Tujuan data Aliran Data Gen2 dan pengaturan terkelola
Setelah membersihkan dan menyiapkan data dengan Dataflow Gen2, Anda ingin mendaratkan data Anda di tujuan. Anda dapat melakukan ini menggunakan kemampuan tujuan data di Dataflow Gen2. Dengan kemampuan ini, Anda dapat memilih dari berbagai tujuan, seperti Azure SQL, Fabric Lakehouse, dan banyak lagi. Dataflow Gen2 kemudian menulis data Anda ke tujuan, dan dari sana Anda dapat menggunakan data Anda untuk analisis dan pelaporan lebih lanjut.
Daftar berikut berisi tujuan data yang didukung.
- Database Azure SQL
- Azure Data Explorer (Kusto)
- Fabric Lakehouse
- Gudang Fabric
- Database Fabric KQL
- Database Fabric SQL
Titik masuk
Setiap kueri data di Dataflow Gen2 Anda bisa memiliki tujuan data. Fungsi dan daftar tidak didukung; Anda hanya dapat menerapkannya ke kueri tabular. Anda dapat menentukan tujuan data untuk setiap kueri satu per satu, dan Anda bisa menggunakan beberapa tujuan yang berbeda dalam aliran data.
Ada tiga titik masuk utama untuk menentukan tujuan data:
Melalui pita atas.
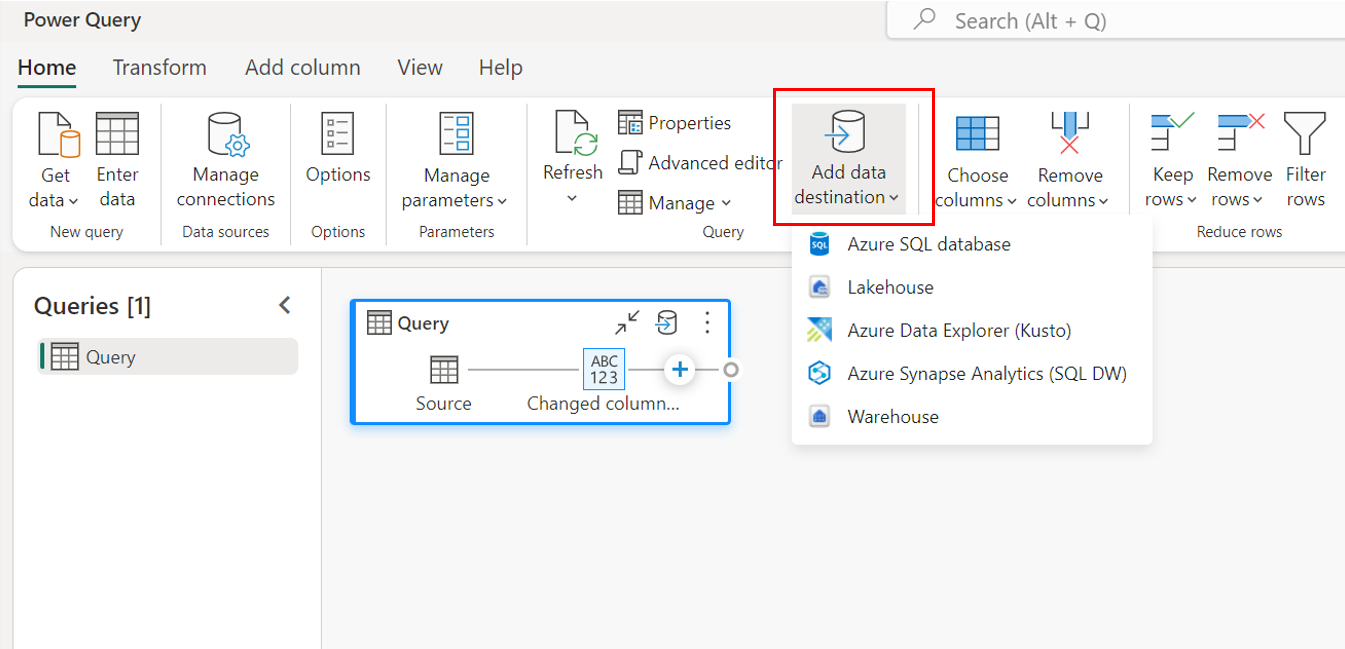
Melalui pengaturan kueri.
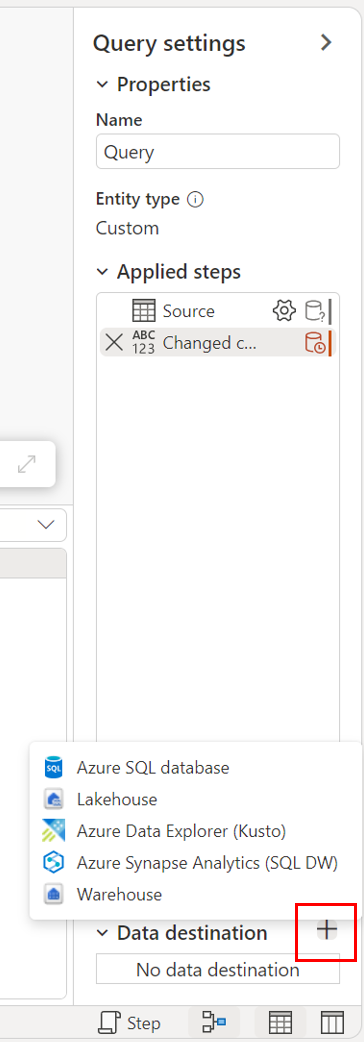
Melalui tampilan diagram.
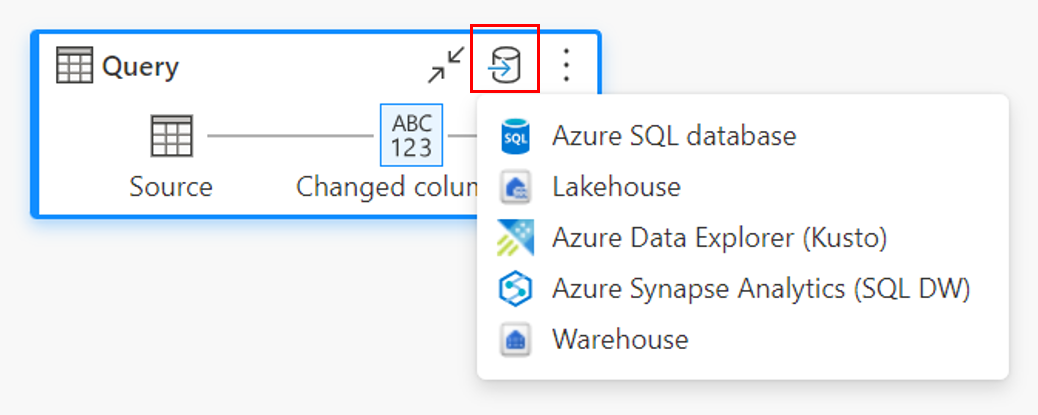
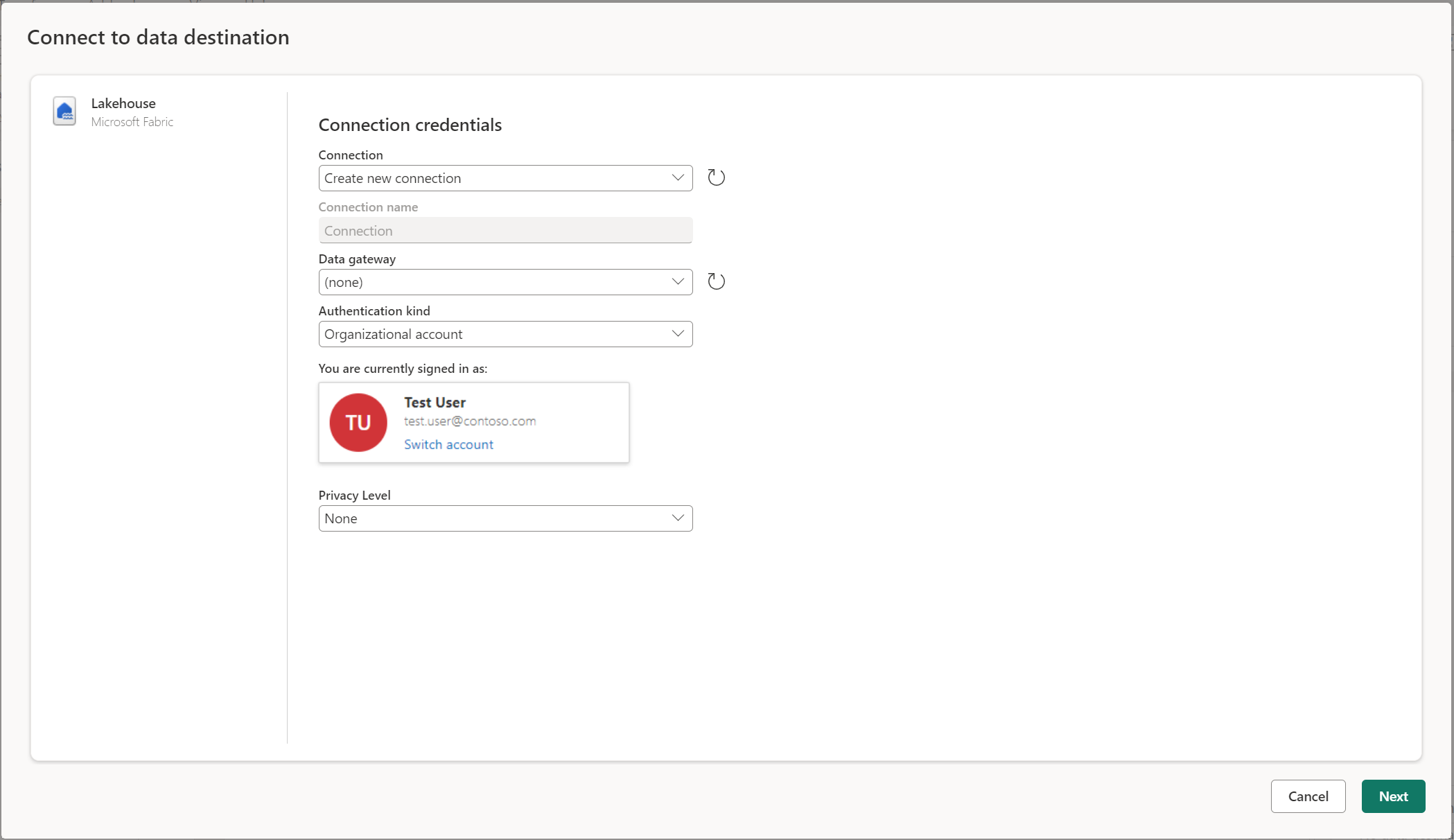
Menyambungkan ke tujuan data
Menyambungkan ke tujuan data mirip dengan menyambungkan ke sumber data. Koneksi dapat digunakan untuk membaca dan menulis data Anda, mengingat Anda memiliki izin yang tepat pada sumber data. Anda perlu membuat koneksi baru atau memilih koneksi yang sudah ada, lalu pilih Berikutnya.
Membuat tabel baru atau memilih tabel yang sudah ada
Saat memuat ke tujuan data, Anda dapat membuat tabel baru atau memilih tabel yang sudah ada.
Membuat tabel baru
Saat Anda memilih untuk membuat tabel baru, selama refresh Dataflow Gen2 tabel baru dibuat di tujuan data Anda. Jika tabel dihapus di masa mendatang dengan masuk secara manual ke tujuan, aliran data membuat ulang tabel selama refresh aliran data berikutnya.
Secara default, nama tabel Anda memiliki nama yang sama dengan nama kueri Anda. Jika Anda memiliki karakter yang tidak valid dalam nama tabel yang tidak didukung tujuan, nama tabel akan disesuaikan secara otomatis. Misalnya, banyak tujuan tidak mendukung spasi atau karakter khusus.
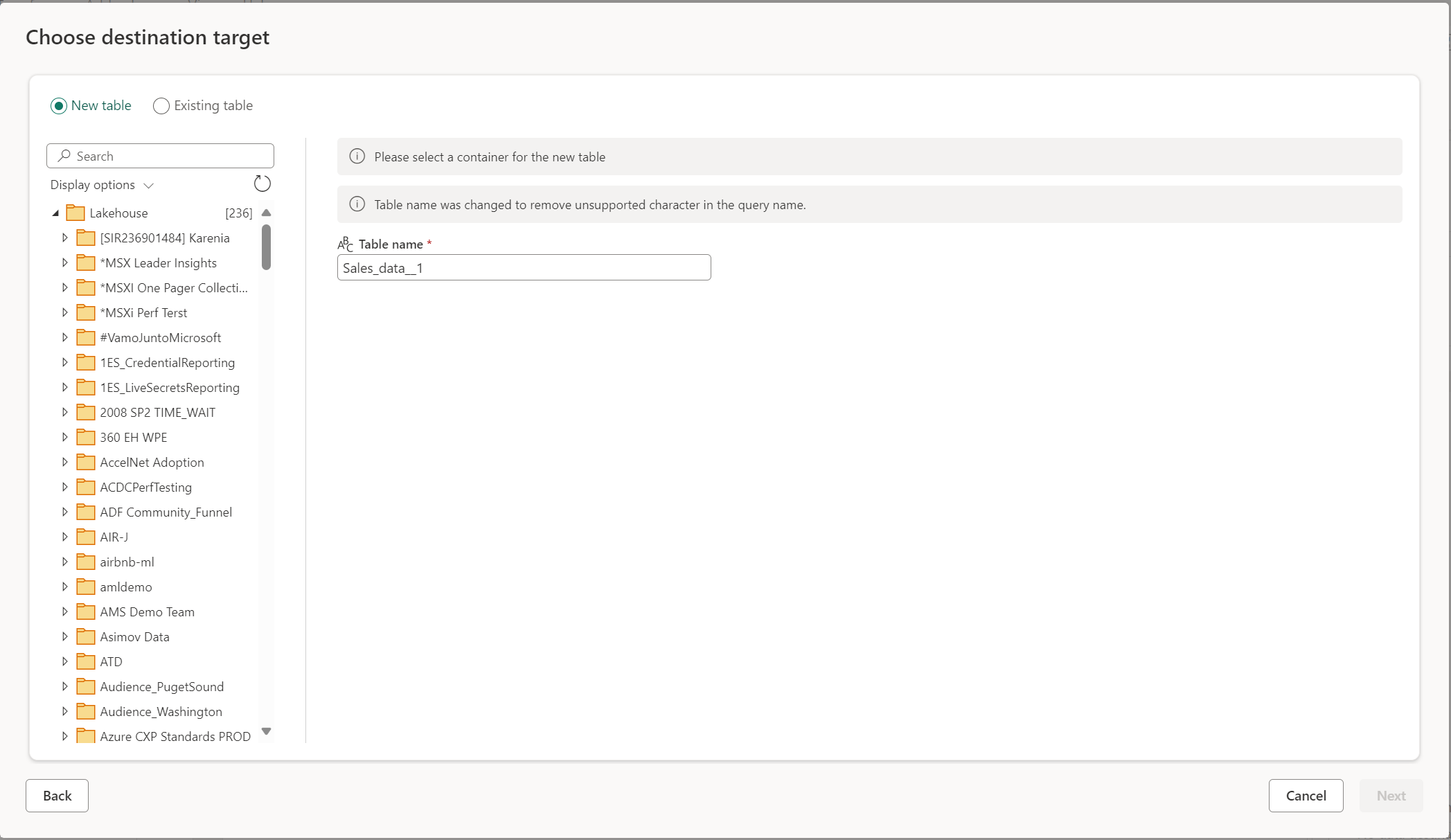
Selanjutnya, Anda harus memilih kontainer tujuan. Jika Anda memilih salah satu tujuan data Fabric, Anda dapat menggunakan navigator untuk memilih artefak Fabric yang ingin Anda muat data Anda. Untuk tujuan Azure, Anda dapat menentukan database selama pembuatan koneksi, atau memilih database dari pengalaman navigator.
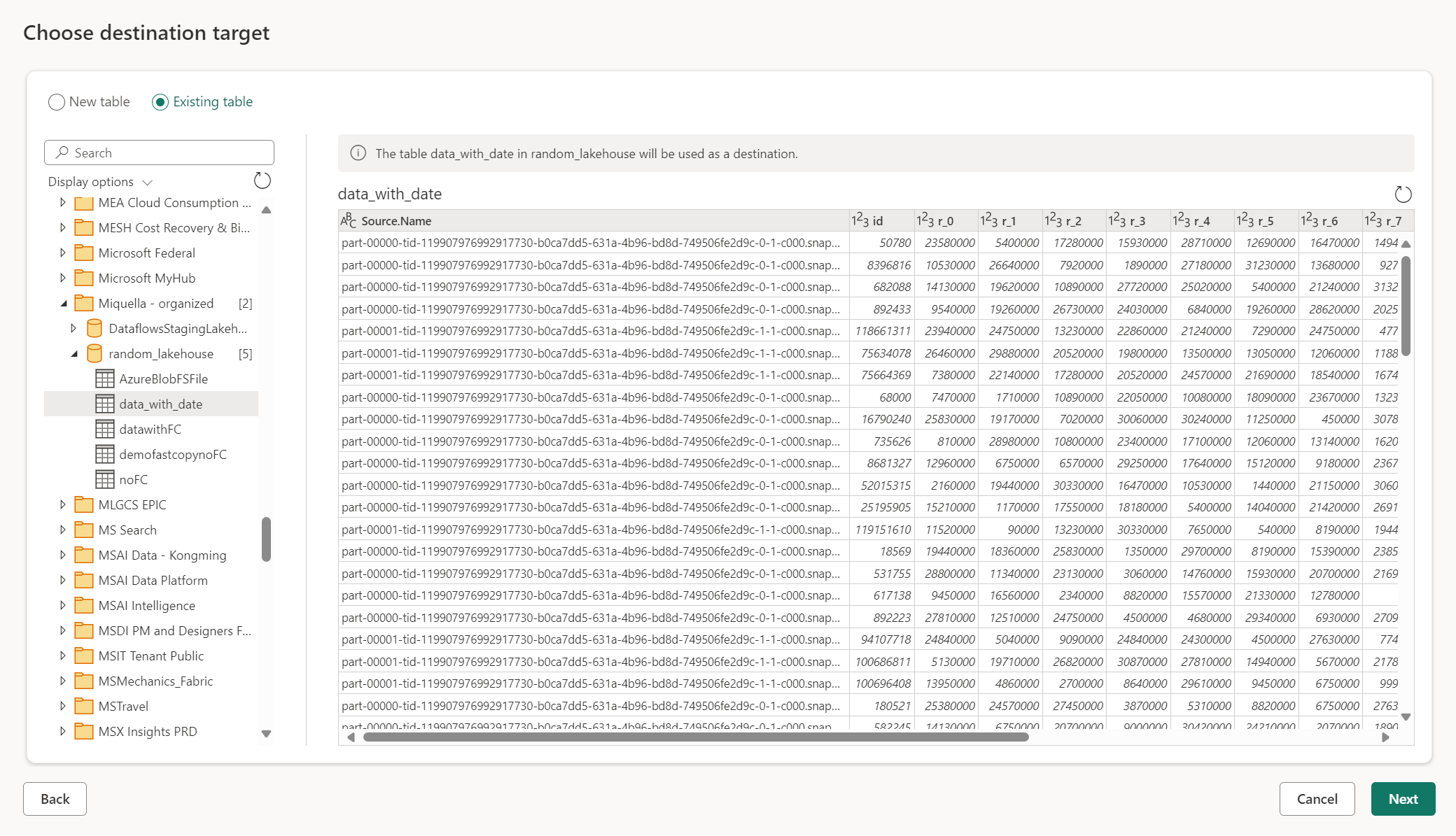
Menggunakan tabel yang sudah ada
Untuk memilih tabel yang sudah ada, gunakan tombol di bagian atas navigator. Saat memilih tabel yang ada, Anda perlu memilih artefak/database Fabric dan tabel menggunakan navigator.
Saat Anda menggunakan tabel yang sudah ada, tabel tidak dapat dibuat ulang dalam skenario apa pun. Jika Anda menghapus tabel secara manual dari tujuan data, Dataflow Gen2 tidak membuat ulang tabel pada refresh berikutnya.
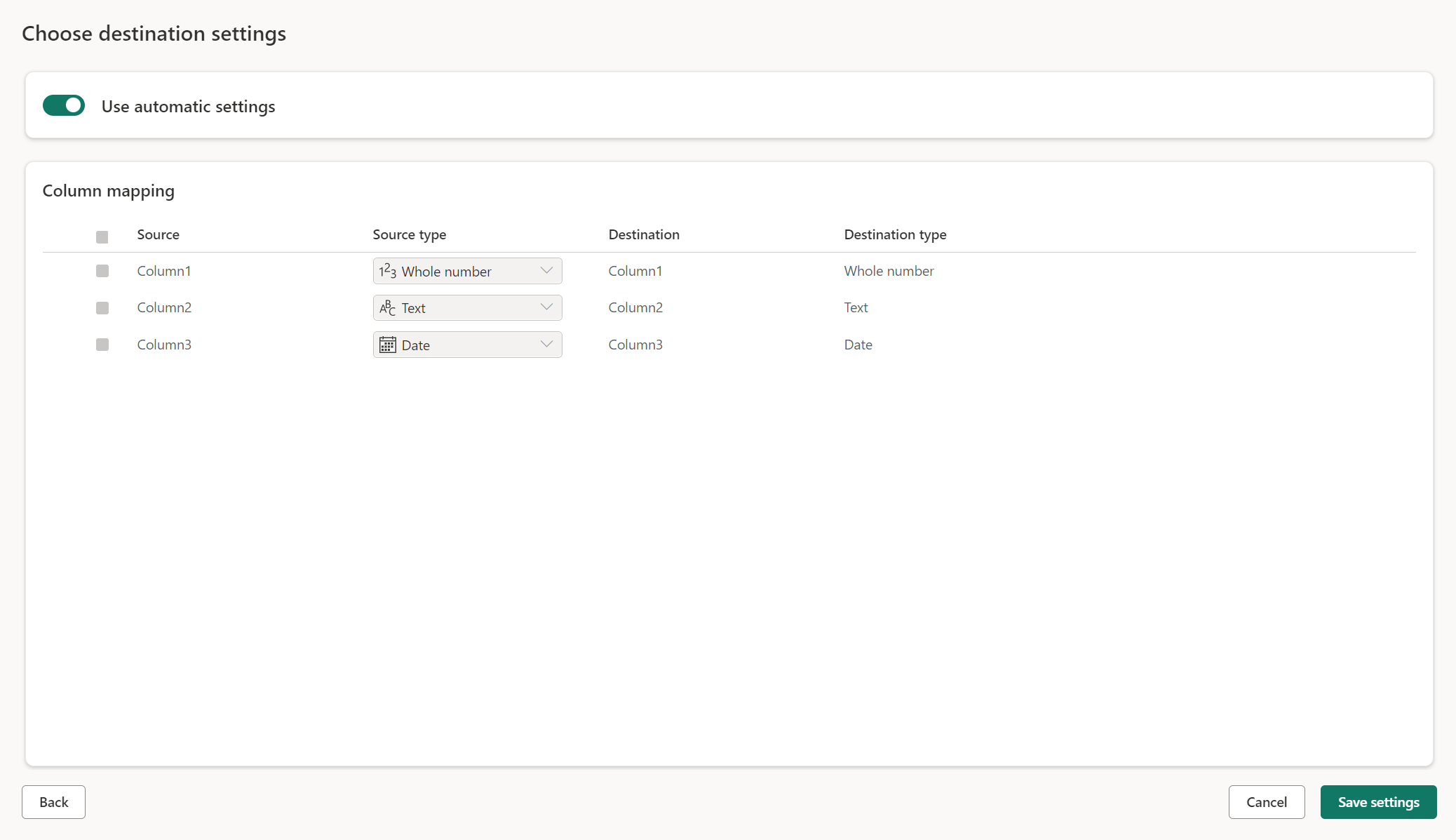
Pengaturan terkelola untuk tabel baru
Saat Anda memuat ke tabel baru, pengaturan otomatis aktif secara default. Jika Anda menggunakan pengaturan otomatis, Dataflow Gen2 mengelola pemetaan untuk Anda. Pengaturan otomatis menyediakan perilaku berikut:
Ganti metode pembaruan: Data diganti di setiap refresh aliran data. Data apa pun di tujuan dihapus. Data di tujuan diganti dengan data output aliran data.
Pemetaan terkelola: Pemetaan dikelola untuk Anda. Saat Anda perlu membuat perubahan pada data/kueri Anda untuk menambahkan kolom lain atau mengubah tipe data, pemetaan secara otomatis disesuaikan untuk perubahan ini saat Anda menerbitkan ulang aliran data Anda. Anda tidak perlu masuk ke pengalaman tujuan data setiap kali Anda membuat perubahan pada aliran data Anda, memungkinkan perubahan skema yang mudah saat Anda menerbitkan ulang aliran data.
Jatuhkan dan buat ulang tabel: Untuk memungkinkan perubahan skema ini, pada setiap aliran data refresh tabel dihilangkan dan dibuat ulang. Refresh aliran data Anda dapat menyebabkan penghapusan hubungan atau pengukuran yang ditambahkan sebelumnya ke tabel Anda.
Catatan
Saat ini, pengaturan otomatis hanya didukung untuk database Lakehouse dan Azure SQL sebagai tujuan data.
Pengaturan manual
Dengan beralih Gunakan pengaturan otomatis, Anda mendapatkan kontrol penuh atas cara memuat data Anda ke tujuan data. Anda dapat membuat perubahan apa pun pada pemetaan kolom dengan mengubah jenis sumber atau mengecualikan kolom apa pun yang tidak Anda butuhkan di tujuan data Anda.
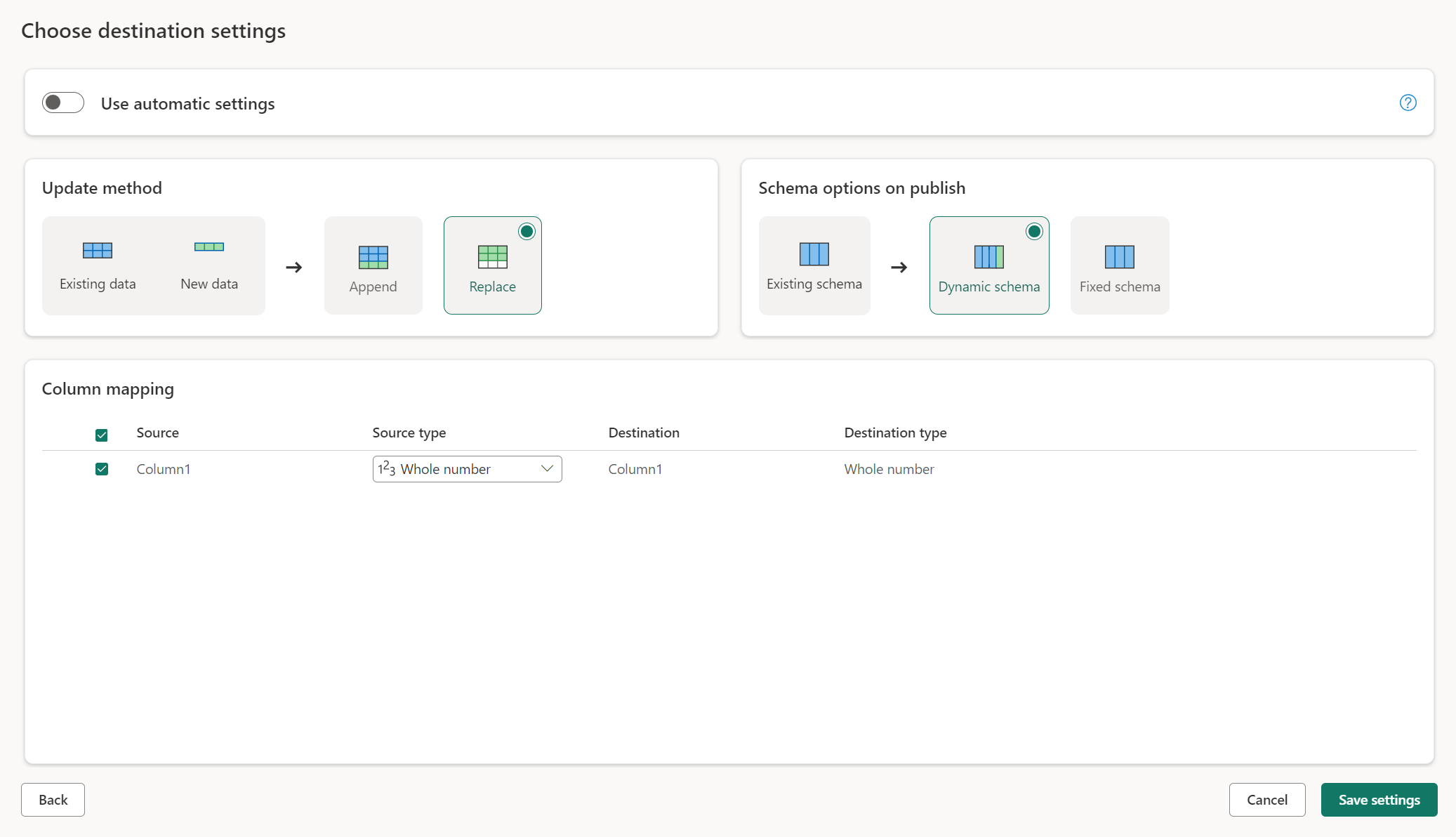
Memperbarui metode
Sebagian besar tujuan mendukung penambah dan penggantian sebagai metode pembaruan. Namun, database Fabric KQL dan Azure Data Explorer tidak mendukung penggantian sebagai metode pembaruan.
Ganti: Pada setiap refresh aliran data, data Anda dihilangkan dari tujuan dan digantikan oleh data output aliran data.
Tambahkan: Pada setiap refresh aliran data, data output dari aliran data ditambahkan ke data yang ada dalam tabel tujuan data.
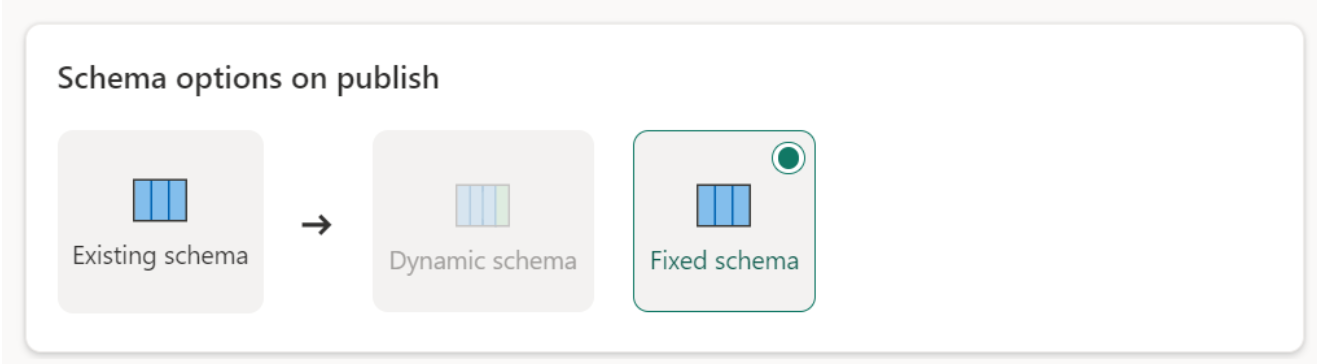
Opsi skema saat menerbitkan
Opsi skema pada publikasi hanya berlaku ketika metode pembaruan diganti. Saat Anda menambahkan data, perubahan pada skema tidak dimungkinkan.
Skema dinamis: Saat memilih skema dinamis, Anda mengizinkan perubahan skema di tujuan data saat Anda menerbitkan ulang aliran data. Karena Anda tidak menggunakan pemetaan terkelola, Anda masih perlu memperbarui pemetaan kolom di alur tujuan aliran data saat Anda membuat perubahan apa pun pada kueri Anda. Saat aliran data disegarkan, tabel Anda dihilangkan dan dibuat ulang. Refresh aliran data Anda dapat menyebabkan penghapusan hubungan atau pengukuran yang ditambahkan sebelumnya ke tabel Anda.
Skema tetap: Saat Anda memilih skema tetap, perubahan skema tidak dimungkinkan. Saat aliran data disegarkan, hanya baris dalam tabel yang dihilangkan dan diganti dengan data output dari aliran data. Hubungan atau ukuran apa pun pada tabel tetap utuh. Jika Anda membuat perubahan pada kueri Anda dalam aliran data, penerbitan aliran data gagal jika mendeteksi bahwa skema kueri tidak cocok dengan skema tujuan data. Gunakan pengaturan ini saat Anda tidak berencana untuk mengubah skema dan memiliki hubungan atau pengukuran yang ditambahkan ke tabel tujuan Anda.
Catatan
Saat memuat data ke gudang, hanya skema tetap yang didukung.
Jenis sumber data yang didukung per tujuan
| Jenis data yang didukung per lokasi penyimpanan | DataflowStagingLakehouse | Azure DB (SQL) Output | Azure Data Explorer Output | Fabric Lakehouse (LH) Output | Fabric Warehouse (WH) Output | Fabric SQL Database (SQL) Output |
|---|---|---|---|---|---|---|
| Perbuatan | Tidak | No | No | No | No | Tidak |
| Mana pun | Tidak | No | No | No | No | Tidak |
| Biner | Tidak | No | No | No | No | Tidak |
| Mata Uang | Ya | Ya | Ya | Ya | No | Ya |
| Zona Tanggal Waktu | Ya | Ya | Ya | No | No | Ya |
| Durasi | Tidak | No | Ya | No | No | Tidak |
| Fungsi | Tidak | No | No | No | No | Tidak |
| Tidak | Tidak | No | No | No | No | Tidak |
| Null | Tidak | No | No | No | No | Tidak |
| Waktu | Ya | Ya | No | No | No | Ya |
| Jenis | Tidak | No | No | No | No | Tidak |
| Terstruktur (Daftar, Rekaman, Tabel) | Tidak | No | No | No | No | Tidak |
Topik tingkat lanjut
Menggunakan penahapan sebelum memuat ke tujuan
Untuk meningkatkan performa pemrosesan kueri, penahapan dapat digunakan dalam Aliran Data Gen2 untuk menggunakan komputasi Fabric untuk menjalankan kueri Anda.
Saat penahapan diaktifkan pada kueri Anda (perilaku default), data Anda dimuat ke lokasi penahapan, yang merupakan Lakehouse internal yang hanya dapat diakses oleh aliran data itu sendiri.
Menggunakan lokasi penahapan dapat meningkatkan performa dalam beberapa kasus di mana melipat kueri ke titik akhir analitik SQL lebih cepat daripada dalam pemrosesan memori.
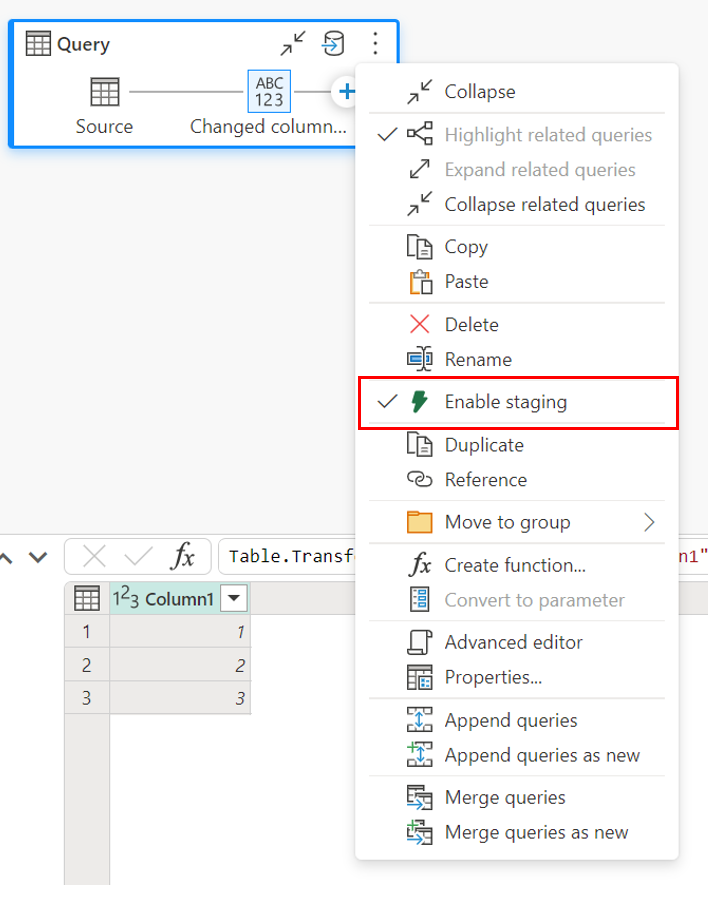
Saat Anda memuat data ke Lakehouse atau tujuan non-gudang lainnya, kami secara default menonaktifkan fitur penahapan untuk meningkatkan performa. Saat Anda memuat data ke tujuan data, data langsung ditulis ke tujuan data tanpa menggunakan penahapan. Jika Anda ingin menggunakan penahapan untuk kueri, Anda bisa mengaktifkannya lagi.
Untuk mengaktifkan penahapan, klik kanan pada kueri dan aktifkan penahapan dengan memilih tombol Aktifkan penahapan . Kueri Anda kemudian berubah menjadi biru.
Memuat data ke gudang
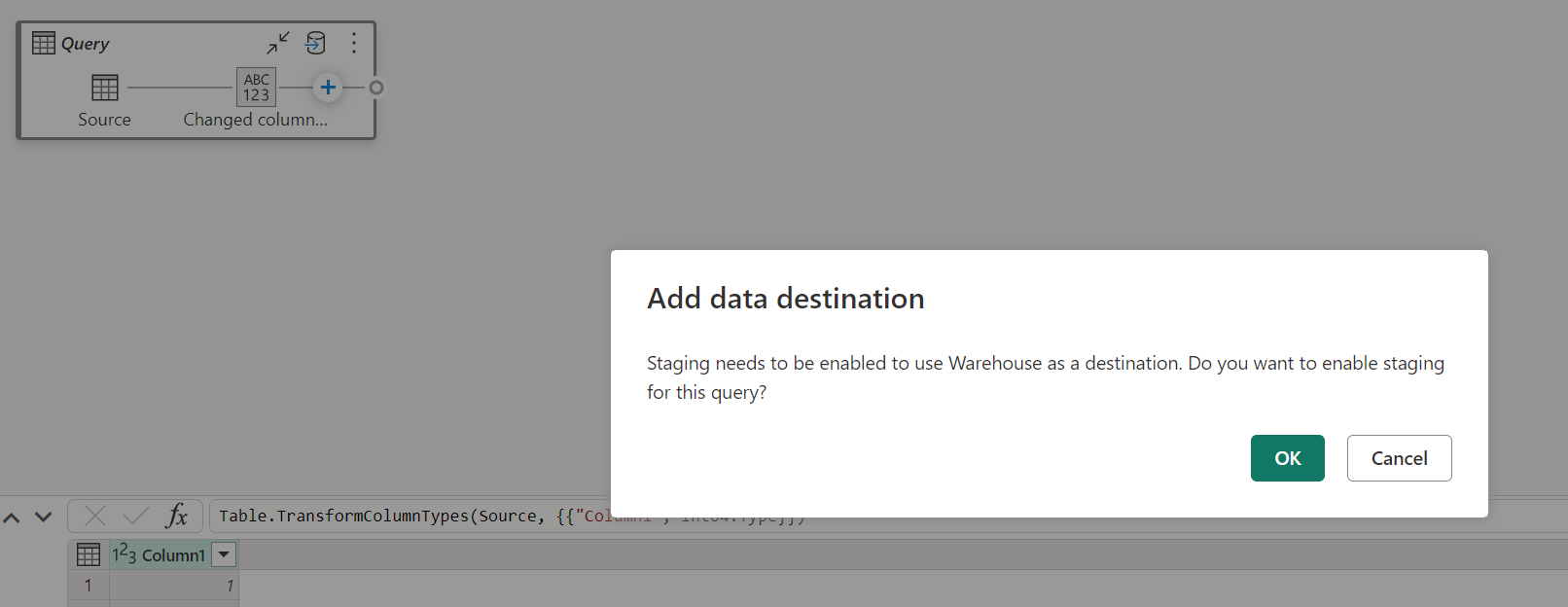
Saat Anda memuat data ke Gudang, penahapan diperlukan sebelum operasi tulis ke tujuan data. Persyaratan ini meningkatkan performa. Saat ini, hanya memuat ke ruang kerja yang sama dengan aliran data yang didukung. Pastikan penahapan diaktifkan untuk semua kueri yang dimuat ke gudang.
Saat penahapan dinonaktifkan, dan Anda memilih Gudang sebagai tujuan output, Anda mendapatkan peringatan untuk mengaktifkan penahapan terlebih dahulu sebelum Anda dapat mengonfigurasi tujuan data.
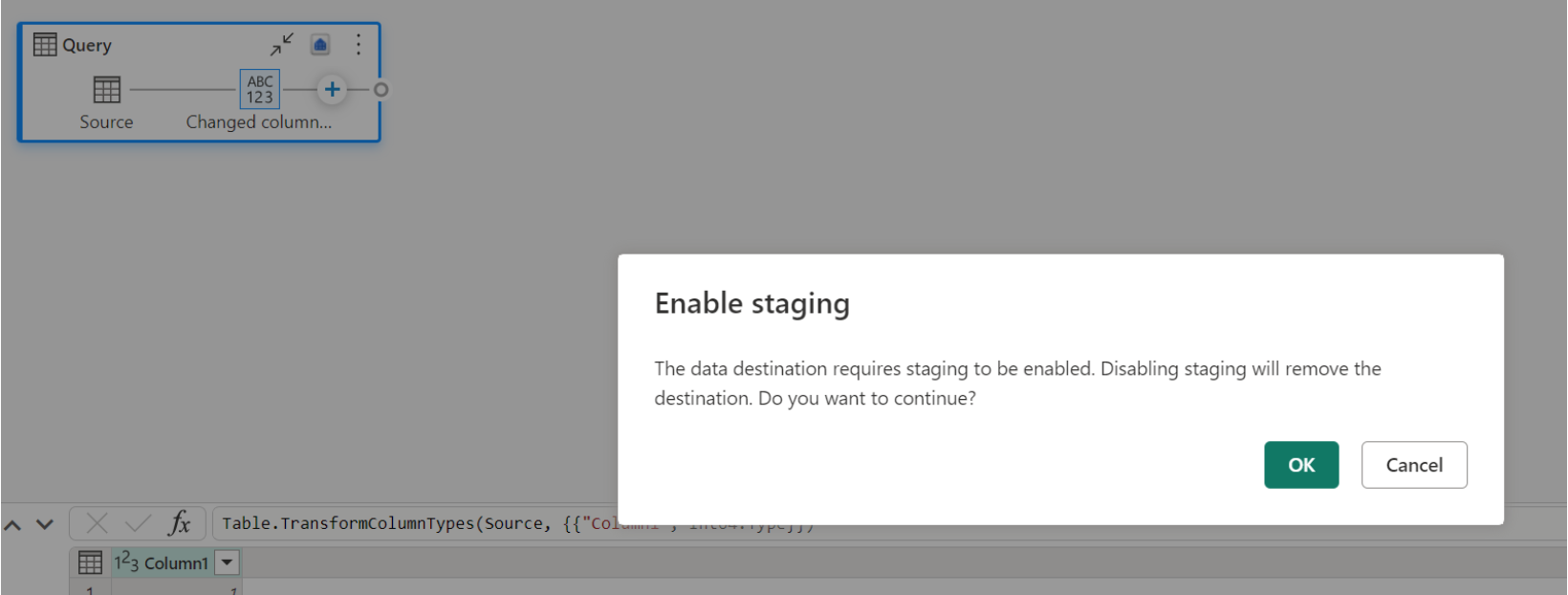
Jika Anda sudah memiliki gudang sebagai tujuan dan mencoba menonaktifkan penahapan, peringatan akan ditampilkan. Anda dapat menghapus gudang sebagai tujuan atau menutup tindakan penahapan.
Menyedot data tujuan Lakehouse Anda
Saat menggunakan Lakehouse sebagai tujuan untuk Dataflow Gen2 di Microsoft Fabric, sangat penting untuk melakukan pemeliharaan rutin untuk memastikan performa optimal dan manajemen penyimpanan yang efisien. Salah satu tugas pemeliharaan penting adalah menyedot vakum tujuan data Anda. Proses ini membantu menghapus file lama yang tidak lagi direferensikan oleh log tabel Delta, sehingga mengoptimalkan biaya penyimpanan dan mempertahankan integritas data Anda.
Mengapa menyedot debu itu penting
- Pengoptimalan Penyimpanan: Seiring waktu, tabel Delta mengumpulkan file lama yang tidak lagi diperlukan. Menyedot debu membantu membersihkan file-file ini, membebaskan ruang penyimpanan dan mengurangi biaya.
- Peningkatan Performa: Menghapus file yang tidak perlu dapat meningkatkan performa kueri dengan mengurangi jumlah file yang perlu dipindai selama operasi baca.
- Integritas Data: Memastikan bahwa hanya file yang relevan yang dipertahankan yang membantu menjaga integritas data Anda, mencegah potensi masalah dengan file yang tidak dilakukan yang dapat menyebabkan kegagalan pembaca atau kerusakan tabel.
Cara menyedot data tujuan Anda
Untuk menyedot tabel Delta Anda di Lakehouse, ikuti langkah-langkah berikut:
- Navigasi ke Lakehouse Anda: Dari akun Microsoft Fabric Anda, buka Lakehouse yang diinginkan.
- Pemeliharaan tabel akses: Di penjelajah Lakehouse, klik kanan pada tabel yang ingin Anda pertahankan atau gunakan elipsis untuk mengakses menu kontekstual.
- Pilih opsi pemeliharaan: Pilih entri menu Pemeliharaan dan pilih opsi Vakum .
- Jalankan perintah vakum: Atur ambang retensi (defaultnya adalah tujuh hari) dan jalankan perintah vakum dengan memilih Jalankan sekarang.
Praktik terbaik
- Periode retensi: Tetapkan interval retensi setidaknya tujuh hari untuk memastikan bahwa rekam jepret lama dan file yang tidak dikomit tidak dihapus sebelumnya, yang dapat mengganggu pembaca dan penulis tabel bersamaan.
- Pemeliharaan rutin: Jadwalkan vakum reguler sebagai bagian dari rutinitas pemeliharaan data Anda untuk menjaga tabel Delta Anda tetap optimal dan siap untuk analitik.
Dengan menggabungkan vakum ke dalam strategi pemeliharaan data, Anda dapat memastikan bahwa tujuan Lakehouse Anda tetap efisien, hemat biaya, dan dapat diandalkan untuk operasi aliran data Anda.
Untuk informasi selengkapnya tentang pemeliharaan tabel di Lakehouse, lihat dokumentasi pemeliharaan tabel Delta.
Dapat diubah ke null
Dalam beberapa kasus saat Anda memiliki kolom yang dapat diubah ke null, kolom akan terdeteksi oleh Power Query sebagai tidak dapat diubah ke null dan saat menulis ke tujuan data, tipe kolom tidak dapat diubah ke null. Selama refresh, kesalahan berikut terjadi:
E104100 Couldn't refresh entity because of an issue with the mashup document MashupException.Error: DataFormat.Error: Error in replacing table's content with new data in a version: #{0}., InnerException: We can't insert null data into a non-nullable column., Underlying error: We can't insert null data into a non-nullable column. Details: Reason = DataFormat.Error;Message = We can't insert null data into a non-nullable column.; Message.Format = we can't insert null data into a non-nullable column.
Untuk memaksa kolom nullable, Anda bisa mencoba langkah-langkah berikut:
Hapus tabel dari tujuan data.
Hapus tujuan data dari aliran data.
Masuk ke aliran data dan perbarui tipe data dengan menggunakan kode Power Query berikut:
Table.TransformColumnTypes( #"PREVIOUS STEP", { {"COLLUMNNAME1", type nullable text}, {"COLLUMNNAME2", type nullable Int64.Type} } )Tambahkan tujuan data.
Konversi dan peningkatan jenis data
Dalam beberapa kasus, jenis data dalam aliran data berbeda dari apa yang didukung di tujuan data di bawah ini adalah beberapa konversi default yang telah kami terapkan untuk memastikan Anda masih bisa mendapatkan data Anda di tujuan data:
| Tujuan | Datatype Aliran Data | Tipe Data Tujuan |
|---|---|---|
| Gudang Fabric | Int8.Type | Int16.Type |