Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Microsoft Fabric memungkinkan Anda mengoprasikan model machine learning dengan menggunakan fungsi PREDICT yang dapat diskalakan. Fungsi ini mendukung penilaian batch di mesin komputasi apa pun. Anda dapat membuat prediksi batch langsung dari buku catatan Microsoft Fabric atau dari halaman item model ML tertentu.
Dalam artikel ini, Anda mempelajari cara menerapkan PREDICT dengan menulis kode sendiri atau melalui penggunaan pengalaman UI terpandu yang menangani penilaian batch untuk Anda.
Prasyarat
Dapatkan langganan Microsoft Fabric. Atau, daftar uji coba Microsoft Fabric gratis.
Masuk ke Microsoft Fabric.
Beralih ke Fabric dengan menggunakan pengalih pengalaman di sisi kiri bawah halaman beranda Anda.

Batasan
- Fungsi PREDICT saat ini hanya mendukung ragam model ML berikut:
- CatBoost
- Keras
- LightGBM
- ONNX
- Nabi
- PyTorch
- Sklearn
- Spark
- Statsmodels
- TensorFlow
- XGBoost
- PREDICT mengharuskan Anda menyimpan model ML dalam format MLflow, dengan tanda tangannya diisi.
- PREDICT tidak mendukung model ML dengan input atau output multi-tensor.
Memanggil PREDICT dari buku catatan
PREDICT mendukung model paket MLflow di registri Microsoft Fabric. Jika model ML yang sudah terlatih dan terdaftar ada di ruang kerja Anda, Anda dapat melompat ke langkah 2. Jika tidak, langkah 1 menyediakan kode sampel untuk memandu Anda melalui pelatihan model regresi logistik sampel. Gunakan model ini untuk menghasilkan prediksi batch di akhir prosedur.
Latih model ML dan daftarkan dengan MLflow. Sampel kode berikutnya menggunakan API MLflow untuk membuat eksperimen machine learning, lalu memulai eksekusi MLflow untuk model regresi logistik scikit-learn. Versi model kemudian disimpan dan didaftarkan di registri Microsoft Fabric. Untuk informasi selengkapnya tentang model pelatihan dan melacak eksperimen Anda sendiri, lihat cara melatih model ML dengan scikit-learn.
import mlflow import numpy as np from sklearn.linear_model import LogisticRegression from sklearn.datasets import load_diabetes from mlflow.models.signature import infer_signature mlflow.set_experiment("diabetes-demo") with mlflow.start_run() as run: lr = LogisticRegression() data = load_diabetes(as_frame=True) lr.fit(data.data, data.target) signature = infer_signature(data.data, data.target) mlflow.sklearn.log_model( lr, "diabetes-model", signature=signature, registered_model_name="diabetes-model" )Muat data uji sebagai Spark DataFrame. Untuk menghasilkan prediksi batch dengan model ML yang dilatih pada langkah sebelumnya, Anda memerlukan data pengujian dalam bentuk Spark DataFrame. Dalam kode berikut, ganti
testnilai variabel dengan data Anda sendiri.# You can substitute "test" below with your own data test = spark.createDataFrame(data.frame.drop(['target'], axis=1))Buat
MLFlowTransformerobjek untuk memuat model ML untuk inferensi. Untuk membuatMLFlowTransformerobjek untuk menghasilkan prediksi batch, lakukan tindakan ini:-
testTentukan kolom DataFrame yang Anda butuhkan sebagai input model (dalam hal ini, semuanya). - Pilih nama untuk kolom output baru (dalam hal ini,
predictions). - Berikan nama model dan versi model yang benar untuk pembuatan prediksi tersebut.
Jika Anda menggunakan model ML Anda sendiri, ganti nilai untuk kolom input, nama kolom output, nama model, dan versi model.
from synapse.ml.predict import MLFlowTransformer # You can substitute values below for your own input columns, # output column name, model name, and model version model = MLFlowTransformer( inputCols=test.columns, outputCol='predictions', modelName='diabetes-model', modelVersion=1 )-
Hasilkan prediksi menggunakan fungsi PREDICT. Untuk memanggil fungsi PREDICT, gunakan TRANSFORMER API, Spark SQL API, atau fungsi yang ditentukan pengguna (UDF) PySpark. Bagian berikut menunjukkan cara menghasilkan prediksi batch dengan data pengujian dan model ML yang ditentukan dalam langkah-langkah sebelumnya, menggunakan metode yang berbeda untuk memanggil fungsi PREDICT.
PREDICT dengan Transformer API
Kode ini memanggil fungsi PREDICT dengan Transformer API. Jika Anda menggunakan model ML Anda sendiri, ganti nilai untuk model dan data pengujian.
# You can substitute "model" and "test" below with values
# for your own model and test data
model.transform(test).show()
PREDICT dengan Spark SQL API
Kode ini memanggil fungsi PREDICT dengan menggunakan Spark SQL API. Jika Anda menggunakan model ML Anda sendiri, ganti nilai untuk model_name, , model_versiondan features dengan nama model, versi model, dan kolom fitur Anda.
Catatan
Saat Anda menggunakan Spark SQL API untuk menghasilkan prediksi, Anda masih perlu membuat objek, seperti yang MLFlowTransformer ditunjukkan pada langkah 3.
from pyspark.ml.feature import SQLTransformer
# You can substitute "model_name," "model_version," and "features"
# with values for your own model name, model version, and feature columns
model_name = 'diabetes-model'
model_version = 1
features = test.columns
sqlt = SQLTransformer().setStatement(
f"SELECT PREDICT('{model_name}/{model_version}', {','.join(features)}) as predictions FROM __THIS__")
# You can substitute "test" below with your own test data
sqlt.transform(test).show()
PREDICT dengan fungsi yang ditentukan pengguna
Kode ini memanggil fungsi PREDICT dengan menggunakan UDF PySpark. Jika Anda menggunakan model ML Anda sendiri, ganti nilai untuk model dan fitur.
from pyspark.sql.functions import col, pandas_udf, udf, lit
# You can substitute "model" and "features" below with your own values
my_udf = model.to_udf()
features = test.columns
test.withColumn("PREDICT", my_udf(*[col(f) for f in features])).show()
Menghasilkan kode PREDICT dari halaman item pada model ML
Dari halaman item model ML apa pun, Anda dapat memilih salah satu opsi ini untuk memulai pembuatan prediksi batch untuk versi model tertentu, dengan menggunakan fungsi PREDICT:
- Salin templat kode ke dalam buku catatan, dan kustomisasi sendiri parameternya.
- Gunakan antarmuka terpandu untuk menghasilkan kode PREDICT.
Menggunakan pengalaman UI didorong
Pengalaman antarmuka pengguna terpandu memandu Anda melalui langkah-langkah berikut:
- Pilih data sumber untuk penilaian.
- Petakan data dengan benar ke input model ML Anda.
- Tentukan tujuan untuk output model Anda.
- Buat buku catatan yang menggunakan PREDICT untuk menghasilkan dan menyimpan hasil prediksi.
Untuk menggunakan pengalaman terpandu,
Navigasi ke halaman item untuk versi model ML tertentu.
Dari menu tarik-turun Terapkan versi ini, pilih Terapkan model ini di wizard.

Pada langkah "Pilih tabel input", jendela "Terapkan prediksi model ML" terbuka.
Pilih tabel input dari lakehouse di lingkungan kerja Anda saat ini.
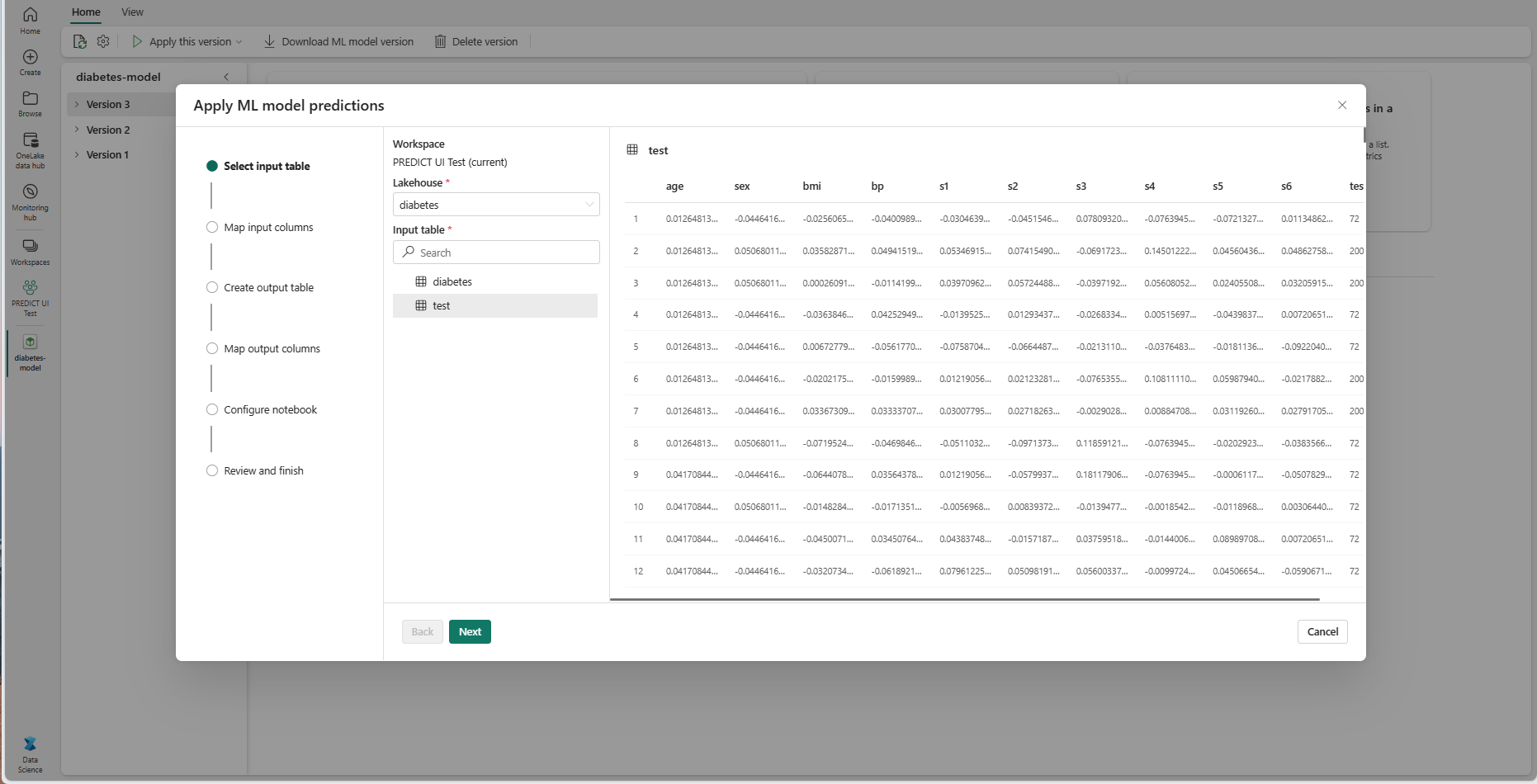
Pilih Berikutnya untuk masuk ke langkah "Petakan kolom input".
Petakan nama kolom dari tabel sumber ke bidang input model ML, yang ditarik dari tanda tangan model. Anda harus menyediakan kolom input untuk semua bidang model yang diperlukan. Selain itu, jenis data kolom sumber harus cocok dengan jenis data model yang diharapkan.
Tip
Wizard secara otomatis mengisi pemetaan ini jika nama kolom tabel input sesuai dengan nama kolom yang tercatat dalam spesifikasi model ML.
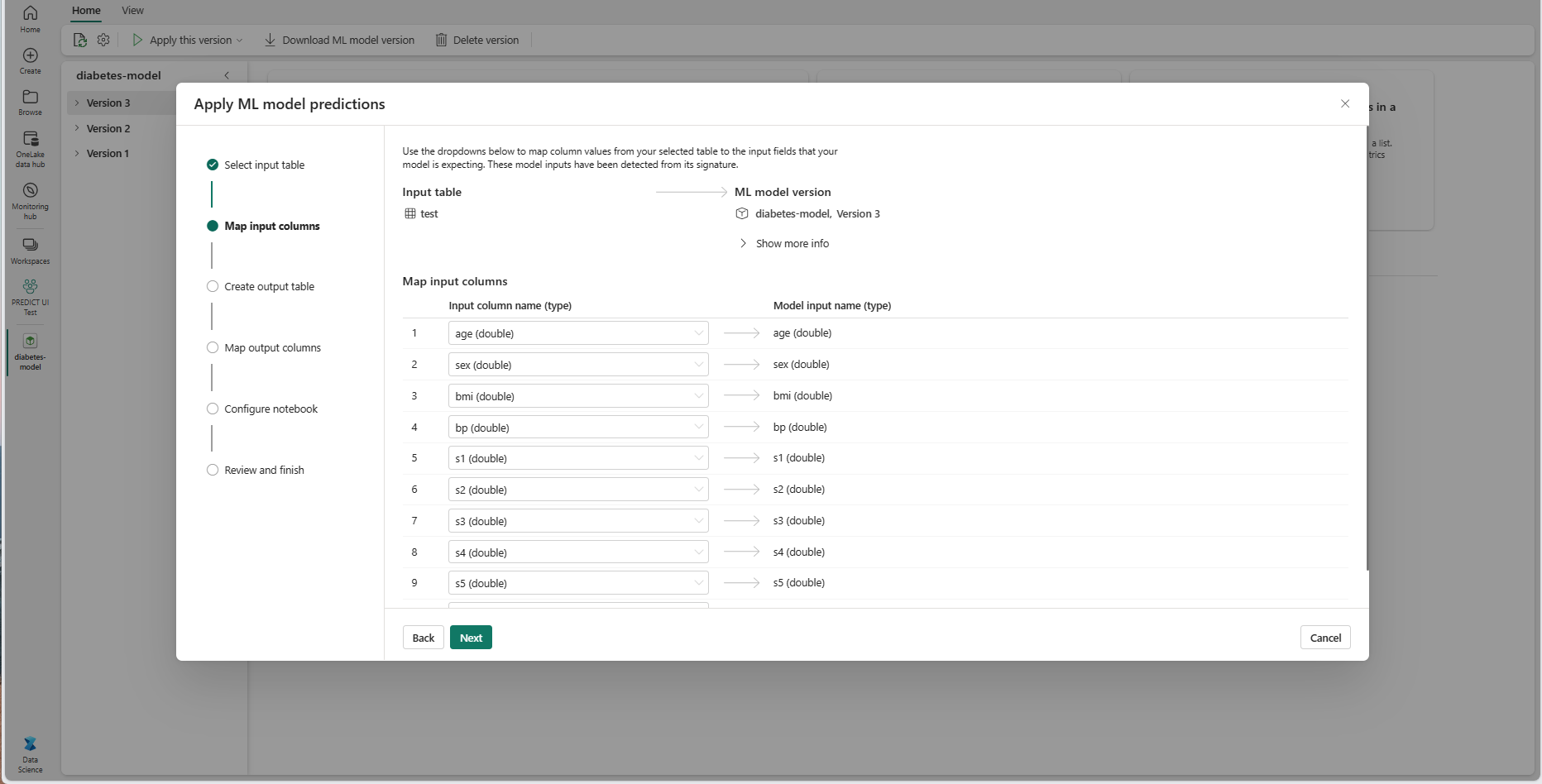
Pilih Berikutnya untuk masuk ke langkah "Buat tabel output".
Berikan nama untuk tabel baru dalam lakehouse yang dipilih dari ruang kerja Anda saat ini. Tabel output ini menyimpan nilai input model ML Anda, dan menambahkan nilai prediksi ke tabel tersebut. Secara default, tabel output dibuat di lakehouse yang sama dengan tabel input. Anda dapat mengubah tujuan lakehouse.

Pilih Berikutnya untuk masuk ke langkah "Petakan kolom output".
Gunakan bidang teks yang disediakan untuk memberi nama kolom tabel output yang menyimpan prediksi model ML.
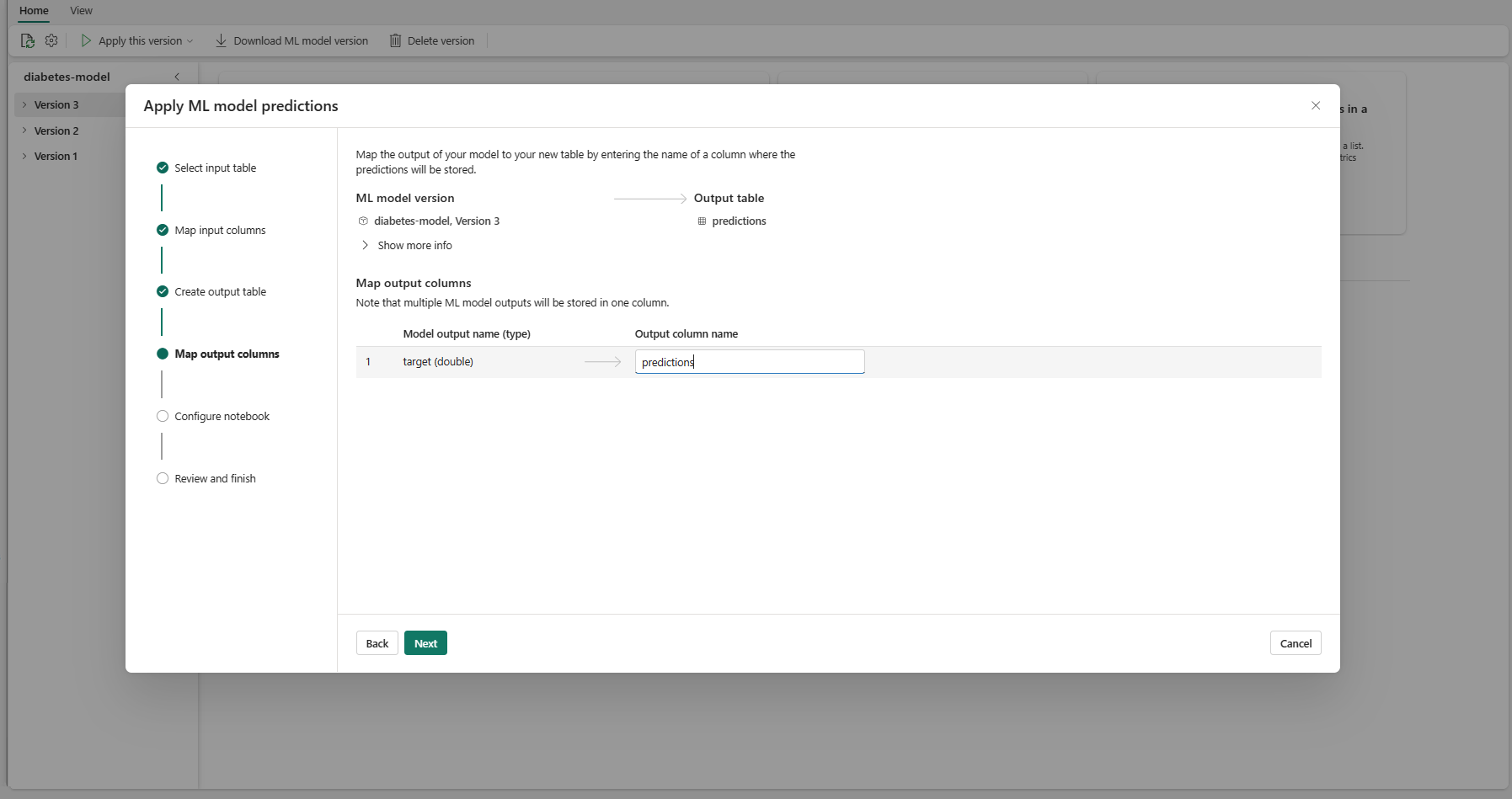
Pilih Berikutnya untuk masuk ke langkah "Konfigurasi buku catatan".
Berikan nama untuk buku catatan baru yang menjalankan kode PREDICT yang dihasilkan. Wizard menampilkan pratinjau kode yang dihasilkan pada langkah ini. Jika mau, Anda bisa menyalin kode ke clipboard Anda dan menempelkannya ke buku catatan yang sudah ada.
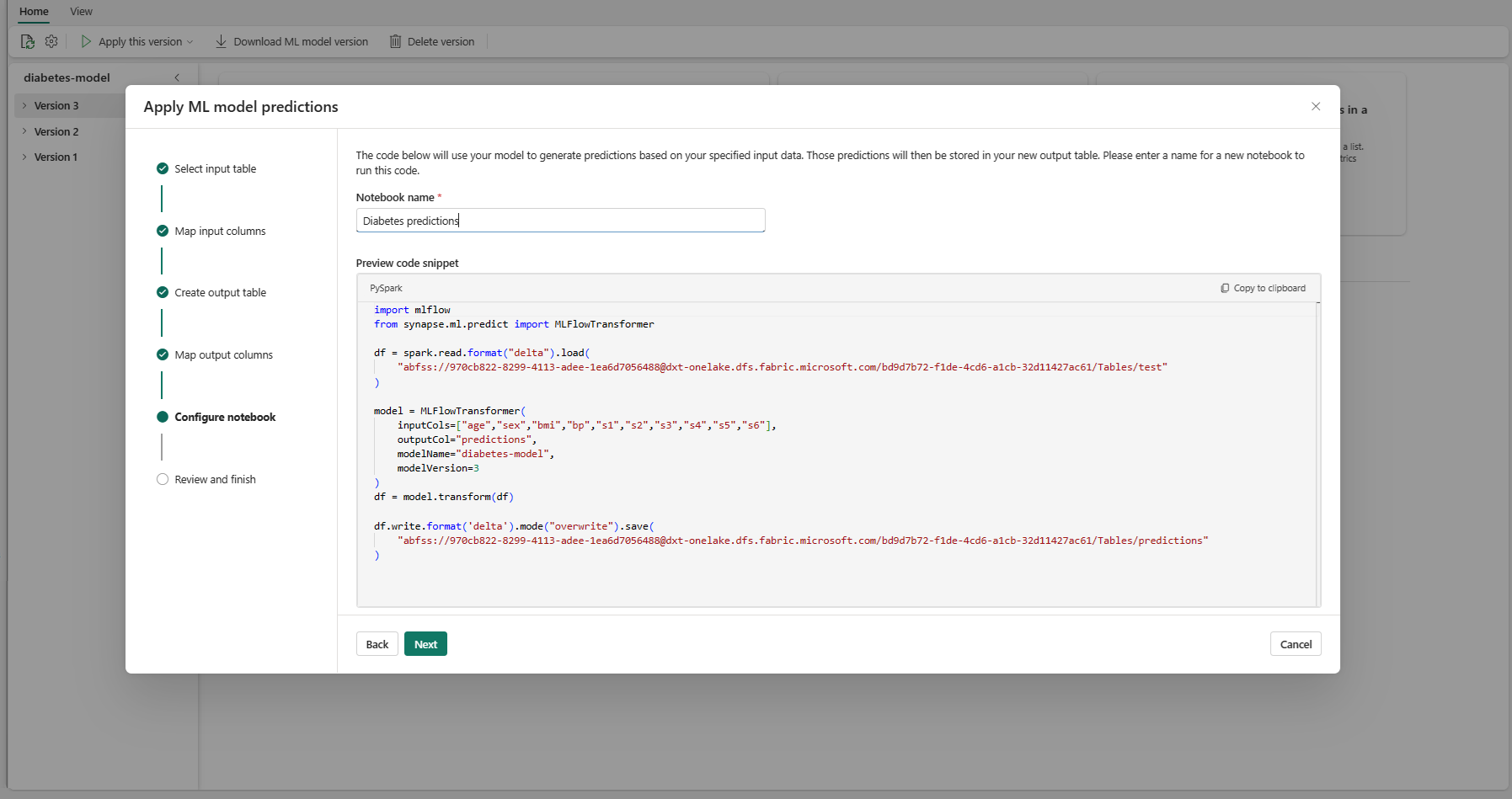
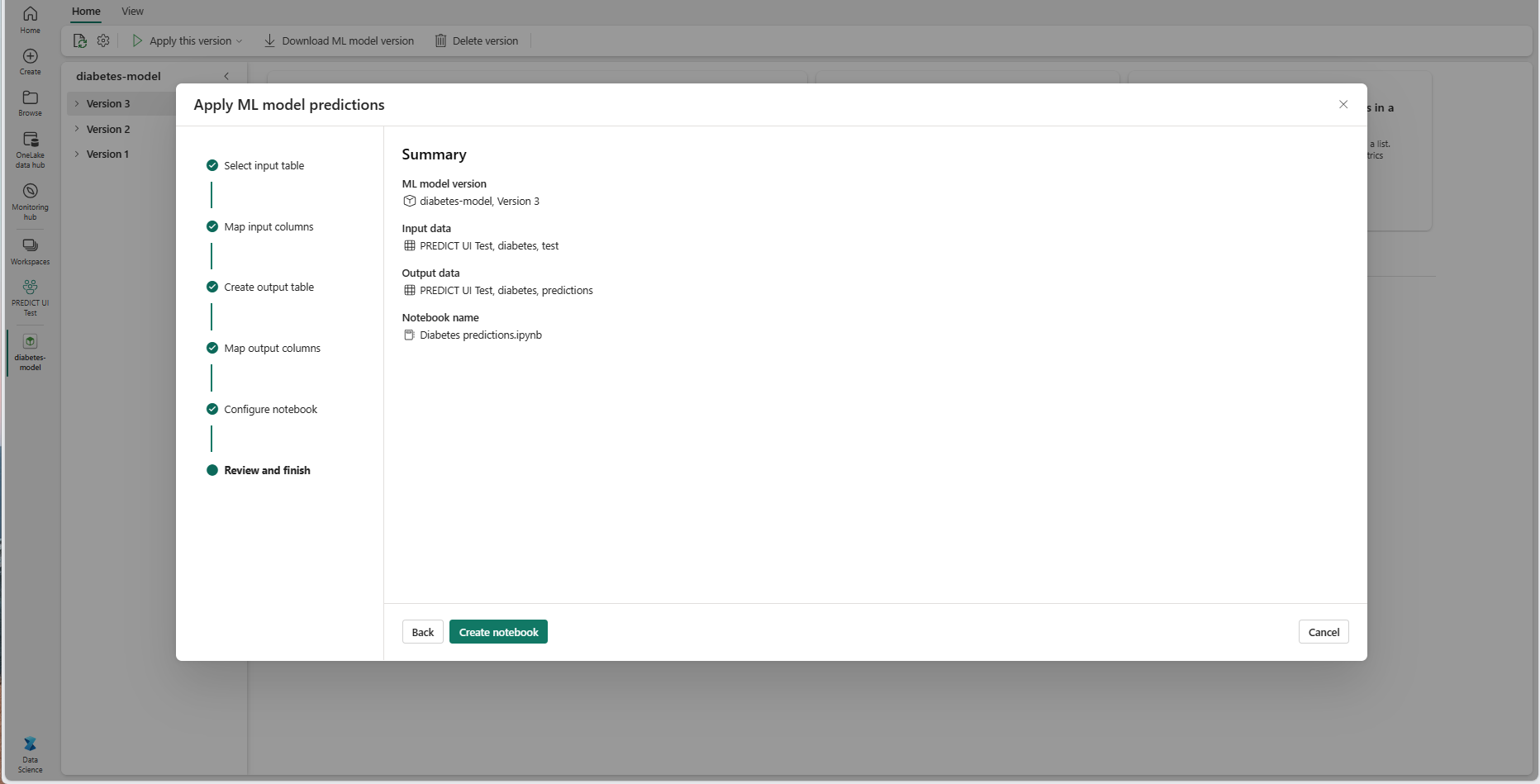
Pilih Berikutnya untuk masuk ke langkah "Tinjau dan selesai".
Tinjau detail di halaman ringkasan, dan pilih Buat buku catatan untuk menambahkan buku catatan baru dengan kode yang dihasilkan ke ruang kerja Anda. Anda dibawa langsung ke notebook tersebut, tempat Anda dapat menjalankan kode untuk menghasilkan dan menyimpan prediksi.







Menggunakan templat kode yang dapat disesuaikan
Untuk menggunakan templat kode untuk menghasilkan prediksi batch:
- Buka halaman item untuk versi model ML tertentu.
- Pilih Salin kode untuk diterapkan dari menu dropdown Terapkan versi ini. Dengan memilih, Anda menyalin templat kode yang dapat disesuaikan.
Anda dapat menempelkan templat kode ini ke dalam buku catatan untuk menghasilkan prediksi batch dengan model ML Anda. Agar berhasil menjalankan templat kode, ganti nilai berikut secara manual:
-
<INPUT_TABLE>: Jalur file untuk tabel yang menyediakan input ke model ML. -
<INPUT_COLS>: Daftar nama kolom dari tabel input untuk diumpankan ke model ML. -
<OUTPUT_COLS>: Nama untuk kolom baru dalam tabel output yang menyimpan prediksi. -
<MODEL_NAME>: Nama model ML yang digunakan untuk menghasilkan prediksi. -
<MODEL_VERSION>: Versi model ML yang digunakan untuk menghasilkan prediksi. -
<OUTPUT_TABLE>: Jalur file untuk tabel yang menyimpan prediksi.

import mlflow
from synapse.ml.predict import MLFlowTransformer
df = spark.read.format("delta").load(
<INPUT_TABLE> # Your input table filepath here
)
model = MLFlowTransformer(
inputCols=<INPUT_COLS>, # Your input columns here
outputCol=<OUTPUT_COLS>, # Your new column name here
modelName=<MODEL_NAME>, # Your ML model name here
modelVersion=<MODEL_VERSION> # Your ML model version here
)
df = model.transform(df)
df.write.format('delta').mode("overwrite").save(
<OUTPUT_TABLE> # Your output table filepath here
)