Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Tip
Microsoft Fabric Data Warehouse adalah gudang relasional skala perusahaan pada fondasi data lake, dengan arsitektur siap masa depan, AI bawaan, dan fitur baru. Jika Anda baru menggunakan pergudangan data, mulailah dengan Fabric Data Warehouse. Beban kerja kumpulan SQL terdedikasi yang ada dapat ditingkatkan ke Fabric untuk mengakses kemampuan baru di seluruh ilmu data, analitik waktu nyata, dan pelaporan.
Artikel ini menjelaskan cara memperkirakan dan mengelola biaya untuk kumpulan SQL tanpa server di Azure Synapse Analytics:
- Memperkirakan jumlah data yang diproses sebelum mengeluarkan kueri
- Menggunakan fitur kontrol biaya untuk mengatur anggaran
Pahami bahwa biaya untuk kumpulan SQL tanpa server di Azure Synapse Analytics hanya sebagian dari biaya bulanan dalam tagihan Azure Anda. Jika Anda menggunakan layanan Azure lainnya, Anda akan ditagih untuk semua layanan dan sumber daya Azure yang digunakan dalam langganan Azure Anda, termasuk layanan pihak ketiga. Artikel ini menjelaskan cara merencanakan dan mengelola biaya untuk kumpulan SQL tanpa server di Azure Synapse Analytics.
Data diproses
Data yang diproses adalah jumlah data yang disimpan sistem untuk sementara waktu saat kueri dijalankan. Data yang diproses terdiri dari jumlah berikut:
- Jumlah data yang dibaca dari penyimpanan. Jumlah ini meliputi:
- Data dibaca selama proses membaca data.
- Data dibaca saat membaca metadata (untuk format file yang berisi metadata, seperti Parquet).
- Jumlah data dalam hasil menengah. Data ini ditransfer di antara simpul saat kueri berjalan. Ini termasuk transfer data ke titik akhir Anda, dalam format yang tidak dikompresi.
- Jumlah data yang ditulis ke penyimpanan. Jika Anda menggunakan CETAS untuk mengekspor set hasil Anda ke penyimpanan, maka jumlah data yang ditulis akan ditambahkan ke jumlah data yang diproses untuk bagian SELECT dari CETAS.
Proses membaca file dari penyimpanan dioptimalkan secara maksimal. Proses ini menggunakan:
- Prefetching, yang mungkin menambahkan beberapa biaya tambahan ke jumlah data yang dibaca. Jika kueri membaca seluruh file, maka tidak ada overhead. Jika file dibaca sebagian, seperti dalam kueri TOP N, maka sedikit lebih banyak data dibaca dengan menggunakan prefetching.
- Pengurai nilai yang dipisahkan koma (CSV) yang dioptimalkan. Jika Anda menggunakan PARSER_VERSION='2.0' untuk membaca file CSV, maka jumlah data yang dibaca dari penyimpanan sedikit meningkat. Pengurai CSV yang dioptimalkan membaca file secara paralel, dalam potongan dengan ukuran yang sama. Potongan data tidak selalu berisi seluruh baris. Untuk memastikan semua baris diurai, pengurai CSV yang dioptimalkan juga membaca fragmen kecil gugus yang berdekatan. Proses ini menambahkan sejumlah kecil overhead.
Statistik
Pengoptimal kueri kumpulan SQL tanpa server bergantung pada statistik untuk menghasilkan rencana eksekusi kueri yang optimal. Anda dapat membuat statistik secara manual. Jika tidak, kumpulan SQL tanpa server membuatnya secara otomatis. Bagaimanapun, statistik dibuat dengan menjalankan kueri terpisah yang mengembalikan kolom tertentu pada laju sampel yang disediakan. Kueri ini memiliki jumlah data terkait yang diproses.
Jika Anda menjalankan kueri yang sama atau lainnya yang akan mendapat manfaat dari statistik yang dibuat, statistik akan digunakan kembali jika memungkinkan. Tidak ada data tambahan yang diproses untuk pembuatan statistik.
Saat statistik dibuat untuk kolom Parquet, hanya kolom yang relevan yang dibaca dari file. Saat statistik dibuat untuk kolom CSV, seluruh file dibaca dan diurai.
Pembulatan
Jumlah data yang diproses dibulatkan ke atas ke MB terdekat per kueri. Setiap kueri memiliki minimal 10 MB data yang diproses.
Data yang diproses tidak termasuk apa?
- Metadata tingkat server (seperti login, peran, dan kredensial tingkat server).
- Database yang Anda buat pada endpoint Anda. Database tersebut hanya berisi metadata (seperti pengguna, peran, skema, tampilan, fungsi bernilai tabel sebaris [TVF], prosedur tersimpan, kredensial cakupan database, sumber data eksternal, format file eksternal, dan tabel eksternal).
- Jika Anda menggunakan inferensi skema, fragmen file dibaca untuk menyimpulkan nama kolom dan jenis data, dan jumlah data yang dibaca ditambahkan ke jumlah data yang diproses.
- Pernyataan bahasa definisi data (DDL), kecuali untuk perintah CREATE STATISTICS, karena memproses data yang diambil dari penyimpanan berdasarkan persentase sampel yang ditentukan.
- Kueri khusus metadata.
Mengurangi jumlah data yang diproses
Anda dapat mengoptimalkan jumlah data per kueri yang diproses dan meningkatkan performa dengan mempartisi dan mengonversi data Anda ke format berbasis kolom terkompresi seperti Parquet.
Contoh
Bayangkan tiga tabel.
- Tabel population_csv didukung oleh 5 TB file CSV. File diatur dalam lima kolom berukuran sama.
- Tabel population_parquet memiliki data yang sama dengan tabel population_csv. Ini didukung oleh sejumlah 1 TB file Parquet. Tabel ini lebih kecil dari yang sebelumnya karena data dikompresi dalam format Parquet.
- Tabel very_small_csv didukung oleh 100 KB file CSV.
Kueri 1: SELECT SUM(populasi) DARI population_csv
Kueri ini membaca dan mengurai seluruh file untuk mendapatkan nilai untuk kolom populasi. Simpul memproses fragmen tabel ini, dan jumlah populasi untuk setiap fragmen ditransfer di antara simpul. Jumlah akhir ditransfer ke endpoint Anda.
Kueri ini memproses 5 TB data ditambah sejumlah kecil overhead untuk mentransfer jumlah fragmen.
Kueri 2: SELECT SUM(populasi) FROM population_parquet
Saat Anda mengkueri format terkompresi dan berbasis kolom seperti Parquet, lebih sedikit data yang dibaca daripada di kueri 1. Anda melihat hasil ini karena kumpulan SQL tanpa server membaca satu kolom terkompresi alih-alih seluruh file. Dalam hal ini, 0,2 TB telah dibaca. (Lima kolom berukuran sama masing-masing 0,2 TB.) Simpul memproses fragmen tabel ini, dan jumlah populasi untuk setiap fragmen ditransfer di antara simpul. Jumlah akhir ditransfer ke endpoint Anda.
Kueri ini memproses 0,2 TB ditambah sedikit overhead untuk mentransfer total fragmen.
Kueri 3: SELECT * FROM population_parquet
Kueri ini membaca semua kolom dan mentransfer semua data dalam format yang tidak dikompresi. Jika format kompresi adalah 5:1, maka kueri memproses 6 TB karena membaca 1 TB dan mentransfer 5 TB data yang tidak dikompresi.
Kueri 4: PILIH COUNT(*) DARI very_small_csv
Kueri ini membaca seluruh file. Ukuran total file dalam penyimpanan untuk tabel ini adalah 100 KB. Simpul memproses fragmen tabel ini, dan jumlah untuk setiap fragmen ditransfer di antara simpul. Jumlah akhir ditransfer ke endpoint Anda.
Kueri ini memproses sedikit lebih dari 100 KB data. Jumlah data yang diproses untuk kueri ini dibulatkan hingga 10 MB, seperti yang ditentukan di bagian Pembulatan artikel ini.
Pengendalian biaya
Fitur kontrol biaya di kumpulan SQL tanpa server memungkinkan Anda mengatur anggaran untuk jumlah data yang diproses. Anda dapat mengatur anggaran dalam TB data yang diproses selama sehari, minggu, dan bulan. Pada saat yang sama Anda dapat memiliki satu atau beberapa anggaran yang ditetapkan. Untuk mengonfigurasi kontrol biaya untuk kumpulan SQL tanpa server, Anda dapat menggunakan Synapse Studio atau T-SQL.
Mengonfigurasi kontrol biaya untuk kumpulan SQL tanpa server di Synapse Studio
Untuk mengonfigurasi kontrol biaya untuk kumpulan SQL tanpa server di Synapse Studio, navigasikan ke Kelola item di menu di sebelah kiri, daripada memilih item kumpulan SQL di bawah Kumpulan analitik. Saat Anda mengarahkan kursor ke kumpulan SQL tanpa server, Anda akan melihat ikon untuk kontrol biaya - klik ikon ini.
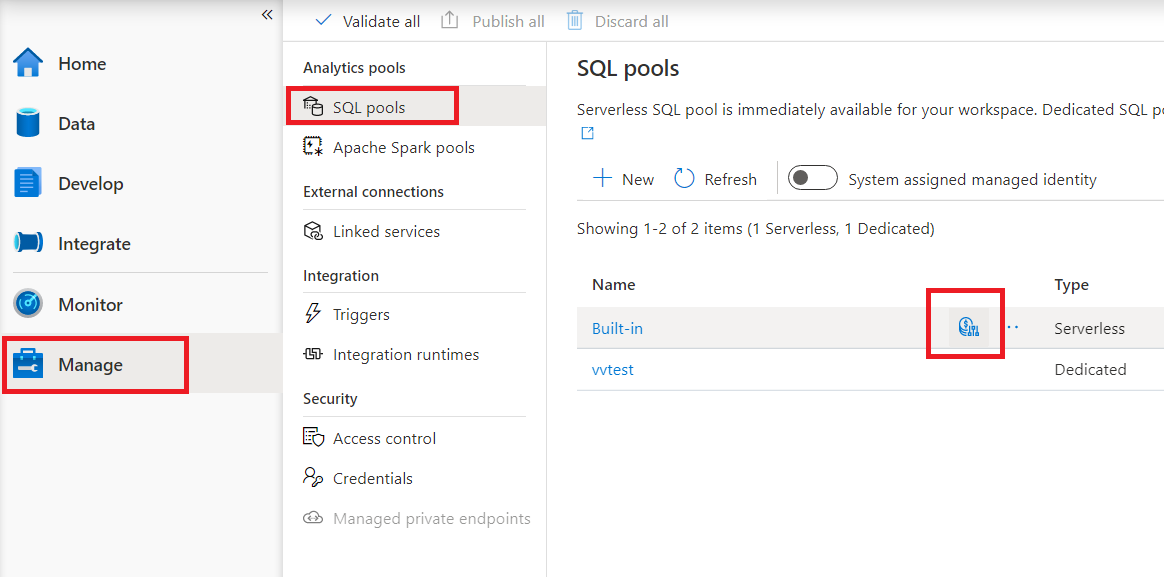
Setelah Anda mengeklik ikon kontrol biaya, bilah samping akan muncul:
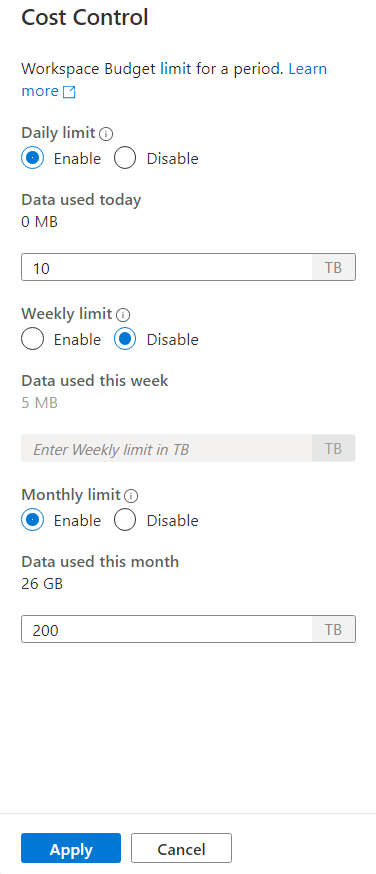
Untuk mengatur satu atau beberapa anggaran, pertama-tama klik tombol Aktifkan radio untuk anggaran yang ingin Anda atur, daripada masukkan nilai bilangan bulat di kotak teks. Unit untuk nilainya adalah TB. Setelah mengonfigurasi anggaran yang ingin Anda klik tombol terapkan di bagian bawah bilah samping. Itu saja, anggaran Anda sekarang ditetapkan.
Mengonfigurasi kontrol biaya untuk kumpulan SQL tanpa server di T-SQL
Untuk mengonfigurasi kontrol biaya untuk kumpulan SQL tanpa server di T-SQL, Anda perlu menjalankan satu atau beberapa prosedur tersimpan berikut.
sp_set_data_processed_limit
@type = N'daily',
@limit_tb = 1
sp_set_data_processed_limit
@type= N'weekly',
@limit_tb = 2
sp_set_data_processed_limit
@type= N'monthly',
@limit_tb = 3334
Untuk melihat konfigurasi saat ini, jalankan pernyataan T-SQL berikut:
SELECT * FROM sys.configurations
WHERE name like 'Data processed %';
Untuk melihat berapa banyak data yang diproses selama hari, minggu, atau bulan saat ini, jalankan pernyataan T-SQL berikut:
SELECT * FROM sys.dm_external_data_processed
Melebihi batas yang ditentukan dalam kontrol biaya
Jika batas apa pun terlampaui selama eksekusi kueri, kueri tidak akan dihentikan.
Ketika batas terlampaui, kueri baru akan ditolak dengan pesan kesalahan yang berisi detail mengenai periode, batas yang ditentukan untuk periode tersebut dan data yang diproses untuk periode tersebut. Misalnya, jika kueri baru dijalankan, di mana batas mingguan diatur ke 1 TB dan terlampaui, pesan kesalahan akan menjadi:
Query is rejected because SQL Serverless budget limit for a period is exceeded. (Period = Weekly: Limit = 1 TB, Data processed = 1 TB))
Langkah berikutnya
Untuk mempelajari cara mengoptimalkan kueri Anda untuk performa, lihat Praktik terbaik untuk kumpulan SQL tanpa server.