Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Microsoft Fabric adalah layanan analitik terintegrasi yang mempercepat waktu untuk mendapatkan wawasan di seluruh gudang data dan sistem big data. Visualisasi data di notebook adalah fitur utama yang memungkinkan Anda mendapatkan wawasan tentang data Anda, membantu pengguna mengidentifikasi pola, tren, dan outlier dengan mudah.
Saat bekerja dengan Apache Spark di Fabric, Anda memiliki opsi bawaan untuk memvisualisasikan data, termasuk fitur bagan notebook Fabric dan akses ke pustaka sumber terbuka populer.
Notebook Fabric juga memungkinkan Anda untuk mengonversi hasil tabular menjadi bagan yang disesuaikan tanpa menulis kode apa pun, memungkinkan pengalaman eksplorasi data yang lebih intuitif dan mulus.
Perintah visualisasi bawaan - fungsi display()
Fungsi visualisasi bawaan Fabric memungkinkan Anda mengubah Apache Spark DataFrames, Pandas DataFrames, dan hasil kueri SQL menjadi visualisasi data interaktif yang kaya.
Dengan menggunakan fungsi tampilan , Anda dapat merender PySpark dan Scala Spark DataFrames atau Resilient Distributed Datasets (RDDs) sebagai tabel atau bagan dinamis.
Anda dapat menentukan jumlah baris kerangka data yang sedang dirender. Nilai defaultnya adalah 1000. Notebook widget output tampilan mendukung untuk melihat dan memprofilkan maksimum 10000 baris dari sebuah dataframe.

Anda dapat menggunakan fungsi filter pada toolbar global untuk menerapkan aturan yang dikustomisasi ke data Anda. Kondisi filter diterapkan ke kolom tertentu, dan hasilnya tercermin dalam tampilan tabel dan bagan.

Hasil pernyataan SQL menggunakan widget output yang sama dengan display() sebagai default.
Tampilan tabel dataframe yang kaya
Dukungan pilihan gratis pada tampilan tabel
Secara default, Tampilan Tabel dirender saat menggunakan perintah display() di notebook Fabric. Pratinjau kerangka data yang kaya menawarkan fungsi pemilihan bebas intuitif, yang dirancang untuk meningkatkan pengalaman analisis data dengan mengaktifkan opsi pilihan interaktif yang fleksibel. Fitur ini memungkinkan pengguna untuk menavigasi dan menjelajahi kerangka data secara efisien dengan mudah.
pemilihan kolom
- Kolom tunggal: Klik header kolom untuk memilih seluruh kolom.
- Beberapa kolom: Setelah memilih satu kolom, tekan dan tahan tombol 'Shift', lalu klik header kolom lain untuk memilih beberapa kolom.
Pilihan baris
- Baris tunggal: Klik pada header baris untuk memilih seluruh baris.
- Beberapa baris: Setelah memilih satu baris, tekan dan tahan tombol 'Shift', lalu klik header baris lain untuk memilih beberapa baris.
Pratinjau konten sel: Pratinjau konten masing-masing sel untuk melihat data dengan cepat dan terperinci tanpa perlu menulis kode tambahan.
Ringkasan kolom: Dapatkan ringkasan setiap kolom, termasuk distribusi data dan statistik utama, untuk memahami karakteristik data dengan cepat.
Pemilihan area bebas: Pilih segmen berkelanjutan tabel untuk mendapatkan gambaran umum tentang total sel yang dipilih dan nilai numerik di area yang dipilih.
Menyalin Konten yang Dipilih: Dalam semua kasus pilihan, Anda dapat dengan cepat menyalin konten yang dipilih menggunakan pintasan 'Ctrl + C'. Data yang dipilih disalin dalam format CSV, sehingga mudah diproses di aplikasi lain.
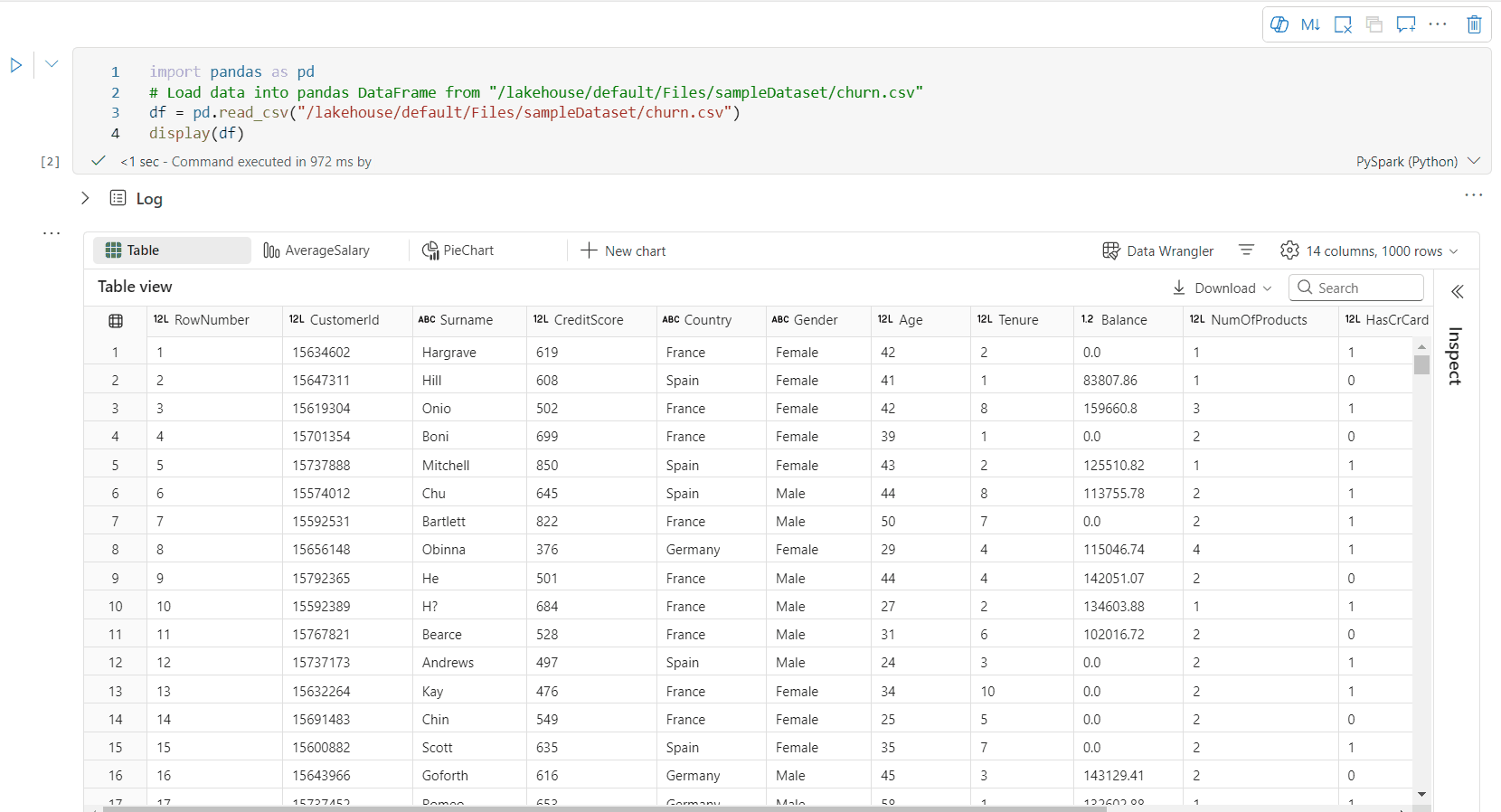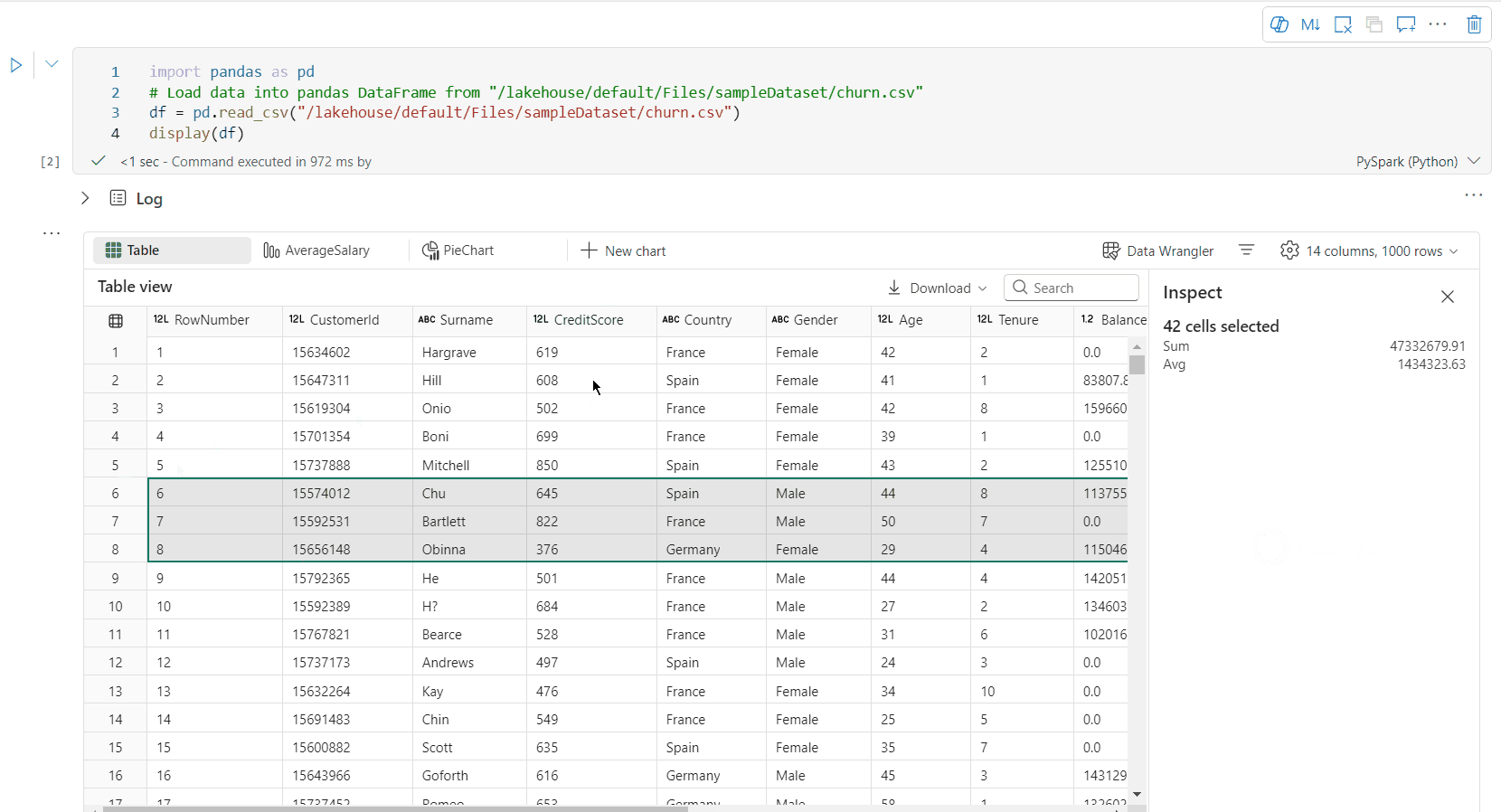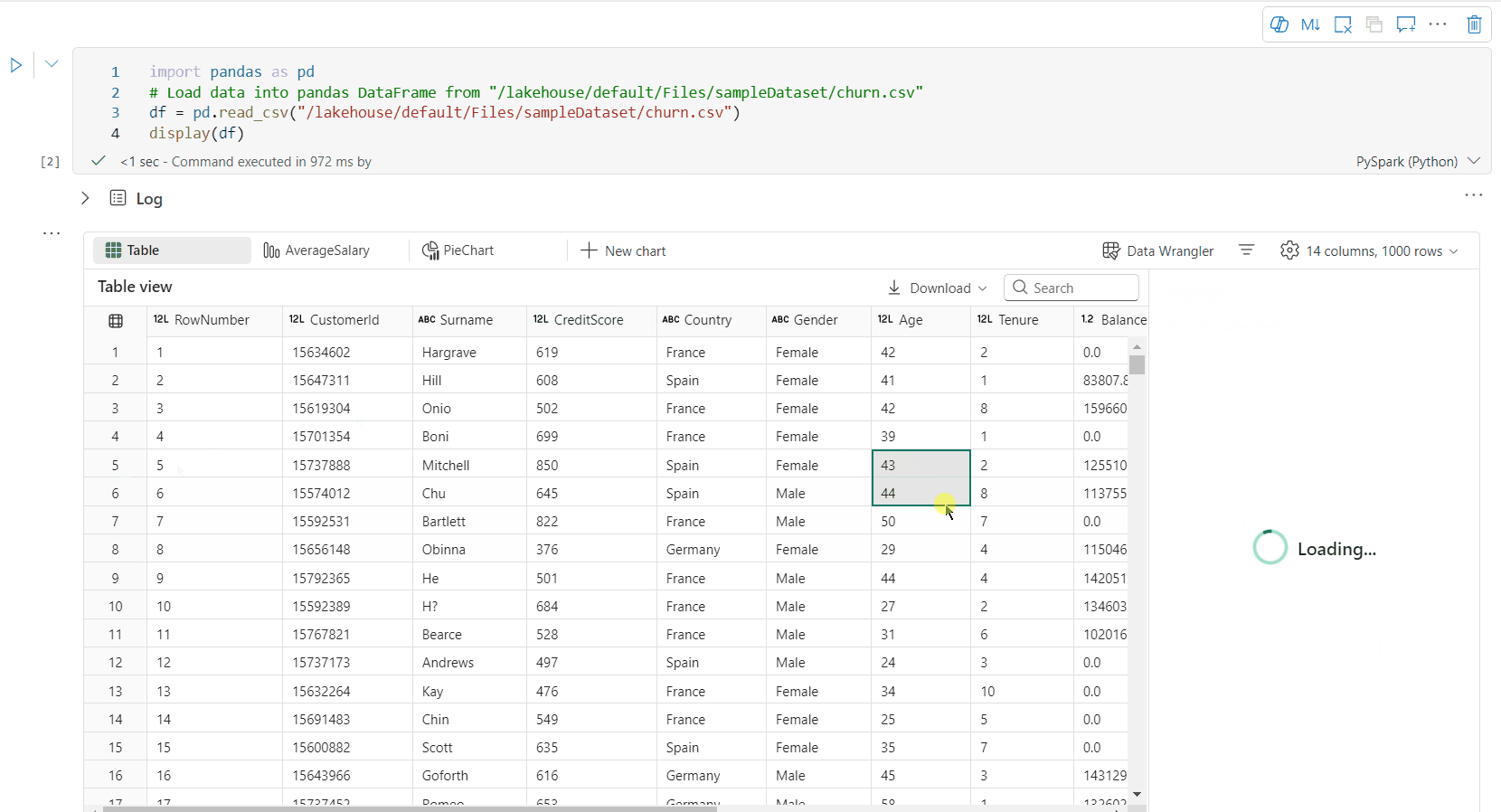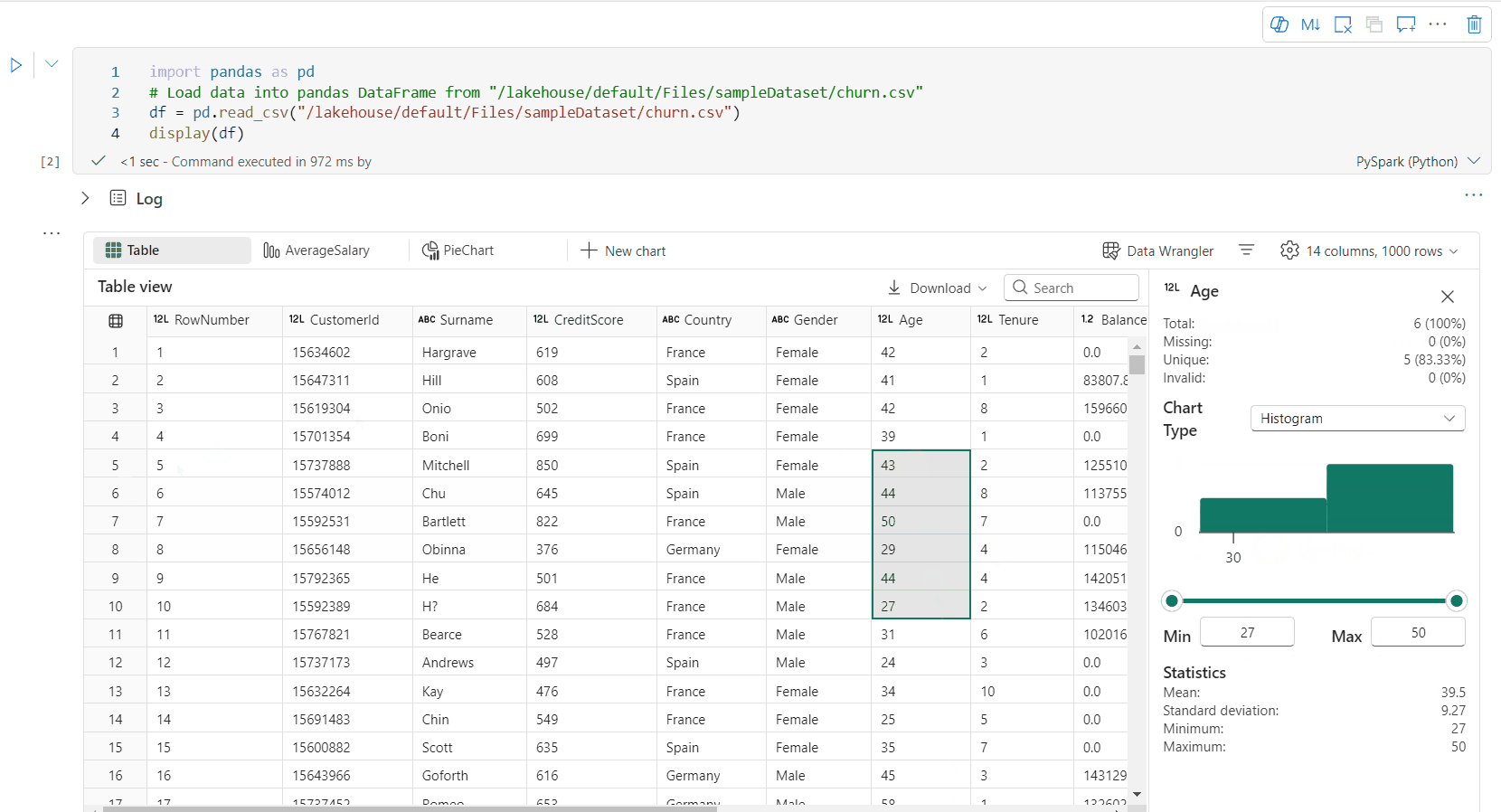

Dukungan pembuatan profil data melalui panel Inspeksi

Anda dapat membuat profil dataframe Anda dengan mengklik tombol Inspeksi . Ini menyediakan distribusi data yang dirangkum dan memperlihatkan statistik setiap kolom.
Setiap kartu di panel samping "Inspeksi" dipetakan ke kolom dari dataframe, Anda dapat melihat detail selengkapnya baik dengan mengklik kartu atau memilih kolom dalam tabel.
Anda bisa menampilkan detail sel dengan mengklik sel tabel. Fitur ini berguna ketika dataframe berisi jenis konten string panjang.
Tampilan Bagan DataFrame Berfitur Lengkap yang Disempurnakan
Tampilan bagan yang ditingkatkan dalam perintah display() menawarkan cara yang lebih intuitif dan dinamis untuk memvisualisasikan data Anda.
Penyempurnaan Kunci:
Dukungan Multi-Bagan: Tambahkan hingga lima bagan dalam widget output tampilan() tunggal dengan memilih Bagan Baru, memungkinkan perbandingan yang mudah di berbagai kolom.
Rekomendasi Bagan Pintar: Dapatkan daftar bagan yang disarankan berdasarkan DataFrame Anda. Pilih untuk mengedit visualisasi yang direkomendasikan atau membuat bagan kustom dari awal.

