru di tabel asli Anda menggunakan entitas dengan struktur berikut:
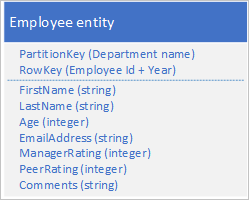
Perhatikan bagaimana RowKey sekarang menjadi kunci gabungan yang terdiri dari ID karyawan dan tahun data tinjauan yang memungkinkan Anda untuk mendapatkan kembali kinerja karyawan dan meninjau data dengan satu permintaan untuk satu entitas.
Contoh berikut menguraikan bagaimana Anda bisa mengambil semua data tinjauan untuk karyawan tertentu (seperti karyawan 000123 di departemen Penjualan):
$filter=(PartitionKey eq 'Penjualan') dan (RowKey ge 'empid_000123') dan (RowKey lt '000123_2012')&$select=RowKey,Peringkat Manajer, Peringkat Rekan, Komentar
Masalah dan pertimbangan
Pertimbangkan poin-poin berikut saat memutuskan cara menerapkan pola ini:
- Anda harus menggunakan karakter pemisah yang cocok yang memudahkan untuk mengurai nilai RowKey: misalnya, 000123_2012.
- Anda juga menyimpan entitas ini di partisi yang sama dengan entitas lain yang berisi data terkait untuk karyawan yang sama, yang berarti Anda dapat menggunakan EGT untuk menjaga konsistensi yang kuat.
- Anda harus mempertimbangkan seberapa sering Anda akan mengkueri data untuk menentukan apakah pola ini sesuai. Misalnya, jika Anda jarang mengakses data tinjauan dan sering mengakses data karyawan utama, Anda harus menyimpannya sebagai entitas terpisah.
Kapan menggunakan pola ini
Gunakan pola ini saat Anda perlu menyimpan satu atau beberapa entitas terkait yang sering Anda kueri.
Pola dan panduan terkait
Pola dan panduan berikut mungkin juga relevan saat menerapkan pola ini:
- Transaksi Grup Entitas
- Bekerja dengan jenis entitas heterogen
- Pola transaksi yang konsisten pada akhirnya
Pola log tail
Ambil entitas n yang terakhir ditambahkan ke partisi dengan menggunakan nilai RowKey yang mengurutkan dalam urutan tanggal dan waktu terbalik.
Konteks dan masalah
Persyaratan umum dapat mengambil entitas yang baru dibuat, misalnya 10 klaim pengeluaran terbaru yang diajukan oleh karyawan. Kueri tabel mendukung operasi kueri $top untuk mengembalikan entitas n pertama dari satu set: tidak ada operasi kueri yang setara untuk mengembalikan entitas n terakhir dalam satu set.
Solution
Simpan entitas menggunakan RowKey yang secara alami mengurutkan dalam urutan tanggal/waktu terbalik dengan menggunakan entri terbaru selalu yang pertama dalam tabel.
Misalnya, untuk dapat memperoleh kembali 10 klaim pengeluaran terbaru yang diajukan oleh seorang karyawan, Anda dapat menggunakan nilai centang terbalik yang diperoleh dari tanggal/waktu saat ini. Contoh kode C# berikut ini menunjukkan salah satu cara untuk membuat nilai "centang terbalik" yang sesuai untuk RowKey yang mengurutkan dari yang terbaru hingga yang terlama:
string invertedTicks = string.Format("{0:D19}", DateTime.MaxValue.Ticks - DateTime.UtcNow.Ticks);
Anda bisa kembali ke nilai tanggal waktu menggunakan kode berikut:
DateTime dt = new DateTime(DateTime.MaxValue.Ticks - Int64.Parse(invertedTicks));
Kueri tabel terlihat seperti ini:
https://myaccount.table.core.windows.net/EmployeeExpense(PartitionKey='empid')?$top=10
Masalah dan pertimbangan
Pertimbangkan poin-poin berikut saat memutuskan cara menerapkan pola ini:
- Anda harus mengisi nilai centang terbalik dengan angka nol di depannya untuk memastikan nilai string diurutkan seperti yang diharapkan.
- Anda harus menyadari target skalabilitas pada tingkat partisi. Hati-hati jangan membuat partisi hot spot.
Kapan menggunakan pola ini
Gunakan pola ini saat Anda perlu mengakses entitas dalam urutan tanggal/waktu terbalik atau ketika Anda perlu mengakses entitas yang terakhir ditambahkan.
Pola dan panduan terkait
Pola dan panduan berikut mungkin juga relevan saat menerapkan pola ini:
Pola penghapusan volume tinggi
Aktifkan penghapusan entitas volume tinggi dengan menyimpan semua entitas untuk penghapusan simultan di tabel terpisah mereka sendiri; Anda menghapus entitas dengan menghapus tabel.
Konteks dan masalah
Banyak aplikasi menghapus data lama yang tidak lagi perlu tersedia untuk aplikasi klien, atau aplikasi tersebut telah diarsipkan ke media penyimpanan lain. Anda biasanya mengidentifikasi data tersebut berdasarkan tanggal: misalnya, Anda memiliki persyaratan untuk menghapus data dari semua permintaan masuk yang lebih dari 60 hari.
Salah satu desain yang mungkin adalah menggunakan tanggal dan waktu permintaan masuk di RowKey:
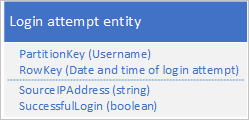
Pendekatan ini menghindari hotspot partisi karena aplikasi dapat memasukkan dan menghapus entitas masuk untuk setiap pengguna di partisi terpisah. Namun, pendekatan ini mungkin mahal dan memakan waktu jika Anda memiliki banyak entitas karena pertama-tama Anda perlu melakukan pemindaian tabel untuk mengidentifikasi semua entitas yang akan dihapus, dan kemudian Anda harus menghapus setiap entitas lama. Anda dapat mengurangi jumlah perjalanan pulang pergi ke server yang perlu diperlukan untuk menghapus entitas lama dengan menggabungkan beberapa permintaan hapus ke dalam EGT.
Solution
Gunakan tabel terpisah untuk setiap hari upaya masuk. Anda dapat menggunakan desain entitas di atas untuk menghindari hotspot saat Anda memasukkan entitas, dan menghapus entitas lama sekarang hanyalah masalah menghapus satu tabel setiap hari (satu operasi penyimpanan) daripada mencari dan menghapus ratusan dan ribuan entitas masuk individual setiap hari.
Masalah dan pertimbangan
Pertimbangkan poin-poin berikut saat memutuskan cara menerapkan pola ini:
- Apakah desain Anda mendukung cara lain aplikasi Anda akan menggunakan data seperti mencari entitas tertentu, menghubungkan dengan data lain, atau menghasilkan informasi agregat?
- Apakah desain Anda menghindari hot spot ketika Anda memasukkan entitas baru?
- Perkirakan penundaan jika Anda ingin menggunakan kembali nama tabel yang sama setelah menghapusnya. Lebih baik selalu menggunakan nama tabel yang unik.
- Harapkan beberapa pembatasan saat Anda pertama kali menggunakan tabel baru saat layanan Tabel mempelajari pola akses dan mendistribusikan partisi ke seluruh node. Anda harus mempertimbangkan seberapa sering Anda perlu membuat tabel baru.
Kapan menggunakan pola ini
Gunakan pola ini ketika Anda memiliki entitas volume tinggi yang harus dihapus secara bersamaan.
Pola dan panduan terkait
Pola dan panduan berikut mungkin juga relevan saat menerapkan pola ini:
- Transaksi Grup Entitas
- Memodifikasi entitas
Pola seri data
Simpan seri data lengkap dalam satu entitas untuk meminimalkan jumlah permintaan yang Anda buat.
Konteks dan masalah
Skenario umum diperuntukan untuk aplikasi menyimpan serangkaian data yang biasanya perlu diambil sekaligus. Misalnya, aplikasi Anda mungkin merekam berapa banyak pesan IM yang dikirim setiap karyawan setiap jam, lalu menggunakan informasi ini untuk mem-plot berapa banyak pesan yang dikirim setiap pengguna selama 24 jam sebelumnya. Satu desain mungkin untuk menyimpan 24 entitas untuk setiap karyawan:
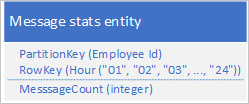
Dengan desain ini, Anda dapat dengan mudah mencari dan memperbarui entitas yang akan diperbarui untuk setiap karyawan kapan pun aplikasi perlu memperbarui nilai jumlah pesan. Namun, saat mengambil informasi untuk mem-plot bagan aktivitas selama 24 jam sebelumnya, Anda harus mengambil 24 entitas.
Solution
Gunakan desain berikut dengan properti terpisah untuk menyimpan jumlah pesan setiap jam:
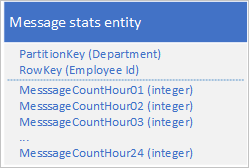
Dengan desain ini, Anda bisa menggunakan operasi penggabungan untuk memperbarui jumlah pesan seorang karyawan untuk jam tertentu. Sekarang, Anda dapat mengambil semua informasi yang Anda butuhkan untuk memplot bagan menggunakan permintaan untuk satu entitas.
Masalah dan pertimbangan
Pertimbangkan poin-poin berikut saat memutuskan cara menerapkan pola ini:
- Jika rangkaian data lengkap Anda tidak cocok dengan satu entitas (entitas dapat memiliki hingga 252 properti), gunakan penyimpanan data alternatif seperti blob.
- Jika Anda memiliki beberapa klien yang memperbarui entitas secara bersamaan, Anda harus menggunakan ETag untuk menerapkan konkurensi optimis. Jika Anda memiliki banyak klien, Anda mungkin mengalami konflik yang tinggi.
Kapan menggunakan pola ini
Gunakan pola ini saat Anda perlu memperbarui dan mengambil seri data yang terkait dengan entitas individu.
Pola dan panduan terkait
Pola dan panduan berikut mungkin juga relevan saat menerapkan pola ini:
- Pola entitas besar
- Menggabungkan atau mengganti
- Pola transaksi yang konsisten pada akhirnya (jika Anda menyimpan seri data dalam blob)
Pola entitas lebar
Gunakan beberapa entitas fisik untuk menyimpan entitas logis dengan lebih dari 252 properti.
Konteks dan masalah
Entitas individu tidak dapat memiliki lebih dari 252 properti (tidak termasuk properti sistem wajib) dan tidak dapat menyimpan lebih dari 1 MB data secara total. Dalam database relasional, Anda biasanya akan mengatasi batasan apa pun pada ukuran baris dengan menambahkan tabel baru dan menerapkan hubungan 1-ke-1 di antara mereka.
