Tutorial: Membuat definisi pekerjaan Apache Spark di Synapse Studio
Tutorial ini menunjukkan cara menggunakan Synapse Studio untuk membuat definisi pekerjaan Apache Spark, dan kemudian mengirimkannya ke kumpulan Apache Spark tanpa server.
Tutorial ini mencakup tugas-tugas berikut:
- Membuat definisi kerja Apache Spark untuk PySpark (Python)
- Membuat definisi kerja Apache Spark untuk Spark (Scala)
- Membuat definisi kerja Apache Spark untuk .NET Spark (C#/F#)
- Membuat definisi kerja dengan mengimpor file JSON
- Mengekspor file definisi kerja Apache Spark ke lokal
- Mengirim definisi kerja Apache Spark sebagai tugas batch
- Menambahkan definisi kerja Apache Spark ke dalam alur
Prasyarat
Sebelum Anda mulai dengan tutorial ini, pastikan untuk memenuhi persyaratan berikut:
- Ruang kerja Azure Synapse Analytics. Untuk mengetahui petunjuknya, lihat Membuat ruang kerja Azure Synapse Analytics.
- Kumpulan Apache Spark tanpa server.
- Akun penyimpanan ADLS Gen2. Anda harus menjadi Kontributor Penyimpanan Data Blob dari sistem file ADLS Gen2 yang ingin Anda kerjakan. Jika tidak, Anda perlu menambahkan izin secara manual.
- Jika Anda tidak ingin menggunakan penyimpanan default ruang kerja, tautkan akun penyimpanan ADLS Gen2 yang diperlukan di Synapse Studio.
Membuat definisi kerja Apache Spark untuk PySpark (Python)
Di bagian ini, Anda membuat definisi kerja Apache Spark untuk PySpark (Python).
Buka Synapse Studio.
Anda dapat membuka Contoh file untuk membuat definisi kerja Apache Spark untuk mengunduh file sampel untuk python.zip, lalu ekstrak zip paket terkompresi, dan mengekstrak file wordcount.py dan danshakespeare.txt.

Pilih Data ->Linked ->Azure Data Lake Storage Gen2, dan unggah wordcount.py dan shakespeare.txt ke dalam sistem file ADLS Gen2 Anda.

Pilih hub Kembangkan, pilih ikon '+' dan pilih definisi kerja Spark untuk membuat definisi kerja baru Spark.

Pilih PySpark (Python) dari daftar drop-down Bahasa di jendela utama definisi kerja Apache Spark.

Isi informasi untuk definisi kerja Apache Spark.
Properti Deskripsi Nama definisi kerja Masukkan nama untuk definisi pekerjaan Apache Spark Anda. Nama ini dapat diperbarui kapan saja hingga diterbitkan.
Sampel:job definition sampleBerkas definisi utama File utama yang digunakan untuk tugas tersebut. Pilih file PY dari penyimpanan Anda. Anda dapat memilih Unggah file untuk mengunggah file ke akun penyimpanan.
Sampel:abfss://…/path/to/wordcount.pyArgumen baris perintah Argumen opsional untuk pekerjaan.
Sampel:abfss://…/path/to/shakespeare.txtabfss://…/path/to/result
Catatan: Dua argumen untuk definisi kerja sampel dipisahkan oleh spasi.File referensi File tambahan yang digunakan untuk referensi dalam file definisi utama. Anda dapat memilih Unggah file untuk mengunggah file ke akun penyimpanan. Kumpulan Spark Pekerjaan akan diserahkan ke kumpulan Apache Spark yang dipilih. Versi Spark Versi Apache Spark yang dijalankan oleh kumpulan Apache Spark. Pelaksana Jumlah pelaksana yang akan diberikan dalam kumpulan Apache Spark yang ditentukan untuk pekerjaan tersebut. Ukuran Pelaksana Jumlah inti dan memori yang akan digunakan untuk pelaksana yang diberikan dalam kumpulan Apache Spark yang ditentukan untuk pekerjaan tersebut. Ukuran driver Jumlah inti dan memori yang akan digunakan untuk driver yang diberikan dalam kumpulan Apache Spark yang ditentukan untuk pekerjaan tersebut. Konfigurasi Apache Spark Sesuaikan konfigurasi dengan menambahkan properti di bawah ini. Jika Anda tidak menambahkan properti, Azure Synapse akan menggunakan nilai default jika berlaku. 
Pilih Terbitkan untuk menyimpan definisi kerja Apache Spark.

Membuat definisi kerja Apache Spark untuk Apache Spark(Scala)
Dalam bagian ini, Anda membuat definisi kerja Apache Spark untuk Apache Spark(Scala).
Buka Azure Synapse Studio.
Anda dapat melihat Contoh file untuk membuat definisi kerja Apache Spark untuk mengunduh file sampel untuk scala.zip, lalu ekstrak zip paket terkompresi, dan mengekstrak file wordcount.jar dan shakespeare.txt.

Pilih Data ->Linked ->Azure Data Lake Storage Gen2, dan unggah wordcount.jar dan shakespeare.txt ke dalam sistem file ADLS Gen2 Anda.

Pilih hub Kembangkan, pilih ikon '+' dan pilih definisi kerja Spark untuk membuat definisi kerja baru Spark. (Gambar sampel sama dengan langkah 4 dari Buat definisi kerja Apache Spark (Python) untuk PySpark.)
Pilih Spark(Scala) dari daftar drop-down Bahasa di jendela utama definisi kerja Apache Spark.

Isi informasi untuk definisi kerja Apache Spark. Anda dapat menyalin informasi sampel.
Properti Deskripsi Nama definisi kerja Masukkan nama untuk definisi pekerjaan Apache Spark Anda. Nama ini dapat diperbarui kapan saja hingga diterbitkan.
Sampel:scalaBerkas definisi utama File utama yang digunakan untuk tugas tersebut. Pilih file JAR dari penyimpanan Anda. Anda dapat memilih Unggah file untuk mengunggah file ke akun penyimpanan.
Sampel:abfss://…/path/to/wordcount.jarNama kelas utama Pengidentifikasi yang sepenuhnya memenuhi syarat atau kelas utama yang ada dalam file definisi utama.
Sampel:WordCountArgumen baris perintah Argumen opsional untuk pekerjaan.
Sampel:abfss://…/path/to/shakespeare.txtabfss://…/path/to/result
Catatan: Dua argumen untuk definisi kerja sampel dipisahkan oleh spasi.File referensi File tambahan yang digunakan untuk referensi dalam file definisi utama. Anda dapat memilih Unggah file untuk mengunggah file ke akun penyimpanan. Kumpulan Spark Pekerjaan akan diserahkan ke kumpulan Apache Spark yang dipilih. Versi Spark Versi Apache Spark yang dijalankan oleh kumpulan Apache Spark. Pelaksana Jumlah pelaksana yang akan diberikan dalam kumpulan Apache Spark yang ditentukan untuk pekerjaan tersebut. Ukuran Pelaksana Jumlah inti dan memori yang akan digunakan untuk pelaksana yang diberikan dalam kumpulan Apache Spark yang ditentukan untuk pekerjaan tersebut. Ukuran driver Jumlah inti dan memori yang akan digunakan untuk driver yang diberikan dalam kumpulan Apache Spark yang ditentukan untuk pekerjaan tersebut. Konfigurasi Apache Spark Sesuaikan konfigurasi dengan menambahkan properti di bawah ini. Jika Anda tidak menambahkan properti, Azure Synapse akan menggunakan nilai default jika berlaku. 
Pilih Terbitkan untuk menyimpan definisi kerja Apache Spark.

Buat definisi kerja Apache Spark untuk .NET Spark(C#/F#)
Dalam bagian ini, Anda membuat definisi kerja Apache Spark untuk .NET Spark (C#F#).
Buka Azure Synapse Studio.
Anda dapat melihat Contoh file untuk membuat definisi kerja Apache Spark untuk mengunduh file sampel untuk dotnet.zip, lalu ekstrak zip paket terkompresi, dan mengekstrak file wordcount.zip dan shakespeare.txt.

Pilih Data ->Linked ->Azure Data Lake Storage Gen2, dan unggah wordcount.zip dan shakespeare.txt ke dalam sistem file ADLS Gen2 Anda.
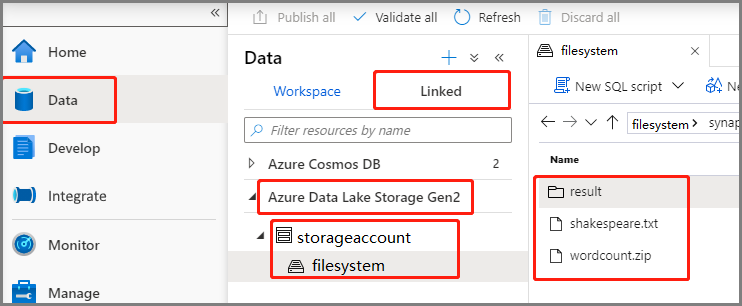
Pilih hub Kembangkan, pilih ikon '+' dan pilih definisi kerja Spark untuk membuat definisi kerja baru Spark. (Gambar sampel sama dengan langkah 4 dari Buat definisi kerja Apache Spark (Python) untuk PySpark.)
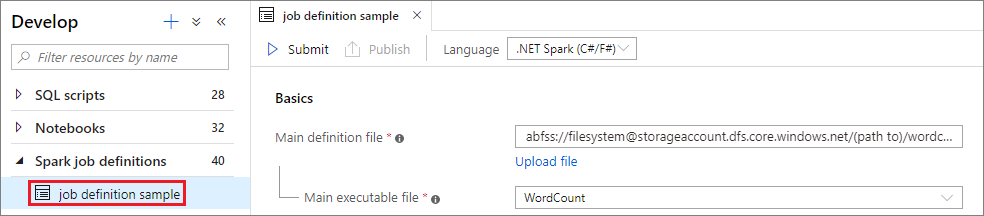
Pilih .NET Spark(C#F#) dari daftar drop-down Bahasa di jendela utama Definisi Kerja Apache Spark.

Isi informasi untuk Definisi Kerja Apache Spark. Anda dapat menyalin informasi sampel.
Properti Deskripsi Nama definisi kerja Masukkan nama untuk definisi pekerjaan Apache Spark Anda. Nama ini dapat diperbarui kapan saja hingga diterbitkan.
Sampel:dotnetBerkas definisi utama File utama yang digunakan untuk tugas tersebut. Pilih file ZIP yang berisi aplikasi .NET for Apache Spark Anda (yaitu, file yang dapat dieksekusi utama, DLL yang berisi fungsi yang ditentukan pengguna, dan file lain yang diperlukan) dari penyimpanan Anda. Anda dapat memilih Unggah file untuk mengunggah file ke akun penyimpanan.
Sampel:abfss://…/path/to/wordcount.zipBerkas utama yang dapat dieksekusi Berkas utama yang dapat dieksekusi dalam berkas ZIP definisi utama.
Sampel:WordCountArgumen baris perintah Argumen opsional untuk pekerjaan.
Sampel:abfss://…/path/to/shakespeare.txtabfss://…/path/to/result
Catatan: Dua argumen untuk definisi kerja sampel dipisahkan oleh spasi.File referensi File tambahan yang diperlukan oleh simpul pekerja untuk menjalankan aplikasi .NET untuk Apache Spark yang tidak termasuk dalam file ZIP definisi utama (yaitu, jar dependen, DLL fungsi tambahan yang ditentukan pengguna, dan file konfigurasi lainnya). Anda dapat memilih Unggah file untuk mengunggah file ke akun penyimpanan. Kumpulan Spark Pekerjaan akan diserahkan ke kumpulan Apache Spark yang dipilih. Versi Spark Versi Apache Spark yang dijalankan oleh kumpulan Apache Spark. Pelaksana Jumlah pelaksana yang akan diberikan dalam kumpulan Apache Spark yang ditentukan untuk pekerjaan tersebut. Ukuran Pelaksana Jumlah inti dan memori yang akan digunakan untuk pelaksana yang diberikan dalam kumpulan Apache Spark yang ditentukan untuk pekerjaan tersebut. Ukuran driver Jumlah inti dan memori yang akan digunakan untuk driver yang diberikan dalam kumpulan Apache Spark yang ditentukan untuk pekerjaan tersebut. Konfigurasi Apache Spark Sesuaikan konfigurasi dengan menambahkan properti di bawah ini. Jika Anda tidak menambahkan properti, Azure Synapse akan menggunakan nilai default jika berlaku. 
Pilih Terbitkan untuk menyimpan definisi kerja Apache Spark.

Catatan
Untuk konfigurasi Apache Spark, jika konfigurasi Apache Spark definisi pekerjaan Apache Spark tidak melakukan sesuatu yang istimewa, konfigurasi default akan digunakan saat menjalankan pekerjaan.
Membuat definisi pekerjaan Apache Spark dengan mengimpor file JSON
Anda dapat mengimpor file JSON lokal yang ada ke ruang kerja Azure Synapse dari menu Tindakan (...) dari definisi kerja Apache Spark Explorer untuk membuat definisi kerja Apache Spark baru.

Definisi kerja Spark sepenuhnya kompatibel dengan Livy API. Anda dapat menambahkan parameter tambahan untuk properti Livy lainnya (Livy Docs - REST API (apache.org) dalam file JSON lokal. Anda juga dapat menentukan parameter terkait konfigurasi Spark di properti konfigurasi seperti yang ditunjukkan di bawah ini. Kemudian, Anda dapat mengimpor kembali file JSON untuk membuat definisi pekerjaan Apache Spark baru untuk pekerjaan batch Anda. Contoh JSON untuk impor definisi spark:
{
"targetBigDataPool": {
"referenceName": "socdemolarge",
"type": "BigDataPoolReference"
},
"requiredSparkVersion": "2.3",
"language": "scala",
"jobProperties": {
"name": "robinSparkDefinitiontest",
"file": "adl://socdemo-c14.azuredatalakestore.net/users/robinyao/wordcount.jar",
"className": "WordCount",
"args": [
"adl://socdemo-c14.azuredatalakestore.net/users/robinyao/shakespeare.txt"
],
"jars": [],
"files": [],
"conf": {
"spark.dynamicAllocation.enabled": "false",
"spark.dynamicAllocation.minExecutors": "2",
"spark.dynamicAllocation.maxExecutors": "2"
},
"numExecutors": 2,
"executorCores": 8,
"executorMemory": "24g",
"driverCores": 8,
"driverMemory": "24g"
}
}

Mengekspor file definisi kerja Apache Spark yang ada
Anda dapat mengekspor file definisi pekerjaan Apache Spark yang ada ke lokal dari menu Tindakan (...) dari File Explorer. Anda dapat memperbarui lebih lanjut file JSON untuk properti Livy tambahan, dan mengimpornya kembali untuk membuat definisi pekerjaan baru jika perlu.


Mengirim definisi kerja Apache Spark sebagai tugas batch
Setelah membuat definisi pekerjaan Apache Spark, Anda dapat mengirimkannya ke kumpulan Apache Spark. Pastikan Anda menjadi Kontributor Penyimpanan Data Blob dari sistem file ADLS Gen2 yang ingin Anda kerjakan. Jika tidak, Anda perlu menambahkan izin secara manual.
Skenario 1: Kirim definisi pekerjaan Apache Spark
Buka jendela definisi kerja Apache sparl dengan memilihnya.
Pilih tombol Kirim untuk mengirimkan proyek Anda ke Kumpulan Apache Spark yang dipilih. Anda dapat memilih tab URL pemantauan Spark untuk melihat LogQuery dari aplikasi Apache Spark.


Skenario 2: Lihat kemajuan kerja Apache Spark yang sedang berjalan
Pilih Monitor, lalu pilih opsi aplikasi Apache Spark. Anda dapat menemukan aplikasi Apache Spark yang dikirimkan.

Kemudian pilih aplikasi Apache Spark, jendela pekerjaan SparkJobDefinition ditampilkan. Anda dapat melihat progres eksekusi pekerjaan dari sini.

Skenario 3: Periksa file output
Pilih Data ->Linked ->Azure Data Lake Storage Gen2 (hozhaobdbj), buka folder hasil yang dibuat sebelumnya, Anda dapat masuk ke folder hasil dan memeriksa apakah output dihasilkan.

Menambahkan definisi kerja Apache Spark ke dalam alur
Di bagian ini, Anda menambahkan definisi pekerjaan Apache Spark ke dalam alur.
Membuka definisi kerja Apache Spark yang ada.
Pilih ikon di kanan atas definisi kerja Apache Spark, pilih Alur yang Ada,atau Alur baru. Anda dapat merujuk ke halaman Alur untuk informasi lebih lanjut.


Langkah berikutnya
Selanjutnya Anda bisa menggunakan Azure Synapse Studio untuk membuat himpunan data Power BI dan mengelola data Power BI. Lanjutkan ke artikel Menautkan ruang kerja Power BI ke ruang kerja Synapse untuk mempelajari selengkapnya.