Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Pelajari cara menggunakan Panda untuk membaca/ menulis data ke Azure Data Lake Storage Gen2 (ADLS) menggunakan pool Apache Spark tanpa server di Azure Synapse Analytics. Contoh dalam tutorial ini menunjukkan kepada Anda cara membaca data csv dengan Pandas dalam file Synapse, excel, dan parket.
Dalam tutorial ini, Anda akan mempelajari cara:
- Baca/tulis data ADLS Gen2 menggunakan Panda dalam sesi Spark.
Jika Anda tidak memiliki langganan Azure, buat akun gratis sebelum Anda memulai.
Prasyarat
Ruang kerja Azure Synapse Analytics dengan akun penyimpanan Azure Data Lake Storage Gen2 yang dikonfigurasi sebagai penyimpanan default (atau penyimpanan utama). Anda harus menjadi Kontributor Penyimpanan Data Blob dari sistem file Data Lake Storage Gen2 yang Anda gunakan.
Kumpulan Apache Spark nirserver di ruang kerja Azure Synapse Analytics Anda. Untuk detailnya, lihat Membuat kumpulan Spark di Azure Synapse.
Konfigurasikan akun Secondary Azure Data Lake Storage Gen2 (yang tidak secara otomatis terhubung ke ruang kerja Synapse). Anda harus menjadi Kontributor Penyimpanan Data Blob dari sistem file Data Lake Storage Gen2 yang Anda gunakan.
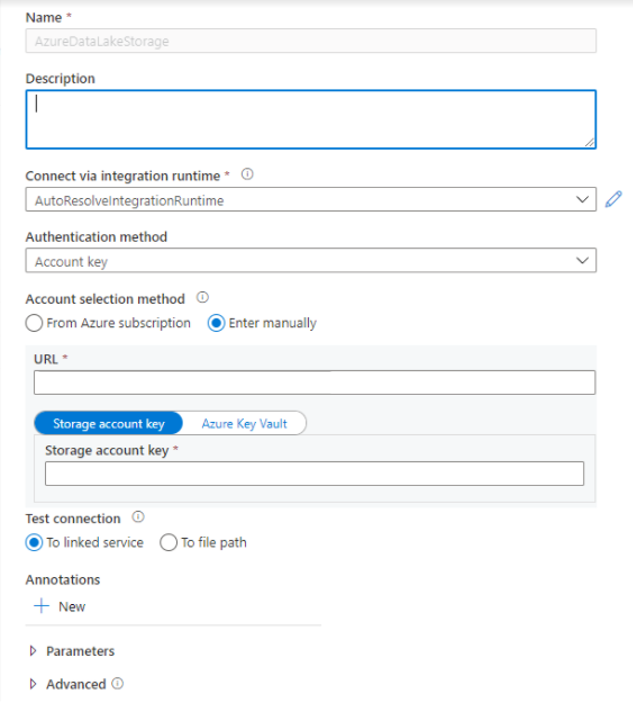
Buat layanan tertaut - Di Azure Synapse Analytics, layanan tertaut menentukan informasi koneksi Anda ke layanan. Di bagian ini, Anda akan menambahkan Azure Synapse Analytics dan Azure Data Lake Storage Gen2 sebagai layanan tertaut.
- Buka Studio Azure Synapse dan pilih tab Kelola.
- Di bawah Koneksi eksternal, pilih Layanan tertaut.
- Untuk menambahkan layanan tertaut, pilih Baru.
- Pilih petak peta Azure Data Lake Storage Gen2 dari daftar dan pilih Lanjutkan.
- Masukkan info masuk autentikasi Anda. Kunci akun, perwakilan layanan (SP), Kredensial, dan Identitas layanan terkelola (MSI) saat ini didukung jenis autentikasi. Pastikan Kontributor Data Blob Penyimpanan telah dipasang pada penyimpanan untuk SP dan MSI sebelum Anda memilihnya untuk autentikasi. Uji koneksi untuk memastikan info masuk Anda sudah benar. Pilih Buat.
Penting
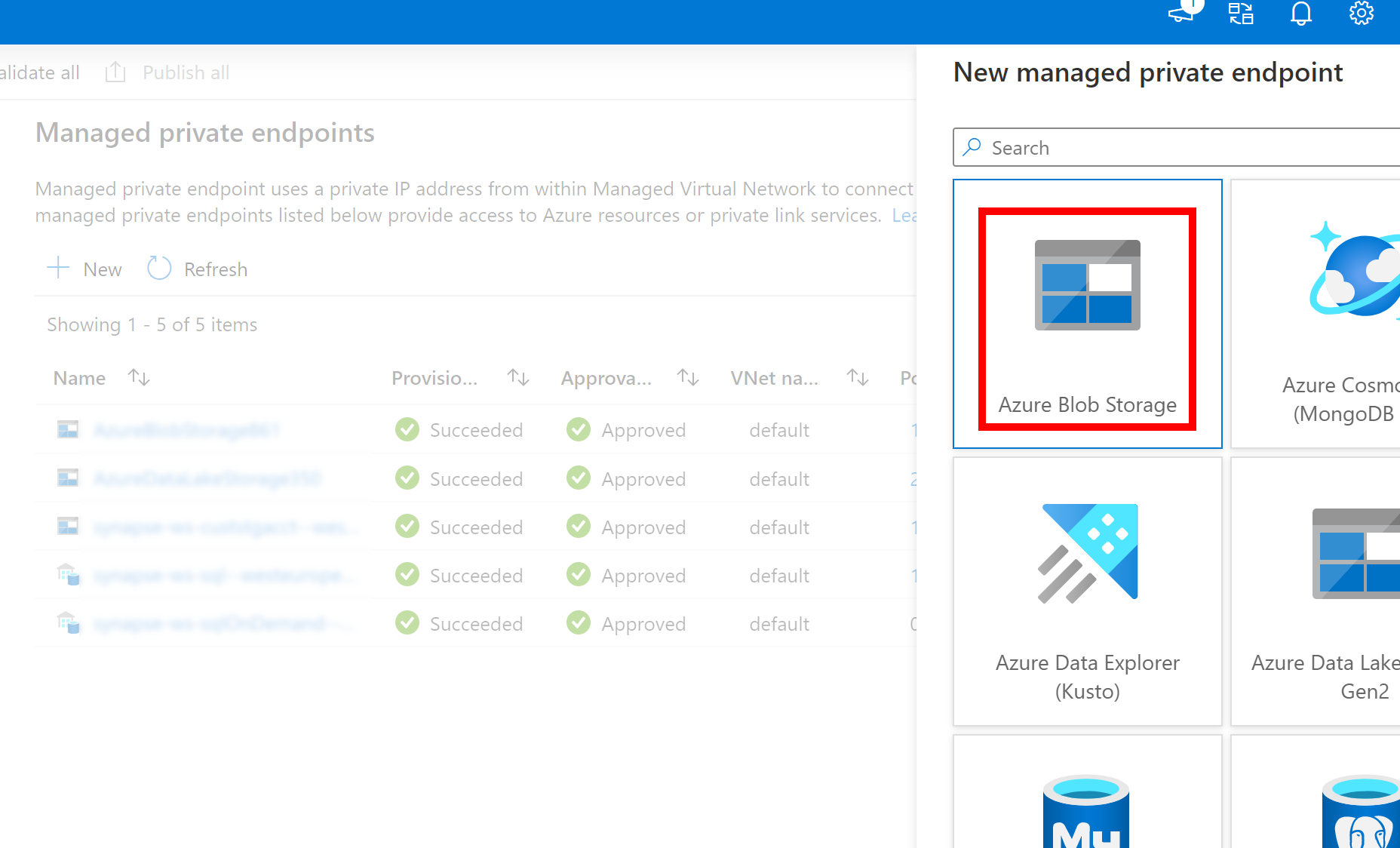
- Jika Layanan Tertaut yang dibuat di atas ke Azure Data Lake Storage Gen2 menggunakan titik akhir privat terkelola (dengan URI dfs), maka kita perlu membuat titik akhir privat terkelola sekunder menggunakan opsi Azure Blob Storage (dengan URI blob) untuk memastikan bahwa kode internal fsspec/adlfs dapat tersambung menggunakan antarmuka BlobServiceClient.
- Jika titik akhir privat terkelola sekunder tidak dikonfigurasi dengan benar, maka kita akan melihat pesan kesalahan seperti ServiceRequestError: Tidak dapat tersambung ke host [storageaccountname].blob.core.windows.net:443 ssl:True [Nama atau layanan tidak diketahui]
Catatan
- Fitur Pandas didukung pada Python 3.8 dan pool Apache Spark Spark3 nirserver di Azure Synapse Analytics.
- Dukungan yang tersedia untuk versi berikut: pandas 1.2.3, fsspec 2021.10.0, adlfs 0.7.7
- Memiliki kemampuan untuk mendukung Azure Data Lake Storage Gen2 URI (abfs[s]://file_system_name@account_name.dfs.core.windows.net/file_path) dan URL pendek FSSPEC (abfs[s]://container_name/file_path).
Masuk ke portal Microsoft Azure.
Masuk ke portal Azure.
Membaca dan menulis data ke akun penyimpanan ADLS default di Synapse workspace
Panda dapat membaca/menulis data ADLS dengan menentukan jalur file langsung dari penyimpanan ADLS Gen 2 default Anda.
Jalankan kode berikut.
Catatan
Perbarui URL berkas dalam skrip ini sebelum menjalankannya.
#Read data file from URI of default Azure Data Lake Storage Gen2
import pandas
#read csv file
df = pandas.read_csv('abfs[s]://file_system_name@account_name.dfs.core.windows.net/file_path')
print(df)
#write csv file
data = pandas.DataFrame({'Name':['A', 'B', 'C', 'D'], 'ID':[20, 21, 19, 18]})
data.to_csv('abfs[s]://file_system_name@account_name.dfs.core.windows.net/file_path')
#Read data file from FSSPEC short URL of default Azure Data Lake Storage Gen2
import pandas
#read csv file
df = pandas.read_csv('abfs[s]://container_name/file_path')
print(df)
#write csv file
data = pandas.DataFrame({'Name':['A', 'B', 'C', 'D'], 'ID':[20, 21, 19, 18]})
data.to_csv('abfs[s]://container_name/file_path')
Baca/Tulis data menggunakan akun ADLS sekunder
Panda dapat membaca/menulis data akun ADLS sekunder:
- menggunakan layanan tertaut (dengan opsi autentikasi - kunci akun penyimpanan, prinsip layanan, mengelola identitas layanan dan kredensial).
- menggunakan opsi penyimpanan untuk langsung memasukkan ID klien & rahasia, kunci SAS, kunci akun penyimpanan, dan string koneksi.
Jalankan kode berikut.
Catatan
Perbarui URL file dan nama layanan tertaut dalam skrip ini sebelum menjalankannya.
#Read data file from URI of secondary Azure Data Lake Storage Gen2
import pandas
#read data file
df = pandas.read_csv('abfs[s]://file_system_name@account_name.dfs.core.windows.net/ file_path', storage_options = {'linked_service' : 'linked_service_name'})
print(df)
#write data file
data = pandas.DataFrame({'Name':['A', 'B', 'C', 'D'], 'ID':[20, 21, 19, 18]})
data.to_csv('abfs[s]://file_system_name@account_name.dfs.core.windows.net/file_path', storage_options = {'linked_service' : 'linked_service_name'})
#Read data file from FSSPEC short URL of default Azure Data Lake Storage Gen2
import pandas
#read data file
df = pandas.read_csv('abfs[s]://container_name/file_path', storage_options = {'linked_service' : 'linked_service_name'})
print(df)
#write data file
data = pandas.DataFrame({'Name':['A', 'B', 'C', 'D'], 'ID':[20, 21, 19, 18]})
data.to_csv('abfs[s]://container_name/file_path', storage_options = {'linked_service' : 'linked_service_name'})
Contoh untuk membaca/menulis file parquet
Jalankan kode berikut.
Catatan
Perbarui URL berkas dalam skrip ini sebelum menjalankannya.
import pandas
#read parquet file
df = pandas.read_parquet('abfs[s]://file_system_name@account_name.dfs.core.windows.net/ parquet_file_path')
print(df)
#write parquet file
df.to_parquet('abfs[s]://file_system_name@account_name.dfs.core.windows.net/ parquet_file_path')
Contoh untuk membaca/menulis file Microsoft Excel
Jalankan kode berikut.
Catatan
Perbarui URL berkas dalam skrip ini sebelum menjalankannya.
import pandas
#read excel file
df = pandas.read_excel('abfs[s]://file_system_name@account_name.dfs.core.windows.net/ excel_file_path')
print(df)
#write excel file
df.to_excel('abfs[s]://file_system_name@account_name.dfs.core.windows.net/excel_file_path')