Solution
Dengan menggunakan layanan Tabel, Anda dapat menyimpan beberapa entitas untuk mewakili satu objek bisnis besar dengan lebih dari 252 properti. Misalnya, jika Anda ingin menyimpan hitungan jumlah pesan IM yang dikirim oleh setiap karyawan selama 365 hari terakhir, Anda bisa menggunakan desain berikut ini yang menggunakan dua entitas dengan skema berbeda:
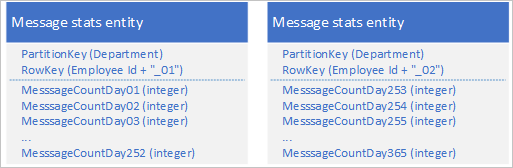
Jika Anda perlu membuat perubahan yang mengharuskan memperbarui kedua entitas agar tetap sinkron satu sama lain, Anda dapat menggunakan EGT. Jika tidak, Anda dapat menggunakan operasi penggabungan tunggal untuk memperbarui jumlah pesan hari tertentu. Untuk mengambil semua data untuk karyawan individual, Anda harus mengambil kedua entitas, yang dapat Anda lakukan dengan dua permintaan efisien yang menggunakan nilai PartitionKey dan RowKey.
Masalah dan pertimbangan
Pertimbangkan poin-poin berikut saat memutuskan cara menerapkan pola ini:
- Mengambil entitas logis lengkap melibatkan setidaknya dua transaksi penyimpanan: satu untuk mengambil setiap entitas fisik.
Kapan menggunakan pola ini
Gunakan pola ini saat perlu menyimpan entitas yang ukuran atau jumlah propertinya melebihi batas untuk entitas individu dalam layanan Tabel.
Pola dan panduan terkait
Pola dan panduan berikut mungkin juga relevan saat menerapkan pola ini:
- Transaksi Grup Entitas
- Menggabungkan atau mengganti
Pola entitas besar
Gunakan penyimpanan blob untuk menyimpan nilai properti besar.
Konteks dan masalah
Entitas individu tidak dapat menyimpan lebih dari 1 MB data secara total. Jika satu atau beberapa properti Anda menyimpan nilai yang menyebabkan ukuran total entitas Anda melebihi nilai ini, Anda tidak dapat menyimpan seluruh entitas dalam layanan Tabel.
Solution
Jika entitas Anda melebihi ukuran 1 MB karena satu atau beberapa properti berisi sejumlah besar data, Anda dapat menyimpan data di Blob service dan kemudian menyimpan alamat blob dalam properti dalam entitas. Misalnya, Anda dapat menyimpan foto karyawan di penyimpanan blob dan menyimpan tautan ke foto di properti Foto entitas karyawan Anda:
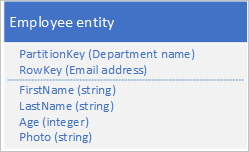
Masalah dan pertimbangan
Pertimbangkan poin-poin berikut saat memutuskan cara menerapkan pola ini:
- Untuk mempertahankan konsistensi akhir antara entitas dalam layanan Tabel dan data dalam Blob service, gunakan Pola transaksi yang konsisten pada akhirnya untuk mempertahankan entitas Anda.
- Mengambil entitas lengkap melibatkan setidaknya dua transaksi penyimpanan: satu untuk mengambil entitas dan satu untuk mengambil data blob.
Kapan menggunakan pola ini
Gunakan pola ini saat Anda perlu menyimpan entitas yang ukurannya melebihi batas untuk entitas individu di layanan Tabel.
Pola dan panduan terkait
Pola dan panduan berikut mungkin juga relevan saat menerapkan pola ini:
Prepend/append anti-pola
Tingkatkan skalabilitas saat Anda memiliki volume sisipan yang tinggi dengan menyebarkan sisipan di beberapa partisi.
Konteks dan masalah
Menambahkan di awal entitas atau menambahkan di akhir entitas ke entitas yang tersimpan biasanya menghasilkan aplikasi yang menambahkan entitas baru ke partisi pertama atau terakhir dari urutan partisi. Dalam kasus ini, semua penyisipan pada waktu tertentu berlangsung di partisi yang sama, membuat hotspot yang mencegah layanan tabel dari penyisipan load-balancing di beberapa node, dan mungkin menyebabkan aplikasi Anda mencapai target skalabilitas untuk partisi. Misalnya, jika Anda memiliki aplikasi yang mencatat akses jaringan dan sumber daya oleh karyawan, maka struktur entitas seperti yang ditunjukkan di bawah ini dapat mengakibatkan partisi jam saat ini menjadi hotspot jika volume transaksi mencapai target skalabilitas untuk masing-masing partisi:

Solution
Struktur entitas alternatif berikut menghindari hotspot di partisi tertentu saat aplikasi mencatat aktivitas:
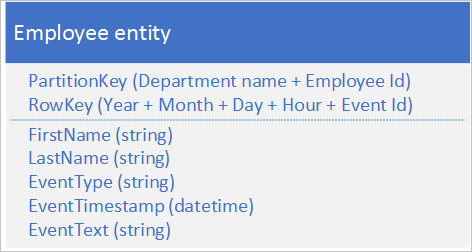
Perhatikan dengan contoh ini bagaimana PartitionKey dan RowKey adalah kunci gabungan. PartitionKey menggunakan ID departemen dan ID karyawan untuk mendistribusikan pencatatan di beberapa partisi.
Masalah dan pertimbangan
Pertimbangkan poin-poin berikut saat memutuskan cara menerapkan pola ini:
- Apakah struktur kunci alternatif yang menghindari pembuatan partisi panas pada sisipan secara efisien mendukung kueri yang dibuat oleh aplikasi klien Anda?
- Apakah volume transaksi yang Anda antisipasi berarti Anda cenderung mencapai target skalabilitas untuk masing-masing partisi dan dibatasi oleh layanan penyimpanan?
Kapan menggunakan pola ini
Hindari menambahkan di awal/menambahkan di akhir anti-pola ketika volume transaksi Anda cenderung mengakibatkan pembatasan oleh layanan penyimpanan saat Anda mengakses partisi panas.
Pola dan panduan terkait
Pola dan panduan berikut mungkin juga relevan saat menerapkan pola ini:
Log data anti-pola
Biasanya, Anda harus menggunakan Blob service daripada layanan Tabel untuk menyimpan data log.
Konteks dan masalah
Kasus penggunaan umum untuk data log adalah mengambil pilihan entri log untuk rentang tanggal/waktu tertentu: misalnya, Anda ingin menemukan semua kesalahan dan pesan penting yang dicatat oleh aplikasi Anda antara pukul 15:04 dan 15:06 pada tanggal yang spesifik. Anda tidak ingin menggunakan tanggal dan waktu pesan log untuk menentukan partisi tempat Anda menyimpan entitas log: yang menghasilkan partisi panas karena pada waktu tertentu, semua entitas log akan berbagi nilai PartitionKey yang sama (lihat bagian menambahkan di awal/menambahkan di akhir anti-pola). Misalnya, skema entitas berikut untuk pesan log menghasilkan partisi panas karena aplikasi menulis semua pesan log ke partisi untuk tanggal dan jam saat ini:
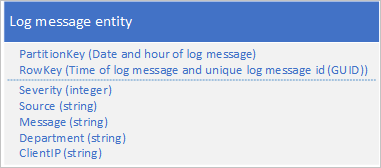
Dalam contoh ini, RowKey menyertakan tanggal dan waktu pesan log untuk memastikan bahwa pesan log disimpan dengan urutan tanggal/waktu, dan menyertakan ID pesan jika beberapa pesan log memiliki tanggal dan waktu yang sama.
Pendekatan lain adalah menggunakan PartitionKey yang memastikan bahwa aplikasi menulis pesan di berbagai partisi. Misalnya, jika sumber pesan log menyediakan cara untuk mendistribusikan pesan ke banyak partisi, Anda dapat menggunakan skema entitas berikut:
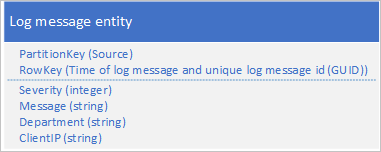
Namun, masalah dengan skema ini adalah, untuk mengambil semua pesan log untuk rentang waktu tertentu Anda harus mencari setiap partisi dalam tabel.
Solution
Bagian sebelumnya menyoroti masalah mencoba menggunakan layanan Tabel untuk menyimpan entri log dan menyarankan dua desain yang tidak memuaskan. Salah satu solusi menyebabkan partisi panas dengan risiko kinerja yang buruk menulis pesan log; solusi lain menghasilkan kinerja kueri yang buruk karena persyaratan untuk memindai setiap partisi dalam tabel untuk mengambil pesan log untuk rentang waktu tertentu. Penyimpanan blob menawarkan solusi yang lebih baik untuk jenis skenario ini dan inilah cara Azure Storage Analytics menyimpan data log yang dikumpulkannya.
Bagian ini menjelaskan bagaimana Storage Analytics menyimpan data log di penyimpanan blob sebagai ilustrasi dari pendekatan ini untuk menyimpan data yang biasanya Anda kueri berdasarkan rentang.
Storage Analytics menyimpan pesan log dalam format yang dibatasi dalam beberapa blob. Format yang dibatasi memudahkan aplikasi klien untuk mengurai data dalam pesan log.
Storage Analytics menggunakan konvensi penamaan untuk blob yang memungkinkan Anda menemukan blob yang berisi pesan log yang Anda cari. Misalnya, blob bernama "antrean/2014/07/31/1800/000001.log" berisi pesan log yang berkaitan dengan layanan antrean untuk jam mulai pukul 18.00 pada 31 Juli 2014. "000001" menunjukkan bahwa ini adalah file log pertama untuk periode ini. Storage Analytics juga merekam stempel waktu pesan log pertama dan terakhir yang disimpan dalam file sebagai bagian dari metadata blob. API untuk penyimpanan blob memungkinkan Anda menemukan blob dalam kontainer berdasarkan awalan nama: untuk menemukan semua blob yang berisi data log antrean untuk jam mulai pukul 18:00, Anda dapat menggunakan awalan "antrean/2014/07/31/1800."
Buffer Storage Analytics mencatat pesan secara internal lalu secara berkala memperbarui blob yang sesuai atau membuat yang baru dengan kumpulan entri log terbaru. Ini mengurangi jumlah penulisan yang harus dilakukan ke layanan blob.
Jika Anda mengimplementasikan solusi serupa di aplikasi Anda sendiri, Anda harus mempertimbangkan cara mengelola trade-off antara keandalan (menulis setiap entri log ke penyimpanan blob saat terjadi) dan biaya dan skalabilitas (mem-buffer pembaruan dalam aplikasi Anda dan menuliskannya ke penyimpanan blob dalam batch).
Masalah dan pertimbangan
Pertimbangkan poin-poin berikut saat memutuskan cara menyimpan data log:
- Jika Anda membuat desain tabel yang menghindari partisi panas potensial, Anda mungkin menemukan bahwa Anda tidak dapat mengakses data log Anda secara efisien.
- Untuk memproses data log, klien sering kali perlu memuat banyak data.
- Meskipun data log sering kali terstruktur, penyimpanan blob mungkin merupakan solusi yang lebih baik.
Pertimbangan implementasi
Bagian ini membahas beberapa pertimbangan yang perlu diperhatikan saat Anda menerapkan pola yang dijelaskan di bagian sebelumnya. Sebagian besar bagian ini menggunakan contoh yang ditulis dalam C# yang menggunakan pustaka klien Storage (versi 4.3.0 pada saat penulisan).
Mengambil entitas
Seperti yang dibahas di bagian Desain untuk mengkueri, kueri yang paling efisien adalah kueri titik. Namun, dalam beberapa skenario Anda mungkin perlu mengambil beberapa entitas. Bagian ini menjelaskan beberapa pendekatan umum untuk mengambil entitas menggunakan pustaka klien Storage.
Menjalankan kueri titik menggunakan pustaka klien Storage
Cara termudah untuk menjalankan kueri titik adalah dengan menggunakan metode GetEntityAsync seperti yang ditunjukkan dalam cuplikan kode C# berikut yang mengambil entitas PartitionKey dengan nilai "Penjualan" dan RowKey dengan nilai "212":
EmployeeEntity employee = await employeeTable.GetEntityAsync<EmployeeEntity>("Sales", "212");
Perhatikan bagaimana contoh ini mengharapkan entitas yang diambilnya menjadi jenis EmployeeEntity.
Mengambil beberapa entitas menggunakan LINQ
Anda dapat menggunakan LINQ untuk mengambil beberapa entitas dari layanan Tabel saat bekerja dengan Pustaka Standar Tabel Microsoft Azure Cosmos DB.
dotnet add package Azure.Data.Tables
Untuk membuat contoh di bawah ini berfungsi, Anda harus menyertakan namespace:
using System.Linq;
using Azure.Data.Tables
Mengambil beberapa entitas dapat dicapai dengan menentukan kueri dengan klausa filter . Untuk menghindari pemindaian tabel, Anda harus selalu menyertakan nilai PartitionKey di klausa filter, dan jika memungkinkan nilai RowKey untuk menghindari pemindaian tabel dan partisi. Layanan tabel mendukung sekumpulan operator pembanding yang terbatas (lebih besar dari, lebih besar dari atau sama dengan, kurang dari, kurang dari atau sama dengan, sama dengan, dan tidak sama dengan) untuk digunakan dalam klausa filter.
Dalam contoh berikut, employeeTable adalah objek TableClient . Contoh ini menemukan semua karyawan yang nama belakangnya dimulai dengan "B" (dengan asumsi bahwa RowKey menyimpan nama belakang) di departemen penjualan (dengan asumsi PartitionKey menyimpan nama departemen):
var employees = employeeTable.Query<EmployeeEntity>(e => (e.PartitionKey == "Sales" && e.RowKey.CompareTo("B") >= 0 && e.RowKey.CompareTo("C") < 0));
Perhatikan bagaimana kueri menentukan RowKey dan PartitionKey untuk memastikan kinerja yang lebih baik.
Contoh kode berikut menunjukkan fungsionalitas yang setara tanpa menggunakan sintaks LINQ:
var employees = employeeTable.Query<EmployeeEntity>(filter: $"PartitionKey eq 'Sales' and RowKey ge 'B' and RowKey lt 'C'");
Catatan
Metode Kueri sampel menyertakan tiga kondisi filter.
Mengambil sejumlah besar entitas dari kueri
Kueri yang optimal mengembalikan entitas individu berdasarkan nilai PartitionKey dan nilai RowKey. Namun, dalam beberapa skenario Anda mungkin memiliki persyaratan untuk mengembalikan banyak entitas dari partisi yang sama atau bahkan dari banyak partisi.
Anda harus selalu sepenuhnya menguji kinerja aplikasi Anda dalam skenario seperti itu.
Kueri terhadap layanan tabel dapat mengembalikan maksimal 1.000 entitas pada satu waktu dan dapat dieksekusi selama maksimal lima detik. Jika kumpulan hasil berisi lebih dari 1.000 entitas, jika kueri tidak selesai dalam lima detik, atau jika kueri melewati batas partisi, layanan Tabel mengembalikan token kelanjutan untuk memungkinkan aplikasi klien meminta kumpulan entitas berikutnya. Untuk informasi selengkapnya tentang cara kerja token kelanjutan, lihat Waktu Habis Kueri dan Paginasi.
Jika Anda menggunakan pustaka klien Azure Tables, pustaka klien dapat secara otomatis menangani token kelanjutan untuk Anda karena mengembalikan entitas dari layanan Tabel. Sampel kode C# berikut menggunakan pustaka klien secara otomatis menangani token kelanjutan jika layanan tabel mengembalikannya dalam respons:
var employees = employeeTable.Query<EmployeeEntity>("PartitionKey eq 'Sales'")
foreach (var emp in employees)
{
// ...
}
Anda juga dapat menentukan jumlah maksimum entitas yang dikembalikan per halaman. Contoh berikut menunjukkan cara mengkueri entitas dengan maxPerPage:
var employees = employeeTable.Query<EmployeeEntity>(maxPerPage: 10);
// Iterate the Pageable object by page
foreach (var page in employees.AsPages())
{
// Iterate the entities returned for this page
foreach (var emp in page.Values)
{
// ...
}
}
Dalam skenario yang lebih canggih, Anda mungkin ingin menyimpan token kelanjutan yang dikembalikan dari layanan sehingga kode Anda mengontrol persis ketika halaman berikutnya diambil. Contoh berikut menunjukkan skenario dasar tentang bagaimana token dapat diambil dan diterapkan ke hasil paginasi:
string continuationToken = null;
bool moreResultsAvailable = true;
while (moreResultsAvailable)
{
var page = employeeTable
.Query<EmployeeEntity>()
.AsPages(continuationToken, pageSizeHint: 10)
.FirstOrDefault(); // pageSizeHint limits the number of results in a single page, so we only enumerate the first page
if (page == null)
break;
// Get the continuation token from the page
// Note: This value can be stored so that the next page query can be executed later
continuationToken = page.ContinuationToken;
var pageResults = page.Values;
moreResultsAvailable = pageResults.Any() && continuationToken != null;
// Iterate the results for this page
foreach (var result in pageResults)
{
// ...
}
}
Dengan menggunakan token kelanjutan secara eksplisit, Anda dapat mengontrol kapan aplikasi Anda mengambil segmen data berikutnya. Misalnya, jika aplikasi klien Anda memungkinkan pengguna untuk membuka halaman melalui entitas yang disimpan dalam tabel, pengguna dapat memutuskan untuk tidak melalui halaman melalui semua entitas yang diambil oleh kueri sehingga aplikasi Anda hanya akan menggunakan token kelanjutan untuk mengambil segmen berikutnya ketika pengguna telah menyelesaikan paging melalui semua entitas di segmen saat ini. Pendekatan ini memiliki beberapa manfaat:
- Ini memungkinkan Anda untuk membatasi jumlah data untuk diambil dari layanan Tabel dan bahwa Anda bergerak melalui jaringan.
- Ini memungkinkan Anda untuk melakukan IO asinkron di .NET.
- Ini memungkinkan Anda untuk membuat serial token kelanjutan ke penyimpanan persisten sehingga Anda dapat melanjutkan jika terjadi crash aplikasi.
Catatan
Token kelanjutan biasanya mengembalikan segmen yang berisi 1.000 entitas, meskipun mungkin lebih sedikit. Ini juga terjadi jika Anda membatasi jumlah entri yang dikembalikan kueri dengan menggunakan Take untuk mengembalikan n entitas pertama yang cocok dengan kriteria pencarian Anda: layanan tabel dapat mengembalikan segmen yang berisi kurang dari n entitas bersama dengan token kelanjutan untuk memungkinkan Anda untuk mengambil entitas yang tersisa.
Proyeksi sisi server
Satu entitas dapat berisi hingga 255 properti dan berukuran hingga 1 MB. Saat Anda membuat kueri tabel dan mengambil entitas, Anda mungkin tidak memerlukan semua properti dan dapat menghindari transfer data yang tidak perlu (untuk membantu mengurangi latensi dan biaya). Anda dapat menggunakan proyeksi sisi server untuk mentransfer hanya properti yang Anda butuhkan. Contoh berikut ini hanya mengambil properti Email (bersama dengan PartitionKey, RowKey, Stempel waktu, dan ETag) dari entitas yang dipilih oleh kueri.
var subsetResults = query{
for employee in employeeTable.Query<EmployeeEntity>("PartitionKey eq 'Sales'") do
select employee.Email
}
foreach (var e in subsetResults)
{
Console.WriteLine("RowKey: {0}, EmployeeEmail: {1}", e.RowKey, e.Email);
}
Perhatikan bagaimana nilai RowKey tersedia meskipun tidak disertakan dalam daftar properti untuk diambil.
Memodifikasi entitas
Pustaka klien Storage memungkinkan Anda memodifikasi entitas yang disimpan dalam layanan tabel dengan menyisipkan, menghapus, dan memperbarui entitas. Anda dapat menggunakan EGT untuk menggabungkan beberapa proses menyisipkan, memperbarui, dan menghapus operasi bersama-sama untuk mengurangi jumlah perjalanan pulang pergi yang diperlukan dan meningkatkan kinerja solusi Anda.
Pengecualian yang dilemparkan ketika pustaka klien Storage menjalankan EGT biasanya menyertakan indeks entitas yang menyebabkan batch gagal. Ini berguna ketika Anda men-debug kode yang menggunakan EGTs.
Anda juga harus mempertimbangkan bagaimana desain Anda memengaruhi cara aplikasi klien menangani operasi konkurensi dan pembaruan.
Mengelola konkurensi
Secara default, layanan tabel mengimplementasikan pemeriksaan konkurensi optimis pada tingkat entitas individu untuk operasi Insert, Merge, dan Delete, meskipun dimungkinkan bagi klien untuk memaksa layanan tabel untuk melewati pemeriksaan ini. Untuk informasi selengkapnya tentang cara layanan tabel mengelola konkurensi, lihat Mengelola Konkurensi di Microsoft Azure Storage.
Menggabungkan atau mengganti
Metode Replace dari kelas TableOperation selalu menggantikan entitas lengkap dalam layanan Tabel. Jika Anda tidak menyertakan properti dalam permintaan ketika properti itu ada di entitas yang disimpan, permintaan akan menghapus properti itu dari entitas yang disimpan. Kecuali Jika Anda ingin menghapus properti secara eksplisit dari entitas yang disimpan, Anda harus menyertakan setiap properti dalam permintaan.
Anda dapat menggunakan metode Merge dari kelas TableOperation untuk mengurangi jumlah data yang Anda kirim ke layanan Tabel saat Anda ingin memperbarui entitas. Metode Merge mengganti properti apa pun dalam entitas yang disimpan dengan nilai properti dari entitas yang termasuk dalam permintaan, tetapi membiarkan semua properti dalam entitas tersimpan yang tidak disertakan dalam permintaan tetap utuh. Ini berguna jika Anda memiliki entitas besar dan hanya perlu memperbarui sejumlah kecil properti dalam sebuah permintaan.
