Optimalkan pekerjaan Apache Spark di Azure Synapse Analytics
Pelajari cara mengoptimalkan konfigurasi kluster Apache Spark untuk beban kerja tertentu. Tantangan yang paling umum adalah tekanan memori, karena konfigurasi yang tidak tepat (terutama pelaksana berukuran salah), operasi yang berjalan lama, dan tugas yang mengakibatkan operasi Cartesian. Anda dapat mempercepat pekerjaan dengan penembolokan yang sesuai, dan dengan mengizinkan kemiringan data. Untuk performa terbaik, pantau dan tinjau eksekusi pekerjaan Spark yang sudah berjalan lama dan memakan sumber daya.
Bagian berikut menjelaskan pengoptimalan dan rekomendasi pekerjaan Spark yang umum.
Memilih abstraksi data
Versi Spark sebelumnya menggunakan RDD untuk mengabstraksi data, Spark 1.3, dan 1.6 masing-masing memperkenalkan DataFrames dan DataSets. Pertimbangkan manfaat relatif berikut:
- DataFrames
- Pilihan terbaik dalam sebagian besar situasi.
- Menyediakan pengoptimalan kueri melalui Catalyst.
- Pembuatan kode seluruh tahap.
- Akses memori langsung.
- Overhead pengumpulan sampah (garbage collection atau GC) rendah.
- Tidak ramah pengembang seperti DataSets, karena tidak ada pemeriksaan waktu kompilasi atau pemrograman objek domain.
- DataSets
- Berjalan dengan baik dalam alur ETL kompleks di mana dampak performa dapat diterima.
- Tidak berjalan dengan baik dalam agregasi di mana dampak performa mungkin cukup besar.
- Menyediakan pengoptimalan kueri melalui Catalyst.
- Ramah pengembang dengan menyediakan pemrograman objek domain dan pemeriksaan waktu kompilasi.
- Menambahkan serialisasi/deserialisasi overhead.
- Overhead GC tinggi.
- Memecahkan seluruh tahap pembuatan kode.
- RDD
- Anda tidak perlu menggunakan RDD, kecuali Anda perlu membuat RDD kustom baru.
- Tidak ada pengoptimalan kueri melalui Catalyst.
- Tidak ada pembuatan kode seluruh tahap.
- Overhead GC tinggi.
- Harus menggunakan API warisan Spark 1.x.
Gunakan format data yang optimal
Spark mendukung berbagai format, seperti csv, json, xml, parquet, orc, dan avro. Spark dapat diperluas untuk mendukung lebih banyak format dengan sumber data eksternal - untuk informasi selengkapnya, lihat paket Apache Spark.
Format terbaik untuk performa adalah parquet dengan kompresi tajam, yang merupakan default dalam Spark 2.x. Parquet menyimpan data dalam format kolom, dan sangat dioptimalkan dalam Spark. Selain itu, meskipun kompresi cepat mungkin menghasilkan file yang lebih besar daripada kompresi gzip. Karena sifat file-file yang dapat dipisahkan, file akan mendekompresi lebih cepat.
Gunakan cache
Spark menyediakan mekanisme penembolokan aslinya sendiri, yang dapat digunakan melalui metode yang berbeda seperti .persist(), .cache(), dan CACHE TABLE. Penembolokan asli ini efektif dengan kumpulan data kecil serta dalam alur ETL tempat Anda perlu melakukan penembolokan hasil menengah. Namun, penembolokan asli Spark saat ini tidak berfungsi dengan baik dengan pemartisian, karena tabel cache tidak menyimpan data pemartisian.
Gunakan memori secara efektif
Spark beroperasi dengan menempatkan data dalam memori, sehingga mengelola sumber daya memori adalah aspek kunci dalam mengoptimalkan pelaksanaan pekerjaan Spark. Ada beberapa teknik yang dapat Anda terapkan untuk menggunakan memori kluster Anda secara efisien.
- Pilih partisi data yang lebih kecil dan akun untuk ukuran, jenis, dan distribusi data dalam strategi pemartisian Anda.
- Pertimbangkan serialisasi data Kryo yang lebih baru dan lebih efisien, daripada serialisasi Java default.
- Pantau dan sesuaikan pengaturan konfigurasi Spark.
Untuk referensi Anda, struktur memori Spark dan beberapa parameter memori eksekutor utama ditampilkan pada gambar berikutnya.
Pertimbangan memori Spark
Apache Spark di Azure Synapse menggunakan YARN Apache Hadoop YARN, YARN mengontrol jumlah maksimum memori yang digunakan oleh semua kontainer di setiap simpul Spark. Diagram berikut memperlihatkan objek kunci dan hubungannya.
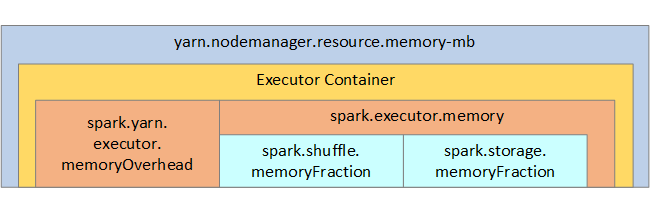
Untuk mengatasi pesan 'kehabisan memori', cobalah:
- Tinjau Pengacakan Manajemen DAG. Kurangi dengan pengurangan sisi peta, data sumber pra-partisi (atau masukkan ke wadah), maksimalkan acak tunggal, dan kurangi jumlah data yang dikirim.
- Pilihlah
ReduceByKeydengan batas memori tetap hinggaGroupByKeyyang menyediakan agregasi, windowing, dan fungsi lainnya tetapi memiliki batas memori tak terbatas. - Pilihlah
TreeReduce, yang melakukan lebih banyak pekerjaan pada eksekutor atau partisi, daripadaReduce, yang melakukan semua pekerjaan pada driver. - Manfaatkan DataFrames daripada objek RDD tingkat bawah.
- Buat ComplexTypes yang merangkum tindakan, seperti "Top N", berbagai agregasi, atau operasi windowing.
Optimalkan serialisasi data
Pekerjaan spark didistribusikan, sehingga serialisasi data yang sesuai penting untuk performa terbaik. Ada dua opsi serialisasi untuk Spark:
- Serialisasi Java adalah pengaturan defaultnya.
- Serialisasi Kryo adalah format yang lebih baru dan dapat menghasilkan serialisasi yang lebih cepat dan lebih ringkas daripada Java. Kryo mengharuskan Anda mendaftarkan kelas dalam program Anda, dan belum mendukung semua jenis Serializable.
Gunakan pengelompokan
Pengelompokan mirip dengan pemartisian data, tetapi setiap wadah dapat menahan kumpulan nilai kolom daripada hanya satu. Pengelompokan berfungsi dengan baik untuk pemartisian pada jumlah nilai yang besar (dalam jutaan atau lebih), seperti pengidentifikasi produk. Wadah ditentukan dengan hashing kunci wadah dari baris. Tabel dengan bucket menawarkan pengoptimalan unik karena menyimpan metadata tentang cara proses pengelompokan dan pengurutan.
Beberapa fitur pengelompokan lanjutan adalah:
- Pengoptimalan kueri berdasarkan meta-informasi bucketing.
- Agregasi yang dioptimalkan.
- Gabungan yang dioptimalkan.
Anda dapat menggunakan pemartisian dan pengelompokan secara bersamaan.
Optimalkan penggabungan dan pengacakan
Jika Anda memiliki pekerjaan yang lambat di Gabung atau Acak, penyebabnya mungkin adalah kemiringan data, yang merupakan asimetri dalam data pekerjaan Anda. Misalnya, pekerjaan peta mungkin memakan waktu 20 detik, tetapi menjalankan pekerjaan di mana data bergabung atau diacak membutuhkan waktu berjam-jam. Untuk memperbaiki penyimpangan data, Anda harus memberikan salt ke seluruh kunci, atau menggunakan salt terisolasi hanya untuk beberapa subset kunci. Jika Anda menggunakan salt terisolasi, Anda harus memfilter lebih lanjut untuk mengisolasi subset kunci Anda yang diberi salt di gabungan peta. Pilihan lain adalah memasukkan kolom wadah dan pra-agregat dalam wadah terlebih dahulu.
Faktor lain yang menyebabkan gabungan lambat mungkin saja dikarenakan jenis gabungan. Secara default, Spark menggunakan jenis gabungan SortMerge. Jenis gabungan ini paling cocok untuk himpunan data besar, tetapi sebaliknya mahal secara komputasi karena harus terlebih dahulu menyortir sisi kiri dan kanan data sebelum menggabungkannya.
Gabungan Broadcast paling cocok untuk himpunan data yang lebih kecil, atau di mana satu sisi gabungan jauh lebih kecil daripada sisi lain. Jenis gabungan ini menyiarkan satu sisi ke semua eksekutor, sehingga membutuhkan lebih banyak memori untuk siaran secara umum.
Anda dapat mengubah jenis gabungan dalam konfigurasi Anda dengan mengatur spark.sql.autoBroadcastJoinThreshold, atau Anda dapat mengatur petunjuk gabungan menggunakan DataFrame API (dataframe.join(broadcast(df2))).
// Option 1
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", 1*1024*1024*1024)
// Option 2
val df1 = spark.table("FactTableA")
val df2 = spark.table("dimMP")
df1.join(broadcast(df2), Seq("PK")).
createOrReplaceTempView("V_JOIN")
sql("SELECT col1, col2 FROM V_JOIN")
Jika menggunakan tabel yang dengan bucket, Anda memiliki jenis gabungan ketiga, gabungan Merge. Set data yang sebelumnya dipartisi dan diurutkan dengan benar akan melewatkan fase pengurutan mahal dari gabungan SortMerge.
Urutan gabungan merupakan hal yang penting, terutama dalam kueri yang lebih kompleks. Mulailah dengan gabungan yang paling selektif. Selain itu, pindahkan gabungan yang meningkatkan jumlah baris setelah agregasi jika memungkinkan.
Untuk mengelola paralelisme untuk gabungan Cartesian, Anda dapat menambahkan struktur bersarang, windowing, dan mungkin melewatkan satu atau beberapa langkah dalam Pekerjaan Spark Anda.
Memilih ukuran eksekutor yang benar
Saat memutuskan konfigurasi eksekutor Anda, pertimbangkan overhead pengumpulan sampah (garbage collection, GC) Java.
Faktor-faktor untuk mengurangi ukuran eksekutor:
- Kurangi ukuran tumpukan di bawah 32 GB untuk menjaga overhead GC < 10%.
- Kurangi jumlah inti untuk menjaga overhead GC < 10%.
Faktor untuk meningkatkan ukuran eksekutor:
- Kurangi overhead komunikasi antar eksekutor.
- Kurangi jumlah koneksi terbuka antar pelaksana (N2) pada kluster yang lebih besar (>100 pelaksana).
- Tingkatkan ukuran heap untuk mengakomodasi tugas intensif memori.
- Opsional: Kurangi overhead memori per-eksekutor.
- Opsional: Tingkatkan pemanfaatan dan konkurensi dengan oversubscribing CPU.
Sebagai aturan umum saat memilih ukuran eksekutor:
- Mulai dengan 30 GB per eksekutor dan distribusikan inti mesin yang tersedia.
- Tingkatkan jumlah core pelaksana untuk kluster yang lebih besar (> 100 pelaksana).
- Ubah ukuran berdasarkan uji coba dan faktor-faktor sebelumnya seperti overhead GC.
Saat menjalankan kueri bersamaan, pertimbangkan hal berikut:
- Mulai dengan 30 GB per eksekutor dan semua inti mesin.
- Buat beberapa aplikasi Spark paralel dengan oversubscribing CPU (sekitar 30% peningkatan latensi).
- Distribusikan kueri di seluruh aplikasi paralel.
- Ubah ukuran berdasarkan uji coba dan faktor-faktor sebelumnya seperti overhead GC.
Pantau performa kueri Anda untuk outlier atau masalah performa lainnya, dengan melihat tampilan garis waktu, grafik SQL, statistik pekerjaan, dan sebagainya. Terkadang satu atau beberapa eksekutor lebih lambat dari yang lain, dan tugas membutuhkan waktu lebih lama untuk dijalankan. Ini sering terjadi pada kluster yang lebih besar (> 30 node). Dalam hal ini, bagi pekerjaan menjadi jumlah tugas yang lebih besar sehingga penjadwal dapat mengimbangi tugas yang lambat.
Misalnya, miliki setidaknya dua kali lebih banyak tugas dari jumlah inti eksekutor dalam aplikasi. Anda juga dapat mengaktifkan eksekusi spekulatif tugas dengan conf: spark.speculation = true.
Optimalkan pelaksanaan pekerjaan
- Tembolokkan seperlunya, misalnya jika Anda menggunakan data dua kali, lalu tembolokkan.
- Siarkan variabel ke semua eksekutor. Variabel hanya diserialkan sekali, menghasilkan pencarian yang lebih cepat.
- Gunakan kumpulan rangkaian pada driver, yang menghasilkan operasi yang lebih cepat untuk banyak tugas.
Kunci untuk performa kueri Spark 2.x adalah mesin Tungsten, yang bergantung pada pembuatan kode seluruh tahap. Dalam beberapa kasus, pembuatan kode seluruh tahap dapat dinonaktifkan.
Contohnya, jika Anda menggunakan jenis yang tidak dapat berubah (string) dalam ekspresi agregasi, SortAggregate yang muncul dan bukan HashAggregate. Contohnya, untuk performa yang lebih baik, cobalah hal berikut ini lalu aktifkan ulang pembuatan kode:
MAX(AMOUNT) -> MAX(cast(AMOUNT as DOUBLE))
Langkah berikutnya
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk