Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Model pembelajaran mesin adalah file yang dilatih untuk mengenali jenis pola tertentu. Anda melatih model melalui sekumpulan data, dan Anda menyediakannya dengan algoritma yang digunakan untuk alasan dan belajar dari himpunan data tersebut. Setelah melatih model, Anda dapat menggunakannya untuk alasan atas data yang tidak pernah dilihat sebelumnya, dan membuat prediksi tentang data tersebut.
Dalam MLflow, model pembelajaran mesin dapat menyertakan beberapa versi model. Di sini, setiap versi dapat mewakili iterasi model. Dalam artikel ini, Anda mempelajari cara berinteraksi dengan model ML untuk melacak dan membandingkan iterasi model.
Dalam artikel ini, Anda mempelajari cara:
- Membuat model pembelajaran mesin di Microsoft Fabric
- Mengelola dan melacak versi model
- Membandingkan performa model di seluruh versi
- Menerapkan model untuk penilaian dan inferensi
Membuat model pembelajaran mesin
Anda dapat membuat model pembelajaran mesin dari Fabric UI atau secara terprogram dengan API MLflow. Dalam MLflow, model menggunakan format kemasan standar yang berfungsi dengan berbagai alat hilir, termasuk inferensi batch pada Apache Spark. Format menyimpan model dalam "rasa" yang berbeda yang dapat dipahami oleh alat hilir yang berbeda.
Untuk membuat model pembelajaran mesin dari UI:
- Pilih ruang kerja ilmu data yang sudah ada, atau buat ruang kerja baru.
- Buat item baru melalui ruang kerja atau dengan menggunakan tombol Buat:
- Ruang Kerja
- Pilih ruang kerja Anda.
- Pilih Item baru.
- Pilih Model ML di bawah Analisis dan latih data.
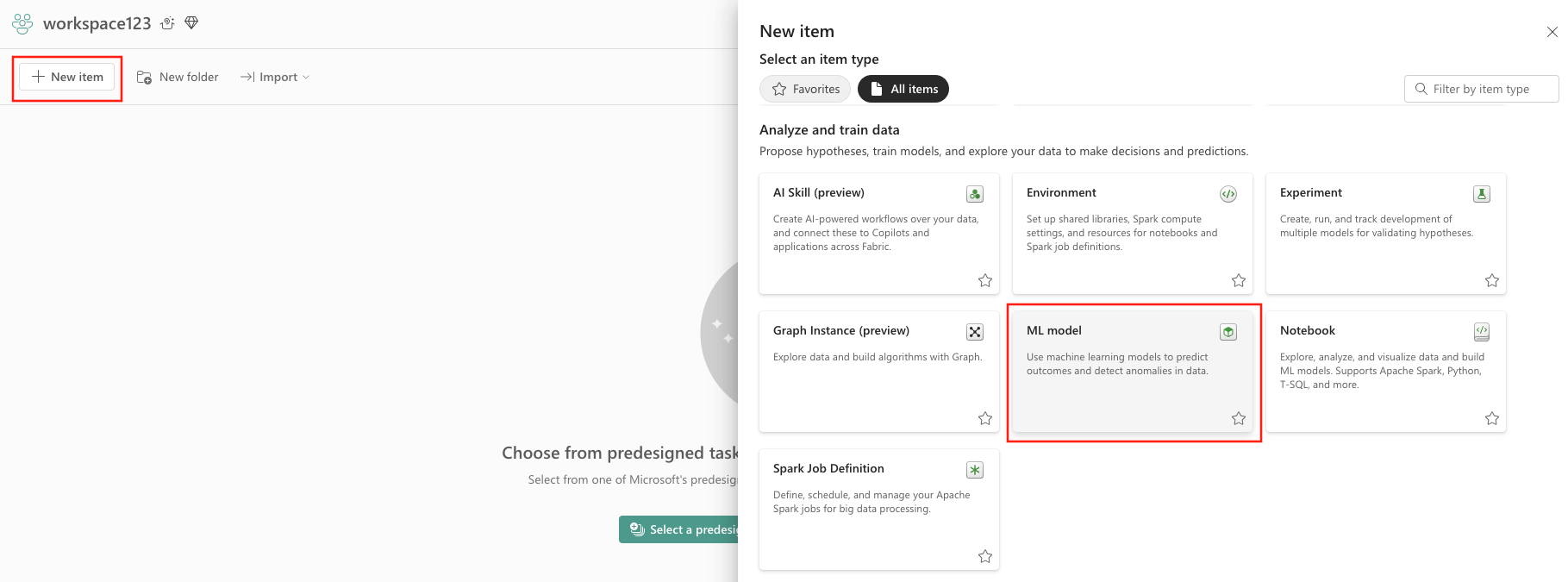
- Tombol Buat:
- Pilih Buat, yang dapat ditemukan di ... dari menu vertikal.
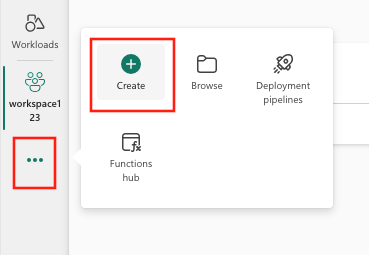
- Pilih Model ML di bawah Ilmu Data.

- Pilih Buat, yang dapat ditemukan di ... dari menu vertikal.
- Ruang Kerja
- Setelah pembuatan model, Anda dapat mulai menambahkan versi model untuk melacak metrik dan parameter eksekusi. Daftarkan atau simpan eksekusi eksperimen ke model yang ada.



Anda juga dapat membuat model pembelajaran mesin langsung dari pengalaman penulisan Anda dengan mlflow.register_model() API. Jika model pembelajaran mesin terdaftar dengan nama yang diberikan tidak ada, API membuatnya secara otomatis.
import mlflow
model_uri = "runs:/{}/model-uri-name".format(run.info.run_id)
mv = mlflow.register_model(model_uri, "model-name")
print("Name: {}".format(mv.name))
print("Version: {}".format(mv.version))
Mengelola versi dalam model pembelajaran mesin
Model pembelajaran mesin berisi kumpulan versi model untuk pelacakan dan perbandingan yang disederhanakan. Dalam model, ilmuwan data dapat menavigasi di berbagai versi model untuk menjelajahi parameter dan metrik yang mendasar. Ilmuwan data juga dapat membuat perbandingan di seluruh versi model untuk mengidentifikasi apakah model yang lebih baru mungkin memberikan hasil yang lebih baik atau tidak.
Melacak model pembelajaran mesin
Versi model pembelajaran mesin mewakili model individual yang terdaftar untuk pelacakan.
![]()
Setiap versi model menyertakan informasi berikut:
| Harta benda | Deskripsi |
|---|---|
| Waktu Dibuat | Tanggal dan waktu pembuatan model. |
| Nama Eksekusi | Pengidentifikasi untuk pelaksanaan eksperimen yang digunakan secara spesifik untuk membuat versi model ini. |
| Hyperparameter | Disimpan sebagai pasangan kunci-nilai. Kunci dan nilai adalah berjenis string. |
| Metrics | Jalankan metrik yang disimpan sebagai pasangan kunci-nilai. Nilainya adalah numerik. |
| Skema/Tanda Tangan Model | Deskripsi input dan output model. |
| File yang dicatat | File yang dicatat dalam format apa pun. Misalnya, Anda dapat merekam gambar, lingkungan, model, dan file data. |
| Tags | Metadata kustom sebagai pasangan kunci-nilai yang dilampirkan pada jalankan. Pelajari cara menerapkan tag. |
Menerapkan tag ke model pembelajaran mesin
Penandaan MLflow untuk versi model memungkinkan pengguna melampirkan metadata kustom ke versi tertentu dari model terdaftar di MLflow Model Registry. Tag ini, disimpan sebagai pasangan kunci-nilai, membantu mengatur, melacak, dan membedakan antara versi model, sehingga lebih mudah untuk mengelola siklus hidup model. Tag dapat digunakan untuk menunjukkan tujuan model, lingkungan penyebaran, atau informasi relevan lainnya, memfasilitasi manajemen model dan pengambilan keputusan yang lebih efisien dalam tim.
Kode ini menunjukkan cara melatih model RandomForestRegressor menggunakan Scikit-learn, mencatat model dan parameter dengan MLflow, lalu mendaftarkan model di MLflow Model Registry dengan tag kustom. Tag ini menyediakan metadata yang berguna, seperti nama proyek, departemen, tim, dan kuartal proyek, sehingga lebih mudah untuk mengelola dan melacak versi model.
import mlflow.sklearn
from mlflow.models import infer_signature
from sklearn.datasets import make_regression
from sklearn.ensemble import RandomForestRegressor
# Generate synthetic regression data
X, y = make_regression(n_features=4, n_informative=2, random_state=0, shuffle=False)
# Model parameters
params = {"n_estimators": 3, "random_state": 42}
# Model tags for MLflow
model_tags = {
"project_name": "grocery-forecasting",
"store_dept": "produce",
"team": "stores-ml",
"project_quarter": "Q3-2023"
}
# Log MLflow entities
with mlflow.start_run() as run:
# Train the model
model = RandomForestRegressor(**params).fit(X, y)
# Infer the model signature
signature = infer_signature(X, model.predict(X))
# Log parameters and the model
mlflow.log_params(params)
mlflow.sklearn.log_model(model, artifact_path="sklearn-model", signature=signature)
# Register the model with tags
model_uri = f"runs:/{run.info.run_id}/sklearn-model"
model_version = mlflow.register_model(model_uri, "RandomForestRegressionModel", tags=model_tags)
# Output model registration details
print(f"Model Name: {model_version.name}")
print(f"Model Version: {model_version.version}")
Setelah menerapkan tag, Anda dapat melihatnya langsung di halaman detail versi model. Selain itu, tag dapat ditambahkan, diperbarui, atau dihapus dari halaman ini kapan saja.

Membandingkan dan memfilter model pembelajaran mesin
Untuk membandingkan dan mengevaluasi kualitas versi model pembelajaran mesin, Anda dapat membandingkan parameter, metrik, dan metadata antara versi yang dipilih.
Membandingkan model pembelajaran mesin secara visual
Anda dapat membandingkan eksekusi secara visual dalam model yang ada. Perbandingan visual memungkinkan navigasi yang mudah di antara beberapa versi serta pengurutan di seluruh versi tersebut.

Untuk membandingkan pengujian, Anda dapat:
- Pilih model pembelajaran mesin yang ada yang berisi beberapa versi.
- Pilih tab Tampilan , lalu navigasikan ke tampilan daftar Model . Anda juga dapat memilih opsi untuk Menampilkan daftar model langsung dari tampilan detail.
- Anda bisa mengkustomisasi kolom dalam tabel. Perluas panel Kustomisasi kolom . Dari sana, Anda dapat memilih properti, metrik, tag, dan hiperparameter yang ingin Anda lihat.
- Terakhir, Anda dapat memilih beberapa versi, untuk membandingkan hasilnya, di panel perbandingan metrik. Dari panel ini, Anda bisa mengkustomisasi bagan dengan perubahan pada judul bagan, jenis visualisasi, sumbu X, sumbu Y, dan lainnya.
Membandingkan model pembelajaran mesin menggunakan API MLflow
Ilmuwan data juga dapat menggunakan MLflow untuk mencari di antara beberapa model yang disimpan dalam ruang kerja. Kunjungi dokumentasi MLflow untuk menjelajahi API MLflow lainnya untuk interaksi model.
from pprint import pprint
from mlflow import MlflowClient
client = MlflowClient()
for rm in client.search_registered_models():
pprint(dict(rm), indent=4)
Menerapkan model pembelajaran mesin
Setelah melatih model pada himpunan data, Anda dapat menerapkan model tersebut ke data yang tidak pernah dilihatnya untuk menghasilkan prediksi. Kami menyebut teknik penggunaan model ini sebagai penilaian atau inferensi.
Fabric mendukung beberapa pendekatan untuk menerapkan model terlatih Anda:
- Penilaian batch Terapkan model Anda dalam skala besar di seluruh himpunan data besar menggunakan Apache Spark. Ini sangat ideal untuk menghasilkan prediksi pada data historis atau terjadwal.
- Penilaian real time Sebarkan model Anda ke titik akhir untuk prediksi sesuai permintaan, berguna untuk aplikasi yang membutuhkan hasil segera.
Untuk mulai menerapkan model Anda, pilih pendekatan yang sesuai dengan skenario Anda:
Konten terkait
- Pantau eksperimen dengan MLflow di Fabric
- Referensi API untuk Eksperimen MLflow
- Mengelola model MLflow di seluruh ruang kerja dan platform