Catatan
Metode Replace dan Merge gagal jika entitas tidak ada. Sebagai alternatif, Anda dapat menggunakan metode InsertOrReplace dan InsertOrMerge yang membuat entitas baru jika entitas tidak ada.
Bekerja dengan jenis entitas heterogen
Layanan Tabel adalah penyimpanan tabel tanpa skema yang berarti bahwa satu tabel dapat menyimpan entitas dari berbagai jenis yang memberikan fleksibilitas tinggi dalam desain Anda. Contoh berikut mengilustrasikan tabel yang menyimpan entitas karyawan dan departemen:
| PartitionKey | RowKey | Tanda Waktu | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| |||||||||||
| |||||||||||
|
|||||||||||
|
Setiap entitas harus masih memiliki nilai PartitionKey, RowKey, dan Timestamp, tetapi mungkin memiliki sekumpulan properti. Selain itu, tidak ada yang menunjukkan jenis entitas kecuali Anda memilih untuk menyimpan informasi tersebut di suatu tempat. Ada dua opsi untuk mengidentifikasi jenis entitas:
- Menambahkan di awal tipe entitas ke RowKey (atau mungkin PartitionKey). Misalnya, EMPLOYEE_000123 atau DEPARTMENT_SALES sebagai nilai RowKey.
- Gunakan properti terpisah untuk mencatat jenis entitas seperti yang ditunjukkan pada tabel di bawah ini.
| PartitionKey | RowKey | Tanda Waktu | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| |||||||||||||
| |||||||||||||
|
|||||||||||||
|
Opsi pertama, menambahkan di awal tipe entitas ke RowKey, berguna jika ada kemungkinan bahwa dua entitas dari berbagai jenis mungkin memiliki nilai kunci yang sama. Ini juga mengelompokkan entitas dari jenis yang sama bersama-sama di partisi.
Teknik yang dibahas di bagian ini sangat relevan dengan diskusi Hubungan warisan sebelumnya dalam panduan ini dalam artikel Pemodelan hubungan.
Catatan
Anda harus mempertimbangkan untuk menyertakan nomor versi dalam nilai jenis entitas untuk memungkinkan aplikasi klien mengembangkan objek POCO dan bekerja dengan versi yang berbeda.
Sisa bagian ini menjelaskan beberapa fitur di pustaka klien Storage yang memfasilitasi bekerja dengan beberapa jenis entitas dalam tabel yang sama.
Mengambil jenis entitas heterogen
Jika Anda menggunakan pustaka klien Tabel, Anda memiliki tiga opsi untuk bekerja dengan beberapa jenis entitas.
Jika Anda mengetahui jenis entitas yang disimpan dengan nilai RowKey dan PartitionKey tertentu, maka Anda dapat menentukan jenis entitas saat Mengambil entitas seperti yang ditunjukkan dalam dua contoh sebelumnya yang mengambil entitas jenis EmployeeEntity: Menjalankan kueri titik menggunakan pustaka klien Storage dan Mengambil beberapa entitas menggunakan LINQ.
Opsi kedua adalah menggunakan jenis TableEntity (tas properti) daripada jenis entitas POCO konkret (opsi ini juga dapat meningkatkan kinerja karena tidak perlu melakukan serialisasi dan deserialisasi entitas ke jenis .NET). Kode C# berikut berpotensi mengambil beberapa entitas dari jenis yang berbeda dari tabel, tetapi mengembalikan semua entitas sebagai instans TableEntity. Kemudian menggunakan properti EntityType untuk menentukan jenis setiap entitas:
Pageable<TableEntity> entities = employeeTable.Query<TableEntity>(x =>
x.PartitionKey == "Sales" && x.RowKey.CompareTo("B") >= 0 && x.RowKey.CompareTo("F") <= 0)
foreach (var entity in entities)
{
if (entity.GetString("EntityType") == "Employee")
{
// use entityTypeProperty, RowKey, PartitionKey, Etag, and Timestamp
}
}
Untuk mengambil properti lain, Anda harus menggunakan metode GetString pada entitas kelas TableEntity.
Memodifikasi jenis entitas heterogen
Anda tidak perlu mengetahui jenis entitas untuk menghapusnya, dan Anda selalu mengetahui jenis entitas saat Anda menyisipkannya. Namun, Anda dapat menggunakan jenis TableEntity untuk memperbarui entitas tanpa mengetahui jenisnya dan tanpa menggunakan kelas entitas POCO. Contoh kode berikut mengambil satu entitas, dan memeriksa properti EmployeeCount ada sebelum memperbaruinya.
var result = employeeTable.GetEntity<TableEntity>(partitionKey, rowKey);
TableEntity department = result.Value;
if (department.GetInt32("EmployeeCount") == null)
{
throw new InvalidOperationException("Invalid entity, EmployeeCount property not found.");
}
employeeTable.UpdateEntity(department, ETag.All, TableUpdateMode.Merge);
Mengontrol akses dengan Shared Access Signature
Anda bisa menggunakan token Shared Access Signature (SAS) untuk memungkinkan aplikasi klien mengubah (dan mengkueri) entitas tabel tanpa perlu menyertakan kunci akun penyimpanan Anda dalam kode Anda. Biasanya, ada tiga manfaat utama menggunakan SAS dalam aplikasi Anda:
- Anda tidak perlu mendistribusikan kunci akun penyimpanan Anda ke platform yang tidak aman (seperti perangkat seluler) untuk mengizinkan perangkat tersebut mengakses dan memodifikasi entitas dalam layanan Tabel.
- Anda dapat membongkar beberapa pekerjaan yang dilakukan peran web dan pekerja dalam mengelola entitas Anda ke perangkat klien seperti komputer pengguna akhir dan perangkat seluler.
- Anda bisa menetapkan sekumpulan izin terbatas dan terbatas waktu ke klien (seperti mengizinkan akses baca-saja ke sumber daya tertentu).
Untuk informasi selengkapnya tentang menggunakan token SAS dengan layanan Tabel, lihat Menggunakan Shared Access Signature (SAS).
Namun, Anda masih harus membuat token SAS yang memberikan aplikasi klien ke entitas dalam layanan tabel: Anda harus melakukan ini di lingkungan yang memiliki akses aman ke kunci akun penyimpanan Anda. Umumnya, Anda menggunakan peran web atau pekerja untuk menghasilkan token SAS dan mengirimkannya ke aplikasi klien yang membutuhkan akses ke entitas Anda. Karena masih ada overhead yang terlibat dalam menghasilkan dan mengirimkan token SAS ke klien, Anda harus mempertimbangkan cara terbaik untuk mengurangi overhead ini, terutama dalam skenario volume tinggi.
Dimungkinkan untuk menghasilkan token SAS yang memberikan akses ke subset entitas dalam sebuah tabel. Secara default, Anda membuat token SAS untuk seluruh tabel, tetapi juga dimungkinkan untuk menentukan bahwa token SAS memberikan akses ke rentang nilai PartitionKey, atau rentang nilai PartitionKey dan RowKey. Anda dapat memilih untuk membuat token SAS untuk pengguna individu sistem Anda sehingga setiap token SAS pengguna hanya memungkinkan mereka mengakses ke entitas mereka sendiri dalam layanan tabel.
Operasi asinkron dan paralel
Asalkan Anda menyebarkan permintaan Anda ke beberapa partisi, Anda dapat meningkatkan throughput dan daya tanggap klien dengan menggunakan kueri asinkron atau paralel. Misalnya, Anda mungkin memiliki dua atau lebih instans peran pekerja yang mengakses tabel Anda secara paralel. Anda dapat memiliki peran pekerja individu yang bertanggung jawab untuk kumpulan partisi tertentu, atau memiliki beberapa contoh peran pekerja, masing-masing dapat mengakses semua partisi dalam tabel.
Dalam instans klien, Anda dapat meningkatkan throughput dengan menjalankan operasi penyimpanan secara asinkron. Pustaka klien Storage memudahkan untuk menulis kueri dan modifikasi asinkron. Misalnya, Anda dapat memulai dengan metode sinkron yang mengambil semua entitas di partisi seperti yang ditunjukkan pada kode C# berikut:
private static void ManyEntitiesQuery(TableClient employeeTable, string department)
{
TableContinuationToken continuationToken = null;
do
{
var employees = employeeTable.Query<EmployeeEntity>($"PartitionKey eq {department}");
foreach (var emp in employees.AsPages())
{
// ...
continuationToken = emp.ContinuationToken;
}
} while (continuationToken != null);
}
Anda dapat dengan mudah mengubah kode ini sehingga kueri berjalan secara asinkron sebagai berikut:
private static async Task ManyEntitiesQueryAsync(TableClient employeeTable, string department)
{
TableContinuationToken continuationToken = null;
do
{
var employees = await employeeTable.QueryAsync<EmployeeEntity>($"PartitionKey eq {department}");
foreach (var emp in employees.AsPages())
{
// ...
continuationToken = emp.ContinuationToken;
}
} while (continuationToken != null);
}
Dalam contoh asinkron ini, Anda dapat melihat perubahan berikut dari versi sinkron:
- Tanda tangan metode sekarang menyertakan pengubah async dan mengembalikan instans Tugas.
- Alih-alih memanggil metode Kueri untuk mengambil hasil, metode ini kini memanggil metode QueryAsync dan menggunakan pengubahawait untuk mengambil hasil secara asinkron.
Aplikasi klien dapat memanggil metode ini beberapa kali (dengan nilai berbeda untuk parameter departemen), dan setiap kueri akan dijalankan pada utas terpisah.
Anda juga dapat menyisipkan, memperbarui, dan menghapus entitas secara asinkron. Contoh C# berikut ini memperlihatkan metode sederhana dan sinkron untuk menyisipkan atau mengganti entitas karyawan:
private static void SimpleEmployeeUpsert(
TableClient employeeTable,
EmployeeEntity employee)
{
var result = employeeTable.UpdateEntity(employee, Azure.ETag.All, TableUpdateMode.Replace);
Console.WriteLine("HTTP Status: {0}", result.Status);
}
Anda dapat dengan mudah mengubah kode ini sehingga pembaruan berjalan secara asinkron seperti berikut:
private static async Task SimpleEmployeeUpsertAsync(
TableClient employeeTable,
EmployeeEntity employee)
{
var result = await employeeTable.UpdateEntityAsync(employee, Azure.ETag.All, TableUpdateMode.Replace);
Console.WriteLine("HTTP Status: {0}", result.Result.Status);
}
Dalam contoh asinkron ini, Anda dapat melihat perubahan berikut dari versi sinkron:
- Tanda tangan metode sekarang menyertakan pengubah async dan mengembalikan instans Tugas.
- Alih-alih memanggil metode Execute untuk memperbarui entitas, metode tersebut sekarang memanggil metode ExecuteAsync dan menggunakan pengubah await untuk mengambil hasil secara asinkron.
Aplikasi klien dapat memanggil beberapa metode asinkron seperti ini, dan setiap pemanggilan metode akan berjalan di utas terpisah.
Langkah berikutnya
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk