Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Di tutorial mulai cepat ini, Anda akan menggunakan Azure Synapse Analytics untuk membuat pipeline yang mentransformasi data dari sumber Azure Data Lake Storage Gen2 (ADLS Gen2) menjadi sink ADLS Gen2 menggunakan aliran data pemetaan. Pola konfigurasi dalam tutorial ini dapat diperluas saat mentransformasi data menggunakan aliran data pemetaan
Di tutorial mulai cepat ini, Anda akan melakukan langkah-langkah berikut:
- Membuat pipeline dengan aktivitas Aliran Data di Azure Synapse Analytics.
- Bangun aliran data pemetaan dengan empat transformasi.
- Uji coba alur.
- Memantau aktivitas Aliran Data
Prasyarat
Langganan Azure: Jika Anda belum memiliki langganan Azure, buat akun Azure gratis sebelum memulai.
Ruang kerja Azure Synapse: Buat ruang kerja Synapse menggunakan portal Azure dengan mengikuti instruksi dalam Mulai Cepat: Membuat ruang kerja Synapse.
Akun penyimpanan Azure: Anda menggunakan penyimpanan ADLS sebagai penyimpanan data sumber dan sink. Jika Anda tidak memiliki akun penyimpanan Azure, lihat artikel Membuat akun penyimpanan Azure untuk langkah-langkah pembuatannya.
File yang kita ubah dalam tutorial ini MoviesDB.csv, yang dapat ditemukan di sini. Untuk mengambil file dari GitHub, salin konten ke editor teks pilihan Anda untuk disimpan secara lokal sebagai file .csv. Untuk mengunggah file ke akun penyimpanan Anda, lihat Mengunggah blob dengan portal Microsoft Azure. Contohnya akan merujuk kontainer bernama 'sample-data'.
Membuka Synapse Studio
Setelah ruang kerja Azure Synapse dibuat, Anda dapat membuka Studio Synapse dengan dua cara:
- Buka ruang kerja Synapse Anda di portal Microsoft Azure. Pilih Buka pada kartu Buka Synapse Studio di bawah Memulai.
- Buka Azure Synapse Analytics dan masuk ke ruang kerja Anda.
Di tutorial mulai cepat ini, kami menggunakan ruang kerja bernama "adftest2020" sebagai contoh. Ruang kerja ini akan secara otomatis membawa Anda ke beranda Synapse Studio.
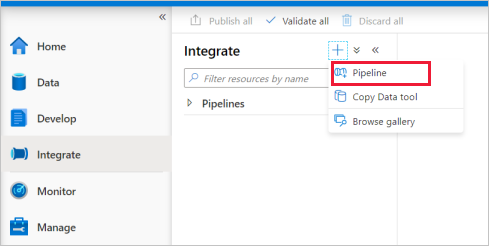
Buat alur dengan aktivitas Aliran Data
Alur berisi alur logika untuk proses eksekusi serangkaian aktivitas. Dalam bagian ini, Anda akan membuat pipeline yang berisi aktivitas Aliran Data.
Buka tab Integrasikan . Pilih ikon plus di samping header alur dan pilih Alur.
Di halaman pengaturan Properti pipeline, masukkan TransformMovies untuk Nama.
Di bagian Pindahkan dan Transformasi di panel Aktivitas, seret Aliran data ke kanvas pipeline.
Di pop-up halaman Menambahkan aliran data, pilih Buat aliran data baru ->Aliran data. Pilih OKE bila selesai.

Beri nama aliran data TransformMovies di halaman Properti.
Bangun logika transformasi di kanvas aliran data
Setelah membuat Aliran Data, Anda akan dikirim secara otomatis ke kanvas aliran data. Pada langkah ini, Anda akan membuat aliran data yang mengambil MoviesDB.csv di penyimpanan ADLS dan mengagregasi peringkat rata-rata komedi dari 1910 hingga 2000. Anda kemudian akan menulis kembali file ini ke penyimpanan ADLS.
Di atas kanvas aliran data, pindahkan penggeser Debug aliran data ke posisi aktif. Mode debug memungkinkan pengujian interaktif logika transformasi terhadap kluster Spark langsung. Kluster Aliran Data membutuhkan waktu pemanasan 5-7 menit dan pengguna disarankan untuk mengaktifkan debug terlebih dahulu jika berencana untuk melakukan pengembangan Aliran Data. Untuk informasi selengkapnya, lihat Mode Debug.

Di kanvas aliran data, tambahkan sumber dengan mengklik kotak Tambahkan Sumber.
Beri nama sumber Anda MoviesDB. Klik Baru untuk membuat himpunan data sumber baru.

Pilih Azure Data Lake Storage Gen2. Pilih Lanjutkan.

Pilih DelimitedText. Pilih Lanjutkan.
Beri nama himpunan data Anda MoviesDB. Di dropdown layanan tertaut, pilih Baru.
Di layar pembuatan layanan yang tertaut, beri nama layanan tertaut ADLS Gen2 ADLSGen2 dan tentukan metode autentikasi Anda. Lalu masukkan informasi masuk koneksi Anda. Di tutorial mulai cepat ini, kita akan menggunakan Kunci akun untuk menghubungkan ke akun penyimpanan. Anda dapat memilih Uji koneksi untuk memverifikasi kredensial Anda dimasukkan dengan benar. Pilih Buat saat selesai.

Setelah Anda kembali ke layar pembuatan set data, masukkan lokasi file Anda di bawah bidang Jalur file. Di tutorial mulai cepat ini, file “MoviesDB.csv” terletak di “sampel-data” kontainer. Saat file memiliki header, centang Baris pertama sebagai header. Pilih Dari koneksi/penyimpanan untuk mengimpor skema header langsung dari file dalam penyimpanan. Pilih OKE bila selesai.

Jika kluster debug Anda telah dimulai, buka tab Pratinjau Data dari transformasi sumber dan pilih Refresh untuk mendapatkan rekam jepret data. Anda dapat menggunakan pratinjau data untuk memverifikasi bahwa transformasi Anda dikonfigurasi dengan benar.

Di samping simpul sumber Anda pada kanvas aliran data, klik ikon plus untuk menambahkan transformasi baru. Transformasi pertama yang Anda tambahkan adalah Filter.

Beri nama filter transformasi Anda FilterYears. Klik pada kotak ekspresi di samping Filter untuk membuka penyusun ekspresi. Di sini Anda akan menentukan kondisi pemfilteran Anda.
Penyusun ekspresi aliran data memungkinkan Anda membangun ekspresi secara interaktif yang digunakan dalam berbagai transformasi. Ekspresi dapat menyertakan fungsi bawaan, kolom dari skema input, dan parameter yang ditentukan pengguna. Untuk informasi selengkapnya tentang cara menyusun ekspresi, lihat Penyusun ekspresi Aliran Data.
Di tutorial mulai cepat ini, Anda akan memfilter film genre komedi yang dirilis antara tahun 1910 dan 2000. Karena tahun saat ini adalah untai (karakter), Anda perlu mengonversinya menjadi bilangan bulat menggunakan fungsi
toInteger(). Gunakan operator yang lebih besar dari atau sama dengan (>=) dan lebih kecil dari atau sama dengan (<=) untuk membandingkan dengan nilai tahun literal 1910 dan 200-. Satukan ekspresi ini bersama dengan&&(dan) operator. Ekspresi akan keluar sebagai:toInteger(year) >= 1910 && toInteger(year) <= 2000Untuk menemukan film mana yang merupakan komedi, Anda dapat menggunakan fungsi
rlike()untuk menemukan pola 'Komedi' dalam genre kolom. Satukan ekspresirlikedengan perbandingan tahun untuk mendapatkan:toInteger(year) >= 1910 && toInteger(year) <= 2000 && rlike(genres, 'Comedy')
Jika Anda memiliki kluster debug aktif, Anda dapat memverifikasi logika Anda dengan mengklik Refresh untuk melihat output ekspresi dibandingkan dengan input yang digunakan. Ada lebih dari satu jawaban yang tepat tentang bagaimana Anda dapat menyelesaikan logika ini menggunakan bahasa ekspresi aliran data.
Pilih Simpan dan Selesai setelah Anda selesai dengan ekspresi Anda.
Ambil Pratinjau Data untuk memverifikasi bahwa filter berfungsi dengan benar.
Transformasi berikutnya yang akan Anda tambahkan adalah transformasi Agregat di bawah pengubah Skema.

Beri nama transformasi agregat Anda AggregateComedyRatings. Di tab Kelompokkan menurut, pilih tahun dari dropdown untuk mengelompokkan agregasi menurut tahun film yang telah keluar.

Masuk ke tab Agregat. Di kotak teks kiri, beri nama kolom agregat AverageComedyRating. Pilih kotak ekspresi kanan untuk memasukkan ekspresi agregat melalui pembuat ekspresi.

Untuk mendapatkan rata-rata kolom Peringkat, gunakan
avg()fungsi agregat. Karena Peringkat adalah untai (karakter) danavg()mengambil input numerik, kita harus mengonversi nilai ke angka melalui fungsitoInteger(). Ekspresi ini terlihat seperti:avg(toInteger(Rating))Pilih Simpan dan Selesai setelah selesai.

Masuk ke tab Pratinjau Data untuk melihat output transformasi. Perhatikan hanya dua kolom yang ada di sana, tahun dan AverageComedyRating.

Selanjutnya, Anda ingin menambahkan transformasi Sink di bawah Tujuan.

Beri nama sink Anda Sink. Klik Baru untuk membuat himpunan data sink Anda.
Pilih Azure Data Lake Storage Gen2. Pilih Lanjutkan.
Pilih DelimitedText. Pilih Lanjutkan.
Beri nama set data sink Anda MoviesSink. Untuk layanan tertaut, pilih layanan tertaut ADLS Gen2 yang Anda buat di langkah 7. Masukkan folder output untuk menulis data Anda. Di tutorial mulai cepat ini, kita akan menulis ke folder 'output' dalam 'sample-data' kontainer. Folder tidak perlu ada sebelumnya dan dapat dibuat secara dinamis. Atur Baris pertama sebagai header ke true dan pilih Tidak ada untuk Skema impor. Pilih OKE bila selesai.

Sekarang Anda sudah selesai membangun aliran data Anda. Anda siap untuk menjalankannya pada pipeline.
Menjalankan dan memantau Aliran Data
Anda dapat men-debug alur sebelum memublikasikannya. Dalam langkah ini, Anda akan memicu proses debug dari pipeline aliran data. Meskipun pratinjau data tidak menulis data, eksekusi debug menulis data ke tujuan sink Anda.
Pergi ke kanvas alur. Klik Debug untuk memicu eksekusi debug.

Debug pipeline aktivitas Aliran Data menggunakan kluster debug aktif, tetapi masih membutuhkan waktu setidaknya satu menit untuk diinisialisasi. Anda dapat melacak kemajuan melalui tab Output . Setelah eksekusi berhasil, pilih ikon kacamata untuk membuka panel pemantauan.

Di panel pemantauan, Anda dapat melihat jumlah baris dan waktu yang dihabiskan di setiap langkah transformasi.

Klik transformasi untuk mendapatkan informasi terperinci tentang kolom dan pemartisian data.

Jika Anda mengikuti tutorial mulai cepat ini dengan benar, seharusnya Anda sudah menulis 83 baris dan 2 kolom ke dalam folder sink Anda. Anda dapat memverifikasi data dengan memeriksa penyimpanan blob.
Langkah berikutnya
Lanjutkan ke artikel berikut untuk mempelajari dukungan Azure Synapse Analytics: