Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Dalam artikel ini, Anda mempelajari cara melakukan analisis data eksploratif dengan menggunakan Azure Open Datasets dan Apache Spark. Artikel ini menganalisis himpunan data taksi New York City. Data tersedia melalui Azure Open Datasets. Subset himpunan data ini berisi informasi tentang perjalanan taksi kuning: informasi tentang setiap perjalanan, waktu dan lokasi mulai dan berakhir, biaya, dan atribut menarik lainnya.
Dalam artikel ini, Anda:
- Mengunduh dan menyiapkan data
- Menganalisis data
- Memvisualisasikan data
Prasyarat
Dapatkan langganan Microsoft Fabric. Atau, daftar untuk uji coba Microsoft Fabric gratis.
Masuk ke Microsoft Fabric.
Beralih ke Fabric dengan menggunakan pengalih pengalaman di sisi kiri bawah halaman beranda Anda.

Mengunduh dan menyiapkan data
Untuk memulai, unduh himpunan data Taksi New York City (NYC) dan siapkan data.
Buat buku catatan dengan menggunakan PySpark. Untuk instruksi, lihat Membuat buku catatan.
Catatan
Karena kernel PySpark, Anda tidak perlu membuat konteks apa pun secara eksplisit. Konteks Spark secara otomatis dibuat saat Anda menjalankan sel kode pertama.
Dalam artikel ini, Anda menggunakan beberapa pustaka berbeda untuk membantu memvisualisasikan himpunan data. Untuk melakukan analisis ini, impor pustaka berikut ini:
import matplotlib.pyplot as plt import seaborn as sns import pandas as pdKarena data mentah dalam format Parquet, Anda dapat menggunakan konteks Spark untuk menarik file ke dalam memori sebagai DataFrame secara langsung. Gunakan OPEN Datasets API untuk mengambil data dan membuat Spark DataFrame. Untuk menyimpulkan jenis data dan skema, gunakan skema Spark DataFrame pada properti baca .
from azureml.opendatasets import NycTlcYellow end_date = parser.parse('2018-06-06') start_date = parser.parse('2018-05-01') nyc_tlc = NycTlcYellow(start_date=start_date, end_date=end_date) nyc_tlc_pd = nyc_tlc.to_pandas_dataframe() df = spark.createDataFrame(nyc_tlc_pd)Setelah data dibaca, lakukan beberapa pemfilteran awal untuk membersihkan himpunan data. Anda dapat menghapus kolom yang tidak diperlukan dan menambahkan kolom yang mengekstrak informasi penting. Selain itu, Anda dapat memfilter anomali dalam himpunan data.
# Filter the dataset from pyspark.sql.functions import * filtered_df = df.select('vendorID', 'passengerCount', 'tripDistance','paymentType', 'fareAmount', 'tipAmount'\ , date_format('tpepPickupDateTime', 'hh').alias('hour_of_day')\ , dayofweek('tpepPickupDateTime').alias('day_of_week')\ , dayofmonth(col('tpepPickupDateTime')).alias('day_of_month'))\ .filter((df.passengerCount > 0)\ & (df.tipAmount >= 0)\ & (df.fareAmount >= 1) & (df.fareAmount <= 250)\ & (df.tripDistance > 0) & (df.tripDistance <= 200)) filtered_df.createOrReplaceTempView("taxi_dataset")
Menganalisis data
Sebagai analis data, Anda memiliki berbagai alat yang tersedia untuk membantu Anda mengekstrak wawasan dari data. Di bagian artikel ini, pelajari tentang beberapa alat berguna yang tersedia dalam notebook Microsoft Fabric. Dalam analisis ini, Anda ingin memahami faktor-faktor yang menghasilkan tips taksi yang lebih tinggi untuk periode yang dipilih.
Magic Apache Spark SQL
Pertama, lakukan analisis data eksploratif dengan menggunakan Apache Spark SQL dan perintah ajaib dengan notebook Microsoft Fabric. Setelah Anda memiliki kueri, visualisasikan hasilnya dengan menggunakan kemampuan bawaan chart options .
Di buku catatan, buat sel baru dan salin kode berikut. Dengan menggunakan kueri ini, Anda dapat memahami bagaimana jumlah tip rata-rata berubah selama periode yang Anda pilih. Kueri ini juga membantu Anda mengidentifikasi wawasan berguna lainnya, termasuk jumlah tip minimum/maksimum per hari dan jumlah tarif rata-rata.
%%sql SELECT day_of_month , MIN(tipAmount) AS minTipAmount , MAX(tipAmount) AS maxTipAmount , AVG(tipAmount) AS avgTipAmount , AVG(fareAmount) as fareAmount FROM taxi_dataset GROUP BY day_of_month ORDER BY day_of_month ASCSetelah kueri selesai berjalan, Anda bisa memvisualisasikan hasilnya dengan beralih ke tampilan bagan. Contoh ini membuat bagan garis dengan menentukan bidang
day_of_monthsebagai kunci dan sebagai nilaiavgTipAmount. Setelah Anda membuat pilihan, pilih Terapkan untuk me-refresh bagan Anda.
Memvisualisasikan data
Selain opsi pembuatan bagan buku catatan bawaan, Anda bisa menggunakan pustaka sumber terbuka populer untuk membuat visualisasi Anda sendiri. Dalam contoh berikut, gunakan Seaborn dan Matplotlib, yang umumnya digunakan pustaka Python untuk visualisasi data.
Untuk membuat pengembangan lebih mudah dan lebih murah, downsample himpunan data. Gunakan kemampuan pengambilan sampel Apache Spark bawaan. Selain itu, Seaborn dan Matplotlib memerlukan Pandas DataFrame atau array NumPy. Untuk mendapatkan DataFrame Pandas, gunakan perintah
toPandas()untuk mengonversi DataFrame.# To make development easier, faster, and less expensive, downsample for now sampled_taxi_df = filtered_df.sample(True, 0.001, seed=1234) # The charting package needs a Pandas DataFrame or NumPy array to do the conversion sampled_taxi_pd_df = sampled_taxi_df.toPandas()Anda dapat memahami distribusi tips dalam himpunan data. Gunakan Matplotlib untuk membuat histogram yang menunjukkan distribusi jumlah dan jumlah tip. Berdasarkan distribusi, Anda dapat melihat bahwa tips condong ke arah jumlah kurang dari atau sama dengan $10.
# Look at a histogram of tips by count by using Matplotlib ax1 = sampled_taxi_pd_df['tipAmount'].plot(kind='hist', bins=25, facecolor='lightblue') ax1.set_title('Tip amount distribution') ax1.set_xlabel('Tip Amount ($)') ax1.set_ylabel('Counts') plt.suptitle('') plt.show()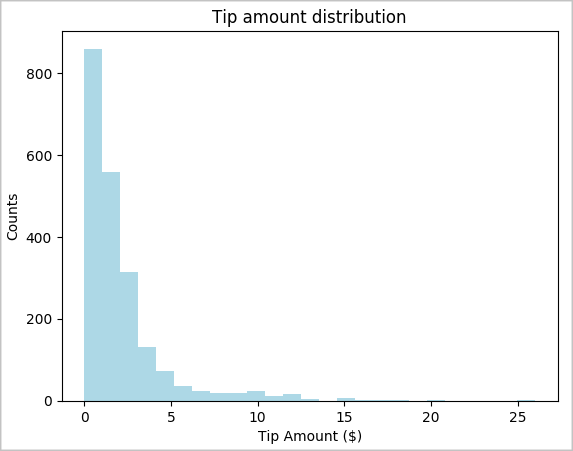
Selanjutnya, cobalah untuk memahami hubungan antara tips untuk perjalanan tertentu dan hari dalam seminggu. Gunakan Seaborn untuk membuat plot kotak yang meringkas tren untuk setiap hari dalam seminggu.
# View the distribution of tips by day of week using Seaborn ax = sns.boxplot(x="day_of_week", y="tipAmount",data=sampled_taxi_pd_df, showfliers = False) ax.set_title('Tip amount distribution per day') ax.set_xlabel('Day of Week') ax.set_ylabel('Tip Amount ($)') plt.show()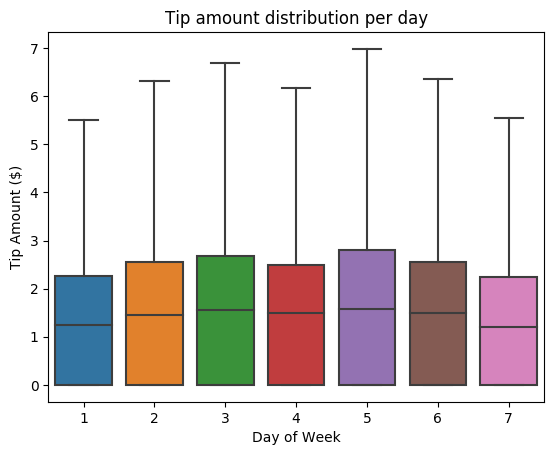
Hipotesis lain mungkin ada hubungan positif antara jumlah penumpang dan jumlah total tip taksi. Untuk memverifikasi hubungan ini, jalankan kode berikut untuk menghasilkan plot kotak yang mengilustrasikan distribusi tip untuk setiap jumlah penumpang.
# How many passengers tipped by various amounts ax2 = sampled_taxi_pd_df.boxplot(column=['tipAmount'], by=['passengerCount']) ax2.set_title('Tip amount by Passenger count') ax2.set_xlabel('Passenger count') ax2.set_ylabel('Tip Amount ($)') ax2.set_ylim(0,30) plt.suptitle('') plt.show()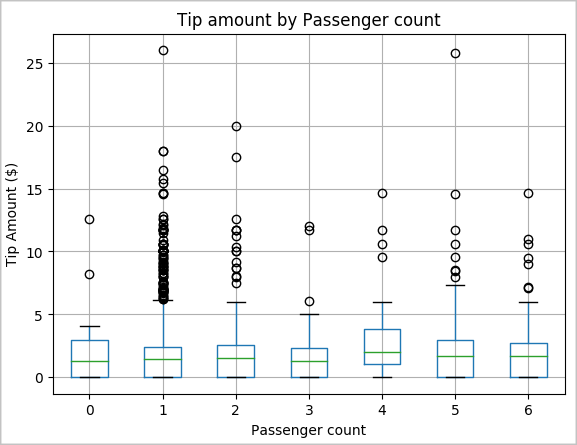
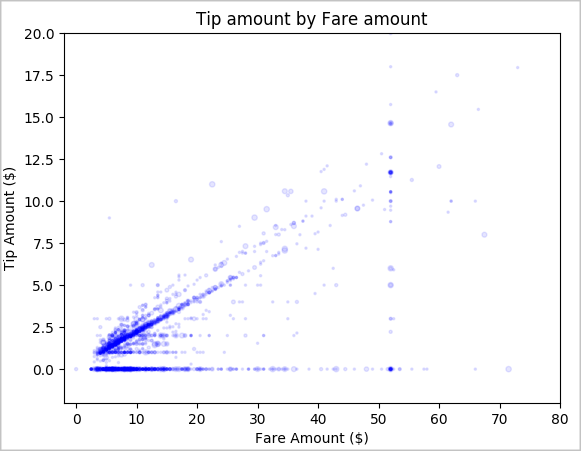
Terakhir, jelajahi hubungan antara jumlah tarif dan jumlah tip. Berdasarkan hasilnya, Anda dapat melihat bahwa ada beberapa pengamatan di mana orang tidak memberi tip. Namun, ada hubungan positif antara tarif keseluruhan dan jumlah tip.
# Look at the relationship between fare and tip amounts ax = sampled_taxi_pd_df.plot(kind='scatter', x= 'fareAmount', y = 'tipAmount', c='blue', alpha = 0.10, s=2.5*(sampled_taxi_pd_df['passengerCount'])) ax.set_title('Tip amount by Fare amount') ax.set_xlabel('Fare Amount ($)') ax.set_ylabel('Tip Amount ($)') plt.axis([-2, 80, -2, 20]) plt.suptitle('') plt.show()