Opsi konfigurasi untuk meminimalkan latensi jaringan dengan aplikasi SAP
Penting
Pada bulan November 2021, kami membuat perubahan signifikan dalam bagaimana grup penempatan kedekatan harus digunakan dengan beban kerja SAP dalam penyebaran zona.
Aplikasi SAP berdasarkan arsitektur SAP NetWeaver atau SAP S/4HANA sensitif terhadap latensi jaringan antara tingkat aplikasi SAP dan tingkat database SAP. Sensitivitas ini adalah hasil dari sebagian besar logika bisnis yang berjalan di lapisan aplikasi. Karena lapisan aplikasi SAP menjalankan logika bisnis, lapisan aplikasi tersebut mengeluarkan kueri ke tingkat database pada frekuensi tinggi, dengan kecepatan ribuan atau puluhan ribu per detik. Dalam kebanyakan kasus, kueri ini bersifat sederhana. Kueri sering dapat dijalankan pada tingkat database dalam 500 mikrodetik atau kurang.
Waktu yang dihabiskan di jaringan untuk mengirim kueri seperti itu dari tingkat aplikasi ke tingkat database dan menerima hasil yang dikirim kembali memiliki dampak besar pada waktu yang dibutuhkan untuk menjalankan proses bisnis. Karena sensitivitas terhadap latensi jaringan inilah, Anda mungkin ingin mencapai latensi jaringan minimum tertentu dalam proyek penyebaran SAP. Lihat Catatan SAP #1100926 - Tanya Jawab Umum: Performa jaringan untuk panduan tentang cara mengklasifikasikan latensi jaringan.
Di banyak wilayah Azure, jumlah pusat data telah bertambah. Pada saat yang sama, pelanggan, terutama untuk sistem SAP kelas atas, menggunakan keluarga VM yang lebih khusus seperti keluarga Mv2 atau Mv3 dan yang lebih baru. Jenis komputer virtual Azure ini tidak selalu tersedia di setiap pusat data yang dikumpulkan ke wilayah Azure. Fakta-fakta ini dapat menciptakan peluang untuk mengoptimalkan latensi jaringan antara lapisan aplikasi SAP dan lapisan DBMS SAP.
Azure menyediakan opsi penyebaran yang berbeda untuk beban kerja SAP. Untuk jenis penyebaran yang dipilih, Anda memiliki opsi untuk mengoptimalkan latensi jaringan, jika diperlukan. Informasi terperinci tentang setiap opsi dijelaskan secara menyeluruh di bagian berikut dalam artikel ini:
Grup Penempatan Kedekatan
Grup penempatan kedekatan memungkinkan pengelompokan jenis VM yang berbeda di bawah satu tulang belakang jaringan, memastikan latensi jaringan rendah yang optimal di antara mereka. Ketika VM pertama disebarkan dalam grup penempatan kedekatan, VM tersebut terikat ke tulang belakang jaringan tertentu. Seperti semua VM lain yang akan disebarkan ke dalam grup penempatan kedekatan yang sama, VM tersebut dikelompokkan di bawah spine jaringan yang sama. Meskipun prospek ini terdengar menarik, penggunaan konstruksi juga memperkenalkan beberapa batasan dan perangkap:
- Anda tidak dapat berasumsi bahwa semua jenis mesin virtual Azure tersedia di setiap dan seluruh pusat data Azure atau berada di bawah setiap dan seluruh spine jaringan. Akibatnya, kombinasi berbagai jenis VM dalam satu grup penempatan kedekatan dapat sangat dibatasi. Pembatasan ini terjadi karena perangkat keras host yang diperlukan untuk menjalankan jenis VM tertentu mungkin tidak ada di pusat data atau di bawah spine jaringan tempat grup penempatan kedekatan ditetapkan
- Ketika Anda mengubah ukuran bagian mesin virtual yang berada dalam satu grup penempatan terdekat, Anda tidak dapat secara otomatis berasumsi terhadap semua kasus di mana jenis mesin virtual baru tersedia di pusat data yang sama atau di bawah spine jaringan yang ditugaskan pada grup penempatan
- Saat Azure menonaktifkan perangkat keras, perangkat keras ini mungkin memaksa VM tertentu dari grup penempatan kedekatan ke pusat data Azure lain atau spine jaringan lain. Untuk detail yang mencakup kasus ini, baca dokumen Gup penempatan kedekatan
Penting
Sebagai hasil dari potensi pembatasan, grup penempatan kedekatan harus hanya digunakan:
- Bila perlu dalam skenario tertentu (lihat nanti)
- Ketika latensi jaringan antara lapisan aplikasi dan lapisan DBMS terlalu tinggi dan berdampak pada beban kerja
- Hanya pada granuralitas sistem SAP tunggal dan bukan untuk keseluruhan lanskap sistem atau lanskap SAP lengkap
- Agar meminimalkan berbagai jenis VM dan jumlah VM dalam grup penempatan kedekatan
Skenario di mana grup penempatan kedekatan dapat digunakan untuk mengoptimalkan latensi jaringan:
- Anda ingin menyebarkan sumber daya penting beban kerja SAP Anda di berbagai zona ketersediaan dan di sisi lain memerlukan VM tingkat aplikasi untuk tersebar di berbagai domain kesalahan dengan menggunakan set ketersediaan di setiap zona. Dalam hal ini, seperti yang dijelaskan kemudian dalam dokumen, grup penempatan kedekatan adalah lem yang diperlukan.
- Anda menyebarkan beban kerja SAP dengan set ketersediaan. Di mana tingkat database SAP, tingkat aplikasi SAP dan VM ASCS/SCS dikelompokkan dalam tiga set ketersediaan yang berbeda. Dalam kasus seperti itu, Anda ingin memastikan bahwa set ketersediaan tidak tersebar di seluruh wilayah Azure lengkap karena ini bisa, tergantung pada wilayah Azure, mengakibatkan latensi jaringan yang dapat berdampak pada beban kerja SAP secara negatif.
- Anda menggunakan grup penempatan kedekatan untuk mengelompokkan VM bersama-sama untuk mencapai latensi jaringan serendah mungkin antara layanan yang dihosting di VM. Misalnya, latensi dalam zona ketersediaan saja tidak memenuhi persyaratan aplikasi.
Adapun skenario penyebaran #2, di banyak wilayah, terutama wilayah tanpa zona ketersediaan dan sebagian besar wilayah dengan zona ketersediaan, latensi jaringan independen di mana lahan VM dapat diterima. Meskipun ada beberapa wilayah Azure yang tidak dapat memberikan pengalaman yang cukup baik tanpa mengalokasikan tiga set ketersediaan yang berbeda tanpa menggunakan grup penempatan kedekatan.
Apa yang dimaksud grup penempatan kedekatan?
Grup penempatan kedekatan Azure adalah konstruksi yang logis. Saat grup penempatan kedekatan ditentukan, grup penempatan tersebut terikat ke wilayah Azure dan grup sumber daya Azure. Saat VM disebarkan, grup penempatan kedekatan direferensikan oleh:
- VM Azure pertama yang disebarkan di bawah spine jaringan dengan banyak unit komputasi Azure dan latensi jaringan rendah. Spine jaringan seperti tersebut sering kali cocok dengan pusat data Azure tunggal. Anda dapat menganggap mesin virtual pertama sebagai "VM cakupan" yang digunakan ke dalam unit skala komputasi berdasarkan algoritma alokasi Azure yang pada akhirnya dikombinasikan dengan parameter penyebaran.
- Semua VM tersebar berikutnya yang merujuk pada grup penempatan kedekatan akan digunakan di bawah spine jaringan yang sama dengan mesin virtual pertama.
Catatan
Jika tidak ada perangkat keras host yang disebarkan yang dapat menjalankan jenis VM tertentu di bawah tulang belakang jaringan tempat VM pertama ditempatkan, penyebaran jenis VM yang diminta tidak akan berhasil. Anda akan mendapatkan pesan kegagalan alokasi yang menunjukkan bahwa VM tidak dapat didukung dalam perimeter grup penempatan kedekatan.
Untuk mengurangi risiko hal di atas, disarankan untuk menggunakan opsi niat saat membuat grup penempatan kedekatan. Opsi niat memungkinkan Anda untuk mencantumkan jenis VM yang ingin Anda sertakan ke dalam grup penempatan kedekatan. Daftar jenis VM ini akan diambil untuk menemukan pusat data terbaik yang menghosting jenis VM ini. Jika pusat data seperti itu ditemukan, PPG akan dibuat dan tercakup untuk pusat data yang memenuhi persyaratan SKU VM. Jika tidak ada pusat data seperti itu yang ditemukan, pembuatan grup penempatan kedekatan akan gagal. Anda dapat menemukan informasi selengkapnya dalam dokumentasi PPG - Gunakan niat untuk menentukan ukuran VM. Ketahuilah bahwa situasi kapasitas aktual tidak diperhitungkan dalam pemeriksaan yang dipicu oleh opsi niat. Akibatnya, masih mungkin ada kesalahan alokasi yang berakar pada kapasitas yang tidak mencukup yang tersedia.
Satu grup sumber daya Azure dapat memiliki beberapa grup penempatan kedekatan yang ditetapkan untuknya. Tetapi grup penempatan kedekatan hanya dapat ditetapkan ke satu grup sumber daya Azure.
Untuk informasi selengkapnya dan contoh penyebaran grup penempatan kedekatan, lihat dokumentasi yang tersedia.
Grup penempatan kedekatan dengan penyebaran zona
Penting untuk memberikan latensi jaringan yang cukup rendah antara tingkat aplikasi SAP dan tingkat DBMS. Dalam kebanyakan situasi, penyebaran zonal saja memenuhi persyaratan ini. Untuk serangkaian skenario terbatas, penyebaran zonal saja mungkin tidak memenuhi persyaratan latensi aplikasi. Situasi seperti itu memerlukan penempatan VM sedekat mungkin dan memungkinkan latensi jaringan yang cukup rendah, grup penempatan kedekatan Azure dapat didefinisikan untuk sistem SAP tersebut.
Hindari menggabungkan beberapa sistem produksi atau nonproduksi SAP ke dalam satu grup penempatan kedekatan. Hindari bundel sistem SAP karena semakin banyak sistem yang Anda kelompokkan dalam grup penempatan kedekatan, semakin tinggi peluangnya:
- Bahwa Anda memerlukan jenis VM yang tidak tersedia di bawah tulang belakang jaringan tempat grup penempatan kedekatan ditetapkan.
- Sumber daya VM nonmainstream itu, seperti VM Seri M, pada akhirnya dapat tidak terpenuhi ketika Anda perlu memperluas jumlah VM ke dalam grup penempatan kedekatan dari waktu ke waktu.
Berdasarkan banyak peningkatan yang disebarkan oleh Microsoft ke wilayah Azure untuk mengurangi latensi jaringan dalam zona ketersediaan Azure, panduan penyebaran saat menggunakan grup penempatan kedekatan untuk penyebaran zona, terlihat seperti:
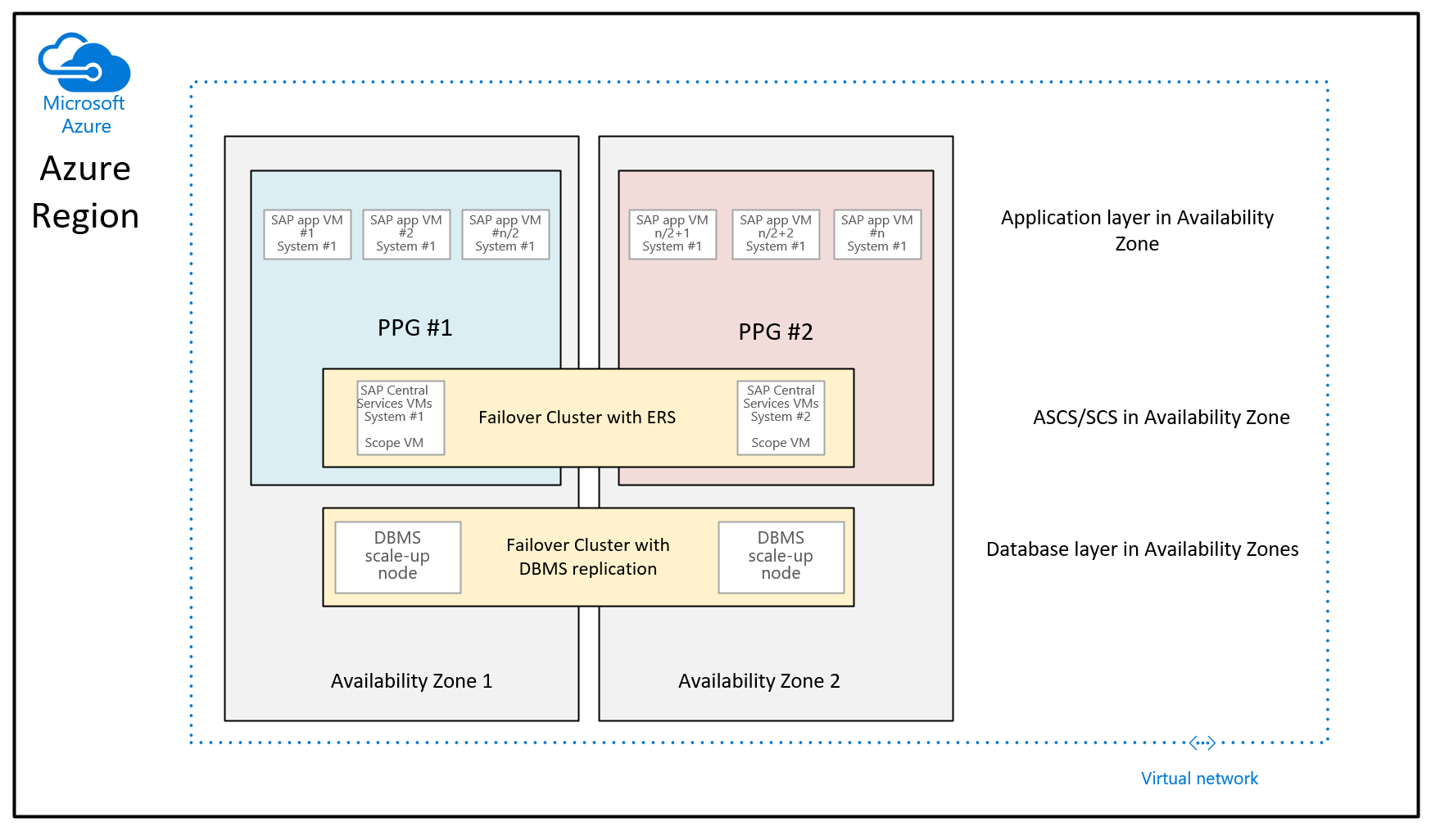
Perbedaan rekomendasi yang diberikan sejauh ini adalah bahwa VM database di dua zona tidak lagi menjadi bagian dari grup penempatan kedekatan. Grup penempatan kedekatan per zona sekarang dicakup dengan penyebaran VM yang menjalankan instans SAP ASCS/SCS. Ini juga berarti bahwa untuk wilayah tempat zona ketersediaan dikumpulkan oleh beberapa pusat data, instans ASCS/SCS, dan tingkat aplikasi dapat berjalan di bawah satu tulang belakang jaringan dan VM database dapat berjalan di bawah tulang belakang jaringan lain. Meskipun dengan perbaikan jaringan yang dilakukan, latensi jaringan antara tingkat aplikasi SAP dan tingkat DBMS masih harus cukup untuk kinerja dan throughput yang cukup baik. Keuntungan dari konfigurasi baru ini adalah Anda lebih fleksibel dalam mengubah ukuran VM atau beralih ke jenis VM baru dengan lapisan DBMS atau/dan lapisan aplikasi sistem SAP.
Untuk kasus khusus penggunaan Azure NetApp Files untuk lingkungan DBMS dan fungsionalitas terkait Azure NetApp Files dari grup volume aplikasi Azure NetApp Files untuk SAP Hana dan kebutuhannya untuk grup penempatan kedekatan, periksa dokumen volume NFS v4.1 di Azure NetApp Files untuk SAP Hana.
Grup penempatan kedekatan dengan penyebaran set ketersediaan
Dalam hal ini, tujuannya adalah untuk menggunakan grup penempatan kedekatan untuk mengolokasikan VM yang digunakan melalui set ketersediaan yang berbeda. Dalam skenario penggunaan ini, Anda tidak menggunakan penyebaran terkontrol di berbagai zona ketersediaan di suatu wilayah. Sebagai gantinya, Anda perlu menerapkan sistem SAP dengan menggunakan set ketersediaan. Akibatnya, Anda memiliki setidaknya satu set ketersediaan untuk VM DBMS, VM ASCS/SCS, dan VM tingkat aplikasi. Karena Anda tidak dapat menentukan pada waktu penyebaran VM set ketersediaan DAN zona ketersediaan, Anda tidak dapat mengontrol di mana VM di set ketersediaan yang berbeda akan dialokasikan. Hal ini dapat mengakibatkan beberapa wilayah Azure di mana latensi jaringan antara VM yang berbeda masih terlalu tinggi untuk memberikan pengalaman performa yang cukup baik. Jadi, arsitektur yang dihasilkan akan terlihat seperti:
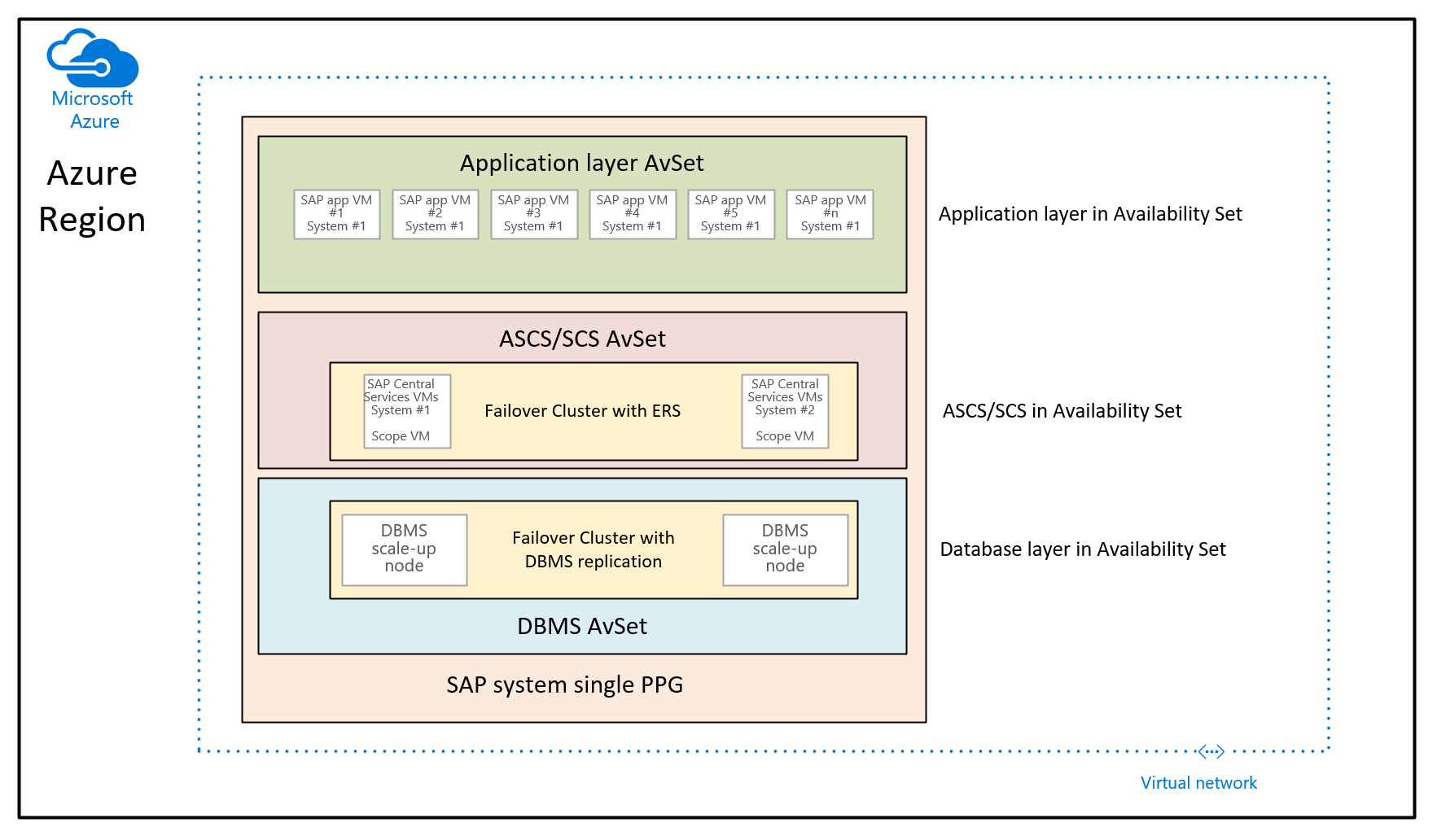
Dalam grafik ini, grup penempatan kedekatan tunggal akan ditugaskan ke satu sistem SAP. PPG ini ditetapkan ke tiga set ketersediaan. Grup penempatan kedekatan kemudian dibatasi dengan menyebarkan VM tingkat database pertama ke dalam set ketersediaan DBMS. Rekomendasi arsitektur ini mengalokasikan semua VM di bawah tulang belakang jaringan yang sama. Ini memperkenalkan pembatasan yang disebutkan sebelumnya dalam artikel ini. Oleh karena itu, arsitektur grup penempatan kedekatan sebaiknya jarang digunakan.
Menggabungkan set ketersediaan dan zona ketersediaan dengan grup penempatan kedekatan
Salah satu masalah dalam menggunakan zona ketersediaan untuk penyebaran sistem SAP adalah Anda tidak dapat menyebarkan tingkat aplikasi SAP dengan menggunakan set ketersediaan dalam zona ketersediaan tertentu. Anda ingin tingkat aplikasi SAP disebarkan di zona yang sama dengan VM SAP ASCS/SCS. Mereferensikan zona ketersediaan dan set ketersediaan saat menyebarkan satu VM sejauh ini tidak dimungkinkan. Tetapi hanya menyebarkan VM yang menginstruksikan zona ketersediaan, Anda kehilangan kemampuan untuk memastikan VM lapisan aplikasi tersebar di berbagai domain pembaruan dan kegagalan.
Menggunakan grup penempatan kedekatan, Anda dapat melewati batasan ini. Berikut urutan penyebarannya:
- Buat grup penempatan kedekatan.
- Sebarkan VM jangkar Anda, disarankan menjadi VM ASCS/SCS, dengan mereferensikan zona ketersediaan.
- Buat set ketersediaan yang mereferensikan grup penempatan kedekatan Azure. (Lihat perintahnya nanti di artikel ini.)
- Sebarkan VM lapisan aplikasi dengan mereferensikan pada kumpulan ketersediaan dan grup penempatan kedekatan.
Penting
Penting untuk dipahami bahwa disk VM lapisan aplikasi tidak dijamin dialokasikan di zona ketersediaan yang sama dengan VM diarahkan untuk menggunakan grup penempatan kedekatan. Hasil penyebaran yang ditunjukkan pada langkah berikutnya mungkin VM dialokasikan di tulang belakang jaringan yang sama dan dengan zona ketersediaan yang sama dengan VM jangkar. Tetapi disk respctive (VHD dasar dan disk penyimpanan blok Azure yang dipasang) mungkin tidak dialokasikan di bawah tulang belakang jaringan yang sama atau bahkan zona ketersediaan yang sama. Sebagai gantinya, disk VM tersebut dapat dialokasikan di salah satu pusat data wilayah tertentu. Meskipun disk VM jangkar yang disebarkan dengan menentukan zona akan disebarkan di zona yang sama dengan VM yang disebarkan.
Alih-alih menyebarkan VM pertama seperti yang ditunjukkan di bagian sebelumnya, Anda mereferensikan zona ketersediaan dan grup penempatan kedekatan saat Anda menyebarkan VM:
New-AzVm -ResourceGroupName "ppgexercise" -Name "centralserviceszone1" -Location "westus2" -OpenPorts 80,3389 -Zone "1" -ProximityPlacementGroup "collocate" -Size "Standard_E8s_v4"
Penyebaran komputer virtual ini yang berhasil akan menghosting instans ASCS/SCS sistem SAP dalam satu zona ketersediaan. Dalam hal ini, VM dan VHD dasar VM dan disk penyimpanan blok Azure yang berpotensi dipasang dialokasikan dalam zona ketersediaan yang sama. Cakupan grup penempatan kedekatan diperbaiki ke salah satu duri jaringan di zona ketersediaan yang Anda tentukan.
Pada langkah berikutnya, Anda perlu membuat kumpulan ketersediaan yang ingin Anda gunakan untuk lapisan aplikasi sistem SAP Anda.
Tentukan dan buat grup penempatan kedekatan. Perintah untuk membuat kumpulan ketersediaan memerlukan referensi tambahan ke ID grup penempatan kedekatan (bukan nama). Anda bisa mendapatkan ID grup penempatan kedekatan menggunakan perintah ini:
Get-AzProximityPlacementGroup -ResourceGroupName "ppgexercise" -Name "collocate"
Saat membuat kumpulan ketersediaan, Anda perlu mempertimbangkan parameter tambahan saat menggunakan disk terkelola (default kecuali ditentukan lain) dan grup penempatan kedekatan:
New-AzAvailabilitySet -ResourceGroupName "ppgexercise" -Name "ppgavset" -Location "westus2" -ProximityPlacementGroupId "/subscriptions/my very long ppg id string" -sku "aligned" -PlatformUpdateDomainCount 3 -PlatformFaultDomainCount 2
Idealnya, Anda harus menggunakan tiga domain kesalahan. Tetapi jumlah domain kesalahan yang didukung dapat bervariasi dari satu wilayah ke wilayah lainnya. Jika ini terjadi, jumlah maksimum domain kesalahan yang mungkin untuk wilayah tertentu adalah dua. Untuk menyebarkan VM lapisan aplikasi, Anda perlu menambahkan referensi ke nama kumpulan ketersediaan dan nama grup penempatan kedekatan Anda, seperti yang ditunjukkan di sini:
New-AzVm -ResourceGroupName "ppgexercise" -Name "appinstance1" -Location "westus2" -OpenPorts 80,3389 -AvailabilitySetName "myppgavset" -ProximityPlacementGroup "collocate" -Size "Standard_E16s_v4"
Catatan
Disk VM yang disebarkan ke dalam set ketersediaan di atas tidak dipaksa untuk dialokasikan di zona ketersediaan yang sama dengan VM. Meskipun Anda mencapai bahwa VM lapisan aplikasi tersebar di berbagai domain kesalahan di bawah tulang belakang jaringan yang sama dengan VM jangkar dialokasikan, disk, meskipun juga dialokasikan di domain kesalahan yang berbeda dapat dialokasikan di lokasi yang berbeda pada cakupan luas wilayah.
Hasil dari penyebaran ini adalah:
- Layanan Pusat untuk sistem SAP Anda yang terletak di zona ketersediaan tertentu.
- Lapisan aplikasi SAP yang ditemukan melalui set ketersediaan di spine jaringan yang sama dengan satu atau beberapa VM layanan SAP Central (ASCS/SCS).
Catatan
Karena Anda menyebarkan satu VM DBMS dan ASCS/SCS ke dalam satu zona dan VM DBMS dan ASCS/SCS kedua ke zona lain untuk membuat konfigurasi ketersediaan tinggi, Anda memerlukan grup penempatan kedekatan yang berbeda untuk setiap zona. Hal yang sama berlaku untuk setiap kumpulan ketersediaan yang Anda gunakan.
Mengubah konfigurasi grup penempatan kedekatan dari sistem yang sudah ada
Jika Anda menerapkan grup penempatan kedekatan sebagai rekomendasi yang diberikan sejauh ini, dan Anda ingin menyesuaikan dengan konfigurasi baru, Anda dapat melakukannya dengan metode yang dijelaskan dalam artikel ini:
- Sebarkan VM ke grup penempatan kedekatan menggunakan Azure CLI.
- Sebarkan VM ke grup penempatan kedekatan menggunakan PowerShell.
Anda juga dapat menggunakan perintah ini untuk kasus di mana Anda mendapatkan kesalahan alokasi dalam kasus di mana Anda tidak dapat berpindah ke jenis VM baru dengan VM yang ada di grup penempatan kedekatan.
Set Skala Komputer Virtual dengan orkestrasi Fleksibel
Untuk menghindari keterbatasan yang terkait dengan grup penempatan kedekatan, disarankan untuk menyebarkan beban kerja SAP di seluruh zona ketersediaan menggunakan set skala fleksibel dengan FD=1. Strategi penyebaran ini memastikan bahwa VM yang disebarkan di setiap zona tidak dibatasi untuk satu pusat data atau tulang belakang jaringan, dan semua komponen sistem SAP, seperti database, ASCS/ERS, dan tingkat aplikasi tercakup dalam zona. Dengan semua komponen sistem SAP yang dilingkup pada tingkat zonal, latensi jaringan antara komponen yang berbeda dari satu sistem SAP harus cukup untuk memastikan performa dan throughput yang memuaskan. Manfaat utama dari opsi penyebaran baru ini dengan set skala fleksibel dengan FD=1 adalah memberikan fleksibilitas yang lebih besar dalam mengubah ukuran VM atau beralih ke jenis VM baru untuk semua lapisan sistem SAP. Selain itu, set skala akan mengalokasikan VM di beberapa domain kesalahan dalam satu zona, yang ideal untuk menjalankan beberapa VM tingkat aplikasi di setiap zona. Untuk informasi selengkapnya, lihat set skala komputer virtual untuk dokumen beban kerja SAP.

Dalam lingkungan nonproduksi atau non-HA, dimungkinkan untuk menyebarkan semua komponen sistem SAP, termasuk database, ASCS, dan tingkat aplikasi, dalam satu zona menggunakan set skala fleksibel dengan FD=1.
Opsi penyebaran yang direkomendasikan sebelumnya
Bagian ini mencakup detail tentang opsi penyebaran yang direkomendasikan sebelumnya untuk mengoptimalkan latensi jaringan untuk SAP. Dengan fitur baru dan pertumbuhan Azure dari waktu ke waktu, detail dalam bagian ini hanya boleh diterapkan dalam kasus yang jarang terjadi.
Grup penempatan kedekatan untuk seluruh sistem SAP dengan penyebaran zona
Penggunaan grup penempatan kedekatan yang kami rekomendasikan sejauh ini, terlihat seperti dalam grafik ini.

Anda membuat grup penempatan kedekatan (PPG) di masing-masing dari dua zona ketersediaan tempat Anda menyebarkan sistem SAP. Semua VM dari zona tertentu adalah bagian dari grup penempatan kedekatan individu dari zona tertentu tersebut. Anda mulai di setiap zona dengan menyebarkan DBMS VM untuk mencakup PPG dan kemudian menyebarkan ASCS VM ke zona dan PPG yang sama. Pada langkah ketiga, Anda membuat set ketersediaan Azure, menetapkan ketersediaan yang diatur ke PPG tercakup dan menyebarkan lapisan aplikasi SAP ke dalamnya. Keuntungan dari konfigurasi ini adalah bahwa semua komponen selaras dengan baik di bawah tulang belakang jaringan yang sama. Kerugian besarnya adalah fleksibilitas Anda dalam mengubah ukuran mesin virtual mungkin terbatas.
Berdasarkan banyak peningkatan yang disebarkan oleh Microsoft ke wilayah Azure untuk mengurangi latensi jaringan dalam zona ketersediaan Azure, panduan penyebaran saat ini untuk penyebaran zona dalam artikel ini ada.
Grup penempatan kedekatan dan Instans Besar HANA
Jika beberapa sistem SAP Anda mengandalkan Instans Besar HANA untuk lapisan database, Anda dapat mengalami peningkatan signifikan dalam latensi jaringan antara unit Instans Besar HANA dan VM Azure saat Anda menggunakan unit Instans Besar HANA yang disebarkan dalam baris atau stempel Revisi 4. Salah satu peningkatannya adalah bahwa unit Instans Besar HANA, saat unit tersebut disebarkan, sebarkan dengan grup penempatan kedekatan. Anda dapat menggunakan grup penempatan kedekatan tersebut untuk menyebarkan VM lapisan aplikasi Anda. Akibatnya, VM tersebut akan disebarkan di pusat data yang sama yang menghosting unit Instans Besar HANA Anda.
Untuk menentukan apakah unit Instans Besar HANA Anda disebarkan dalam stempel atau baris Revisi 4, periksa artikel Kontrol Instans Besar HANA Azure melalui portal Azure. Dalam ringkasan atribut unit Instans Besar HANA, Anda juga dapat menentukan nama grup penempatan kedekatan karena grup tersebut dibuat saat unit Instans Besar HANA Anda disebarkan. Nama yang muncul di ringkasan atribut adalah nama grup penempatan kedekatan tempat Anda harus menyebarkan VM lapisan aplikasi Anda.
Dibandingkan dengan sistem SAP yang hanya menggunakan komputer virtual Azure, saat Anda menggunakan Instans Besar HANA, Anda memiliki lebih sedikit fleksibilitas dalam memutuskan berapa banyak grup sumber daya Azure yang akan digunakan. Semua unit Instans Besar HANA dari penyewa Instans Besar HANA dikelompokkan dalam satu grup sumber daya, seperti yang dijelaskan artikel ini. Kecuali jika Anda menyebarkan ke penyewa yang berbeda untuk memisahkan, misalnya, sistem produksi dan non-produksi atau sistem lain, semua unit Instans Besar HANA Anda akan disebarkan di satu penyewa Instans Besar HANA. Penyewa ini memiliki hubungan satu-ke-satu dengan grup sumber daya. Tetapi grup penempatan kedekatan yang terpisah akan ditentukan untuk masing-masing unit tunggal.
Akibatnya, hubungan antara grup sumber daya Azure dan grup penempatan kedekatan untuk satu penyewa akan seperti yang ditunjukkan di sini:

Langkah berikutnya
Lihat dokumentasinya: