Penyetelan performa dengan indeks penyimpan kolom berkluster yang diurutkan di Azure Synapse Analytics
Berlaku untuk: Kumpulan SQL khusus Azure Synapse Analytics
Saat pengguna mengkueri tabel columnstore di kumpulan SQL khusus, pengoptimal memeriksa nilai minimum dan maksimum yang disimpan di setiap segmen. Segmen yang berada di luar batas predikat kueri tidak dibaca dari disk ke memori. Kueri bisa selesai lebih cepat jika jumlah segmen untuk dibaca dan ukuran totalnya kecil.
Catatan
Artikel ini berlaku untuk kumpulan SQL khusus Azure Synapse Analytics. Untuk informasi tentang indeks penyimpan kolom yang diurutkan di SQL Server dan platform SQL lainnya, lihat Penyetelan performa dengan indeks penyimpan kolom berkluster yang diurutkan.
Indeks columnstore terkluster yang tidak diurutkan vs. tidak diurutkan
Secara default, untuk setiap tabel yang dibuat tanpa opsi indeks, komponen internal (pembuat indeks) membuat indeks columnstore terkluster (CCI) yang tidak diurutkan di atasnya. Data di setiap kolom dikompresi ke dalam segmen rowgroup CCI terpisah. Ada metadata pada rentang nilai setiap segmen, sehingga segmen yang berada di luar batas predikat kueri tidak dibaca dari disk selama eksekusi kueri. CCI menawarkan tingkat kompresi data tertinggi dan mengurangi ukuran segmen untuk dibaca sehingga kueri dapat berjalan lebih cepat. Namun, karena pembuat indeks tidak mengurutkan data sebelum mengompresinya menjadi segmen, segmen dengan rentang nilai yang tumpang tindih dapat terjadi, menyebabkan kueri membaca lebih banyak segmen dari disk dan membutuhkan waktu lebih lama untuk diselesaikan.
Mengurutkan indeks penyimpan kolom berkluster dengan mengaktifkan eliminasi segmen yang efisien, menghasilkan performa yang jauh lebih cepat dengan melewati sejumlah besar data yang diurutkan yang tidak cocok dengan predikat kueri. Saat membuat CCI yang diurutkan, mesin kumpulan SQL khusus mengurutkan data yang ada dalam memori dengan kunci urutan sebelum pembangun indeks mengompresinya ke dalam segmen indeks. Dengan data yang diurutkan, tumpang tindih segmen berkurang, memungkinkan kueri memiliki eliminasi segmen yang lebih efisien dan dengan demikian performa yang lebih cepat karena jumlah segmen untuk dibaca dari disk lebih kecil. Jika semua data dapat diurutkan dalam memori sekaligus, maka segmen yang tumpang tindih dapat dihindari. Karena tabel besar di gudang data, skenario ini tidak sering terjadi.
Untuk memeriksa rentang segmen untuk kolom, jalankan perintah berikut ini dengan nama tabel dan nama kolom Anda:
SELECT o.name, pnp.index_id,
cls.row_count, pnp.data_compression_desc,
pnp.pdw_node_id, pnp.distribution_id, cls.segment_id,
cls.column_id,
cls.min_data_id, cls.max_data_id,
cls.max_data_id-cls.min_data_id as difference
FROM sys.pdw_nodes_partitions AS pnp
JOIN sys.pdw_nodes_tables AS Ntables ON pnp.object_id = NTables.object_id AND pnp.pdw_node_id = NTables.pdw_node_id
JOIN sys.pdw_table_mappings AS Tmap ON NTables.name = TMap.physical_name AND substring(TMap.physical_name,40, 10) = pnp.distribution_id
JOIN sys.objects AS o ON TMap.object_id = o.object_id
JOIN sys.pdw_nodes_column_store_segments AS cls ON pnp.partition_id = cls.partition_id AND pnp.distribution_id = cls.distribution_id
JOIN sys.columns as cols ON o.object_id = cols.object_id AND cls.column_id = cols.column_id
WHERE o.name = '<Table Name>' and cols.name = '<Column Name>' and TMap.physical_name not like '%HdTable%'
ORDER BY o.name, pnp.distribution_id, cls.min_data_id;
Catatan
Dalam tabel CCI yang diurutkan, data baru yang dihasilkan dari batch DML atau operasi pemuatan data yang sama diurutkan dalam batch itu, tidak ada pengurutan global di semua data dalam tabel. Pengguna dapat MEMBANGUN ULANG CCI yang diurutkan untuk mengurutkan semua data dalam tabel. Dalam kumpulan SQL khusus, indeks columnstore BANGUN ULANG adalah operasi offline. Untuk tabel yang dipartisi, BANGUN ULANG dilakukan satu partisi demi satu partisi. Data dalam partisi yang sedang dibangun ulang adalah "offline" dan tidak tersedia sampai BANGUN ULANG selesai untuk partisi itu.
Performa Kueri
Perolehan performa kueri dari CCI yang diurutkan bergantung pada pola kueri, ukuran data, seberapa baik data diurutkan, struktur fisik segmen, dan kelas DWU dan sumber daya yang dipilih untuk eksekusi kueri. Pengguna harus meninjau semua faktor ini sebelum memilih kolom pemesanan saat mendesain tabel CCI yang diurutkan.
Kueri dengan semua pola ini biasanya berjalan lebih cepat dengan CCI yang diurutkan.
- Kueri memiliki predikat kesetaraan, ketidaksetaraan, atau rentang
- Kolom predikat dan kolom CCI yang diurutkan sama.
Dalam contoh ini, tabel T1 memiliki indeks columnstore terkluster yang diurutkan dalam urutan Col_C, Col_B, dan Col_A.
CREATE CLUSTERED COLUMNSTORE INDEX MyOrderedCCI ON T1
ORDER (Col_C, Col_B, Col_A);
Performa kueri 1 dan kueri 2 dapat memperoleh lebih banyak manfaat dari CCI yang diurutkan daripada kueri lainnya, karena mereferensikan semua kolom CCI yang diurutkan.
-- Query #1:
SELECT * FROM T1 WHERE Col_C = 'c' AND Col_B = 'b' AND Col_A = 'a';
-- Query #2
SELECT * FROM T1 WHERE Col_B = 'b' AND Col_C = 'c' AND Col_A = 'a';
-- Query #3
SELECT * FROM T1 WHERE Col_B = 'b' AND Col_A = 'a';
-- Query #4
SELECT * FROM T1 WHERE Col_A = 'a' AND Col_C = 'c';
Performa pemuatan data
Performa pemuatan data ke dalam tabel CCI yang diurutkan mirip dengan tabel yang dipartisi. Memuat data ke dalam tabel CCI yang diurutkan dapat memakan waktu lebih lama dari tabel CCI yang tidak diurutkan karena operasi pengurutan data, namun kueri dapat berjalan lebih cepat setelahnya dengan CCI yang diurutkan.
Berikut adalah contoh perbandingan performa pemuatan data ke dalam tabel dengan skema yang berbeda.
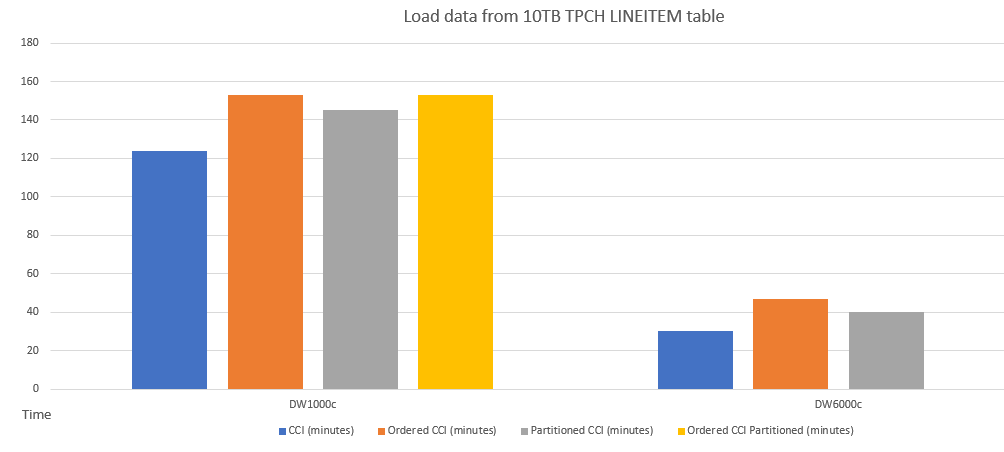
Berikut adalah contoh perbandingan performa kueri antara CCI dan CCI yang diurutkan.
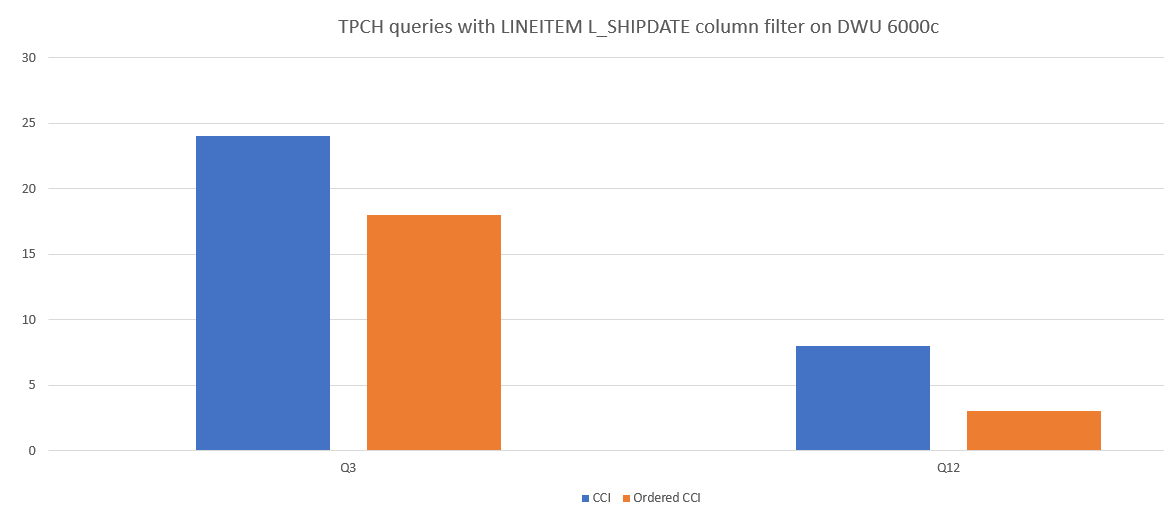
Kurangi segmen yang tumpang tindih
Jumlah segmen yang tumpang tindih tergantung pada ukuran data untuk diurutkan, memori yang tersedia, dan tingkat maksimum pengaturan paralelisme (MAXDOP) selama pembuatan CCI yang diurutkan. Strategi berikut mengurangi tumpang tindih segmen saat membuat CCI yang diurutkan.
Gunakan kelas sumber daya
xlargercpada DWU yang lebih tinggi untuk memungkinkan lebih banyak memori untuk pengurutan data sebelum pembuat indeks memadatkan data ke dalam segmen. Setelah berada di segmen indeks, lokasi fisik data tidak dapat diubah. Tidak ada pengurutan data dalam segmen atau lintas segmen.Buat CCI yang diurutkan dengan
OPTION (MAXDOP = 1). Setiap utas yang digunakan untuk pembuatan CCI yang diurutkan bekerja pada subkumpulan data dan mengurutkannya secara lokal. Tidak ada pengurutan global di seluruh data yang diurutkan berdasarkan utas yang berbeda. Penggunaan utas paralel dapat mengurangi waktu untuk membuat CCI yang diurutkan tetapi akan menghasilkan lebih banyak segmen tumpang tindih daripada menggunakan satu utas. Menggunakan operasi berulir tunggal memberikan kualitas kompresi tertinggi. Contoh:
CREATE TABLE Table1 WITH (DISTRIBUTION = HASH(c1), CLUSTERED COLUMNSTORE INDEX ORDER(c1) )
AS SELECT * FROM ExampleTable
OPTION (MAXDOP 1);
Catatan
Saat ini, dalam kumpulan SQL khusus di Azure Synapse Analytics, opsi MAXDOP hanya didukung dalam membuat tabel CCI yang diurutkan menggunakan CREATE TABLE AS SELECT perintah. Membuat CCI yang diurutkan melalui CREATE INDEX perintah atau CREATE TABLE tidak mendukung opsi MAXDOP. Batasan ini tidak berlaku untuk SQL Server 2022 dan versi yang lebih baru, di mana Anda dapat menentukan MAXDOP dengan CREATE INDEX perintah atau CREATE TABLE .
- Pra-urutkan data menurut kunci pengurutan sebelum memuatnya ke dalam tabel.
Berikut adalah contoh distribusi tabel CCI yang diurutkan yang tidak memiliki segmen tumpang tindih mengikuti rekomendasi di atas. Tabel CCI yang diurutkan dibuat dalam database DWU1000c melalui CTAS dari tabel timbunan 20 GB menggunakan MAXDOP 1 dan xlargerc. CCI diurutkan pada kolom BIGINT tanpa duplikat.
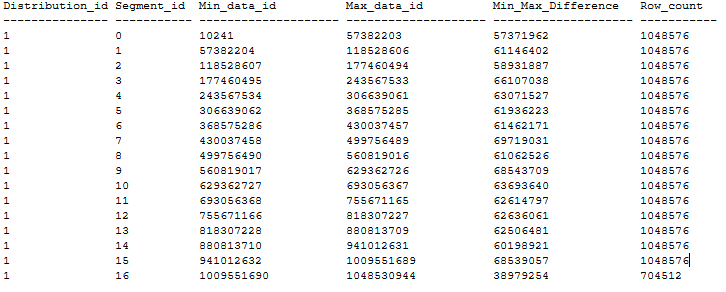
Buat CCI yang diurutkan pada tabel besar
Pembuatan CCI yang diurutkan adalah operasi offline. Untuk tabel tanpa partisi, data tidak akan dapat diakses oleh pengguna hingga proses pembuatan CCI yang diurutkan selesai. Untuk tabel berpartisi, karena mesin membuat partisi CCI yang diurutkan berdasarkan partisi, pengguna masih dapat mengakses data dalam partisi di mana pembuatan CCI yang diurutkan tidak sedang dalam proses. Anda dapat menggunakan opsi ini untuk meminimalkan downtime selama pembuatan CCI yang diurutkan pada tabel besar:
- Buat partisi pada tabel besar target (disebut
Table_A). - Buat tabel CCI kosong yang diurutkan (disebut
Table_B) dengan skema tabel dan partisi yang sama denganTable_A. - Tukar satu partisi dari
Table_AkeTable_B. - Jalankan
ALTER INDEX <Ordered_CCI_Index> ON <Table_B> REBUILD PARTITION = <Partition_ID>untuk membangun kembali partisi yang dialihkan padaTable_B. - Ulangi langkah 3 dan 4 untuk setiap partisi di
Table_A. - Setelah semua partisi telah ditukar dari
Table_AkeTable_Bdan telah dibangun kembali, hilangkanTable_A, dan ubah namaTable_BkeTable_A.
Tip
Untuk tabel kumpulan SQL khusus dengan CCI yang diurutkan, ALTER INDEX REBUILD akan mengurutkan ulang data menggunakan tempdb. Pantau tempdbselama operasi pembangunan ulang. Jika Anda membutuhkan lebih banyak ruang tempdb, tingkatkan skala kumpulan database. Turunkan skala setelah pembangunan ulang indeks selesai.
Untuk tabel kumpulan SQL khusus dengan CCI yang diurutkan, ALTER INDEX REORGANIZE tidak mengurutkan ulang data. Untuk mengurutkan ulang data, gunakan ALTER INDEX REBUILD.
Untuk informasi selengkapnya tentang pemeliharaan CCI yang diurutkan, lihat Mengoptimalkan indeks columnstore terkluster.
Perbedaan fitur dalam kemampuan SQL Server 2022
SQL Server 2022 (16.x) memperkenalkan indeks penyimpan kolom terkluster yang diurutkan yang mirip dengan fitur di kumpulan SQL khusus Azure Synapse.
- Saat ini, hanya SQL Server 2022 (16.x) dan versi yang lebih baru yang mendukung kemampuan eliminasi segmen penyimpan kolom berkluster yang ditingkatkan untuk jenis data string, biner, dan guid, dan jenis data datetimeoffset untuk skala yang lebih besar dari dua. Sebelumnya, penghapusan segmen ini berlaku untuk jenis data numerik, tanggal, dan waktu, dan jenis data datetimeoffset dengan skala kurang dari atau sama dengan dua.
- Saat ini, hanya SQL Server 2022 (16.x) dan versi yang lebih baru yang mendukung penghapusan grup baris penyimpan kolom berkluster untuk awalan
LIKEpredikat, misalnyacolumn LIKE 'string%'. Penghapusan segmen tidak didukung untuk penggunaan non-awalan LIKE seperticolumn LIKE '%string'.
Untuk informasi selengkapnya, lihat Apa yang Baru dalam Indeks Penyimpan Kolom.
Contoh
J. Untuk memeriksa kolom yang diurutkan dan ordinal urutan:
SELECT object_name(c.object_id) table_name, c.name column_name, i.column_store_order_ordinal
FROM sys.index_columns i
JOIN sys.columns c ON i.object_id = c.object_id AND c.column_id = i.column_id
WHERE column_store_order_ordinal <>0;
B. Untuk mengubah ordinal kolom, menambah atau menghapus kolom dari daftar urutan, atau mengubah dari CCI ke CCI yang diurutkan:
CREATE CLUSTERED COLUMNSTORE INDEX InternetSales ON dbo.InternetSales
ORDER (ProductKey, SalesAmount)
WITH (DROP_EXISTING = ON);
Langkah berikutnya
- Untuk tips pengembangan selengkapnya, lihat ringkasan pengembangan.
- Indeks Penyimpan Kolom: Ringkasan
- Apa yang baru dalam indeks penyimpan kolom
- Indeks Penyimpan Kolom - Panduan desain
- Indeks Penyimpan Kolom - Performa kueri