Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
ML.NET Model Builder adalah ekstensi Visual Studio grafis intuitif untuk membangun, melatih, dan menyebarkan model pembelajaran mesin kustom. Ini menggunakan pembelajaran mesin otomatis (AutoML) untuk menjelajahi algoritma dan pengaturan pembelajaran mesin yang berbeda untuk membantu Anda menemukan yang paling sesuai dengan skenario Anda.
Anda tidak memerlukan keahlian pembelajaran mesin untuk menggunakan Model Builder. Yang Anda butuhkan hanyalah beberapa data, dan masalah untuk dipecahkan. Model Builder menghasilkan kode untuk menambahkan model ke aplikasi .NET Anda.

Membuat proyek Model Builder
Ketika Anda pertama kali memulai Model Builder, ia meminta Anda untuk memberi nama proyek, lalu membuat mbconfig file konfigurasi di dalam proyek. File mbconfig ini melacak semua yang Anda lakukan di Model Builder untuk memungkinkan Anda membuka kembali sesi.
Setelah pelatihan, tiga file dihasilkan di bawah file *.mbconfig:
- Model.consumption.cs: File ini berisi
ModelInputskema danModelOutputserta fungsi yangPredictdihasilkan untuk mengonsumsi model. - Model.training.cs: File ini berisi alur pelatihan (transformasi data, algoritma, algoritma hiperparameter) yang dipilih oleh Model Builder untuk melatih model. Anda dapat menggunakan alur ini untuk melatih kembali model Anda.
- Model.zip: Ini adalah file zip berseri yang mewakili model ML.NET terlatih Anda.
Saat membuat mbconfig file, Anda akan dimintai nama. Nama ini diterapkan ke file konsumsi, pelatihan, dan model. Dalam hal ini, nama yang digunakan adalah Model.
Skenario
Anda dapat membawa berbagai skenario ke Model Builder, untuk menghasilkan model pembelajaran mesin untuk aplikasi Anda.
Skenario adalah deskripsi jenis prediksi yang ingin Anda buat menggunakan data Anda. Contohnya:
- Memprediksi volume penjualan produk di masa mendatang berdasarkan data penjualan historis.
- Mengklasifikasikan sentimen sebagai positif atau negatif berdasarkan ulasan pelanggan.
- Deteksi apakah transaksi perbankan penipuan.
- Rutekan masalah umpan balik pelanggan ke tim yang benar di perusahaan Anda.
Setiap skenario memetakan ke tugas pembelajaran mesin yang berbeda, yang meliputi:
| Tugas | Skenario |
|---|---|
| Klasifikasi biner | Klasifikasi data |
| Klasifikasi multikelas | Klasifikasi data |
| Klasifikasi gambar | Klasifikasi gambar |
| Klasifikasi teks | Klasifikasi teks |
| Regresi | Prediksi nilai |
| Rekomendasi | Rekomendasi |
| Prakiraan | Prakiraan |
Misalnya, skenario mengklasifikasikan sentimen sebagai positif atau negatif akan berada di bawah tugas klasifikasi biner.
Untuk informasi selengkapnya tentang berbagai Tugas ML yang didukung oleh ML.NET lihat Tugas pembelajaran mesin di ML.NET.
Skenario pembelajaran mesin mana yang tepat untuk saya?
Di Model Builder, Anda perlu memilih skenario. Jenis skenario tergantung pada jenis prediksi apa yang coba Anda buat.
Tabular
Klasifikasi data
Klasifikasi digunakan untuk mengategorikan data ke dalam kategori.
Contoh Input
Output sampel
| SepalLength | SepalWidth | Panjang Kelopak | Lebar Kelopak | Species |
|---|---|---|---|---|
| 5.1 | 3.5 | 1.4 | 0,2 | setosa |
| Spesies yang diprediksi |
|---|
| setosa |
Prediksi nilai
Prediksi nilai, yang termasuk dalam tugas regresi, digunakan untuk memprediksi angka.
Contoh Input
Output sampel
| vendor_id | rate_code | passenger_count | trip_time_in_secs | trip_distance | payment_type | fare_amount |
|---|---|---|---|---|---|---|
| CMT | 1 | 1 | 1271 | 3.8 | CRD | 17.5 |
| Prediksi Tarif |
|---|
| 4.5 |
Rekomendasi
Skenario rekomendasi memprediksi daftar item yang disarankan untuk pengguna tertentu, berdasarkan seberapa mirip suka dan ketidaksukaan mereka dengan pengguna lain'.
Anda dapat menggunakan skenario rekomendasi saat Anda memiliki sekumpulan pengguna dan sekumpulan "produk", seperti item untuk dibeli, film, buku, atau acara TV, bersama dengan serangkaian "peringkat" pengguna dari produk tersebut.
Contoh Input
Output sampel
| UserId | ProductId | Peringkat |
|---|---|---|
| 1 | 2 | 4.2 |
| Peringkat yang diprediksi |
|---|
| 4.5 |
Prakiraan
Skenario prakiraan menggunakan data historis dengan rangkaian waktu atau komponen musiman ke dalamnya.
Anda dapat menggunakan skenario prakiraan untuk memperkirakan permintaan atau penjualan produk.
Contoh Input
Output sampel
| Tanggal | SaleQty |
|---|---|
| 1/1/1970 | 1000 |
| Prakiraan 3 Hari |
|---|
| [1000,1001,1002] |
Computer Vision
Klasifikasi gambar
Klasifikasi gambar digunakan untuk mengidentifikasi gambar dari berbagai kategori. Misalnya, berbagai jenis medan atau hewan atau cacat manufaktur.
Anda dapat menggunakan skenario klasifikasi gambar jika Anda memiliki sekumpulan gambar, dan Anda ingin mengklasifikasikan gambar ke dalam kategori yang berbeda.
Contoh Input
Output sampel

| Label Yang Diprediksi |
|---|
| Anjing |
Deteksi objek
Deteksi objek digunakan untuk menemukan dan mengategorikan entitas dalam gambar. Misalnya, menemukan dan mengidentifikasi mobil dan orang dalam gambar.
Anda dapat menggunakan deteksi objek saat gambar berisi beberapa objek dari berbagai jenis.
Contoh Input
Output sampel

Pemrosesan bahasa alami
Klasifikasi teks
Klasifikasi teks mengategorikan input teks mentah.
Anda dapat menggunakan skenario klasifikasi teks jika Anda memiliki sekumpulan dokumen atau komentar, dan Anda ingin mengklasifikasikannya ke dalam kategori yang berbeda.
Contoh Input
Contoh Keluaran
| Tinjauan |
|---|
| Aku sangat suka steak ini! |
| Sentimen |
|---|
| Positif |
Lingkungan
Anda dapat melatih model pembelajaran mesin Anda secara lokal di komputer Anda atau di cloud di Azure, tergantung pada skenarionya.
Saat berlatih secara lokal, Anda bekerja dalam batasan sumber daya komputer Anda (CPU, memori, dan disk). Saat berlatih di cloud, Anda dapat meningkatkan sumber daya untuk memenuhi tuntutan skenario Anda, terutama untuk himpunan data besar.
| Skenario | CPU lokal | GPU lokal | Azure |
|---|---|---|---|
| Klasifikasi data | ✔️ | ❌ | ❌ |
| Prediksi nilai | ✔️ | ❌ | ❌ |
| Rekomendasi | ✔️ | ❌ | ❌ |
| Prakiraan | ✔️ | ❌ | ❌ |
| Klasifikasi gambar | ✔️ | ✔️ | ✔️ |
| Deteksi objek | ❌ | ❌ | ✔️ |
| Klasifikasi teks | ✔️ | ✔️ | ❌ |
Data
Setelah Anda memilih skenario, Model Builder meminta Anda untuk menyediakan himpunan data. Data digunakan untuk melatih, mengevaluasi, dan memilih model terbaik untuk skenario Anda.
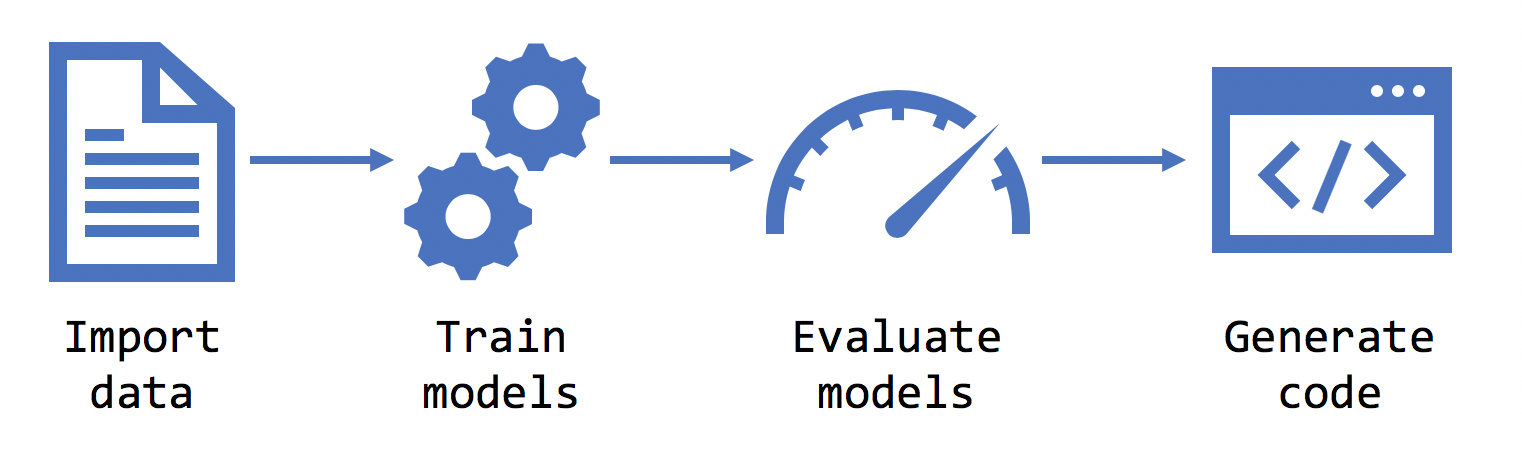
Model Builder mendukung himpunan data dalam format database .tsv, .csv, .txt, dan SQL. Jika Anda memiliki file .txt, kolom harus dipisahkan dengan ,, , ;atau \t.
Jika himpunan data terdiri dari gambar, jenis file yang didukung adalah .jpg dan .png.
Untuk informasi selengkapnya, lihat Memuat data pelatihan ke Dalam Pembuat Model.
Pilih output yang akan diprediksi (label)
Himpunan data adalah tabel baris contoh pelatihan, dan kolom atribut. Setiap baris memiliki:
- label (atribut yang ingin Anda prediksi)
- fitur (atribut yang digunakan sebagai input untuk memprediksi label)
Untuk skenario prediksi harga rumah, fiturnya bisa menjadi:
- Rekaman persegi rumah.
- Jumlah kamar tidur dan kamar mandi.
- Kode pos.
Label adalah harga rumah historis untuk baris rekaman persegi, kamar tidur, dan nilai kamar mandi dan kode pos.
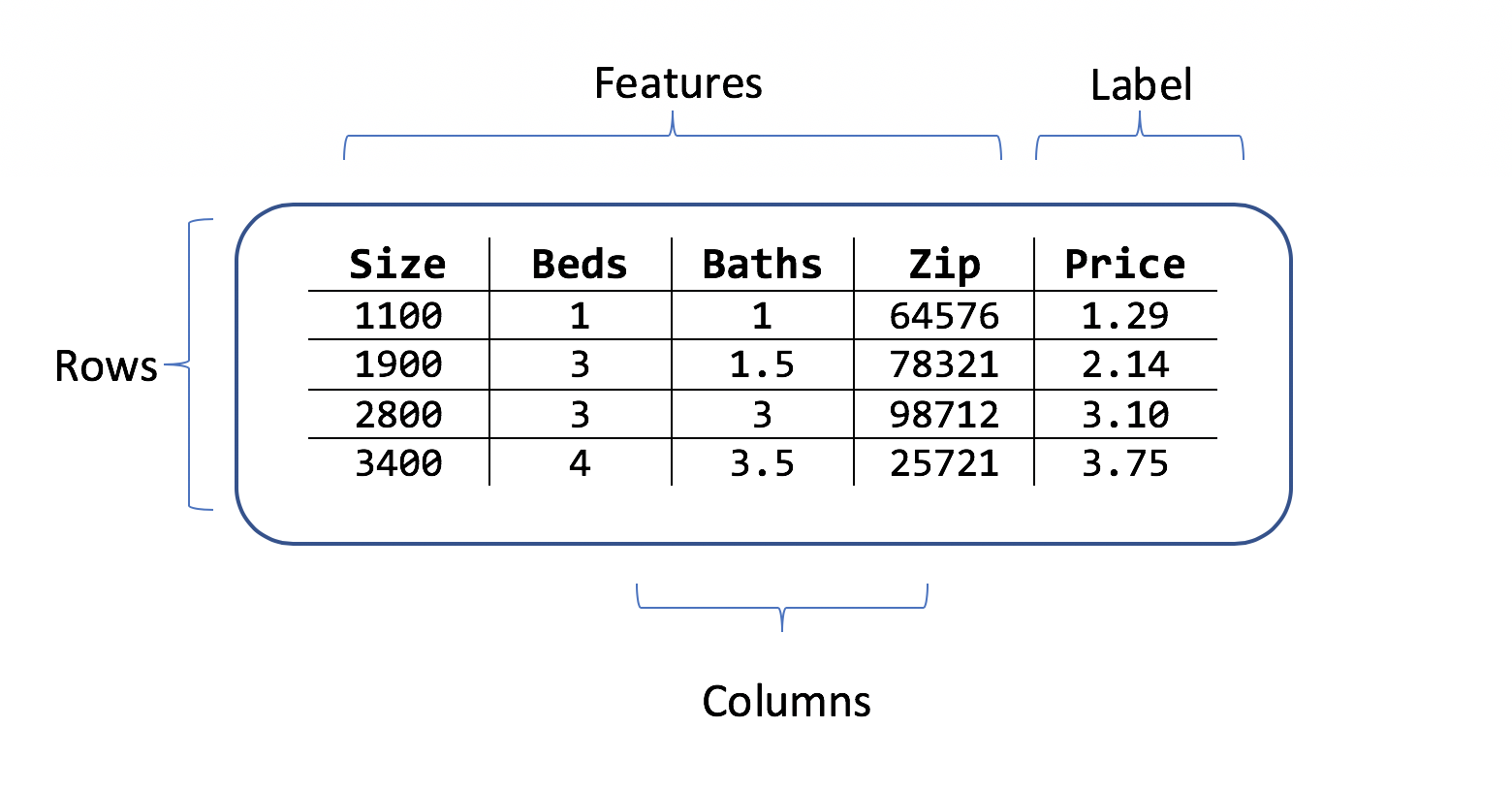
Contoh himpunan data
Jika Anda belum memiliki data Anda sendiri, cobalah salah satu himpunan data ini:
| Skenario | Contoh | Data | Label | Fitur |
|---|---|---|---|---|
| Klasifikasi | Memprediksi anomali penjualan | data penjualan produk | Penjualan Produk | Month |
| Memprediksi sentimen komentar situs web | data komentar situs web | Label (1 ketika sentimen negatif, 0 saat positif) | Komentar, Tahun | |
| Memprediksi transaksi kartu kredit penipuan | data kartu kredit | Kelas (1 saat penipuan, 0 jika tidak) | Jumlah, V1-V28 (fitur anonim) | |
| Memprediksi jenis masalah dalam repositori GitHub | Data masalah GitHub | Luas | Judul, Deskripsi | |
| Prediksi nilai | Memprediksi harga tarif taksi | data tarif taksi | Tarif | Waktu perjalanan, jarak |
| Klasifikasi gambar | Memprediksi kategori bunga | gambar bunga | Jenis bunga: bunga daisy, dandelion, mawar, bunga matahari, tulip | Data gambar itu sendiri |
| Rekomendasi | Memprediksi film yang akan disukai seseorang | peringkat film | Pengguna, Film | Peringkat |
Berlatih
Setelah Anda memilih skenario, lingkungan, data, dan label, Model Builder melatih model.
Apa itu pelatihan?
Pelatihan adalah proses otomatis di mana Model Builder mengajarkan model Anda cara menjawab pertanyaan untuk skenario Anda. Setelah dilatih, model Anda dapat membuat prediksi dengan data input yang belum dilihat sebelumnya. Misalnya, jika Anda memprediksi harga rumah dan rumah baru hadir di pasaran, Anda dapat memprediksi harga jualnya.
Karena Model Builder menggunakan pembelajaran mesin otomatis (AutoML), Model Builder tidak memerlukan input atau penyetelan apa pun dari Anda selama pelatihan.
Berapa lama saya harus melatihnya?
Model Builder menggunakan AutoML untuk menjelajahi beberapa model untuk menemukan model berkinerja terbaik.
Periode pelatihan yang lebih lama memungkinkan AutoML menjelajahi lebih banyak model dengan berbagai pengaturan yang lebih luas.
Tabel di bawah ini meringkas waktu rata-rata yang diperlukan untuk mendapatkan performa yang baik untuk serangkaian himpunan data contoh, pada komputer lokal.
| Ukuran himpunan data | Waktu rata-rata untuk melatih |
|---|---|
| 0 - 10 MB | 10 dtk |
| 10 - 100 MB | 10 menit |
| 100 - 500 MB | 30 menit |
| 500 - 1 GB | 60 menit |
| 1 GB+ | 3+ jam |
Angka-angka ini hanya sebagai panduan. Lama pelatihan yang tepat tergantung pada:
- Jumlah fitur (kolom) yang digunakan untuk sebagai input ke model.
- Jenis kolom.
- Tugas ML.
- Performa CPU, disk, dan memori komputer yang digunakan untuk pelatihan.
Umumnya disarankan agar Anda menggunakan lebih dari 100 baris sebagai himpunan data dengan kurang dari yang mungkin tidak menghasilkan hasil apa pun.
Evaluasi
Evaluasi adalah proses mengukur seberapa baik model Anda. Model Builder menggunakan model terlatih untuk membuat prediksi dengan data pengujian baru, lalu mengukur seberapa baik prediksinya.
Model Builder membagi data pelatihan menjadi set pelatihan dan set pengujian. Data pelatihan (80%) digunakan untuk melatih model Anda dan data pengujian (20%) ditahan untuk mengevaluasi model Anda.
Bagaimana cara memahami performa model saya?
Skenario memetakan ke tugas pembelajaran mesin. Setiap tugas ML memiliki serangkaian metrik evaluasinya sendiri.
Prediksi nilai
Metrik default untuk masalah prediksi nilai adalah RSquared, nilai rentang RSquared antara 0 dan 1. 1 adalah nilai terbaik atau dengan kata lain semakin dekat nilai RSquared ke 1 semakin baik performa model Anda.
Metrik lain yang dilaporkan seperti kehilangan absolut, kehilangan kuadrat, dan kehilangan RMS adalah metrik tambahan, yang dapat digunakan untuk memahami performa model Anda dan membandingkannya dengan model prediksi nilai lainnya.
Klasifikasi (2 kategori)
Metrik default untuk masalah klasifikasi adalah akurasi. Akurasi menentukan proporsi prediksi yang benar yang dibuat model Anda melalui himpunan data pengujian. Semakin dekat ke 100% atau 1,0 semakin baik.
Metrik lain yang dilaporkan seperti AUC (Area di bawah kurva), yang mengukur tingkat positif sejati vs. tingkat positif palsu harus lebih besar dari 0,50 agar model dapat diterima.
Metrik tambahan seperti skor F1 dapat digunakan untuk mengontrol keseimbangan antara Presisi dan Pengenalan.
Klasifikasi (3+ kategori)
Metrik default untuk klasifikasi Multi-kelas adalah Akurasi Mikro. Semakin dekat Akurasi Mikro menjadi 100% atau 1,0 semakin baik.
Metrik penting lainnya untuk klasifikasi Multi-kelas adalah Akurasi makro, mirip dengan Akurasi mikro semakin dekat ke 1,0 semakin baik. Cara yang baik untuk memikirkan dua jenis akurasi ini adalah:
- Akurasi mikro: Seberapa sering tiket masuk diklasifikasikan ke tim yang tepat?
- Akurasi makro: Untuk tim rata-rata, seberapa sering tiket masuk benar untuk tim mereka?
Informasi selengkapnya tentang metrik evaluasi
Untuk informasi selengkapnya, lihat metrik evaluasi model.
Tingkatkan
Jika skor performa model Anda tidak sebagus yang Anda inginkan, Anda dapat:
Melatih untuk jangka waktu yang lebih lama. Dengan lebih banyak waktu, mesin pembelajaran mesin otomatis bereksperimen dengan lebih banyak algoritma dan pengaturan.
Tambahkan lebih banyak data. Terkadang jumlah data tidak cukup untuk melatih model pembelajaran mesin berkualitas tinggi. Ini terutama berlaku dengan himpunan data yang memiliki sejumlah kecil contoh.
Seimbangkan data Anda. Untuk tugas klasifikasi, pastikan bahwa set pelatihan seimbang di seluruh kategori. Misalnya, jika Anda memiliki empat kelas untuk 100 contoh pelatihan, dan dua kelas pertama (tag1 dan tag2) digunakan untuk 90 rekaman, tetapi dua lainnya (tag3 dan tag4) hanya digunakan pada 10 rekaman yang tersisa, kurangnya data seimbang dapat menyebabkan model Anda berjuang untuk memprediksi tag3 atau tag4 dengan benar.
Konsumsi
Setelah fase evaluasi, Model Builder menghasilkan file model, dan kode yang dapat Anda gunakan untuk menambahkan model ke aplikasi Anda. ML.NET model disimpan sebagai file zip. Kode untuk memuat dan menggunakan model Anda ditambahkan sebagai proyek baru dalam solusi Anda. Model Builder juga menambahkan aplikasi konsol sampel yang dapat Anda jalankan untuk melihat model Anda beraksi.
Selain itu, Model Builder memberi Anda opsi untuk membuat proyek yang menggunakan model Anda. Saat ini, Model Builder akan membuat proyek berikut:
- Aplikasi konsol: Membuat aplikasi konsol .NET untuk membuat prediksi dari model Anda.
- API Web: Membuat ASP.NET Core Web API yang memungkinkan Anda menggunakan model melalui internet.
Apa selanjutnya?
Instal ekstensi Visual Studio Pembuat Model.
Coba prediksi harga atau skenario regresi apa pun.
Berkolaborasi dengan kami di GitHub
Sumber untuk konten ini dapat ditemukan di GitHub, yang juga dapat Anda gunakan untuk membuat dan meninjau masalah dan menarik permintaan. Untuk informasi selengkapnya, lihat panduan kontributor kami.