Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Anda dapat menerapkan model pembelajaran mesin sebagai fungsi yang ditentukan pengguna (UDF) dalam tugas Azure Stream Analytics untuk melakukan penilaian dan prediksi real-time pada data input streaming Anda. Azure Machine Learning memungkinkan Anda menggunakan alat sumber terbuka populer apa pun, seperti Tensorflow, scikit-learn, atau PyTorch, untuk mempersiapkan, melatih, dan menyebarkan model.
Prasyarat
Selesaikan langkah-langkah berikut sebelum menambahkan model pembelajaran mesin sebagai fungsi ke tugas Azure Stream Analytics Anda:
Gunakan Azure Machine Learning untuk menyebarkan model Anda sebagai layanan web.
Titik akhir pembelajaran mesin Anda harus memiliki swagger terkait yang membantu Stream Analytics memahami skema dari input dan output. Anda dapat menggunakan contoh definisi swagger ini sebagai referensi untuk memastikan Anda telah menyiapkannya dengan benar.
Pastikan layanan web Anda menerima dan menampilkan data seri JSON.
Sebarkan model Anda di Azure Kubernetes Service untuk penyebaran produksi skala tinggi. Jika layanan web tidak dapat menangani jumlah permintaan yang berasal dari pekerjaan Anda, performa pekerjaan Azure Stream Analytics Anda akan terdegradasi, yang memengaruhi latensi. Model yang disebarkan pada Azure Container Instances hanya didukung saat Anda menggunakan portal Azure.
Menambahkan model pembelajaran mesin ke pekerjaan Anda
Anda dapat menambahkan fungsi Azure Machine Learning ke pekerjaan Stream Analytics langsung dari portal Azure atau Visual Studio Code.
portal Azure
Buka pekerjaan Stream Analytics di portal Azure dan pilih Fungsi di bawah Topologi pekerjaan. Kemudian, pilih Layanan Azure Machine Learning dari menu drop-down + Tambahkan.
Isi formulir Fungsi Layanan Azure Machine Learning dengan nilai properti berikut ini:
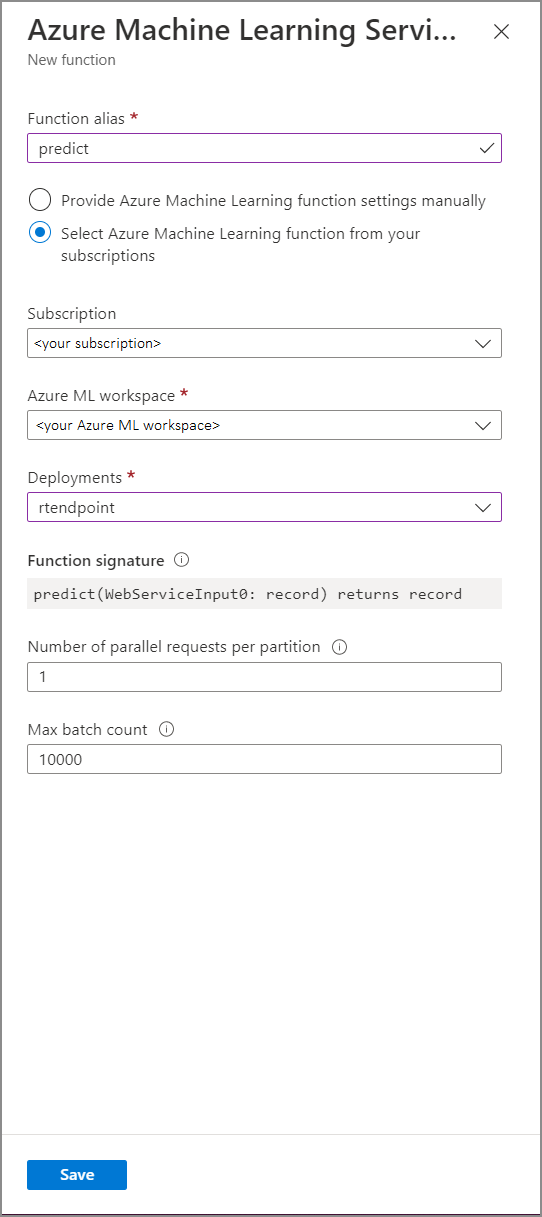
Tabel berikut ini menjelaskan setiap properti fungsi Layanan Azure Machine Learning di Stream Analytics.
| Properti | Deskripsi |
|---|---|
| Alias fungsi | Masukkan nama untuk memanggil fungsi di kueri Anda. |
| Langganan | Langganan Azure Anda. |
| Ruang kerja Azure Machine Learning | Ruang kerja Azure Machine Learning yang Anda gunakan untuk menerapkan model sebagai layanan berbasis web. |
| Titik akhir | Layanan web yang menghosting model Anda. |
| Tanda tangan fungsi | Tanda tangan layanan web Anda yang disimpulkan dari spesifikasi skema API. Jika tanda tangan Anda gagal dimuat, periksa apakah Anda telah memasukkan contoh input dan output dalam skrip penilaian Anda untuk menghasilkan skema secara otomatis. |
| Jumlah permintaan paralel per partisi | Ini adalah konfigurasi tingkat lanjut untuk mengoptimalkan throughput skala tinggi. Jumlah ini menunjukkan permintaan bersamaan yang dikirim dari setiap partisi pekerjaan Anda ke layanan web. Pekerjaan dengan enam unit streaming (SU) dan yang lebih rendah memiliki satu partisi. Pekerjaan dengan 12 SU memiliki dua partisi, 18 SU memiliki tiga partisi dan seterusnya. Misalnya, jika pekerjaan Anda memiliki dua partisi dan Anda mengatur parameter ini ke empat, akan ada delapan permintaan bersamaan dari pekerjaan Anda ke layanan web. |
| Jumlah batch maksimum | Ini adalah konfigurasi tingkat lanjut untuk mengoptimalkan tingkat aliran data skala tinggi. Jumlah ini menunjukkan jumlah maksimum peristiwa yang dikumpulkan bersama-sama dalam satu permintaan yang dikirim ke layanan web Anda. |
Memanggil titik akhir pembelajaran mesin dari kueri Anda
Saat kueri Stream Analytics Anda memanggil UDF Azure Machine Learning, pekerjaan akan membuat permintaan serialisasi JSON ke layanan web. Permintaan didasarkan pada skema khusus model yang disimpulkan Azure Stream Analytics dari Swagger titik akhir.
Peringatan
Titik akhir Pembelajaran Mesin tidak dipanggil saat Anda menguji dengan editor kueri Portal Azure karena pekerjaan tidak berjalan. Untuk menguji panggilan titik akhir dari portal, pekerjaan Stream Analytics perlu dijalankan.
Kueri Stream Analytics berikut adalah contoh cara memanggil UDF Azure Machine Learning.
SELECT udf.score(<model-specific-data-structure>)
INTO output
FROM input
WHERE <model-specific-data-structure> is not null
Jika data input Anda yang dikirim ke ML UDF tidak konsisten dengan skema yang diharapkan, titik akhir akan mengembalikan respons dengan kode kesalahan 400, yang akan menyebabkan pekerjaan Azure Stream Analytics Anda masuk ke status gagal. Disarankan agar Anda mengaktifkan log sumber daya untuk pekerjaan Anda, yang akan memungkinkan Anda untuk dengan mudah men-debug dan memecahkan masalah tersebut. Oleh karena itu, sangat disarankan agar Anda:
- Pastikan input ke ML UDF Anda tidak bernilai null
- Validasikan jenis setiap bidang yang menjadi input untuk UDF ML Anda untuk memastikan itu sesuai dengan yang diharapkan oleh endpoint.
Catatan
ML UDF dievaluasi untuk setiap baris dari langkah kueri tertentu, bahkan saat dipanggil melalui ekspresi bersyarat (yaitu CASE WHEN [A] IS NOT NULL THEN udf.score(A) ELSE '' END). Jika perlu, gunakan klausa WITH untuk membuat jalur divergen, memanggil ML UDF hanya jika diperlukan, sebelum menggunakan UNION untuk menggabungkan jalur kembali.
Operkan beberapa parameter input ke UDF
Contoh input yang paling umum untuk model pembelajaran mesin adalah array numpy dan DataFrames. Anda dapat membuat array menggunakan UDF JavaScript, dan membuat DataFrame serial JSON menggunakan klausul WITH.
Membuat array input
Anda dapat membuat UDF JavaScript yang menerima jumlah N input dan membuat array yang dapat digunakan sebagai input ke UDF Azure Machine Learning Anda.
function createArray(vendorid, weekday, pickuphour, passenger, distance) {
'use strict';
var array = [vendorid, weekday, pickuphour, passenger, distance]
return array;
}
Setelah menambahkan UDF JavaScript ke pekerjaan, Anda dapat memanggil Azure Machine Learning UDF menggunakan kueri berikut:
WITH
ModelInput AS (
#use JavaScript UDF to construct array that will be used as input to ML UDF
SELECT udf.createArray(vendorid, weekday, pickuphour, passenger, distance) as inputArray
FROM input
)
SELECT udf.score(inputArray)
INTO output
FROM ModelInput
#validate inputArray is not null before passing it to ML UDF to prevent job from failing
WHERE inputArray is not null
JSON berikut adalah contoh permintaan:
{
"Inputs": {
"WebServiceInput0": [
["1","Mon","12","1","5.8"],
["2","Wed","10","2","10"]
]
}
}
Membuat DataFrame Pandas atau PySpark
Anda dapat menggunakan klausul WITH untuk membuat DataFrame serial JSON yang dapat diteruskan sebagai input ke UDF Azure Machine Learning seperti yang ditunjukkan di bawah ini.
Kueri berikut membuat DataFrame dengan memilih bidang yang diperlukan dan menggunakan DataFrame sebagai input ke UDF Azure Machine Learning.
WITH
Dataframe AS (
SELECT vendorid, weekday, pickuphour, passenger, distance
FROM input
)
SELECT udf.score(Dataframe)
INTO output
FROM Dataframe
WHERE Dataframe is not null
JSON berikut adalah contoh permintaan dari kueri sebelumnya:
{
"Inputs": {
"WebServiceInput0": [
{
"vendorid": "1",
"weekday": "Mon",
"pickuphour": "12",
"passenger": "1",
"distance": "5.8"
},
{
"vendorid": "2",
"weekday": "Tue",
"pickuphour": "10",
"passenger": "2",
"distance": "10"
}]
}
}
Mengoptimalkan performa untuk UDF Azure Machine Learning
Saat menyebarkan model ke Azure Kubernetes Service, Anda dapat memprofilkan model Anda untuk menentukan penggunaan sumber daya. Anda juga dapat mengaktifkan App Insight untuk penyebaran guna memahami tingkat permintaan, waktu respons, dan tingkat kegagalan.
Jika memiliki skenario dengan throughput peristiwa yang tinggi, Anda mungkin perlu mengubah parameter berikut di Azure Stream Analytics untuk mencapai performa optimal dengan latensi ujung-ke-ujung yang rendah:
- Jumlah batch maksimum.
- Jumlah permintaan paralel per partisi.
Menentukan ukuran batch yang tepat
Setelah menyebarkan layanan web, Anda mengirim permintaan sampel dengan berbagai ukuran batch mulai dari 50 dan meningkatkannya dalam kelipatan ratusan. Misalnya, 200, 500, 1000, 2000 dan seterusnya. Anda akan melihat bahwa setelah ukuran batch tertentu, latensi respons akan meningkat. Titik di mana latensi respons mulai meningkat harus menjadi jumlah batch maksimum untuk pekerjaan Anda.
Menentukan jumlah permintaan paralel per partisi
Pada penskalaan optimal, tugas Azure Stream Analytics Anda adalah dapat mengirim beberapa permintaan paralel ke layanan web Anda dan mendapatkan respons dalam beberapa milidetik. Latensi respons layanan web dapat berdampak langsung terhadap latensi dan performa pekerjaan Azure Stream Analytics Anda. Jika panggilan dari pekerjaan Anda ke layanan web membutuhkan waktu lama, Anda mungkin akan melihat peningkatan penundaan tanda batas dan mungkin juga melihat peningkatan jumlah peristiwa input tertunda.
Untuk mendapatkan latensi rendah, pastikan kluster Azure Kubernetes Service (AKS) telah diprovisikan dengan jumlah simpul dan replika yang sesuai. Layanan web Anda harus sangat dapat diandalkan dan menghasilkan respons yang berhasil. Jika pekerjaan Anda menerima kesalahan yang dapat diulang prosesnya, seperti respons layanan tidak tersedia (503), pekerjaan tersebut akan secara otomatis mencoba kembali dengan penundaan eksponensial. Jika pekerjaan Anda menerima salah satu kesalahan ini sebagai respons dari titik akhir, pekerjaan akan masuk ke status gagal.
- Permintaan Tidak Valid (400)
- Konflik (409)
- Tidak Ditemukan(404)
- Tidak diizinkan (401)
Batasan
Jika Anda menggunakan layanan Titik Akhir Terkelola Azure ML, Azure Stream Analytics saat ini hanya dapat mengakses titik akhir yang mengaktifkan akses jaringan publik. Baca selengkapnya tentang hal itu di halaman tentang titik akhir privat Azure ML.