Kebijakan jaringan Azure Kubernetes
Kebijakan jaringan menyediakan segmentasi mikro untuk pod seperti Kelompok Keamanan Jaringan (NSG) menyediakan segmentasi mikro untuk VM. Implementasi Azure Network Policy Manager mendukung spesifikasi kebijakan jaringan Kubernetes standar. Anda dapat menggunakan label untuk memilih sekelompok pod dan menentukan daftar aturan ingress dan egress untuk memfilter lalu lintas ke dan dari pod tersebut. Pelajari lebih lanjut kebijakan jaringan Kubernetes dalam dokumentasi Kubernetes.
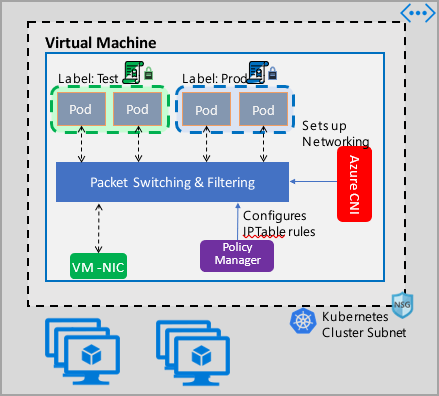
Implementasi Manajemen Kebijakan Jaringan Azure berfungsi dengan Azure CNI yang menyediakan integrasi jaringan virtual untuk kontainer. Pengelola Kebijakan Jaringan didukung di Linux dan Windows Server. Implementasi memberlakukan pemfilteran lalu lintas dengan mengonfigurasi aturan izinkan dan tolak IP berdasarkan kebijakan yang ditentukan di Linux IPTables atau Host Network Service (HNS) ACLPolicies untuk Windows Server.
Merencanakan keamanan untuk kluster Kubernetes
Saat mengimplementasikan keamanan untuk kluster Anda, gunakan kelompok keamanan jaringan (NSG) untuk memfilter lalu lintas yang masuk dan keluar subnet kluster Anda (lalu lintas Utara-Selatan). Gunakan Azure Network Policy Manager untuk lalu lintas antar pod di kluster Anda (lalu lintas Timur-Barat).
Menggunakan Azure Network Policy Manager
Azure Network Policy Manager dapat digunakan dengan cara berikut untuk menyediakan segmentasi mikro untuk pod.
Azure Kubernetes Service (AKS)
Pengelola Kebijakan Jaringan tersedia secara asli di AKS dan dapat diaktifkan pada saat pembuatan kluster.
Pelajari selengkapnya mengenai ini di Mengamankan traffic antara pod menggunakan kebijakan jaringan di Azure Kubernetes Service (AKS).
Lakukan sendiri/Do it yourself (DIY) kluster Kubernetes di Azure
Untuk kluster DIY, pertama-tama instal plug-in CNI dan aktifkan pada setiap komputer virtual dalam kluster. Untuk petunjuk terperinci, lihat Menyebarkan plug-in untuk kluster Kubernetes yang Anda terapkan sendiri.
Setelah kluster disebarkan, jalankan perintah berikut kubectl untuk mengunduh dan menerapkan daemon Azure Network Policy Manager yang diatur ke kluster.
Untuk Linux:
kubectl apply -f https://raw.githubusercontent.com/Azure/azure-container-networking/master/npm/azure-npm.yaml
Untuk Windows:
kubectl apply -f https://raw.githubusercontent.com/Azure/azure-container-networking/master/npm/examples/windows/azure-npm.yaml
Solusinya juga berupa sumber terbuka dan kodenya tersedia di repositori Azure Container Networking.
Memantau dan memvisualisasikan konfigurasi jaringan dengan Azure NPM
Azure Network Policy Manager menyertakan metrik Prometheus informatif yang memungkinkan Anda memantau dan lebih memahami konfigurasi Anda. Ini menyediakan visualisasi bawaan di portal Microsoft Azure atau Grafana Labs. Anda dapat mulai mengumpulkan metrik ini menggunakan Azure Monitor atau server Prometheus.
Manfaat metrik Azure Network Policy Manager
Pengguna sebelumnya hanya dapat mempelajari tentang konfigurasi jaringan mereka dengan iptables dan ipset perintah berjalan di dalam node kluster, yang menghasilkan verbose dan sulit untuk memahami output.
Secara keseluruhan, metrik menyediakan:
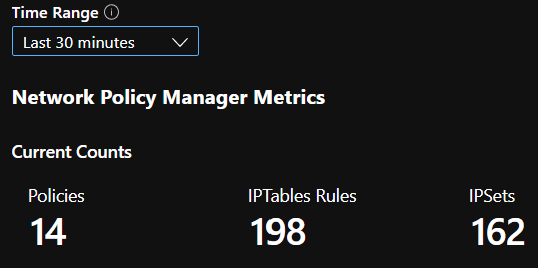
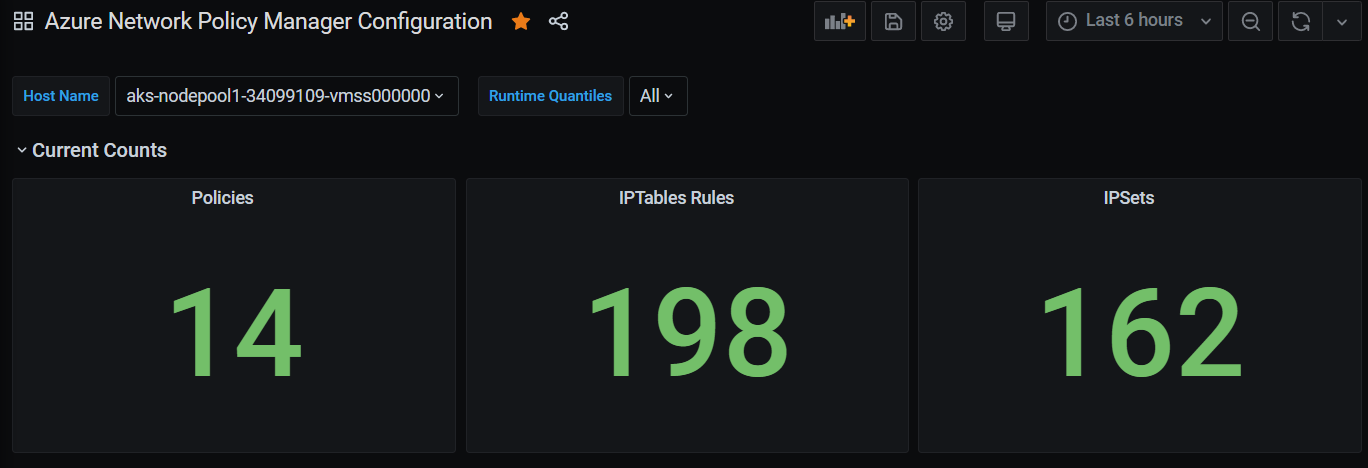
Jumlah kebijakan, aturan ACL, ipset, entri ipset, dan entri dalam ipset tertentu
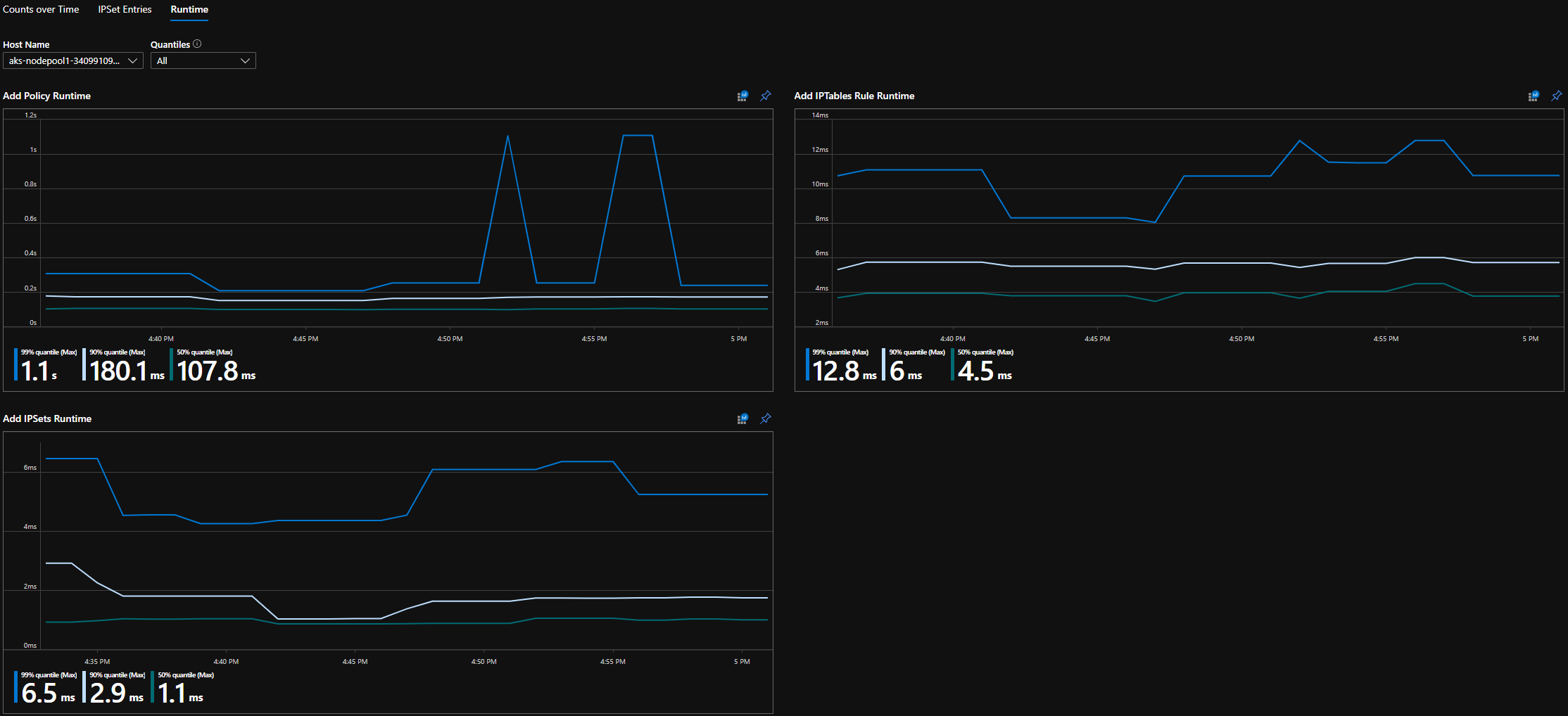
Waktu eksekusi untuk panggilan OS individual dan untuk menangani peristiwa sumber daya kubernetes (median, persentil ke-90, dan persentil ke-99)
Info kegagalan untuk menangani peristiwa sumber daya kubernetes (peristiwa sumber daya ini gagal ketika panggilan OS gagal)
Contoh kasus penggunaan metrik
Pemberitahuan melalui AlertManager Prometheus
Lihat konfigurasi untuk pemberitahuan ini sebagai berikut.
Pemberitahuan saat Pengelola Kebijakan Jaringan mengalami kegagalan dengan panggilan OS atau saat menerjemahkan kebijakan jaringan.
Pemberitahuan ketika waktu median untuk menerapkan perubahan untuk peristiwa buat lebih dari 100 milidetik.
Visualisasi dan penelusuran kesalahan melalui dasbor Grafana atau buku kerja Azure Monitor kami
Lihat berapa banyak aturan IPTable yang dibuat kebijakan Anda (memiliki sejumlah besar aturan IPTables dapat sedikit meningkatkan latensi).
Menghubungkan jumlah kluster (misalnya ACL) ke waktu eksekusi.
Dapatkan nama ipset yang ramah manusia dalam aturan IPTables tertentu (misalnya,
azure-npm-487392mewakilipodlabel-role:database).
Semua metrik yang didukung
Daftar berikut adalah metrik yang didukung. Label quantile apa pun memiliki nilai 0.5, 0.9, dan 0.99 yang memungkinkan. Label had_error apa pun memiliki kemungkinan nilai false dan true, yang merepresentasikan apakah operasi berhasil atau gagal.
| Nama Metrik | Deskripsi | Tipe Metrik Prometheus | Label |
|---|---|---|---|
npm_num_policies |
jumlah kebijakan jaringan | Pengukur | - |
npm_num_iptables_rules |
jumlah aturan IPTable | Pengukur | - |
npm_num_ipsets |
jumlah IPSet | Pengukur | - |
npm_num_ipset_entries |
jumlah entri alamat IP di semua IPSet | Pengukur | - |
npm_add_iptables_rule_exec_time |
runtime untuk menambahkan aturan IPTable | Ringkasan | quantile |
npm_add_ipset_exec_time |
runtime untuk menambahkan IPSet | Ringkasan | quantile |
npm_ipset_counts (tingkat lanjut) |
jumlah entri dalam setiap IPSet individu | GaugeVec | set_name & set_hash |
npm_add_policy_exec_time |
runtime untuk menambahkan kebijakan jaringan | Ringkasan | quantile & had_error |
npm_controller_policy_exec_time |
runtime untuk memperbarui/menghapus kebijakan jaringan | Ringkasan | quantile & had_error ( operation dengan nilai update atau delete) |
npm_controller_namespace_exec_time |
runtime untuk membuat/memperbarui/menghapus namespace | Ringkasan | quantile & had_error & operation (dengan nilai create, update, atau delete) |
npm_controller_pod_exec_time |
runtime untuk membuat/memperbarui/menghapus pod | Ringkasan | quantile & had_error & operation (dengan nilai create, update, atau delete) |
Terdapat juga metrik "exec_time_count" dan "exec_time_sum" untuk setiap metrik Ringkasan "exec_time".
Metrik dapat diekstraksi melalui Azure Monitor untuk kontainer atau melalui Prometheus.
Menyiapkan Azure Monitor
Langkah pertama adalah mengaktifkan Azure Monitor untuk kontainer untuk kluster Kubernetes Anda. Langkah-langkahnya dapat ditemukan di Ringkasan Azure Monitor untuk kontainer. Setelah Anda mengaktifkan Azure Monitor untuk kontainer, konfigurasikan Azure Monitor untuk kontainer ConfigMap untuk mengaktifkan integrasi Pengelola Kebijakan Jaringan dan pengumpulan metrik Prometheus Network Policy Manager.
Azure Monitor untuk kontainer ConfigMap memiliki integrations bagian dengan pengaturan untuk mengumpulkan metrik Pengelola Kebijakan Jaringan.
Pengaturan ini dinonaktifkan secara default di dalam ConfigMap. Mengaktifkan pengaturan collect_basic_metrics = truedasar , mengumpulkan metrik Pengelola Kebijakan Jaringan dasar. Pengaktifan pengaturan collect_advanced_metrics = true tingkat lanjut mengumpulkan metrik tingkat lanjut selain metrik dasar.
Setelah mengedit ConfigMap, simpan secara lokal dan terapkan ConfigMap ke kluster Anda sebagai berikut.
kubectl apply -f container-azm-ms-agentconfig.yaml
Cuplikan berikut berasal dari Azure Monitor untuk kontainer ConfigMap, yang menunjukkan integrasi Pengelola Kebijakan Jaringan yang diaktifkan dengan kumpulan metrik tingkat lanjut.
integrations: |-
[integrations.azure_network_policy_manager]
collect_basic_metrics = false
collect_advanced_metrics = true
Metrik tingkat lanjut bersifat opsional, dan mengaktifkannya secara otomatis mengaktifkan pengumpulan metrik dasar. Metrik tingkat lanjut saat ini hanya Network Policy Manager_ipset_countsmenyertakan .
Pelajari selengkapnya tentang Azure Monitor untuk pengaturan pengumpulan kontainer di peta konfigurasi.
Opsi visualisasi untuk Azure Monitor
Setelah pengumpulan metrik Network Policy Manager diaktifkan, Anda dapat melihat metrik di portal Azure menggunakan wawasan kontainer atau di Grafana.
Menampilkan di portal Azure di bawah wawasan untuk kluster
Buka portal Azure. Setelah berada dalam wawasan kluster Anda, navigasikan ke Buku Kerja dan buka Konfigurasi Manajer Kebijakan Jaringan (Pengelola Kebijakan Jaringan).
Selain menampilkan buku kerja, Anda juga bisa langsung mengkueri metrik Prometheus di "Log" di bawah bagian wawasan. Misalnya, kueri ini mengembalikan semua metrik yang dikumpulkan.
| where TimeGenerated > ago(5h)
| where Name contains "npm_"
Anda juga dapat mengkueri analitik log secara langsung untuk metrik. Untuk informasi selengkapnya, lihat Memulai Kueri Analitik Log.
Menampilkan di dasbor Grafana
Siapkan Grafana Server Anda dan konfigurasikan sumber data analitik log seperti yang dijelaskan di sini. Kemudian, impor Dasbor Grafana dengan backend Log Analytics ke Grafana Labs Anda.
Dasbor memiliki tampilan yang mirip dengan Buku Kerja Azure. Anda dapat menambahkan panel ke bagan & memvisualisasikan metrik Pengelola Kebijakan Jaringan dari tabel InsightsMetrics.
Menyiapkan untuk server Prometheus
Beberapa pengguna dapat memilih untuk mengumpulkan metrik dengan server Prometheus alih-alih Azure Monitor untuk kontainer. Anda hanya perlu menambahkan dua pekerjaan ke konfigurasi scrape Anda untuk mengumpulkan metrik Pengelola Kebijakan Jaringan.
Untuk menginstal server Prometheus, tambahkan repositori helm ini di kluster Anda:
helm repo add stable https://kubernetes-charts.storage.googleapis.com
helm repo update
lalu tambahkan server
helm install prometheus stable/prometheus -n monitoring \
--set pushgateway.enabled=false,alertmanager.enabled=false, \
--set-file extraScrapeConfigs=prometheus-server-scrape-config.yaml
di mana prometheus-server-scrape-config.yaml terdiri dari:
- job_name: "azure-npm-node-metrics"
metrics_path: /node-metrics
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__]
action: replace
regex: ([^:]+)(?::\d+)?
replacement: "$1:10091"
target_label: __address__
- job_name: "azure-npm-cluster-metrics"
metrics_path: /cluster-metrics
kubernetes_sd_configs:
- role: service
relabel_configs:
- source_labels: [__meta_kubernetes_namespace]
regex: kube-system
action: keep
- source_labels: [__meta_kubernetes_service_name]
regex: npm-metrics-cluster-service
action: keep
# Comment from here to the end to collect advanced metrics: number of entries for each IPSet
metric_relabel_configs:
- source_labels: [__name__]
regex: npm_ipset_counts
action: drop
Anda juga dapat mengganti azure-npm-node-metrics pekerjaan dengan konten berikut atau memasukkannya ke dalam pekerjaan yang sudah ada sebelumnya untuk pod Kubernetes:
- job_name: "azure-npm-node-metrics-from-pod-config"
metrics_path: /node-metrics
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_namespace]
regex: kube-system
action: keep
- source_labels: [__meta_kubernetes_pod_annotationpresent_azure_Network Policy Manager_scrapeable]
action: keep
- source_labels: [__address__]
action: replace
regex: ([^:]+)(?::\d+)?
replacement: "$1:10091"
target_label: __address__
Menyiapkan pemberitahuan untuk AlertManager
Jika Anda menggunakan server Prometheus, Anda dapat menyiapkan AlertManager seperti itu. Berikut adalah contoh konfigurasi untuk dua aturan pemberitahuan yang dijelaskan sebelumnya:
groups:
- name: npm.rules
rules:
# fire when Network Policy Manager has a new failure with an OS call or when translating a Network Policy (suppose there's a scraping interval of 5m)
- alert: AzureNetwork Policy ManagerFailureCreatePolicy
# this expression says to grab the current count minus the count 5 minutes ago, or grab the current count if there was no data 5 minutes ago
expr: (npm_add_policy_exec_time_count{had_error='true'} - (npm_add_policy_exec_time_count{had_error='true'} offset 5m)) or npm_add_policy_exec_time_count{had_error='true'}
labels:
severity: warning
addon: azure-npm
annotations:
summary: "Azure Network Policy Manager failed to handle a policy create event"
description: "Current failure count since Network Policy Manager started: {{ $value }}"
# fire when the median time to apply changes for a pod create event is more than 100 milliseconds.
- alert: AzurenpmHighControllerPodCreateTimeMedian
expr: topk(1, npm_controller_pod_exec_time{operation="create",quantile="0.5",had_error="false"}) > 100.0
labels:
severity: warning
addon: azure-Network Policy Manager
annotations:
summary: "Azure Network Policy Manager controller pod create time median > 100.0 ms"
# could have a simpler description like the one for the alert above,
# but this description includes the number of pod creates that were handled in the past 10 minutes,
# which is the retention period for observations when calculating quantiles for a Prometheus Summary metric
description: "value: [{{ $value }}] and observation count: [{{ printf `(npm_controller_pod_exec_time_count{operation='create',pod='%s',had_error='false'} - (npm_controller_pod_exec_time_count{operation='create',pod='%s',had_error='false'} offset 10m)) or npm_controller_pod_exec_time_count{operation='create',pod='%s',had_error='false'}` $labels.pod $labels.pod $labels.pod | query | first | value }}] for pod: [{{ $labels.pod }}]"
Opsi visualisasi untuk Prometheus
Saat Anda menggunakan Server Prometheus, hanya dasbor Grafana yang didukung.
Jika Anda belum melakukannya, siapkan server Grafana Anda dan konfigurasikan sumber data Prometheus. Kemudian, impor Dasbor Grafana dengan backend Prometheus ke Grafana Labs Anda.
Visual untuk dasbor ini identik dengan dasbor dengan backend wawasan kontainer/analitik log.
Dasbor sampel
Berikut adalah beberapa dasbor sampel untuk metrik Pengelola Kebijakan Jaringan dalam wawasan kontainer (CI) dan Grafana.
Jumlah ringkasan CI
Jumlah CI dari waktu ke waktu

Entri IPSet CI

Kuantil runtime CI
Jumlah ringkasan dasbor Grafana
Jumlah dasbor Grafana dari waktu ke waktu

Entri IPSet dasbor Grafana

Kuantil runtime dasbor Grafana

Langkah berikutnya
Pelajari tentang Azure Kubernetes Service.
Pelajari tentang jaringan kontainer.
Sebarkan plug-in untuk kluster Kubernetes atau kontainer Docker.
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk