Menggunakan notebook untuk memuat data ke lakehouse Anda
Dalam tutorial ini, pelajari cara membaca/menulis data ke fabric lakehouse Anda dengan notebook. Fabric mendukung Spark API dan Pandas API adalah untuk mencapai tujuan ini.
Memuat data dengan API Apache Spark
Di sel kode notebook, gunakan contoh kode berikut untuk membaca data dari sumber dan memuatnya ke dalam File, Tabel, atau kedua bagian lakehouse Anda.
Untuk menentukan lokasi yang akan dibaca, Anda dapat menggunakan jalur relatif jika data berasal dari lakehouse default buku catatan Anda saat ini. Atau, jika data berasal dari lakehouse yang berbeda, Anda dapat menggunakan jalur Azure Blob File System (ABFS) absolut. Salin jalur ini dari menu konteks data.
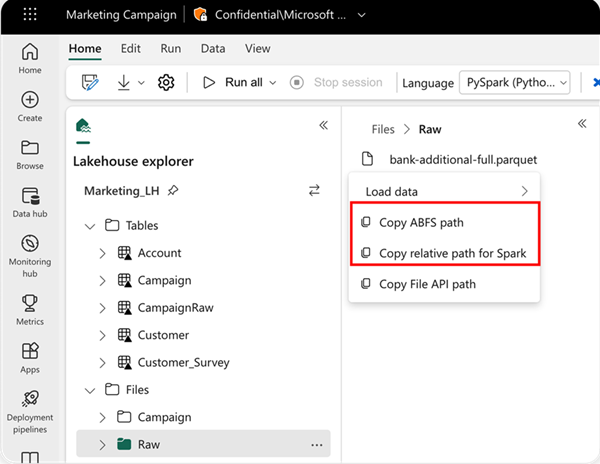
Salin jalur ABFS: Opsi ini mengembalikan jalur absolut file.
Salin jalur relatif untuk Spark: Opsi ini mengembalikan jalur relatif file di lakehouse default Anda.
df = spark.read.parquet("location to read from")
# Keep it if you want to save dataframe as CSV files to Files section of the default lakehouse
df.write.mode("overwrite").format("csv").save("Files/ " + csv_table_name)
# Keep it if you want to save dataframe as Parquet files to Files section of the default lakehouse
df.write.mode("overwrite").format("parquet").save("Files/" + parquet_table_name)
# Keep it if you want to save dataframe as a delta lake, parquet table to Tables section of the default lakehouse
df.write.mode("overwrite").format("delta").saveAsTable(delta_table_name)
# Keep it if you want to save the dataframe as a delta lake, appending the data to an existing table
df.write.mode("append").format("delta").saveAsTable(delta_table_name)
Memuat data dengan Pandas API
Untuk mendukung PANDAS API, lakehouse default secara otomatis dipasang ke notebook. Titik pemasangan adalah '/lakehouse/default/'. Anda dapat menggunakan titik pemasangan ini untuk membaca/menulis data dari/ke lakehouse default. Opsi "Salin Jalur API File" dari menu konteks mengembalikan jalur API File dari titik pemasangan tersebut. Jalur yang dikembalikan dari opsi Salin jalur ABFS juga berfungsi untuk PANDAS API.
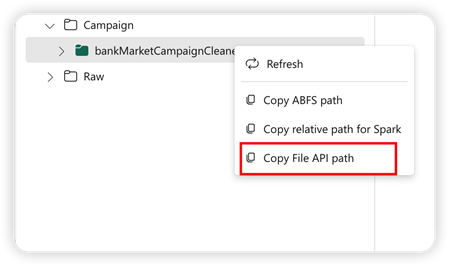
Salin Jalur API File: Opsi ini mengembalikan jalur di bawah titik pemasangan lakehouse default.
# Keep it if you want to read parquet file with Pandas from the default lakehouse mount point
import pandas as pd
df = pd.read_parquet("/lakehouse/default/Files/sample.parquet")
# Keep it if you want to read parquet file with Pandas from the absolute abfss path
import pandas as pd
df = pd.read_parquet("abfss://DevExpBuildDemo@msit-onelake.dfs.fabric.microsoft.com/Marketing_LH.Lakehouse/Files/sample.parquet")
Tip
Untuk Spark API, gunakan opsi Salin jalur ABFS atau Salin jalur relatif untuk Spark untuk mendapatkan jalur file. Untuk API Pandas, silakan gunakan opsi jalur Salin ABFS atau salin jalur API File untuk mendapatkan jalur file.
Cara tercepat agar kode berfungsi dengan Spark API atau Pandas API adalah dengan menggunakan opsi Muat data dan pilih API yang ingin Anda gunakan. Kode secara otomatis dibuat di sel kode baru buku catatan.