Kustomisasi Fleksibel: Mempersonalisasi visualisasi Anda dengan pengaturan yang dapat disesuaikan yang beradaptasi berdasarkan jenis bagan yang dipilih.
Kategori Pengaturan dasar Keterangan Jenis bagan Fungsi tampilan mendukung berbagai jenis bagan, termasuk bagan batang, plot sebar, grafik garis, tabel pivot, dan banyak lagi. Judul Judul Judul grafik. Judul Subtitel Subjudul bagan dengan deskripsi lebih rinci. Data Informasi Sumbu X Tentukan kunci bagan. Data Informasi Sumbu Y Tentukan nilai bagan. Legenda Tampilkan Legenda Aktifkan/nonaktifkan legenda. Legenda Posisi Atur posisi legenda. Lainnya Grup rangkaian Gunakan konfigurasi ini untuk menentukan grup untuk agregasi. Lainnya Agregasi Gunakan metode ini untuk mengagregasi data dalam visualisasi Anda. Lainnya Tumpukan Konfigurasikan gaya tampilan hasil. Lainnya Nilai hilang dan NULL Konfigurasikan bagaimana nilai bagan hilang atau NULL ditampilkan. Catatan
Selain itu, Anda dapat menentukan jumlah baris yang ditampilkan, dengan pengaturan default 1.000. Widget output display pada notebook mendukung penayangan dan pembuatan profil hingga 10.000 baris DataFrame. Pilih Agregasi di semua hasil lalu pilih Terapkan untuk menerapkan pembuatan bagan dari seluruh kerangka data. Pekerjaan Spark dipicu saat pengaturan bagan berubah. Mungkin perlu waktu beberapa menit untuk menyelesaikan perhitungan dan merender bagan.
Kategori Pengaturan tingkat lanjut Keterangan Warna Tema Tentukan kumpulan warna tema bagan. Sumbu X Etiket Tentukan label untuk sumbu X. Sumbu X Skala Tentukan fungsi skala sumbu X. Sumbu X Rentang Tentukan rentang nilai sumbu X. Sumbu Y Etiket Tentukan label untuk sumbu Y. Sumbu Y Skala Tentukan fungsi skala sumbu Y. Sumbu Y Rentang Tentukan rentang nilai sumbu Y. Tampilan Perlihatkan label Perlihatkan/sembunyikan label hasil pada bagan. Perubahan konfigurasi segera berlaku, dan semua konfigurasi disimpan secara otomatis dalam konten buku catatan.
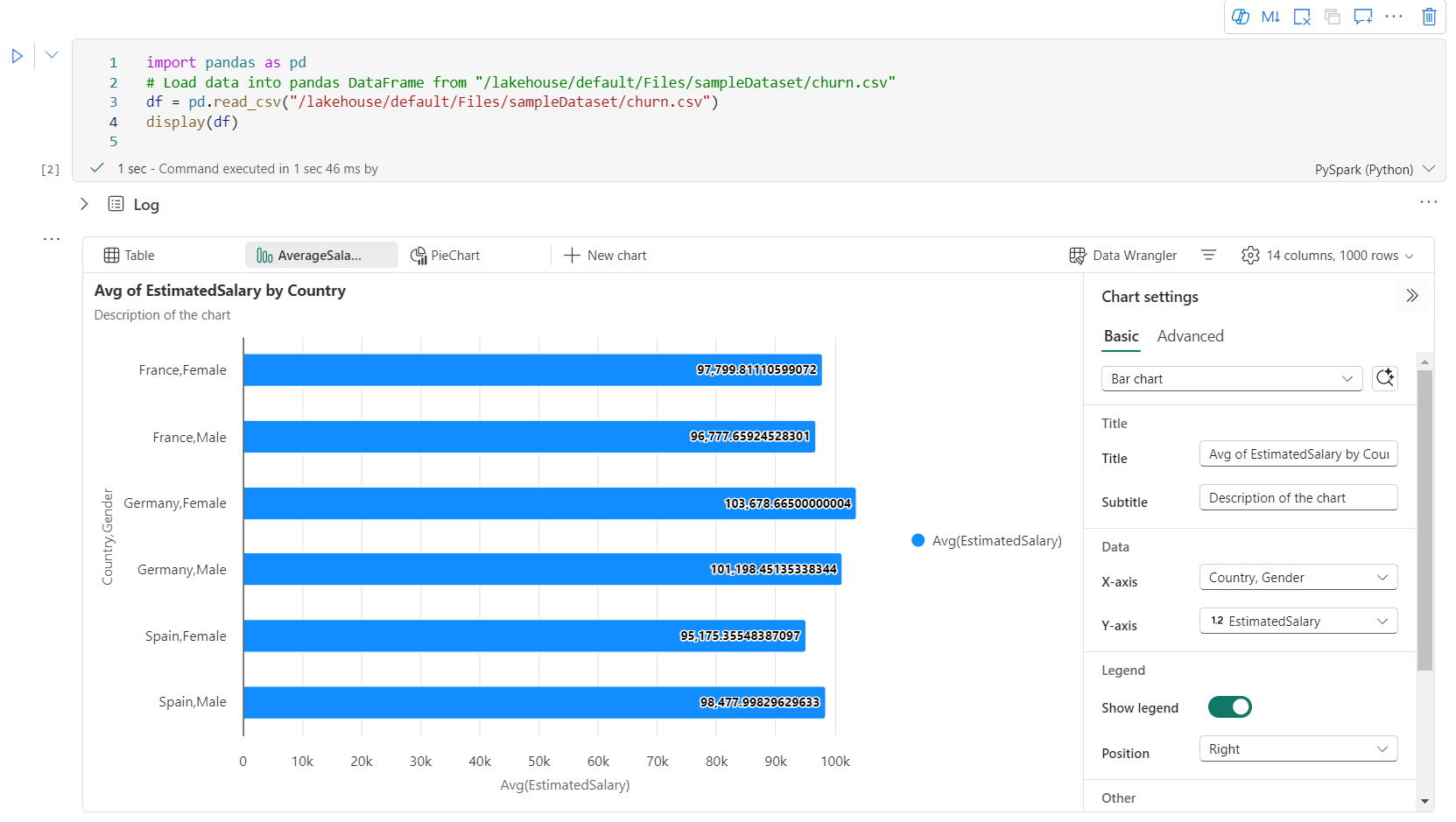
Anda dapat dengan mudah mengganti nama, menduplikasi, menghapus, atau memindahkan bagan di menu tab bagan. Anda juga dapat menyeret dan meletakkan tab untuk menyusun ulang tab tersebut. Tab pertama akan ditampilkan sebagai default saat buku catatan dibuka.
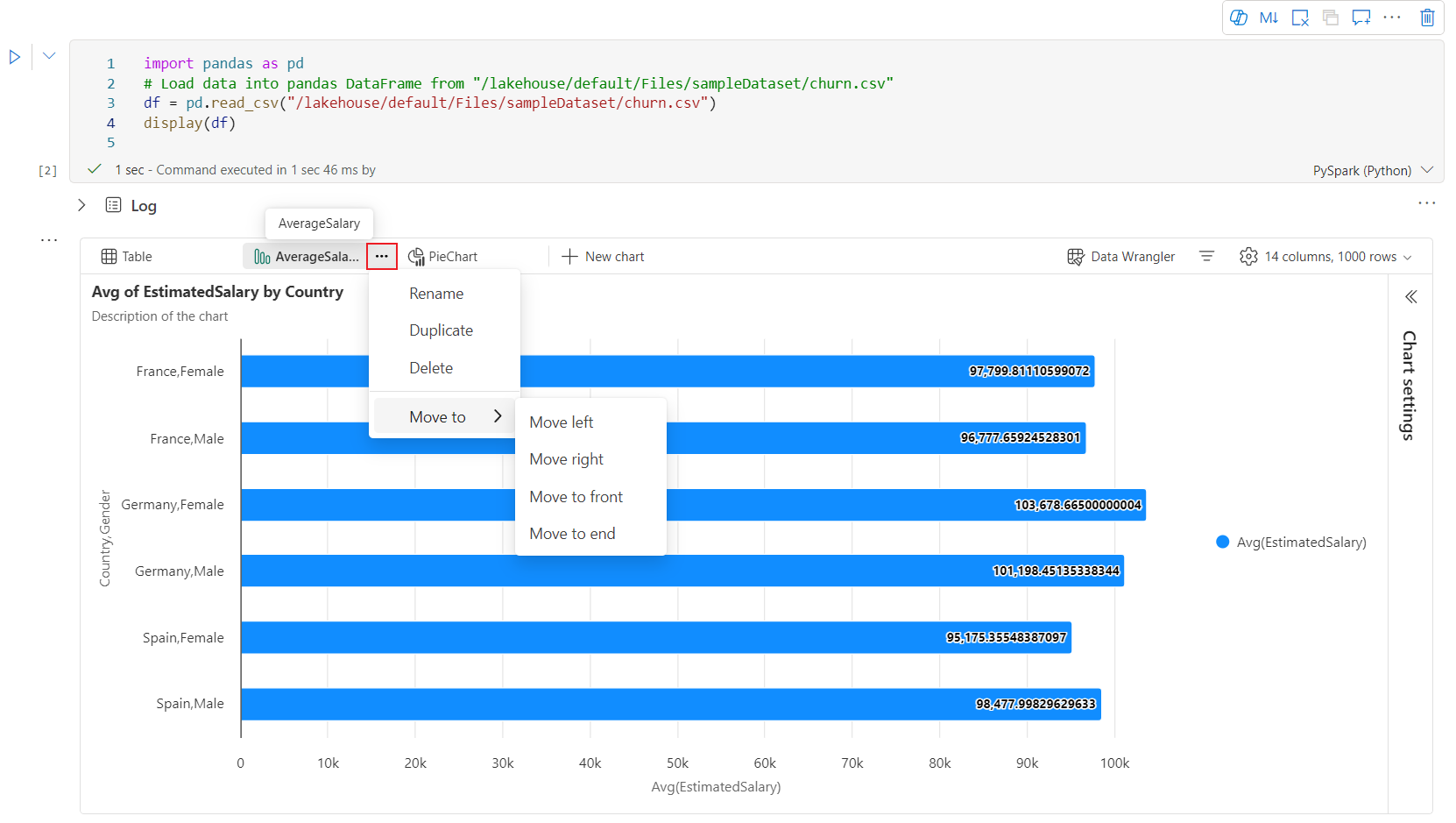
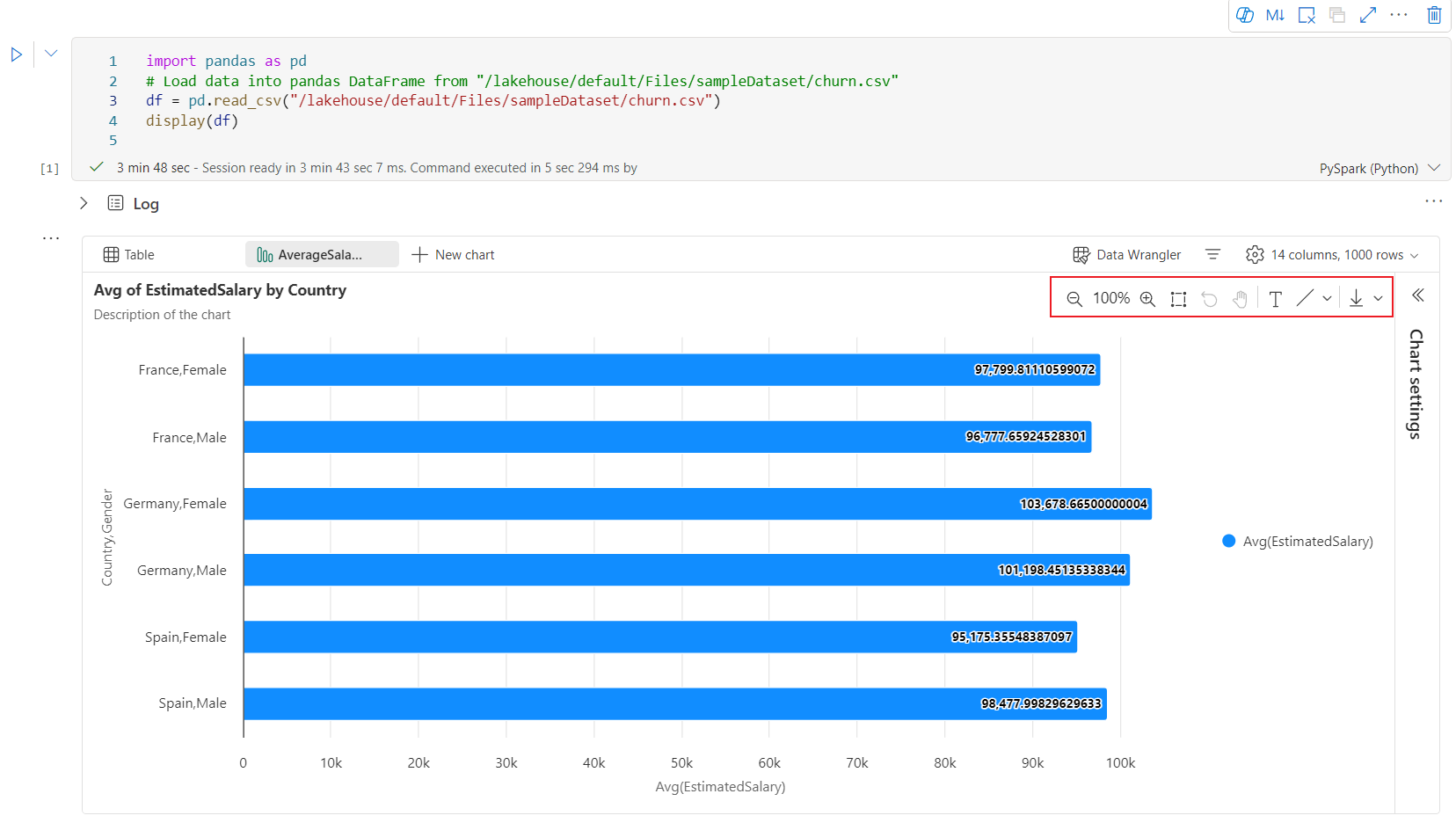
Toolbar interaktif tersedia dalam pengalaman bagan baru saat pengguna mengarahkan kursor ke bagan. Operasi dukungan seperti memperbesar, memperkecil, memilih untuk memperbesar, mengatur ulang, menggeser, mengedit anotasi, dll.
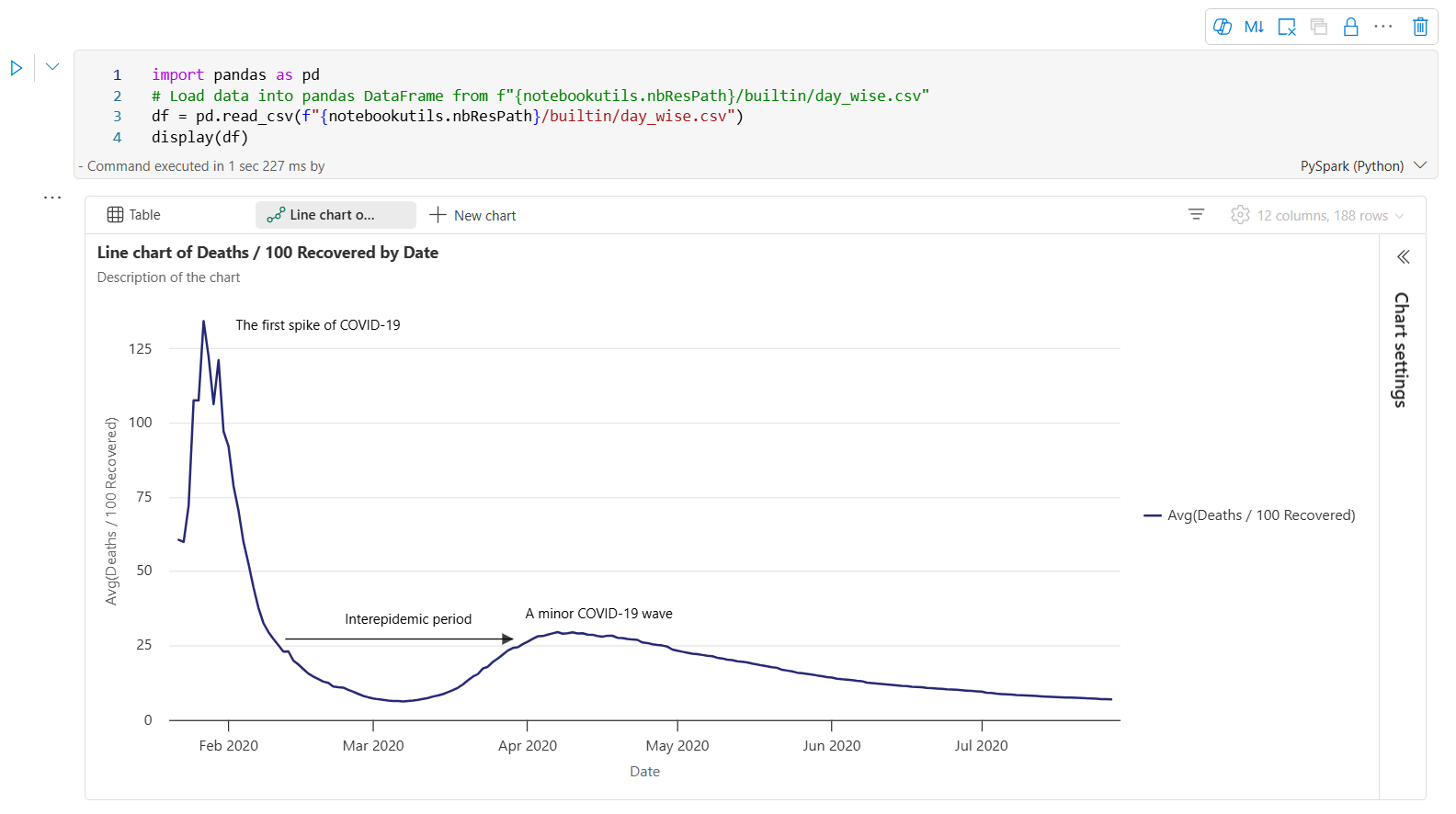
Berikut adalah contoh anotasi bagan.




tampilan ringkasan display()
Gunakan display(df, summary = true) untuk memeriksa ringkasan statistik Apache Spark DataFrame tertentu. Ringkasan mencakup nama kolom, jenis kolom, nilai unik, dan nilai yang hilang untuk setiap kolom. Anda juga dapat memilih kolom tertentu untuk melihat nilai minimumnya, nilai maksimum, nilai rata-rata, dan simpang siur standar.

opsi displayHTML()
Notebook Fabric mendukung grafis HTML menggunakan fungsi displayHTML .
Gambar berikut adalah contoh membuat visualisasi menggunakan D3.js.

Untuk membuat visualisasi ini, jalankan kode berikut.
displayHTML("""<!DOCTYPE html>
<meta charset="utf-8">
<!-- Load d3.js -->
<script src="https://d3js.org/d3.v4.js"></script>
<!-- Create a div where the graph will take place -->
<div id="my_dataviz"></div>
<script>
// set the dimensions and margins of the graph
var margin = {top: 10, right: 30, bottom: 30, left: 40},
width = 400 - margin.left - margin.right,
height = 400 - margin.top - margin.bottom;
// append the svg object to the body of the page
var svg = d3.select("#my_dataviz")
.append("svg")
.attr("width", width + margin.left + margin.right)
.attr("height", height + margin.top + margin.bottom)
.append("g")
.attr("transform",
"translate(" + margin.left + "," + margin.top + ")");
// Create Data
var data = [12,19,11,13,12,22,13,4,15,16,18,19,20,12,11,9]
// Compute summary statistics used for the box:
var data_sorted = data.sort(d3.ascending)
var q1 = d3.quantile(data_sorted, .25)
var median = d3.quantile(data_sorted, .5)
var q3 = d3.quantile(data_sorted, .75)
var interQuantileRange = q3 - q1
var min = q1 - 1.5 * interQuantileRange
var max = q1 + 1.5 * interQuantileRange
// Show the Y scale
var y = d3.scaleLinear()
.domain([0,24])
.range([height, 0]);
svg.call(d3.axisLeft(y))
// a few features for the box
var center = 200
var width = 100
// Show the main vertical line
svg
.append("line")
.attr("x1", center)
.attr("x2", center)
.attr("y1", y(min) )
.attr("y2", y(max) )
.attr("stroke", "black")
// Show the box
svg
.append("rect")
.attr("x", center - width/2)
.attr("y", y(q3) )
.attr("height", (y(q1)-y(q3)) )
.attr("width", width )
.attr("stroke", "black")
.style("fill", "#69b3a2")
// show median, min and max horizontal lines
svg
.selectAll("toto")
.data([min, median, max])
.enter()
.append("line")
.attr("x1", center-width/2)
.attr("x2", center+width/2)
.attr("y1", function(d){ return(y(d))} )
.attr("y2", function(d){ return(y(d))} )
.attr("stroke", "black")
</script>
"""
)
Menyematkan laporan Power BI di buku catatan
Penting
Fitur ini sedang dalam tahap pratinjau.
Paket Powerbiclient Python sekarang didukung secara asli di notebook Fabric. Anda tidak perlu melakukan penyiapan tambahan (seperti proses autentikasi) pada fabric notebook Spark runtime 3.4. Cukup impor powerbiclient dan kemudian lanjutkan eksplorasi Anda. Untuk mempelajari selengkapnya tentang cara menggunakan paket powerbiclient, lihat dokumentasi powerbiclient.
Powerbiclient mendukung fitur utama berikut.
Merender laporan Power BI yang sudah ada
Anda dapat dengan mudah menyematkan dan berinteraksi dengan laporan Power BI di buku catatan Anda hanya dengan beberapa baris kode.
Gambar berikut adalah contoh penyajian laporan Power BI yang sudah ada.

Jalankan kode berikut untuk merender laporan Power BI yang sudah ada.
from powerbiclient import Report
report_id="Your report id"
report = Report(group_id=None, report_id=report_id)
report
Membuat visual laporan dari Spark DataFrame
Anda bisa menggunakan Spark DataFrame di buku catatan Anda untuk menghasilkan visualisasi yang berwawasan dengan cepat. Anda juga dapat memilih Simpan dalam laporan yang disematkan untuk membuat item laporan di ruang kerja target.
Gambar berikut adalah contoh QuickVisualize() dari Spark DataFrame.

Jalankan kode berikut untuk merender laporan dari Spark DataFrame.
# Create a spark dataframe from a Lakehouse parquet table
sdf = spark.sql("SELECT * FROM testlakehouse.table LIMIT 1000")
# Create a Power BI report object from spark data frame
from powerbiclient import QuickVisualize, get_dataset_config
PBI_visualize = QuickVisualize(get_dataset_config(sdf))
# Render new report
PBI_visualize
Membuat visual laporan dari pandas DataFrame
Anda juga dapat membuat laporan berdasarkan Pandas DataFrame di notebook.
Gambar berikut adalah contoh QuickVisualize() dari Pandas DataFrame.

Jalankan kode berikut untuk merender laporan dari Spark DataFrame.
import pandas as pd
# Create a pandas dataframe from a URL
df = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/fips-unemp-16.csv")
# Create a pandas dataframe from a Lakehouse csv file
from powerbiclient import QuickVisualize, get_dataset_config
# Create a Power BI report object from your data
PBI_visualize = QuickVisualize(get_dataset_config(df))
# Render new report
PBI_visualize
Pustaka populer
Dalam hal visualisasi data, Python menawarkan beberapa pustaka grafik yang dikemas dengan banyak fitur berbeda. Secara default, setiap kumpulan Apache Spark di Fabric berisi sekumpulan pustaka sumber terbuka yang dikumpulkan dan populer.
Matplotlib
Anda dapat merender pustaka plot standar, seperti Matplotlib, menggunakan fungsi rendering bawaan untuk setiap pustaka.
Gambar berikut adalah contoh pembuatan bagan batang menggunakan Matplotlib.


Jalankan kode sampel berikut untuk menggambar bagan batang ini.
# Bar chart
import matplotlib.pyplot as plt
x1 = [1, 3, 4, 5, 6, 7, 9]
y1 = [4, 7, 2, 4, 7, 8, 3]
x2 = [2, 4, 6, 8, 10]
y2 = [5, 6, 2, 6, 2]
plt.bar(x1, y1, label="Blue Bar", color='b')
plt.bar(x2, y2, label="Green Bar", color='g')
plt.plot()
plt.xlabel("bar number")
plt.ylabel("bar height")
plt.title("Bar Chart Example")
plt.legend()
plt.show()
Efek Bokeh
Anda dapat merender HTML atau pustaka interaktif, seperti bokeh, menggunakan displayHTML(df).
Gambar berikut adalah contoh plot glif pada peta menggunakan bokeh.

Untuk menggambar gambar ini, jalankan kode sampel berikut.
from bokeh.plotting import figure, output_file
from bokeh.tile_providers import get_provider, Vendors
from bokeh.embed import file_html
from bokeh.resources import CDN
from bokeh.models import ColumnDataSource
tile_provider = get_provider(Vendors.CARTODBPOSITRON)
# range bounds supplied in web mercator coordinates
p = figure(x_range=(-9000000,-8000000), y_range=(4000000,5000000),
x_axis_type="mercator", y_axis_type="mercator")
p.add_tile(tile_provider)
# plot datapoints on the map
source = ColumnDataSource(
data=dict(x=[ -8800000, -8500000 , -8800000],
y=[4200000, 4500000, 4900000])
)
p.circle(x="x", y="y", size=15, fill_color="blue", fill_alpha=0.8, source=source)
# create an html document that embeds the Bokeh plot
html = file_html(p, CDN, "my plot1")
# display this html
displayHTML(html)
Secara plot
Anda dapat merender HTML atau pustaka interaktif seperti Plotly, menggunakan displayHTML().
Untuk menggambar gambar ini, jalankan kode sampel berikut.

from urllib.request import urlopen
import json
with urlopen('https://raw.githubusercontent.com/plotly/datasets/master/geojson-counties-fips.json') as response:
counties = json.load(response)
import pandas as pd
df = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/fips-unemp-16.csv",
dtype={"fips": str})
import plotly
import plotly.express as px
fig = px.choropleth(df, geojson=counties, locations='fips', color='unemp',
color_continuous_scale="Viridis",
range_color=(0, 12),
scope="usa",
labels={'unemp':'unemployment rate'}
)
fig.update_layout(margin={"r":0,"t":0,"l":0,"b":0})
# create an html document that embeds the Plotly plot
h = plotly.offline.plot(fig, output_type='div')
# display this html
displayHTML(h)
Panda
Anda dapat melihat output HTML dari Pandas DataFrames sebagai output default. Notebook Fabric secara otomatis memperlihatkan konten HTML yang ditata.

import pandas as pd
import numpy as np
df = pd.DataFrame([[38.0, 2.0, 18.0, 22.0, 21, np.nan],[19, 439, 6, 452, 226,232]],
index=pd.Index(['Tumour (Positive)', 'Non-Tumour (Negative)'], name='Actual Label:'),
columns=pd.MultiIndex.from_product([['Decision Tree', 'Regression', 'Random'],['Tumour', 'Non-Tumour']], names=['Model:', 'Predicted:']))
df